최근 ICML 피어 리뷰 중, 리뷰할 논문이 이 논문을 베이스로 삼았다는 것을 보았습니다. 그동안은 핵심 아이디어만 대략적으로 알고 있었는데, 이번 기회에 꼼꼼히 읽어봤고 해당 내용을 리뷰로 남겨두려고 합니다.

- Venue: ICLR 2023
- Authors: Hongwei Xue, Yuchong Sun, Bei Liu, Jianlong Fu, Ruihua Song, Houqiang Li, Jiebo Luo
- Affiliation: University of Science and Technology of China, Renmin University of China, Microsoft Research, University of Rocheste
- Title: CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Langauge Alignment
- Code: GitHub
1. Introduction
CLIP은 대규모 image-text pair로 학습되어 이미지-텍스트 정렬 능력이 매우 강합니다. 그래서 많은 video-text retrieval 연구들이 CLIP을 가져와서 각 프레임 feature를 평균 내거나, 간단한 temporal 모듈만 붙여도 꽤 좋은 성능을 얻었습니다.
그런데 정작 “그렇게 좋은 CLIP을 가지고, 대규모 video-text 데이터로 한 번 더 pretrain하면 더 좋아져야 하는 것 아닌가?”라는 질문에는, 기존 결과가 생각보다 큰 이득을 보여주지 못했다는 점이 문제였습니다. 논문은 바로 이 지점을 문제로 삼았습니다. 즉, 왜 CLIP을 video-text 데이터로 추가 학습시키는 것이 기대만큼 잘 안 되는가, 그리고 그걸 어떻게 해결할 것인가가 핵심이었죠
저자들은 이 실패 원인을 크게 두 가지로 정리하였습니다.
첫째는 데이터 스케일 문제입니다. 작은 video-text 데이터로 CLIP을 추가 학습시키면, 원래 CLIP이 image-text에서 배운 풍부한 지식을 유지하는 것이 아니라 새 데이터에 과적합하면서 오히려 성능이 떨어질 수 있다고 봤습니다.
둘째는 언어 도메인 갭입니다. 대규모 video pretraining 데이터는 흔히 subtitle 기반인데, downstream retrieval 벤치마크들은 보통 video caption처럼 “설명문 (caption)” 스타일 텍스트를 씁니다. 즉, pretraining text와 downstream text의 성격이 꽤 다르다는 것입니다
이 두 문제를 해결하기 위해 제안한 것이 바로 CLIP-ViP이고, 방법론은 크게 두 축입니다.
- Video Proxy mechanism: CLIP의 ViT를 비디오에 맞게 최소 수정으로 확장
- Omnisource Cross-modal Learning (OCL): subtitle과 auxiliary caption을 함께 쓰는 학습 전략
자세한 방법론은 이제 다음 섹션에서 다뤄보도록 하겠습니다!
2. Preliminary Analysis
앞서 저자들은, CLIP을 비디오-텍스트 데이터로 한번 더 pre-train했을 때 기대만큼 잘 되지 않는 이유를 1) 데이터 스케일 문제 2) 언어 도메인 갭 문제로 언급하였는데요. 그렇게 주장한 근거를 먼저 살펴보겠습니다.
2.1 데이터 스케일 문제
저자들은 CLIP-ViT-B/32를 베이스로 두고, CLIP4Clip처럼 프레임 feature를 평균내는 MeanPooling 방식으로 post-pretraining을 해보았는데, 서로 다른 규모의 아래 세 가지 데이터셋으로 학습한 실험을 먼저 보여주었습니다.
