안녕하세요 이번에 리뷰할 논문은 CVPR 2025년에 올라온 CityWalker Learning Embodied Urban Navigation from Web-Scale Videos 라는 논문입니다. 바로 리뷰 시작하도록 하겠습니다.
introduction
동적 도시 환경에서의 내비게이션은 고도화된 공간 추론 능력과 상식적인 규범 준수(우/좌측 통행, 신호 준수, 보도 이용등등)가 요구되기 떄문에 이런 복잡한 도시환경에서의 내비게이션은 어려운 도전과제라고 합니다. 현재 연구되고 있는 기존 RL/IL 접근법은 일반적으로 정적이거나 통제된 환경에서는 뛰어난 성능을 보이지만 실제 이런 동적이고 복잡한 도시 내비게이션에서는 많은 어려움이 있다고 합니다. 또 이러한 복잡한 상황이나 환경에 대한 내용을 담고 있는 teleoperation 시연 데이터셋도 아직은 많이 부족하고 데이터 규모나 다양성의 한계가 있기 때문에 다양한 도시 시나리오 전반에 대한 일반화 성능이 약하다고 합니다. 결과적으로 이 embodied urban navigation은 여전히 해결되지 않은 문제로 남아있다고 합니다.
그래서 저자들은 최소한의 annotation만 필요하면서도 일반화 성능을 최대화할 수 있는 데이터 기반 접근법을 생각하게 되었고 저자들은 웹 스케일의 도시 보행 및 주행 영상을 활용해서 embodied urban navigation 모델을 학습하는 Citywalker라는 프레임워크를 제안합니다. 서로 다른 지리적 위치, 날씨 조건, 시간대를 포함하는 인터넷 기반 영상 2000시간 이상으로 학습시킨다고 합니다.
저자들은 이런 대규모 스케일의 in the wild 영상으로부터 action supervision을 효과적으로 뽑아내기 위해서 범용적으로 쓰이는 VIsual odometry 모델을 통해 pseudo label을 생성하여 학습에 활용합니다. 즉, 비용이 많이 드는 수작업 주석 없이도 대규모 모방 학습이 가능하도록 해당 영상들로부터 행동 supervision을 추출하는 단순하면서도 확장 가능한 데이터 처리 파이프라인을 저자들은 도입합니다.
결과적으로 주행영상으로 학습한 모델도 사족보행 에이전트에서 잘 동작하는 모습을 보였고 나아가서 도시 보행 데이터와 주행데이터(논문에서 저자는 바퀴로 움직이면 주행, 사람이 걷거나 4족 보행 로봇이 움직이는 걸 보행으로 표현합니다.)를 함께 사용하는 cross domain 학습 설정에서 성능이 더 향상됨을 보였다고 합니다.
Embodied Urban Navigation
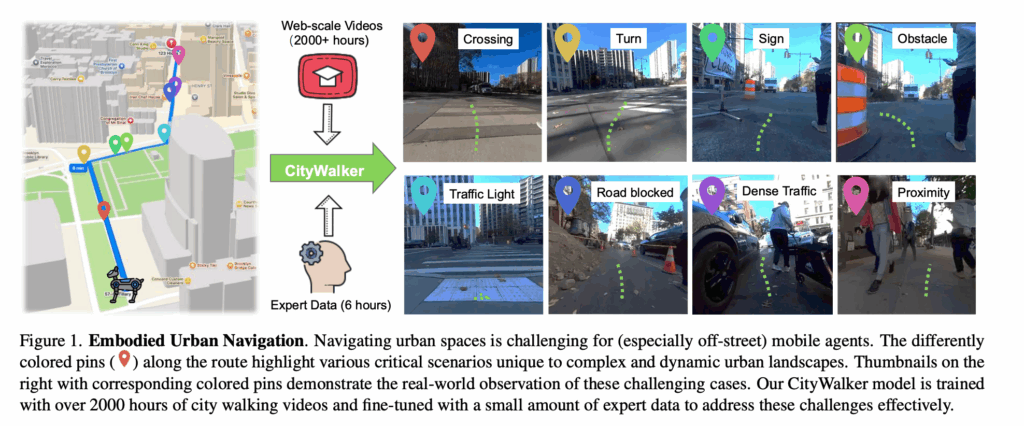
먼저 저자가 풀고자하는 문제 설정은 동적인 도시환경에서 내비게이션 도구가 제공하는 일련의 waypoint(GPS 정보)를 따라서 현재 위치에서 지정된 목표 waypoint 위치까지 이동하는 것입니다. 동적 도시환경에서 point-goal navigation 문제를 풀고자하는 설정이라고 보시면 됩니다.
