오늘 리뷰는 CVPR 2026에 게재된 Video Compression 논문입니다.
Introduction
비디오 데이터의 증가로 인해서 낮은 비트레이트에서도 높은 품질을 유지하는 동시에 효율적으로 압축하는 기술이 점점 중요해지고 있습니다. 전통적인 Codec(코덱)과 Neural Network(신경망) 기반의 비디오 코덱은 주로 PSNR과 같은 일반적인 왜곡 지표에 최적화되어 있어서 보존되는 정보가 제한적일 때에는 비디오의 복원 결과가 흐릿해지는 문제가 존재합니다. 이를 개선하기 위해서 최근에는 Generative Video Codec(GVC, 생성형 비디오 코덱)이 주목받고 있습니다. GVC는 raw 비디오를 latent representation으로 인코딩한 후에 생성 모델을 활용하여 디코딩하고 디테일을 추가하는 방식입니다. 전통적, 신경망 기반, 생성형 기반 모두 궁극적으로는 raw 신호를 2D 공간 구조의 블록 또는 2D 신경망 특징맵으로 변환하여 인코딩과 디코딩을 수행합니다.
여기서 잠시 생소한 용어들을 간략하게 설명드리겠습니다. Codec은 Coder/Decoder의 합성어로 raw 데이터를 압축(인코딩)하고 복원(디코딩) 하는 알고리즘을 말합니다. 여기서 압축, 복원을 하는 이유는 raw 영상이 용량이 매우 크기 때문에 데이터 전송을 할 때에 비효율적이기 때문입니다. 영상 압축에서는 일반적으로 공간적 압축(Intra-frame)과 시간적 압축(Inter-frame)이 필요합니다. 공간적 압축은 JPEG, PNG와 같은 이미지 압축 기술과 유사하게 하나의 프레임 내에서 중복되는 정보를 제거하고 하나의 프레임으로 복원할 수 있는 압축을 의미하고, 시간적 압축은 프레임 간의 차이를 저장하는 것으로 정보를 압축하고 이전/이후 프레임과 프레임 간의 차이를 통해 복원합니다. 비트레이트(Bitrate)는 일반적으로 초당 처리하는 데이터의 양(bps, bitrate per second)을 말합니다. 당연히 높을수록 품질이 좋고 용량이 커지게 됩니다. 앞서 설명드린 Codec이 필요한 이유에서 raw 영상이 용량이 크기 때문이라고 설명했는데 비트레이트의 개념도 설명했으니 더 정확하게 설명드리면 한정된 비트레이트 내에서 raw 영상의 방대한 용량을 그대로 전달하는 것은 비효율적이기에 정보를 압축하여 빠르게 전달하기 위함입니다. 기본적으로 이러한 Codec의 목표는 정보를 압축하고 정보를 전송한 후에 그대로 복원하는 것을 목표로 하고 있으며 압축률이 클수록 정보의 손실량이 커지기 때문에 이 trade-off 관계를 잘 조절하는 것이 중요한 과제입니다.
기존 방법론은 PSNR 왜곡 지표를 사용한다고 설명했는데, PSNR은 Peak Signal-to-Noise Ratio로 영상 압축 및 처리에서 원본 대비 화질 손실량을 평가하는 지표입니다. 영상 압축의 개념으로 설명하면, 원본 영상과 복원된 영상 사이의 픽셀 차이를 제곱 평균한 MSE(Mean Squared Error)를 계산한 후에 PSNR을 계산합니다. 값이 높을수록 잘 복원했음을 의미하며 일반적으로 40이상인 경우 육안으로 구분할 수 없는 수준입니다.
\text{MSE} = \frac{1}{mn} \sum_{i=0}^{m-1} \sum_{j=0}^{n-1} \left[ I(i,j) - K(i,j) \right]^2 (m, n은 각각 영상의 세로, 가로 픽셀 수를 의미하고, I, K는 각각 원본과 복원된 영상의 픽셀값을 의미합니다.)
