
안녕하세요 오늘은 위 영상처럼 3인칭 영상을 1인칭 영상으로 만들어주는 논문을 가져왔습니다.
시각적 결과가 인상깊어서 어떻게 했나 궁금해서 한번 읽어봤습니다.
Introduction
1인칭 시점 영상을 만드는 것을 쉽지 않은 task입니다. model은 보이는 영역을 reconstruct하는 동시에 보이는 않는 영역은 synthesize해야합니다. 위 축구 영상에서도 골키퍼가 골을 차는 사람에 막혀 보이지 않을때도 synthesize해서 그려내는 것을 볼 수 있습니다. 일반적으로 이러한 문제를 풀려면 camera control model을 사용합니다. Camera control model은 카메라의 움직임만 condition으로 주는 방식입니다. 하지만 저자들은 이러한 camera control model들은 view point 변화가 크지 않은 상황(modest)에서만 강하다고 합니다. 3인칭(exocentric) to 1인칭(egocentric) video generation은 visible field of view가 크게 바뀌어서 기존 방식으로 풀기는 어렵다고 주장합니다.
그리고 이런 차이는 크게 2가지 문제를 가진다고 합니다.
- 심한 viewpoint 변화는 large unseen region을 발생시킵니다. 그리고 이러한 영역은 scene understanding을 바탕으로 synthesis되어야합니다.
- exocentric(3인칭) view와 egocentric(1인칭) view 사이에는 overlap되는 영역이 작습니다. 이는 model이 view-related 정보를 구별하기 어렵게 만들어서 condition으로 써야하는 정보와 억제되어야하는 content를 구별하기 어렵습니다.

위 Figure 2.처럼 좋은 generation을 위해서는 의미 있는 영역만 attend하는게 중요합니다. 보면 노랑색 영역은 overlap하는 영역이므로 집중해야하고, 파랑색 영역은 suppress돼어야합니다. 그리고 빨간색 영역은 그럴듯하게 생성해야하는 부분입니다. 하지만 기존의 camera control model은 이런 문제에 집중하지 않아서 exocentric-to-egocentric video generation을 잘하지 못한다고 합니다.
이러한 상황에서 저자들의 contribution을 정리해보겠습니다.
- EgoX라는 고품질의 egocentric에서 exocentric의 video를 만드는 model을 제안함
- width-wise와 channel-wise 통합을 이용한 unified conditional strategy를 디자인함
- view와 관련 있는 곳에 집중하는 geometry-guided self-attention과 clean latent representation을 제안함
Method

먼저 video sequence X = {X_i}_{i=0}^F와 egocentric cameara pose \phi = {\phi_i}_{i=0}^{F}를 입력으로 받습니다. 그리고 목표는 egocentric view Y = {Y_i}_{i=0}^F를 만들어내는 것입니다. 요약해서 구조를 먼저 설명하면 먼저 X를 3D로 표현(lift)하고 egocentric한 viewpoint로 rendering합니다. 그리고 이를 egocentric prior video P라고 부릅니다. Video diffusion model에는 X와 P가 들어갑니다.
Egocentric Point Cloud Rendering
이 부분은 P \in \mathbb{R}^{F \times 3 \times H \times W}를 만듭니다. 만들기 위해서는 각 이미지에 대해서 Monocular Depth Estimation 모델을 사용합니다(여기선 MoGE2를 사용했습니다, D^m \in \mathbb{R}^{F \times H \times W}). 그리고 temporal depth estimation 모델을 통해 한번 더 뽑아줍니다(D^v \in \mathbb{R}^{F \times H \times W}). 이렇게 두번 뽑는 이유는 D^v이 프레임 간 더 잘 이어지고 affine 불변한 depth estimate 결과를 내놓기 때문입니다. 이후 D^m를 이용해서 D^v를 align 시킵니다.
