해당 논문의 1저자가 제가 이전에 리뷰한 Affordance-R1의 1저자이기도 하며 SeqAfford, A4-agent, FSAG의 공동 저자라 찾아보다 읽게 되었습니다. 그 외에도 최근 다양한 학술대회에 논문을 많이 작성한 것 같습니다.
Abstract
기존 연구들의 경우 이미지와 같은 정적인 데이터로부터 affordance 지식을 학습하는 것에 집중하였으나, 이러한 방식은 시간적 정보와 인과관계나 동적 상호작용 맥락을 제공하는 데 어려움이 있습니다. 따라서 해당 연구는 로봇 조작을 위해 3D 물체의 affordance 영역을 찾는 것을 목표로 합니다. 이를 위해 HOI(Human-Object-Interaction) 비디오를 포함한 3D Affordance 데이터 셋 VIDA를 수집하였으며, VideoAfford라는 베이스라인을 구축합니다. 다양한 실험을 통해 저자들이 제안한 VideoAfford가 기존의 방법론들을 능가하며, affordance 추론 능력을 갖춘 강력한 open-world generalization 성능을 보임을 입증합니다.
Introduction
Affordance Grounding은 특정 행동이 이루어질 물체의 영역을 인식하므로써 시각적 인식과 로봇 조작을 연결하는 연구 분야입니다. 기존 연구들은 주로 2D 이미지를 대상으로 파운데이션 모델을 통합하여 세계에 대한 지식을 전이 하거나 Human-Object Interaction(HOI) 이미지로부터 사전 정보를 획득하는 방식으로 연구가 이루어졌습니다. 그러나 저자들은 현실적인 물리적 환경에서의 작업 수행을 고려할 때, 3D Affordance가 보다 정확하고 직관적인 지침을 제공할 수 있다고 보았습니다. 그러나 기존 3D affordance 연구들은 HOI 이미지나 언어적 지시에만 의존하고 있어, affordance의 인과적 메커니즘을 이해하는 데 중요한 상호작용 패턴을 파악하는데 시간적 정보를 충분히 활용하지 못한다는 한계가 있습니다. 이를 해결을 위해 최근 일부 연구에서는 HOI 비디오로부터 학습하는 방식이 연구되었으나, 이러한 방식은 노동 집약적으로 라벨을 요구며, 라벨 없이 egocentric 비디오를 활용하는 방식의 경우 로봇 조작에 필요한 세밀한 수준의 affordance 분할까지 수행하기 어렵다는 한계가 있습니다.
이러한 한계를 해결하기 위해 저자들은 HOI 시연 비디오로부터 3D affordance grounding이라는 새로운 문제를 정의하였습니다. 이는 물체 중심의 3D affordance를 찾기 위해 대규모의 시연 비디오 코퍼스를 활용하는 것을 목표로 합니다. 이를 위해 저자들은 유튜브 및 기존 데이터 셋 등으로부터 HOI 비디오를 수집하여 대규모 비디오-point cloud 쌍 데이터 셋인 VIDA를 구축하였습니다. 아래의 Figure 2와 같이, 저자들은 VLMs(해당 논문에서는 GPT-4o)을 이용하여 인터넷 비디오에 대한 설명 캡션을 생성하고, 이를 통해 객체 및 행동 정보를 추출합니다. 이후 VLMs는 비디오 내의 행동과 affordance 카테고리 사이의 대응 관계를 분석하며, 이렇게 생성된 어노테이션은 품질 보장을 위해 사람이 검증하고 수정합하였다고 합니다.
