안녕하세요. 이번에 들고온 논문은 LLM 을 서빙할때 KV cache 메모리 관리의 비효율을 어떻게 해결할 것인지를 다룬 논문입니다. 저희 연구실 사람들이 이런 메모리 관리 측면의 OS 연구를 진행하지는 않지만 해당 논문의 방법론을 사용하면 LLM을 사용할때 여러 요청을 동시에 처리해야하는 상황에서의 병목을 줄일 수 있어서 가져왔습니다. 좀 이전 논문이라 최근 방법론들이 (특정상황에서) 더 빠른 속도를 내는 것들이 있는거로 확인되는데, 논문 1저자가 한국인이기도 해서 들고왔습니다.
https://github.com/vllm-project/vllm
Abstract
저자들은 먼저 대형 언어모델들을 높은 처리량으로 서빙하려면 많은 요청을 한번에 배치해야한다고 합니다. 기존 시스템들은 각 요청마다 필요한 KV cache가 매우 컸습니다. ( 요청마다 생성해야할 문장의 길이를 알 수 없기에 가장 큰 KV cache를 미리 할당하는 방식이기 때문) 이러한 비효율적인 메모리 방식에는 배치 사이즈도 제한적이고 처리량도 낮아질 수 밖에 없습니다.
이 문제를 해결하기 위해서 저자는 PagedAttention 이라는 새로운 어텐션 방식을 제안합니다. 이 방식은 운영체제의 가상 메모리와 paging 아이디어에서 영감을 받았고, KV cache를 연속된 메모리 덩어리로 보관하는 대신 고정 크기 block 단위로 나누고, 이를 비연속적인 물리 메모리에 저장할 수 있도록 합니다. (저희가 흔히 아는 attention을 새로운 방식으로 제안했다기보다 Attention 매커니즘 시 생성되는 KV캐시를 시스템적으로 관리하는 기법을 칭하는 것입니다.) 운영 체제에서 페이지는 가상 메모리를 관리하기 위해 사용하는 고정된 크기의 논리적 메모리 블록을 의미합니다.
저자가 주장하는 핵심 장점은 두 가지 입니다.
- KV cache memory waste 를 0에 가깝게 줄임
- KV cache를 요청 간 / 시퀀스 간 유연하게 공유 가능
실험 결과로는 기존 SOTA 서빙 시스템들 대비 같은 latency 수준에서 2배~4배 정도의 처리량 향상을 보였다고 합니다. 특히 긴 시퀀스, 큰 모델, 복잡한 디코딩 알고리즘을 사용할수록 개선 폭이 커졌다고 합니다. 즉 LLM의 서빙 병목이 연산만의 문제가 아니라 메모리 관리의 문제이고 그걸 OS에서 사용하던 paging 으로 풀면 처리량을 크게 높일 수 있다고 이해하면 됩니다.
Introduction
저자들은 LLM 서비스의 현실적인 문제를 언급하는데, GPT 나 PaLM 같은 대형 언어모델이 코딩 어시스턴트, 챗봇 같은 다양한 응용을 가능하게 했지만, 실제로 이런 서비스를 운영하는 비용이 매우 큽니다. 논문에서는 LLM 요청 처리 비용이 전통적인 쿼리 검색보다 비쌀 수 있다고 언급하면서 결국에는 serving 처리량을 높여 요청당 비용을 낮추는 것이 중요하다고 합니다.
문제는 LLM 의 autoregressive 한 생성 방식 특성상 토큰을 하나씩 순차적으로 생성하기에, 어떤 질문이 들어왔을때 실제로 생성될 문장의 전체 길이를 알 수 없어, 모델이 최대 2048 토큰을 내뱉는다면 실제로 10토큰이 생성되더라도 일단 2048 토큰 분량의 연속된 VRAM 공간을 할당합니다. 이러한 Static Allocation 방식은 Batch size가 커졌을때 연속된 빈 공간이 존재하지 않아 OOM(Out of Memory) 가 뜰 확률이 늘어나게 됩니다.

논문 figure 1에서 설명하는 부분을 보면 우선 13B 모델을 A100 40GB GPU 에 올릴 때 26GB는 모델의 파라미터가 차지하게 되고, 그 다음 상당한 비중을 KV cache가 차지하여 실제 모델을 올릴 때 병목이 모델의 weight보다는 요청 별 KV cahce를 어떻게 저장하고 관리하는지에 더 가깝다는 것입니다.