정리하자면, D^m와 같은 무거운 모델로 뽑은 결과는 scale의 값이 더 정확하고, D^v와 같이 temporal한 관계를 고려한 모델로 뽑은 결과는 frame 사이가 더 잘 이어집니다. 그래서 D^v를 D^m로 momentum기반(ViPE 논문에서 사용한 방식을 그대로 가져왔다고 합니다) affine 변환을 시켜습니다. 이를 통해, 프레임간 잘 이어지면서 scale값이 더 정확해진 결과(D^f)를 얻었습니다.
그리고 D^f는 Dynamic object를 masking하여 static한 배경 영역만 내놓습니다(이 역시 ViPE를 그대로 가져왔습니다).
이렇게 3D point cloud로 표현되었고, static한 배경만 남은 D^f를 point cloud render를 이용하여 exocentric하게 표현합니다.
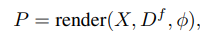
Exo-to-Ego View Generation with VDM
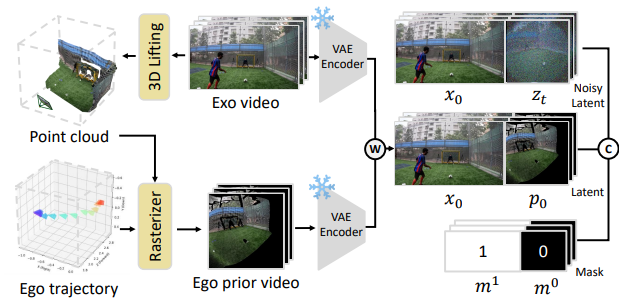
frozen VAE에 exocentric 영상과 위에서 만든 P가 입력으로 들어갑니다. 각각 x_0 \in \mathbb{R}^{f \times c \times h \times w}, p_0 \in \mathbb{R}^{f \times c \times h \times w}로 표현됩니다.
이후 p_0와 noise latent z_t \in \mathbb{R}^{f \times c \times h \times w}를 channel-wise로 concat합니다. p_0는 camera pose로 투영되었기 때문에 생성하려는 영상과 pixel단위로 일치합니다. 그렇기에 viewpoint-aligned된 temporal guidance를 제공하지만, 그럼에도 여전히 noisy하고 정보가 부족합니다. 그래서 x_0를 사용하여 더 넓은 scene의 context를 제공합니다.
x_0의 viewpoint가 noisy latent z_t와 다르기 때문에 width dimention을 따라 concat합니다. denoising step을 할때 z_t가 항상 clean한 x_0를 보고, 또 x_0가 timestep에 따라 변하지 않기 때문에 모델이 고정된 reference fine-grained를 얻어 더 정확한 spatial wraping이 가능하다고 저자들은 얘기합니다.
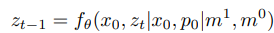
denoising이 끝난 후에는 exocentric한 latent는 제거합니다. 그리고 egocentric한 부분만 decoding해서 최종 결과를 얻어냅니다.
Geometry-Guided Self-Attention
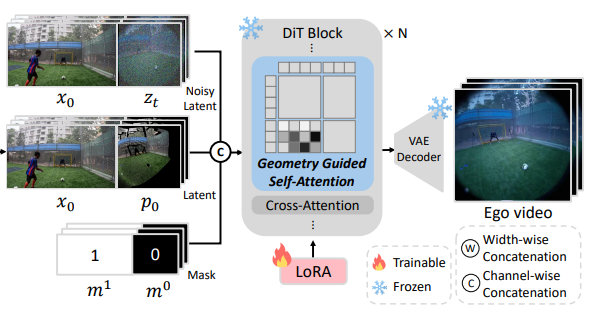
영상을 생성할때 viewpoint가 다른 x_0를 주기 때문에 학습 도중 모델이 distract될 수 있습니다. 이를 방지하기 위해 저자들은 Geometry Guided Self-Attention(이하 GGA)를 제안했습니다. 이는 exo/egocentric들 중 대응되는 부분에 집중합니다. egocentric한 query token을 q_{ego} \in \mathbb{R}^{l \times c}라고 할때 exocentric한 key token k_{\text {exo}} \in \mathbb{R}^{l \times c}에 attend합니다.
