안녕하세요 3번째 X-review네요. 아마 당분간은 쭉 VPR(visual place recognition)쪽 논문 리뷰를 들고오지 않을까 싶습니다. 오늘 소개드릴 논문은 MixVPR입니다. 간략하게 소개를 드리자면 무거운 transformer 연산 없이도, mlp-mixer의 방법론을 들고와서 가볍게 global VPR 성능을 끌어올린 논문입니다. 예전에 승현님이 한번 리뷰한적도 있어서, 같이 읽으시면 더 이해하는데 수월할거 같습니다. 리뷰 시작하겠습니다.
Introduction
VPR이라는 분야는 본질적으로 image retrival입니다. 다른 이미지들이 얼마나 유사하고 다른가를 환경이나 시간대에 무관하게 찾아내야하는 task입니다. 그래서 가장 문제가 되는것은 저자들은 short term appearance change(e.g. illumination occlusion and weather)이라고 합니다. 그리고 물론 long term variation(e.g. seasonal changes, construction and vegetation)도 문제 삼고 있습니다.
그래서 기존의 방법론들이 어떻게 이 문제를 풀었는지를 순차적으로 얘기해보면, 당연히 SIFT SUFT와 같은 알고리즘 기법을 이용한 Fisher Vecotrs, BOVW, BLAD와 같은 머신러닝적 방법으로 먼저 접근을 했습니다. 그리고 시대의 흐름에 따라 그 이후에는 CNN을 이용해서 접근했습니다. 그래서 등장한게 NetVLAD와 같은 방법론입니다. 그러나 여전히 이러한 방법론으로는 severe illumination and seasonal changes들에 취약하다고 저자는 주장합니다.
다음은 당연하게 attention 기반의 transformer backbone입니다. TransVPR과 같은 논문들은 transformer을 이용해 global descriptor를 뽑아낸 후, 추가적으로 top@K개의 이미지에 대해 reranking을 진행하는 2단계를 거칩니다. 이러한 방식으로 기존의 CNN기반의 방법론을 압도하는 성능을 끌어냈습니다. 그러나 저자들은 reranking 없이는 CNN기반의 NetVLAD나 CosPlace와 같은 논문보다 global descriptor의 성능을 여전히 낮다고 주장합니다.
그래서 저자들이 하고싶은 말은 무거운 transformer가 (reranking빼면) global VPR이 CNN계열보다 좋지 않기에, global descriptor성능을 CNN과 MLP만으로 transformer 기반의 reranking보다 좋은 성능을 낼 수 있다! 입니다.
About MLP-Mixer
MLP-Mixer는 CNN없이도 공간적 정보를 학습하기 위해 나온 방법론입니다. 간단하게 알아보겠습니다.
조원님이 작성하신 리뷰를 참고하시면 더 이해에 도움될 것 같습니다.
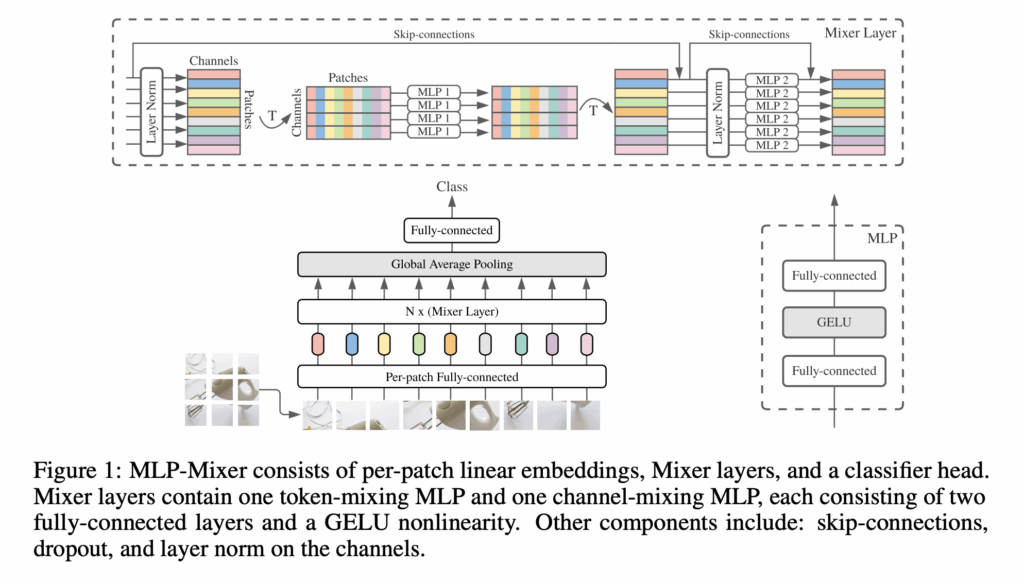
엄청 간단합니다. 위 그림이 거의 전부입니다.
