안녕하세요, 이번주 X-review는 fine-grained manipulation에 관련한 내용으로 작성해보려고 합니다. 최근 robot learning 패러다임에는 기존의 로봇데이터로만 학습하는것에 그치지 않고 human video와 같은 다른 소스를 통한 학습이나 world model, human in the loop로 finetuning을 하는 식의 연구도 많이 등장하고 있습니다. 저자들은 human preference를 기준으로 pick and place와 같은 정량적인 평가가 가능한 task가 아닌 성공의 기준이 연속적이고 주관적인 작업을 학습시키는 방법에 대해 연구했습니다. 리뷰 시작하도록 하겠습니다.
Introduction
모방학습은 현재 로봇 러닝에서 주류 방법으로 자리잡았고, 다양한 task를 수행할 수 있도록 발전하고 있지만 음식 조리, 수술, 각종 공예와 같이 contact-rich 하고 힘 제어가 중요한 작업들에 대해 어떻게 배우고 평가할 것인지에 대한 부재가 큰 병목이라고 합니다. 저자들은 이런 task들은 특히 작업 성공에 대한 기준이 주관적이기 때문에 더욱 데모 수집과 평가에 어려움이 있다고 문제를 정의합니다. 크게 양적인 문제와 질적인 문제 두 축으로 정리했습니다.
첫째는 양적인 문제입니다. 과일깎기와 같은 작업은 force-contact의 상호작용이 복잡해서 좋은 demonstration을 대량 수집하기 어려운 문제가 있스빈다. 단순한 pick-and-place와 달리, 조금만 힘이 과하거나 부족해도 실패하거나 원하지 않는 결과가 나올 수 있습니다. 이런 문제에서 이어지는 둘째 문제는 질적인 문제입니다. 껍질을 벗겼다고 해서 다 같은 성공이 아니라 얼마나 얇게 벗겼는지, 끊기지 않았는지, 표면이 고른지, 살을 너무 많이 깎지 않았는지처럼 결과물의 완성도가 연속적이고 주관적입니다. 그래서 고정된 metric 하나로는 실제 인간이 느끼는 “잘 됨”을 표현하기 어렵다고 합니다. 저자들은 이러한 두 병목, 즉 성공적인 데이터를 모으기 어렵고, 모아도 무엇을 잘한 것으로 볼지 정의하기 어려운 문제를 푸는 것이 목적이라고 합니다. 이 때 저자들은 과일깎기를 task로 정했습니다. 날을 과일에 밀착시킨채 정밀한 힘 조절, 과일 형상의 추론, 그리고 크기나 곡률이 다른 대상들에 대한 일반화를 동시에 요구하기 때문에 perception, force control, generalization을 요구하는 현재 구조에서의 병목이 생기는 대표적인 task라고 합니다.
저자들은 위에서 정의한 문제를 해결하기 위해 새로운 2-stage learning framework를 제안합니다. 먼저 force-aware imitation learning을 통해 baseline policy를 학습시키고, reward model을 human notion을 활용해 finetuning하는 방식입니다. 저자들은 제안한 파이프라인을 통해 50~200개의 학습 데이터 만으로 90%의 success rate를 보이고, unseen 인스턴스들에 대해서도 ood에서 매우 강건하게 작동했다고 합니다. Primary contribution들은 아래와 같이 정리할 수 있을 것 같습니다.
- 2-stage learning framework
- Human preference-based reward model
- Data-efficient generalization
Related Work
Learning manipulation from human preference
Human preference를 기준으로 모델링하거나 학습시키는 것은 머신러닝 분야에서 오래된 문제였다고 합니다. 강화학습이나 supervised learning으로 뻗어 나갔었는데, 최근 LLM을 학습시키는 방법으로 급부상했었고, robot 모델들의 덩치가 커지면서 슬슬 넘어오는 분위기라고 하네요. 다만 LLM과 비교했을 때 현재 로봇 러닝은 시뮬레이션에서의 간단한 task나 심하게 제약이 걸린 현실 task만을 집중해서 풀고있기 때문에 성공/실패가 이분법적이고 쉬운 task들이라 사실 human preference를 적용하는 것의 의미가 좀 떨어졌다고 합니다. 따라서 저자들은 처음으로 challenging한 task에서 real robot을 통해 human preference를 통해 학습한 결과를 분석해보았다고 하네요.
Peeling with a knife
저자들은 칼을 이용해 여러 종류의 농산물을 성공적으로 껍질 벗긴 prior work는 사실상 없었다고 말합니다. 항상 감자칼을 사용해 껍질을 벗기거나 칼을 활용해서 절단을 했다고 하는데요, 그래서 완전히 같은 문제 대신 knife cutting과 감자칼을 활용한 peeling 연구들을 검토했다고 합니다.
Knife cutting 연구들은 전통적인 model-based approach에 의존하는 연구들이 대부분이었다고 합니다. Force dynamics를 해석하고 knife motion에 대한 제어 규칙을 모델링 했지만 모델링 오차에 민감하고 센서 노이즈에 극도로 취약해 일반화 성능이 낮았다고 합니다. Learning-based 접근은 없다싶이 했다고 하네요. Peeler-based peeling의 경우는 learning-based 접근도 존재하는데, 곡률이 거의 없는 대상이에서만 진행됐고, 일반화 능력이 극히 제한적이었다고 합니다. 칼로 과일을 깎는 task가 없었던 것은, 해당 task가 단순히 아키텍쳐를 바꾸는 것으로 해결되지 않고, 고품질의 demonstrationr과 force-aware compliant control 학습이 함께 해결되어야 하는 task이기 떄문이라고 합니다. KRoC가서 단순 방향에 대한 언급만 있었던 고품질 데이터와 force aware control이 둘 다 등장한 연구여서 더 관심이 생겼습니다.