각 시각 t 에서 에이전트는 RGB 관측 o_t, 현재 GPS 위치 p_t, 서브골 waypoint w_t를 입력으로 받게되고 에이전트는 과거 관측 및 위치정보를 바탕으로 행동a_t를 출력하는 정책 \pi(a_t \mid o_{(t-k):t},\ p_{(t-k):t},\ w_t) 를 학습하게 됩니다. 여기서 행동 a_t는 waypoint들의 시퀀스라고 보시면 좋을 것 같습니다.
저자들은 k = 5(과거 히스토리 길이)를 사하면서 다음 5개 시점에 대한 행동도 함께 예측합니다. (본 연구는 연속된 두 waypoint 사이를 이동하는 문제에 초점을 둔 연구임.) 그리고 에이전트는 현재 서브골 w_t를 즉각적인 목표로 간주하고 자신의 관측과 위치 정보를 기반으로 이 서브골에 도달했는지 여부를 스스로 판단도 하고 w_t에 도달했다고 판단되면, 에이전트는 waypoint 시퀀스 내의 다음 waypoint로 이동하게 되는 식의 흐름으로 동한다고 이해하시면 좋을 것 같습니다.
그리고 저자들은 오프라인 teleoperation 데이터에서, 예측된 각 action과 ground truth action 사이의 오차를 주요 평가 지표로 사용하게 되는데 여기서 활용되는 L2 거리는 직관적인 지표이긴 하지만 저자들은 이 지표만으로는 문제의 핵심을 충분히 반영하지 못한다고 지적하면서 예측한 action의 품질을 더 잘 반영하는 새로운 평가지표 Average Orientation Error (AOE)를 제안합니다.
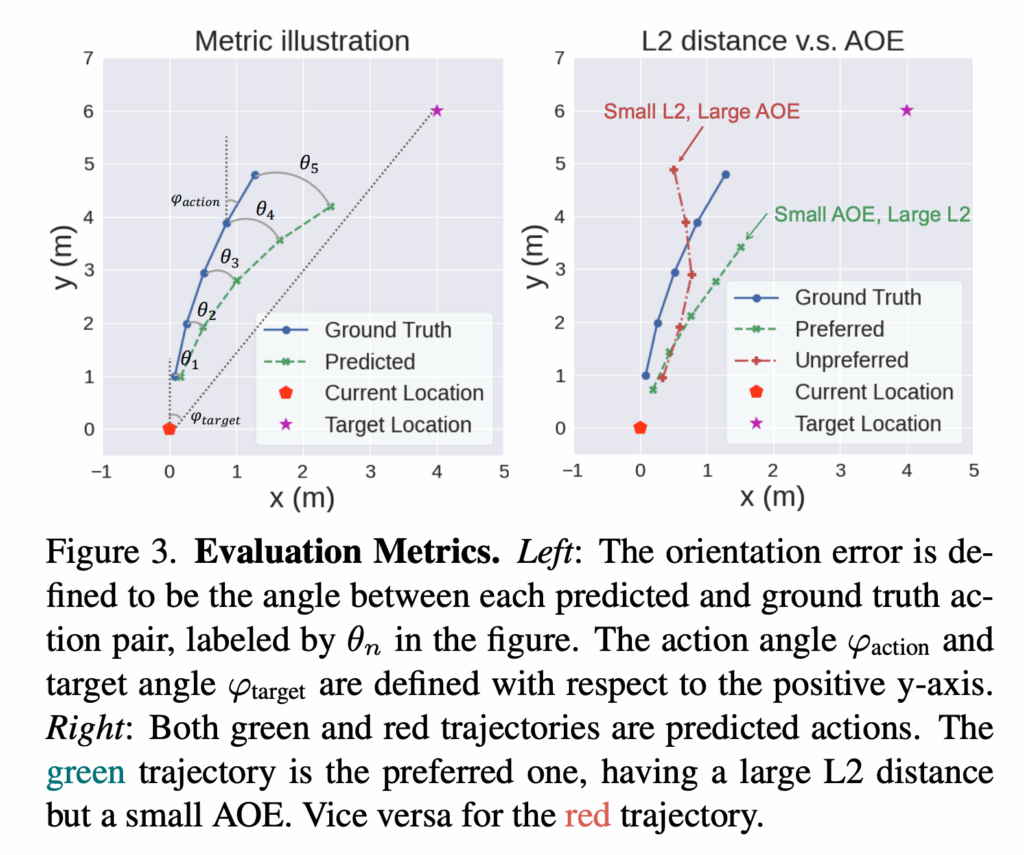
fig 3에서 오른쪽 예시처럼 빨간 traj 가 초록 traj 보다 L2 오차는 더 작을 수는 있어도 실제 목표 방향에서는 더 많이 벗어난 방향으로 움직일 수도 있기 때문에 저자들은 예측 action과 gt action 사이의 각도 차이를 기반으로 하는 AOE 평가를 활용합니다.
수식은 아래와 같습니다.
AOE(k)=\frac{1}{n}\sum_i^n \theta_i^k =\frac{1}{n}\sum_i^n \arccos \frac{\langle \hat a_i^k, a_i^k \rangle}{|\hat a_i^k||a_i^k|}
k는 예측된 action의 인덱스 (미래 몇 번째 step인지)이고 \hat a_i^k는 i번째 샘플의 k번째 예측 action입니다.
