안녕하세요 오늘은 RefineVQA논문을 리뷰하겠습니다.
이 논문은 VideoQA에서 질문에 맞는 비디오 설명을 반복적으로 보완해 더 정확한 답을 생성하도록 하는 방법을 제안한 연구입니다!
리뷰 시작하겠습니다.
Intro
이 논문은 VideoQA(Video Question Answering), 즉 비디오를 보고 질문에 답하는 문제를 다룹니다.

이 문제는 단순히 한 장면만 보는 이미지QA보다 어렵습니다. 해당 논문에서는 그 이유를 3가지로 설명합니다. 먼저 첫째로 비디오 내용 자체를 이해해야 합니다. 예를 들자면 해당 영상 속 사람이 무엇을 들고 있는지, 어디를 보고 있는지, 또는 어떤 물체가 등장하는 지와 같은 시각적인 정보들을 알아야 합니다.
두번째로는 질문의 문장(의도)를 이해해야 합니다. fig1의 질문으로 보자면 “왜 여자가 영상 초반에 아기를 마졌는지”와 같은 질문처럼 언제, 왜 와 같은 질문에 따라 필요한 정보가 달라집니다.
마지막으로는 시간 순서를 따라가며 추론을 해야 합니다. 비디오에서는 뭐가 먼저 일어났고 그 다음 뭐가 일어났는지가 중요합니다. 즉 ‘장면 하나’가 아니라 ‘장면의 흐름’을 이해해야 합니다.
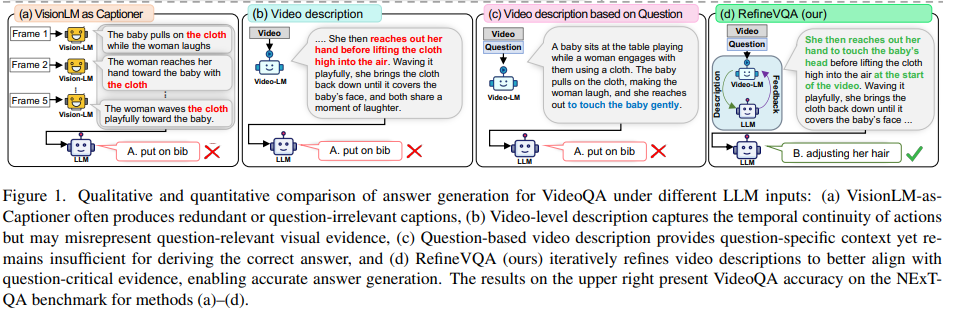
그렇다면 videoQA를 풀기위해 [기존의 방법(fig1.a)~(fig1.b)]들은 무엇이 있었는지 살펴보자면 VLM으로 비디오에서 샘플링된 프레임 각각의 캡션을 만들고 → 그 캡션을 LLM에 넣어 답을 내는 방식(fig1.a)이 많이 쓰였습니다. 해당 방법은 프레임별 캡션은 각 장면을 따로따로 설명하기 때문에 시간적인 정보가 유기적으로 연결되기에는 한계가 있다는 단점(limited temporal coherence across frames)이 있습니다.
예를 들자면 프레임별 (여성이 천을 든다), (아기가 천을 잡는다), (아기가 웃는다) 처럼 따로따로 설명은 가능하지만 ‘여성이 아기랑 놀이를 하다가 어떤이유로 손을 뻗었다’ 같은 흐름은 잘 안잡힐수가 있습니다. 즉, 프레임별 정보는 있는데 연속된 사건의 서사가 부족합니다.
또 다른 기존 방법으로는 아예 VideoLM에 여러 프레임을 뭉텅이로 한꺼번에 받아서 하나 비디오 전체 설명을 만들고 → LLM에 그 전체 문장을 넣어 답을 내는 방식(fig1.b) (or VideoLM이 바로 답까지 내는 방식)이 있습니다. 이 방식은 프레임별 캡션 방식보다 시간의 흐름을 더 잘 반영할 수 있습니다. 하지만 이 방식도 입력 가능한 프레임수가 제한적이고 어떤 프레임을 넣는지, 어떤 프롬프트를 넣는지에 따라 정보나 설명이 달라질 수 있기 때문에 질문에 필요한 세밀한 시각적 단서(fine-grained visual cues)를 놓치기 쉽습니다.