GGA는 여기에 geometric한 정보를 더해줍니다. 우리는 camera pose를 알고 있기 때문에 ego camera center c에 대한 각 지점의 ray를 구할 수 있습니다.
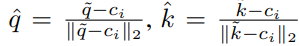
query token과 key token의 ray를 각각 \hat{q}, \hat{k}이라 하자.
그러면 기본 attention에 \hat{q}, \hat{k}의 cosine 유사도 값을 더해줄 수 있습니다.
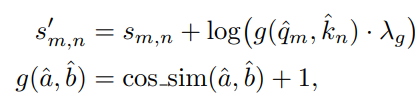
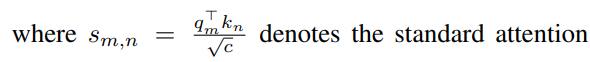
이러한 과정을 통해, attention에 spatial relationship을 encoding해주었습니다.
일반적으로 이미지 생성에서는 rotation을 이용해서 spatial한 관계를 encoding해주곤합니다. 그러나 video 생성은 camera의 위치가 매 frame 변하기 때문에 key의 방향을 query에 항상 상대적으로 구해줘야합니다.
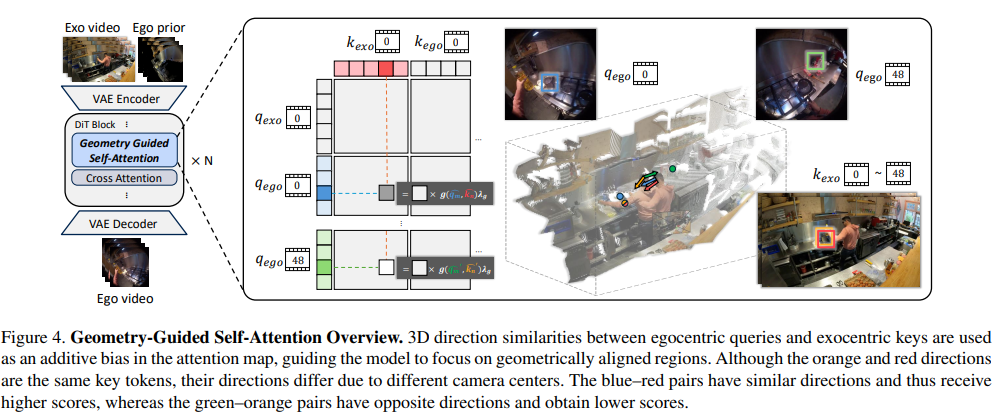
Fig 4.를 보면 k_{exo}는 frame에 따라 완전히 다른 q_{exo}에 대응됩니다. 이처럼 rotate로 표현하게 되면 위치가 변하는 문제를 해결할 수 없기에 저자들은 addtion으로 처리하는게 맞다고 주장하고 있습니다.
Experiments
저자들이 평가하고자 하는 목표는 4개입니다.
- 우리 방법론이 정상/정량적으로 baseline보다 얼마나 높은가
- exocentric에서 보이는 영역을 얼마나 reconstruct 잘하는가
- unseen scene과 in-the-wild scene을 잘 처리하는가
- 전반적인 performance와 generation quality에 각 요소가 얼마나 기여하는가
Implementation Details
영상 생성에 주로 사용되는 Wan 2.1를 LoRA를 붙여서 사용했습니다. 학습은 H200(140gb) 8개로 하루동안 했다고 합니다. 그리고 Ego-Exo4D 중 4000개의 clip을 골라, 3600개를 학습 나머지 400개를 test에 사용하였습니다.
