안녕하세요!
이번에 리뷰할 논문은 Stable Diffusion의 근간이 되는 Latent Diffusion Model(LDM)논문입니다!
최근에 디퓨전 모델을 서베이 하면서 거슬러 거슬러 올라가 stable diffusion의 토대인 모델을 읽어보게 되었는데요. 저도 디퓨전모델을 들여다 본건 처음이라 마냥 낯설었는데 생각보다 디퓨전이라는 개념자체 간단한 것 같습니다!
많은 디퓨전 연구들 중에서도 이 논문은 기존 디퓨전모델의 높은 계산비용 문제를 줄이기 위해 픽셀공간이 아닌 latent공간에서 디퓨전을 수행하는 방법을 제안합니다!
생성의 품질은 최대한 유지하면서도 더 효울적으로, 조건까지 반영해서 이미지를 생성해보자! 하는것이 이 논문의 핵심입니다.
그럼 리뷰시작하겠습니다!
Intro
디퓨전이 뭘까요?!
Diffusion모델은 데이터분포 p(x)를 학습하기 위해 정규분포 노이즈가 섞인 변수를 점점 denoising하는 과정을 배우는 확률 모델입니다. 간단하게 말하자면 노이즈로부터 점점 원래 데이터를 복원하는 법을 배워 결국 새로운 데이터를 생성하는 모델입니다!
디퓨전은 무겁다~ 하는 말을 종종 듣는데, 그럼 디퓨전은 왜 무거울까요?
디퓨전 모델은 이미지에 노이즈를 넣었다가 반복적으로 조금씩 노이즈를 제거합니다. 근데 이 과정을 픽셀공간 전체에서 진행을합니다. 512x512x3의 픽셀공간에서 매 스텝마다 UNet을 돌려야하게 됩니다.
이렇게 되면 학습 때도, 추론때도 high cost이고, 또 step수도 많아서 느립니다. 특히나 powerful diffusion model(DM)은 hundreds of GPU days가 필요하고 A100 한개에서 5만 샘플 생성에 약 5일정도가 걸린다고 합니다. 즉 단순히 비싸다를 넘어 연구의 풀 자체가 자원이 있는 소수만 할수 있는 연구가 되어버린다고 지적합니다. 이에 반해 저자들은 이 논문을 통해 자신들이 제시하는 모델을 “Democratizing”라는 표현을 사용합니다!
따라서 진짜 중요한 정보만 압축해서 남긴 뒤 그 압축된 더 작은 공간에서 디퓨전을 돌리자! 라는 아이디어로 시작합니다.
즉, 핵심은 디퓨전 모델은 성능이 좋은데 너무 무겁기 때문에 픽셀에서 직접 돌리지 말고 더 작고 중요한 정보만 남긴 latent space에서 디퓨전을 돌리자! 입니다.
그렇다면 여기서 이 latent space는 어떻게 구성되어 있을까요?!
간단히 말하자면 원본이미지가 압축된 특징공간을 말합니다. 이 latent space는 파워풀한 pretrained autoencoder가 만든다고 합니다. 그럼 더 한단계 거슬러 올라가서 이 오토인코더를 통한 압축은 어떤식으로 이루어 질까요?
기존 픽셀 공간 diffusion의 학습을 보면 이미지를 크게 두 층으로 나눠서 봅니다.
먼저 perceptual compression으로, 이 압축은 사람눈에는 별로 안중요하지만 미세한 고주파 디테일을 줄이는 단계라고 합니다. 쉽게 말하자면 사람은 거의 못느끼는 사소한 텍스쳐 차이 같은 아주 미세한 픽셀노이즈 같은 걸 말합니다. 쓱 없어져도 사람이 보기에는 거의 티 안나는 부분들을 먼저 정리하는 단계를 거친 후, 다음으로 semantic compression단계가 진행됩니다. 이 압축은 진짜 중요한 의미적인 구조를 배우는 단계로 , 예를 들면 이게 고양이인지? 강아지인지?, 얼굴 위치가 어디인지?, 나무/도로가 어떻게 배치됐는지? 같은 이 이미지가 무엇인지를 결정하는 중요한 정보들을 압축하는 단계입니다.