우측 위의 graph 를 보면 기존 방식에서 contiguous 한 방식으로 momory를 저장하기 때문에 두 가지 문제점이 생긴다고 합니다.
- Fragmentation
- Memory Sharing 불가
먼저 fragmentation 을 보면, 요청마다 최대 길이를 기준으로 미리 큰 청크를 잡아두다 보니 실제로는 사용되지 않는 공간이 많아집니다. 그리고 요청 길이가 제각각이기 때문에 external fragmentation도 커진다고 합니다.
여기서 external fragmentation을 예시로 설명을 드리겠습니다.
- 요청 A,B,C가 들어와서 메로리를 순서대로 점유
- 요청 B가 생성을 먼저 마치고 완료
- 그 자리에 빈 구멍이 생김
- 새로운 요청 D가 들어왔는데 B가 나간 구멍보다 조금 더 큰 경우
- 메모리 뒤쪽에 자리가 있더라도 연속된 공간에만 할당이 되므로 메모리가 텅텅 비어 보이는데 OOM 이 뜨거나 새로운 요청을 거절하게 되는 현상
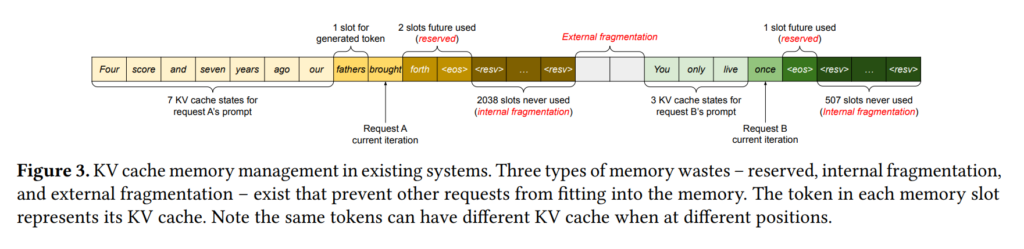
논문에서는 기존 시스템에서 실제 token state 저장에 쓰이는 메모리 비율이 20.4%~38.2% 수준에 불과하다고 분석합니다.
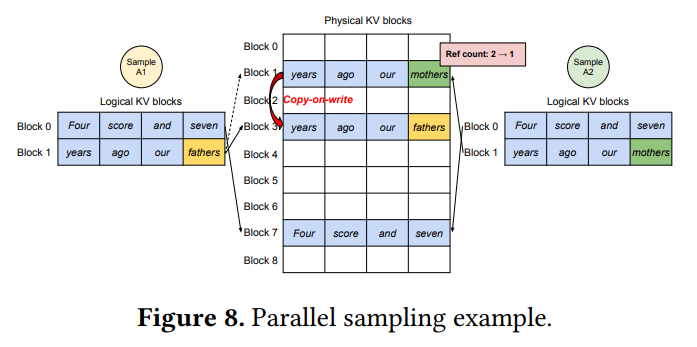
또 다른 문제였던 Sharing은 parallel sampling 이나 beam search 처럼 하나의 프롬프트에서 여러 ouput sequence 를 생성할 때는 프롬프트 부분의 KV cache 를 공유할 수 있어야 메모리 낭비를 절약할 수 있는데, 기존 방식은 요청별로 KV cahce를 따로 연속적으로 들고 있어 이 공유가 어렵습니다.
그래서 저자들은 운영체제의 virtual memory처럼 KV cache를 page처럼 block 단위로 나누고, 논리적 block 과 물리적 block을 분리하는 PagedAttention 을 제안합니다.
이 설계를 통해 작은 block 단위의 allocation이 가능해지고, 위에서 언급한 external fragmentation도 제거되며 block 단위의 sharing이 가능해진다고 합니다.
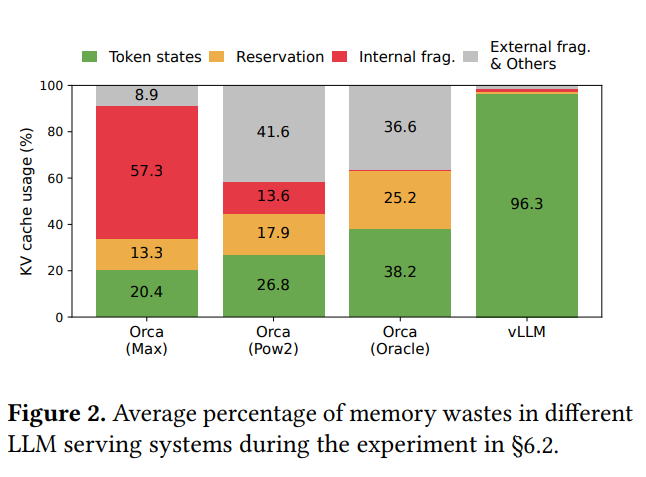
해당 figure는 위에서 언급한 실제 사용되는 메모리 비율입니다.