각 step에서 샘플에 대한 action과 Gt Action 각도차이의 평균값을 평가지표로 사용한다고 보시면 좋을 것 같습니다.
그리고 여기서 또 저자들은 미래 k개 step에 대해 단순 평균을 취하면 오차가 매우 작은 step들 때문에 전체 성능이 과소평가 될 수 있는 문제가 있을 수 있다고 하면서 예측된 action들 중 최대 orientation error를 사용하는 Maximum Average Orientation Error (MAOE)도 제안을 합니다.
MAOE=\frac{1}{n}\sum_i^n \max_k \theta_i^k각 샘플마다 미래 예측들 중 가장 방향 오차가 큰 step을 뽑고 그것을 평균내는 방식이라고 보시면 좋을 것 같습니다.
그렇다고 저자들은 L2를 사용안하는 것은 아니고 action의 이동거리가 작은 경우에는 이런 orientation error가 노이즈에 민감해질 수 있기 때문에 L2도 보조적인 평가지표로써 활용합니다.
Action Labels from Videos
저자들은 인터넷에서 수집한 city walking 비디오(1인칭 시점-person view)를 활용합니다. 이러한 비디오들은 보행자와의 상호작용, 교통 신호 준수, 다양한 장애물 회피와 같은 동적인 도시환경을 내비게이션 할 때의 복잡성을 자연스럽게 담고 있다고 합니다. 따라서 저자들은 다양한 날씨, 조명 조건을 포함하는 2000시간 이상의 도시 보행 비디오 데이터셋을 구축합니다.
여기서 IL을 위한 액션라벨 생성을 위해서 저자들은 수집한 보행 비디오에서 trajectory pose를 추출을 해야만했고 여기서 VO 방법론을 활용합니다. SOTA방법론인 DPVO를 활용하여 수도 라벨링을 했다고 합니다.
근데 여기서 생길 수 있는 의문점은 VO 시스템의 가장 큰 문제인 누적오차 때문에 전역 trajectory 정확도에 대한 문제입니다. 근데 저자들이 제안한 방식에 대해서는 제한된 길이의 action 시퀀스(과거 5 step에 대한 미래 5 step)만을 예측하는데에 초점을 두기 때문에 저자들은 짧은 시간 윈도우 내의 상대 pose만 사용하기 때문에 전역 traj 정확도 문제는 크게 고려할 사항이 아니라고 합니다.
