안녕하세요. 최근 Multimodal LLM을 임베딩 모델로 활용하는 연구들에 관심을 가지면서 관련 논문들을 계속 살펴보고 있었는데, 이번에 소개할 논문은 reasoning 과정을 reinforcement learning으로 최적화해 멀티모달 임베딩 정확도를 높이려 한다는 점이 흥미로워 이번에 리뷰하게 되었습니다. 그럼 자세한 내용은 리뷰에서 설명드리겠습니다.
1. Introduction
Multimodal embedding은 이미지-텍스트 검색, 비디오 검색, 비주얼 문서 이해처럼 서로 다른 모달리티를 연결해야 하는 다양한 태스크의 핵심 기술입니다. 전통적으로는 CLIP, BLIP, SigLIP 같은 dual-encoder 구조가 널리 사용되어 왔습니다. 이런 방식은 각 모달리티를 별도 인코더로 표현한 뒤 공통 임베딩 공간에서 정렬하는 데 강점이 있지만, 서로 다른 모달리티 사이의 간극을 정교하게 메우는 능력은 최근의 Multimodal Large Language Models(MLLMs)에 비해 다소 제한적이라는 평가를 받습니다.
실제로 최근에는 MLLM이 가진 강한 멀티모달 이해 능력과 instruction-following을 활용해, 보다 범용적인 Universal Multimodal Embedding(UME)을 학습하려는 연구가 빠르게 늘고 있습니다. MMEB, MMEB-V2 같은 벤치마크도 이런 흐름을 잘 보여주는데, 다양한 모달리티와 instruction-aware 태스크를 폭넓게 포함하면서 “정말 범용적인 멀티모달 임베딩이 가능한가?”라는 질문을 본격적으로 다루기 시작했습니다.
이러한 연구 흐름은 그림 1에서 확인할 수 있습니다.
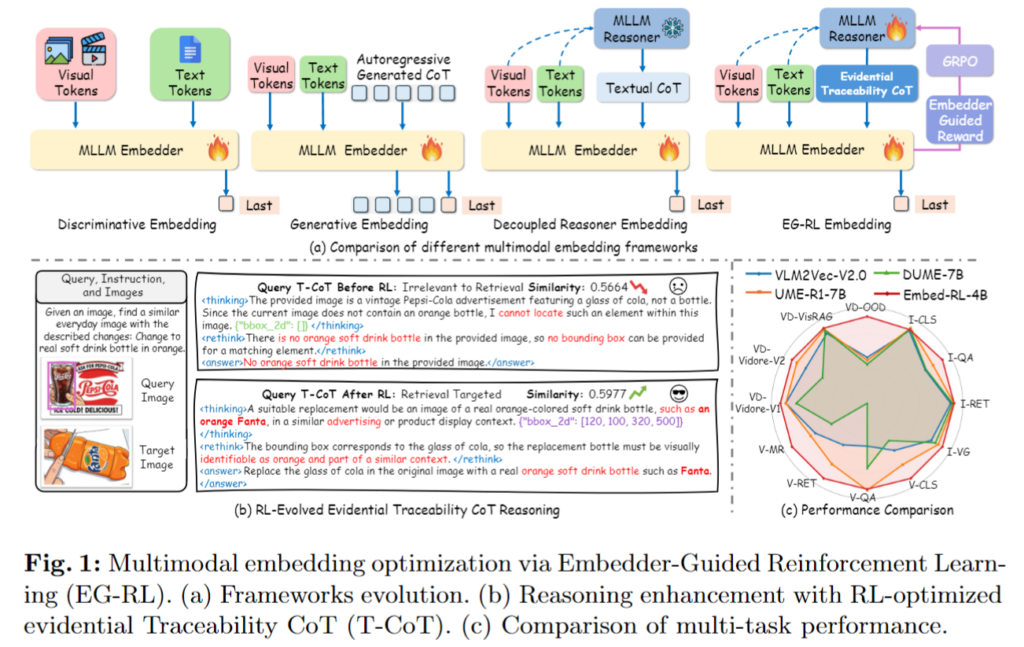
기존 MLLM 기반 임베딩 방법은 크게 마지막 hidden state를 직접 embedding으로 사용하는 discriminative 방식, CoT를 생성해 embedding 과정에 함께 반영하는 generative 방식, 그리고 Reasoner와 Embedder를 분리해 reasoning을 embedding 학습에 간접적으로 활용하는 decoupled 방식으로 나뉘어 발전해왔습니다.
그런데 여기서 기존 연구들이 공통적으로 마주하는 핵심 질문은 크게 두 가지로 볼 수 있습니다.
MLLM의 generative capability를 임베딩 학습에 어떻게 활용할 것인가?
그리고 이렇게 생성된 reasoning이 실제 retrieval 성능 향상으로 어떻게 연결되도록 만들 것인가?
