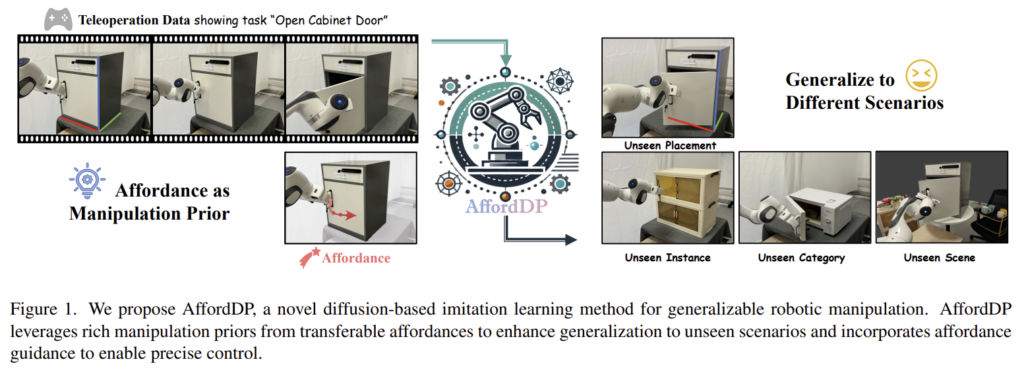
Abstract
해당 논문은 일반화 가능한 로봇 조작을 위해 Diffusion 기반의 모방학습에 Affordance 개념을 추가한 AffordDP를 제안합니다. Diffusion 기반의 policy는 로봇 작업에서 인상적인 성능을 보여주었으나, Out-of-Domain에 대해서는 어려움을 겪고 있으며, 이를 해결하기 위한 시각적 특징 개선 연구들 역시 유사한 외형의 동일 카테고리로 한정된다는 문제가 있었습니다. 저자들은 affordance를 통해 agent가 객체의 어느 부분에서 어떻게 상호작용이 이루어질 지 이해하도록 하여 일반화 가능하도록 하고자 하였습니다. 저자들은 transferable affordance를 활용한 AffordDP를 통해 unseen 객체 인스턴스와 카테고리로 일반화 성능을 개선하였으며, diffusion sampling 과정에 affordance guidance를 통합하여 action sequence를 생성하는 과정을 개선하였다고 합니다. AffordDP는 기존 방법론 대비 우수한 성능을 보였으며, unseen 인스턴스와 카테고리에 대해서도 우수한 성능을 보여주어 일반화 성능을 입증하였다고 합니다.
Introduction
모방학습은 명시적으로 로봇의 동작을 프로그래밍하거나 환경을 모델링하지 않아도 되기 때문에 효율적인 솔루션으로 받아들여지며, 이러한 이유로 로봇 조작, 보행 로봇 등 다양한 분야에서 관심을 받아왔습니다. 최근 Diffusion 기반 모델이 관심을 얻고 있으며, 이는 로봇의 visuomotor policy를 conditional diffusion denoising으로 개념화하여 action 분포 학습을 용이하게 하는 방식입니다.
그러나 높은 이러한 diffusion 기반의 모방학습은 Out-of-Domain에 대해 일반화가 어려운 문제가 존재하며, 이를 해결하기 위해 최근 연구들은 시각적 특징 인코딩의 일반화 능력을 향상시켜 Diffusion Policy에 직접 이용하고자 하였습니다. 그러나, 이러한 방식들은 diffusion 모델이 다른 초기 위치, 외형, 자세로 일반화 가능하도록 하지만, 유사한 외형의 동일 카테고리 물체로 제한되며, 여전히 unseen 인스턴스와 카테고리로는 적용이 어렵습니다.