- WebVid-2.5M
- HD-VILA-10M
- HD-VILA-100M
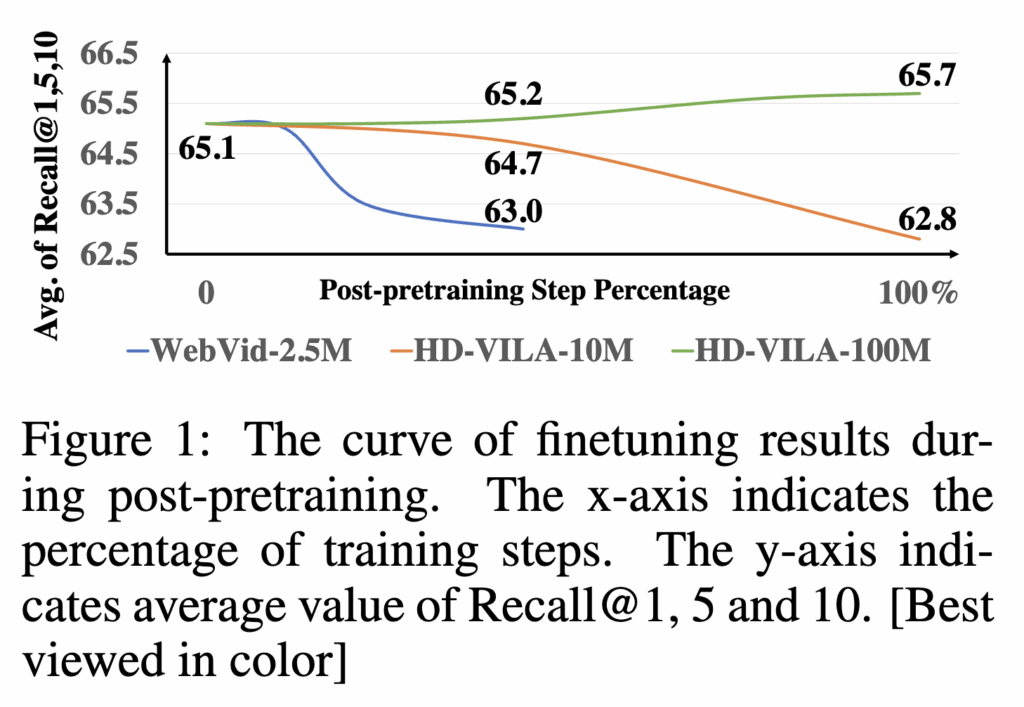
그 결과는 상단 그림 1에서 확인할 수 있었습니다. 작은 데이터셋에서는 post-pretraining을 오래 할수록 downstream fine-tuning 성능이 오히려 떨어졌습니다. 즉, CLIP이 이미 4억 개 image-text pair로 학습되어 있는데, 작은 video-text 데이터로 더 학습시키면 video domain adaptation이 되는 게 아니라 오히려 기존 CLIP knowledge가 망가지는 방향으로 갈 수 있다는 것입니다. 그래서 이 논문은 대규모의 Video-Text 데이터셋인 HD-VILA-100M을 사용하였습니다.
2.2 언어 도메인 갭 문제
subtitle – caption 이라는 텍스트 형태의 차이도 그 원인 중 하나라고 저자들은 분석했었는데요. 이를 측정하기 위해 저자들은 CLIP text encoder feature를 이용해 언어 도메인 갭을 NMI로 측정해보았습니다.
NMI (Normalized Mutual Information) 측정 방법
1. pretraining text와 downstream text의 feature를 뽑기
2. 둘을 섞어서 K-means로 2개 클러스터로 나누기
