안녕하세요 이번에 가져온 논문은 다들 알고는 있는 CLIP 의 잠재 공간이 복잡한 시각-텍스트 상호작용을 못한다는 것을 밝히고 해결까지한 논문입니다. 처음 읽게된 이유는 흥미로운 제목과 요즘 사용하는 VLM 들의 백본에서 아직 CLIP의 이미지 인코더를 사용하기는 하니 연결지어 생각해볼점이 없을까 해서 읽게되었습니다.
그럼 리뷰 시작하겠습니다.
Abstract
우선 CLIP은 저희가 잘 알고있는 대조학습 기법을 통해 잘 구조화된 의미를 갖는 멀티모달 공간을 학습하기 위한 방법론입니다. 다양한 응용 분야가 생겼지만 CLIP의 잠재 공간이 복잡한 시각-텍스트 상호작용을 처리하는 데에는 실패하는 것으로 알려져 있죠.
최근 연구들에서 데이터 중심적 접근이나 알고리즘적 접근을 통해서 이러한 한게를 해결하려 시도하고 있지만 저자가 밝혀낸 것으로는 이 문제가 더 근본적인 것이고, CLIP의 기하학적 구조에 기인한 것이라는 것을 밝혔다고 합니다.
논문의 핵심 주장은 CLIP과 같은 joint embedding 구조에서는 다음 4가지 능력 중 2개 이상을 동시에 제대로 만족하는 것이 불가능하다고 합니다.
- represent basic descriptions and image content. (이미지 내용 + 기본적인 텍스트 설명 표현)
- represent attribute binding ( 예: “red car vs blue car” 구분)
- represent spatial location and relationships (예: “left of”, “behind”)
- represent negation (예 : ”no dog”, “not red”)
이러한 분석에 기반해서, 저자들은 이미지 패치와 텍스트 토큰의 의미적 위상 구조를 유지함으로써 CLIP의 근본적인 한계를 해결하는, CLIP 계열 모델을 위한 원리 기반이며 해석 가능한 스코어링 방법인 Dense Cosine Similarity Maps (DCSMs)를 제안합니다.
이 방법은 다양한 벤치마크에서 기존 CLIP 계열 공동 인코더 모델의 성능을 향상시켰습니다.
Introduction
CLIP은 vision-language 모델에서 가장 널리 사용되는 사전학습 방식 중 하나로, 이미지와 텍스트를 각각 encoder에 통과시킨 뒤 동일한 latent space로 매핑하는 구조를 사용합니다. 이 공간에서는 cosine similarity를 기준으로 두 embedding 간의 의미적 유사도를 측정하며, 값이 높을수록 텍스트와 이미지가 잘 대응된다고 해석할 수 있습니다.
이 방식의 장점은 구조가 단순하고 계산 효율이 높다는 점입니다. 특히 autoregressive 모델과 달리 긴 context를 요구하지 않고, 이미지와 텍스트를 각각 독립적으로 처리한 뒤 inner product 연산만으로 scoring이 가능하기 때문에 zero-shot classification이나 retrieval 같은 task에서 매우 강력한 성능을 보여왔습니다.실제로 CLIP 기반 embedding은 이미지 캡셔닝, VQA, 텍스트 기반 이미지 생성 등 다양한 downstream task에 활용되고 있습니다.
하지만 CLIP에는 명확한 한계도 존재합니다.
대표적으로
- spatial reasoning (공간적 관계 이해)
- compositional understanding (조합적 의미 이해)
- attribute binding (속성-객체 결합)
- negation (부정 표현)
과 같은 문제에서 성능이 떨어진다고 합니다.

Figure 1을 보면 CLIP은 실제 의미와 맞지 않은 텍스트에 더 높은 similarity score를 주는 경우가 많습니다. 이러한 문제는 단순히 특정 task의 성능 저하에 그치지 않고, CLIP을 사용하는 다양한 downstream 시스템에도 영향을 미칩니다.
기존 연구들은 더 좋은 데이터로 학습하거나, 모델 구조를 변경하거나, 학습 방식을 개선하는 방향으로 접근해왔습니다. 저자들은 여기서 더 나아가 개선으로 해결될 문제가 아니라 구조적은 한계일 수 있다는 관점을 제시합니다. 이러한 관점에서 저자들은 두가지의 핵심 질문을 던집니다.