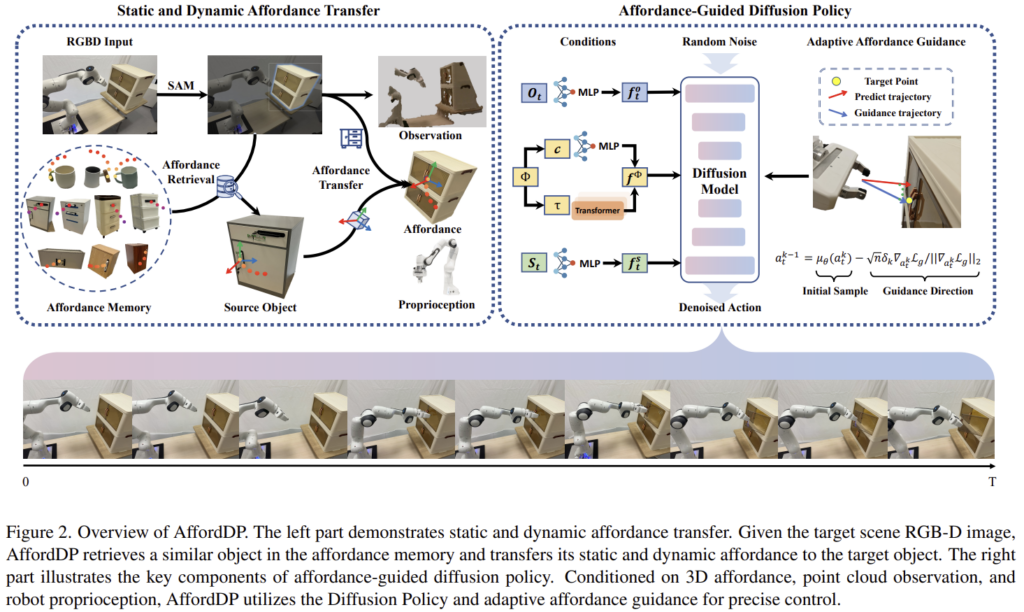
인간의 경우에는 캐비닛을 여는 기술을 전자레인지나 냉장고 여는 데 적용할 수 있는 것처럼, 외관 뿐만 아니라 유형이 다르더라도 쉽게 기술을 전이하여 적용이 가능합니다. 저자들은 이를 인간이 상호작용에 대한 방대한 양의 사전지식을 가졌기 때문이라 보았습니다. 그러나 기존의 모방학습은 affordance를 2D contact point가 있는 trajectory, task-specific key frame 등으로 정의하였으며, 이러한 방식들은 “어떻게”에 대한 표현은 부족하다고 보았습니다. 따라서, 저자들은 static/dynamic affordance(“어디”에 해당하는 정보를 static affordance, “어떻게”에 해당하는 정보를 dynamic affordance로 봄)에 대한 일반적인 표현을 설계하고, affordance가 전이 가능한 diffusion policy인 AffordDP를 제안하였습니다. AffordDP는 affordance를 조건으로 사용하여 다양한 조작 시나리오에 일반화 성능을 높이고자 하였습니다. 그러나 단순히 합치는 방식은 unseen 객체로의 적용에 어려움이 있다고 보았고, 로봇의 end-effector와 static affordance 사이의 거리를 활용하는 affordance-guided sampling process를 제안하여 생성된 action sequence가 원하는 manipulation position으로 점진적으로 이동하도록 하였습니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- transferable affordance를 활용한 AffordDP를 제안하여 unseen 물체와 카테고리로의 일반화 성능 개선
- foundation 모델을 사용하여 static & dynamic affordance를 모두 전이 가능하도록 하여 제한된 in-domain 데이터로 복잡한 조작을 표현할 수 있도록 함
- AffordDP에 adaptive affordance guidance를 통합하여, unseen 객체에 대해서도 생성된 action sequence가 action space의 manifold를 유지하면서 원하는 조작 위치로 점진적으로 이동할 수 있도록 함
Transfer of Static and Dynamic Affordances
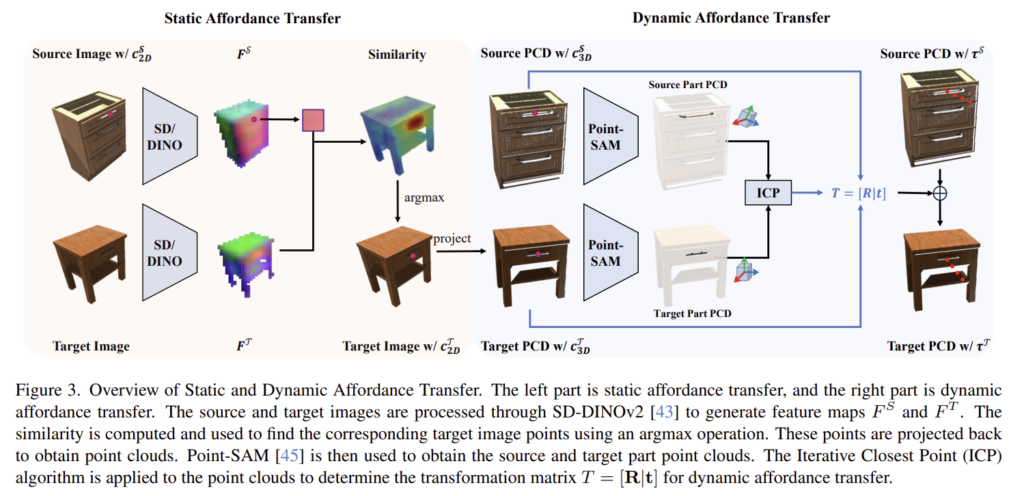
먼저, 저자들은 3D affordance를 \Phi=(c,\tau) 로 정의하였으며, 이때 c\in \mathbb{R}^3는 static affordance인 3D contact point, \tau \in \mathbb{R}^{3⨉N}는 dynamic affordance로 접촉한 뒤 이동하는 경로를 의미합니다. 저자들은 affordance transfer를 source 물체의 affordance를 이용하여 target의 affordance를 생성하는 것으로 정의하였습니다. AffordDP는 ① target과 가장 유사한 물체를 찾은 뒤, ② 의미론적 대응을 통해 static affordance를 전이하고, ③ 6D transformation matrix를 이용하여 dynamic affordance를 전이하도록 하였으며, Figure 3에서 이를 확인하실 수 있습니다.
