Intro
본 논문이 타깃으로 하는 task는 Tracking Any Point (TAP)라는 task로 Deepmind가 작성한 TAP-Vid: A Benchmark for Tracking Any Point in a Video라는 논문에서 처음 등장한 task입니다.
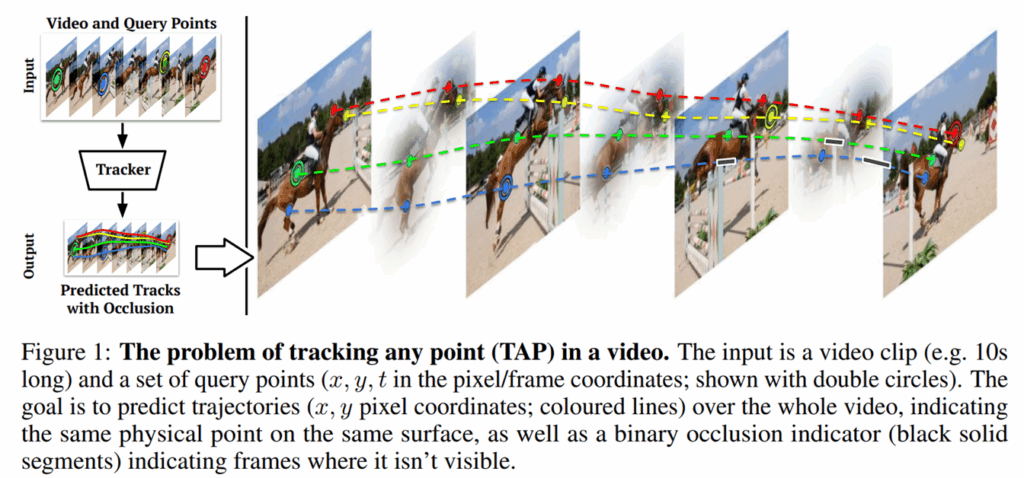
동영상 내에서 모션에 대한 이해를 수행할 필요가 있는데 두 장의 대응 관계 정도를 파악하는 것은 기존에 연구되고 있던 optical flow나 semantic corresponding 같은 기술들을 활용하면 됐지만, 시간 축으로 길게 늘어졌을 때도 강인하게 물리적 지점들에 대한 대응 관계를 이해하고 이를 표현할 수 있는 모델 및 벤치마크가 마땅히 없었다고 합니다. 그래서 TAP-Vid라고 하는 벤치마크를 만들어 제안한 것이죠.

특히, 논문에서 저자들은 detection, segmentation, optical flow, SfM 등등 기존 컴퓨터비전 task만으로는 한계가 명확하다고 주장하면서 Track Any Point라는 task가 필요하다는 점을 강조합니다.
이러한 TAP task는 서로 다른 시간대 사이에 대응관계를 잘 찾는 것을 목표로 하는 것이기 때문에 모델 학습을 하기 위해서는 두 대응관계에 대한 GT가 필요합니다. 하지만 정해진 object에 대한 대응관계가 아니라 영상 내 물리적으로 선택할 수 있는 지점이라 하면 occlusion 때문에 보이지가 않는 이상 대응 관계를 반드시 예측해야만 하는 해당 task에서 올바른 양질의 GT를 구하는 것은 상당히 많은 비용이 소모됩니다.
특히 optical flow task에서는 GT를 구하는 것이 너무 어렵기 때문에 합성 데이터셋으로 모델을 학습하고 실제 데이터로는 평가만 하는 것이 일반적인 벤치마크 구성이긴 합니다. 하지만 합성 데이터셋은 실제 real data와 다른 분포를 가지고 있기 때문에 성능에 명확한 한계가 있다는 점이 있긴 하죠.
그래서 저자들은 TAP task를 노동집약적인 GT 없이 self-supervised learning 방식으로 접근하는 방법론을 찾고자 하였으며, 결과적으로 Contrastive Random Walk라는 방법론에 이르게 됩니다.
Self-supervised Space-Time Correspondence
Contrastive Random Walk(CRW)란 NeurIPS2020에 게재된 “Space-Time Correspondence as a Contrastive Random Walk”라는 논문에서 등장한 개념으로, 해당 논문은 약간 비디오 모달리티의 self-supervised learning이라고 생각하시면 됩니다.