- cosine similarity 기반의 CLIP latent space가, 실제 VLM task 에서 요구되는 모든 의미 표현을 동시에 만족할 수 있는가?
- 만약 불가능하다면, CLIP 구조를 완전히 버리지 않고 이를 보완할 방법이 있는가?
이를 위해 저자들은 먼저 CLIP latent space 의 geometry를 정식으로 정의하고, 이미지와 텍스트의 의미를 정확히 표현하기 위해 필요한 조건들을 정리합니다.
그리고 중요한 결론을 도출하는데, unit hypersphere 위에서 코사인 유사도를 사용하는 한, 이러한 조건을 동시에 만족하는 embedding space는 존재하지 않음을 이론적으로 보입니다.
이 문제를 해결하기 위해서 저자들은 CLIP 을 완전히 대체하는 것이 아니라, 기존 CLIP의 임베딩을 유지하면서 scoring 방식을 바꾸는 접근을 취합니다. 구체적으로는 이미지 패치와 텍스트 토큰간의 cosine similarity를 모두 계산해서 Dense Cosine Similarity Map (DCSM) 을 구성하고 이를 기반으로 CNN을 통해 최종 text-image score를 계산하는 방법을 제안합니다.
이 방식은 기존처럼 하나의 global embedding으로 비교하는 것이 아니라, token-level / patch-level 관계를 보존한 상태에서 similarity를 계산한다는 점이 핵심이라고 합니다.
Contribution을 정리하자면 다음과 같습니다.
- Cosine similarity 기반 임베딩이 위에서말한 4가지 정의의 표현중 여러가지를 표현하는 데 구조적인 한계가 있음을 지적
- CLIP latent space를 수학적으로 정의하고, 원하는 조건을 만족하는 임베딩 공간이 존재하지 않음을 증명
- dense similarity map 기반의 DCSM 을 제안하여 기존 CLIP의 한계를 보완
- 다양한 벤치마크에서 기존 CLIP 계열 대비 성능 향상을 확인
Vision Language Models
최근 CLIP과 같은 대조학습 기반 VLM들은 이미지와 텍스트를 하나의 latent space로 정렬시키면서 두 모달리티간의 격차를 크게 줄였습니다.
이러한 CLIP과는 다른 방향으로 텍스트와 이미지를 함께 autoregressive하게 처리하는 VLM 또는 text-image 매칭을 여러 sub-task로 나누는 방식들도 등장했다고 합니다. 이러한 방식들이 CLIP보다 복잡한 reasoning에서는 더 강력한 성능을 보이기도 하지만 이들 대부분이 여전히 내부적으로 CLIP과 유사한 latent space를 기반으로 동작한다는 점에서 저자는 CLIP의 한계가 단순한 특정 모델의 문제를 넘어 VLM 전반에 걸친 공통적인 bottleneck일 수 있다고 합니다.
이러한 말들로 CLIP 자체를 개선하려고 하는 연구 동기는 여전히 유효하다고 하네요.
The Ideal CLIP
CLIP이 어떤 성질을 만족해야 정말 제대로 된 모델이라고 할 수 있을까? 를 정의합니다. 먼저 CLIP이 이상적으로 동작하려면 어떤 조건들이 필요하고, 그 조건들이 수학적으로 만족할 수 있는지를 따져보는 과정입니다.