① Affordance Memory and similarity retrieval
해당 과정은 affordance memory를 구축한 뒤, GorundedSAM과 CLIP의 이미지 인코더를 이용하여 target과 가장 유사한 source를 찾는 과정입니다. affordance memory는 \mathcal{M}=\{(T, \Phi, z, \mathcal{P})\}로 정의되며, T는 task name, \Phi는 affordance \Phi=(c,\tau) , z는 appearance feature, \mathcal{P}는 조작 물체의 point cloud를 의미합니다. 구체적인 과정은 다음과 같습니다. 동일한 T에 대하여 source와 target의 물체 영역에 대하여 crop된 이미지에 CLIP 이미지 인코더로 feature를 구한 뒤, 두 feature 사이의 cosine similarity를 계산하여 가장 유사한 메모리를 찾아내는 것 입니다.
② Static affordance transfer
target과 가장 유사한 메모리를 찾은 뒤, source의 static affordance 정보(3D contact point)를 target으로 전이합니다. 이때, target과 source 물체의 외형, 모양, 카테고리 등이 다를 수 있으며, 이러한 차이를 완화하기 윙해 저자들은 vision foundation 모델이 제공하는 의미론적 특징을 활용합니다. 픽셀 수준의 feature를 생성하기 위해 SD-DINOv2를 upsampling 한 뒤, 2D 상에서 source의 static affordance c^{\mathcal{S}}_{2D}를 target의 모든 픽셀과 비교하여 target의 2D static affordance c^{\mathcal{T}}_{2D}를 찾은 뒤, 이를 3차원 공간으로 역투영하여 c^{\mathcal{T}}_{3D}를 구합니다.
③ Dynamic affordance transfer
dynamic affordance 전이를 위해 저자들은 6D transformation matrix를 이용합니다. 기존 연구는 instance-level registration 기반 방식으로 두 객체를 직접적으로 align을 맞추는 방식이지만, 저자들은 이러한 방식은 source와 target의 형태 및 크기 차이로 인해 부정확하다고 보고 rotation과 translation을 독립적으로 추정하였습니다. Translation은 source와 target의 3D contact point 차이로 계산하였으며, rotation에 대해서는 조작 대상 부위에 대한 point cloud 만을 이용하여 정렬을 수행합니다. 이때, part 영역의 point cloud 만을 사용하기 때문에 구조적 차이에 대한 민감도를 줄이고자 하였으며, ICP를 이용하여 part를 정렬하고 이렇게 얻은 rotation과 translation을 결합하여 source 객체의 dynamic affordance를 target으로 전이하는 6D transforamtion matrix를 구합니다.
Affordance Guided Diffusion Policy
일반화 능력을 높이기 위해 저자들은 affordance를 추가 조건(condition)으로 이용하는 conditional diffusion 모델을 설계합니다. 저자들은 조작에 대한 사전 지식을 이용하여 학습과 실제 배포 사이의 격차를 줄이고자 하였으며, 단순히 condition으로 추가하는 것으로는 잠재력을 충분히 이용하지 못한다고 보았습니다. 이에 대하여 저자들은 diffusion 모델이 본질적으로 전체 행동 분포를 모델링하는 데 중점을 두기 때문으로, 특정 작업에 특화된 제약 조건을 따르기보다는 분포와의 정렬을 수선시하기 때문이라 설명합니다. 따라서, static affordance를 향해 policy를 유도하는 adaptive affordance-guided sampling 과정을 도입함으로써 작업에 집중하고 정밀도를 개선하였다고 합니다.
1. Conditions for AffordDP
AffordDP의 전체적인 condition은 \mathcal{C}=\{ O_t, S_t, \mathcal{\Phi}\}로 정의되며, 이때 O_t는 장면에 대한 point cloud, S_t는 로봇의 state를 의미합니다. AffordDP는 DDIMs를 기반으로 하며, affordance-guided conditional action distribution p(a_t|O_t,S_t,\Phi)를 근사하는 것을 목표로 합니다. 각 조건은 서로 다른 encoder를 통해 feature로 변환되며, 최종 conditioning feature는 f_t=\{ f^O_t, f^S_t, f^\mathcal{\Phi}\}로 구성됩니다. scene에 대한 feature는 장면을 물체 영역으로 crop & downsample 한 뒤 MLP로 인코딩하며, trajectory \tau는 [CLS] 토큰이 포함된 transformer 인코더를 통과하고, contact point \mathcal{c}와 로봇의 state는 별도의 MLP를 통과하여 구해집니다.