즉, 전체적인 시간적 동작이나 사건의 흐름은 직접적으로 찾아낼 수 있지만 질문에 필요한 디테일을 놓칠 수가 있습니다.
해당 논문에서 위와 같은 문제(VideoQA의 문제들과 기존의 방법들이 가지는 문제)를 “처음 만든 비디오의 설명이 부족하면 그 부족한 부분만 다시 찾아와서 설명을 고쳐쓰자!” 라는 직관적인 아이디어로 접근합니다.
간단히만 저자들이 어떻게 QA를 진행햐는지 살펴보자면,
초기 설명으로 일단 전체 설명을 만들고 → LLM이 그 설명이 질문에 답하기에 충분한지 먼저 판단합니다. → 부족하다고 판단되면 빠진 정보를 설명하는 rationale과 feedback question을 만들고 → 그 피드백 질문과 관련된 프레임을 다시 보고 추가정보를 추출해서 → 추출된 정보를 반영해 설명을 반복적으로 정제(refinement)합니다.
그럼 질문 기준으로 설명을 반복적으로 보완하는 방식으로 접근한 이유는 무엇일까요?
저자들은 videoLM을 사용하는 기존방법에 비디오 뿐만이 아닌 QA질문도 함께 넣어주어 question-specific한 설명이 생성되는지 확인하는 미니 실험을 진행했고, fic1(c)의 결과처럼 답변은 틀렸지만 이 단순한 접근만으로도 더 관련성 높은 설명과 질문에 답하기 위한 더 가까운 증거를 반영하는 결과를 확인할수 있었습니다.
이 방법의 [장점]으로 크게 3가지를 언급합니다.
기존 videoLM의 문제였던 질문이 요구하는 포인트에 집중하지 못한다는 문제를 LLM이 지금 설명으로는 질문에 답하기에 뭐가 부족한지를 따져보고 그 부족한 부분을 메우게 함으로 질문 중심으로 비디오를 다시 본다는 점 입니다.
두번째로는 videoLM으로 비디오의 전체 시간흐름을 유지(preserving temporal context)한채 세부정보를 보강한다는 점 입니다. 마지막으로는 해당 방법은 이 프레임워크를 training-free로 진행합니다. 대규모의 학습없이 기존의 VideoLM에 붙여 바로 사용함으로 이미 있는 모델의 출력을 더 똑똑하게 만드는 방식이라는 점입니다.
Method

ReFineVQA는 인트로에서 설명한 것처럼 설명 생성 자체가 목적이 아니라 답변의 정확도를 높이기 위한 설명 품질 개선이 목적입니다.
다음과 같이 총 5개로 구성된 프레임워크로 동작합니다.
초기 설명 생성(initial description) , 피드백 생성(feedback generation), 확대 설명 생성(zoom-in description generation), 반복 정제(iterative refinement), 최종 답변 생성(final answer generation)
각 프레임워크가 어떻게 동작하는지 살펴보겠습니다.
[용어 정리]
l개의 프레임으로 구성된 input비디오 V={v1~vl}
자연어로 표현된 질문 Q
후보 답변 집합(A_cands)에서 정답A를 결정. (open-ended VideoQA에는 A_cands가 없음)
1. Initial Description Generation
먼저 VideoLM을 이용하여 초기 설명을 생성하는 파트로, 비디오V에서 uniform sampling을 통해 프레임을 샘플링 하고 프롬프트와 함께 VideoLM에 입력됩니다.
여러 프레임을 동시에 입력으로 받아 V의 전반적인 흐름(동적인 action과 event정보)을 담는 비디오 수준의 초기 description(D_init)을 생성합니다.

이때 함께 입력하는 프롬프트(x_Dinit)는 이 비디오 전체 흐름을 설명해라! 정도의 VideoLM을 안내하는 프롬프트입니다.
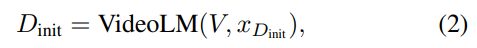
이렇게 생성된 초기 설명인 D_init이 QA를 해결하는데 필요한 정보를 다 담고 있지 않을수 있기 때문에 이 설명이 충분한지 검사하고, 부족할경우 보완하는 단계를 이어서 진행합니다.
2. Iterative Refinement of Video Description
이렇게 생성된 초기 설명인 D_init가 QA를 해결하는데 필요한 정보를 다 담고 있지 않을수 있기 때문에 이 설명이 충분한지 검사하고, 부족할경우 보완하는 반복적 정제(iterative refinement)단계를 이어서 진행합니다.