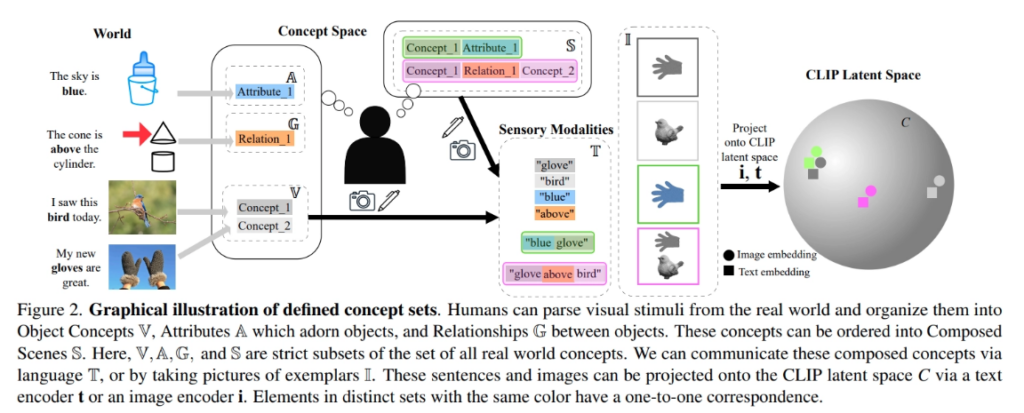
논문의 Figure2에서 세상을 다음과 같은 단계로 바라봅니다.
- 현실 세계에는 다양한 객체가 존재
- 각 객체는 색, 크기 같은 속성을 가질 수 있음
- 여러 객체가 함께 있을 때는 위/아래, 왼쪽/오른쪽과 같은 관계가 생김
- 이런 요소들은 합쳐져 하나의 장면(scene)이 됨
- 이 장면은 이미지로 표현될 수 있고, 텍스트로 설명될 수도 있음
- CLIP은 이 이미지와 텍스트를 같은 latent space로 projection해야함
즉 저자들은 CLIP을 단순히 이미지-문장 매칭 모델로 보지 않고, 그 안에서 실제로 표현되어야 하는 의미 단위를 객체, 속성, 관계, 이들의 조합으로 나누어 생각했습니다.
concepts, attributes, and compositions
이 부분은 이후 증명을 위한 기호 정의입니다.
CLIP embediding space C
먼저 CLIP 의 latent space를 정의하는데, CLIP은 이미지와 텍스트를 각각 어떤 N차원 벡터로 바꾸는데, 이 벡터들은 모두 길이가 1로 정규화되어 있다고 가정합니다. 즉 이미지 embedding과 텍스트 embedding은 모두 unit hypersphere 위의 점으로 표현됩니다. 간단하게 이미지와 텍스트를 구 위에 올려놓고 각도 기반 유사도로 의미를 비교하는 모델이라는 뜻입니다.
Atomic Concept Set V
여기서는 기본 객체 개념 집합을 정의합니다. 예를 들어 apple bird glove 같은 개별 객체들이 여기에 속하고 저자들은 이 객체들이 서로 명확히 구분되는 개념이라고 가정합니다. (서로 다른 개념이면서 하나가 다른 하나의 하위개념이 아니라고 생각하면 됩니다.)
그리고 각 개념마다 그 개념을 대표하는 이미지, 텍스트가 하나씩 있다고 둡니다. 예를 들어 “glove”라는 개념이 있으면 그걸 대표하는 이미지 embedding i(x) 와 텍스트 embedding t(x)가 존재한다고 보는 것입니다.
Attribute Representation Set A
이제 객체에 붙는 속성을 정의합니다. 객체에 붙는 성질로 이해하면 되고, “blue glove” 에서 객체 glove에 속성 blue 가 붙은 조합이라고 볼 수 있습니다.
논문에서는 i(xa) 같은 표기를 쓰는데, 이는 객체 x가 속성 a를 가진 이미지의 embedding 정도로 이해하면 됩니다. 여기서 저자들이 말하는 점은 기본 객체 embedding i(x) 자체도 사실 완전 중립적인 것이 아니라 그 객체에 대한 가장 전형적인 속성들을 어느정도 암묵적으로 표현하고 있다는 것입니다.
예를 들면 apple 하면 빨간색이 어느정도 떠오를 수 있다는 식입니다.
Composition Concept Set G
여기서는 장면 내 관계를 정의합니다.
이 집합에는 절대 위치와 객체 간 관계가 들어갑니다. 예를 들면 “right” “above” 와 같은 개념입니다. 즉 “glove above bird” 라면 glove 와 bird 라는 두 객체 사이에 above 라는 관계가 들어간 조합이라고 볼 수 있습니다. 이부분은 이후에 spatial relation을 다룰 때 핵심이 됩니다.