저자들은 기존 픽셀 기반 diffusion은 이 두 압축을 다 똑같이 비싸게 처리한다고, 사실은 중요한건 senantic쪽 정보다다! 라고 말하면서, 그럼 덜 중요한 시각적인 디테일들을 압축해버리고 중요한 의미적인 구조를 최대한 남긴 latent space 학습으로 디퓨전이 배우게 하자고 합니다. 바로 이 부분이 latent space에서 diffusion의 출발점이 됩니다.
다시 latent space로 돌아와서, 이전에도 이 latent공간에서 생성하려는 시도는 있었지만 너무 많이 압축하면 디테일이 날아가고 약하게 하면 계산량 절감 효과가 떨어지는 trade-off 문제가 있다고 합니다. 이 때문에 저자들은 이 오토인코더가 만든 latent space은 단순히 작기만 하는게 아니라 사람이 보기엔 원본 이미지와 거의 비슷하게**(perceptually equivalent)** 복원이 될수 있도록 충분히 작으면서도 중요한 정보는 잘 남아 있는 latent space를 구성하는게 중요하다고 합니다.
저자들은 이 논문을 통해 복잡도 감소와 디테일 보존 사이의 균형을 가지는 latent space공간에 대해 거~의 최적점을 찾았다고 주장합니다.
이 모델의 또다른 핵심으로는 cross-attention이 있습니다.
디퓨전 모델이 단순하게 아무 이미지나 생성하는 모델이 아니라 조건(condition)을 받아서 그 조건에 맞게 생성하는 모델이 됩니다. 단순하게 말하자면 크로스어텐션으로 UNet의 이미지 쪽의 특징이 조건(텍스트,레이아웃 등)정보를 참고하게 만드는 연결장치입니다. Stable Diffusion계열이 텍스트 프롬프트를 잘 반영 할 수있는 가장 큰 이유도 여기에서 나옵니다.
대략적인 흐름은 아래와 같이 진행이 됩니다.
이미지 x → 오토인코더로 latent z로 압축 → latent z 위에서 diffusion 수행 → 다시 디코더로 이미지 복원
아래애서 이 흐름에 맞춰 구체적으로 어떻게 되는지를 살펴봅시다!
Method
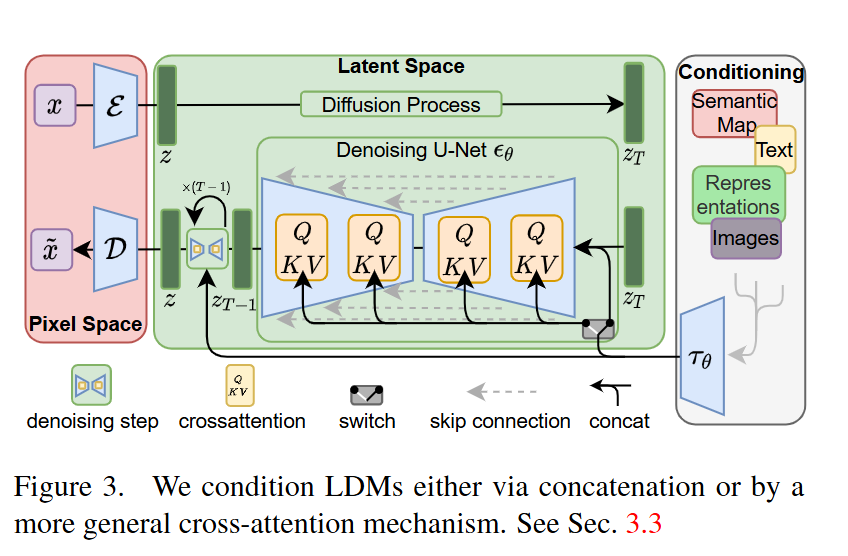
3.1. Perceptual Image Compression
이 단계에서는 먼저 이미지를 더 작은 latent space로 압축하는 오토인코더를 학습합니다. 이 오토인코더는 perceptual loss와 patch-based adversarial objective를 함께 사용하기 때문에 단순히 픽셀 값만 맞추는 것이 아니라 사람이 보기에 더 자연스럽고 선명한 복원 이미지를 만들 수 있습니다. 따라서 L1,L2 loss만 사용할때 자주 나타나는 블러현상도 줄일 수 있습니다.