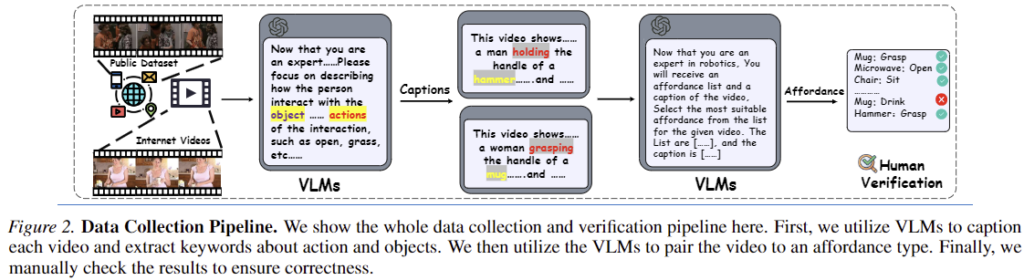
또한, 저자들은 MLLMs가 뛰어난 시각적 이해 능력을 갖추고 있다는 점에 주목하였습니다. 이러한 관점에서 video MLLM을 분석한 결과, 비디오 내 상호작용을 인식하고 affordance 영역의 위치를 추정할 수 있는 잠재적 능력이 존재함을 관찰하였다고 합니다. 이러한 관찰로부터 저자들은 video MLLMs에 내장된 affordance 추론 능력을 3D affordance grounding 분야로 확장하고자 하였습니다. 따라서 해당 논문에서 제안하는 VIDA를 기반으로 video MLLMs의 내재된 세계에 대한 지식을 활용하는 베이스라인 VideoAfford를 제안하였습니다. VideoAfford는 모델이 동적 행동 정보를 이해할 수 있도록 HOI 비디오로부터 action embedding을 추출하는 latent action encoder를 도입하였고, 공간 인식 능력을 강화하기 위한 loss를 설계하였으며, in-distribution과 out-ot-distribution 환경 모두에서 우수한 성능을 달성하였다고 합니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- HOI 비디오를 활용하는 video-based 3D affordance grounding 태스크 정의
- 최초의 대규모 video-based affordance grounding 벤치마크인 VIDA 데이터 셋 제안. VIDA는 38K개 HOI 비디오,16개 affordance 카테고리, 22K개의 annotated affordance point clouds로 구성
- 공간 인식에 대한 loss와 latent action encoding 매커니즘 통합을 위해 비디오 데이터에 내재된 affordance 지식을 효과적으로 활용하도록 설계된 베이스라인 VideoAfford 제안
- 광범위한 실험을 통해 저자들이 제안한 방식의 우수한 성능을 입증하였으며, open-vocabulary 일반화 능력을 보여줌으로써 real-world 적용에 대한 가능성을 확인
Datasets: VIDA
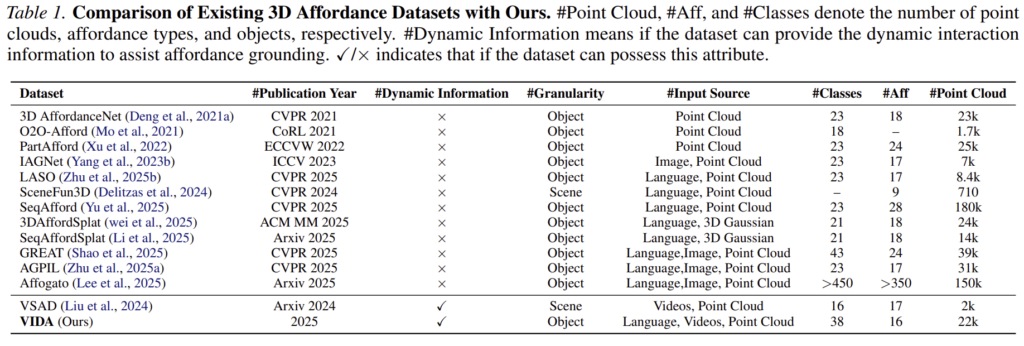
기존의 affordance 데이터 셋은 정적 이미지나 text에 집중하였으며, 복잡한 동적 상호작용을 고려하지는 못하였습니다. HOI 비디오의 물체와 접촉 시점 및 앞/뒤 프레임은 상호작용의 의도와 접촉의 인과 관계에 대한 풍부한 시간적 정보를 제공할 수 있으며, 저자들은 최초로 3D 객체 중심의 affordance 접지를 위해 HOI 비디오를 포함하도록 설계한 대규모 벤치마크 VIDA를 제안하였습니다.