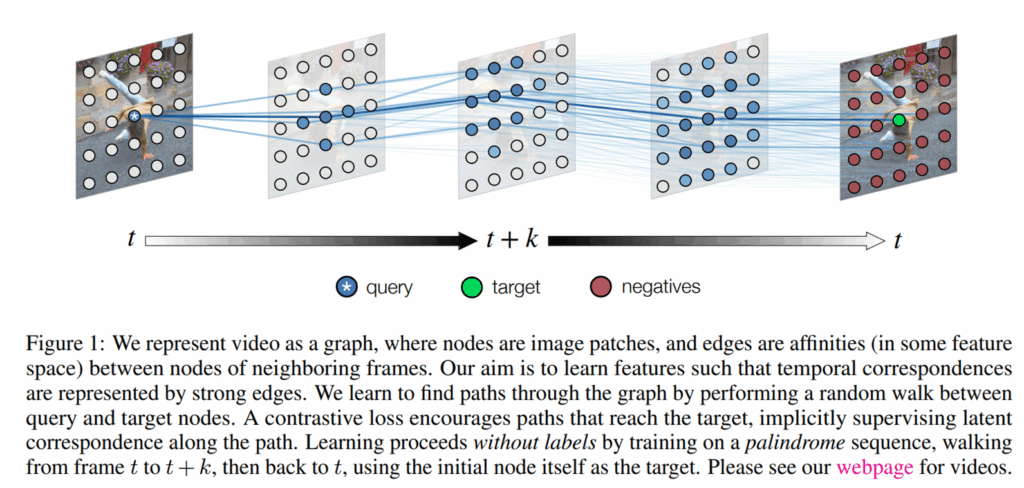
즉, Moco, SimCLR 같은 contrastive learning과 MAE 등등 다양한 image level에서의 self-supervised learning 연구가 수행되었던 것처럼, CRW는 비디오 데이터에 대한 좋은 특징을 추출할 수 있는 사전학습 가중치를 구하기 위해 제안된 방법이었습니다.
우선 CRW를 제안한 저자들의 사고 방식은 다음과 같은데, 공간적 맥락 정보만을 이해하면 되는 이미지와 다르게 비디오는 시간축에 대한 맥락도 모두 이해를 해야하기 때문에 시공간적 정보에 대한 학습이 필요로 했습니다. 그래서 저자들은 시간의 변화에 따라 시각적 패치들이 어떻게 변화하는지 그 대응관계를 학습시키고자 하였는데 처음에 TAP task 소개할 때도 말씀드렸다시피 시간축에 따른 영역들간의 대응 관계를 GT로 구하는 것은 상당히 노동집약적입니다.
그래서 CRW 저자들은 self-supervised learning으로 학습할 수 있도록 확률 기반의 전이 행렬(Transition Matrix)을 예측하는 방식을 채택했습니다.
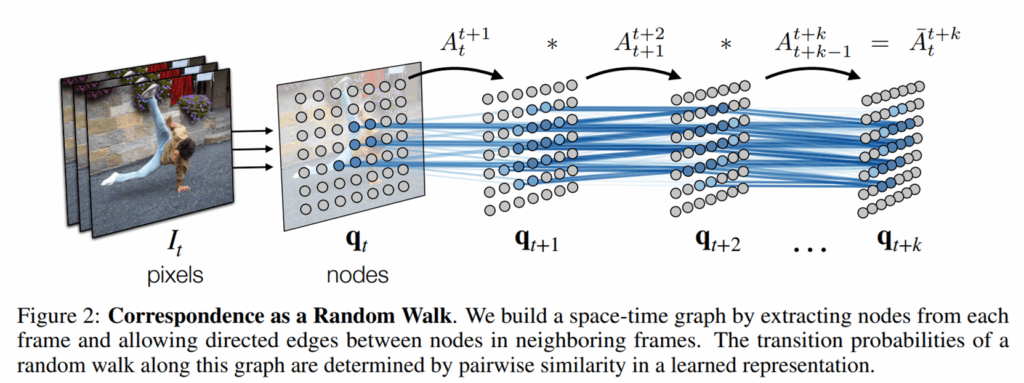
위의 그림처럼 t frame에 대하여 특징을 추출한 것을 q_{t} 라고 하였을 때 t+1,…,t+k에 대한 시각적 특징들은 q_{t+1},...,q_{t+k} 라고 할 수 있을 것입니다. 여기서 저자들은 각각의 visual patch를 노드라고 보고, t, t+1, t+2 각각의 프레임 내 visual patch(노드)들은 유사도에 따라 엣지로 연결되어 있다고 가정하였습니다.
그리고 전이 행렬 A는 source frame의 시각적 토큰이 target frame의 어떠한 시각적 토큰들과 관련성이 높은지를 표현해 주는 행렬이라고 이해하시면 될 것 같습니다. 이해가 잘 안되실 수 있는데 실제로 전이 행렬 A가 어떻게 계산되는지를 알면 사실 쉽게 이해되실 겁니다. 전이 행렬 A는 저희가 잘 아는 transformer의 attention map을 계산하는 방식과 동일합니다.