2. Conditional diffusion model training
AffordDP는 DDIM 기반의 conditional diffusion policy를 학습하며, 초기 noisy action a^k_t로부터 반복적으로 denoising하여 noise-free action a^0_t를 생성합니다. 이 과정은 아래의 식으로 정의되며,
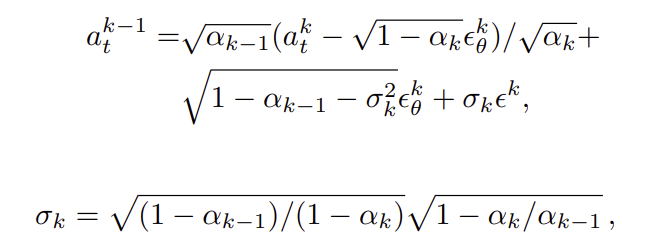
noise prediction 네트워크 \epsilon_{\theta}는 각 denoising step에서 추가된 noise를 예측하도록 아래의 loss를 이용하여 학습됩니다.
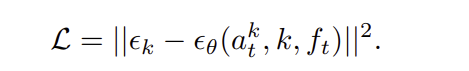
3. Diffusion sampling with affordance guidance
표준 diffusion 공식은 데이터 분포상 자연스러운 action을 생성하더라도, 문 손잡이 grasp와 같이 정밀한 task condition을 만족하지 못할 수 있습니다. 따라서 저자들은 affordance guidance를 샘플링 과정에추가합니다. 베이즈 정리에 기반하여 조건 y를 포함하여 샘플링을 아래의 식으로 보정합니다.
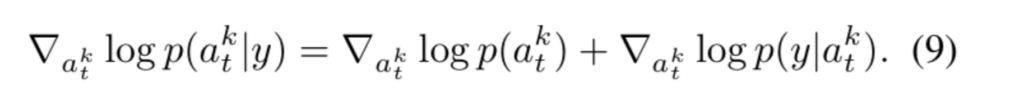
sampling guidance를 위해 미분 가능한 loss function L({a}^0_t, y)을 이용하여 DDIM 업데이트에 affordance guidance를 추가한 correction step을 수행합니다. 여기서 {\hat{a}}^0_t(a^k_t)는 {\hat{a}}^0_t로부터의 추정값이며, \gamma는 guidance weight입니다.
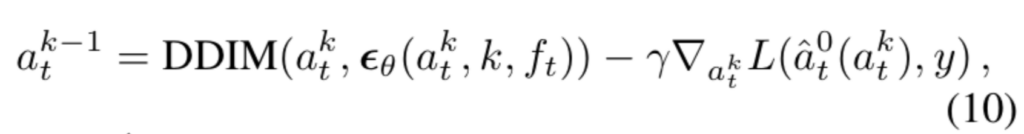
추론시에는 forward kinematics를 통해 end-effector 위치 p_{ee}를 구한 뒤, static affordance인 c_{3D}와의 거리를 계산하여 adaptive loss로 사용합니다. 참고로 이 loss는 end-effector가 target 주변에 왔을 때(threshold \theta 이하의 거리가 되었을 때)만 적용됩니다.
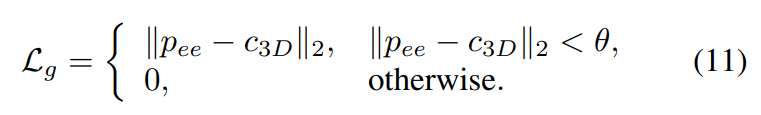
이 adaptive guidance를 포함한 sampling update는 아래의 식으로 정의되며, 여기서 n은 action dimension을 의미합니다.
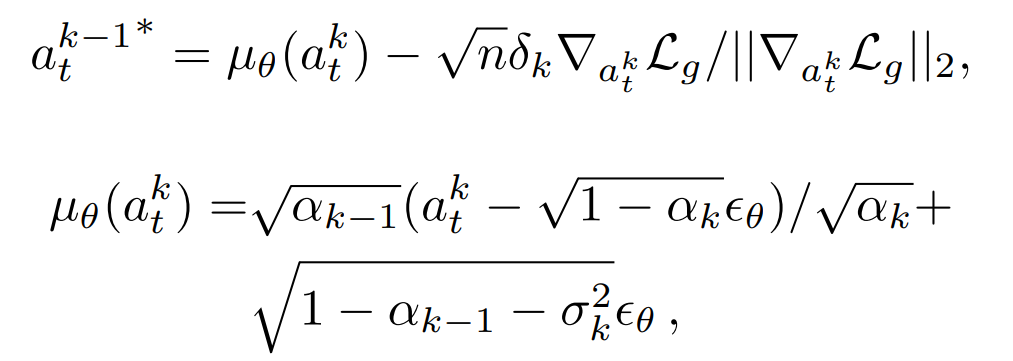
즉, AffordDP는 단순 affordance condition을 추가하는 것 뿐만 아니라 sampling 단계에 end-effector가 목표 static affordance에 접근할 수 있도록 하는 adaptive affordance guidance를 추가하므로써, unseen 객체에 대해서도 목표 조작 위치로 더 정밀하게 다가갈 수 있도록 설계되었습니다.