먼저 첫 번째 질문과 관련해, 현재 대부분의 MLLM 기반 임베딩 방법은 여전히 discriminative embedding 모델에 가깝습니다. 즉, 입력 토큰의 마지막 hidden state에서 바로 embedding을 뽑아내는 방식이 주류라는 뜻입니다. 이런 방식은 구현이 단순하고 효율적이지만, MLLM이 본래 가지고 있는 생성 능력이나 추론 잠재력을 충분히 활용하지 못한다는 한계가 있습니다. 쉽게 말하면, reasoning이 가능한 모델을 가져와 놓고도 실제로는 “좋은 feature extractor” 정도로만 쓰고 있는 셈입니다.
이 한계를 넘기 위해 최근에는 generative reasoning을 embedding에 접목하려는 시도도 등장했습니다. 대표적으로 UME-R1은 MLLM이 생성한 textual Chain-of-Thought(CoT)를 활용해 discriminative embedding과 generative reasoning을 함께 다루려 합니다. 아이디어 자체는 retrieval을 할 때도 단순히 벡터만 뽑는 것이 아니라, 중간 추론 과정을 함께 사용하여 더 좋은 정렬을 하도록 유도하는 것입니다.
다만 이 방식은 contrastive loss와 next-token prediction objective를 동시에 최적화해야 하므로, 학습 과정에서 gradient conflict가 발생할 수 있다는 문제가 있습니다. 저자는 이것이 결국 성능을 제한하는 핵심 원인 중 하나라고 봅니다.
반대로 기존 연구에서는 Reasoner와 Embedder를 분리하는 decoupled paradigm도 제안되었습니다. 이 방식은 대형 모델이 offline으로 CoT를 생성하고, 그 reasoning을 바탕으로 Embedder만 학습하는 구조입니다. 얼핏 보면 앞선 gradient conflict 문제를 해결하는 방법처럼 보입니다.
하지만 여기에도 또 다른 문제가 있습니다. Reasoner가 만들어내는 CoT는 embedding 자체를 위해 함께 최적화된 reasoning이 아니라는 점입니다. 다시 말해, reasoning은 생성되지만 그 reasoning이 retrieval에 정말 유효한 방향으로 정렬되어 있는지는 보장되지 않습니다. 그래서 불필요한 설명이 섞이거나, 심하면 hallucination에 가까운 noise가 들어갈 수 있습니다.
또 하나 저자가 중요하게 지적하는 부분은, 기존 접근들이 reasoning을 주로 텍스트 수준에서만 다룬다는 점입니다. 하지만 멀티모달 retrieval에서는 텍스트 reasoning만으로 충분하지 않을 수 있습니다. 예를 들어 이미지에서는 중요한 영역 정보가, 비디오에서는 핵심 프레임이나 시간적 단서가 retrieval의 성능을 좌우할 수 있습니다. 그런데 reasoning이 텍스트 위주로만 이루어지면, 이런 visual-spatial cue나 video-temporal signal이 충분히 반영되지 못합니다. 저자는 이 지점을 embedding alignment bias로 설명하고 있습니다.
이러한 한계를 해결하기 위해 저자는 reasoning-driven decoupled UME framework를 제안합니다. 핵심은 Reasoner와 Embedder를 분리하되, 둘을 완전히 독립적으로 두는 것이 아니라 Embedder가 Reasoner를 다시 유도하도록 만드는 것입니다. 이를 위해 저자는 Embedder-Guided Reinforcement Learning(EG-RL)을 설계합니다. 쉽게 말하면, Reasoner가 생성한 CoT가 실제로 retrieval에 도움이 되는지를 Embedder가 reward signal의 형태로 평가하고, 그 보상을 바탕으로 Reasoner가 더 나은 reasoning trajectory를 생성하도록 학습시키는 구조입니다.
이 과정에서 저자는 먼저, 입력과 CoT 토큰의 순서를 받아 embedding을 생성하도록 Embedder를 학습합니다. 이렇게 학습된 Embedder는 일종의 reward model처럼 동작하며, Reasoner가 만든 추론이 query-target alignment에 얼마나 기여하는지를 판단할 수 있게 됩니다.
여기에 더해 저자는 evidential Traceability CoT(T-CoT)도 함께 제안합니다. 이 부분은 단순한 텍스트 reasoning뿐만 아니라, 이미지의 지역 정보, 비디오의 핵심 프레임, 텍스트의 키워드처럼 retrieval과 직접적으로 연결되는 단서를 추론 과정 안에 명시적으로 포함시키려는 시도입니다. 쉽게 말하면, 모델이 막연하게 길게 생각하도록 두는 것이 아니라, “어디를 봐야 하는지”, “어떤 단서가 중요한지”를 추론 궤적 안에 더 분명하게 남기도록 만든 것입니다. 저자는 이를 통해 긴 텍스트 검색, 거친 수준의 의미 매칭, 세밀한 정렬이 모두 필요한 복합적인 멀티모달 시나리오에서 더 강건한 성능을 기대할 수 있다고 주장합니다.
