안녕하세요. 이번 논문은 RGB 데이터셋은 Thermal 이미지로 변환(생성)하는 방법론입니다.
SiT와 adaLN-zero와 같은 개념에 대해 알아보고자 골랐습니다.
시작하겠습니다.
Introduction
먼저 두가지 측면에 대해서 얘기합니다.
Q. RGB-T 데이터셋은 왜 좋은가?
A. 저조도 환경과 다양한 날씨에도 강건하기 때문이다.
Q. 그럼 왜 synthesis RGB-T 데이터셋이 필요한가?
A. 먼저 alignment가 완벽히 맞고, 현존하는 RGB 데이터셋을 전부 활용 가능하고, RGB-T 데이터셋이 한정되어 있기 때문.
위의 이유들로 저자들은 RGB 이미지를 Thermal로 synthesis하는 방법론이 필요하다고 주장합니다.
해당 논문은 GT가 존재하는 상황에서 기존의 GAN이나 diffusion 기반의 방법을 사용하지 않고, Scalable Interpolant Transformer(SiT)을 통해 Thermal synthesis하는 방법을 소개합니다.
Methodolody
1. preliminaries
먼저 DiT 기반의 SiT에 대한 설명부터 preliminaries로 소개합니다.
Scalable Interpolate Transformer는 아래와 같이 정의됩니다.
z_0 \sim p(z)를 데이터에서의 latent variable이라 정의하고
\epsilon \sim \mathcal{N} (0, I) 는 Gaussian noise입니다.
시간 t \in [0, 1]에서의 연속적인 수식은 아래와 같이 표현됩니다.
z_t = \alpha_t z_0 + \sigma_t \epsilon
\sigma_t는 1에서 0으로 감소하고, \alpha_t는 0에서 1로 증가하는 함수입니다.
따라서 t = 0에서 는 원본 데이터 z_0이고, t = 1인 terminal state에서는 순수 노이즈 z_1 = \epsilon이 됩니다.
그래서 DiT와 SiT의 차이가 무엇이냐?라고 묻는다면
DiT는 Diffusion 기반의 방법론으로 분포를 기반으로 noisy한 데이터를 생성하고 이를 학습합니다
그 과정에서 아래 빨간색 네모의 식을 기반으로 noise를 추가합니다.

반면 SiT는 위에서 얘기한 공식처럼 선형적으로 noise를 섞습니다.
z_t = \alpha_t z_0 + \sigma_t \epsilon그렇기에 이전에 noise를 예측했어야하는 diffusion 방식과 달리 이제는 정답과의 방향(flow)만 예측하면 되는 문제로 변화하였습니다.
그리고 이것을 ODE(상미분방정식)을 이용해서 modeling합니다
\dot{z}_t = v(z_t, t)
그렇게 수식적으로 전개해서 최종적으로 flow loss는 아래와 같습니다.
\mathcal{L}_{\text{flow}} = \mathbb{E}_{\mathbf{z}_t, t} \left[ \| v_\theta(\mathbf{z}_t, t) - v(\mathbf{z}_t, t) \|^2 \right]
간단하게 설명하자면,
v_\theta(\mathbf{z}_t, t)가 특정 timestep t에서의 model의 예측이고
v(\mathbf{z}_t, t)가 특정 timestep t에서의 GT입니다.
그래서 그 차이를 MSE로 계산한 후 Mean하는 것입니다.
이렇게 학습을 하면 model은 denoised된 latent variable \hat{z_0}을 terminal noise state z_1 = \epsilon로부터 얻을 수 있습니다.
2. RGB-Image-Conditioning and Style-Disentangled Generative Model
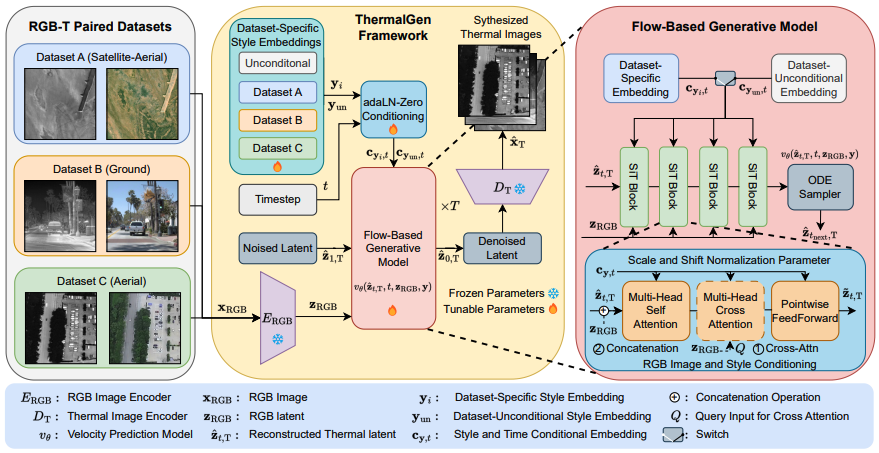
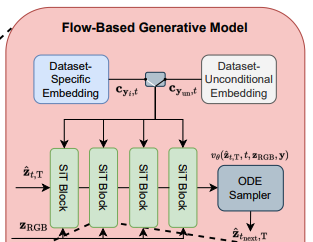
a. Flow-based Latent Generation
SiT를 flow-base latent generation을 위해 활용합니다.