[Feedback Generation]
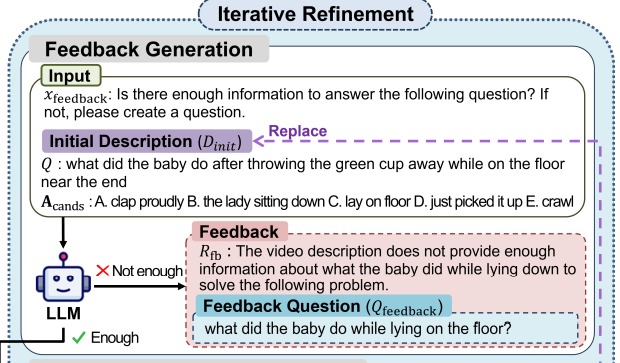
그럼 D_init에서 뭐가 빠져있는지를 추론해야하는데 이때 LLM을 활용합니다.
D_init, Q, A_cands, 피드백 프롬프트(x_feedback), few-shot예시(E_feedback)를 입력으로 받아 LLM이 D_init이 충분하지 않다고 판단할 경우 현재 설명에서 뭐가 부족한지를 설명하는 근거(R_feedback)를 출력하고 그 부족한 정보를 찾기위한 피드백질문(Q_feedback)을 생성합니다.
즉 부족한 점을 근거로 삼아 정확히 무엇을 더 봐야하는지가 담긴 피드백 질문을 만듭니다. 이 두 출력은 다음 반복때 비디오 description을 정제하는데 사용됩니다.

만약 이때 LLM이 D_init에 설명이 충분(Enough)하다고 판단할 경우 바로 최종 답변 생성(final answer generation)로 넘어갑니다!
[Zoom-in Description Generation]
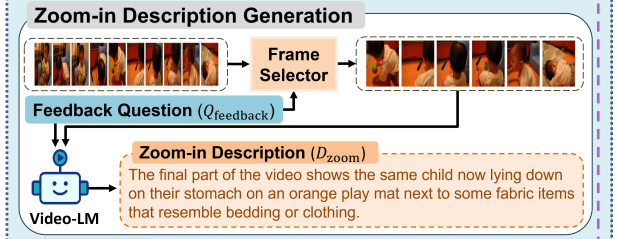
앞에서 출력된 Q_feedback(Q_fd)와 VideoLM을 사용해 추가 정보를 포함한 확대설명(D_zoom)을 생성하는 단계입니다. 이때의 핵심은 Q_fd을 사용하여 D_init에 들어있지 않았던 정보를 추출하는 것 입니다.
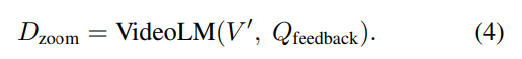
따라서 이때는 V에서 프레임 선택기(frame selector,FS)를 통해 다시 프레임을 선택(V’)해야하는데, D_init때 처럼 uniform sampling대신 적응적 프레임 선택 전략(adaptive frame selection strategy)을 사용합니다.
FS(ϕ)는 Q_fd와 프레임들 간의 매칭 점수 s를 계산합니다.
이때 이 FS는 caption-based 방식이나 image-based 방식으로 구현되는데,
먼저 caption-based 방식은 pretrained text encoder를 사용하여 Q_fd과 캡션간의 text-to-text 매칭을 수행합니다.
다음으로 image-based 방식은 CLIP같은 pretrained vision-language encoder를 사용하여 프레임과 Q_fd간의 image-to-text매칭을 수행합니다. 이 FS를 통해 나온 매칭 점수는 해당 프레임이 Q_fd와 관련된 시각적인 증거를 포함할 가능성을 반영하는 점수입니다. (s_t=ϕ(Q_fd, v_t))
모든 프레임은 이 매칭점수에 따라 순위를 매기고 상위 N개의 프레임이 선택되어 zoom-in 비디오 프레임 V’를 구성합니다.