Combination Clause Set S
이제 객체,속성, 관계를 합쳐서 실제 하나의 의미 있는 문장이나 장면을 만드는 집합을 정의합니다. 예를 들면 “red car left of bus” 쯤으로 이해하면 됩니다.
즉 S 객체/속성/관계를 조합해서 만든 의미 단위들의 집합입니다.
Geometric Requirements for an Ideal CLIP
이제 저자들은 이상적인 CLIP이라면 최소한 만족해야 하는 조건들을 제시합니다. 여기서 ‘ideal’ 이라는 것은 이미지와 텍스트 간의 semantic distance가 사람의 직관과 잘 맞는 경우를 뜻합니다.
즉 oracle encoder가 있다고 가정했을 때조차 이 조건들을 동시에 만족하는 latent space가 없으면, 현실의 CLIP도 당연히 완벽해질 수 없다는 논리입니다.
Condition 1. Concept Categorization
(1.1) 첫 번째 조건은 가장 기본적인 수준으로 기본 객체가 맞게 분류되어야 한다는 조건입니다. 저희가 알고있는 기존 CLIP의 가장 기본적인 기능입니다.
(1.2) 같은 객체라면 속성이나 위치가 달라도 다른 객체보다는 더 비슷해야 합니다.
예를 들어 red car, blue car 는 서로 차이가 있더라도 car와 bird 보다는 더 비슷해야 한다는 뜻입니다.
Condition 2. Attribute Binding
두 번째 조건은 속성 결합입니다. 보통 CLIP이 자주 실패하는 부분입니다.
(2.1) 서로 다른 속성을 가진 같은 객체는 완전히 같은 embedding 이면 안됩니다. 즉 red car 와 blue car가 완전히 같은 embedding이면 색 정보가 사라진거로 봅니다.
(2.2) 특정 속성을 가진 이미지는 그 속성 텍스트와 더 가까워야 합니다.
즉 red car는 red와 더 관련 있어야 하고, blue car 보다 red와 더 가까워야 합니다.
(2.3) 객체는 같고 속성만 서로 바뀐 경우도 구분되어야 합니다.
예를 들어 black car, yellow bus, yellow car, black bus 는 등장 객체와 색 종류는 같지만 어떤 속성이 어떤 객체에 붙었는지가 다릅니다. 이 둘이 같게 보이면 attribute binding이 안되는 것으로 봅니다.
Condition 3. Spatial Relationship
세 번째 조건은 공간 관계입니다.
(3.1) 같은 객체라도 위치가 다르면 embedding이 달라야 합니다.
예를 들어 bird 가 왼쪽에 있는 경우와 오른쪽에 있는 경우는 달라야 합니다.
(3.2) 같은 두 객체라도 관계가 다르면 embedding이 달라야 합니다.
예를 들어 glove above bird 와 glove below bird는 달라야 합니다.
(3.3) 같은 관계를 가진 장면이 더 가깝게 표현되어야 합니다.
즉 관계가 유지된 장면끼리는 비슷하고, 관계가 바뀌면 덜 비슷해야 한다는 것입니다. 이 조건이 필요한 이유는 CLIP 이 단순히 “무엇이 있느냐” 만이 아니라 어떻게 배치되어 있느냐도 표현해야 실제 reasoning이 가능하기 때문입니다.
Condition 4. Negation
네 번째 조건은 부정 표현입니다. 해당 부분도 CLIP이 매우 약한 영역입니다.
(4.1) 어떤 텍스트와 그 부정형은 충분히 달라야 합니다. 다들 알다싶이 dog 와 not dog는 달라야 합니다.
(4.2) 어떤 이미지가 어떤 개념을 담고 있다면, 그 부정형 텍스트와는 덜 비슷해야 합니다.
예를 들어 dog 이미지가 있을 때 “not dog”와 높은 similarity를 가지면 안됩니다.
(4.3) 두 부정 표현은 원래의 두 양의 표현보다 더 많은 의미적 겹침을 가질 수 있다.
간단히 “not cat”과 “not dog”는 cat과 dog 자체보다는 더 넓고 겹치는 의미 영역을 가질 수 있다는 뜻입니다. 부정 자체가 의미 공간에서 더 복잡한 구조를 요구합니다.