Force-Based Manipulation
Force에 민감한 작업들은 단순한 position 제어만으로는 어렵고, force-aware manipulation이 필요하다고 합니다. 이 때문에 이전 연구들은 force를 사용하기는 했지만, 단순히 관측값으로 force를 넣거나 제어기 자체를 compliant하게 만드는 방식에 머물러 고품질의 demonstration을 모으기 어렵고, compliance를 학습하거나 복원하는 과정이 rule-based에 의존하기 때문에 복잡한 작업으로 확장되기 어렵다고 합니다. 저자들은 이런 force-sensitive task들은 motion planning 문제이면서 동시에 force regulation 문제이기 때문에 성능 향상과 별개로 다양한 접촉 상황에 일반화 하기 위해 learning-based approach가 필수적이라고 합니다.
다만 이 때 데이터 수집을 위해 force-aware teleoperation system을 사용하는 것을 지적했는데, 좋은 품질의 force-sensitive demo를 얻을 수는 있지만 특수한 시스템이 필요하고, 연구실 밖의 환경에서의 확장성에도 문제가 있다고 합니다. 또한 시뮬레이션 기반의 scale-up또한 deformable함과 모양에 따른 다양한 곡률이나 단단한 정도를 표현하기 힘들고, 무엇보다 peeling이나 cutting의 dynamics가 매우 복잡해 시뮬레이션 상에서 모델링 하는것에 한계가 있다고 합니다.
How to Peel with a Knife

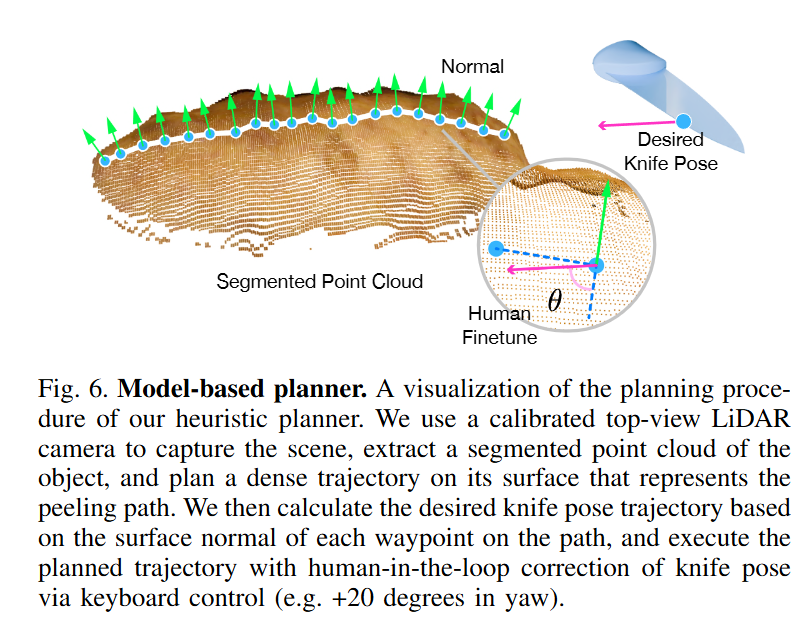
그래서 앞에서 말한 문제,, 어떻게 해결할거냐?에 대해서는 크게 3가지로 정리했습니다. 시스템 디자인, 데이터 수집과 학습 파이프라인, preference-based finetuning으로 이루어져있다고 합니다. 해당 시스템에서 학습한 모델은 seen 객체들에 대해 100%, 보지 못 한 객체들에 대해서도 70%의 일반화 능력을 보여주었다고 합니다. Fig1의 하드웨어 세팅과 같은 시스템을 셋업하고 아래 fig2와 같은 파이프라인을 통해 학습했습니다.
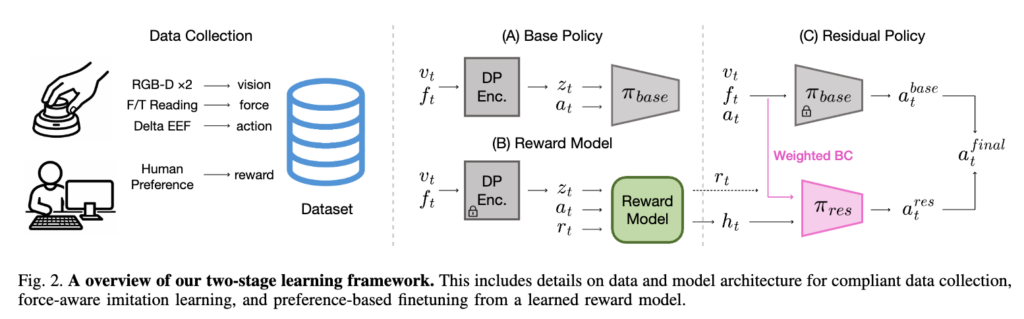
System Design
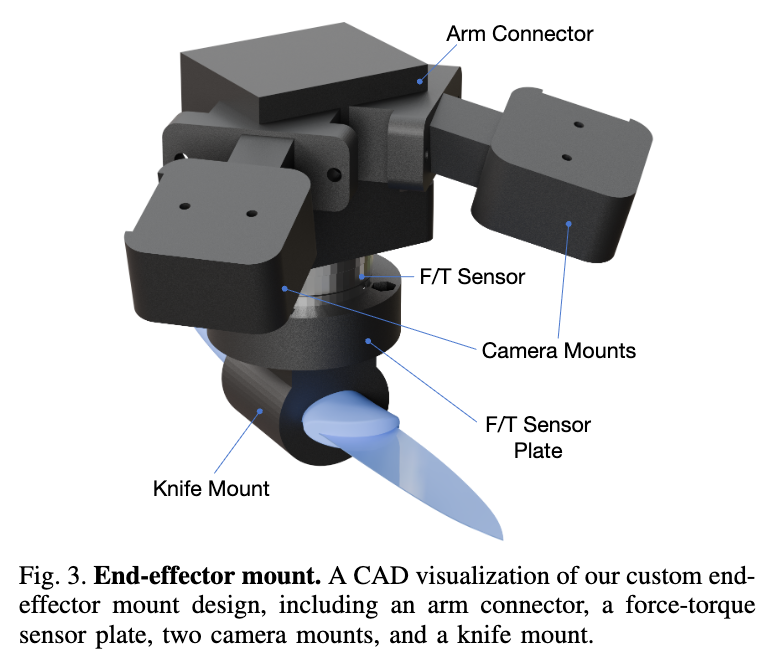
하드웨어는 Kinova Gen3 (7-DoF)를 사용했다고 합니다. Torque-control이 가능해 impedance controller를 사용할 수 있어서 선택했다고 하네요. Tool flange와 엔드 이펙터 사이에 ATI mini45를 통해 500 Hz로 force 정보를 전달받았다고 합니다. 이외로는 위 Fig3와 같이 D405를 두 개 부착하고 칼을 안정적으로 끼워넣을 수 있는 마운트를 CAD 모델로 제작했다고 하네요. 최근 그리퍼를 사용해 물체를 잡고 tool 사용을 하면 F/T sensor의 데이터를 100프로 활용할 수 없다는 글을 봤었는데 그 때문인가 싶기도 합니다.