t프레임과 t+1 프레임에 대한 시각적 토큰들의 집합을 각각 Q_{t}, Q_{t+1} 라고 할 때, 각 시각적 토큰들에 대하여 내적을 한 다음에 softmax를 취한 것을 저자들은 transition matrix라고 본 것이죠. 저희한테는 두 프레임에 대한 cross-attention map으로 쉽게 해석되겠지만 2020년 당시에는 비전 분야에서 attention map이라는 개념이 잘 도입되지 않았던 터라 저자들은 transition matrix로 표현한 것은 아닐까라는 생각이 드네요.
아무튼 저희가 잘 알고 있는 attention map은 이제 value에 곱해지는 것으로 그 역할을 다하지만, 저자들의 transition matrix는 그런 의미는 아닙니다. t에서 t+1에 대한 전이 행렬을 A_{t}^{t+1} 라고 하고 t+1에서 t+k에 대한 전이 행렬을 A_{t+1}^{t+k} 라고 할 때, 마카로프 체인 법칙?에 따라서 A_{t}^{t+k} 에 대한 전이 행렬은 A_{t+1}^{t+k} [/latex]과 A_{t}^{t+1} 를 내적함으로써 표현할 수 있습니다.그림 2에서 등장하는 수식이 바로 그런 의미죠.
아무튼 저자들은 모델이 전이행렬을 잘 예측할 수 있으면 비디오에 대한 공간적, 시간적 맥락을 잘 이해하는 것으로 판단하여 해당 값을 예측하는 것을 사전학습으로 정의하였습니다. 근데 전이 행렬도 결국 GT가 필요합니다. 그 GT를 실제 대응관계로 주는 것은 self-supervised learning의 철학에 반하는 것이기 때문에 저자들은 다음과 같은 방식으로 노동집약적인 GT 없이 전이 행렬을 학습시키고자 하였습니다.
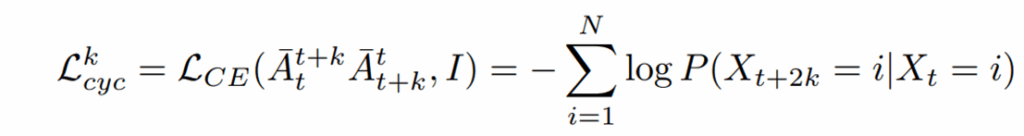
위의 수식은 CE인데 t에서 t+k로 가는 전이 행렬 A_{t}^{t+k} 과 역으로 t+k에서 t로 가는 전이 행렬 A_{t+k}^{t} 의 내적한 결과값이 Identity matrix가 되도록 하는 것이죠. CE를 사용하는 것은 전이 행렬들이 대응관계가 높은 영역들에 대한 확률분포를 의미하는 것이므로 CE loss를 사용하는 것이며, 갔다가 되돌아오면 제자리라는 점을 이용해서 identity matrix를 GT로 삼은 것입니다. 이러한 학습 방식을 통해 얻은 가중치를 통해 저자들은 video segmentation 등 비디오 관련 task에서 당시에 좋은 성능을 달성할 수 있었습니다.
STFC
CRW 논문 이후로 21년도에 ICCV workshop에 STFC라는 논문이 등장했습니다. 해당 논문은 CRW가 학습 때 입력 이미지 단에서 crop을 한다음에 각 crop된 영상을 Encoder의 input으로 사용한다는 점이 추론 단계에서 전체 이미지를 보는 것과 상이하다는 점을 문제로 삼았습니다.