Geometric Contradictions in CLIP
앞서 정의한 조건들이 실제로는 서로 동시에 만족될 수 없다는 것을 증명합니다.
논문의 핵심 주장인 “ideal CLIP latent space는 존재하지 않는다” 를 수학적으로 보이는 부분입니다.
접근 방식 자체는 Condition 1을 만족한다고 가정하면 다른 조건들을 동시에 만족할 수 없음을 보입니다. 즉 하나를 만족하면 다른 하나가 깨지는 구조적 모순이 발생한다는 것을 보이는 것이 목표입니다.
Contradiction for Conditions 1 and 2
Lemma 1. Embeddings of images or texts with two obect concepts must be a linear superposition of the respective single object concept embeddings.
(논문에 있는 표현을 가져왔는데 object에 오타가 있네요..)
먼저 저자들은 두 객체가 있는 경우의 embedding이 어떻게 생겨야 하는지 분석합니다. 예를 들어 x1 + x2가 있는 이미지 임베딩은 각각의 single object embedding i(x1), i(x2)와 모두 유사해야하고 이 조건을 만족하는 최적의 위치를 두 벡터의 합 방향이라고 합니다. 즉 embedding의 평균이라고 볼 수 있습니다. CLIP은 구조적으로 composition이 vector 의 sum 형태로 표현할 수 밖에 없다는 결론입니다.
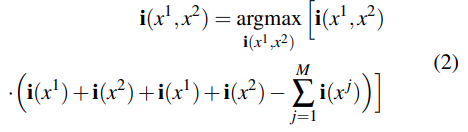
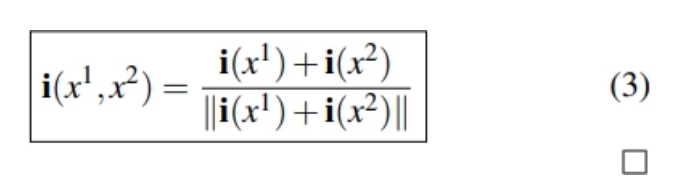
Lemma 2. C cannot distinguish between different attribute bindings. That is, i(xa,yb) = i(xb,ya). 저자들은 다음 두 경우를 비교합니다. 위에서 말한 속성만 서로 바뀐 경우입니다. CLIP 구조에서는 각각이 다음처럼 표현됩니다.
i(xa) = i(x) + t(a) , i(yb) = i(y) + t(b)
i(xa,yb) = i(x) + i(y) +t(a) + t(b)
해당 과정이 순서가 바뀌더라도 결과가 동일합니다. 실제 논문에서는 위에서 정의한 condition들의 조건까지 다 따져가면서 수식적으로 증명해냅니다. 결과를 말하자면 CLIP이 무슨 속성이 있는지는 표현할 수 있지만 그 속성이 누구에게 붙었는지를 표현할 수 없습니다. 이것을 attribute binding failure라고합니다.

위에서 언급한 condition 3,4도 비슷한 방식으로 증명하며 결국 Spatial relation에서는 위치정보와 관계정보를 동시에 일관되게 유지하지 못한다는 점, 그리고 negation 의 문제에서는 not x 가 거의 -x 의 형태가 되는데 이게 “not x” 와 “not y” 가 더 비슷해지는 이상한 구조가 된다고 합니다.

종합해서 얘기하면 CLIP 의 cosine similarity 기반 임베딩이 compositional semantics를 표현할 수 없고 구조적으로 object ,attribute, relation을 더하는 방식으로 표현되기 때문에 누가 무엇을 가졌는지, 어떻게 배치되었는지 구분할 수 없다고 합니다.
Rescuing the CLIP Latent Space
문제가 표현 방식이 아닌 scoring 방식으로 보고 similarity 계산 방식을 바꾸는 식으로 해결합니다.
Abstract에서 언급했듯이 global embedding 하나만 쓰지 말고, token / patch 단위 정보를 유지하고 cosine similarity 대신 learned scoring 사용하는 것이 아이디어 입니다.