[ Collection Details ]
VIDA 데이터는 HOIGEN-1M , TASTE-Rob나 인터넷에서 수집된 38K개의 HOI 비디오로 구성되며, 38가지 물체에 대한 16가지 affordance 카테고리로이루어집니다. 먼저, 비디오에 대한 캡션을 얻은 뒤, 물체와 action에 대한 정보를 추출합니다. 이후 GPT-4o를 이용하여 각 비디오에 대한 현재 동작에 해당하는 affordance를 추가로 분석합니다. 마지막으로 결과를 사람이 검토하여 어노테이션의 품질을 보장합니다. 또한, PIADv1,v2에서 point cloud를 추가로 수집하였으며, 그 중 HOI 비디오와 쌍을 이룰 수 있는 객체만을 선택하였다고 합니다. 다른 데이터 소스에서 어떻게 맞췄나 했는데, 인스턴스를 맞추지는 않은 것 같습니다.(다음 절에서 다시 설명합니다.)
[ Statistic and Analysis ]
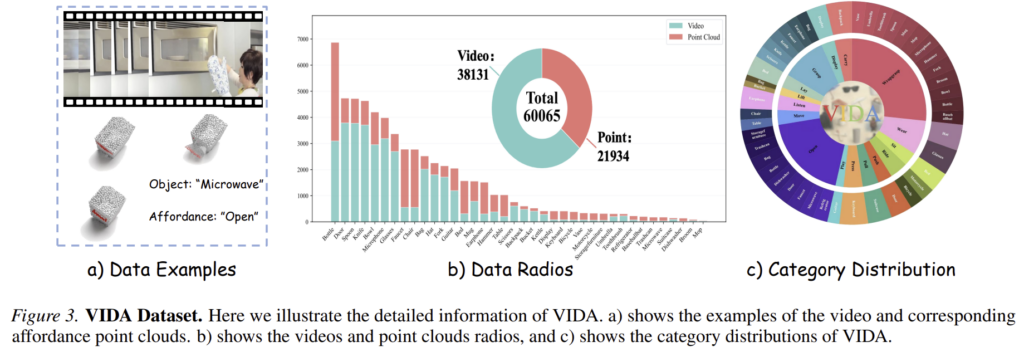
VIDA는 38.1K개 이상의 비디오와 21.9K개의 point cloud로 구성되며, 38개 객체 카테고리와 16개 affordance 유형을 포함합니다. 학습 시에는 비디오와 포인트클라우드가 고정된 1:1 대응일 필요가 없지만, 평가 시에는 재현성을 위해 엄격한 1:1 대응을 사용합니다.(Figure 3의 데이터 예시를 보면, 비디오는 오른쪽 손잡이로 여는 전자레인지고 point cloud는 위에 있는 손잡이를 당기는 방식의 전자레인지입니다.) 또한 데이터셋은 seen/unseen 설정으로 나뉘며, unseen에서는 테스트 시 학습에 없던 객체나 affordance가 포함됩니다.