\text{PSNR} = 10 \cdot \log_{10} \left( \frac{MAX_I^2}{\text{MSE}} \right)전통적인 Codec은 인공지능 없이 휴리스틱한 알고리즘을 사용한 Codec을 말하며 현재는 유튜브, 넷플릭스 등 전통적인 Codec을 사용중입니다. 신경망 기반 Codec은 신경망(여기서는 정확하게 CNN을 말합니다.)을 활용하여 영상을 특징맵으로 압축하는 방법을 말합니다. 성능은 개선되었으나 실용화 단계까지는 발전되지 않았습니다. 생성현 기반 Codec은 영상을 latent representation으로 압축하고 이를 생성형 모델을 통해 복원하는 Codec입니다. 기존에는 2D latent representation을 통해 압축했지만 본 논문에서는 이러한 2D latent grid로 압축하는 것의 근본적인 한계를 두가지 차원에서 지적하고 있습니다.
- spatial redundancy(공간적 중복성) 문제: 2D latent grid의 각 토큰은 대응되는 영상의 패치만을 모델링하고 있기에 객체의 의미론적인 정보는 거의 무시되고 국소적인 시각적 정보에만 의존하고 있습니다. 또한, 2D grid의 고정된 공간 구조로 인해서 각 이미지 패치는 동일한 크기의 토큰으로 인코딩되어 복잡한 영역과 단순한 영역이 모두 같은 크기의 토큰이 할당되는 불필요한 중복이 생깁니다.
- temporal redundancy(시간적 중복성) 문제: 2D grid는 프레임 간의 시각적 변화를 포착하고 semantic dynamics는 포착하지 못합니다. 이로 인해서 긴 영상 사이의 시간적인 상호관계를 의미론적으로 일관된 방식으로 압축하지 못하는 한계가 존재하며 프레임 간 공통된 콘텐츠를 압축하지 못합니다.
이러한 두가지 차원에서의 한계를 극복하기 위해서 저자는 2D가 아니라 1D 차원의 latent representation으로 압축하는 GVC1D(Generative Video Compression with One-Dimensional Latent Representation)을 제안합니다. 1D latent token은 고정된 2D 공간 대응 없이 의미론적인 영역에 attention을 집중할 수 있으며 토큰 수의 자연스러운 감소로 공간적 중복성을 지우는 동시에 의미론적으로 풍부한 장기 context를 낮은 계산 비용으로 제공하여 시간적 중복성을 줄일 수 있습니다.
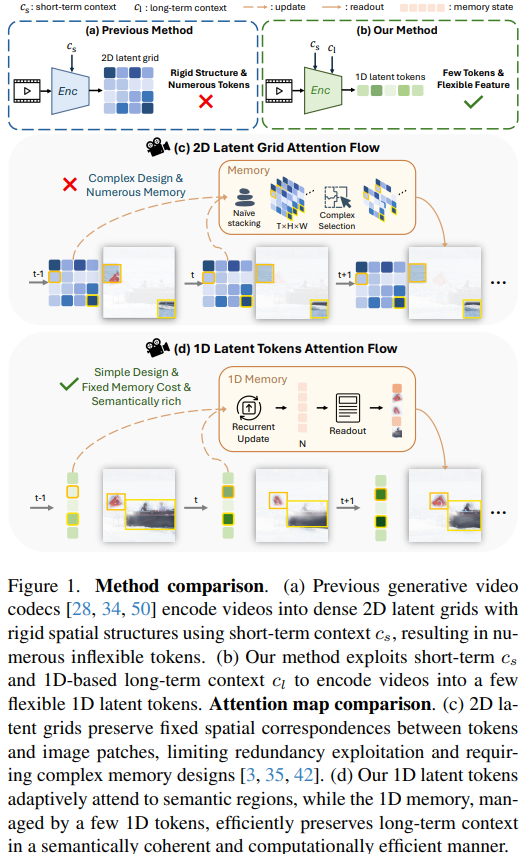
Figure 1.은 앞서 설명드린 GVC1D와 기존 연구의 차이점을 보여주고 있습니다.