(해당 부분의 학습 loss는 이전 연구의 로스를 그대로 쓴다고 합니다. 해당 부분의 자세한 내용은 참조한 이전 연구 논문(링크)을 참고해주세요! )
입력이미지x( HxWx3)는 encoder E를 통해 latent representation인 z(hxwxc)로 압축됩니다. z = E(x)
그 후 decoder D를 통해 x’로 복원됩니다 x’ = D(z) = D(E(x))
이때 인코더는 이미지를 f(=H/h=W/w)비율로 downsampling합니다.
(논문에서는 f를 여러 downsampling factor로 실험했다고 합니다)
또한 latent space가 너무 불안정해지지 않도록 두가지 정규화기법도 비교합니다.
먼저 KL-reg는 VAE(Variational Autoencoder)처럼 학습된 잠재공간이 표준 정규분포에서 크게 벗어나지 않도록 약간의 KL패널티를 부과하는 방식으로 에서 사용하는 기법과 유사합니다.
두번째는 VQ-reg로 이 방식은 decoder 내부에 vector quantization을 도입하는 방식입니다.
이 latent space를 구성하는 것에 있어 가장 중요한것은 2차원 구조를 그대로 유지한다는 것 입니다. 그래서 latent를 1차원으로 펼쳐서 다루던 기존의 방법보다 이미지의 공간 정보나 세부묘사 같은 디테일을 잘 보존 할수 있습니다.
3.2. Latent Diffusion Models
[Diffusion Models]
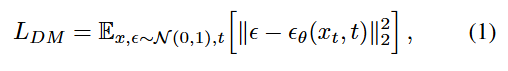
Diffusion모델은 인트로 초반에 말 한것처럼 데이터분포 p(x)를 학습하기 위해 정규분포 노이즈가 섞인 변수를 점점 denoising하는 과정을 배우는 확률 모델입니다. 이제 이 말이 무슨말인지 감이 오셨을거라고 생각됩니다!
기존의 diffusion은 픽셀공간에서 진행됩니다. 입력이미지 x에 노이즈를 점점 섞어 x_t를 만들고, 모델은 이 노이즈 낀 이미지로부터 실제 노이즈ϵ를 예측합니다.
즉, 위의 식(1)은 사실상 모델이 실제 노이즈를 얼마나 잘 맞히는가?!를 보는 손실입니다. 위의 식에서 대괄호 내부의 식은 실제 노이즈 ϵ와 모델이 예측한 뒷 항(노이즈 ϵ(어쩌구))의 차이를 줄이도록 학습합니다. 이걸 여러 시간 단계(t)에 대해 반복하면 모델은 점점 noisy한 샘플에서 노이즈를 제거하는 법을 배우게 됩니다.
그럼 저자들이 제안하는 LDM에서는 어떻게 될까요? 아래를 살펴보죠!
[Generative Modeling of Latent Representations]
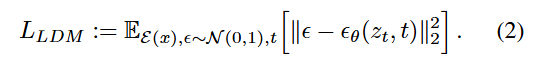
가장 중요한 변화는 딱 하나입니다. LDM에서는 x(픽셀공간) 대신 z(잠재공간)를 씁니다.
기존의 DM이 픽셀 이미지에 대해 diffusion했다면, LDM은 latent representation z에 노이즈를 섞어 만든 z_t에 대해 diffusion을 진행합니다. 즉 식 (1)에서의 x_t가 식 (2)에서는 z_t로 바뀝니다.
컨셉은 굉장히 단순하죠?! 하지만 이 단순한 부분이 논문 전체에 걸친 핵심입니다. z는 더 작고, 고주파의 잡다한 정보가 줄어있고, 그만큼 의미적인 정보가 더 잘 모여있는 표현이기 때문에 diffusion 모델이 더 적은 계산으로도 더 중요한 구조를 배우는데 집중할 수 있게됩니다.
또한 오토인코더로 만든 latent representation(z)는 이미지처럼 2D의 spatial structure구조로 보관하기 때문에 convolution, local receptive field, multi-scale processing, skip connection같은 이미지용 inductive bias를 그대로 활용할수 있습니다.
따라서 이 노이즈를 예측하는 diffusion의 백본(ϵθ (-, t)) 으로 time-conditional UNet을 사용하여 공간 구조는 유지한 latent위에서 이미지에 잘 맞는 UNent으로 diffusion을 하는 구조 입니다.