Experiments
[Experiment Setup]
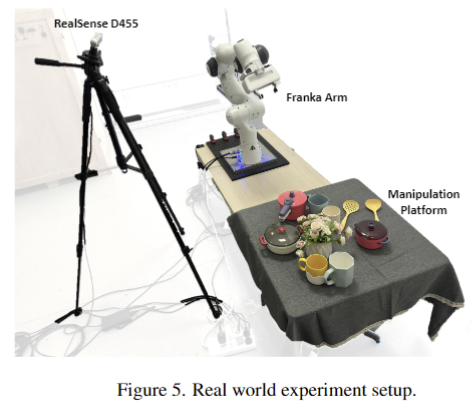
저자들은 시뮬레이션(IsaacGym)과 real-world 모두에서 평가하였으며, GAPartNet의 객체와 depth camera로 생성한 point cloud를 observation으로 활용하였습니다. 두 환경 모두에서 Franka 로봇 팔과 side-mounted camera를 사용하였습니다. 시뮬레이션에서는 CuRoBo를 expert motion planner로 사용하여 전문가 시연 데이터를 수집하였고, trajectory 다양성을 높이기 위해 객체의 6D 위치, 로봇 베이스 위치, 초기 DOF 등에 랜덤 노이즈를 추가하였다고합다. 또한 GAPartNet의 part bounding box annotation을 활용하여 part manipulation에 특화된 시연을 수집합니다. real-world에서는 teleoperation을 통해 전문가 시연을 수집하였다고합니다.
저자들은 두 가지 diffusion 기반 policy 방법론을 이용하여 작업 성공률(success rate)을 평가합니다. 하나는 이미지를 입력으로 사용하는 Diffusion Policy(DP) 이고, 다른 하나는 이미지 대신 point cloud를 입력으로 사용하는 DP3 입니다. 또한, 두 가지 training setting으로 나누어 평가합니다. 기존 DP와 DP3는 하나의 객체만 사용하는 single-object training 방식으로 객체에 특화된 표현은 잘 학습하지만, unseen 인스턴스에 대한 일반화에는 한계가 있을 수 있다고 보았습니다. 따라서 저자들은 기존 single-object setup을 유지하는 object-specific policy training과, 여러 객체를 함께 학습하여 일반화를 유도하는 unified policy training을 함께 실험합니다.
Simulation Performance
저자들은 시뮬레이션 환경에서 PullDrawer와 OpenDoor 두 작업에 대해 평가하였으며, 공정한 비교를 위해 object-specific policy training과 unified policy training 두 학습 설정 모두에서 실험을 수행하였습니다. Object-specific policy training에서는 각 작업마다 30개의 전문가 시연을 수집하였고, 객체의 초기 위치와 로봇 팔의 초기 자세에 서로 다른 수준의 variance를 부여한 데이터셋을 구성하여 강인성을 평가하였습니다.
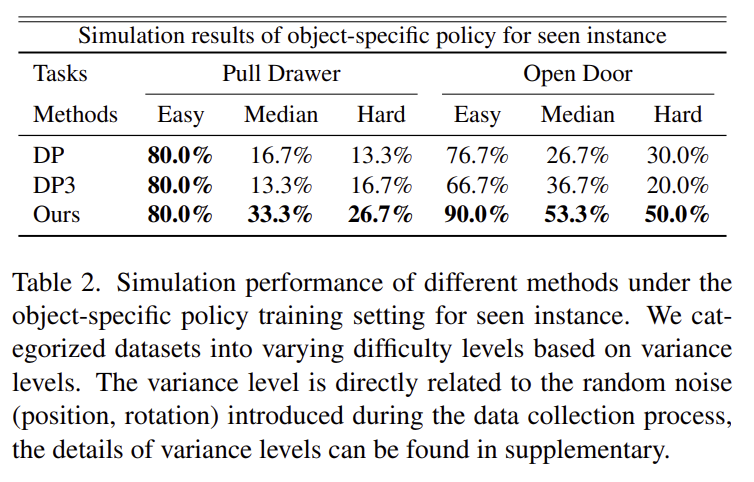
저자들의 방법은 두 작업 모두에서 다양한 variance 수준 전반에 걸쳐 기존 방식보다 우수한 성능을 보였습니다. 특히 low-variance 조건(easy)에서는 기존 방식과 유사한 성능을 보였지만, variance가 증가할수록 뚜렷한 성능 개선을 보였습니다.