로봇 제어는 Kinova Gen3 arm을 500Hz로 low-level impedance control해 python control command를 10Hz로 보냈다고 합니다. 해당 compliant-control 연구와 TidyBot 연구를 가져다 썼다고 합니다. 아래와 같이 파라미터들을 공유하기는 했는데, impedance control을 잘 몰라서 우선 공유만 해두겠습니다,,

Data Collection and Policy Training
해당 내용은 base policy를 학습 하는 과정입니다.
Infrastructure
저자들은 고품질 peeling 데이터를 수집하기 위해 사람이 3D SpaceMouse로 Kinova를 직접 조작했다고 합니다. 이 때 weighted least-squares IK solver를 따로 설계해서 관절 움직임을 매끄럽게 만들었다고 합니다. 해당 solver는 모든 관절을 똑같이 다루지 않고, 큰 leverage를 만드는 proximal joint는 덜 쓰고, elbow/wrist 같은 distal joint를 더 선호하도록 adaptive weight를 둔다고 하네요. 여기에 null-space projector를 추가해 jitter가 생기지 않게 했다고 합니다. 이렇게 해서 joint state, force-torque, 두 wrist camera (D405)의 RGB-D를 10Hz로 수집했다고 합니다.
저자들은 단순히 EE를 움직여가며 teleoperation 하는 것이 아니라 부드럽고 일관된 cartesian motion이 필요했기 때문에, 기존의 단순한 task와는 다르게 policy 학습을 위한 trajectory quality engineering이 추가로 필요했따고 합니다. Fine grained manipulation에서는 미세한 각도나 접촉 정도에 따라서 작업 성공여부가 갈리기 때문에 data quality자체도 매우 중요하고, 이를 위해 설계된 IK solver와 같은 데이터 취득 파이프라인 또한 method의 일부라고 주장합니다.
Data Processing
저자들은 고품질로 취득한 데이터 뿐 만 아니라 잘 가공된 observation 또한 매우 중요하다고 합니다. Contact rich 하고 adaptive한 policy를 위해서는 올바르게 가공된 observation이 필수적이라고 하고, raw RGB나 force는 불필요한 정보를 모델이 같이 학습하기 때문에 task-specific한 데이터 processing이 필요하다고 합니다.
저자들은 수집한 raw sensor data를 그대로 데이터에 넣지 않고, peeling에 필요한 정보만 남도록 observation을 실시간 processing 합니다. F/T 신호는 초기 10개 샘플의 평균을 빼서 표준화함으로써, 센서의 고정 bias보다 실제 접촉 중 발생하는 힘 변화에 집중하게 만들어 준다고 합니다. 이미지 입력은 SAM2를 online으로 실행하며 취득해 knife와 object를 각각 분리된 mask로 segmentation하여, 모델이 배경이나 불필요한 texture가 아니라 칼과 대상의 관계에 집중하도록 설계했다고 합니다. 마지막으로 proprioception은 end-effector frame 기준의 delta pose로 기록합니다. 이러한 구조가 arbitrary base position에 대한 일반화에 유리하다는 것이 기존 연구들을 통해 거의 굳혀졌다고 합니다. 이렇게 모델이 봐야 할 정보를 줄이고 조작의 본질적인 구조를 더 잘 보이게 만드는 representation design이 필수적이라고 합니다.
Training and Inference
모델 학습 단계에서도 저자들의 설계가 들어가있는 것을 볼 수 있습니다. 학습할 때 먼저 컬러 RGB는 grayscale로 변환하고, depth는 knife/object segmentation mask를 통해 masking해서 접촉과 관련된 geometry 정보만 남긴다고 합니다. 이렇게 처리한 RGB와 depth에 random crop augmentation을 적용하고, force-torque 신호는 [-1, 1] 범위로 정규화해서 학습한다고 하네요. 학습은 Diffusion policy를 이용해 진행되고 vision 정보는 ResNet으로, force 정보는 MLP로 인코딩한 뒤 액션 생성을 한다고 합니다. Contact-rich 한 작업은 texture가 중요하지 않고 칼과 표면의 기하 관계와 접촉 상태를 읽어야 하는 작업이기 때문이라고 하네요. 뒤에 보면 ablation에서도 grayscale RGB가 성능이 진짜 더 좋은데 생각해보지 못 한 접근이라 신선했습니다. 확실히 어떻게 모델을 설계하는지도 매우 중요한 것 같습니다.