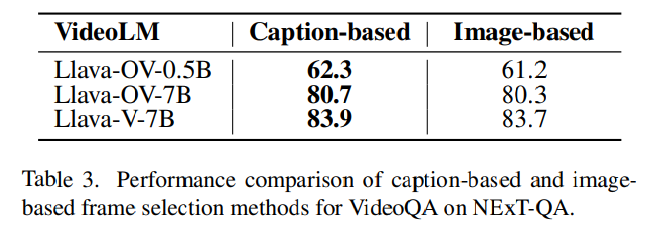
저자들은 두 FS접근법은 trade-off 구조라고 언급합니다.
table3에서 확인할수 있다 싶이 caption-based 방식이 image-based 방식보다 높은 성능을 보입니다. 그 이유를 caption-based 방식은 텍스트 표현을 활용하기 때문에 매칭에 있어서 Q_fd와 alignment가 더 잘 맞기 때문이라고 설명합니다 . 하지만 이 방법은 프레임을 한번 더 캡션화 해야하는 추가 계산비용이 들기 때문에 처리속도 측면에서의 효율은 낮다고 언급합니다.
[Refinement]
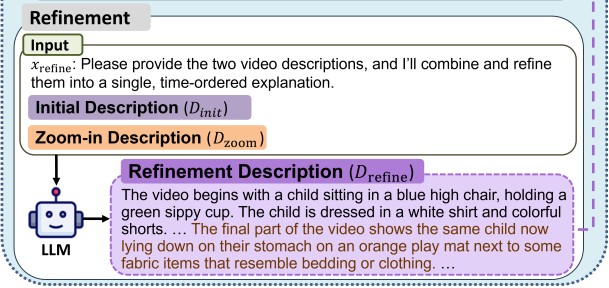
앞서 만든 D_zoom은 Q_fd와 관련된 추가 정보를 담고 있긴 하지만 전체 흐름을 보려고 만든 설명이 아닌 관련 프레임들 만으로 만든 설명이기 때문에 temporal grounding(해당 정보가 비디오의 어디 시점에서 나온건지)이 부족합니다.
따라서 LLM을 사용해 D_zoom의 추가정보를 D_init의 시간적 흐름안에 통합해줌으로 global context를 유지하면서도 Q에 결정적으로 중요한 국소적인 증거를 담을수 있게 정제해줍니다. (이때 x_refine은 정제를 지시하는 프롬프트이고, E_refine은 few-shot예시를 말합니다.)
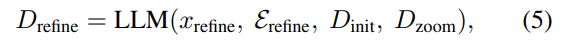
이렇게 정제된 설명 D_refine은 다시 Feedback Generation단계로 D_init을 대체하여 들어가고, 정보가 충분하다고 판단될 때까지 이 과정을 반복합니다.
3. Answer Generation

마지막으로는 Feedback Generation의 LLM이 Enough(이제 답할수 있다!)라고 판단한 설명을 D_final로 지정하고 이 description을 바탕으로 LLM이 최종 A 추론을 수행합니다.
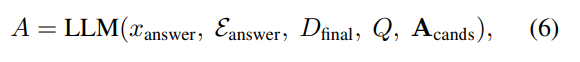
이 단계에서는 본 질문 Q를 LLM의 입력으로 제공하여 충분히 정제된 최종설명 D_final을 바탕으로 답변A 생성합니다. (x_answer는 QA를 지시하는 프롬프트이고, E_answer는 답변 과정을 보여주는 예시들입니다.)
이러한 프레임워크는 왜 그런 답을 냈는지 중간 설명들이 남아있기 때문에 블랙박스식의 end-to-end보다 더 설명이 가능하다는 장점이 있고, 이미 설명이 잘 정리돼 있기 문에 비교적 작은 LLM(3.8B정도)으로도 안정적인 성능을 보일 수 있습니다.
