안녕하세요 이번 x-review는 VLA에서 continual learning을 다룬 논문을 리뷰해보려고 합니다. 제목에서 알 수 있듯 사전학습된 VLA는 생각보다 forgetting에 강하고, 조금의 replay 만으로도 forgetting이 없어지거나 오히려 해당 부분에 대해 이전보다 성능이 좋아지는 경우도 생겼다고 합니다. 다만 gr00t와 pi 시리즈 같이 대규모로 사전학습된 모델이 주로 강하다는 결과를 볼 수 있었는데요, 리뷰 시작해보도록 하겠습니다.
Introduction
저자들은 먼저 로봇 정책 학습에서 continual learning이 왜 중요한지부터 짚습니다. 로봇은 현실적으로 한 번에 모든 태스크를 동시에 배우기보다, 시간이 지나면서 새로운 작업을 순차적으로 배우게 됩니다. 그런데 이때 문제는 새 태스크를 배우는 동안 이전에 배운 행동을 잊어버리는 것입니다. 이는 새로운 태스크를 잘 배워야 하는 plasticity와 기존 지식을 유지해야 하는 stability를 동시에 만족해야 하는데, 이 균형이 무너지기 때문에 catastrophic forgetting이 발생한다고 합니다. 저자들은 naive한 sequential finetuning 때문에 해당 현상이 자주 발생한다고 합니다. 이는 사실 continual learning 분야에서 느낄 수 있는 전형적인 문제라고 합니다. 다만 저자들은 기존 로봇 continual learning 연구가 대체로 작고 scratch에서 학습한 policy 모델을 중심으로 이루어졌다고 합니다. 이런 설정에서는 catastrophic forgetting이 매우 흔하고, 이를 막으려면 큰 replay buffer를 쓰거나 정교한 regularization 기법을 넣어줘야 한다고 합니다. 특히 VLA는 continual learning이 잘 안된다는 이미지가 그래서 깔려있었다고 합니다.
저자들은 large-scale pretrained VLA가 등장했기 때문에 해당 부분에 대해 다시 점검해봐야 한다고 문제정의를 했습니다. Gr00t나 pi 시리즈와 같은 대규모 사전학습 VLA들은 강한 generalization과 downstream transfer를 보여주었고, 이 모델들은 단순히 task-specific policy를 처음부터 배우는 것이 아니라 이미 방대한 멀티모달 데이터와 robot trajectory를 통해 사전학습되어 있다는 점이 굉장히 중요한 차이점이라고 합니다. 저자들은 대규모 사전학습 VLA들은 새로운 task를 학습할 때 기존에 갖고 있던 표현을 재사용하고 재구성하는 방식으로 적응한다고 본다고 합니다. 논문 방향은 이렇게 대규모 사전학습 VLA들이 다른 양상을 갖는다면 replay buffer나 regularization과 같은 연구들 말고 이미 pretrain된 표현 구조를 어떻게 활용할 것인가?가 핵심이 될 것이라고 합니다. 저자들은 단순히 학습에 사용된 동일 데이터셋에서 N%를 랜덤 샘플링해서 다시 학습시키는 ER 방식 (Experience Replay)으로 실험해 다음과 같은 발견을 했다고 합니다.
- Pretrained VLA가 scratch policy보다 현저히 forgetting에 강하고, 단순한 experience replay만으로도 zero forgetting에 가까운 결과가 나올 수 있다고 합니다. 어떤 경우에는 새 태스크를 배우고 나서 이전 태스크 성능이 오히려 좋아지는 경우도 있다고 합니다. 이는 작은 모델들과의 차이점이라고 합니다.
- 저자들은 이런 차이의 핵심 원인이 pretraining이라고 합니다. 단순히 모델이 커서가 아니라, 사전학습된 지식이 continual learning 성능을 올려준다고 합니다. 특히 replay 데이터가 적은 low-data regime일수록 pretraining의 효과가 더 크게 나타난다고 합니다.