- 어떤 image를 먼저 patch단위로 나눠줍니다. HxWxC의 이미지를 HW를 합쳐서 NxC라고 얘기해봅시다.
- NxC의 이미지를 transpose시켜서 CxN으로 만들어준 후 linear layer를 통과시킵니다 (CxN -> linear -> CxN)
- 다시 transpose시켜서 linear을 통과시켜줍니다(NxC -> linear -> NxC)
물론 skip-connection과 LayerNorm도 있지만, 핵심만 요약한다면 위와 같습니다.
결국 patch-wise mix와 channel-wise를 통해, MLP만 통과했지만 global receptive field를 가지고 channel간의 정보도 정제됩니다.
Methodolody
다시 MixVPR의 method로 돌아오겠습니다.
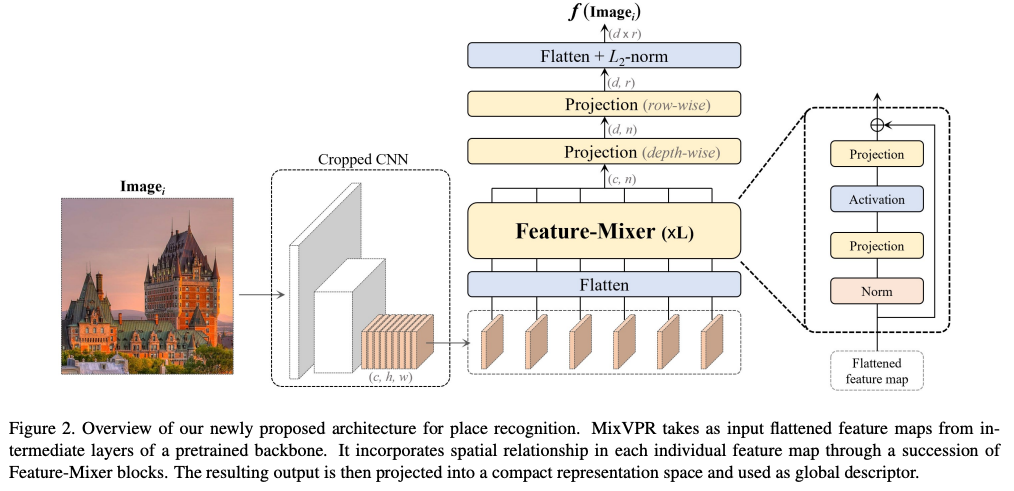
먼저 MixVPR은 CNN backbone을 사용하기에 multi-scale feature map을 활용해줍니다.
feature map들을 아래와 같이 표현할 수 있습니다
F \in \mathbb{R}^{c \times h \times w}
F = CNN(\mathcal{I}) (\mathcal{I}: Image)
c는 channel이 아니고 intermediate layer들입니다.
그래서 결국 h \times w를
X^{i} , i = \{1, ..., c\}
으로 표현할 수 있습니다.
이게 이걸 드디어 Feature-Mixer에 태웁니다. 저자는
cascade of L MLP blocks of identical structure
이라고 표현합니다.
수식을 가져오자면
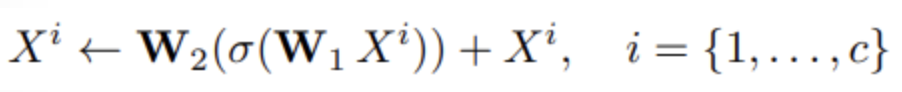
입니다. 여기서 \mathcal{W}_{1}, \mathcal{W}_{2}는 weights of two fc layer입니다.
그래서 저자는 이 수식의 직관적 설명을 얘기해줍니다.
Feature-Mixer는 local feature에 집중하는 대신 network가 attention mechanism을 통과하게 하여, fc layer가 자holistic하게 feature를 aggregation해준다고 합니다.
Feature Mixer(FM)은 input과 동일한 output을 내놓습니다.
output \mathcal{Z} \in \mathbb{R}^{c \times n}
이렇게 input과 output이 같으므로 Feature Mixer layer를 합성곱처럼 \mathcal{L}번 통과시켜줄 수 있습니다. 그렇게 \mathcal{L}번 통과시켜준 후 차원을 줄여주기위해(descriptor로 만들기 위해서) channel-wise fc layer, row-wise fc layer를 각각 태워서 일종의 weighted pooling을 진행하여 final descriptor로 만들어줍니다. 그리고 최종적으로 L2-norm만 취해주면 진짜 완성입니다.