Experiment
1. Performance on VideoQA
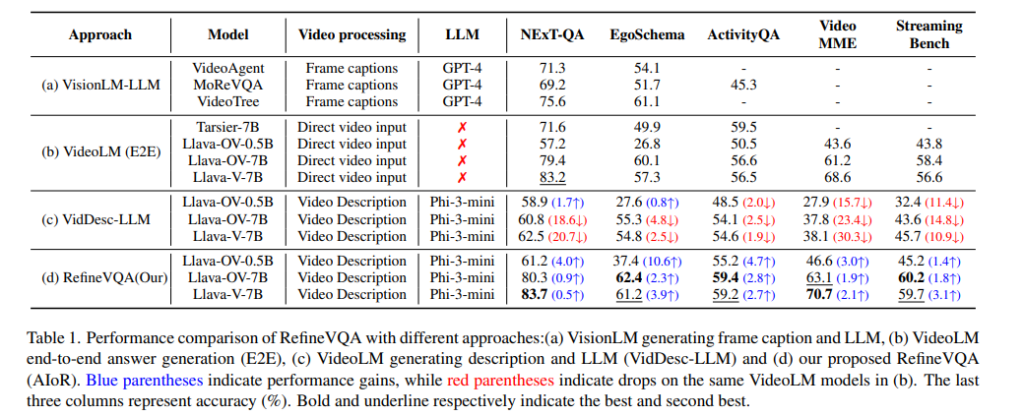
NExT-QA, EgoSchema, Activity-Net, Video-MME, StreamingBench 벤치마크에서 기존 접근법들과 비교실험을 진행했습니다. table1과 fig1의 각각의 방법들을 먼저 설명하자면
(a)는 visionLM으로 프레임별 캡션을 생성하고 이를 LLM이 처리하는 방식,
(b)는 videoLM이 end-to-end로 바로 답변까지 생성하는 방식,
(c)는 videoLM이 비디오 레벨의 설명을 생성한 뒤 LLM이 답을 내는 방식,
(d)는 저자들이 제안하는 방식으로 구성되어 있습니다.
GPT4같은 대형 LLM대신 더 작은 LLM(Phi-3-mini(3.8B))을 사용하는 RefineVQA가 VisionLM 캡셔너 접근법(a)보다 우수한 성능을 보이는 것을 확인할수 있습니다. 하지만 이 비교는 videoLM의 비디오 이해 능력 덕분일수 있기 때문에 저자들은 (b)와 RefineVQA(d)를 비교합니다.
먼저 Llava-0.5B와 비교했을때 다섯개의 벤치마크 모두에서 성능향상을 보였습니다.
뿐만아니라 여기서 videoLM모델을 Llava-OV-7B와 Llava-V-7B로 올렸을때도 일관되게 성능이 향상되는 것으로 단순히 좋은 videoLM모델을 썻기 때문이 아닌 저자들이 제안한 iterative refinement방식이 효과적임을 확인할 수 있습니다.
다음으로 (c)의 지표를 살펴보자면 (b)에 비해 성능이 하락한 것을 볼수 있습니다. 특히나 video-MME나 StreamingBench같은 롱폼 비디오 데이터셋어서 하락폭이 두드러지는데, 저자들은 이 이유를 설명은 만들었지만 초기 설명만으로는 질문에 필요한 정보가 충분히 담기지 않았기 때문이라고 이 초기설명을 LLM이 받아도 답에 필요한 근거가 부족하기 때문에 이러한 결과가 나왔다고 말합니다.
2. Performance Improvements Across Refinement Iterations
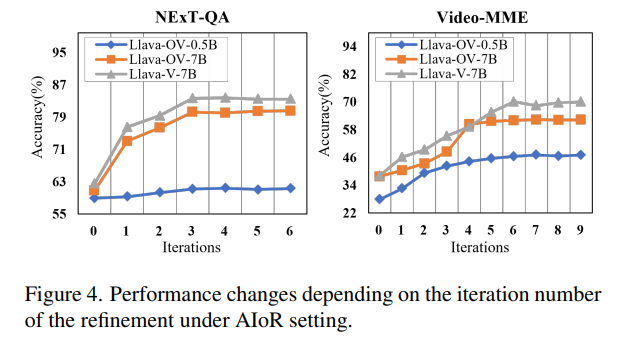
fig4는 저자들이 제안한 refinement방식인 Autonomous Iteration of Refinement (AIoR)를 진행할때 각 반복 단계마다 성능이 어떻게 향상되는지를 확인한 실험입니다.
NExT-QA에서는 한번의 정제만으로도 모든 모델이서 성능향상이 일어났고, 더 긴 비디오를 포함하고있는 Video-MME에서는 세번째 반복부터 두드러지는 성능향상을 볼수 있습니다.
이를 통해 반복이 거듭될수록 복잡한 비디오에서 필요한 정보를 더 잘 추출할 수 있다는 것을 간접적으로 확인할 수 있습니다.
NExT-QA에서는 3번정도 이후 성능이 후렴하고 Video-MME는 6번 이후부터 수렴하는데 이는 긴 비디오일수록 추가반복이 필요하고 refinement 수렴도 더 느리다는 것을 의미합니다
3. Generalizability of Proposed Method
저자들은 일반화 가능성과 강건성을 확인하기위해 해당 method를 다른 videoLM(tabel4)과 LLM(table5)을 사용하여 실험을 진행했습니다.