- Task performance가 떨어졌다고 해서, 내부 지식이 사라진 것은 아닐 수 있다고 합니다. Pretrained VLA는 새 태스크를 배우는 동안 예전 태스크 성능이 감소하더라도, task-relevant knowledge가 내부 표현 안에 여전히 남아 있을 수 있으며, 그래서 몇 번의 finetuning만으로 빠르게 회복될 수 있다고 합니다.
VLAs are Surprisingly Resistant to Forgetting
저자들은 LIBERO benchmark의 네 가지 task인 LIBERO-Spatial, LIBERO-10, LIBERO-Object, LIBERO-Goal에서 continual learning 실험을 수행했다고 합니다. 모델은 Pi0, GR00T N1.5를 사용했고 베이스라인으로는 scratch 로 학습한 BC-Transformer, Diffusion Policy, BC-ViT를 사용했다고 합니다. 태스크당 replay sample size를 1000으로 두었고, Success Rate와 NBT(Negative Backward Transfer, forgetting 정도를 나타내는 수치로 보시면 될 것 같습니다)를 측정했습니다. NBT는 낮을수록 forgetting이 적고, 음수면이전 태스크 성능이 좋아진 것을 의미합니다.
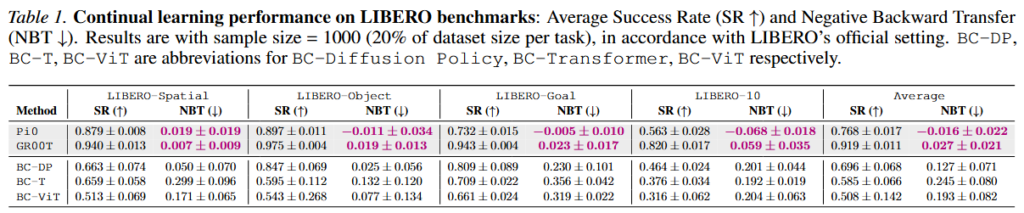
Table 1을 보면 Pi0는 네 개 벤치마크 평균에서 SR 0.768, NBT -0.016, GR00T는 SR 0.919, NBT 0.027이 나왔습니다. 반면 BC-Transformer는 SR 0.585, NBT 0.245, BC-ViT도 NBT 0.193이 나왔습니다. Pretrained VLA는 높은 태스크 수행 성능을 유지하면서도 과거 태스크를 거의 잊지 않았지만, scratch 기반 모델들은 동일한 replay 설정에서도 훨씬 큰 forgetting을 보였다고 합니다. Pi0의 경우에는 NBT가 음수인데, 새로운 태스크 학습이 과거 태스크 표현까지 함께 정제한 결과라고 합니다. 저자들은 이 결과가 기존 연구들이 주장하는 stability-plasticity trade-off에 대한 반대되는 결과라고 합니다.