Method
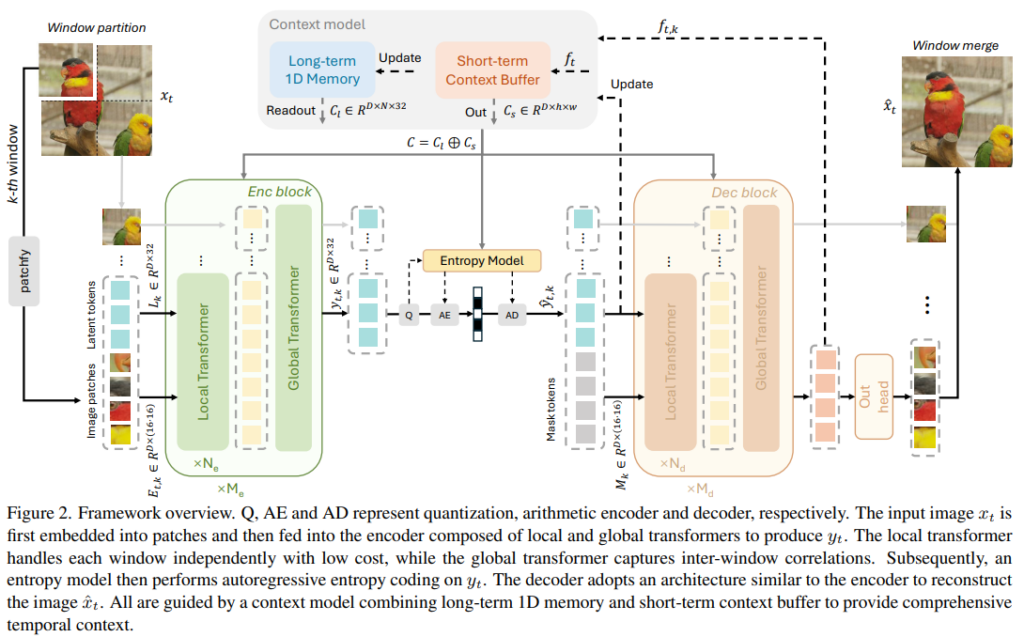
Figure 2.은 GVC1D의 프레임워크로 크게 3가지 단계로 구성되어 있습니다. 1단계는 인코딩 단계로 ViT기반의 인코더로 현재 프레임 x_t을 1D latent token y_t으로 인코딩합니다. 2단계는 1D latent token에 대해서 Entropy coding을 수행합니다. 마지막은 1D latent token을 디코딩하여 복원된 프레임 \hat{x}_t를 생성하는 단계입니다. 세 단계 모두 long-ten 1D memory와 short-term context buffer를 통합하는 context 모델의 guide를 받습니다.
인코딩 단계에서는 먼저 현재 프레임 x_t \in \mathbb{R}^{3 \times H \times W}은 패치 임베딩을 통해 변환됩니다 \text{Emb} \in \mathbb{R}^{D \times h \times w} (h = H/16, w = W/16). 이 임베딩은 1D sequence E_t \in \mathbb{R}^{D \times (h \cdot w)}로 펼쳐진 후에 학습 가능한 1D latent token L \in \mathbb{R}^{D \times ( N \cdot 32)} (N=\frac{h \times w}{16 \times 16})와 context C = C_l \oplus C_s (l는 long-term, s는 short-term을 의미합니다.)와 concat되어 인코더에 입력됩니다. 인코더는 이들을 처리해서 압축된 1D token y_t를 생성합니다.
y_t = \text{Enc}(E_t \oplus L \oplus C)쉽게 그냥 패치 임베딩 1D로 만들어서 latent token이랑 context token를 concat하고 인코더 태우는겁니다.