결국 이 논문의 핵심은 reasoning과 embedding 사이의 목적 불일치를 어떻게 줄일 것인지, 그리고 멀티모달 retrieval에 실제로 유효한 reasoning은 어떤 형태여야 하는지를 더 구체적으로 다루고 있다는 점이 중요합니다. 하나는 EG-RL을 통해 retrieval 친화적인 CoT를 학습하는 것이고, 다른 하나는 T-CoT를 통해 멀티모달 단서를 reasoning 과정 안에 구조적으로 녹여내는 것입니다. 저자는 이러한 설계를 통해 기존 generative embedding 방법들이 겪던 objective conflict, reasoning-task misalignment, 그리고 multimodal cue 활용 부족 문제를 동시에 완화할 수 있다고 봅니다.
이제 각 구성 요소와 학습 방식에 대해 살펴보겠습니다.
2. Methodology
2.1 Preliminaries
먼저 저자가 다루는 태스크는 universal multimodal retrieval입니다. 즉, 텍스트, 이미지, 혹은 text-image가 섞인 interleaved 입력을 query로 받았을 때, 여러 후보 집합 Ω={cn}n=1N 중에서 가장 관련 있는 대상을 찾아내는 문제입니다. 이 문제를 풀기 위한 가장 기본적인 학습 방식으로 저자는 contrastive learning을 사용합니다. 그림 2-(a)가 바로 이 부분을 보여주고 있습니다.
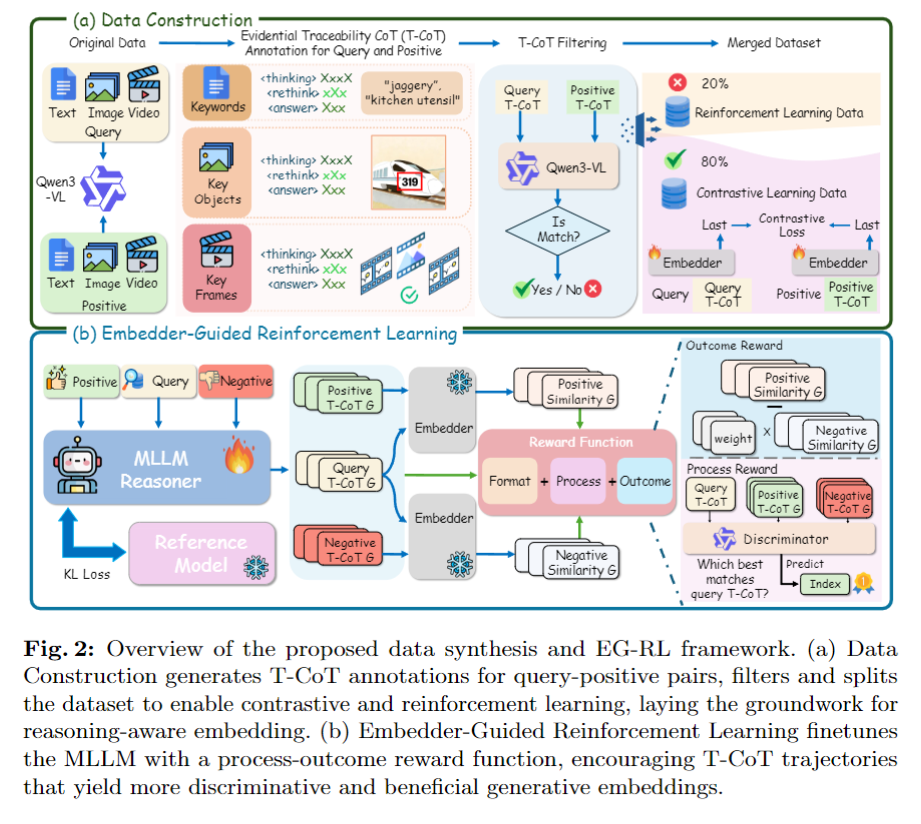
2.2 Data Construction
다음은 reasoning-driven universal multimodal embedding을 학습하기 위한 데이터 구성 방식입니다. 저자는 이를 sampling–annotation–filtering–splitting의 파이프라인으로 정리합니다. 그림 2-(a)가 이 과정도 함께 보여주고 있습니다.
먼저 데이터 풀은 세 가지 축에서 가져옵니다. 첫 번째는 MMEB-train 기반의 image-centric task들입니다. 여기에는 이미지 분류, 질문응답, retrieval, grounding 같은 작업이 포함됩니다. 두 번째는 LLaVA-Hound의 video-language instruction 데이터로, 비디오 캡셔닝, QA, retrieval 등을 포함합니다. 세 번째는 ViDoRe와 VisRAG 기반의 visual document retrieval 데이터입니다.
이렇게 가져온 query-positive pair에 대해, 저자는 evidential Traceability Chain-of-Thought, 줄여서 T-CoT를 추가 정보로 함께 붙여서 학습 샘플을 만듭니다. 여기서 T-CoT는 구조화된 세 단계 포맷을 따릅니다. 첫 번째인 <thinking>에서는 모달리티별 핵심 단서를 추출합니다. 예를 들어 텍스트는 키워드, 이미지는 bounding box, 비디오는 key frame처럼 retrieval에 직접적으로 도움이 되는 단서를 뽑아내는 식입니다. 두 번째인 <rethink>에서는 이렇게 뽑아낸 단서를 바탕으로 reasoning을 다시 정리합니다. 세 번째인 최종 answer에서는 retrieval과 관련된 핵심 정보를 요약합니다.