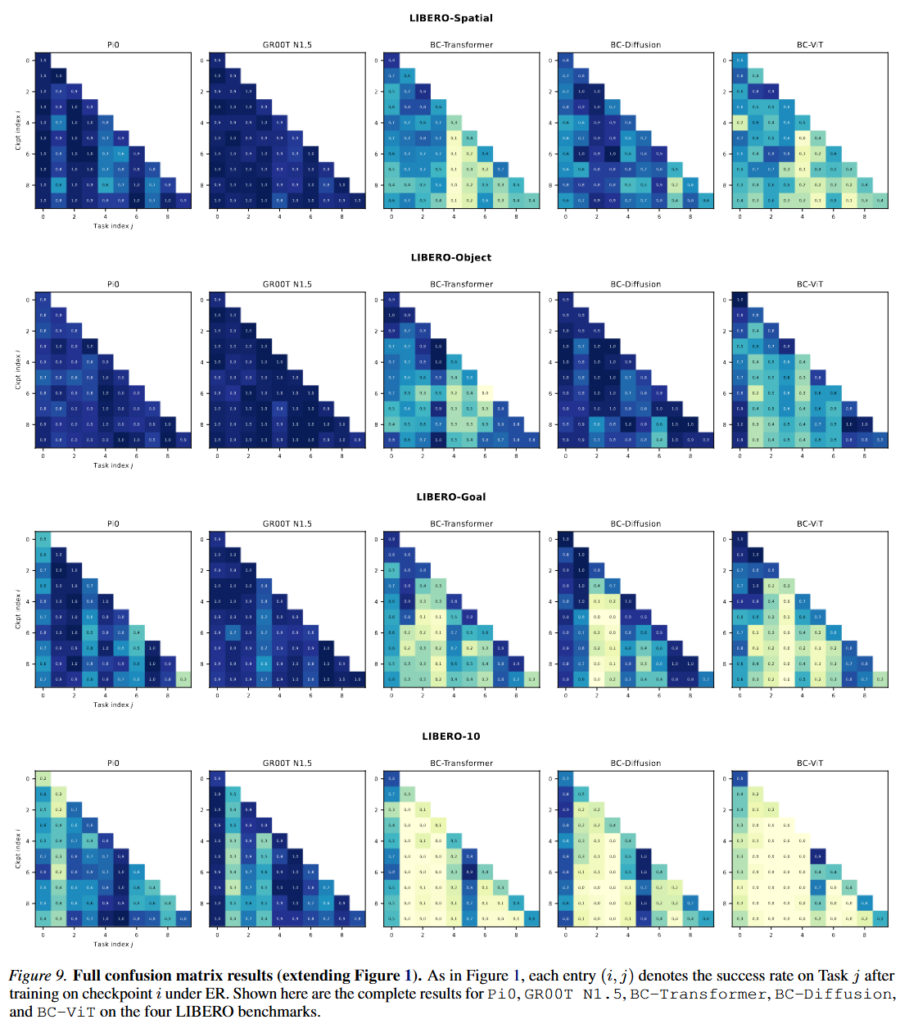
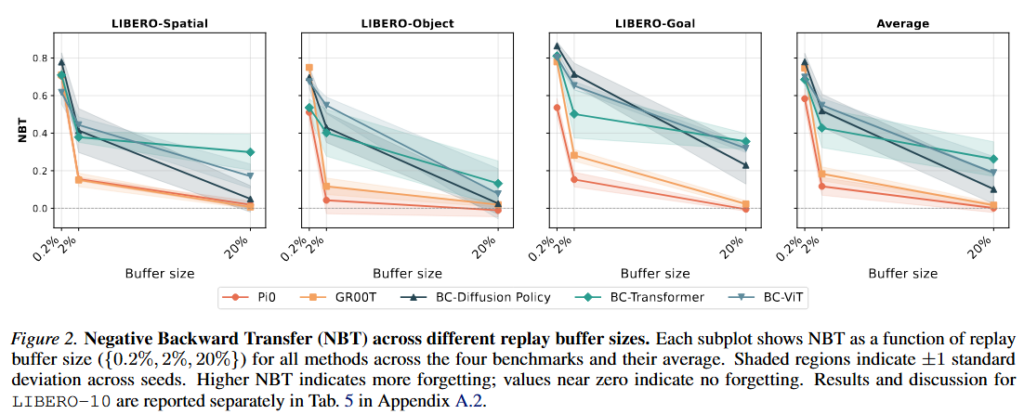
Figure 1에서는 각 행이 몇 번째 태스크까지 순차적으로 학습했는지 이고, 각 열은 그 때의 success rate 변화입니다. 진할수록 더 높은 성능이라고 생각하시면 될 것 같습니다. 이 결과를 통해 저자들은 같은 replay를 어떤 모델이 얼마나 잘 활용하는지에 차이가 있다고 합니다. Figure 2를 보면 저자들이 replay buffer 크기를 0.2%, 2%, 20%로 바꿔가며 forgetting을 비교했습니다. 결과로 2% 버퍼 샘플만 써도 Pi0와 GR00T의 NBT는 0.1~0.2 정도이지만 BC-Transformer, BC-ViT, BC-Diffusion Policy는 0.4~0.5까지 나왔스빈다. Scratch 정책들은 비슷한 수준의 retention을 얻기 위해 훨씬 큰 replay memory가 필요했지만, pretrained VLA는 매우 작은 replay만으로도 과거 지식을 불러올 수 있다고 합니다. 저자들은 대규모 pretrained 모델들이 사전학습이 잘 된 경우 replay를 통해 내부에 남아 있는 지식을 깨워 줄 수 있다고 합니다. 0.2% 규모의 작은 buffer만 사용했을 때는 어느정도 비슷한 결과를 보였다고 하네요.