Background
논문은 background에서 먼저 Transformer 기반 LLM 과 serving 과정을 간단히 다시 짚습니다. 트랜스포머가 self-attention을 통해서 이전 토큰들의 key/value를 참고하면서 다음 토큰을 생성하는데, serving 시에는 이전 토큰들의 key/value를 매번 다시 계산하지 않기 위해 KV cache를 저장해둡니다. 이 KV cache는 generation이 진행될수록 계속 커집니다. 저자들은 serving 단계를 크게 두 단계로 나눕니다.
- prompt phase
- 입력 prompt 전체가 주어져 있어서 병렬 계산이 가능
- autoregressive generation phase
- 토큰을 하나씩 순차적으로 생성해야 해서 비효율적이고 momory-bound가 되기 쉬움
Method
PagedAttention
기존 attention은 KV cache가 연속 메모리에 있다고 가정하는데, PagedAttention은 비연속 메모리에 저장된 KV block들을 읽어 attention을 계산할 수 있도록 설계됩니다. 즉 KV cache를 token 단위로 길게 이어진 배열처럼 보는 것이 아니라, 고정 길이 B의 block들로 쪼개서 관리합니다.
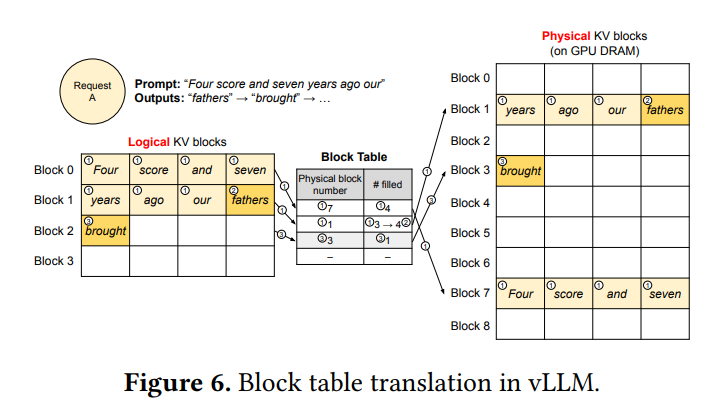
다시 말해 logical block 과 physical block을 분리하여 사용하고 논리적으로는 시퀀스가 연속된 블록들로 이루어져 있지만, 실제 GPU 메모리에서는 이 block들이 여기저기 흩어져 있어도 됩니다. attention kernel이 block table을 보고 필요한 physical blcok을 찾아가며 연산합니다.
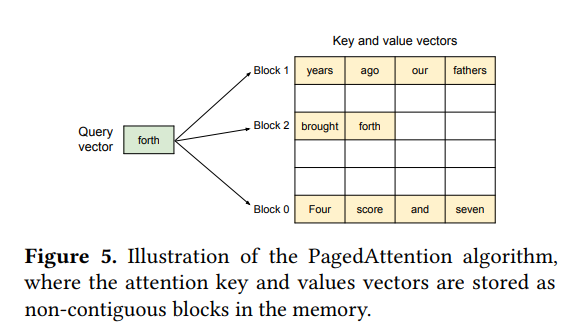
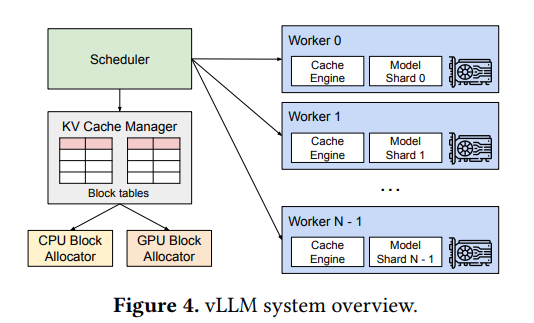
KV cache manager
vLLM은 운영체제의 virtual memory와 유사한 방식으로 KV cache를 관리합니다.