그 다음 단계는 filtering입니다. 저자는 custom judgment prompt를 사용해 query와 positive sample의 T-CoT가 정말 관련 있는지, 혹은 태스크 설명과 모순되지는 않는지를 점검합니다. 이 과정에서 relevance가 떨어지거나 reasoning이 어긋난 샘플은 제거하고, 문제가 없는 샘플만 contrastive learning에 사용합니다. 논문에 따르면 초기 데이터는 222만 개였고, filtering 이후 183만 개가 남았다고 합니다.
하지만 여기서 걸러낸 샘플을 완전히 버리지 않습니다. 필터링된 샘플 중 약 20%는 reinforcement learning 단계에서 hard example로 다시 사용합니다. 즉, contrastive pretraining에서는 noise를 줄이기 위해 제외했지만, RL 단계에서는 오히려 이런 어려운 예제가 exploration에 도움이 될 수 있다고 본 것입니다. 이 부분은 pretraining과 RL이 데이터에 요구하는 성격이 다르다는 점을 어느 정도 잘 반영한 설계로 보입니다.
또한 저자는 각 데이터셋에 대해 task importance와 data quality에 따라 서로 다른 training weight를 부여한다고 설명합니다. 다양한 데이터 소스를 섞을 때는 사실 이런 weighting이 성능에 꽤 큰 영향을 줄 수 있습니다.
정리하면, 저자가 구성한 데이터셋의 특징은 세 가지입니다. 첫째, text, image, video를 모두 포함하는 모달 다양성. 둘째, T-CoT를 통해 reasoning이 retrieval 목표와 직접적으로 연결되도록 만든 reasoning alignment. 셋째, filtering과 weighted sampling을 통해 noise를 줄이고 task 간 균형을 맞춘 quality assurance입니다. 결국 이 데이터 구성의 목적은 단순히 대규모 데이터를 모으는 것이 아니라, retrieval에 실제로 도움이 되는 reasoning을 학습할 수 있는 학습 환경을 만드는 것이라 볼 수 있습니다.
3.3 Embedder-Guided Reinforcement Learning
이제 본 논문의 가장 핵심적인 제안으로 넘어갑니다. 저자는 generative reasoning과 embedding objective 사이의 misalignment를 해결하기 위해, Embedder-Guided Reinforcement Learning(EG-RL)이라는 decoupled RL 프레임워크를 제안합니다. 이름 그대로 Embedder가 Reasoner를 guide한다는 점입니다.
앞서 관련 연구에서도 보았듯, reasoning을 embedding에 활용하려는 시도는 이미 있었지만, 크게 두 가지 문제가 반복되었습니다. 하나는 generative objective와 contrastive objective를 동시에 학습할 때 생기는 gradient conflict이고, 다른 하나는 reasoning을 embedding 목적에 맞게 충분히 정렬하지 못해 noise나 hallucination이 생길 수 있다는 점이었습니다. 저자는 이 문제를 정면으로 받아들이고, 아예 Reasoner와 Embedder를 분리하되, Embedder가 reward model처럼 Reasoner를 다시 유도하는 구조를 설계합니다.
(a) EG-RL Framework Design
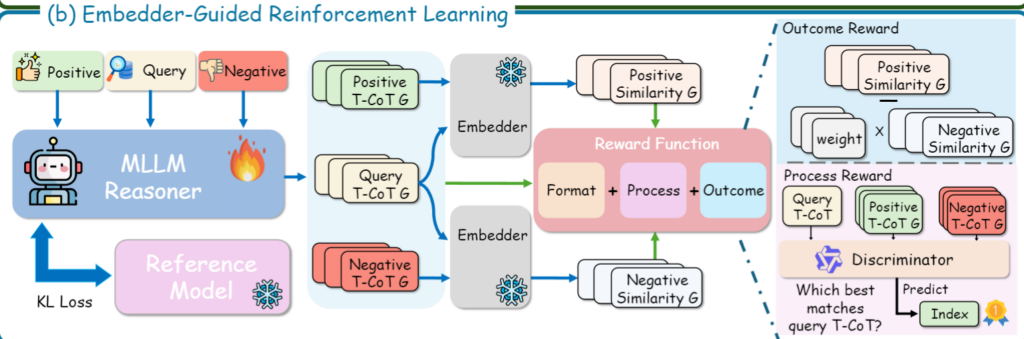
먼저 저자는 InfoNCE loss를 이용해 Embedder를 충분히 학습시킵니다. 이 단계에서 Embedder는 robust한 embedding 능력을 갖추게 됩니다. 그리고 RL 단계에 들어가면, 이 Embedder는 더 이상 업데이트하지 않고 freeze합니다. 반면 Reasoner만 policy optimization의 대상이 됩니다.
이런 decoupling이 주는 장점은 저자 기준으로 세 가지입니다. 첫째, 이미 잘 학습된 Embedder의 discriminative capability를 해치지 않고 reasoning만 따로 최적화할 수 있습니다. 둘째, freeze된 Embedder가 비교적 안정적인 reward signal을 줄 수 있습니다. 셋째, retrieval 관련 reward와 reranking 관련 reward 같은 여러 종류의 signal을 좀 더 유연하게 결합할 수 있습니다.