Pretraining Plays an Integral Role in Improving Continual Learning Performance
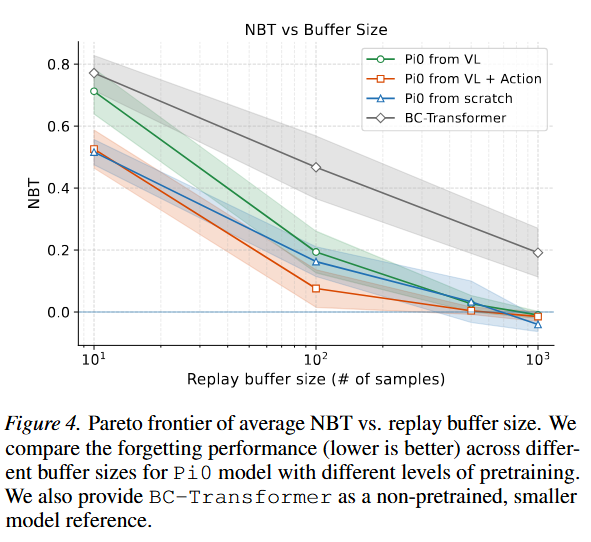
Figure 4를 보시면 replay buffer size와 forgetting의 관계를 볼 수 있습니다. 저자들은 fig.4에서 볼 수 있듯 buffer가 작아질수록 pretraining의 가치가 더 커지는 것을 확인할 수 있었다고 합니다. Replay가 풍부할 때는 모두 forgetting이 적을 수 있지만 replay가 극도로 작아지는 low-data regime에서는 pretrained 모델과 non-pretrained 모델의 차이가 급격히 벌어졌다고 합니다. 사전학습을 하는 것 만으로도 과거 지식을 유지하는 데 필요한 외부 메모리의 양까지 줄여주는 역할을 했습니다.
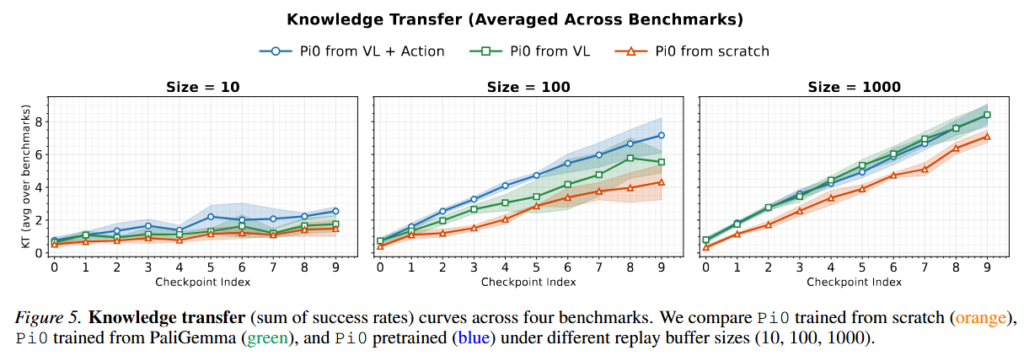
저자들은 여기서 forgetting이 적다고 해서 항상 좋은 것은 아니었다고 합니다. 어떤 모델은 그냥 새 태스크를 잘 못 배우기 때문에 결과적으로 성능 변화가 작아 보일 수도 있기 때문에 저자들은 backward transfer만 보지 않고 Knowledge Transfer(KT) 도 함께 분석했습니다. KT는 모든 task에 대한 SR의 합으로, 시간이 지나면서 전체 지식이 얼마나 축적되는지를 보여주는 지표였다고 합니다. Figure 5를 보면 Pi0 from VL + Action과 Pi0 from VL은 replay size가 10, 100, 1000인 경우 모두 KT가 꾸준히 증가했지만, Pi0 from scratch는 증가 폭이 훨씬 작았습니다. 즉, pretrained 모델은 안 잊으면서도 계속 배웠고, scratch 모델은 안 잊는 것처럼 보여도 사실 덜 배우고 있었을 가능성이 있다고 합니다.