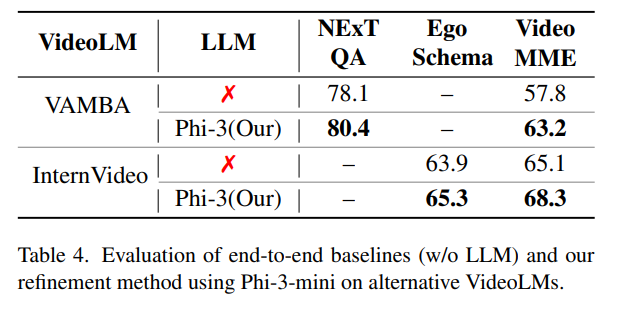
먼저 다른 VideoLM으로 바꿔도 효과가 있나?를 확인해보기 위해 Llava가 아닌 다른 videoLM(VAMBA, InternVideo2.5)을 사용한 실험결과(table4) end-to-end방식과 비교하여 저자들의 LLM을 활용한 refinement방식이 일관되게 좋은 성능을 보임을 확인할 수 있습니다.
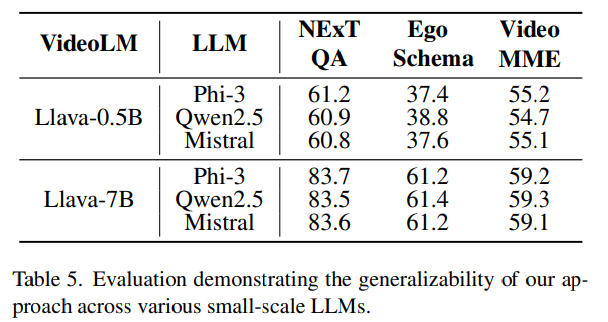
다음으로 다른 LLM으로 바꿔도 효과가 있나?를 확인해보기 위해 서로 다른 3가지 small scale의 LLM을 사용하여 실험해 본 결과(table5) Phi-3, Qwen2.5, Mistral로 바꿔도 Phi-3의 성능과 크게 차이나지 않는 것을 확인할 수 있습니다.
즉, 특정 LLM에 종속된 결과가 아닌 small scale의 LLM이여도 일관되게 성능이 유지된다는 것을 확인할 수 있습니다.
(하지만 large LLM와의 비교 실험이 비어있어서 LLM의 scale에 관련없다 까지로 해석하기 보다는 작은 LLM으로도 된다 까지를 보이는 실험인 것 같습니다)
conclusion
논문을 읽으면서 반복 정제에 대한 비용측면은 괜찮은가? 에 대한 의문이 있었는데, 저자들이 결론 부분에서 반복적 refinement로 인해 계산 비용과 복잡성이 증가한다는 한계를 인정한다고 언급합니다. 그럼에도 제안하는 RefineVQA는 training-free 프레임워크로 기존 videoLM에 붙여서 별도의 학습없이 성능을 올릴수 있는 구조라는 점에서 실용적인 측면의 장점이 꽤 크다고 볼수 있습니다. 또한 end-to-end VideoLM방식처럼 왜 그런 결과가 나왔는지 중간과정을 알수 없는 blackbox의 성격이 아니라 video understanding과정을 더 설명 가능하게 만들어 준다는 점 역시 중요한 장점이라고 생각합니다!
좋은 리뷰 잘 읽었습니다. RefineVQA는 먼저 비디오 전체에 대한 초기 설명을 만들고, 이후 부족한 부분만 보완하는 구조라고 이해했는데요.
특히 caption-based frame selection이 image-based보다 성능이 더 좋았다는 결과 관련해서 궁금한 점이 생겼는데요.
설명대로라면 Q_feedback이 텍스트이기 때문에 텍스트-텍스트 정렬이 더 잘 맞는다는 것 같은데, 그렇다면 이 결과는 결국 frame selection에서 시각적 유사도보다 언어적 alignment가 더 중요하다는 해석으로 봐도 되는지 궁금합니다! 그리고 이게 비디오 QA 일반의 성질인지, 아니면 이 프레임워크 구조에서만 특히 그런 건지도 궁금하네요1
안녕하세요 주영님 리뷰 읽어주셔서 감사합니다!!