그리고 VO 방법들은 스케일 모호성 문제를 가지고 있기 때문에 서로 다른 데이터 간 trajectory 길이가 일관되게 나오지 않을 수 있습니다.
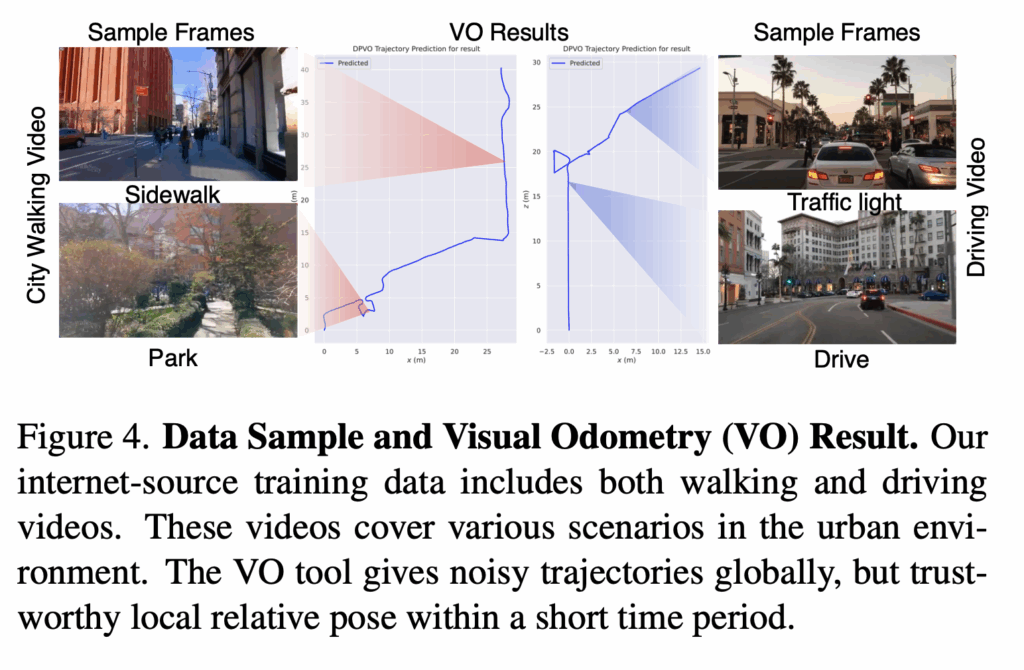
위 예시를 보면 실제로는 주행 비디오의 traj 가 보행 비디오보다 더 길어야 맞는데 DPVO 출력에서느 오히려 더 짧게 나타날 수 가 있습니다. 따라서 자자들은 이러한 문제를 해결하고자 GNM 연구를 따라서 각 traj 내 평균 step length 로 각 action을 정규화를 함으로써 VO의 스케일 모호성 문제를 해결하고자 하였고 결과적으로 모델은 일관되고 추상화된 action space에서 policy를 학습할 수 있게된다고 합니다.
추가적으로 deployment 단계에서는 예측된 action을 배포하고자하는 로봇의 고유한 step length를 사용해서 다시 역정규화 해서 실제 환경에서 적절한 움직임이 수행되도록한다고 합니다.
위와 같은 데이터 처리 파이프라인은 도시 보행 비디오를 넘어서 egomotion 이 포함된 모든 비디오 소스에 적용될수도 있기 때문에 온라인에 풍부하게 존재하는 주행 비디오에도 적용가능합니다. 그래서 보행 내비게이션에서 차량 내비게이션으로 전환하는 것과 같은 cross domain/cross embodiment 과제에 대해서 보다 일반화 가능한 내비게이션 policy를 학습할 수도 있습니다.