Quantitative Results
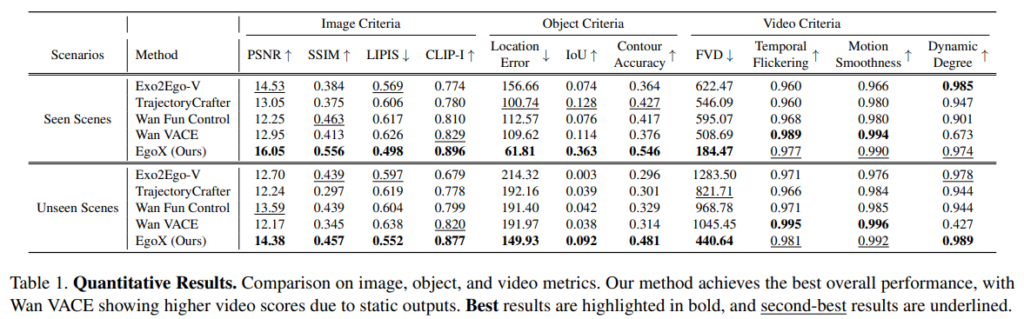
Table 1.의 평가지표로는 3개가 있습니다.
Image Criteria는 GT와 생성된 frame과의 비교입니다.
Object Criteria는 SAM2로 segment하고 DINOv3로 물체를 track한 후 IoU를 계산합니다
Video Criteria는 FVD를 이용하여 측정합니다. FVD는 간단한 3d CNN network를 태운 후 중간 layer의 특징의 분포를 비교하는 방식입니다.
Table 1을 보면 object criteria에서 높은 격차를 보이는 것을 볼 수 있습니다. 이는 저자의 방법론이 scene의 geomtry와 object의 일관성을 잘 잡아낸다는 지표입니다. 이외에도 Seen과 Unseen 모두에서 대부분의 지표에서 높은 성능을 보이고 있습니다. Video Criteria에서는 WAN VACE가 높은 성능을 보이고 있는데, 이는 해당 모델이 static하고 motion이 제한된 상황을 학습한 모델이기 때문에 flickering이나 smotthness가 높다고 얘기하고 있습니다.
Ablation Study
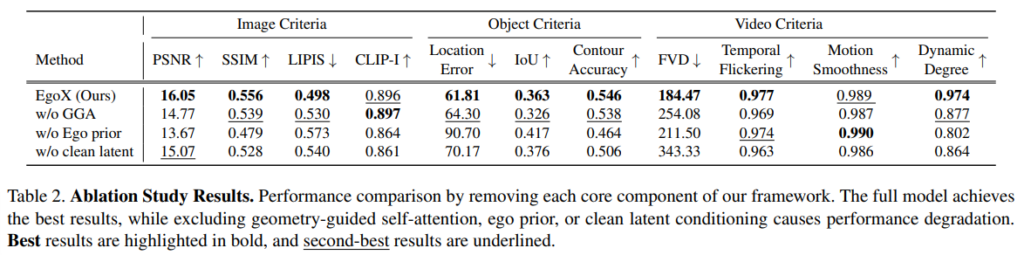

ablation을 정성/정량적 둘다 진행했습니다. 어느 것을 봐도, 요소 하나하나가 중요한 역할을 하고 있습니다. 특히 저자는 GGA가 없으면 Geometric한 align이 안된다고 얘기합니다.(다만 개인적으로는 Figure 6이 잘 못 드러내는 것 같음) 그리고 egocentric prior가 없으면 explicit한 pixel 단위의 camera 정보가 없어서 viewpoint를 맞추기 못하는 것이 잘 드러납니다. clean latent(denoising시 x_0 제공)가 없으면 fine-grained detail이 blur한 것을 볼 수 있습니다. Fig 6.을 더 자세히 보면 숫가락이나 재료들이 많이 누락되었습니다.