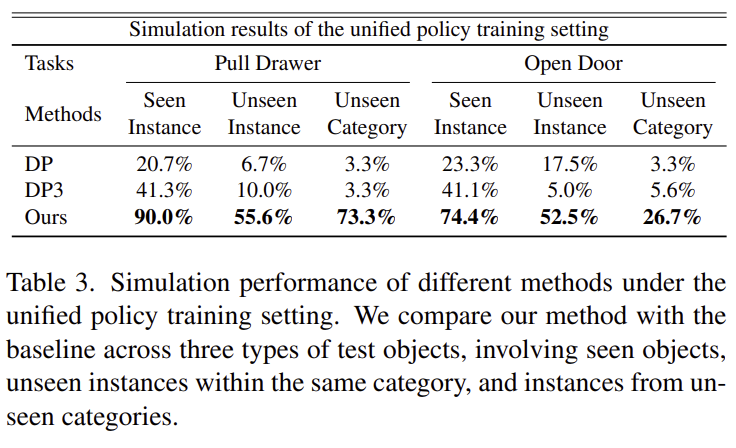
Unified policy training에서는 각 작업마다 5개의 서로 다른 객체를 선택하고, 각 객체에 대해 20개의 전문가 시연을 수집하였습니다. 일반화 성능을 평가하기 위해 테스트 객체를 seen instances, 동일 카테고리에 대한 unseen instances, unseen categories의 물체로 3가지 케이스를 구분하였습니다. 실험 결과 AffordDP(Ours)는 세 가지 케이스에서 모두 우수한 성능을 달성하였으며, 특히 학습에 포함되지 않은 카테고리에 대해서도 강한 일반화 능력을 보였습니다. 반면 기존 방식들은 unseen category 에서 매우 낮은 성공률을 나타냈습니다. 저자들은 이러한 결과를 통해 transferable affordance를 통해 seen/unseen 객체의 조작 특성을 포착할 수 있었기 때문이라고 설명합니다.
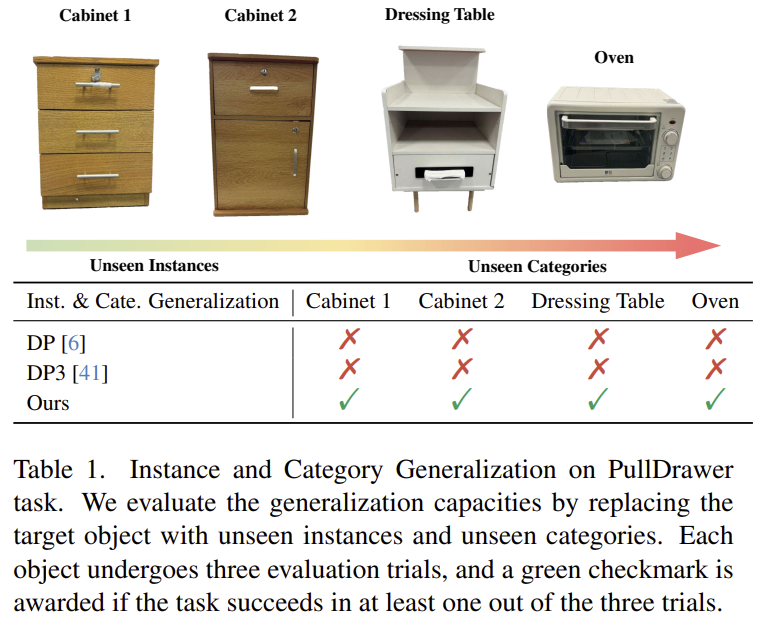
Real-world Performance

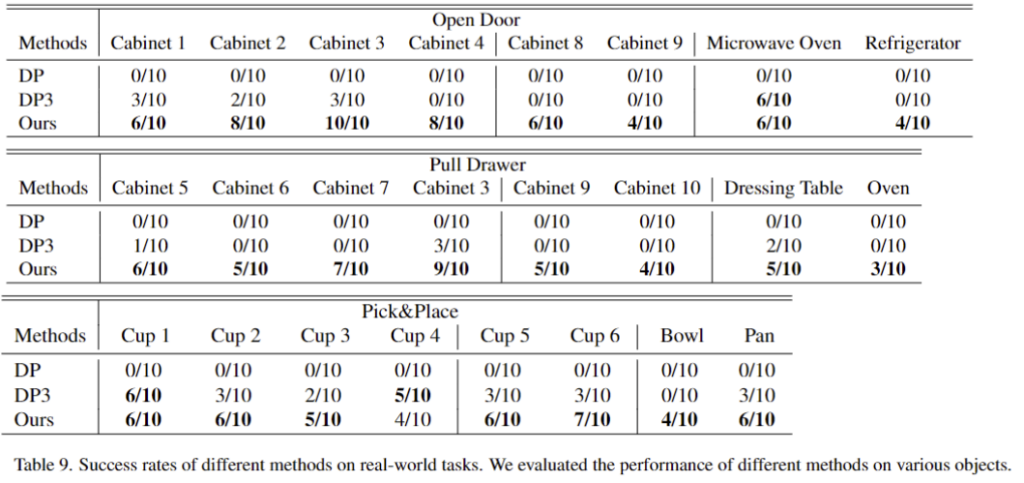
real-world에서는 OpenDoor, PullDrawer, Pick&Place 3가지 작업에 대한 unified policy training에 대한 평가를 수행합니다. teleoperation을 통해 각 객체당 25개의 시연 데이터를 수집하였으며, 각 작업마다 4개의 객체로 구성되어 총 100개의 시연 데이터로 구성됩니다. 또한, 마찬가지로 seen instances, 동일 카테고리에 대한 unseen instances, unseen categories 3가지 케이스로 나누어 평가를 수행하였습니다.