인코더는 M_e개의 인코딩 블록으로 구성되어 있으면 각 블록은 N_e개의 local transformer와 1개의 global transformer를 포함하고 있습니다. local transformer는 결합된 토큰을 N개의 window로 분할하여 각 window를 독립적으로 병렬처리합니다. 이때 E_t와 C_s는 16 \times 16 윈도우, L 과 C_l 는 32개의 토큰으로 분할됩니다(추후에 더 자세하게 설명하겠지만, C_s는 이전 프레임 정보이기때문에 이미지 토큰과 길이가 같고 C_l는 영상 전반의 정보이기 때문에 latent token과 길이가 같습니다. ). 각 window 내에서 네가지 구성요소가 ViT를 통해 처리되며 1D latent token L은 이미지 토큰과 context C로부터 정보를 압축합니다. local transformer 이후에는 global transformer를 거치게되는데 다시 각 구성요소들을 concat한 후에 Rotary Positional Embeddings(RoPE)를 부여하여 상대적 위치 관계를 독립적으로 모델링합니다.
결과적으로는 y_t \in \mathbb{R}^{D \times (N \cdot 32)}가 생성됩니다. 이전 Codec들은 모두 2D latent grid를 통해 인코딩을 했는데 고정된 공간 대응을 제거하는 것으로 프레임 모델링에 유연함을 더했으며 의미정보를 더 잘 포착하고 압축적인 latent representation을 얻을 수 있습니다(낮은 비트레이트에서 유리함을 의미합니다).
엔트로피 모델 단계에서는 AR(Auto Regressive) Transformer기반 엔트로피 모델을 사용합니다. 1D latent representation을 양자화한 후에 AR Transformer가 이전에 디코딩된 모든 토큰을 조건으로 각 양자화된 토큰의 확률을 순차적으로 예측합니다. 저자는 1D latent token의 수가 많지 않고 N개의 window를 병렬처리할 수 있어 계산 비용이 크지 않다는 점을 강조하고 있습니다.
디코딩 단계에서는 인코더와 동일하지만 반대되는 순서로 진행됩니다. 동일한 방법이 역으로 수행되기에 수식적인 설명은 생략하도록 하겠습니다. 결국 복원된 프레임은 마지막에 CNN Out Head를 통해 생성됩니다.
\hat{x}_t = \text{Out}( \text{Dec} ( \hat{y}_t \oplus M \oplus C ))여기서 M은 학습가능한 마스크 토큰으로 Out Head의에 입력되어 복원된 영상 생성에 사용됩니다.
Context 모델은 1D Memory와 short-term context buffer로 구성됩니다. 1D 토큰에서 파생되는 long context를 통합하는 것으로 기존 방법과 달리 풍부한 시각 정보를 제공할 수 있습니다. short-term context는 세밀한 특징을 포착하는 반면 long-term context는 전역적인 의미론적 context를 제공합니다.
short-term context는 어려울 것 없이 직전 프레임의 디코더 특징 f_t를 사용합니다. long-term context를 위해서는 두가지 transformer 구조가 사용되며 고정된 크기의 Memory를 유지하는 것을 목표로합니다.
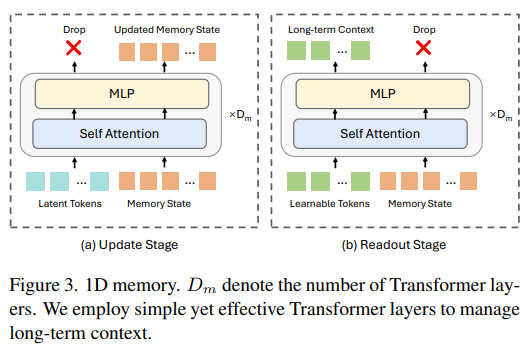
Figure 3.은 long-term context를 설명하고 있는 그림입니다. Update 단계는 1D latext token 이 Memory를 업데이트하는 데에 사용됩니다. latent token과 memory를 concat하여 transformer 구조를 거치고 latent를 drop하여 Memory만 업데이트합니다. Readout 단계는 학습 가능한 쿼리 토큰이 Memory로부터 long-term context를 검색합니다. Memory와 concat되어 transformer 구조를 거치고 memory를 drop하는 것으로 memory로부터 필요한 정보를 검색하여 long-term context C_l로 사용합니다.