Methods: VideoAfford
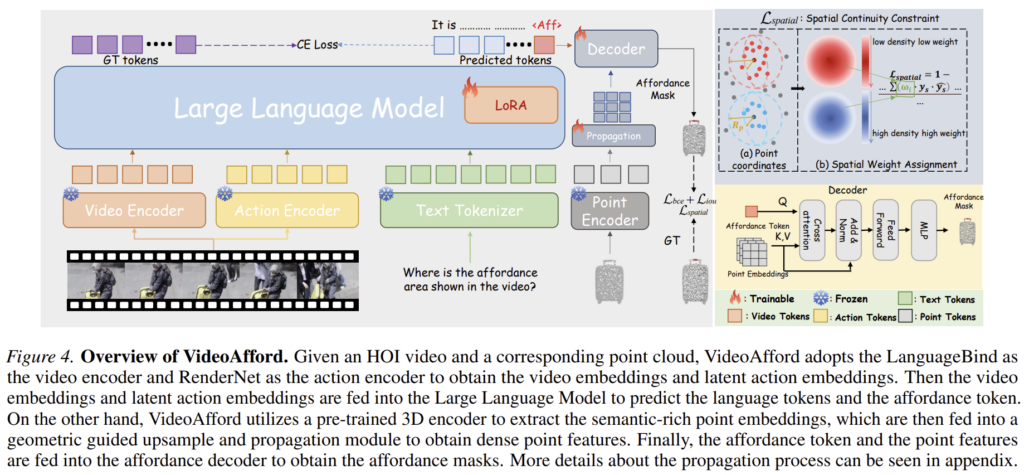
해당 논문은 HOI 비디오로부터 affordance를 학습하여 3D 물체의 행동이 이루어지는 영역을 찾는 것을 목표로 합니다. HOI 비디오 \mathcal{V}와 text instruction \mathcal{T}가 주어졌을 때, 모델 g는 affordance mask \mathcal{A}_{f}를 출력합니다. VideoAfford는 4가지 요소로 구성됩니다. (1) 3D vision encoder: dense prediction을 위한 3D feature 제공, (2) pre-trained latent action encoder: 행동에 대한 풍부한 사전정보를 제공, (3) video MLLM g: affordance 추론 능력을 위해 내재된 세계 이해 지식 제공, (4) transformer-based lightweight affordance decoder: affordance 임베딩과 point 임베딩을 통합하여 affordance mask를 예측.
[ Point Encoder ]
저자들은 대규모 text-image-point 쌍 데이터로 사전학습된 3D point cloud encoder(해당 논문은 Uni3D의 인코더를 사용하였다고합니다.)를 사용해 입력 point cloud를 임베딩합니다. 이후 Point-Bert 방식을 따라 기하학 정보를 활용한 업샘플링을 수행하여 sparse한 feature를 dense한 point feature로 확장합니다.
[ Spatial Constraints ]
대부분의 기존 연구들은 point 의 예측이 정확한지에 집중하여 공간적 연속성과 영역의 중첩에 대한 제약을 고려하지 않았습니다. 이러한 한계를 해결하기 위해 저자들은 point cloud의 공강적 이웃 정보를 활용하여 적응적으로 가중치 w_i를 부여하는 spatial loss를 제안합니다. 먼저 가중치w_i는 아래의 식으로 정의되며, \mathcal{N}_i는 사전에 정의된 반지름 이내에 포함되는 이웃 point를 의미합니다. 즉, 이웃 point와의 거리에 따라 조정되는 것 입니다.
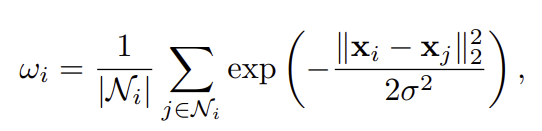
- \sigma: 사전 정의된 반지름의 0.1
spatial loss는 Dice loss에 가중치 w_i를 적용한 것으로 아래의 식으로 정의됩니다.
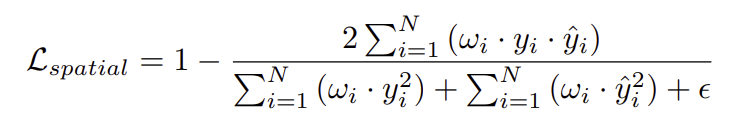
- y_i, \hat{y}_i: 는 GT와 예측된 확률 값
- \epsilon: 0이 되지 않도록 하는 작은 값
이는 모델이 인접한 point들이 함께 예측되도록 유도하여, affordance 영역이 더 연속적이고 응집된 형태를 갖도록 만듭니다.