Reasoner는 멀티모달 query를 입력으로 받아 structured T-CoT를 생성합니다. 이 T-CoT 안에는 text keyword, image bounding box, video keyframe 같은 중요한 단서가 포함됩니다. 그리고 bounding box 내부 영역이나 keyframe을 다시 crop해서, reasoning-aware embedding을 만들 때 추가적으로 활용합니다. 이후 원래 입력과 생성된 T-CoT를 concat한 뒤, 맨 끝에<emb>토큰을 붙여 Embedder의 입력 III를 구성합니다.
수식 (2)는 이를 나타내고 있습니다.
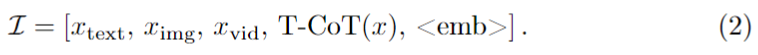
즉, 원본 멀티모달 입력 뒤에 reasoning 결과를 덧붙이고, 마지막 <emb>토큰의 hidden state를 최종 embedding으로 사용한다는 뜻입니다. 이제 임베딩은 원본 입력만 보고 만들어지는 것이 아니라, 모델이 생성한 reasoning까지 함께 보고 만들어지게 되는 것입니다. 그리고 그 결과가 좋았는지 나빴는지를 Embedder가 평가하여, 다시 Reasoner의 policy update를 유도합니다.
(b) Reward Function with Process and Outcome Guidance
이 프레임워크에서 가장 중요한 설계 중 하나는 reward function입니다. 저자는 총 세 가지 reward를 사용합니다. 하나는 형식을 맞췄는지를 보는 format reward, 하나는 retrieval 결과 자체를 보는 outcome reward, 마지막 하나는 reasoning 과정의 정렬을 보는 process reward입니다. 결국 “형식도 맞아야 하고, 결과도 좋아야 하며, 중간 reasoning도 retrieval 친화적이어야 한다”는 설계입니다.
1) Format Reward
첫 번째는 Rformat입니다. 이 reward는 T-CoT가 미리 정한 템플릿, 즉 <thinking> -> <rethink> –
> <answer> 구조를 잘 따르고 있는지, 그리고 필요한 multimodal cue를 모두 포함하고 있는지를 확인합니다. 조건을 모두 만족하면 1, 아니면 0을 줍니다.
이 reward는 단순해 보이지만 형식을 강제하지 않으면 모델이 retrieval과 무관한 장황한 설명을 늘어놓을 수 있기 때문에 interpretability와 module compatibility를 보장하기 위한 안전장치라고 볼 수 있습니다.
2) Embedder-Guided Outcome Reward
두 번째는 Routcome입니다. 이 reward는생성된 T-CoT가 실제로 embedding alignment를 얼마나 개선했는지를 retrieval 관점에서 직접 평가합니다. 저자는 이를 두 요소로 봅니다. 하나는 positive sample이 top-k 안에 잘 들어왔는지에 대한 ranking accuracy이고, 다른 하나는 positive와 hard negative 사이의 similarity margin입니다.
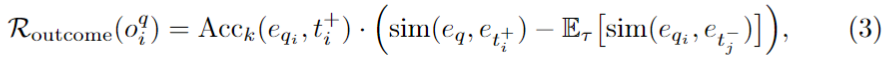
수식 (3)을 보면 조금 복잡해 보이지만 핵심은query embedding과 positive embedding의 similarity는 크게, query embedding과 negative embedding들의 similarity 평균은 작게 만들수록 높은 reward를 주는 구조입니다. 여기서 negative similarity는 softmax-weighted average로 계산되므로, 특히 query와 헷갈리기 쉬운 hard negative에 더 민감하게 반응한다고 볼 수 있습니다.
또한 이 reward는 query-to-target 방향만 보는 것이 아니라, target-to-query 방향으로도 대칭적으로 계산합니다. 즉, 정렬이 한쪽 방향에서만 잘 되는 것이 아니라 양방향에서 일관되게 좋아지도록 만든 것입니다. 표현은 길지만 결국 이 reasoning이 retrieval 성능을 실제로 좋게 만들었는가를 직접 reward로 삼는다고 이해하시면 됩니다.
3) T-CoT Process Reward
세 번째는 Rprocess입니다. 이 reward는 결과 자체보다, query와 target이 생성한 T-CoT가 과정 수준에서 얼마나 잘 align되어 있는지를 평가합니다. 이를 위해 저자는 별도의 pretrained Vision-Language Model Discriminator D를 둡니다.
구조는 query의 T-CoT 하나와, 배치 내 여러 candidate target들의 T-CoT를 셔플한 뒤 함께 넣습니다. 그리고 discriminator가 이 중 query와 가장 잘 맞는 candidate T-CoT를 고르게 합니다. 만약 ground-truth positive 집합 중 하나를 제대로 고르면 reward 1, 아니면 0입니다. 수식 (4)가 바로 이 정의입니다.