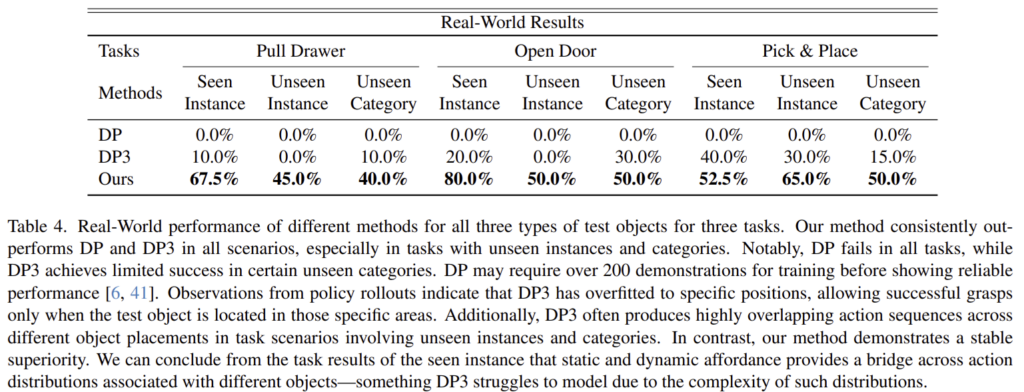
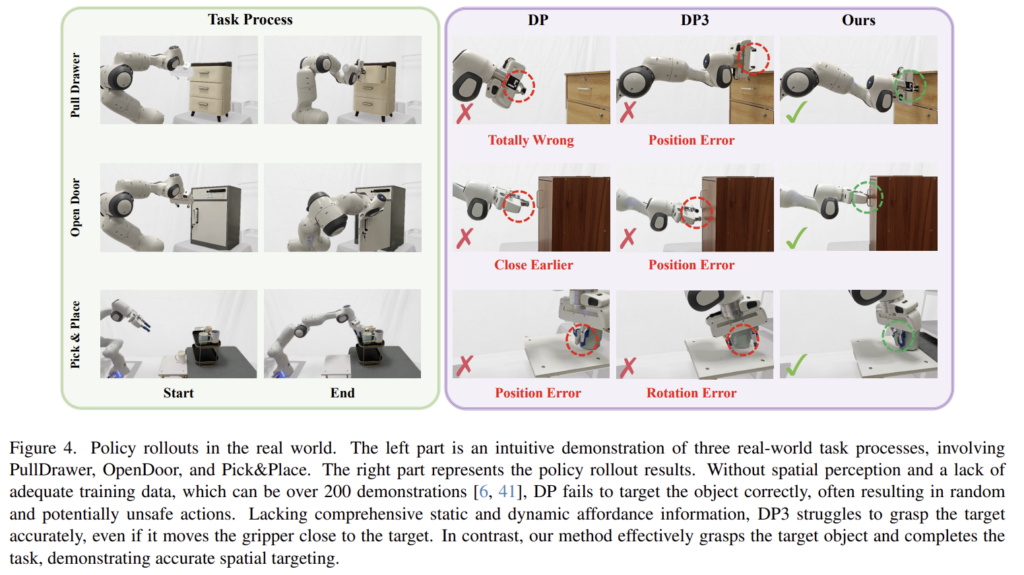
실험 결과 저자들이 제안한 방법론이 real-world에서도 기존 방식들보다 우수한 성능을 보이는 것을 확인할수 있습니다. 특히, PullDrawer 작업에 대한 실험 결과 instance에 대한 일반화 뿐만 아니라 카테고리에 대한 일반화 능력도 갖추고 있다는 것을 보여줍니다. 또한, unseen instance 뿐만 아니라 unseen category에 대해서도 일반화가 가능함을 확인하였습니다. 아래는 real-world에서의 실험 결과를 시각화 한 것입니다.