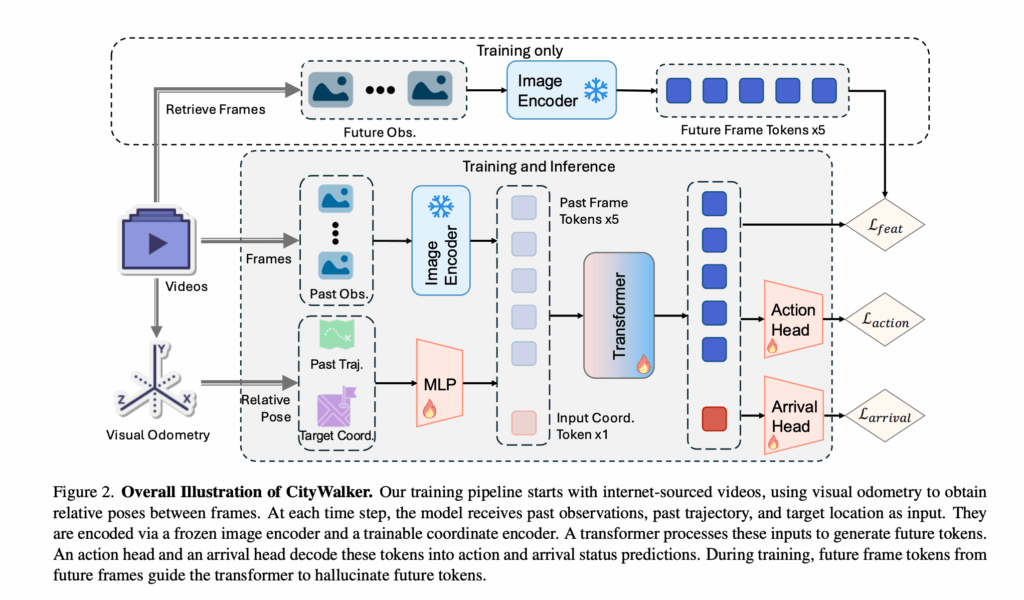
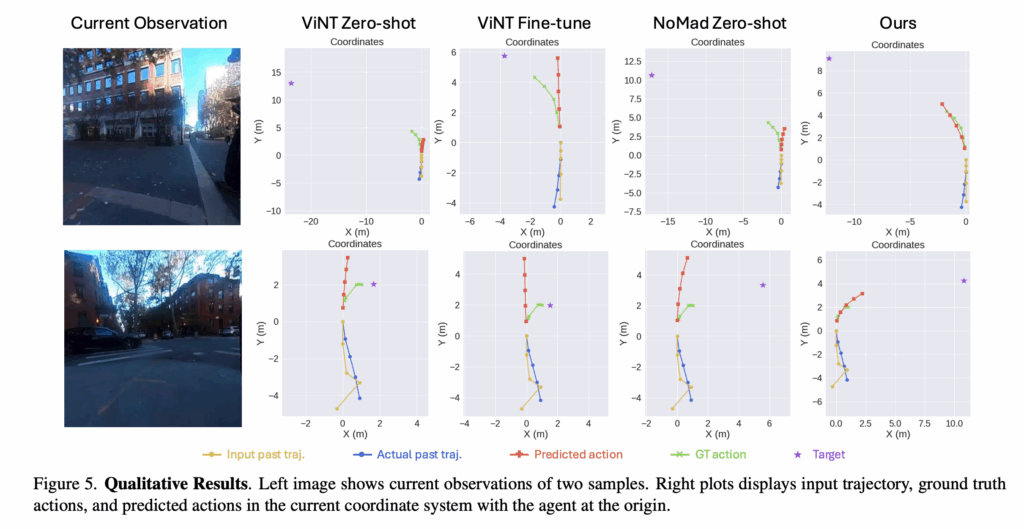
위는 해당 City Walker의 프레임워크입니다. 위 구조는 기존 연구 ViNT,NoMaD를 기반으로 설계를 했다고 합니다. 먼저 모델은 각 시간 step에서 과거 observation, 과거 trajectory, 그리고 target 좌표를 입력으로 받게됩니다. 이 입력들은 각각 이미지 인코더, 좌표 인코더를 통해서 인코딩( k개의 이미지 feature와 하나의 좌표 임베딩)이 되고 이후 Transformer를 거쳐서 각각에 대한 token들을 생성하게 됩니다. action head와 arrival head는 각각 토큰들을 입력으로 받아서 action 시퀀스, action status를 예측하게 됩니다. 그리고 저자들은 이전 연구들에서 영감을 받아서 학습 시에 미래 프레임으로부터 얻은 future frame token이 Transformer가 예측한 토큰을 hallucinate 하도록 가이드 하게끔 설계를 합니다. (저자들은 이 설계를 Feature Hallucination이라고 부르고 학습 중 auxiliary loss로 활용을 한다고 하빈다.) 구체적으로는 출력된 이미지 토큰과 미래 프레임에서 직접 추출한 이미지 토큰 사이의 MSE 손실을 계산합니다.