모든 연산은 2D가 아닌 1D에서 수행되기 때문에 복잡한 설계없이 유연한 메모리 관리가 가능하며 토큰 수 자체가 2D보다 적어 고정된 메모리 공간 내에 더 많은 정보를 저장할 수 있고 memory를 관리하기에 정보 손실을 줄일 수 있습니다.
Figure 4.와 5.는 1D latent token에 대한 분석입니다.
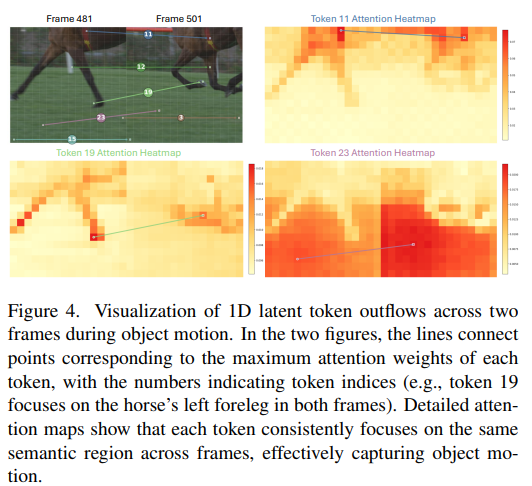
Figure 4.를 먼저 확인하면 Object Motion에 뛰어난 것을 확인할 수 있습니다. 481 프레임과 501 프레임은 각 토큰의 큰 모션 변화에도 불구하고 정확하게 의미론적으로 관련있는 영역에 집중하는 것을 확인할 수 있습니다. token 11, 19, 23 모두 정확하게 말의 안장, 다리, 배경을 짚어내는 것을 확인할 수 있습니다.
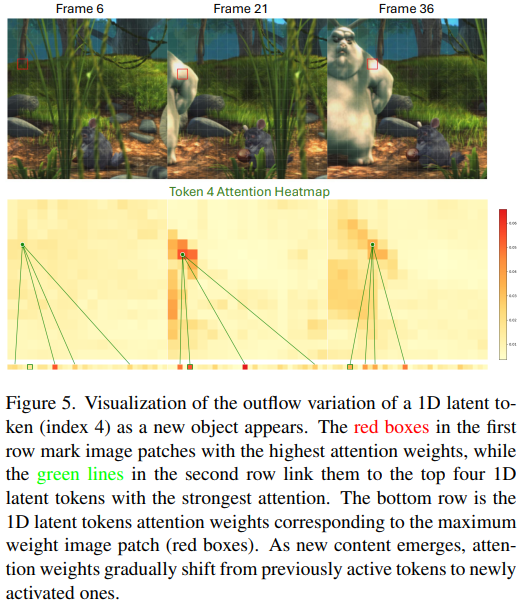
Figure 5.는 New Content에 뛰어난 것을 확인할 수 있습니다. 토끼가 점진적으로 등장하는 장면에서 attention map의 추이를 확인하면 점점 토끼가 우측으로 튀어나오면서 토큰의 attention 가중치가 점진적으로 증가하는 것을 잘 확인할 수 있습니다.
손실함수는 .
Experiments
GVC1D는 Vimeo와 OpenVid-HD 데이터셋에서 학습되었으며 훈련은 3가지 단계로 진행됩니다. 먼저 1단계에서는 인코더와 디코더만 OpenVid-HD의 2프레임 샘플로 학습됩니다. 해상도는 256 \times 256 입니다. 선행 연구인 TA-TiTok의 reconstruction loss를 사용합니다.