Policy Finetuning with Preference-based Reward
Base Policy를 학습한 다음에는 reward를 설정해 모델을 finetuning해줍니다. 해당 부분에서 칼로 껍질 깎기와 같은 연속적이고 정량화하기 애매한 task에 대해서 어떻게 reward를 줄것인가에 대한 인사이트 위주로 보시면 될 것 같습니다.
Reward design
저자들은 knife peeling의 품질을 하나의 objective metric으로 정의할 수 없다고 정의합니다. 실제로 사람은 peel thickness뿐 아니라, peel이 얼마나 길고 얇게 이어졌는지, 중간에 끊기거나 울퉁불퉁하지는 않은지, 전체적으로 얼마나 깔끔해 보이는지를 함께 보고 판단하기 때문이라고 합니다. 실제로 제가 사과 깎은걸 생각해보면 엄마가 깎은거랑은 껍질의 두께나 매끄러움이 좀 차이가 많이 났던 것 같습니다,, ㅋㅋ. 저자들은 여기서 문제가 이 기준들이 모두 같은 성격이 아니라는 점이라고 합니다. Peel thickness는 비교적 기하학적으로 해석 가능한 반면, visual uniformity나 continuity 같은 요소는 본질적으로 holistic하며 인간의 지각적 판단에 크게 의존합니다. 그래서 저자들은 이 문제를 하나의 reward로 뭉개지 않고, quantitative component와 qualitative component를 결합한 hybrid reward로 설계합니다. 용접이나 샌딩에서도 같은 방식으로 reward 설정이 가능하지 않을까…? 싶기도 하네요. Reward는 policy를 실행하며 모은 데이터에 직접 annotation하는 정보를 통해 계산되는 offline 방식으로 진행됩니다.
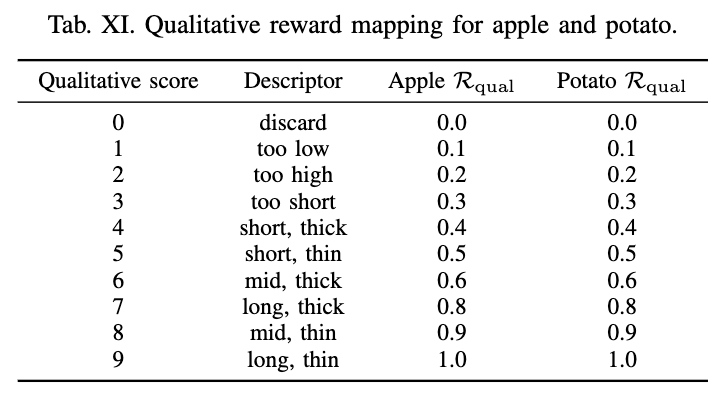
먼저 quantitative component는 local peel thickness를 반영합니다. 각 peeling trajectory를 2Hz로 쪼개준 뒤, 각 segment마다 두께를 6개 카테고리로 라벨링합니다. Nominal thickness가 가장 바람직하고, 그보다 너무 얇거나 두꺼운 경우는 더 낮은 보상을 설정했습니다. 여기서 중요한 점은 이 값이 segment-level에서 정의된 뒤 per-step reward로 설정된다는 것이라고 합니다. 즉, 정책이 단순히 “이번 trajectory가 전체적으로 좋았다”가 아니라, 어느 구간에서 칼이 적절한 두께로 들어갔는지를 더 직접적으로 배울 수 있다고 하네요. 아래 Table X를 보면 apple과 potato에 대해 reward 값을 다르게 두는데, 이는 같은 두께 범주라도 허용 가능한 품질 기준이 다르기 때문에 객체 카테고리마다 따로 부여했다고 합니다. 각 상태가 어떤지는 Fig 5로 확인할 수 있습니다.


Qualitative component는 trajectory 전체의 시각적 품질을 반영합니다. 저자들은 continuity, smoothness, overall naturalness 같은 요소는 local metric으로 표현하기 어렵다고 보고, 각 trajectory에 대해 0에서 9까지의 Likert-style ordinal score를 부여했다고 합니다. Likert-style은 사람의 주관을 평가할 때 쓰는 척도라고 하는데, 저자들이 0~9 범위의 정수로만 세팅해두었기 때문에 그냥 0점부터 9점이라고 생각해도 될 것 같습니다. Figure 4를 보면 0은 discard, 9는 long, thin에 해당하며, 중간 점수들은 too short, short-thick, mid-thin처럼 길이와 두께, 연속성을 함께 반영하는 형태로 구성되어 있습니다. 이를 통해 사람들이 “아 이정도면 잘된거지”를 점수화 했습니다.
최종 reward는 quantitative, qualitative score를 weighted sum해서 per-step signal로 만듭니다. Quantitative reward는 segment-level 값이므로 그 segment 안의 모든 frame에 동일하게 할당되고, 인접 segment 경계에서는 갑작스러운 불연속을 줄이기 위해 overlap 구간에 선형 smoothing을 넣어준다고 합니다. Qualitative reward는 trajectory-level 점수이므로 정규화된 scalar로 바뀐 뒤 전체 trajectory에 걸친 global quality prior처럼 작동합니다.이 때 quantitative quality가 너무 낮은 경우에는 qualitative score가 그걸 가리는 것을 막기위해 thresholding을 진행한다고 합니다. 따라서 전체적으로 보기 좋아 보여도 peel thickness가 명백히 잘못되었다면 높은 reward를 주지 않는 설계입니다. 이를 통해서 그냥 잘해보이는, 매끄러워 보이는 그럴듯한 policy가 아니라, 정확하고 자연스러운 policy를 설계했다고 합니다.