그리고 앞에서 언급했지만 예측된 action의 품질을 평가 할떄 L1,L2 loss는 orientation loss 보다 덜 효과적일 수 있기 때문에 학습시에도 orientation loss를 활용합니다.
저자들은 여기서 orientation loss를 예측 action 과 gt action 사이의 코사인 유사도의 음수값으로 정의를 하여 손실항을 추가합니다.
그리고 여기에 추가적으로 예측 action 에 대한 L1 loss, 그리고 예측된 도착 상태에 대한 BCE loss를 같이 사용해서 최종 손실항은 아래와 같은 4개의 개별 손실의 가중합으로 구성이 됩니다.
L=\omega_{l1}L_{l1}+\omega_{ori}L_{ori}+\omega_{arr}L_{arr}+\omega_{feat}L_{feat}Experiments
저자들이 제안한 모델을 저자들의 연구 설정과 관련있는 outdoor navigation 모델들(GNM, ViNT, NoMaD)과 비교합니다. 이 방식들은 image goal navigation이라 저자들은 수집한 데이터에서 얻은 goal image를 사용해서 입력 goal 모달리티만 바꾼 상황에서 동일한 방식으로 테스트를 진행했다고 합니다.
저자들은 fine tuning과 오프라인 테스트를 위해서 teleoperation으로 expert 데이터를 수집했다고합니다. 데이터 수집할 때에는 Unitree Go1 사족 보행 로봇을 사용하고 라이다 센서를 활용함으로써 로봇 GT pose를 LiDAR SLAM을 통해 뽑아냈다고합니다. 총 수집량은 뉴욕시에서 모은 teleoperation 데이터 15시간이고 이 중 6시간은 fine-tuning에 9시간은 테스트에 사용했다고 합니다.
저자들은 평가에서 강조하고자 하는 몇가지 핵심 시나리오를 데이터셋에서 정의합니다. 이를 위해서 저자들은 GT trajectory를 분석하고, 핵심 시나리오를 정의하기 위해서 객체 탐지도 수행합니다. 저자들이 데이터셋 내에서 정의한 핵심 시나리오는 아래와 같습니다.
- Turn: ground truth action의 진행 방향이 크게 바뀌는 경우.
\phi_{\text{action}} > 20^\circ 일 때로 정의합니다 (Fig. 3) - Crossing: 에이전트가 도로 횡단(교차로/횡단보도) 구간에 있는 경우
신호등이 하나라도 score > 0.5로 탐지되면 해당한다고 정의합니다. - Detour(우회): action 각도가 target 각도에서 크게 벗어나는 경우
|\phi_{\text{action}} - \phi_{\text{target}}| > 45^\circ일 때로 정의합니다 (Fig. 3) - Proximity: 사람이 에이전트에 매우 가까이 있는 경우.
탐지된 사람들 중 가장 큰 bounding box 면적이 이미지 전체 면적의 25%를 초과하면 해당한다고 정의합니다. - Crowd: 에이전트 주변에 사람이 많은 군중 상황인 경우.
사람이 5명 이상 탐지되면 해당한다고 정의합니다.