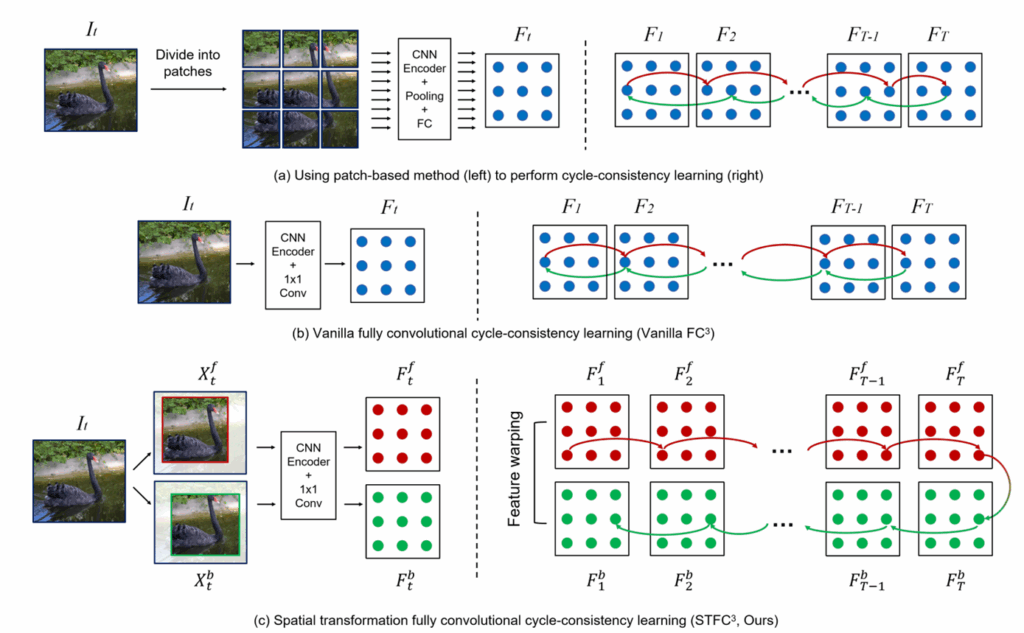
그리하여 학습때도 전체 이미지를 입력으로 하여 기존의 CRW 방식으로 학습을 시켜보았더니(위의 그림의 2번째 버전) 모델이 유의미한 특징을 학습하지 못하는 문제가 발생하였다고 합니다.
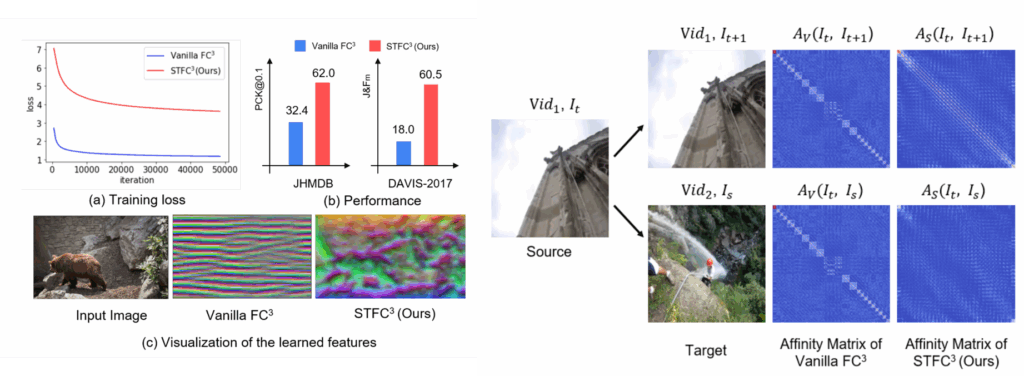
실제로 좌측에 Vanilla FC가 full image에 대하여 CRW로 학습한 모델을 의미하는데 해당 모델에 대하여 feature map을 시각화해보니 영상이 전체적으로 물결표현이 되는 것을 확인할 수 있으며, 우측 예시와 같이 source와 target이 서로 동일할 때와 동일하지 않는 상황에서의 전이 행렬이 유사한 것을 볼 수 있습니다.
즉 서로 다른 이미지에 대해서는 전이 행렬의 대각 성분들이 활성화가 되면 안되는데 활성화가 된다는 것이죠. 저자들은 이러한 정보들을 토대로 full image로 CRW 학습을 진행하면 모델이 시각적인 대응 관계를 학습하는 것이 아니라 단순히 시각적 정보를 외워서 transition matrix를 생성한다고 판단하였습니다.
이를 해결하기 위해 저자들은 forward image와 backward 이미지에 서로 다른 위치의 random crop & resize를 적용하였습니다. 여기서 forward image는 t에서 t+k로 향하는 전이 행렬을 구할 때 사용하는 image를 의미하며, backward image는 반대로 t+k에서 t로 이동하는 전이 행렬을 의미합니다.
즉, 모델이 두 이미지에 시각적 정보들을 비교하고 대응관계를 계산하는 것이 아니라 단순히 위치 정보를 외워버려서 전이 행렬을 예측하는 shortcut이 발생하였다면, 억지로 random crop으로 위치를 틀어버려서 단순 공간 정보 암기만으로는 절대로 올바른 전이 행렬을 예측할 수 없게끔 한 것이죠.