[ Action encoder ]
저자들은 latent action encoder m을 도입하여 compact state representation으로부터 일반화 가능한 human object interaction motion을 학습하고자 하였습니다. 구체적으로, HOI 비디오가 주어졌을 때, N개의 프레임을 샘플링하고, action encoder를 이용하여 latent action embedding을 추출한 뒤, 이를 2개의 토큰 \mathcal{A}_c \in \mathbb{R}^{N⨉2⨉1280}으로 압축합니다. 해당 논문에서는 RenderNet 모델을 이용하였다고합니다.
[ Video MLLM Backbone ]
저자들은 video MLLM의 백본으로 이미지 인코더와 비디오 인코더, text 토크나이저와 LLM으로 구성된 Video-LLaVA를 이용하여 비디오와 행동, 텍스트 정보를 함께 처리합니다. 비디오 \mathcal{V}와 text instruction \mathcal{T}가 입력되면 비디오 인코더 e와 action encoder m을 이용하여 sparse한 비디오 토큰과 action 토큰을 얻고, 이를 concatenation하여 LLM에 입력으로 사용합니다. 이후 VideoAfford는 understanding text \mathcal{J}를 출력합니다. 또한, LISA 방식을 따라서 Video LLaVA의 vocabulary table을 확장하여 affordance 지식을 타나내는 토큰 <AFF>를 추가합니다. 이 토큰의 hidden state는 query embedding(affordance 임베딩)으로 투영되어 dense한 3D affordance mask 생성을 위해 이후의 decoder에 입력됩니다.
[ Affordance Decoder ]
마지막으로 dense한 3D affordance를 예측하기 위해 transformer-based lightweight decoder를 제안합니다. 이때 Query는 affordance 임베딩, Key와 Value는 point feature가 되도록 하여 cross-attention 모듈을 적용한 \mathcal{A}_f를 구하고, 이를 MLP 네트워크를 통과시켜 최종 affordance mask \mathcal{A}_{mask}를 구합니다.
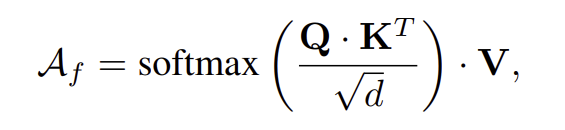
[ Training objectives ]
저자들은 HOI 비디오에서 추출한 affordance 지식을 3D affordance grounding으로 전이하기 위해 end-to-end 학습 loss를 설계합니다. 마스크 예측에 대해서 BCE loss와 IoU loss를 적용하고, 앞서 공간적 연속성과 응집성을 강화하기 위한 spatial loss를 추가하였으며, 마지막으로 언어 출력에 대한 cross-entropy loss를 적용하여 이들을 가중합한 방식으로 total loss가 구해집니다.
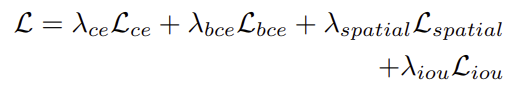
Experiments
Benchmark Setting
해당 논문은 HOI 비디오로부터 affordance 지식을 추출하여 3D affordance grounding을 수행하는 태스크를 처음으로 제안한 논문으로, 직접적으로 기존 방법과 비교하기는 어렵습니다. 따라서 저자들은 HOI 이미지 기반 3D affordance grounding 방법론들을 비디오 입력에 맞도록 변형시켜 비교하였다고 합니다. 또한 평가지표로는 AUC와 mIOU, SIM, MAE 4가지를 이용하였다고 합니다.