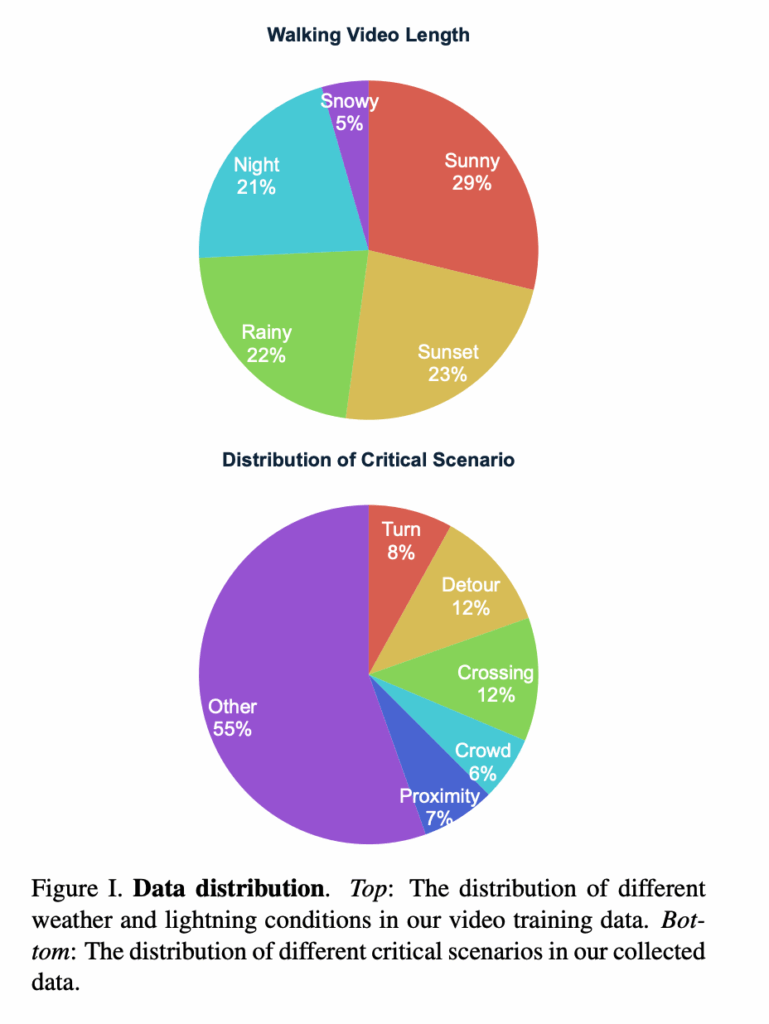
저번주에 리뷰했던 SCAND 데이터 셋에서 사회적 준수를 위해서 저자들이 각각 궤적에 대해서 태깅을 했다고 하였는데 비슷한 맥락에서 여기서는 도시 주행에 있어서 중요한 핵심 시나리오 평가를 위한 세팅으로 보시면 좋을 것 같습니다. 결국 이러한 핵심 시나리오들이 전체 데이터의 절반보다 적은 비중을 차지하긴하지만 저자들은 이러한 핵심 시나리오를 잘 수행하는 능력이 도시 내비게이션을 잘하는데 있어서 중요한 요인들이라고 주장합니다.
저자들은 먼저 Q1. CityWalker 모델이 복잡한 도시 환경에서 성공적인 내비게이션을 할 수 있는지에 답하고자 오프라인 데이터 평가와 실제 환경 내비게이션 배치 실험을 수행하여 제안 모델과 베이스라인들을 벤치마킹합니다.