보통 forward image는 시작 frame (e.g., t)와 target frame (e.g., t+k)로 결정되고, backward image는 forward image를 만들었을 때와 다른 random crop이 시작 frame에만 적용됨으로써 만들어집니다. 그러면 t에서 t+k에 대한 전이 행렬은 동일한 위치에서의 random crop이 적용되었기 때문에 그에 대한 전이 행렬은 문제 없지만, t+k 이미지에서 t로 되돌아올 때는 forward image의 t+k와 backward image의 t와의 전이 행렬을 계산해야하기 때문에 시간에 변화에 따른 시각적 외형 변화 뿐만 아니라 다른 위치에서의 crop으로 인한 공간적 변화에 따른 외형 변화가 발생하게 됩니다.
즉, 시간의 흐름에 따른 변화 뿐만 아니라 그 외의 위치 변화로 인하여 CRW가 제안한 forward했다가 다시 backward로 되돌아오는 전이행렬의 결과값은 identity matrix라는 가정이 깨져버리게 됩니다.
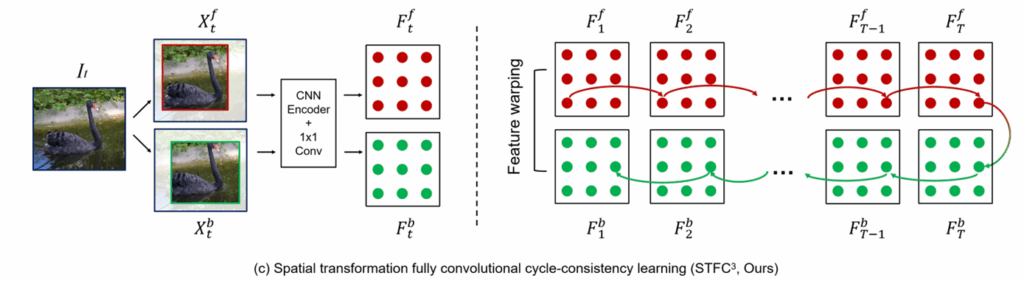
그래서 STFC 저자들은 forward image에서 추출한 feature map F_{1}^{f} 에 대해 backward image의 feature map과 동일한 공간적 좌표로 설정해 주기 위하여 미리 feature warping을 적용한 다음에 transition matrix를 계산합니다.
즉, CNN은 서로 다른 공간적 좌표에서 유의미한 시각적 특징을 추출해야하기 때문에 단순히 공간적 정보를 암기해서는 올바른 전이행렬을 예측하지 못하는 반면, identity matrix로 학습을 수행하기 위한 공간적 정합 과정이 전이 행렬 계산 전에 적용된다는 것이죠.
Self-Supervised Any-Point Tracking by Contrastive Random Walks
앞서 소개드린 CRW에서부터 STFC까지의 배경 지식?을 이해하셨다면 제가 리뷰하고자 하는 방법론은 아주 쉽게 이해하실 수 있습니다. 사실 CRW의 배경지식과 STFC가 왜 등장하였는지를 알아야 STFC의 문제점을 해결하기 위해 저자들이 어떤 contribution을 냈는지를 쉽게 이해할 수 있어서 앞에 길게 소개를 드렸었네요.
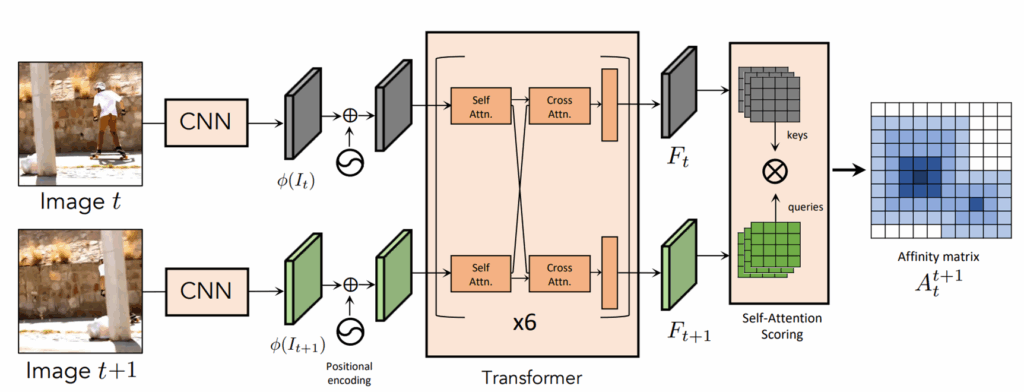
우선 본 논문을 다시 소개하면, Tracking Any Point라는 task를 self-supervised learning 방식을 통해 잘 해보자는 것이 논문의 가장 큰 목표입니다. 24년도 답게 Transformer를 기반으로 전이 행렬을 예측하려고 하였는데, 저 모델의 구조는 2022년도 CVPR oral paper였던 GMFlow의 구조를 그대로 사용했다고 이해하시면 됩니다. 아무래도 TAP task가 optical flow와 연관성이 상당히 높기 때문에 저 구조를 적극 도입한 것 같습니다.