아래 combined reward 식을 예시와 살펴보면, apple에서는 below nominal이 0.3, nominal이 1.0, slightly above nominal이 0.8, above nominal이 0.3, excessive와 N/A가 0.0입니다. qualitative reward는 0~9 점수를 0.0~1.0으로 정규화하며, 0.1 간격으로 설정했습니다. 최종 reward 식에서 R_quant가 임계값 τ보다 작으면 그대로 quantitative reward만 사용하고, 그렇지 않으면 α * R_quant + (1-α) * R_qual을 사용합니다.
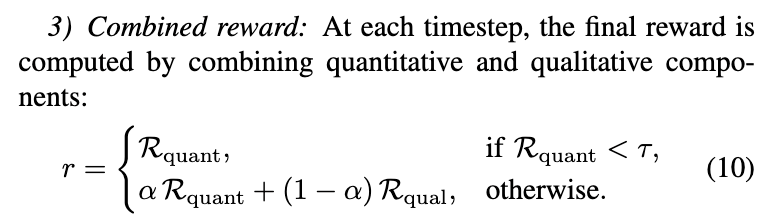
가장 핵심 중에 하나인 reward design은 local geometry와 global perception을 동시에 반영하는 설계라고 생각하면 될 것 같ㅎ습니다. Local thickness만 쓰면 continuity와 naturalness를 놓치고, trajectory 전체 점수만 쓰면 어떤 순간의 행동이 좋았는지 학습하기 어렵기 때문에 저자들은 이 둘을 분리하고 weighted sum으로 결합해 애매한 human preference를 정책을 실제로 finetuning할 수 있는 dense reward로 바꾸었습니다.
Reward-guided policy finetuning
Base policy를 학습한 후에는 residual policy를 올려서 human preference를 반영합니다. 이 때의 신호를 offline human annotation으로 학습한 reward model이 진행합니다. Base policy가 돌아갈 때 미세한 조정을 residual policy가 진행한다고 생각하면 될 것 같습니다. 핵심은 preference alignment를 RL처럼 직접 policy 자체에 넣는게 아니라 base policy가 있고, 그 위에서 인간 선호를 반영한 작은 correction만 학습합니다.
먼저 reward model이 존재합니다. Reward model은 state-action pair가 human preference 관점에서 얼마나 좋은지를 예측합니다. 아래 (1) 식에서 a_t는 offline dataset에 기록된 action이고, z_t는 frozen base policy의 observation encoder가 만든 latent feature입니다. 즉 reward model은 raw image나 raw force를 직접 보는 것이 아니라, base policy가 이미 압축해 놓은 latent representation 에서 “이 행동이 사람이 보기엔 얼마나 좋은가”에 대한 값을 예측합니다. 구조는 3개 레이어의 MLP이고, 학습 목표는 raw human annotation으로부터 만든 normalized reward r_t와 오차를 줄이는 MSE입니다.
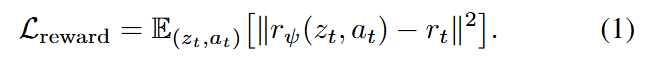
Residual policy는 2개 레이어의 MLP이고 입력으로 base policy의 latent feature, action, reward model의 hidden representation을 받아 출력으로 residual action을 뱉습니다. 간단하게 얼마나 보정해야 하는가?에 대한 정도입니다. 여기서 중요한 포인트는 reward model의 중간 hidden representation을 함께 사용하는 것이라고 합니다. 단순 스칼라 값 하나로는 다 담기지 않는 human preference의 구조적인 측면을 반영하기 위해 왜 그 점수가 높거나 낮은지에 해당하는 어떤 내부 패턴을 residual policy에 condition으로 넘겨주는 것이라고 합니다.
학습은 아래 (2)번 식의 loss로 학습합니다. Objective는 residual policy는 dataset action과 base action의 차이 (a_t – a_t^{base})를 목표로 삼아 behavioral cloning을 수행하되, 모든 샘플을 동일하게 취급하지 않는다고 합니다. 인간 선호가 높은 step일수록 더 큰 가중치 w_t를 주는 reward-weighted behavioral cloning을 사용해, 사람이 더 좋다고 평가한 correction을 더 강하게 모방하게 합니다. w_t의 경우에는 아래 (3)번 식과 같은데요, reward가 높은 step일수록 exponential하게 큰 비중을 줘서 human preference를 더 반영하게 만들고, 베타 값이 temperature 같은 역할을 한다고 보면 될 것 같습니다.
또 residual magnitude에 대한 regularization 항 (오른쪽 항)을 넣어 correction이 지나치게 커지는 것을 막습니다. 정리하면 좋은 correction은 더 많이 따라하고, 그렇지만 correction 자체는 너무 과하지 않게 학습한다고 보시면 될 것 같습니다.
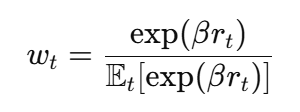
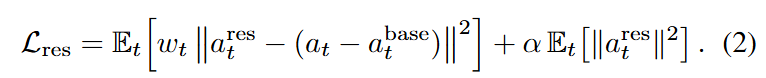
저자들은 이 finetuning 방식의 핵심이 human preference를 RL로 직접 policy 자체를 업데이트 하지 않고, offline reward modeling + weighted supervised correction으로 바꾼 것이라고 합니다.
Experiments
Task definition, Evaluation metrics
저자들은 knife peeling을 단순 성공/실패가 아니라 얇고 일정한 두께로, 끊김 없이, 살을 최소한으로 손상시키며 벗겨내는 것을 목표로 하는 퀄리티 중심의 조작 문제로 정의했습니다. 또한 다양한 모양들 사이에서 비교가 가능하도록, 한 번의 peel을 single stroke로 정의하고, 여러 stroke를 거쳐 한쪽 면을 완전히 깎는 과정을 하나의 trial로 정의했습니다. 오이, 사과, 감자로 각각 50, 150, 200개의 데모를 모아서 학습했다고 합니다.