먼저 noise인 \hat{z_{1, T}}를 model에 넣습니다.
그러면 SiT Block들과 ODE sampler을 통과하여(iteratively하게), noise thermal latent \hat{z_{1, T}}를 다음 timestep \hat{z_{t_{step}, T}}을 얻어낼 수 있습니다. 이 과정을 반복해서, \hat{z_{1, T}}를 \hat{z_{0, T}}으로 만들어줍니다
SiT block을 좀 더 자세히 확인해봅시다.
noise가 참고할 RGB 이미지가 필요하므로 이를 KL-VAE encoder(E_{RGB})를 이용하여 rgb의 latent representation을 추출합니다(z_{RGB}).
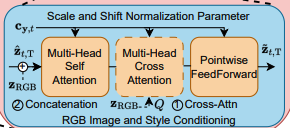
그리고 이걸 noise latent에 먹여줘야하는데요. 두가지 방법론이 있습니다.
1. Cross attention block을 명시적으로 추가해주기
2. concat해서 하나의 거대한 self-attention을 돌리기
CroCo에서도 저자가 같은 고민을 했었는데, 다 비슷한 고민을 하는 것 같습니다.
1번 방법은 self attention후 cross attention을 따로 해주는 것이므로, 관계에 더 집중하고 연산 효율적입니다.
다만 성능적으로는 2번이 더 좋다고 합니다. 위 figure를 참고하시면 이해가 편할 것 같습니다.
b. Style-Disentangled Mechanism
좋습니다. 이제 noise가 RGB를 보고 denoising하는 과정에 대해 알아봤습니다. 하지만 저자의 목표는 RGB이미지를 Thermal 이미지로 변환하는 것인데 thermal에 대한 정보는 지금까지 어디에도 없었습니다.
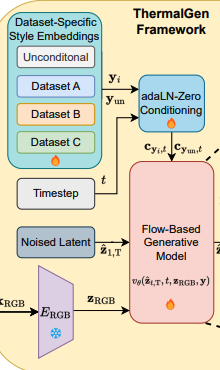
이때 Style-Disentangled Mechanism을 사용합니다.
데이터셋마다 learnable style embeddings Y = \{y_0, y_1, . . ., y_n, y_{un}\}를 정의합니다.
n은 유저가 정의한 RGB-T style의 개수를 의미하며 y_{un}은 unconditional style embedding을 의미합니다.
그리고 이걸 활용하여 adaLN-zero를 사용합니다.
먼저 adaLN-zero를 짚고 넘어가겠습니다.
adaptive layer normalization zero initialization의 축약입니다.
기존의 ViT에 있는 layer normalization의 scale shift를 adaptive한 방식으로 진행하는 방법입니다.
이를 통해, 예전 논문에서 style-transfer이 가능함을 보였습니다. 즉, 원래 가중치는 그대로 두고
feature의 scale과 shift만 조정해주어도 효과적으로 style을 바꿀 수 있는 것입니다.
그리고 이 adaLN-zero는 기존 layer normalization 뒤에 붙습니다.
초기화가 0으로 되어 있기에, 학습 초반에는 기존 LN만 작동합니다. 하지만, 시간이 지남에 따라
adaLN-zero의 가중치가 점차 커지는 방식을 통해서 학습의 안정성을 잡았습니다.
그래서 이 논문은 scale과 shift의 값을 y와 t를 이용해서 결정합니다.
style과 시간을 MLP로 학습시켜 scale, shift를 내놓는 것입니다.
그리고 학습시에 model은 C_{y_i, t}와 C_{un, t}을 random하게 선택하여 학습시켜서, Classifier-Free Guidance(CFG)를 가능하게 했다고 얘기합니다. 즉, 조건이 주어졌을 때 denoising과 조건이 없을때 denoising 모두 잘하게 됩니다.
이렇게 최종적으로 얻어낸 denoised latent는 decoder를 통해, 이미지로 생성됩니다.