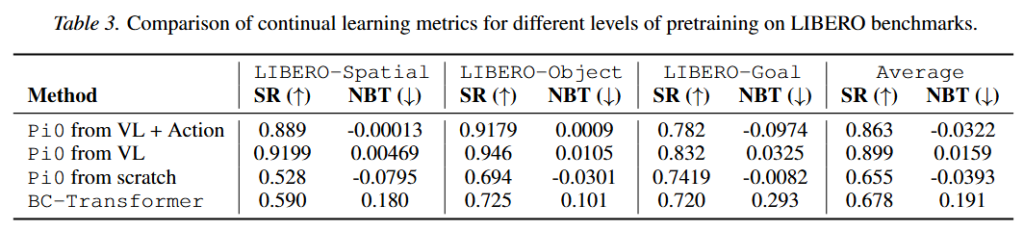
Table 3도 비슷한 결과를 볼 수 있습니다. 예를 들어 평균 SR은 Pi0 from VL + Action이 0.863, Pi0 from VL이 0.899였고, Pi0 from scratch는 0.655였습니다. 하지만 평균 NBT는 각각 -0.0322, 0.0159, -0.0393였습니다. 얼핏 보면 scratch도 forgetting이 적어 보일 수 있지만, from scratch인 경우 BC-Transformer보다 SR이 낮은 것을 볼 수 있습니다.
VLAs Retain Knowledge that is Seemingly Forgotten
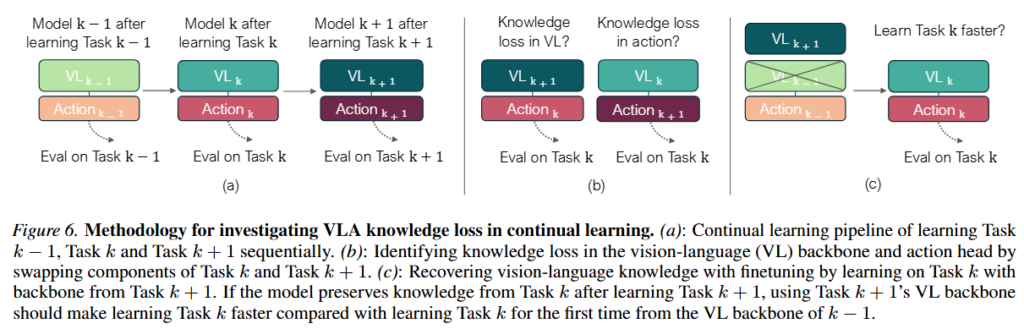
저자들은 pretrained 모델들의 forgetting 현상이 실제로 지식이 사라진건지, 내부 표현은 잠재적으로 남아있지만 끄집어내지지 않은 것 뿐인건지를 vision-language backbone과 action head를 분리해서 분석했습니다. 위 figure 6와 같이 진행했습니다. 베이스라인 (a)는 모델이 Task k-1 → Task k → Task k+1를 순차적으로 학습합니다. 그리고 Task k를 막 배운 직후 성능과 Task k+1까지 배운 뒤 Task k 성능을 비교해서, 다음 태스크 학습이 직전 태스크를 얼마나 망가뜨렸는지 봅니다. 즉, forgetting이 실제로 얼마나 생겼는지 기준점을 잡는 실험입니다. (b)세팅인 componenet swapping은 forgetting이 VL backbone쪽인지 action head 쪽인지를 알아보기 위한 세팅으로 k+1 까지 학습했을 때 VL backbone만, action head만 k+1번쨰를 사용하고 나머지는 k시점을 사용했다고 합니다. 마지막으로 (c) task performance recovery는 겉으로 성능이 떨어졌다고 해서 정말 완전히 잊은 건지 확인하는 실험입니다. Task k+1까지 학습한 VL backbone을 가져와서 다시 Task k를 finetuning하고, 처음 Task k를 배울 때보다 얼마나 빨리 peak 성능에 도달하는지 봅니다.