Evaluation은 껍데기의 길이, 두께, 연속성을 사람의 관점에서 종합적으로 판단한 qualitative score와 onboard sensing으로 추정한 peel thickness를 반영하는 quantitative score입니다. 최종 success rate는 qualitative score가 3을 넘는 경우 (위 fig 4에서 4점부터) 를 성공으로 간주해서 계산했다고 합니다. 각 score의 기준은 위 figure 4,5이빈다.
Overall performance
오이, 사과, 감자 모두 학습 이후 동일 카테고리 내의 새로운 작물에 대해서는 100%의 success rate를 보였다고 합니다. 또 각각 애호박, 배, 순무 (좀 비슷하게 생긴 작물들)에서 각각 50%, 90%, 80%의 성공률을 보였다고 합니다. 아래부터는 저자들이 전체 파이프라인을 구성함에 있어 진행한 ablation들 입니다.
Comparison of data collection methods
저자들은 고품질 peeling demonstration을 어떻게 모을 수 있는지 확인하기 위해, SpaceMouse 기반 텔레오퍼레이션을 다른 세 가지 방법과 비교했습니다. 비교 대상은 시각 기반 heuristic planner, VR 기반 teleoperation, 그리고 kinesthetic teaching 후 heuristic 기반 compliance parameter로 replay하는 방식입니다. 평가는 각 방법으로 수집한 오이 peeling trajectory 10개에 대해 qualitative metric을 적용해 수행하며 결과는 아래 table 1과 같습니다.
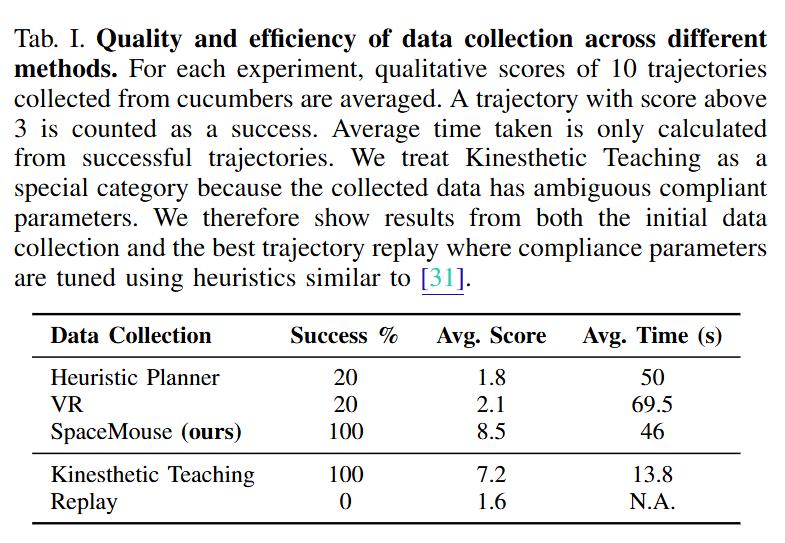
Heuristic planner는 calibrated L515 LiDAR 카메라로 RGB-D를 얻고, 물체의 segmented point cloud를 만든 뒤, 표면 위에 20개의 waypoint를 따라 dense trajectory를 planning 하고 각 waypoint의 surface normal로부터 desired knife pose trajectory를 계산하고, 이를 IK로 joint trajectory로 변환했다고 합니다. 저자들은 이 planner가 물체 형상과 표면 특성이 크게 달라지는 현실적 조건에서는 적응하지 못 한다고 합니다. Peeling처럼 접촉 상태와 표면 특성이 계속 바뀌는 작업에서는 learning-based로 접근해야 한다고 하네요.
VR 기반 텔레오퍼레이션은 직관적으로는 더 몰입감 있고 자연스러워 보일 수 있지만, 실제 peeling에서는 tracking noise 때문에 정교한 움직임이 불가능 했다고 합니다. Kinesthetic teaching은 사람이 직접 로봇을 움직여 position trajectory를 수집하고, 그 다음 heuristic 하게 compliance parameter를 조정해 trajectory replay를 수행했다고 합니다. Parameter tuning 이후에도 replay 성공률은 0%였는데, 이는 produce 표면의 복잡한 변화 때문에 demonstration 당시의 compliance를 단순 heuristic tuning으로 복원하기 어렵기 때문이라고 합니다.
SpaceMouse 기반 텔레오퍼레이션은 별도의 adaptive compliance나 haptic feedback 없이도 고품질, 고성공률의 peeling data를 안정적으로 수집할 수 있었다고 합니다. 저자들은 단순한 입력 장치와 잘 설계된 IK만으로도, surprisingly하게 fine-grained manipulation에서 좋은 데이터 수집 성능을 얻었다고 합니다.
How to learn high-performance peeling policies?
정밀하고 힘에 민감한 작업에서, 어떤 관측 설계와 어떤 데이터 규모가 실제로 잘 작동하는 정책을 만드는지에 대한 ablation이 카메라 배치, 입력 모달리티, 데이터 개수로 정리돼있습니다. 먼저 observation과 action space 입니다. 로봇이 칼과 물체의 접촉 상태를 읽고 그에 맞춰 힘과 자세를 미세하게 조정해야 하므로, “무엇을 입력으로 줄 것인가”가 정책 성능을 크게 좌우했다고 합니다. 따라서 “두 개의 wrist camera 중 어떤 시점이 더 유용한가”와 “vision, depth, force를 어떤 조합으로 써야 하는가”에 대한 실험을 진행했습니다.