3. 클러스터 라벨과 실제 데이터 출처 라벨(pretraining인지 downstream인지) 사이의 NMI 계산
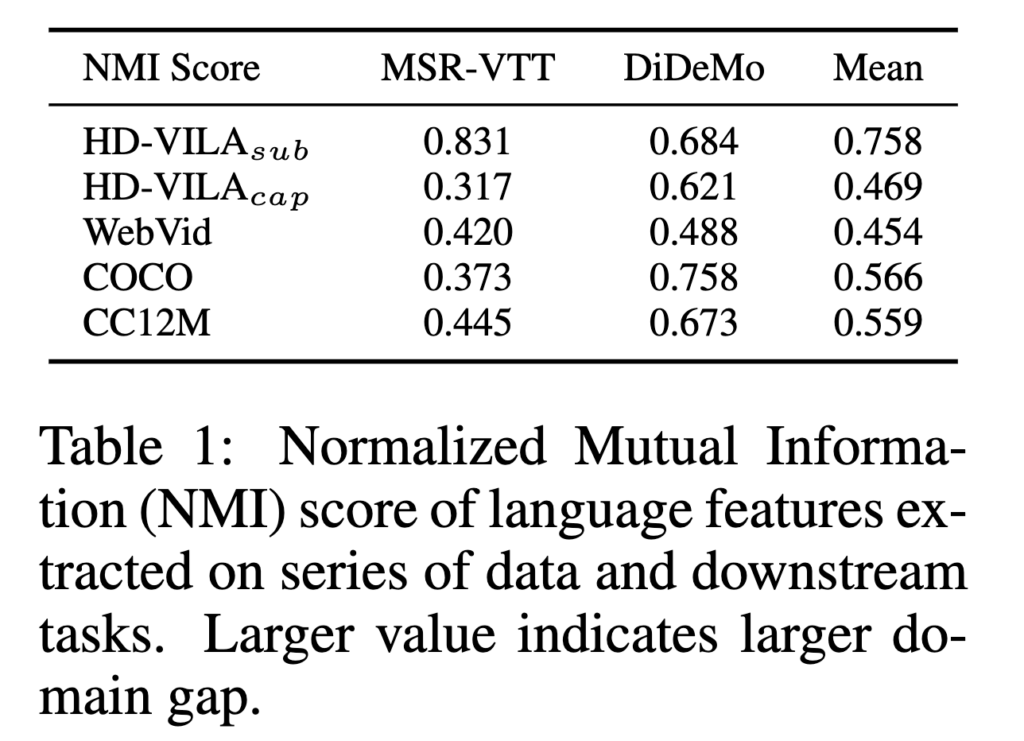
NMI가 크다는 건 feature space에서 두 그룹이 잘 구분된다는 뜻이고, 즉 언어 도메인 갭이 크다고 해석합니다. 결과적으로 표 1을 통해, HD-VILA subtitle은 downstream retrieval 데이터(MSR-VTT, DiDeMo)와의 NMI가 가장 컸고, 이는 subtitle이 downstream descriptive caption과 스타일이 다름을 보여줍니다. 반면 caption류 데이터는 도메인 갭이 더 작았습니다.
결과적으로 저자들은 그림 1과 표 1의 실험을 통해, 기존에 제기되었던 “왜 비디오 데이터로 추가 학습을 해도 성능 향상이 뚜렷하지 않은가?”에 대한 해답을 ‘부족한 데이터 스케일’과 ‘Subtitle과 Caption 간의 언어적 도메인 갭’이라는 두 가지 원인으로 규명했습니다. 즉, 이 두 가지 걸림돌을 해결해야만 CLIP의 강력한 성능을 비디오 도메인으로 온전히 가져올 수 있다는 것이죠.
3. Method
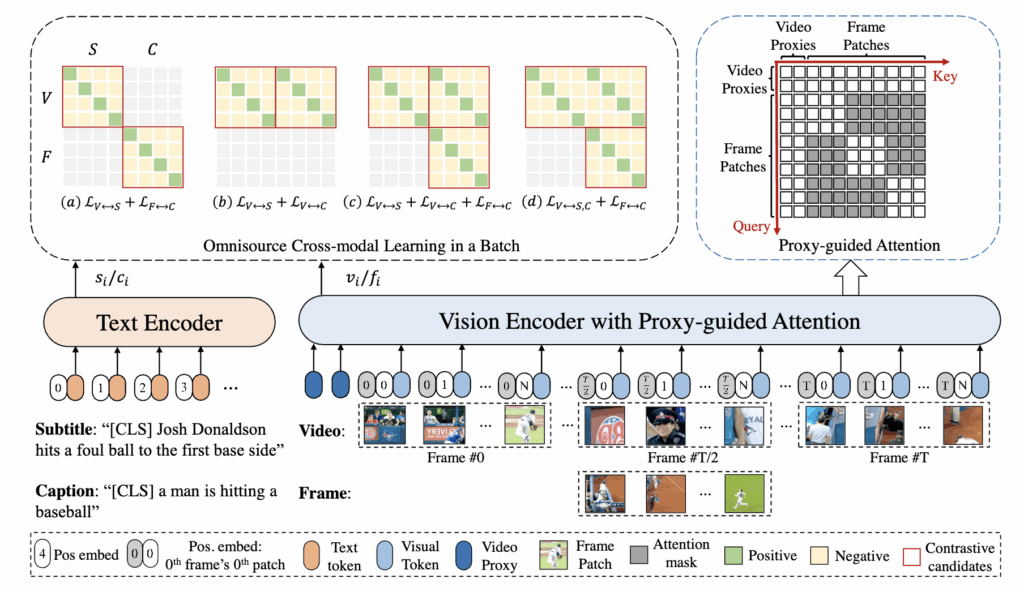
전체 프레임워크는 Figure 2에 잘 나와 있습니다. 입력은 네 종류입니다.
- V: 비디오
- F: 비디오의 middle frame (이미지겠죠?)