네! 해당 논문에서는 frame selection 단계에서는 그렇게 해석합니다. 하지만 이것을 videoQA에서 항상 언어적인 alignment가 중요하다고 일반화 하는것은 어렵습니다
이 방법 차제가 애초에 Q_feedback 이라는 텍스트 질문에 맞는 프레임을 찾는 구조이기 떄문에 이 설정에서는 텍스트와의 정렬이 특히 중요하게 작동한 것이라고 볼 수 있습니다.
안녕하세요 찬미님 좋은 리뷰 감사합니다
수정 iteration 관련하여 질문이 있어서 댓글 남깁니다
재방문/재검토 iteration을 무한대로 반복하면 직관적으로는 성능이 우상향/수렴 할 것 같습니다.
이때 수렴의 속도, 혹은 수렴의 최대범위가 어떠한 원인으로 결정되는지 분석이나 언급이 있었는지 궁금합니다.
하나 더 궁금한 점은 반복횟수와 연산량의 상관관계를 어떻게 언급하고 있는지 궁금합니다.
혹시 해당 논문의 리뷰에는 반복 횟수 증가로 인한 연산량 증가에 대한 언급은 없었나요?
감사합니다
안녕하세요 유진님 리뷰 읽어주셔서 감사합니다!
1. 일단 수렴 속도를 좌우하는 원인으로 직접적으로 언급한 부분은 비디오 길이와 복잡성에 따라 다르다고 fig4부분에서 그래프와 함께 두 벤치마크 비교로 분석한 부분입니다. 해당 부분에서 짧은 비디오는 더 빠르게 수렴하고 길고 복잡한 비디오는 추가 반복이 필요하기 때문에 더 느리게 수렴한다고 분석했습니다.
2. 횟수와 연산량의 상관관계는 conclusion 에서 반복적인 refinement과정으로 인해 계산 비용 측면에서의 연산량 한계를 인정한다! 라고 하는 정도로만 언급하고 넘어갑니다! (뭔가 서플에 관련 실험이 있을것 같기한데 서플이 아직 비공개라!..)
안녕하세요 찬미님 좋은 리뷰 감사합니다!
주제가 흥미로워서 읽다보니, 질문이 생겨서 댓글 남깁니다.
LLM이 Description을 보고, 충분(Enough)하다고 판단하는 기준이 혹시 있을까요?
예를 들어, LLM이 decription을 보고, A_cand 내에서 A를 생성할 수 없다면, 충분하지 않다고 판단하는 것일까요?
혹시 그렇다면, open-end VideoQA에서도 적용이 가능한지 궁금합니다!
감사합니다.
안녕하세요 희승님 댓글감사합니다!
Q1. 충분(Enough)하다고 판단하는 기준
명시적인 기준이 따로 있는것은 아니고 LLM이 현재 description안에 정답을 낼 만큼 충분한 정보가 있는지를 프롬프트 기반으로 스스로 판단합니다!
Q2. open-end VideoQA에서는?
Q1에 이어서 그렇기 때문에 open-end VideoQA에서도 정답 후보군 없이 현재 description만으로 질문에 답할 만큼 충분한지를 LLM이 프롬프트 기반으로 판단하는 동일한 방식을 적용 할수 있습니다!
안녕하세요 찬미님, 좋은 리뷰 감사합니다.
결국 비디오의 프레임을 기반으로 캡션을 생성해서, 이걸 VLM에 넣고 추론을 시킨다는 파이프라인을 그대로 따르는 방법이라고 생각됩니다. 이러한 캡션 기반 추론 방법론의 한계점 중 하나는 ‘비디오의 시각적인 디테일까지 표현하기 힘들다’라고 생각하는데, 논문에서 이런 한계점에 대한 견해를 밝힌 부분이 있는지 궁금합니다.
안녕하세요 재윤님 댓글 감사합니다.
네! 논문에서 이 한계를 직접 언급합니다 VideoLM 기반 description은 시간적 흐름은 잘 담을 수 있지만 제한된 입력 프레임 수와 프롬프트 의존성 때문에 질문에 필요한 fine-grained visual cues를 놓칠 수 있고 또 그러다보니 중요한 프레임을 놓치면 세부 동작 정보까지 충분히 반영되지 못할 수 있다고 언급합니다. 그래서 저자들은 LLM feedback으로 부족한 정보를 다시 보완하는 ReFineVQA를 제시한 거라고 보면 됩니닷!