카메라 시점에 대한 ablation 입니다. 저자들은 end-effector mount에 두 개의 wrist camera를 달아 한 카메라는 항상 현재 peeling 직전의 knife–object view를, 다른 카메라는 peeling 직후의 view를 보게 설계했다고 합니다. 결과를 보면 Table 2와 같이 둘 다 사용했을 때 success rate 80%, average score 5.9였고, before only는 success rate 100% 지만 average score는 4.8, after only는 success rate 60%, average score 3.2였습니다. 단순 성공률만 보면 before-only가 더 높게 보이지만, 전체 peel 품질까지 포함한 평균 점수 기준으로는 두 카메라를 함께 쓰는 구성이 가장 좋았다고 합니다. 저자들은 이를 두 카메라를 모두 사용했을 때 암묵적인 3D 정보를 제공하기 때문이라고 합니다. 동시에 before camera가 after camera보다 더 중요하게 작동한 이유는, 곡선을 띄는 물체에서는 before view가 칼날과 물체의 접촉을 더 덜 가린 상태로 보기 때문이라고 합니다.
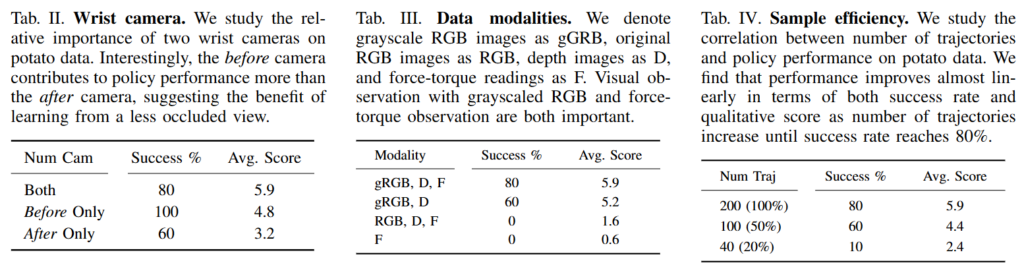
입력 데이터 modality에 대한 결과는 위 table 3와 같이 gRGB + Depth + Force는 success rate 80%, average score 5.9를 기록했고, 여기서 Force를 제거한 경우 60%, 5.2로 떨어졌습니다. 반대로 원본 RGB + Depth + Force는 success rate 0%, average score 1.6으로 하락했고, force만 사용한 경우도 0%, 0.6으로 나왔습니다. 결과가 뭔가 이렇게까지 차이가 나나.. 싶은데 우선 확실한 것은 vision과 force를 함께 써야 한다는 점입니다. 또 vision observation에 대해 grayscale RGB를 사용하는 것이 훨씬 더 유리하다는 점을 볼 수 있습니다. 저자들은 grayscale이 texture나 색에 대한 과적합을 줄이고, policy가 물체의 질감보다 geometry에 집중하게 만들기 때문이라고 합니다. 정밀 작업에서는 기하 정보가 중요한 것 같습니다.
마지막으로 sample efficiency의 경우 위 table 4와 같습니다. 물체 종류에 따라 필요한 데이터 양은 다르지만, 전체적으로 knife peeling 같은 어려운 작업도 200 개 수준의 real-world trajectory로 충분히 학습이 가능했다고 합니다.
How to Align Learned Policies with Human Preference?
먼저 baseline 비교부터 보면, ours는 quantitative reward와 qualitative reward를 함께 사용한 preference-based finetuning입니다. 비교 대상은 finetuning을 하지 않은 Base Only, quantitative reward만 사용한 경우, qualitative reward만 사용한 경우, 그리고 critic을 학습해 advantage-weighted supervised finetuning을 수행하는 IQL-weighted입니다.
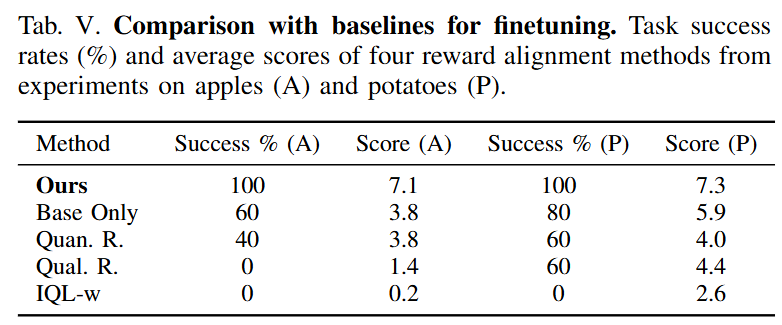
Table 5를 보면 저자들이 제안한 방법은 apple과 potato 모두에서 100% success를 기록했고, 평균 qualitative score도 각각 7.1, 7.3으로 가장 높았습니다. IQL-weighted (Offline RL)는 apple 0%, 0.2, potato 0%, 2.6으로 가장 나빴습니다. 저자들은 자기들의 방식이 critic-guided offline RL보다 더 안정적이고 cost도 낮다고 주장합니다. 아래와 같이 정성적으로도 확인해볼 수 있습니다.