- S: subtitle (원래 비디오-텍스트 데이터셋의 텍스트)
- C: auxiliary caption
그리고 이들을 text encoder와 vision encoder에 넣어 여러 contrastive loss를 조합해 학습합니다. 여기서 핵심은 vision encoder 쪽의 Video Proxy와 learning objective 쪽의 Omnisource Cross-modal Learning이라고 합니다.
3.1 Auxiliary data generation
언어 도메인 갭을 줄이기 위해 저자들은 HD-VILA-100M 각 비디오에 대해 middle frame 하나를 뽑아 image captioning 모델로 caption을 생성합니다. 여기서 video captioning 모델이 아니라 image captioning 모델(OFA-Caption)을 사용한 이유는 두 가지라고 합니다.
- SOTA video captioning 모델은 MSR-VTT, ActivityNet 같은 downstream dataset 위에서 학습된 경우가 많아서 data leakage 우려가 있음
- 당시에는 image captioning 모델이 video captioning 모델보다 더 강하다고 판단
그래서 HD-VILA의 각 비디오에 대해 길이 최대 16단어인 caption 1개를 생성합니다. 결국 원래 데이터는 (video, subtitle)이었는데, 여기에 (middle frame, generated caption)이 추가된 셈입니다. 이게 나중에 OCL의 두 번째 학습 소스가 됩니다.
3.2 Video Proxy mechanism
기본 입력 표현 방법
비디오가 T개의 frame으로 이루어졌다고 합시다. 각 frame은 다시 N개의 patch로 나뉩니다. 그러면 전체 비디오는 총 T \times N개의 patch token으로 표현됩니다. 그리고 각 patch token은 다음처럼 구성됩니다.
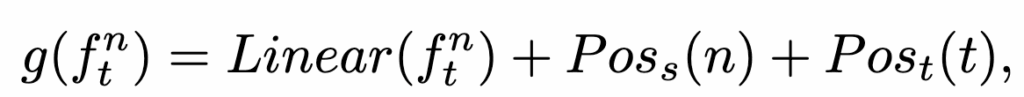
- patch 자체를 linear projection
- spatial positional embedding 추가
- temporal positional embedding 추가
이렇게 해서 frame 내 공간 위치와 frame 간 시간 위치를 모두 반영할 수 있게 도ㅣ었죠. 여기까지는 사실 video ViT에서 흔한 구성입니다. 중요한 건 그 다음 attention 구조입니다.
왜 full attention을 바로 못 쓰는가
가장 간단한 방법은, 모든 frame의 patch token을 한 줄로 펴서 CLIP의 vision encoder에 넣고 모든 토큰끼리 full attention을 하게 만드는 것입니다. 그런데 저자들은 이 학습 방식이 CLIP과 충돌한다고 봣습니다.
CLIP의 ViT는 원래 한 장의 이미지 내부 patch들 사이의 attention을 학습한 모델입니다. 그런데 비디오로 확장하면서 갑자기 “서로 다른 frame의 patch들끼리도 전부 직접 attention” 하게되면, CLIP이 학습한 inductive bias와 달라져서 오히려 불안정해진다는 주장입니다. 실제 ablation에서도 Full Attention은 성능이 떨어지기도 했구요
해결책, Video Proxy token
그래서 저자들은 learnable한 video proxy token P=\{p_1,\dots,p_M\}을 추가합니다. 비디오 patch token들 앞에 이 proxy token들을 붙여서 같이 ViT에 넣습니다. 그리고 첫 번째 proxy token의 출력을 비디오 전체 representation으로 사용합니다. (CLS 토큰 같이 N개의 learnable한 토큰을 추가하는 겁니다)
여기서 핵심은 attention mask입니다. 논문은 attention mask를 다음과 같이 정의합니다.
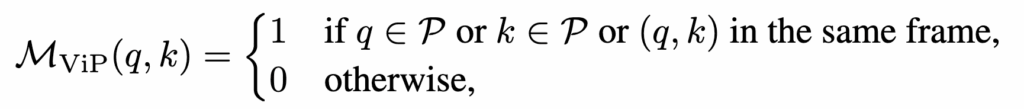
- proxy token은 모든 token을 볼 수 있음
- patch token은
- 같은 frame 안의 patch token들은 볼 수 있고
- proxy token은 볼 수 있지만
- 다른 frame의 일반 patch token은 직접 못 봄
즉, frame 간 정보 교환은 proxy를 통해서 간접적으로만 일어나는 것이죠.