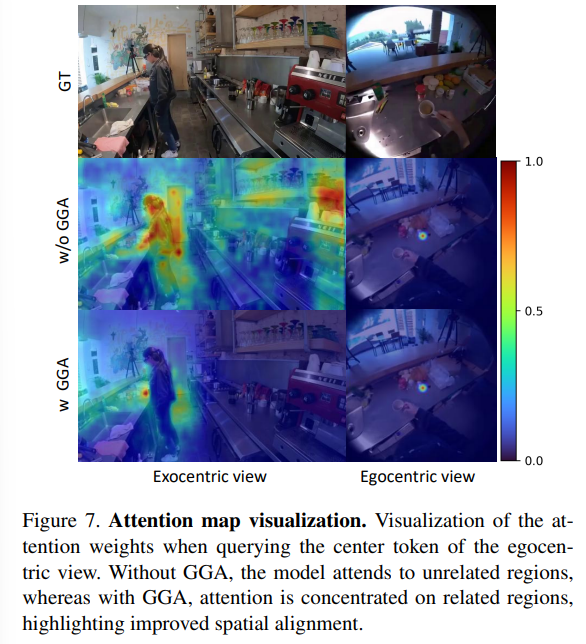
Figure 7.은 attention map을 보여줍니다. GGA가 없으면 관련없는 넓은 영역에 집중하는 것을 볼 수 있습니다. 하지만 GGA를 넣으면 관련 있는(viewpoint가 일치하는) 영역에 대해서만 집중합니다.
Limitation
결국 가장 큰 문제는 egocentric한 camera pose가 필요하다는 점입니다. 저자들은 head pose estimation module과 통합하면 좋지 않을까~라는 future work로 남겨두고 있습니다. 참고로 맨 위 영화 다크나이트의 결과는 저자들이 viser tool을 이용하여 직접 ego trajectory를 지정해주었습니다.
additional visualization

안녕하세요, 정우님. 좋은 리뷰 감사합니다.
리뷰를 읽으면서 이 방법론이 simulator에서 직접 1인칭 데이터를 수집하는 방식과 비교했을 때, 어떤 측면에서 더 효율적인지 궁금했습니다. 기존 exocentric video를 활용해 egocentric video를 생성할 수 있다는 점에서 데이터 구축 비용이나 확장성 측면의 장점이 있는 것인지, 혹은 sim-to-real gap을 줄이는 데에도 의미가 있는지 궁금합니다.
또한 입력 구조에 대해 제가 이해한 것이 맞는지도 확인하고 싶습니다. 리뷰 내용을 보면 사용자가 직접 point cloud를 넣는 방식이라기보다는, exocentric video와 egocentric camera pose/trajectory를 입력으로 주고, depth estimation과 rendering 과정을 통해 point cloud와 egocentric prior video가 내부적으로 생성되는 흐름으로 이해했는데, 이렇게 보는 것이 맞을까요?
좋은 리뷰 감사합니다!
안녕하세요 기현님 질문 감사합니다.
먼저 해당 방법론은 데이터 구축관점에서 대해서 논문에서 얘기하진 않았습니다.
그러나 exocentric video들을 손쉽게(head pose만 있다면) egocentric video로 변환가능하며, 이를 실제 학습에 사용도 가능할 것이라고 생각됩니다.
그리고 입력구조는 이해하신게 맞습니다.
감사합니다.
안녕하세요 김정우 연구원님 좋은 리뷰 감사합니다.
egocentric 영상에 대한 수요가 점점 증가하는 와중에 exocentric 영상을 egocentric으로 성공적으로 변환할 수 있다면 데이터의 취득 및 다양성 확보의 관점에서 장점을 갖는 연구인것 같습니다.
익숙치 않은 task이다보니 task에 관련하여 몇가지 궁금한 점이 있습니다. limitation에서도 언급하고 있지만 모델의 학습과 평가를 위해서는 포즈에 대한 정보가 필수적인 것으로 보이는데, 포즈에 대한 정보가 데이터셋에 있는건지 아니면 포즈에 대한 정보도 camera control model을 활용하여 정보를 취득하는 건지 궁금합니다.