근데 이제 저자들이 이러한 트랜스포머 구조를 도입하여 STFC 방식으로 학습을 진행해 보니 여전히 shortcut 문제가 발생하였다고 합니다. 즉, 모델이 두 프레임 사이의 시각적, 의미론적 이해를 토대로 전이 행렬을 계산하는 것이 아니라 단순히 위치를 외워서 전이 행렬을 예측해 버린다는 것이었죠.
STFC 방법론에서는 서로 다른 random crop을 통해 shortcut 문제가 해결된다고 했었지만, 이는 CNN 구조였기 때문에 가능한 것이었지만, 저자들이 도입한 GMFlow의 경우에는 두 프레임 사이의 대응 관계를 이해시키는 과정에서 트랜스포머가 추가로 사용되었기 때문에 단순히 서로 다른 위치의 random crop을 적용한 것만으로는 shortcut 문제를 막을 수 없었다고 합니다.
그래서 저자들은 이 문제를 해결하기 위해 STFC처럼 전이 행렬을 계산할 때 feature map을 warping하는 것이 아니라 label을 warping하는 방법을 채택했습니다.
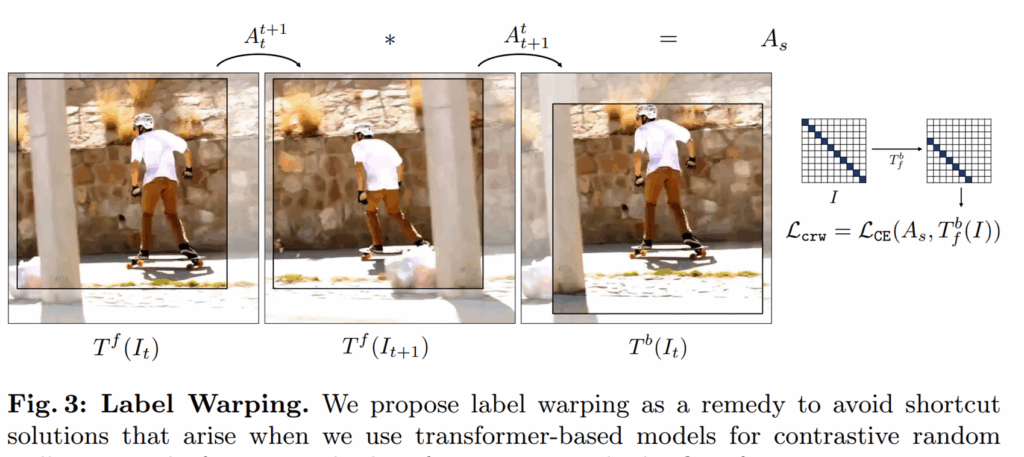
우선 STFC와 동일하게 t 프레임 시작 이미지와 t+1 target image에 대하여 동일한 random crop을 적용한 foward image들과 다른 random crop을 적용한 backward image를 생성합니다. 그렇게해서 각각 foward 전이 행렬과 backward 전이행렬을 계산하게 되는데, 여기서 STFC가 제안하는 feature warping 과정을 거치지 않으면 GT 값으로 identity matrix를 사용할 수 없게 된다고 말씀드렸습니다.
그래서 저자들은 GT로 사용되는 identity matrix에다가 forward image의 좌표계에서 backward image로의 좌표계로 변환이 가능한 변환 행렬을 적용함으로써 feature map의 warping없이도 곧바로 학습할 수 있는 GT를 생성하는 것이죠.
이러한 관점의 전환?으로 인해 트랜스포머 구조에서도 성공적으로 유의미한 전이 행렬을 모델이 학습할 수 있게 되었으며, 결과적으로 저자들이 원했던 TAP task에서도 좋은 성능을 달성할 수 있었다고 하네요.
Experiment
실험결과 살펴보고 리뷰 마무리 짓겠습니다. 우선 평가 지표는 다음과 같습니다. 세 메트릭 모두 값이 높을수록 성능이 좋다고 생각하시면 될 것 같습니다.