저자는 이와 같은 설계를 통해, 같은 frame 내부의 spatial modeling은 CLIP이 하던 방식과 비슷하게 유지하고, cross-frame 정보는 proxy를 통해 집약하였다고 합니다. 그리하여 image-pretrained CLIP의 구조적 prior를 많이 깨지 않을 수 있었죠
3.3 OCL: Omnisource Cross-modal Learning
이제 objective입니다. 여기서 입력 modality/source는 4개입니다.
- V: video representation
- F: frame representation
- S: subtitle representation
- C: auxiliary caption representation
논문은 기본적으로 CLIP 스타일의 bidirectional InfoNCE를 씁니다.
기본 Loss
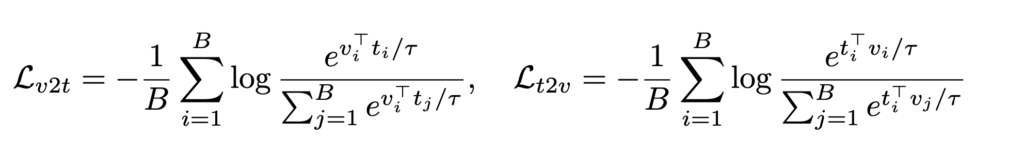
상단 수식은 Video-Text Retrieval 에서 사용하는 기본적인 Loss 입니다.
- v_i, t_i는 정규화된 embedding
- B는 batch size
- \tau는 learnable temperature
그리고 최종 L_{X \leftrightarrow Y}는 L_{v2t}와 L_{t2v}의 평균이죠
OCL Loss
저자들은 이 기본적인 Loss에 나아가 OCL LOSS를 추가 제안하엿는데요.
subtitle만으로 학습하면 도메인 갭이 크고, caption만으로 학습하면 video-scale supervision이 약합니다. 그래서 앞서 생성해낸 video-subtitle과 frame-caption을 함께 쓰자는 것이 OCL입니다. Loss 계산을 위한 조합은 여러가지가 나타날 수 있고, 저자는 총 4가지 조합에 대한 실험을 진행하였습니다
(a) L_{V\leftrightarrow S}+L_{F\leftrightarrow C}
- 비디오는 subtitle과 맞추고
- middle frame은 caption과 맞춤
(b) L_{V\leftrightarrow S}+L_{V\leftrightarrow C}
여기서는 “caption이 middle frame에만 해당하는 것이 아니라, 어느 정도는 video 전체와도 관련 있다”고 보고, video-caption loss를 추가합니다. 즉, caption을 비디오 수준 positive로도 사용합니다.
(c) L_{V\leftrightarrow S}+L_{V\leftrightarrow C}+L_{F\leftrightarrow C}
(a)와 (b)를 모두 합친 형태입니다.
(d) L_{V\leftrightarrow S,C}+L_{F\leftrightarrow C}
이게 저자가 최종적으로 선택한 조합인데요. 여기서는 비디오가 subtitle과 caption 둘 다와 연결된다고 보고, negative set을 더 확장하였습니다. 따라서 최종 Loss는 아래와 같습니다
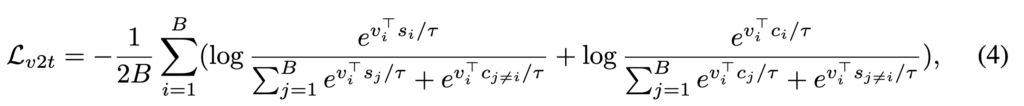
비디오 v_i에 대해 positive가 subtitle s_i 하나, caption c_i 하나 둘 다 존재하고, 나머지 subtitle/caption은 모두 negative처럼 취급되는 거죠. 그래서 한 소스 내 negative뿐 아니라 cross-source negative까지 넓혀 contrastive discrimination을 더 강하게 가져갈 수 있었다고 합니다.
즉, subtitle은 규모가 크고 비디오 전반을 담지만 noisy하고 downstream과 문체가 달랐고, caption은 downstream 문체에 가깝지만 비디오 전체를 충분히 설명하지 못할 수 있었습니다. 그러니 둘을 함께 쓰고, video/frame representation이 서로 다른 text source들과 관계를 맺도록 학습시키자. 즉, large-scale noisy supervision과 small but more in-domain supervision을 결합하는 것을 고려한 설계라고 정리하겠습니다!