또 Figure 2에서의 빨간색 영역처럼 exocentric 영상만으로는 얻기 어려운 정보에 대해서는 그럴듯하게 생성하는 것이 최선일것 같은데 그렇게 된다면 LIPIS나 CLIP-I는 괜찮더라도 PSNR, SSIM와 같이 low-level 유사도를 기반으로 평가하는 방식은 노이즈가 어느정도 있을 수 밖에 없을 것 같습니다. 물론 정량적을 평가하기 위해서 어느정도 감수해야할 부분이기는 하지만 이부분에 대한 저자의 생각이 논문에 있었는지 궁금합니다.
감사합니다.
안녕하세요 정우님 좋은 리뷰 감사합니다.
generation 모델 리뷰를 많이 읽은건 아니지만 저자의 방법론이 이전 흐름을 어느정도 가져와서 추가 contribution을 제시한거로 보였습니다. 여기서 궁금한게 비디오의 geometric 한 지점의 attention 을 사용하는게 이 저자가 처음인지? 그게 아니라면 기존 방법론들은 저자가 한계라고 말했던 것처럼 rotate aware 하지 않은, 시점이 변하는거를 대응하지 못하는 방식으로 처리하고 있었던건지 궁금합니다. 그리고 뭔가 있는 task 일지는 모르겠는데 이렇게 시점변화말고도 전체 scene generation을 하는? 혹은 360도에 대한 생성 task 도 있을거같은데, egocentric한 시점에서 360도 서라운드뷰를 생성해낼 수도 있을 것 같아서, 이럴때는 저자의 contribution을 어떻게 가져가는게 좋을지 정우님의 생각이 궁금합니다.
감사합니다.
안녕하세요 정우님 리뷰 감사합니다.
3인칭 영상을 1인칭화 하는 연구도 흥미로운 것 같습니다. 이쪽 분야도 비디오 디퓨전을 다루다보니 모델이 커지고 리소스가 필요해지는건 어쩔 수 없을 것 같네요,, 질문이 두가지 있는데요,
Q1. 3인칭 1인칭 pair 데이터로 inpainting 하는 diffusion 모델 기반이다보니 어쩔 수 없이 3인칭 영상에 등장하지 않는 부분은 그럴싸하게 만들어야 할 것 같은데, 생각보다 실험에 등장하는 scene들이 다양한 것 같은데 데이터셋이 워낙 폭넓은 것인지, 모델 자체가 가진 능력이 큰건지 궁금합니다.
Q2. 3인칭 영상에서의 객체를 geometry에 맞게 1인칭 영상에 담아 내느것을 중점으로 두는 것 같은데, 해당 객체를 조작할때 생기는 물리적인 현상 (객체 자체의 움직임, 혹은 환경과의 상호작용)을 잘 담아내는지에 대한 실험이나 저자들의 의견이 있는지 궁금합니다.
안녕하세요 정우님 좋은 리뷰 감사합니다
질문 한가지 남깁니다..
Egocentric camera pose는 어떻게 받는 건가요? 학습 때는 Ego-Exo4D의 GT pose를 그대로 쓰는 건지, 그리고 inference 때 임의의 exocentric 영상에 대해 적용하려면 (Dark Knight 예시처럼 viser로 직접 지정하는 거 말고) 어떤 방식이 현실적인지 정우님의 의견이 궁금합니다.
감사합니다
안녕하세요 정우님, 좋은 리뷰 감사합니다. 질문이 있어서 남겨 놓습니다.
Ego Trajectory를 통해서 p_0의 camera pose가 결정될 것 같은데, 영상에서는 꽤 head pose와 비슷하게 view가 움직이는 것 같습니다. 논문에서 head pose가 아니라면 어떤 방법으로 Ego Trajectory를 결정하고 있나요? 그리고 head pose를 추정하는 방법으로 가더라도 head pose의 GT가 있지 않을 것 같은데 그 정확도를 파악할 수 있을까 싶네요.
감사합니다.