Experiments
1. one-stage comparsion
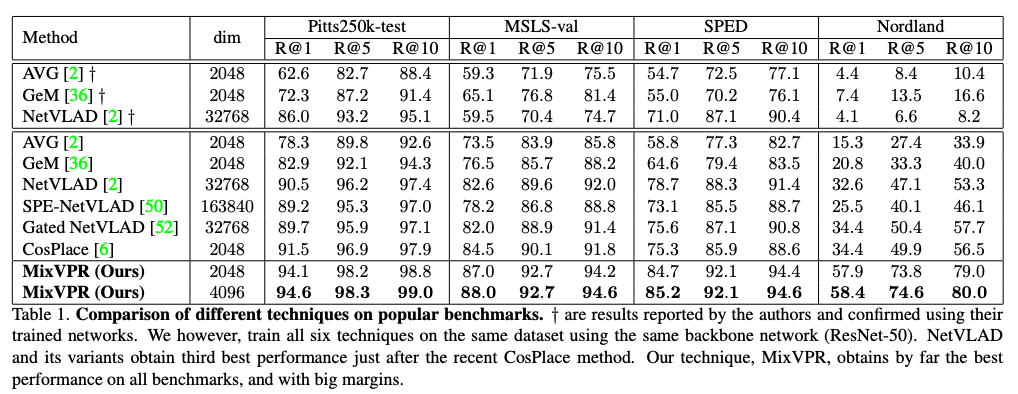
성능은 위 Tabel 1.과 같습니다. 참고로 여기서 R@K는 retrival한 K개의 이미지 중에 성능이 있을 확률을 나타내는 값입니다. 그래서 R@10이 80.0이라면 model이 이미지를 정답이 맞을 확률이 큰 순으로 쭉 나열했을 때, 1등부터 10등 사이에 정답이 있을 확률이 80%라 생각하시면 됩니다.
AVG(GAP), GeM와 같은 단순 aggregation method, 그리고 VLAD기반 방법론들, 그리고 transformer를 적용한 CosPlace와의 비교
이렇게 크게 3가지 틀로 볼 수 있습니다. 성능면에서 모든 데이터셋에서 압도하고 있음을 확인할 수 있습니다. 특히, Nordland에서는 유독 성능 향상이 큰걸 볼 수 있습니다. Nordland dataset을 저자는 extremely challenging이라고 표현하는데, 즉 mixVPR이 어려운 상황에서 더 잘 동작함을 보입니다.
2. two-stage comparsion
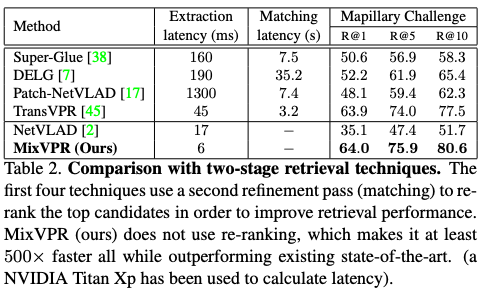
다음은 먼저 빠르게 후보군을 골라내고(1stage), 더 세세하게 비교하는(2stage)의 reranking 방법론을 사용하는 논문들과의 비교입니다.
이 표를 통해 MixVPR이 얘기하고 싶었던 것은, 무거운 two-stage reranking 없이도 우리 MixVPR은 two-stage의 방법론 성능을 압도한다~ 입니다. 또한 당연히 two-stage가 없기에 Matching latency는 없고, Extraction latency도 압도하는 것을 볼 수 있습니다.
3. Ablation
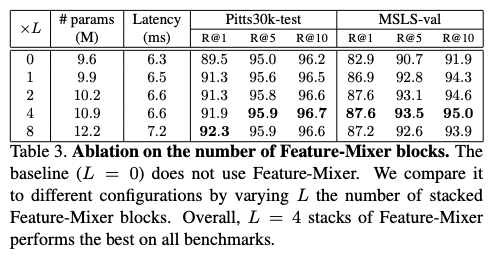
Table3.는 간단한 실험입니다. Feature Mixer(FM)의 iteration 개수를 조절해서, 비교 실험한 것입니다. L=4와 L=8를 보면, L=4가 성능이 더 비슷하거나 좋기에 더 빠른 L=4를 선택했음을 알 수 있습니다.
4. Qualitative Results


시각화 결과입니다. 저자 처음에 주장했던 short term appearance change에 강인한 사진들을 위주로 보여주고 있습니다.

Figure 5.는 Feature Mixer의 첫번째 hidden layer의 weight(의 subset, 400개중 24개)입니다. 저자는 시각화 결과를 통해 FM가 wide range of regional feature selection을 배웠음을 보여줍니다. 봐야할 것은 일부 neurons들은 local한 multiple small spot에 집중하고 있고, 일부는 entire input에 집중하고 있습니다. 이를 통해 attention과 pyramidal 방법론을 대체할 수 있지 않을까~라는 기대를 논문 마지막에 던지면서 마무리하고 있습니다. 물론 현재의 시각으로 보면 결국 attention method가 대세가 되었지만, MLP-Mixer가 attention을 대체하기 바랬던 저자들의 당시의 기대가 보이는 부분입니다.