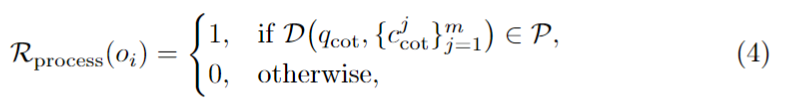
T-CoT는 embedding으로 가기 전 중간 reasoning 과정이기 때문에, query와 target의 T-CoT가 잘 맞아떨어질수록 최종 embedding 정렬도 좋아질 것이라 가정합니다. 하지만 T-CoT 정렬이 곧 embedding 성능 향상으로 얼마나 곧바로 이어지는지는 추가 검증이 더 필요할 수도 있지만, 그래도 reasoning 자체를 process-level supervision으로 보아 이 Reward로 만들었습니다.
최종 reward는 이 세 가지를 가중합한 형태입니다.
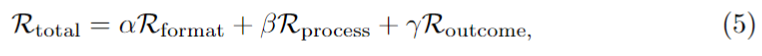
(c) Policy Optimization with GRPO
Reasoner의 policy optimization에는 GRPO를 사용합니다. GRPO는 같은 입력에서 여러 응답을 뽑은 뒤, 그 안에서 상대적으로 더 좋은 응답 쪽으로 모델을 밀어주는 강화학습 방식입니다.
여기서 저자는 각 query-target pair마다 기존 policy πθold로부터 G=8개의 candidate T-CoT를 샘플링합니다. 그리고 이 후보들에 대해 앞서 정의한 reward를 계산한 뒤, group-based advantage를 사용해 policy를 업데이트합니다.
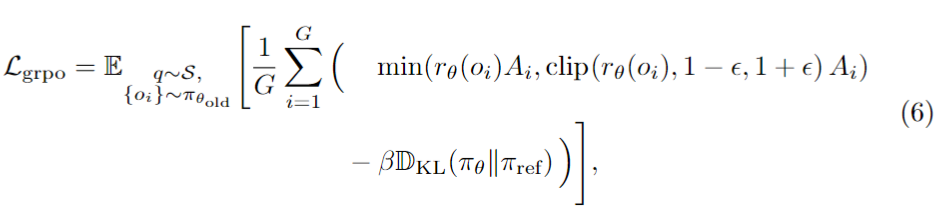
수식 (6)은 전형적인 policy optimization 형태를 따릅니다. importance ratio rθ(oi)를 계산하고 clipping을 적용해 학습을 안정화합니다. 여기에 reference policy와의 KL divergence 항도 추가해 policy가 너무 급격히 무너지지 않도록 제어합니다.
여기서 조금 눈여겨볼 부분은 advantage를 개별 reward가 아니라 group 안에서의 상대적 reward로 정규화한다는 점입니다. 즉, 같은 query-target pair에서 생성된 여러 T-CoT 후보들끼리 비교해, 어떤 reasoning이 상대적으로 더 나은지를 학습하는 구조입니다. 이 방식은 절대적인 reward scale에 덜 민감하다는 장점이 있어 RL에서 자주 쓰이는 방식입니다.
3. Experiments
저자는 Embedder는 Qwen3-VL-2B와 Qwen3-VL-4B를 사용했고, reinforcement learning 단계에서는 Qwen3-VL-8B를 Reasoner로 사용합니다. 그럼 실험 결과를 살펴보겠습니다.
Main Results
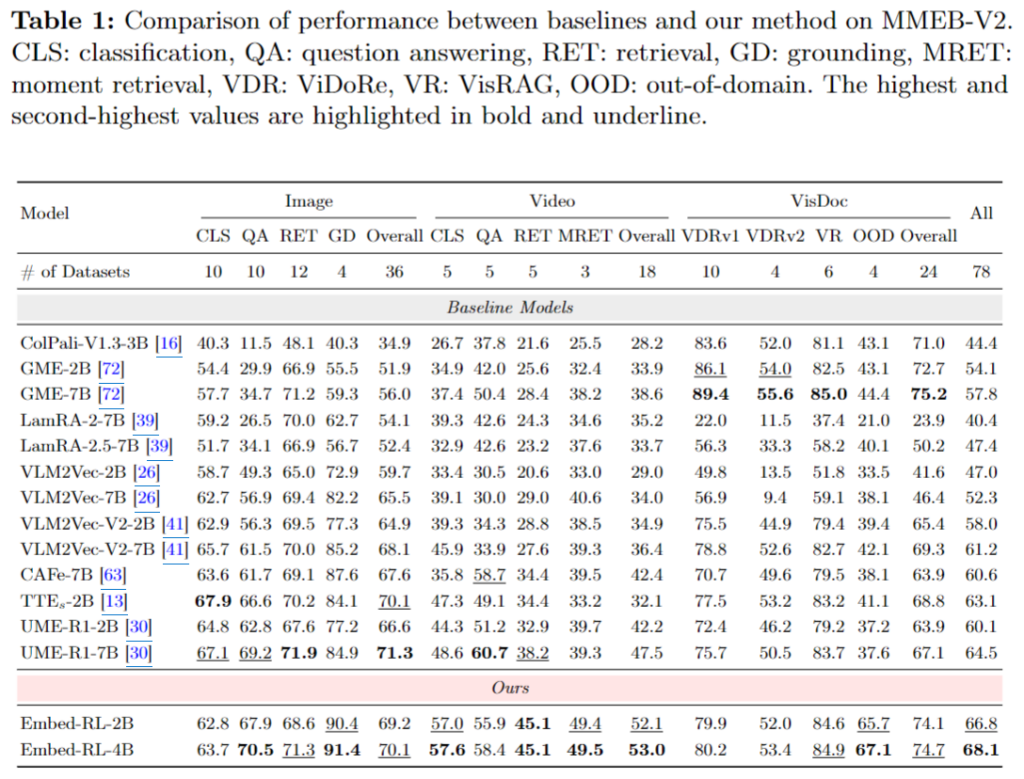
표 1은 MMEB-V2에서의 전체 성능 비교입니다. 저자가 제안한 Embed-RL 계열이 전반적으로 모든 baseline보다 더 높은 성능을 보입니다. 특히 Embed-RL-4B는 전체 점수 68.1로 가장 높은 성능을 기록했고, baseline인 UME-R1-7B보다도 3.6포인트 높습니다. Embed-RL-2B 역시 66.8로 baseline 전반을 넘는 결과를 보여줍니다.