Ablation study
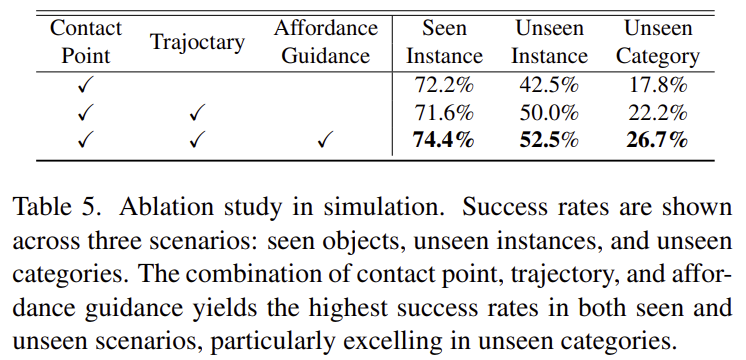
저자들은 unified policy training 세팅의 시뮬레이션 환경에서 ablation study를 수행하였습니다. 해당 실험은 affordance 정보(contact point & trajectory)와 affordance guidance를 선택적으로 제거하여 각 요소의 중요성을 평가한 것 입니다. 실험 결과 contact point만 이용할 경우 뚜렷한 성능 저하가 발생하였으며, 최종적으로 3가지 요소를 모두 사용하는 것이 일반화 성능을 개선시킨다는 것을 보여줍니다. 특히, adaptive affordance guidance는 unseen category에 대해 성능을 크게 향상시켰음을 확인할 수 있습니다.
안녕하세요 승현님 리뷰 감사합니다.
몇가지 질문이 있는데요,
Q1. DP에 affordance에 대한 제약을 걸어줄 때 inference 시의 sampling 과정에서 보정이 일어나는 것 같은데, diffusion에 condition으로 주는것과 어떤 차이가 있는건가요?
Q2. Affordance 제약을 retrieval 기반으로 조작 위치 뿐만 아니라 어떻게 조작하는지까지 주어지는 것 같은데, seen 인스턴스들 중에서도 easy부터 hard까지 어떤 차이가 있는건가요?
질문 감사합니다.
A1. diffusion의 condition으로 사용되는 것은 모델에 추가로 static한 3D contact point와 dynamic한 trajectory가 입력되는 것이며, 샘플링 과정은 diffusion이 생성중인 output을 중간에 수정하는 것이라 이해하면 좋을 것 같습니다. 저자들은 샘플링 과정에 업데이트를 통해 unseen object에 대해서 원하는 조작 위치로 정밀하게 다가갈 수 있도록 설계하였습니다.
A2. easy~hard는 ‘초기 위치와 로봇 팔의 초기 자세’에 대해 variance를 어느정도 주는 지에 따라 나뉘게 됩니다. 즉 seen 인스턴스에 대해서 easy는 거의 동일한 위치에 물체가 존재하고, 로봇팔의 초기 자세도 거의 동일할 것이고, hard는 물체가 다른 위치에 있거나 파의 초기 자세가 다르게 세팅되어있는(혹은 둘다) 케이스를 의미하는 것으로 이해하였습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
예를 들어 컵을 grasp 한다면 손잡이를 잡을 수도 있고 몸체를 잡을 수도 있는 것처럼 하나의 task에 대해 여러 affordance가 있을 수 있을 것 같은데요, 해당 방법론이 이런 multimodal성도 고려가 가능할지 궁금합니다.
질문 감사합니다.
그 점에 대해서는, retrieval 과정에서 어떤 케이스를 선택하는 지에 따라 달리질 것 같습니다. 만약 memory에 손잡이를 잡는 케이스만 있다면, 몸체를 잡는 케이스에 대해서는 적용이 어려울 것 같고(반대도 마찬가지), 두 케이스가 모두 있다면, 대상이 되는 물체(seen 인스턴스일수도 unseen 인스턴스일수도 있음)가 몸통을 잡는 케이스와 유사하면 몸통을 잡도록, 손잡이를 잡는 케이스와 유사하다면 손잡이를 잡도록 설정 될 것으로 보입니다. 예은님이 이야기하시는 multimodal성이라는 게 memory에 손잡이만 있어도 몸체로 확장 가능할지에 대한 질문이시라면, 이에 대해서는 대응 가능한지에 대해 답변을 드리기 어려울 것 같습니다.