본 논문은 특별한 학습없이 다양한 모달리티의 foundation model을 에이전트 구조로 통합하여 모달리티 통합 시스템(omni-modal reasoning)을 세팅할 수 있음을 보인 연구입니다. 본 내용에 대해서는 이어서 더욱 자세하게 다루어 보겠습니다.
#intro

최근 멀티모달 대형 언어 모델(MLLMs)은 높은 성능을 보이고 있으나, 다양한 모달리티에 대해 모두 잘 동작하지는 않습니다. 아래의 Figure1에서 확인 할 수 있듯이 Agent-Omni를 제외한 기존 모델의 경우 데이터셋/도메인 마다 성능이 상이하며, 하나의 모달리티에 잘 동작함이 다른 모달리티에서도 잘 동작함을 의미하지는 않습니다. 또한 Table1에서 확인할 수 있듯이 모든 모델이 다양한 모달리티 입력을 수용할 수 있는것은 아닙니다. 한편 다양한 입력을 수용할 수 있는 Omni 시스템을 위해 MLLMs을 학습하는데 큰 비용이 발생하기 때문에 모든 모달리티에서 잘 동작하는 모델을 구성하는 것은 현실적으로 어려우며, 학습 데이터셋을 구축하는것 조차 매우 어렵습니다.
따라서 저자들은 학습 데이터 없이 master agent와 model pool로 구성된 agent system으로 학습 없이 omni modal 에 대해 수행할 수 있음을 보였으며, 그 결과 비교 모델에 대비하여 높은 성능을 달성했음을 확인할 수 있습니다.
#Agent-Omni
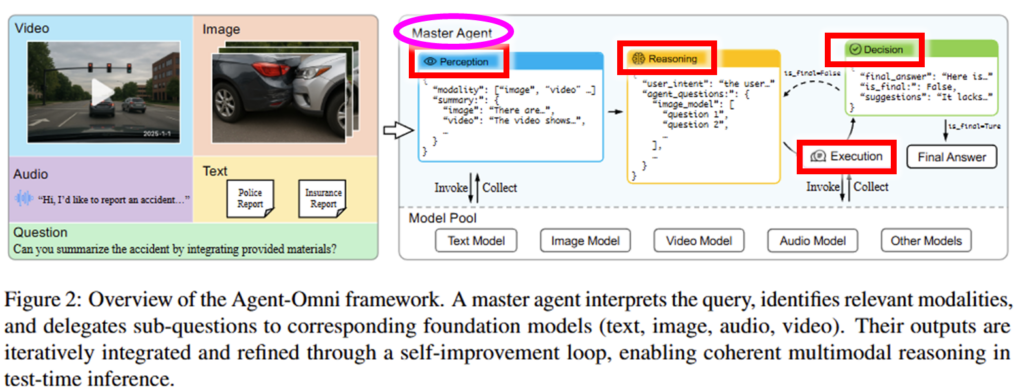
저자들은 학습없이 다양한 도메인의 입력을 처리할 수 있는 시스템을 위하여 agent-omni 시스템을 제안했습니다. agent-omni는 master agent를 통해 기존 파운데이션 모델을 조율하도록 하여 입력 모달리티에 대한 유연성을 확보했으며 워크플로우는 Figure2와 같습니다.
구조의 메인이 되는 master agent는 4가지 기능으로 구성됩니다: perception, reasoning, execution, decision(figure2 붉은 박스). perception은 입력을 통일된 json형태로 구조화하는 기능입니다. Figure2 에서 확인할 수 있듯이 모달리티별로 model pool의 파운데이션 모델을 호출하여 구조화된 정보로 요약하는 단계입니다. 다음으로 Reasoning은 사용자의 질의(question)을 작은 질문(sub-question)으로 나누는 과정입니다. Figure2의 노란 박스가 해당 기능의 출력값이며, 모달리티 별로 작은 질문을 정리하여 reasoning 과정의 해석가능성을 확보하였습니다. 다음으로 분해된 질문을 수행하는 과정이 Execution에 해당합니다. reasoning 과정으로 생성된 작업들을 수행하며 그 출력을 수집하는 단계입니다. 해당 메커니즘으로 중간 결과에 대해 추적이 가능하며, 이 또한 해석 가능성을 확보하는 구조입니다. 마지막으로 Decision은 수집된 결과를 기반으로 추론을 멈출지 지속할지 결정하는 기능입니다. 만약 추론을 멈추어도 된다고 판단되면(is_final=True) 정답값(final_answer)를 생성하고 그렇지 않다면 추론을 최대 한계(L)에 도달하기 전까지 반복할 수 있습니다.
다음으로 master agent의 도구인 파운데이션 모델은 Model pool에서 호출됩니다. 이러한 구조는 모델을 유연하게 변경할 수 있어 agent-omni 프레임워크가 확장성을 갖게 합니다. 저자가 제안한 구조는 직관적이고 단순합니다. 또한 프로세스 진행 중간의 해석가능성에 대해 고려하고 있다는 것이 특징입니다.
#Experiment Evaluation
agent 구조를 통해 구성된 시스템의 실제 동작 성능은 어떨까요? 논문은 이를 확인하기 위한 평가를 진행합니다. 특히 아래 항목을 달성하였는지에 집중하여 평가하였다고 합니다. (실험 디테일에 대한 부가적 정보는 아래의 #Additional을 참고해주세요)
- agent-omni가 다양한 모달리티에 걸쳐 잘 동작하고 있는가?
- 추론에서 계산량/효율성에 대한 경쟁력은 어떠한가?
- Model pool에서 다른 파운데이션 모델을 선택할 때 agent-omni 시스템의 정확도에 어떤 영향을 미치는가?
- 최대 반복 횟수(L, master loop)를 변경했을 때 최종 성능에 어떤 영향을 미치는가?
전반적인 실험 결과는 Figure1과 같으며, 모든 벤치마크에서 제안 방법이 일반적으로 우수한 성능을 보임을 통해 다양한 모달리티에 걸쳐 잘 동작함(1)을 확인했습니다. Figure1에 대한 수치적 정보는 아래와 같습니다.
다음으로 연산량에 대한 실험 결과입니다. 다양한 파운데이션 모델을 반복적으로 호출하는 에이전트 구조가 성능이 우수한것은 직관적인 결과로 생각될 수 있습니다. 그렇다면 연산량의 증가 정도는 어떨까요? 저자는 추론에 걸리는 시간(Latency)을 리포팅하여 이를 검증했습니다. 안타깝게도 Agent-omni는 성능의 개선만큼 연산량이 크게 증가하고 있음을 확인할 수 있습니다. 논문에서는 그저 연산량과 성능사이의 trade-off 관계가 성립한다고 언급하고 있는점이 아쉽지만, 가장 베이직한 구조를 제시하고 그 현황을 리포팅하는 포지션의 연구로 생각하시면 좋을 것 같습니다.