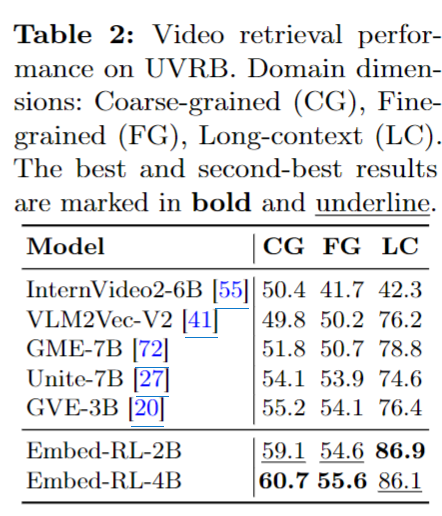
표 2는 UVRB에서의 비디오 retrieval 성능입니다. 저자는 여기서 특히 T-CoT가 keyword나 keyframe을 정확히 찾아주는 점이 성능 향상에 중요한 역할을 했다고 설명합니다. 실제로 coarse-grained, fine-grained, long-context retrieval 전반에서 Embed-RL이 강한 성능을 보입니다.
4B 모델이 coarse-grained에서 60.7, fine-grained에서 55.6으로 가장 좋고, 2B 모델은 long-context에서 86.9로 가장 높은 수치를 기록했습니다. 즉, 두 모델 모두 기존 baseline들보다 좋은 성능을 보이고 특히 비디오 retrieval은 시간적 단서와 핵심 순간을 잘 잡아내는 것이 중요한데, 저자는 이를 T-CoT가 잘 보완해준다고 해석하고 있습니다.

그림 3은 T-CoT의 시각화 결과입니다. 텍스트, 이미지, 비디오 각각에 대해 모델이 어떤 단서를 근거로 retrieval을 수행하는지를 보여줍니다. 이미지에서는 bounding box를 crop하고, 비디오에서는 keyframe을 추출해 reasoning input으로 활용하는데, 저자는 이를 통해 retrieval에 필요한 위치나 순간을 더 정확히 짚어낼 수 있다고 주장합니다.
Ablation Study
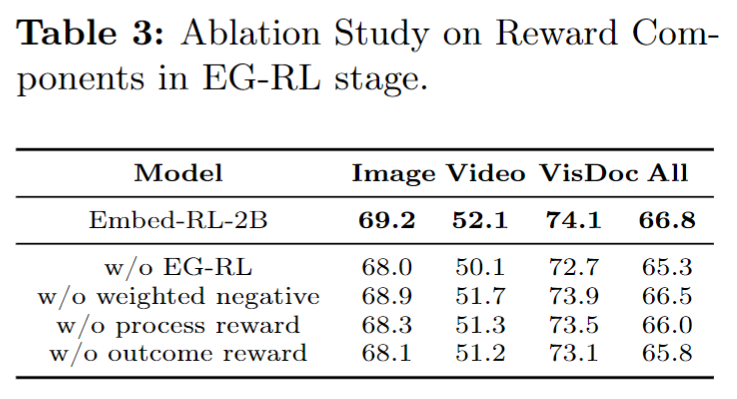
표 3은 RL stage 안의 보상 설계와 샘플링 방식이 실제로 얼마나 기여하는지를 보는 실험입니다. 먼저 RL 단계 자체를 제거하면 전체 성능이 66.8에서 65.3으로 1.5포인트 하락합니다. 또 contrastive reward에서 weighted negative sampling을 빼면 66.8에서 66.5로 0.3포인트 감소합니다. 수치상 폭은 아주 크진 않지만, hard negative를 더 잘 반영하는 설계가 분별력 향상에 도움이 된다는 점은 확인할 수 있습니다.
process reward를 제거하면 전체 성능은 66.0으로 떨어지고, 특히 비디오 태스크는 52.1에서 51.3으로 줄어듭니다. outcome reward를 제거했을 때도 65.8까지 하락합니다. process reward와 outcome reward 둘 다 의미 있는 기여를 하는데, 전자는 reasoning 과정의 정렬, 후자는 최종 retrieval 결과와의 정합성을 책임진다는 식으로 역할이 나뉘어 있다고 저자는 설명합니다. 특히 비디오에서 process reward 영향이 더 두드러지는 것은, 단계적 추론이나 시간적 reasoning이 영상 이해에 더 중요하다는 것을 알 수 있습니다.