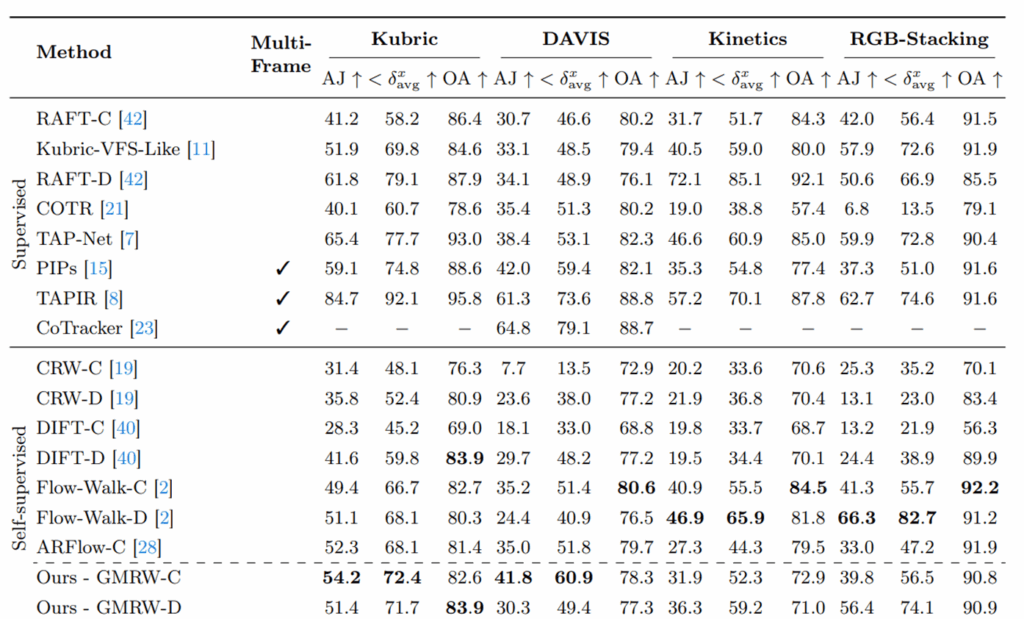
우선 저자들은 4가지 데이터셋에 대해서 성능을 리포팅하는데, 저자들의 방법론은 GT 없이 학습을 하는 self-supervised 방법론이기 때문에 supervised 방법론들과 성능을 비교하기는 어렵습니다. self-supervised 방법론들과의 비교를 살펴보면 저자들의 베이스라인 방법론이었던 CRW와 Flow-Walk은 모두 foward/backward cycle 전이 행렬 학습 방식을 사용한 방법론으로 생각하시면 되고 DIFT는 stable diffusion 모델 기반 특징 매칭 방식입니다.
그리고 방법론에 C와 D가 표기되어있는데 C는 t, t+1, t+2, …, t+k까지 연속적인 프레임에 대해서 전이행렬을 다 계산해서 내적하는 방식을 통해 t에서 t+k까지 전이행렬을 계산한 방식이고, D는 그냥 t와 t+k 두 이미지에 대해서 한번에 전이행렬을 계산하는 방식입니다.
기존의 방법론들은 데이터셋과 평가 지표에 따라서 다르긴 합니다만, C 방식보다 D인 경우에서 성능이 더 높은 것을 볼 수 있는데 이러한 결과는 해당 모델들이 단순히 두 영상에 대한 대응 관계만을 고려할뿐 Tracking Any Point의 핵심 평가 요소 중 하나인 시간축에 대한 연속적인 이해력은 부족함을 암시합니다. 즉, 특정 프레임에서 대응 관계를 놓쳐버리면 에러가 누적되어 트래킹이 실패할 수 있다는 것이죠.
반면 저자들의 방법론은 D보다 C 방식이 더 좋은 성능을 보여주고 있는데, 이러한 점은 연속적인 프레임에서 tracking을 실패하지않고 쭉 이어간다는 점을 의미하며 이는 TAP task 관점에서는 더 좋다고 볼 수 있겠습니다.