4. Experiment
4.1 Main Result
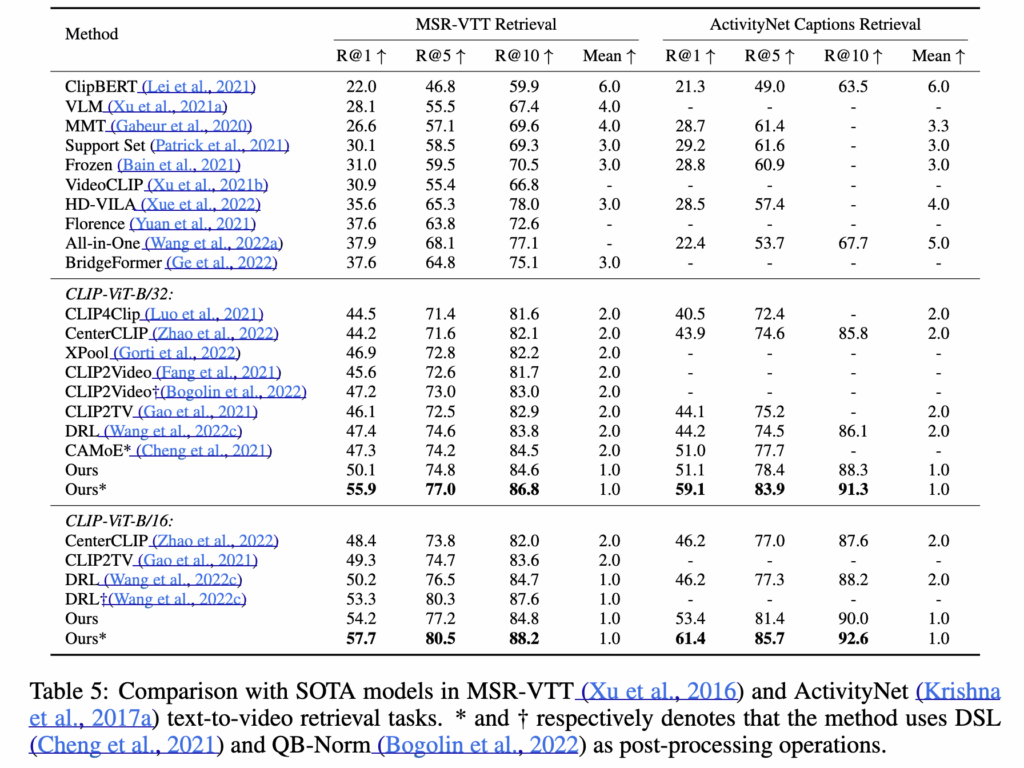
표 5는 MSR-VTT와 ActivityNet 데이터셋에서의 text-to-video retrieval 성능입니다. 그 결과 CLIP-ViP는 CLIP-ViT-B/32와 B/16 두 가지 백본 모두에서 4개 데이터셋의 기존 SOTA 성능을 큰 폭으로 뛰어넘었습니다.
특히, 길이가 긴 영상(평균 180초)으로 구성된 ActivityNet Captions 데이터셋에서도 압도적인 결과를 내어, 짧은 클립뿐만 아니라 긴 비디오에서도 모델이 잘 작동함을 보였죠
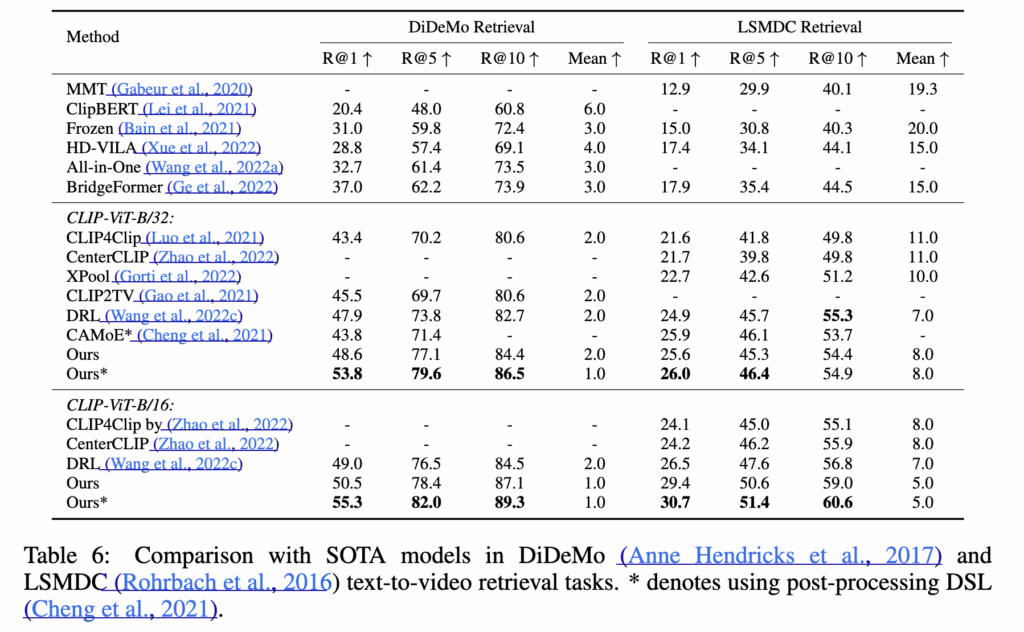
표 6은 DiDeMo와 LSMDC 데이터셋에서의 text-to-video retrieval 성능입니다.