Experiment
평가지표
- PSNR: 영상 화질 손실양을 평가하기 위한 지표로, 클수록 좋습니다
- SSIM: 인간의 지각과 유사한 평가지표로, 클수록 좋습니다
- FID: 생성된 이미지의 분포가 실제 이미지의 분포와 얼마나 유사한지 측정, 작을수록 좋습니다
- LPIPS: feature 상에서의 이미지를 비교하는 지표, 작을수록 좋습니다
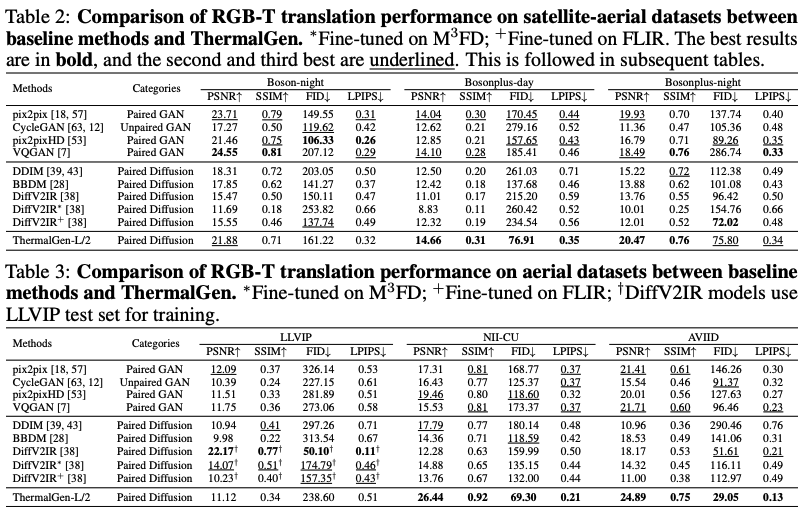
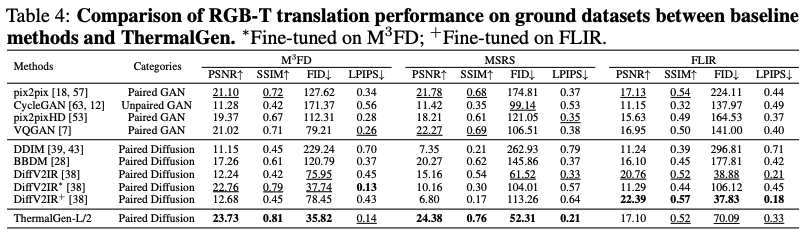
저자의 방법론이 대부분의 Category와 dataset에서 GAN과 diffusion기반의 방법론을 압도한다고 주장합니다. 특히, perceptual quality를 평가하는 FID와 LPIPS에서 두드러진다고 합니다. 또한 DiffV2IR과 같은 방법론은 특정 데이터셋에만 fitting되어 있는 반면, 저자의 방법론은 다양한 데이터셋에서 좋은 지표를 보이기에 강건성까지 좋다는 사실을 알 수 있습니다.
다만… Boson-night 데이터셋에서는 GAN들이 우세함을 보이고 있고, 또한 LLVIP과 FLIR에서도 Diffusion기반에 방법론에 밀리는 것을 볼 수 있습니다. 저자는 일단 여기서는 언급하지 않고 뒤쪽 limiation에서 언급합니다.
Ablation
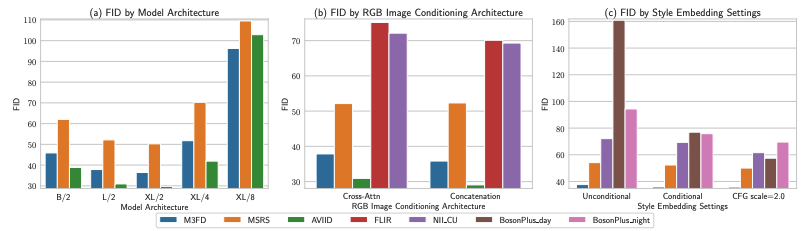
(a) SiT의 모델 size와 patch size(2, 4, 8)에 따른 ablation
L와 XL가 B를 능가하는 성능을 보여줬습니다. patch size 역시 작은수록 좋은 것을 기록되었습니다. 이는 더 fine한 것이 image의 quality를 올린다는 사실에 대한 근거입니다.
(b) Cross-Attn, Cat-block에 대한 ablation
RGB latent들을 concatenating하는 것이 Cross attention하는 것보다 더 좋은 성능을 보입니다.
(b) style을 지정해줬을때, 지정하지 않았을때에 대한 ablation
dataset-condition/uncondition 그리고, CFG(classifier-free guidance)의 scale을 지정하여 더욱 style에 집중하도록 한 방법의 성능을 비교했습니다. 이는 style embedding이 generation quality에 큰 영향을 주는 것을 확인할 수 있습니다.
Limitation
위에서 잠깐 언급한 Boson-night, LLVIP, FLIR에서의 성능이 낮은 이유에 대해서 얘기합니다.
데이터셋에서의 이미지 특성이 다르고, scene이 diversity하다~와 같은 주장들이며 어떻게 tuning하면 성능이 더 오르는지에 대해 언급합니다. 세세한 디테일적인 내용이라 아래에 첨부해놓겠습니다.

Visualization

물론 Cherry picked된 이미지겠지만, 가장 오른쪽 GT와 비교했을때 저자의 방법론이 압도적으로 유사하고 detail이 살아있는 모습을 볼 수 있습니다.