(유넷 구조에 대한 자세한 설명은 논문을 참고해주세요)
여기서 학습과 생성의 과정을 다시 짚어보자면 아래와 같습니다
(학습때 : x를 인코더 E로 latent z로 바꾸고 → 거기에 노이즈를 섞어 z_t를 만들고 → 모델이 노이즈를 예측하게 학습)
(생성때 : latent space에서 샘플 z를 만들고 → 디코더 D를 한번 통과시켜 이미지 복원 )
여기서 diffusion의 무거운 반복 노이즈 예측 과정은 latent공간에서 수행되고 마지막에만 decoder 한번을 통해 이미지로 바뀝니다. 이 부분이 계산량이 크게 줄어드는 이유입니다.
3.3. Conditioning Mechanisms
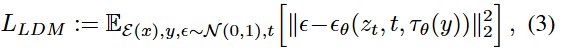
기본 디퓨전은 그냥 데이터 분포 자체를 배웁니다. 예를들어 unconditional model은 그냥 그럴듯한 이미지 하나를 만들어라~ 정도만 배웁니다. 하지만 이미지 생성으로 원하는바는 강아지를 그려줘, 이 화단에 분수를 그려줘, 이 semantic map에 맞는 장면을 만들어줘 같은, 어떤조건 y를 주고 그 조건에 맞는 이미지를 만들고 싶어 합니다. 이 말을 수식으로 쓴다면 p(z|y)로, 조건 y가 주어졌을때 latent z가 어떻게 생겨야 하는가를 배우는 것입니다.
즉 조건부 LDM은 noisy latent z_t뿐만 아니라 조건정보 y도 같이 보고 노이즈 ϵ예측을 진행하는 것으로 이 조건 τθ(y)를 참고해서 그 조건에 맞는 방향으로 노이즈를 빼는법을 학습합니다.
그럼 이 조건 y는 뭐가 될수 있을까요?
논문에서는 텍스트 프롬프트, semantic map, 클래스 라벨, image-to-image translation용 조건 등과 같은 여러 형태가 될 수 있다고 합니다.
즉 이 구조는 하나의 특정 조건에만 맞춰진 것이 아니라 범용적인 조건부 생성 프레임워크입니다. 이 범용성이 나중에 text-to-image나 layout-to-image, super-resolution, inpainting같은 다양한 응용으로 이어질수 있다고 합니다.
그럼 이 조건을 어떻게 받아서 사용할까요?
간단하게 말하자면 UNet안에 cross-attention을 넣습니다. 조금 더 직관적으로 말하자면 현재 diffusion이 보고있는 latent feature가 있고 조건정보 y가 있으면 이 둘을 서로 연결해 지금 어떤 조건을 참고해야 하는지 보게하는 장치가 cross-attention 입니다.
cross-atteniton을 사용해서 UNet이 현재 이미지 latent를 보면서 질문(Q)를 던지고, 조건쪽 정보가 답할 재료(Key, Value)를 주는 구조로 진행됩니다.
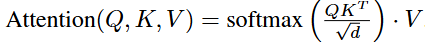
위 식과 같은 attention의 각 요소 Q,K,V를 아래와 같이 둡니다.
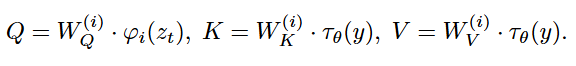
Q(query) : UNet의 중간 latent feature ϕi(zt)에서 만들어진 질문입니다. 이때 ϕi(zt)는 UNet 내부의 중간 latent feature로 지금 생성중인 이미지의 현재상태 입니다.
K(key), V(value) : 각각 조건정보의 검색 키와 실제로 가져올 조건정보 내용입니다. 이때 τθ(y)는 조건 y를 가공한 표현으로 예를들어 조건이 텍스트라면 텍스트를 그냥 넣는것이 아니라 UNet이 읽을 수 있도록 각 조건별로 도메인 특화 encoder를 통해 중간표현으로 바꿔서(projection) 넣습니다.
즉, 현재 이미지 feature가 조건정보 중 어떤 부분을 참고해야 할지 선택해서 가져오는 과정입니다.
이제 다시 식(3)을 다시보자면 기존에는 noisy latent만 보고 노이즈를 맞췄다면 이 conditional LDM은 noisy latent와 조건정보 τθ(y)를 같이보고 노이즈를 맞추게 됩니다.