방법이 아주 간단한데 기존 scalar로 생성되던 CLS X EOS 방식을 patch X token 으로 만들어 matrix를 만드는 것입니다. 이 방식에서 관계 단어들인 left right는 이미지와 직접 대응되는 patch가 없습니다. 그래서 noise로 판단하고 이런 단어를 제거하고 고정된 random vector로 대체한다고 합니다. 즉 의미가 아닌 패턴을 배우는 방식입니다.
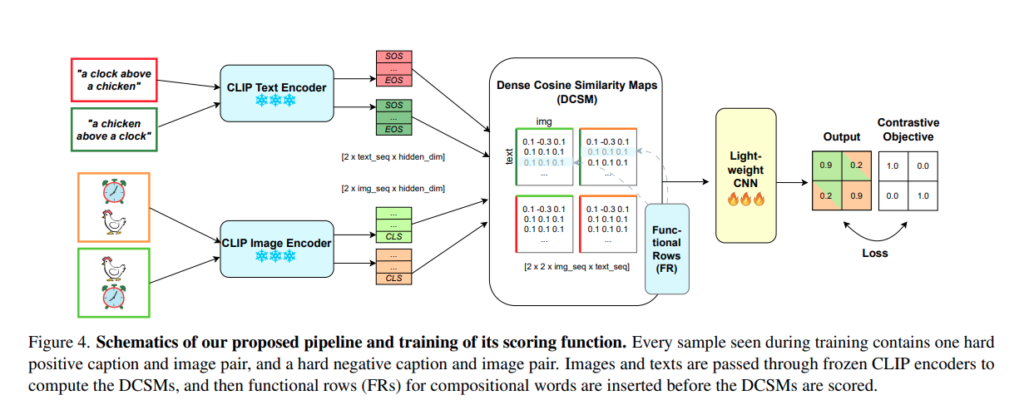
전체 파이프라인으로
- CLIP encoder freeze
- token/patch embedding 추출
- DCSM 생성
- lightwegith CNN(2layer)
- 최종 score 생성
모델이 이미지와 텍스트를 직접 보지 않고 DCSM 패턴만 보고 판단하게 됩니다. 학습에는 합성데이터와 COCO 로 각각 학습했다고 합니다.
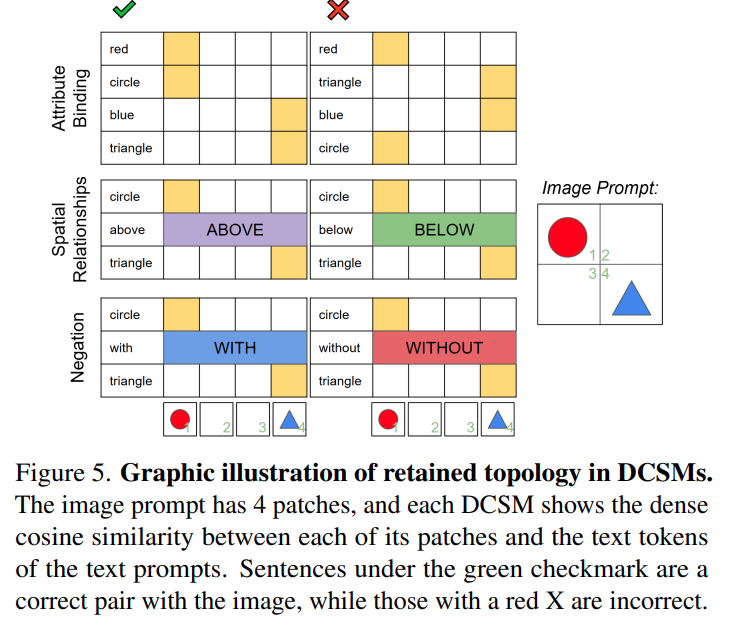
Performance Evaluation
DCSM 방법론이 실제로 CLIP 계열 모델들보다 성능이 좋은지를 검증합니다.