Comparison Results
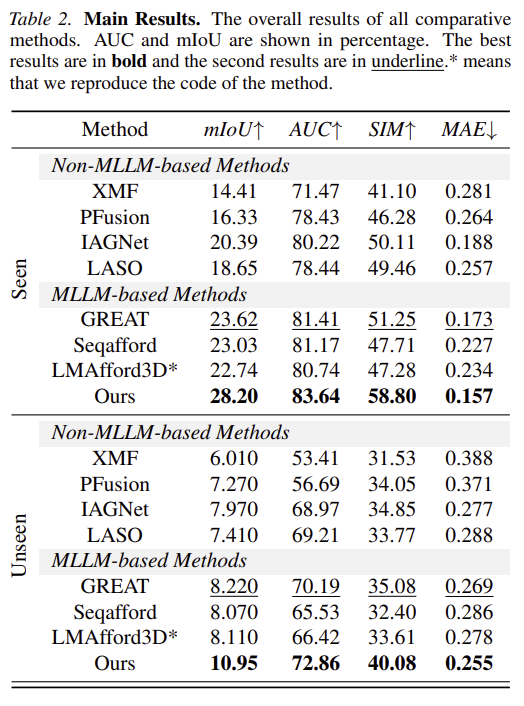
위의 Table 2는 VIDA 데이터셋에 대한 실험 결과로, 모든 기존 방법론들에 비해 저자들이 제안한 방식이 가장 좋은 성능을 보인다는 것을 실험적으로 확인할 수 있습니다. 낮은 성능을 보이는 기존 방법론들에 대해서는, 비디오 프레임을 단순히 인코딩하는 방식이 잘 작동하지 않은 것으로 해석하였으며, 이는 동적인 상호작용에 대한 복잡한 이해가 충분하지 않았기 때문이라고 분석하였습니다. 해당 실험을 통해 저자들은 VideoAfford의 강력한 비디오 이해 능력과 일반화 성능을 입증하였고, HOI 비디오에 내재된 affordance 지식을 활요알 수 있음을 보였습니다.
특히 모든 객체와 affordance 유형에 대해 학습된 Seen 케이스 뿐만 아니라 일부 객체가 포함되지 않은 Unseen 케이스에서도 좋은 성능을 보여주었는데, 이에 대해 저자들은 비디오로부터 동적인 상호작용 단서를 활용할 수 있었기 때문이라고 이야기하며, 이는 다양한 source에서 수집된 데이터 뿐만 아니라 MLLMs의 내재된 세계에 대한 이해 능력 때문이라고 어필합니다. 아래의 Figure 5는 이에 대한 정성적 결과입니다.

Ablation study
[ Effectiveness of Action Encoder and Spatial Loss ]
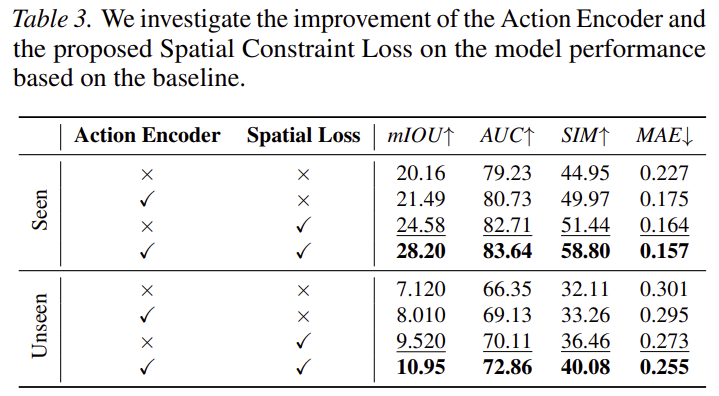
Table 3은 action encoder와 spatial loss에 대한 영향을 확인하기 위한 실험으로, 두가지를 도입하는 것이 모두 효과가 있다는 것을 실험적으로 확인할 수 있습니다. 특히 spatial loss의 경우 예측 마스크의 공간적 연속성과 응집력을 높이기 위해 설계가 된 loss인데, 실험 결과 IoU 지표에서 뚜렷한 성능 개선을 확인할 수 있습니다.