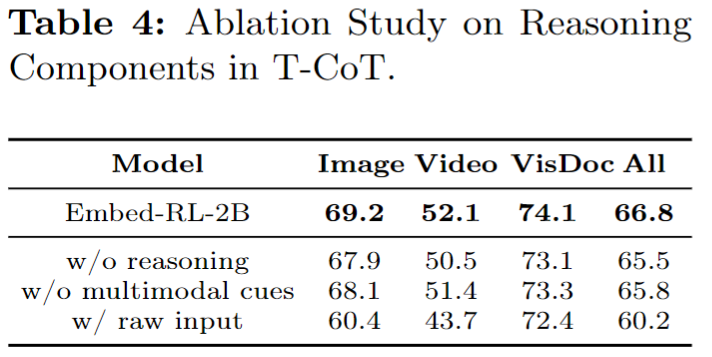
표 4는 T-CoT 내부 구성 요소의 중요도를 보는 실험입니다. reasoning process는 제거하고 answer만 남기면 전체 성능이 66.8에서 65.5로 1.3포인트 감소합니다. 특히 image grounding과 video moment retrieval에서 하락폭이 큰데 이는 단순히 정답성 있는 문장만 있는 것보다, 그에 도달하는 reasoning 과정 자체가 fine-grained alignment에 중요하다는 뜻으로 해석할 수 있습니다.
멀티모달 cue를 제거했을 때도 성능은 65.8로 떨어집니다. 즉, bounding box나 keyframe 같은 명시적인 단서를 reasoning 안에 포함시키는 것이 실제로 도움이 됩니다. 그리고 가장 큰 차이는 T-CoT 자체를 쓰지 않고 raw input만 넣었을 때입니다. 이 경우 전체 성능이 60.2까지 크게 감소하고, 비디오 태스크는 52.1에서 43.7까지 급락합니다. 저자가 왜 T-CoT를 핵심 기여로 계속 강조하는지 가장 잘 보여주는 결과라고 볼 수 있습니다.
4. Conclusion
저자는 기존 generative universal multimodal embedding(UME) 방법들이 두 가지 한계를 가진다고 정리합니다. 첫째는 CoT가 사실상 텍스트 중심으로만 이루어져 retrieval과 직접적인 관련성이 떨어진다는 점이고, 둘째는 generative objective와 embedding objective를 함께 최적화할 때 gradient conflict가 발생해 cross-modal matching을 방해한다는 점입니다.
이를 해결하기 위해 저자는 Embed-RL이라는 reasoning-driven UME 프레임워크를 제안했습니다. 핵심은 Embedder-Guided RL이라는 decoupled reinforcement learning 구조 위에, multimodal evidential Traceability CoT와 retrieval-oriented dual reward를 얹어 reasoning과 embedding이 더 정밀하게 정렬되도록 만든 것입니다.
실험 결과를 통해서 알 수 있듯이, 멀티모달 임베딩은 단순히 representation만 잘 뽑는 것으로 끝나는 것이 아니라 retrieval에 필요한 reasoning을 얼마나 목적에 맞게 설계하고 정렬하느냐가 중요하다는 것을 알 수 있었네요.
감사합니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
CoT를 활용해 embeder가 reasoning 능력을 활용한 임베딩을 수행할 수 있다고 이해했는데, 혹시 접목의 방법이 무엇인가요? 사후학습으로 CoT를 학습한 모델을 임베딩에 활용하는건가요?
둘째로 Reasoner에 대한 보충설명을 부탁드릴 수 있을까요? reasoner가 embeder에 입력을 위한 프롬프트 생성기랑 유사한 개념인지 궁금합니다..
감사합니다.
안녕하세요 유진님, 좋은 질문 감사합니다.
말씀하신 부분은 크게 보면 CoT를 임베딩에 어떻게 붙이느냐와 Reasoner가 정확히 어떤 역할을 하느냐로 나눠서 보시면 이해가 쉽습니다. 이 논문에서 CoT는 임베딩 벡터 자체가 되는 것이 아니라, 먼저 retrieval에 도움이 되는 추론 과정(T-CoT) 을 생성하고, 그 결과를 원래 입력과 함께 Embedder에 다시 넣어 임베딩을 뽑는 조건(condition) 으로 사용됩니다.
또한 Reasoner는 단순 프롬프트 생성기라기보다, 텍스트 키워드,이미지 bbox,비디오 keyframe 같은 retrieval-relevant evidence를 골라 구조화된 추론(T-CoT)을 만드는 모듈로 이해하시면 좋을 것 같습니다.
감사합니다.