즉, 모델이 학습하는 건 단순 노이즈 제거가 아니라 조건에 맞는방향으로 노이즈를 제거하는 법을 학습합니다.
Experiment
[On Perceptual Compression Tradeoffs]
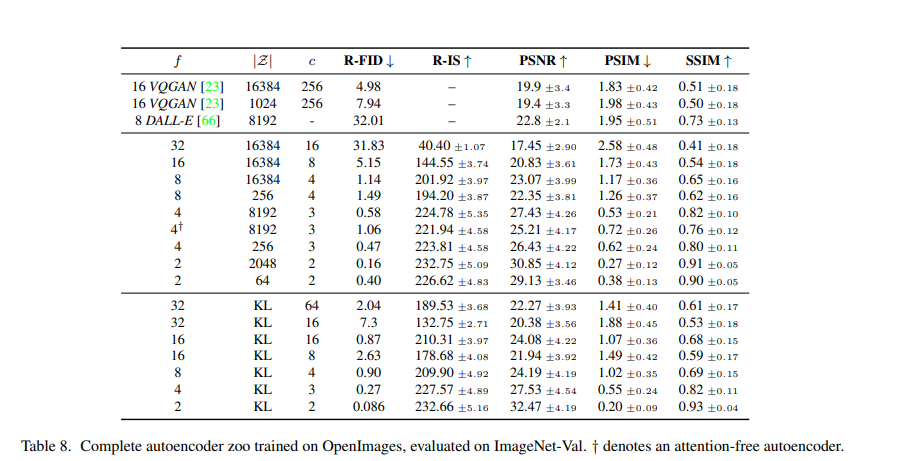
table8은 처음에 진행되는 오토인코더의 성능표입니다. 여기는 latent로 얼마나 압축을 하는게 가장 적당할까? 를 실험으로 확인한 부분입니다.
압축을 너무 적게 하면 대부분의 픽셀들을 다뤄야하니 너무 느리고, 그렇다고 압축을 너무 많이하면 정보가 날아가는데 그 중간 어디쯤이 가장 좋을지를 tabel8으로 확인 할 수있습니다. 표의 f는 다운샘플링 비율로 f가 클수록 압축비율이 큰 강한압축 입니다.
표의 3등분(행 기준)중 중간 부분을 대표적으로 분석해보자면 f가 너무 클경우 압축을 강하게 했기때문에 세밀한 구조나 디테일, 작은 물체와 같은 정보가 사라지기 쉽습니다. 그래서 PSNR(픽셀 단위 복원 품질)/SSIM(구조적 유사도)이 불리해지고 복원 품질도 제한된다고 합니다.
반대로 f가 작아질수록 원본 정보를 더 많이 보존할수 있기 때문에 R-FID(재구성 이미지의 FID)는 더 낮아지고 PSNR/SSIM은 올라 복원품질은 좋아지는 경향이 있습니다
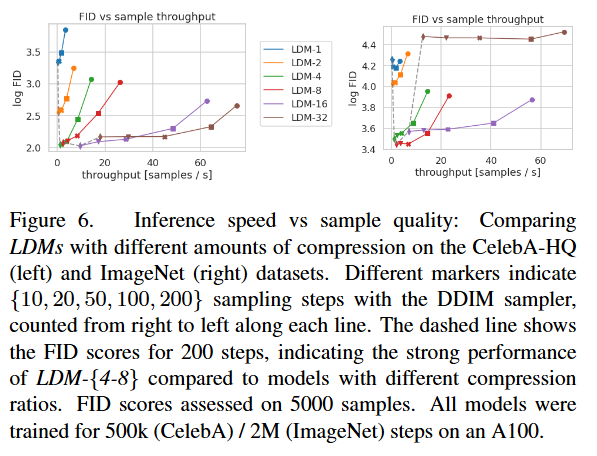
해당 table8만 보면 f=2일때가 가장 좋지만 LDM입장에서는 여전히 다뤄야하는 공간이 크기 때문에 fig6으로 속도와 품질을 동시에 비교함으로 f=4~6일때가 가장 속도와 품질면에서 적당한 구간임을 확인했습니다.