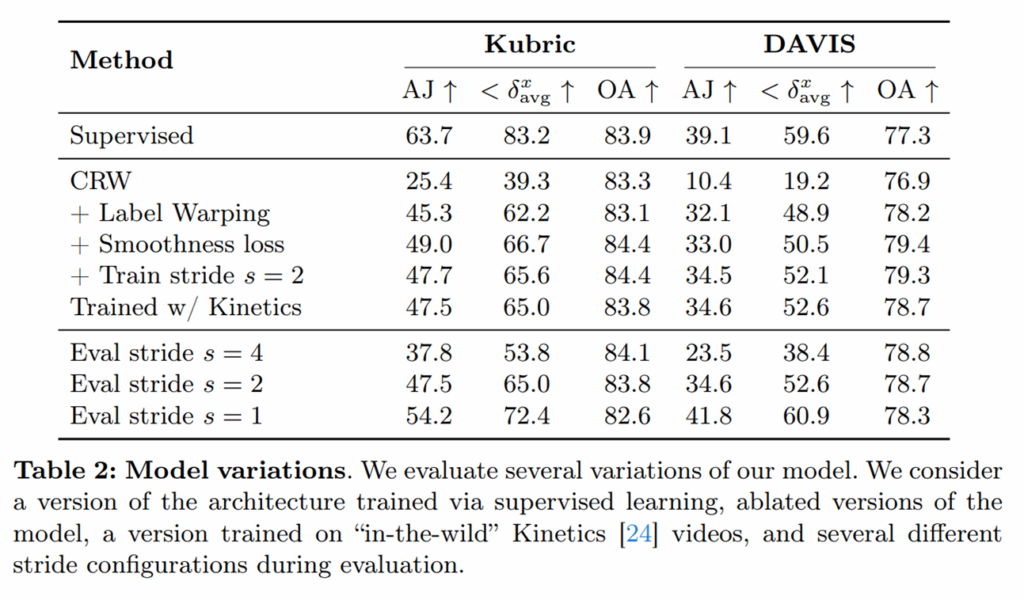
다음은 ablation 실험입니다. 저자들의 GMFlow 모델 구조로 지도학습을 할 때의 성능이 제일 위의 행에 대한 성능으로 upper bound라고 생각하시면 됩니다. self-supervised 관점에서 베이스라인인 CRW를 적용하였을 때 성능이 대폭 감소하는 것을 볼 수 있는데, 이는 CRW 학습 방식은 shortcut을 발생시켜 유의미한 대응 관계를 학습하지 못하기 때문으로 볼 수 있습니다.
그래서 저자들의 핵심 contribution인 label warping을 적용하면 transformer 구조임에도 불구하고 모델의 shortcut이 방지되어 성능이 크게 개선되는 것을 볼 수 있습니다. 그리고 smoothness loss는 저자들의 모델구조가 optical flow 방법론의 구조를 거의 온전히 활용한 것이다보니 flow map을 생성할 수 있게 되는데, 이러한 flow map에 대해 값이 부드럽게 생성되도록 하는 스무딩 규제화를 적용한 것입니다. optical flow 분야에서 기본으로 쓰이는 규제화를 그냥 넣었다고 보시면 될 것 같습니다.
stride의 경우에는 저자들이 처음 이미지에 대해 특징을 추출할 때 CNN을 사용하는데 해당 CNN을 타고 나오면 모델의 해상도가 입력 해상도 HxW 대비 1/4로 다운샘플링이 됩니다. 이렇게 다운샘플링이 1/4 스케일로 되었다는 것을 stride 4라고 합니다. 반대로 stride 값이 1과 2이면 입력 해상도를 각각 4배, 2배 upsampling하여 CNN에 입력으로 사용한다는 뜻이죠.
다시 표로 돌아와서, stride=2의 의미는 모델 학습 단계에서 학습 데이터를 2배로 키워서 진행하였을 때의 성능을 의미하며 이때는 데이터셋과 메트릭별로 성능이 오르는 경우도 오히려 떨어지는 경우도 보입니다. 그리고 Kinetics 데이터셋을 추가로 학습데이터로 사용하는 경우는 모델의 일반화 성능을 개선시키기 위한 실험으로 보이는데 학습에 추가하였을 때 성능의 향상은 딱히 없었다고 합니다.
평가 단계에서는 stride 값을 4에서 1로 줄일수록 (즉, 입력 해상도를 4배 업샘플링 할수록) 성능이 더 좋은 것을 확인할 수 있습니다. 아무래도 해상도가 더 크다는 것은 더 세밀한 영역들에 대한 대응관계를 계산할 수 있기 때문에 이러한 성능 향상 경향성은 당연해보입니다. 대신에 stride 값이 1이 된만큼 사용되는 연산량과 추론 속도 등에 대한 결과는 따로 없어서 아쉽게 느껴지네요.
결론
저자들의 방법론의 메인은 label을 warping으로 보이고, CRW라는 방법론이 대응관계를 self-supervised learning으로 학습시킬 때 활용될 수 있다는 점에서 재밌게 본 논문입니다.
안녕하세요 정민님 좋은 리뷰 감사합니다.
질문이 있습니다.
연속적인 tracking에 대한 이미지를 받다보니, 앞뒤 프레임에서 view가 변하거나
occulsion이 생겨서 cycle이 불가능한 영역이 생길것 같습니다.
wrap-label 방식의 augmentation을 통해, 이러한 외곽의 view가 달라져서
학습에 부정적 영향을 미치는 부분도 일부 완화가 되었다고 보는게 맞는지 궁금합니다.