기존 연구들 중 일부는 성능을 쥐어짜기 위해 DSL이나 QB-Norm 같은 별도의 후처리 연산을 사용했는데요. 하지만 CLIP-ViP는 이런 후처리 없이도 이미 기존 모델들을 대부분 상회하는 결과를 보였고, 후처리를 더할 경우 성능이 더욱 극대화되기도 하였습니다.
4.2 Video Proxy
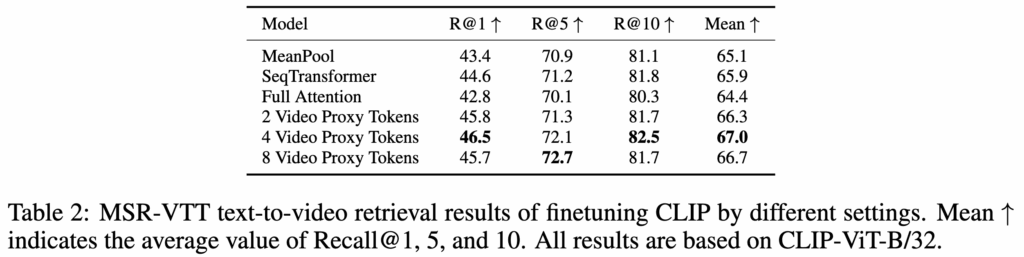
Table 2를 보면, 단순 평균보다 좋아졌고, full attention보다도 낫습니다. 저자 해석대로라면 “CLIP의 원래 image attention 구조를 너무 깨지 않는 게 중요하다”고 할 수 있겠네요. proxy 수는 4개일 때 가장 좋았습니다.
4.3 OCL
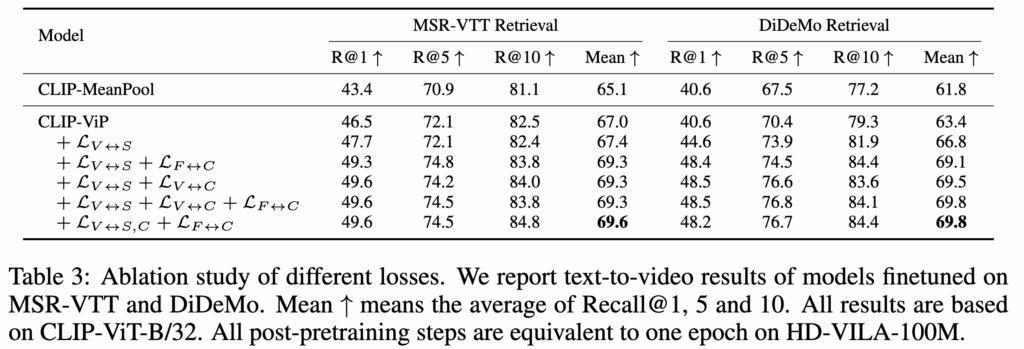
Table 3를 보면, proxy만 넣은 CLIP-ViP는 baseline보다 약간 좋아지지만, subtitle만으로 post-pretraining한 L_{V↔S} 는 향상폭이 매우 제한적입니다. 반면 auxiliary caption을 포함한 OCL variants는 꽤 큰 향상을 보입니다. 최종 설정인 L_{V↔S}+L_{F↔C}가 가장 좋았습니다.