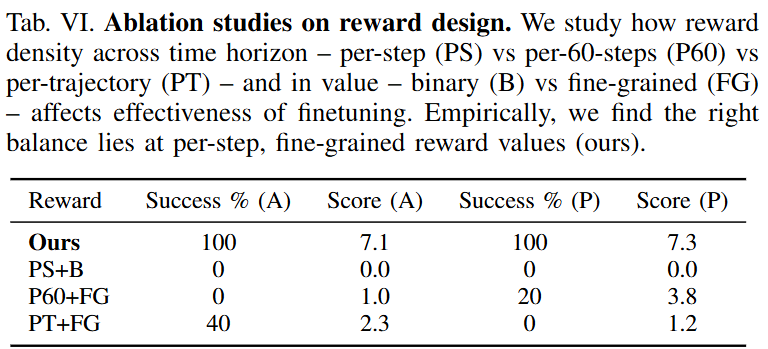
그다음 저자들은 human preference score를 어떤 빈도로 설계해야 하는가에 대한 실험을 진행했습니다. 비교하는 축은 두 가지입니다. 첫째는 시간축 입니다. Reward를 per-step, per-60-steps, per-trajectory 중 어느 수준으로 줄 것인가입니다. 두번쨰는 reward를 binary로 줄 것인가, 아니면 fine-grained하게 줄 것인가입니다. 결과를 보면 저자들의 방법론과 달리 per-step + binary는 두 task 모두 0%, 0.0으로 완전히 실패했고, per-60-steps + fine-grained도 apple 0%, 1.0, potato 20%, 3.8의 성능이 나왔습니다. Per-trajectory + fine-grained 역시 apple 40%, 2.3, potato 0%, 1.2로 낮았습니다. 중요한 것은 human preference를 policy가 실제로 학습할 수 있을 만큼 촘촘하게, fine grained하게 reward를 설정해야 하는 것 같습니다.
또 저자들은 학습된 reward model을 policy 개선에 어떻게 사용할 것인가도 비교했습니다. 저자들이 제안한reward-weighted behavioral cloning을 수행하는 방식과 trajectory 평균을 baseline으로 두고 A_t = r_t − b_τ 형태의 one-step advantage를 만드는 방식과 높은 점수의 step만 threshold로 남기는 binary filtering과 비교했습니다. 단순히 좋은 샘플만 hard-select하는 방식이나, trajectory 중심 baseline을 빼서 local advantage를 만드는 방식들 보다는 raw reward를 부드러운 가중치로 직접 사용하는 저자들의 exponential weighting 방식이 가장 안정적이고 효과적이었다고 합니다.
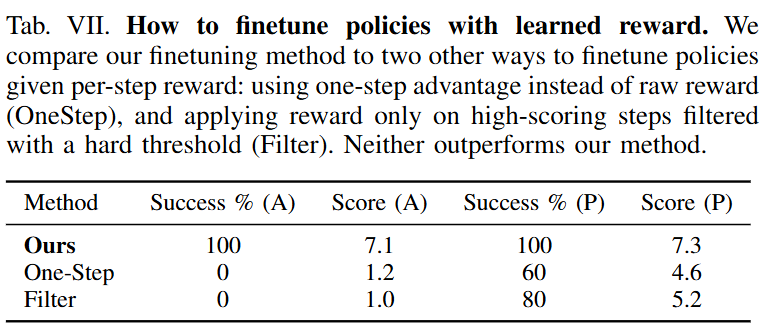
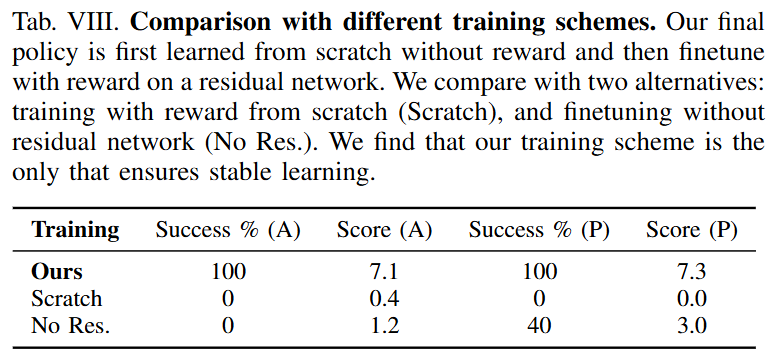
마지막으로는 residual network의 필요성과 2-stage 학습의 효과를 보여주는 실험입니다. 둘 다 적용했을 때 100%인 반면 residual network를 처음부터 같이 학습하거나 없이 사용하는 경우에는 SR이 0입니다. 2-stage로 학습하는 것이 의미가 있는 것 같습니다. RL의 성능이 안 나온 이유랑 비슷한 것 같은데 이미 잘 학습된 base policy의 지식을 해치는 건가? 싶습니다.
영규님 좋은 리뷰 감사합니다.
확실히 과일깎기와 같은 작업은 시뮬레이션으로 구현하는 것도 너무 어렵기 때문에 사람의 비디오를 이용하는 접근 방식이 가장 합리적인 것 같습니다.
해당 논문과 관련한 질문이 있습니다.
1. 고품질 데이터 수집 방식으로 3D SpaceMouse를 사용했다고 하셨는데, 실제 물체를 다룰 때처럼 사람이 직접 힘을 가하는 방식이 아니기 때문에 작업이 부정확해질 가능성도 있을 것 같습니다. 데이터 수집 과정에서 힘(force) 정보에 대한 피드백을 제공하는 등의 추가적인 보정 과정이 있었는지 궁금합니다. 만약 이러한 과정이 없다면, 저자들이 언급한 것처럼 질적으로 ‘잘 깎인’ 데이터를 수집했다고 볼 수 있는지에 대해서는 다소 의문이 듭니다. 논문에서는 껍질의 두께를 측정하는 방식으로 결과를 평가한 것으로 보이는데, 이러한 기준이 데이터 품질을 확인하는 과정에도 사용되었는지 궁금합니다.
2. 저자들이 texture 정보가 중요하지 않다고 보고 학습 과정에 컬러 RGB를 RGB로 변환하여 이용한 것으로 이해하였는데, 그렇다면 차라리 RGB 정보를 사용하지 않고 depth 정보만을 사용하는 게 더 좋은 게 아닌가 하는 생각이 듭니다. Table 3이 이에 해당하는 실험결과로 보이는데, {D,F}로 구성된 실험은 따로 없어보이는데, 혹시 이에 대한 다른 설명은 없었는 지 궁금합니다.