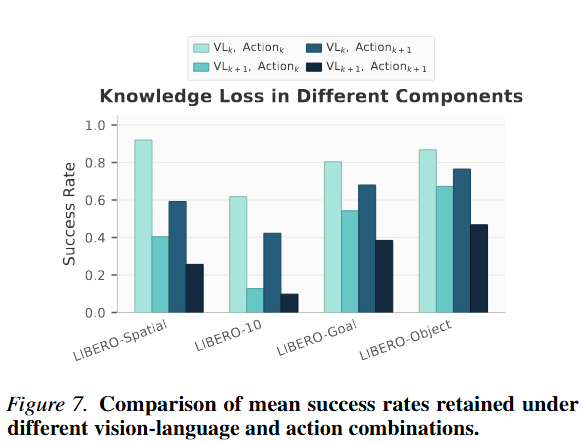
이를 통해서 저자들은 세가지 결과를 얻을 수 있었다고 합니다. 첫째, forgetting은 monolithic하지 않았다고 합니다. action head만 바꾸거나 VL backbone만 바꾸었을 때 성능은 원래 모델보다 낮아졌지만, 완전히 업데이트된 모델보다는 낫다고 합니다. 즉, 지식 손실은 모델 전체가 한 번에 날아가는 식이 아니라, 컴포넌트별로 다르게 나타났다고 합니다. 둘째로는 VL backbone이 forgetting의 주된 원인이었다는 점입니다. Action head를 바꿀 때보다 VL backbone을 바꿀 때 성능 하락이 더 컸습니다. 저자들은 이것을 행동 매핑보다 표현 공간의 변화가 더 큰 문제라고 해석했습니다. 셋째로는 task diversity가 클수록 VL 쪽 forgetting이 더 크게 보였습니다. 예를 들어 시각적 배경이 더 다양한 LIBERO-10에서 VL backbone swap의 성능 하락이 더 컸고, 비슷한 pick-and-place 패턴이 반복되는 LIBERO-Object에서는 action head swap의 영향이 상대적으로 작았다고 합니다.