4.4 Auxiliary data
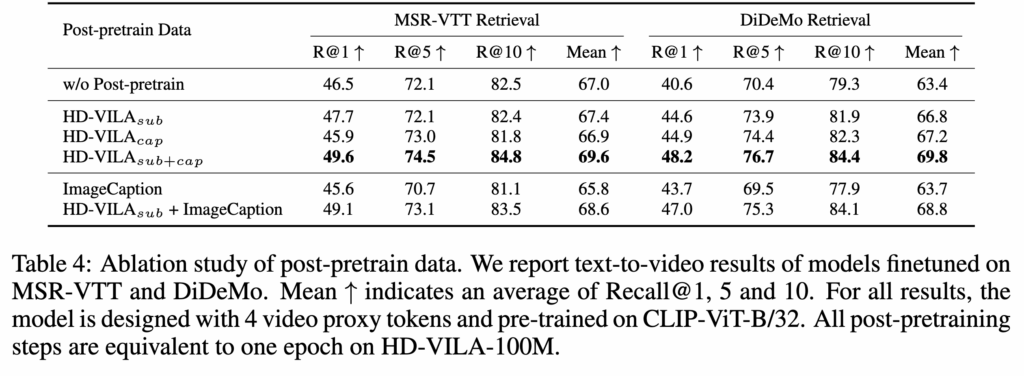
Table 4가 중요한데, 흥미롭게도 subtitle만 써도 성능 향상이 적고, generated caption만 쓰는 것도 마찬가지였습니다. 그런데 subtitle + generated caption을 함께 쓰면 확 좋아졌죠. 즉, 둘의 조합이 핵심이라는 것입니다. 또 image caption 데이터만 따로 넣는 건 별로 효과가 없고, HD-VILA subtitle과 함께 넣었을 때는 좋아집니다.
5. Conclusion
결국 해당 논문을 통해 가져갈 내용은 아래 세 가지 같습니다.
1. CLIP을 비디오로 추가 학습할 때 망가지는 이유를 data scale과 language domain gap으로 설명했다
2. 비디오 전체 patch끼리 full attention하지 않고, proxy token을 통해 간접적으로 temporal aggregation하는 구조를 제안했다는 점. 이것이 CLIP의 image-pretrained prior를 덜 깨면서 비디오로 확장하는 방법임.
3. subtitle + generated caption을 함께 쓰는 OCL로 noisy large-scale video supervision과 downstream-like caption supervision을 결합했다는 점.
저는 무엇보다 이미지 기반의 pre-trained 모델을 비디오나 다른 도메인으로 확장하는 연구를 할 때, 무작정 데이터를 넣고 학습시키기보다는 ‘데이터 스케일의 적절성’과 ‘도메인 간의 갭’, 그리고 ‘기존 모델 아키텍처와의 충돌 최소화’를 어떻게 해결할지 고민해봤다는 관점에서 흥미롭게 봤던 것 같습니다. 리뷰 마치겠습니다.
안녕하세요 주영님 좋은 리뷰 감사합니다.
읽어보니 재밌는 부분이 많네요.
궁금한점을 질문하자면 첫번째로 proxy token을 사용하여 CLS 를 대체했다면 기존 ViT 를 통과하고 나오는 CLS 는 안쓰고 patch token만 사용했다는거로 이해하면 될까요?
두번째는 질문하려했는데 Table4에 이미 존재해서, 스스로 답변이 된 것 같은데, MSR VTT와 DiDeMo의 NMI 지표값이 큰 데이터 2개를 골랐지만, MSR-VTT가 훨씬 높았고, DiDeMo가 sub&cap 크게 구분력 없는 정도로 보였는데 실제 post-training에서 그 경향성을 보여주는 것 같습니다. DiDeMo는 sub과 cap 모두에서 성능 향상이 비슷하고, MSR-VTT는 cap에서 성능드랍, sub에서 성능 유지 혹은 향상이 있었네요.. 전반적으로 논문 흐름이 잘 납득되고 재밌는 분석인 것 같습니다.
감사합니다.
네 맞습니다.
첫 번째는 기존 CLS 대신 proxy token이 비디오 대표값 역할을 한다고 이해하면 됩니다. 그래서 최종 retrieval에는 보통 첫 번째 proxy output을 쓰고, patch token은 중간 상호작용을 위해 쓰이는 것이죠
두 번째도 좋은 해석 같습니다. MSR-VTT는 sub-cap 도메인 차이가 더 커서 source 차이에 따른 성능 차이도 더 뚜렷하게 보이고, DiDeMo는 둘 차이가 작아서 성능도 비슷하게 가는 흐름으로 읽을 수 있을 것 같습니다!