Table10은 최대 반복횟수 조정에 따른 시스템 전체 성능 변화를 리포팅 한 것입니다. 본 실험은 제안한 agent-omni 아키텍쳐의 안정성을 검토하는 실험으로 볼 수 있습니다. 결과에 따르면 대부분의 쿼리가 첫번째 반복 이후 종료되며(Table10의 Exit Rate의 1에 대다수가 할당) 최대 반복 횟수 증가에 따른 성능 변화가 미미함을 예측할 수 있습니다.

#Additional
A. 실험에 사용된 데이터셋 구성
연구진은 다중모달 이해능력을 평가하기 위해 다섯가지 도메인(텍스트, 이미지, 비디오, 오디오, 옴니 레벨)에 대해 다양한 벤치마크 데이터셋을 사용했습니다. 텍스트(MMLU, MMLU-Pro, AQUA-RAT), 이미지(MathVision, MMMU, MMMU-Pro), Video(VideoMathQA, STI-Bench, VSI-Bench), Audio(MMAU, MELD-Emotion, VoxCeleb-Gender), Omni-level(Daily-Omni, OmniBench, OmniInstruct)
B. 실험의 베이스라인 아키텍쳐
연구진은 제안 방법과 비교를 위해 기존 Foundation model과 구조화된 프롬프트로 single model의 추론을 개선한 DSPy-CoT를 베이스라인으로 하였습니다. 저자는 해당 비교를 통해 단일 모델 내에서 추론을 개선하는 것과 여러 파운데이션 모델을 협력하도록 하는것의 차이를 부각하고자 했다고 언급하였습니다. 또한 실험에서 agent-omni 구조의 최대 반복 횟수(L)는 3으로 설정되었습니다.
C. Model pool의 구성
Model pool로 사용된 파운데이션 모델과 역할은 아래와 같습니다.

좋은 리뷰 감사합니다.
질문이 하나 있는데, Reasoning 단계에서 사용자의 질문을 모달리티별 sub-question으로 나눈다고 하신 것 같은데요. 혹시 이 분해는 master agent가 프롬프트만으로 수행하는 방식인가요? 아니면 각 모달리티별로 정해진 template이나 rule이 있는지도 궁금합니다.
안녕하세요 리뷰 읽어주셔서 감사합니다.
말씀해주신대로 프롬프트로 수행하는 방식으로 모달리티별로 정해진 탬플릿이 있는것은 아닙니다
혹시 프롬프트 생성에 활용된 탬플릿이 궁금하시면 논문의 보충자료의 figure4로 확인할 수 있습니다!
논문 링크: https://arxiv.org/pdf/2511.02834
감사합니다.