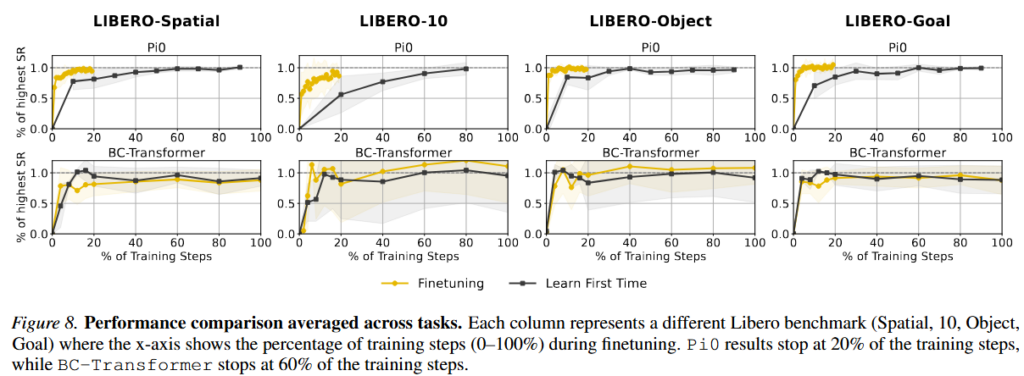
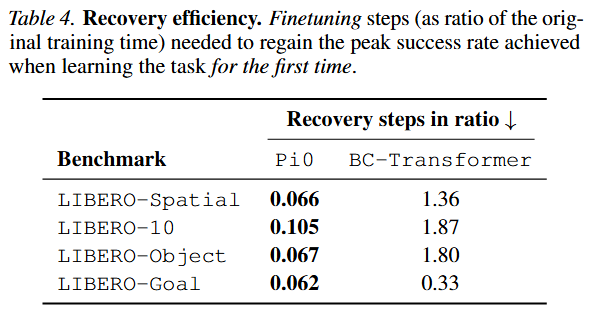
또 흥미로운 점으로 저자들은 recovery 실험을 진행했습니다. Figure 8과 Table 4를 보면 Pi0는 이전 태스크의 peak 성능을 원래 학습 스텝의 10% 이하로 빠르게 회복할 수 있었다고 합니다. Recovery efficiency는 LIBERO-Spatial 0.066, LIBERO-10 0.105, LIBERO-Object 0.067, LIBERO-Goal 0.062였습니다. 반면 BC-Transformer는 각각 1.36, 1.87, 1.80, 0.33으로, 대부분 처음 학습 때보다 더 오래 걸렸습니다. 이는 pretrained VLA가 관련 표현이 내부에 남아 있어 짧은 finetuning만으로 재표현될 수 있다는 것을 보여줍니다. 반대로 scratch policy는 정말로 많이 잊어버렸기 때문에 거의 처음부터 다시 배워야 했습니다. recovery ratio가 1보다 큰것은 좀 의아하긴 합니다.
Conclusion
우선 저는 대규모 사전학습 된 모델들을 SFT하는 연구를 진행하고 있지는 않고, 작은 모델을 가지고 scratch 학습하는 것을 생각하고 있었는데, continual learning을 진행할 때 대규모 pretraining 없이는 확실히 forgetting 문제가 있는 것 같습니다. 흥미로운 점은 forgetting, transfer, recovery가 specialized continual learning algorithm보다 pretraining과 representation reuse에 더 크게 좌우된다고 정리된 결론입니다. 뭔가 더 있을 것 같은 느낌이… 또 모델 내부에 잘 학습된 중간 표현들을 분석하고 최대한 활용하는 방향에 대해서도 고민해볼 필요가 있다고 느껴졌습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다. 저희가 고민하는 부분에 대한 실험적 구성과 분석을 열심히 시도해 본 논문이네요.
궁금한 점 2가지 있습니다.
1. NBT(Negative Backward Transfer) 는 어떻게 정의되는 지 궁금합니다. 학습할 때 gradient로부터 weight 업데이트할 때 뽑는 수치인가요..? 아니면 학습 다 마치고 평가단계에서 따로 구하는 수치인가요?
2. 사실 비판적으로 봤을 때 의문인 점이, LIBERO는 구분된 task들끼리 물론 object의 구성과 배치가 다르겠지만 사실 도메인적으로 봤을 때 굉장히 다양한 background 분포는 가지지 못한 일관된 table top뷰, 유사한 3rd view pose에서 서로 비슷한 시각적 특징을 가진 데이터셋일 것 같은데, LIBERO에 대해서만 replay buffer 를 적용하여 해당 실험을 한 것이 과연 대규모 사전학습된 VLA들의 continual learning에서의 forgetting 문제에 효과적이더라 라고 일반화할 수 있을지 살짝 의문이 들었습니다.. 영규님은 이 정도로도 충분히 유의미한 실험이라고 보시는지 궁금합니다.