L_{\text{stage1}} = |x - \hat{x}|_2 + \lambda_{\text{LPIPS}} L_{\text{LPIPS}}(x, \hat{x}) + \lambda_{\text{adv}} L_{\text{adv}}(x, \hat{x})2단계에서는 엔트로피 모델을 도입하여 Vimeo 데이터셋에서 학습합니다. 훈련할때 프레임의 수를 2개에서 32개로 점진적으로 증가한다고합니다. 선행연구인 DCVC-RT의 비트레이트 항 R를 추가한 loss를 사용합니다.
L_{\text{stage2}} = \frac{1}{T} \sum_{t=1}^{T} (R + \lambda L_{\text{stage1}})3단계는 global transformer와 1D 메모리를 순차적으로 도입하고 해상도를 256 \times 256에서 1280 \times 2048까지 늘렸다고 합니다.
평가는 HEVC-B, UVG, MCL-JCV 데이터셋에서 평가합니다. 96 프레임을 RGB에서 저지연 인코딩 설정으로 테스트한다고합니다. intra-period를 -1로 설정하고 평가는 BD-Rate로 평가합니다. BD-Rate는 Bitrate, Distortion 비율로 동일 품질에서의 비트레이트 절감율을 백분율로 보여주는 평가지표입니다. 값이 낮을수록 효율적인 압축을 의미합니다.
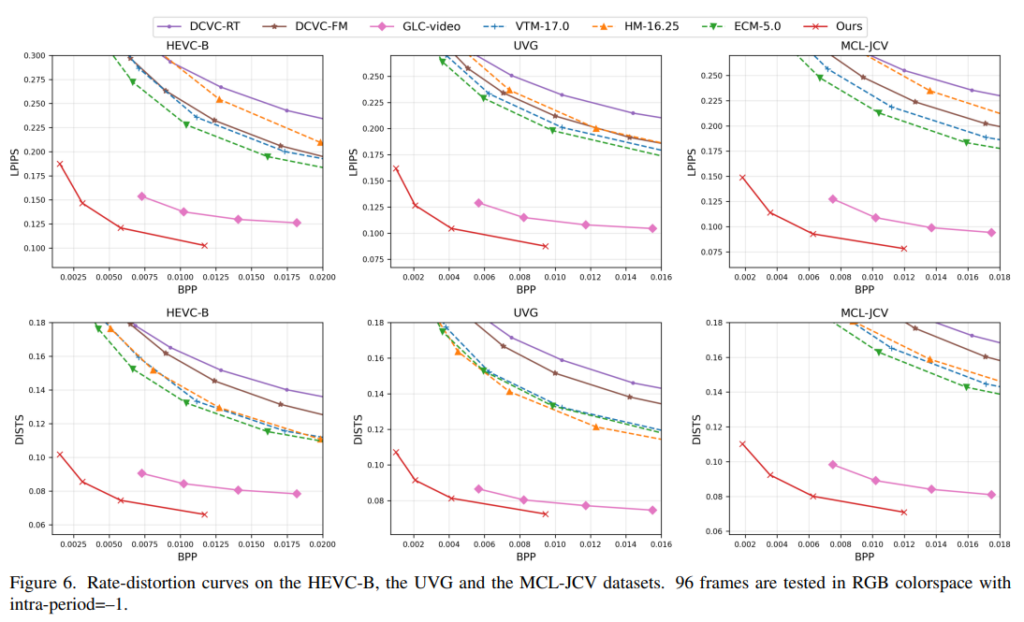
Figure 6.은 Rate-Distortion curve입니다. x축과 y축 모두 작을때가 더 효율적인 압축을 하고 있음을 나타냅니다.