각 요청의 KV cache는 logical KV block들의 연속으로 표현되고, 실제 GPu DRAM 에는 physical KV block 들이 따로 존재합니다. block table로 둘을 매핑하고 block table entry에는 해당 logical block이 어느 physical block에 매핑되는지, 그리고 그 안에 몇 칸이 채워져 있는지를 기록합니다. 이렇게 되면 미리 최대 길이만큼 할당할 필요가 없어지고 생성이 진행되면서 필요한 block 만 추가로 할당해주면 됩니다. 요청이 끝나면 block을 즉시 반환해서 사용하여 기존 방식의 reservation / fragmentation 문제를 거의 제거할 수 있습니다.
Other Decoding Scenarios
저자들은 위에서 보여준 단순 greedy decoding (가장 높은 확률 1개만 선택하며 골라가는 방식) 뿐만 아니라 여러 시나리오에서 디코딩 방식도 잘 처리된다고 강조합니다.
Parallel Sampling
Beam search
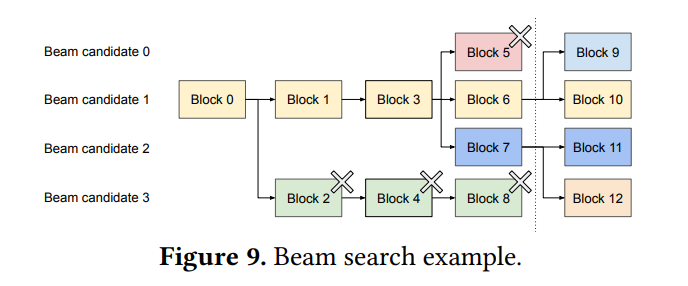
해당 figure는 beam search에서의 저자의 방법론 그림으로 우선 beam search는 위에서의 greedy 방식이 아닌 상위 K 개를 들고가면서 정답을 찾아가는 방식입니다. 기존 시스템에서는 beam candidate 간 KV cache를 복사해서 사용했지만, 저자의 방법론은 갈라지기 전까지는 공유하는거로 이해하면 될 것 같습니다.
Evaluation
실험에서는 OPT 13B,66B,175B 와 LLaMA 13B를 사용했고, A 100 GPU 환경에서 평가합니다. 데이터셋은 실제 LLM 서비스 대화 길이 분포를 반영하기 위해서 ShareGPT와 Alpaca를 기반으로 synthetic workload를 구성했다고 합니다. ShareGPT는 입력과 출력이 더 길고 분산이 크다고 하네요.
Baseline은 크게 FasterTransformer와 Orca 입니다.
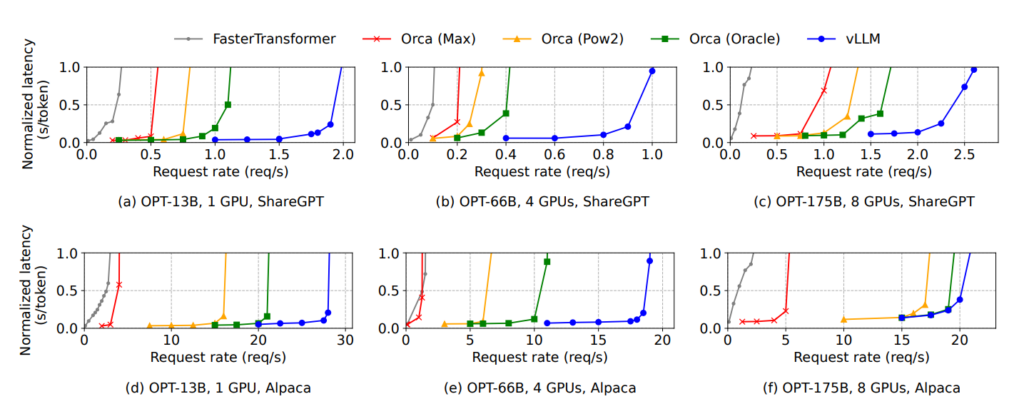
이 그래프는 서버가 얼마나 많은 요청을 견디면서 빠른 속도를 유지하는지를 보여줍니다.
Request Rate는 초당 요청 수를 의미하여 1초에 사용자가 얼마나 많은 질문을 던지는지를 나타내고 Y축은 토큰당 지연 시간으로 글자 하나를 만들어내는데에 걸리는 시간으로 이해하면 됩니다. 그래프에서 갑자기 치솟는 부분은 처리의 한계점으로 GPU 의 메모리나 연상 능력이 꽉 차면 대기 시간이 생겨버리는 상황이라고 이해하면 됩니다.