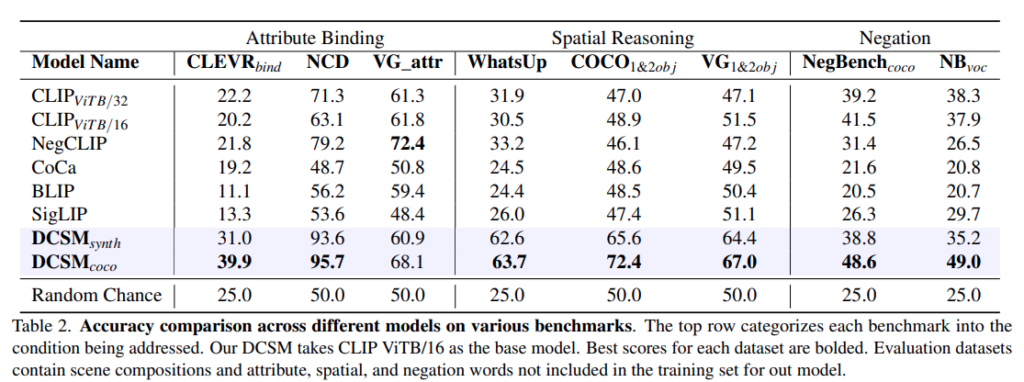
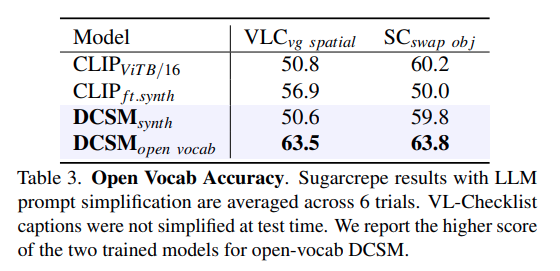
해당 부분은 open-vocab 실험으로 앞서 언급한 left, right 같은 단어들을 가짜 벡터들로 채워 처리했다면 실제 현실에서는 to the left of 등의 표현들이 나와 dictionary에 존재하지 않는 단어들을 처리해야합니다. 이런 것들을 LLM 을 넣어서 parsing 해서 기존 저자의 방식을 (left, right 등의 단어는 placeholder로 자리만 채워주는 벡터로 처리) 확장했다고 생각하면 됩니다. 위의 벤치마크는 spatial split이나 swap-object split등을 검증합니다.
Conclusion
이 논문에서는 CLIP 의 한계를 단순한 성능 문제가 아니라 latent space 의 기하학적 구조에서 비롯된 근본적인 문제로 분석합니다. 해결한 방식은 매우매우 간단하지만, 그 과정을 정의하고 증명하는 것, 그리고 dataset들에서 높은 성능향상이 좋은 학회에 붙게한게 아닌가 싶습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다!
negation 문제에서 cat과 dog보다 not cat과 not dog가 더 넓은 영역을 의미해야 한다고 이해했는데요, “not x 가 거의 -x 의 형태가 되는데 이게 “not x” 와 “not y” 가 더 비슷해지는 이상한 구조”라는 말이 잘 이해가 가지 않아서 질문 드립니다. not x가 x를 나타내는 임베딩 벡터의 반대 방향이 되는 것이 왜 not x와 not y가 비슷해지는 구조인 건가요?
그리고 attribute binding에서 하나의 객체가 여러 속성을 갖는 경우나 여러 객체가 동일한 속성을 갖는 경우에 대한 분석도 있는지 궁금합니다.
감사합니다.
안녕하세요 예은님 답글 감사합니다.
우선 첫번째 질문에 대해서 답해드리자면 저자가 처음 정의한 condition 1 에 의해서 모든 CLIP의 text나 image의 임베딩 벡터는 단위 구의 space 위에 있다고 가정하게 됩니다. 이때 x 와 not x의 이상적인 임베딩 방향은 서로 반대방향인 경우인데, 이렇게 되면 x와 not x 보다 not x와 not y가 가까운 경우가 더 많게됩니다.
두번째 질문에 대해서 답해드리면 명시적으로 나와있거나 분석하지는 않지만, 이상적인 attribute 속성 임베딩을 단순 embedding의 sum 으로 정의한 저자의 방식대로라면 마찬가지로 저희가 원하는대로 사용하기 어려운 형태로 표현될 거라고 생각합니다.