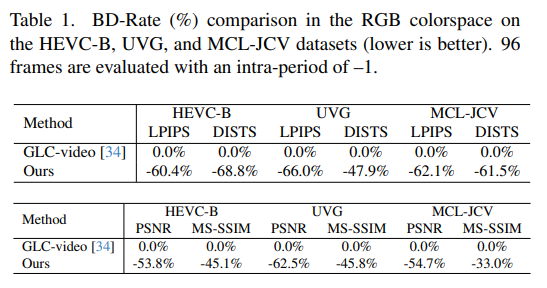
아무튼, 저자는 LPIPS와 DISTS 같은 perceptual metrics로 평가하는 것이 올바른 평가라고 주장하면서 생성형 기반 Codec의 필요성을 강조하고 있습니다. 동시에 perceptual metrics보다는 안좋지만 동시에 fidelity metrics으로도 GVC1D의 성능이 좋은 것을 Table 1.에서 확인할 수 있습니다. 저자는 어느 메트릭으로 보더라도 GVC1D가 상당한 비트레이트 절갑을 보이는 것을 다시 한번 강조하고 있습니다.
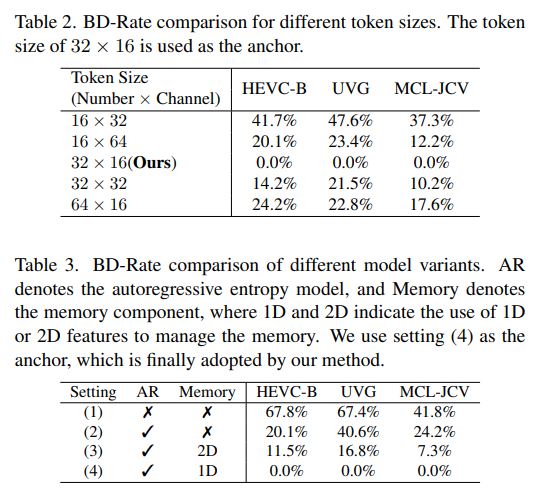
Table 2.와 3.은 ablation study입니다. 먼저, Table 2.는 1D latent token의 길이와 채널 수에 따른 성능을 변화를 보여줍니다. 앞서 설명드린 것처럼 음수일수록 좋은 성능으로 32 \times 16 에서 제일 좋은 성능을 보입니다. Table 3.은 각 모듈과 방법론 별 성능 차이를 비교합니다. 저자가 적용하는 방법론들의 효과를 보여줍니다. 정량적 성능만 봤을 때는 생각보다 2D와 1D의 차이보다는 Entropy 모델과 Memory에서 성능 차이가 크게 발생하는것 같습니다.

Figure 7.은 정성적 결과입니다. 낮은 비트레이트로 갈수록 왜곡이 심해지는 기존 방법론들과 달리 GVC1D는 원본과 유사한 복원이 가능한 것을 확인할 수 있습니다.
저자들은 한계점으로 프레임당 32개의 1D 토큰만으로 표현하는 것에 따른 고유한 정보 손실을 언급하고 있습니다. 동시에 현재 모델이 낮은 비트레이트의 손실 압축을 목표로 한다는 점을 언급하며 약간의 디펜스를 하고 있습니다.
리뷰 읽어주셔서 감사합니다. 궁금하신 점 댓글로 남겨주시면 답변드리겠습니다.
안녕하세요, 성준님 좋은 리뷰 감사합니다.
ablation 결과를 보면, Table 3은 1D 표현 자체의 효과를 직접 비교했다기보다는, AR entropy model이나 memory 모듈이 들어갔을 때의 효과를 보여주는 것처럼 느껴졌습니다.
그래서 저자들이 강조하는 1D latent token의 장점이 실제로 어느 정도인지 조금 더 궁금한데,
예를 들어, 같은 entropy model과 memory 구조를 유지한 상태에서 2D latent grid를 쓰는 경우와 1D latent token을 쓰는 경우를 직접 비교한 실험도 있었을까요?
감사합니다.
안녕하세요 성준님, 좋은 리뷰 감사합니다.
기존 2D latent grid 구조를 1D token sequence로 변환하면서 공간적인 대응능력은 제거된 것으로 보입니다. 이 설계가 semantic한 영역에 attention을 집중하는 데는 유리하지만, fine-grained한 특징이 중요한 small object의 위치와 디테일을 복원하는데 한계가 발생하지 않을까라는 생각이 드는데, 이와 관련한 성준님의 생각이 궁금합니다.