Conclusion
Page 라는 운영체제에서 쓰이는 방식을 vLLM이라는 이름으로 serving system 을 구현한 논문입니다. 일반적으로 LLM inference를 quantization이나 pruning 또는 디코딩 방식으로 속도 개선을 시키는거로 알고 있었는데, 계산은 잘하고 있고, 메모리 관리의 문제를 지적하며 시스템 효율을 개선했다는 점과, 실제 서비스화해서 제공하고 있다는 점이 contribution인 것 같습니다.
감사합니다.
안녕하세요 인택님 리뷰 감사합니다!
예전에 트랜스포머 공부할때 kv cache에 대해 가볍게 공부하고 휙 지나갔었는데 리뷰해주신 덕분에 kv cache 꽤나 중요하구나~! 하고 인지하게 되었습니다
운영체제의 paging 아이디어가 낯설다 보니 저 블록이라는 역할이 잘 와닿지 않아 질문드립니다
기존방식의 문제점 중 두번째인 KV cache가 sharing이 불가한 부분을 블록단위로 나눔으로 블룩단위의 공유가 가능해진다고 하셨는데, 이 로지컬과 피지컬 블록을 구분해서 로컬이 필요한 피지컬 블록을 참조하게 함으로 공유가 가능해진다 라는 맥락으로 이해하면 되는걸까요??
안녕하세요 찬미님 답글 감사합니다.
올바르게 이해하신 것 같습니다. 기존에는 동적으로 불필요한 크기의 고정 메모리를 할당해줬다면, 그거를 블록 단위로 쪼개서 원하는 크기만큼만 참조가 되도록 하여 메모리 효율을 높였다고 생각하시면 됩니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다!
작년에 운영체제를 꽤 재밌게 들었어서 그때 생각도 나고 또 새로운 관점의 논문이라 재미있게 읽었습니다. KV cache 메모리 관리의 비효율 문제가 있다는 것도 처음 알았네요.
paging 방식은 external fragmentation 문제를 효과적으로 해결할 수 있지만, table 접근과 실제 데이터 접근 총 두번의 메모리 접근이 발생하는 것 같은데, 이렇게 접근 횟수가 두배로 늘어나는 것은 성능에 큰 영향이 없을까요?
안녕하세요 예은님 답글 감사합니다.
음 사실 예은님이 언급하신 것처럼 추가적으로 계산이 되어야하는 부분도 분명히 존재합니다. 실제로 논문도 이부분을 무시하지는 않고 블록 테이블 참조나 비연속적인 block 을 접근하고 variable 한 length 를 처리해야하는 추가 오버헤드는 분명히 존재해서 단일 연산만 놓고 보면 더 느릴 수도 있습니다. intro에서 저자가 언급했듯이 LLM serving 의 관점에서 전체 시스템의 처리량을 올리는 것을 목표로 하기에, 여러 batch의 작업이 동시에 들어올 경우에는 속도 향상 이점이 분명한 것 같습니다. 실제 사용자가 저자의 vLLM의 처리 속도를 분석한 유투브 영상을 보았는데, 여러 요청이 동시에 들어오는 경우 기존 방식 대비 3배정도 빨라지는 효과를 보입니다.
감사합니다.
안녕하세요 신인택 연구원님 좋은 리뷰 감사합니다.
vLLM 작동방식도 모르고 빠르다고하니 써보고 했었는데, 다뤄주셔서 흥미롭게 읽었습니다. 연속적으로 메모리를 할당하는게 아니라 미리 고정된 크기의 블록을 할당해서 캐싱해두는 방법으로 이해했습니다. 혹시 놓친 부분 있다면 알려주세요.
빔 서치가 상위 K개를 가져가면서 상위 K개를 트리 형태로 구성하고 여기서 정답을 찾는 알고리즘으로 알고있는데, 기존 시스템의 bean candidate와의 차이점이 좀 헷갈려서 질문합니다. 갈라지기 전까지는 공유한다는게, 트리 구조의 블록들 중 같은 블록이 존재하는경우 복사하지 않고 공유한다는 내용일까요?
감사합니다.
안녕하세요 인택님 좋을 리뷰 감사합니다.
현재 시점에서는 vLLM 이후에도, FlashAttention 계열뿐 아니라 다양한 최적화가 나왔는데, 그럼에도 불구하고 PagedAttention은 여전히 기본 전제처럼 남아 있는 설계인건지 아니면 특정 환경에서는 다른 메모리 관리 방식이 더 유리한지도 궁금합니다. 리뷰 초반에 최근 방법론이 특정 상황에서 더 빠르다고 언급해주셔서 궁금해서 답글 드립니다.
감사합니다.