[ Choice of Sampled Frames ]
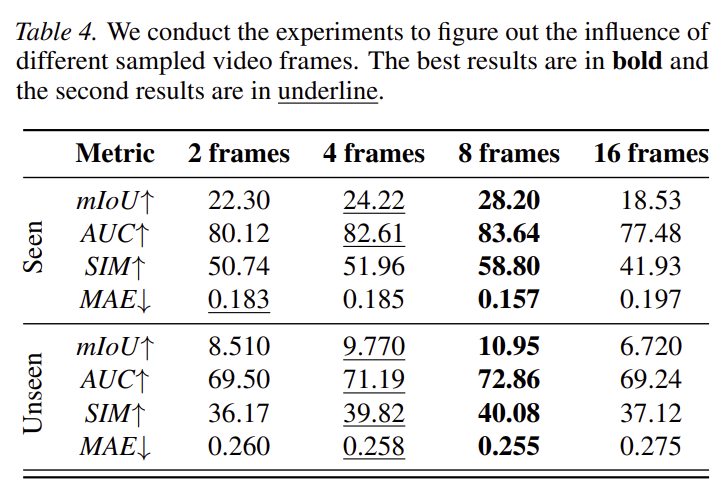
위의 table은 비디오에서 샘플링된 프레임 수에 따른 실험 결과로, 2개와 4개의 경우 너무 적은 프레임을 선택하다보니, 상호작용의 전체적인 동적 정보를 충분히 포착하지 못한다고 이야기합니다. 또한, 너무 많은 프레임인 16개의 프레임을 이용하는 경우에 정보가 중첩되고 혼잡해져 효과적인 feature 학습에 방해를 주고 계산량도 너무 증가시킨다고 분석하였습니다. 따라서 저자들은 8 프레임 정도가 적당하다고 결론을 내렸습니다. 전체 비디오의 길이가 어느정도일 때 프레임인지가 중요할 것 같은데, 이에 대한 자세한 설명은 따로 없어서 아쉽습니다. 그런데 특정 행동 기준으로 보았을 때, 그 행동의 앞뒤라고 생각하면 16 프레임은 너무 많은 것 같기도 합니다..
Conclusion
해당 논문은 HOI 비디오를 통해 동적 상호작용 정보를 활용하고자 하였으며, 이를 위해 HOI 비디오를 활용하는 video-based 3D affordance grounding 태스크를 새롭게 정의하고, 이를 위한 video-point cloud 쌍으로 구성된 데이터 셋 VIDA를 제안하였으며, 비디오 정보를 효과적으로 이용하기 위한 베이스라인 VideoAfford를 구축하였습니다. 또한, 다양한 실험을 통해 VideoAfford의 성능을 실험적으로 확인하였으며, latent action encoder와 spatial loss, MLLMs를 활용하는 등의 설계가 실제로 HOI 비디오의 동적 affordance 지식을 활용하는 데 도움이 된다는 것을 보였습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
HOI를 비디오를 사용하여 Affordance의 상호 작용패턴을 학습하는 것이 신기하네요.
action encoder에 대한 궁금증이 생겼는데요! action encoder가 Human의 직접적인 motion을 표현하는건가요? 아니면 그냥 action의 의도만 표현하는건가요?
loss를 정말 많이 사용하는 것 같은데 각각의 loss 앞에 붙은 가중치들은 hyperparameter인건가요?
제가 잘 몰라서 그럴 수도 있는데 8프레임이면 정말 짧은 순간인 것 같습니다. 이렇게 찰나의 순간만 사용하여도 동적인 정보를 학습할 수 있는건가요?
감사합니다!
질문 감사합니다.
우선 action encoder로 사용한 RenderNet을 찾아보니, 일관성 있는 캐릭터와 고품질 이미지를 생성하고 제어할 수 있는 강력한 AI 이미지 생성 플랫폼이라합니다. action encoder는 human의 직접적인 motion 자체라기 보다, 그 motion을 압축해서 만든 행동의 의미(의도)를 표현한 것으로 보는 것 같습니다.
맞습니다. loss의 가중합에 사용된 가중치는 hyperparameter로, 해당 논문에서 정확한 수치는 아직 공개되지 않은 것으로 보입니다.
저도 이에 대해 고민이 되었는데, 특정 상호작용(행동)에 대하여 앞 뒤로 대략적으로 어떤 행동인지를 보는 관점이라면 문제가 없을 것 같습니다. 물론 여기서 8 frame은 특정 구간 혹은 비디오에 대하여 샘플링 된 8개 프레임입니다.