[Conditional Latent Diffusion]
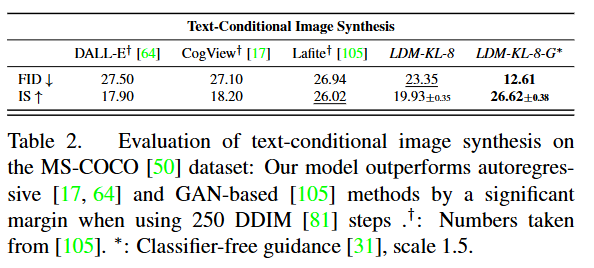

이 부분의 핵심은 LDM에 텍스트 조건을 넣을수 있게 만들었다는 점 입니다. method3.3에서 설명했듯이 먼저 텍스트 프롬프트를 받아서 transformer encoder로 표현한 뒤, cross-attention을 통해 UNet에 주입됩니다. table2는 MS-COCO에서 text-to-image 성능을 정량적으로 비교한 표입니다. DALL-E 등과 같은 다른 생성모델들 보다 텍스트 조건 생성에서 더 좋은 품질을 보이는 것을 확인할 수있습니다.
fig7은 text-to-image와 layout-to-image 예시를 통해 이 conditioning방식이 실제로 생성 결과도 좋게 나타난다는 것을 정성적으로 확인할 수 있습니다.

저자들이 제안하는 이 LDM은 단순히 계산량을 줄이기 위한 압축 기법 뿐만이 아니라 다양한 테스크에 맞춰서 조건부 생성까지 가능하게 함으로 diffusion 모델을 더욱 실용적으로 확장한 핵심연구입니다!
감사합니다!
안녕하세요 찬미님 좋은 글 감사합니다.
디퓨전 관련에서 저도 아주 약간의 지식을 가지고 있어서 재밌게 읽었습니다.
한가지 궁금한점이 있는데, “이 latent space를 구성하는 것에 있어 가장 중요한것은 2차원 구조를 그대로 유지한다는 것 입니다. 그래서 latent를 1차원으로 펼쳐서 다루던 기존의 방법보다 이미지의 공간 정보나 세부묘사 같은 디테일을 잘 보존 할수 있습니다.” 이 표현이 단순 주장으로 납득이 되는 문장인지 궁금합니다. 선행 reference같은게 있나요? 아님 그럴 것 같다 정도로 주장된건가요. 감사합니다.
안녕하세요 인택님 댓글 감사합니다.
질문주신 부분은 논문이 2D vs 1D를 직접 실험으로 증명하지는 않았습니다.
그 부분은 기존 1D ordering 기반 latent autoregressive 방법들(VQGAN, DALL-E)과 비교해서 저자들은 LDM이 2D latent structure를 유지하기 때문에 UNet의 spatial inductive bias를 활용할 수 있게되고, 이 점에서 디테일 보존에 유리하다고 설명합니다.
단순 추측이라기보단 위 기존 방법들과 본문글의 table8결과를 바탕으로한 주장으로 이해하는게 정확할것 같습니닷
안녕하세요 찬미님 좋은 리뷰 감사합니다.
픽셀 레벨에서는 너무 무거워서 latent space에서 reconstruction을 하는게 정말 흥미로웠습니다.
아무래도 더 압축된 정보로 생성을 하다보니 성능과 연산량의 trade-off가 있지 않을까 싶은데
conditioning이 아닐때는 픽셀 단위로 생성하는 모델과 비교해서 얼마나 차이가 나는지 궁금합니다. 감사합니다.
안녕하세요 정우님 댓글 감사합니다.
댓글에는 사진이 첨부되지 않아 논문 링크로 드리겠습니다. (https://arxiv.org/pdf/2112.10752)
논문 6페이지에 있는 table1에 보면 조건 없는 생성에서도 LDM은 여러 데이터셋에서 기존 모델들과 비교해 더 낮거나 비슷한 FID를 보여 성능 차이가 크지 않거나 오히려 더 좋았습니다
안녕하세요 찬미님 좋은 리뷰 감사합니다. 궁금한 부분이 있어서 남겨놓습니다.
Q1. cross-attention 에서 key, value에 도메인 특화된 encoder를 사용한다고 해주셨는데, task마다 heuristic하게 설정해줘야 하는 것인가요?
Q2. latent space는 많이 압축되어 있어서 denoising 후에 아주 작은 변화가 semantic을 크게 바꾸게 되는 것이 아닌지 궁금합니다.
감사합니다.
안녕하세요 성민님 댓글 감사합니다.
Q1.
네! 도메인마다 어느정도 휴리스틱하게 정해집니다. 다만 완전히 임의로 붙인다기 보다는 조건 모달리티에 맞는 encoder방식을 선택하는쪽입니다.
예를 들어 텍스트 조건에서는 BERT tokenizer + transformer encoder를 사용했고, semantic layout처럼 공간적으로 정렬되는 조건은 cross-attention보다는 concat 방식도 함께 사용합니다.
Q2.
논문도 그 부분으로 인해 latent를 무작정 강하게 압축하는것이 아닌 perceptually equivalent 하면서도 의미 정보는 유지되는 공간을 먼저 학습하는 것이 중요하다고 설명합니다. 고주파의 중요하지 않은 디테일은 줄이고 semantic한 정보에 집중할 수 있게 됩니다.
물론 압축을 강하게 하면 정보손실 때문에 recaonstruction품질이 떨어지기긴 합니다. 따라서 Table8,fig6의 실험결과처럼 적당한 latent수준으로 압축해야한다고 말합니다
안녕하세요 찬미님 좋으 리뷰 감사합니다.
diffusion 모델에 대해서 잘 아는건 아니지만 딱 겉으로만 알고 zeroshot으로 사용해보기만 했는데 잘 다뤄주신거 같아 잘 읽었습니다. 저 또한 diffusion은 무겁다는 생각을 가지고 있긴한데요 그래서 처음에는 말씀주신것 처럼 더 빠른 diffusion을 제시하나 ? 좋은 정보만을 가지고 압축해서 생성했을때 더 빠르고 성능 좋은 모델이 나오는 줄알았는데 실험 table에 연산량 비교라던지 step 추론속도는 저자의 언급이 없었는지 궁금합니다.
감사합니다
안녕하세요 우진님 댓글 감사합니다!
fig 6에서 추론 속도와 FID를 같이 비교했습니다 이 실험으로 픽셀기반 보다 latent공간에서 diffusion을 수행한 것이 훨 높은 처리량과 더 낮은 FID를 보인다고 설명합니닷.
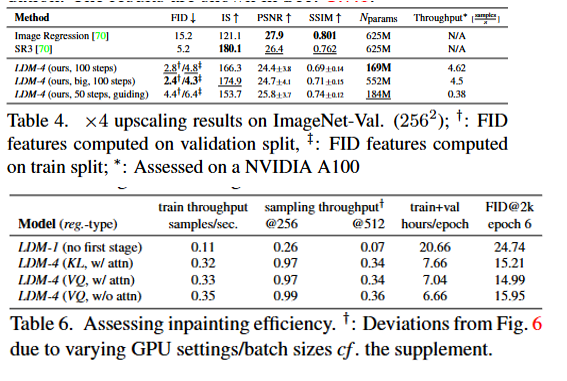
추가로 table4,6(테이블은 본문글 아래에 첨부해두겠습니다~) 에서도 throughput을 같이 다루고있어 연산량을 FLOPs 같은 디테일한 연산량 비교는 없지만 실제 속도나 효율 비교는 확인해 볼 수 있습니다
안녕하세요 찬미님 좋은 리뷰 감사합니다!
해당 방법론은 기존 diffusion model과 달리 latent space에서 diffusion을 진행함으로써 효율을 높이고, conditioning을 추가하여 조건에 맞는 생성이 가능하다는 특징을 가지고 있다고 이해했습니다.
condition에 text뿐만 아니라 image도 들어갈 수 있을 것 같은데, 관련 실험을 논문에서 따로 제시하고 있지는 않았나요? image를 condition으로 활용한다면 image-to-image translation 말고 또 어떤 곳에 쓰일 수 있을지 궁금합니다.
감사합니다.
안녕하세요 예은님 댓글 감사합니다!
네 댓글주신 것처럼 이미지도 조건으로 들어갈 수 있습니다.
논문에서도 실제로 이미지 조건을 써서 semantic synthesis(fig8), super-resolution(fig9), inpainting(fig10) 의 실험을 제시합니다 (해당 피규어는 리뷰글 아래에 첨부해두겠습니다~!)