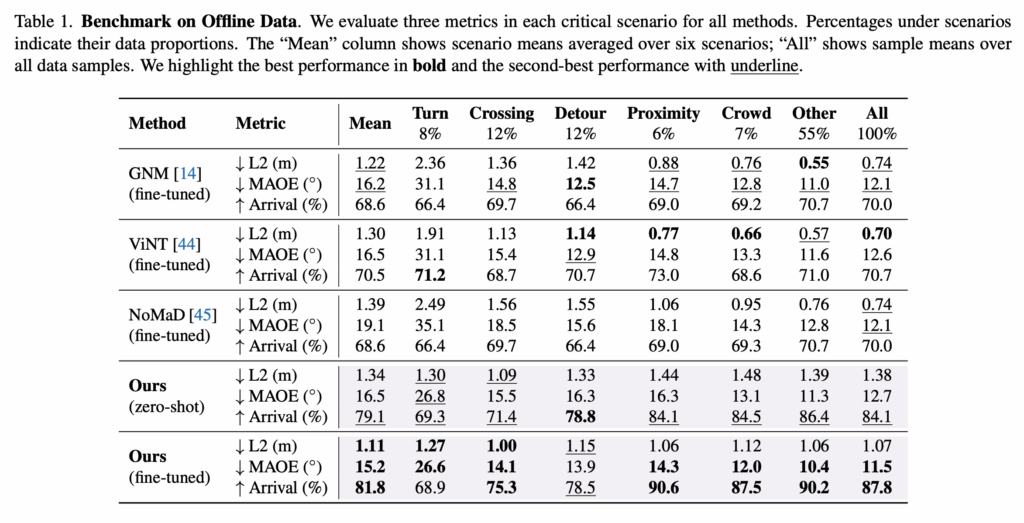
위는 각기 다른 핵심 시나리오에서의 벤치마크 결과를 보여줍니다. 전반적으로 저자들의 fine-tuned 모델은 detour를 제외한 모든 시나리오에서, 대부분 우수한 성능을 보입니다. 저자들은 detour 시나리오에서 상대적으로 성능이 덜 좋은 이유를, 웹 비디오 학습 데이터에서 detour에 해당하는 데이터 비중이 작기 때문이라고 추정합니다. 그리고 여기서 저자들의 -shot 모델이 fine-tuned된 베이스라인들과 비교해 성능이 비슷하거나 심지어 더 좋다는 점을 어필하는데, 학습 데이터가 인간 보행 비디오이고, 실제 배치는 로봇(도메인 갭)이고 입력 모달리티/환경 차이도 존재한다는 점을 고려하면, 대규모 사전학습의 효과가 크는 것을 보여준다고 주장합니다.
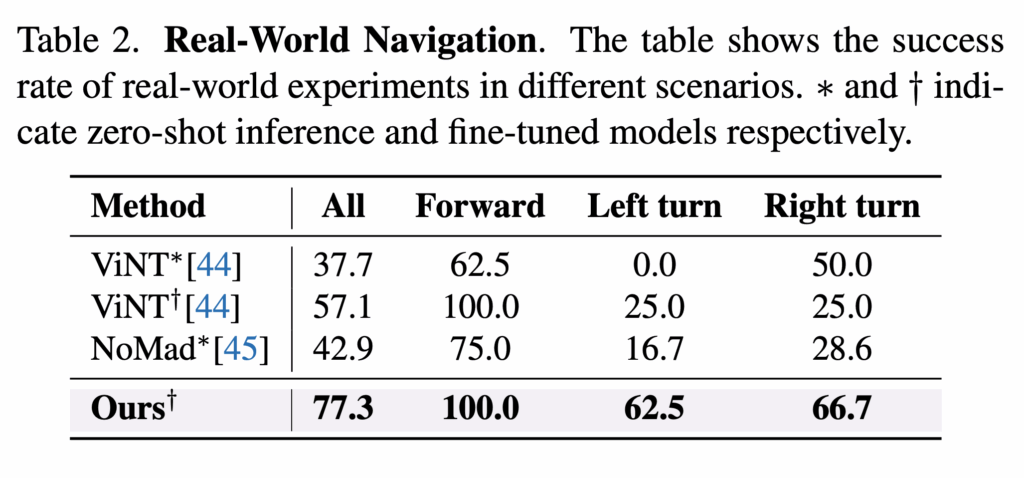
위는 실제 환경에서 진행한 실험 결과입니다. 저자들은 제안한 모델과 베이스라인 방법들을 동일한 Unitree Go1 사족보행 로봇에 탑재해서 이전에 보지 못한 도시 환경에서 실제 내비게이션 실험을 수행합니다. 여기서 저자들은 실제 환경 테스트를 직진(forward), 좌회전(left turn), 우회전(right turn) 세 가지 경우로 분류하여, 케이스별 분석이 가능하도록 합니다. 각 케아스마다 8–14회의 trial을 수행하고
각 trial은 모델이 목표 위치로부터 5m 이내에서 도착을 예측하면 성공으로 간주가고. 잠재적 충돌 위험이나 시간 초과로 인해 사람이 개입한 모든 경우는 실패로 처리했다고 합니다. 결과적으로 저자들의 모델이 모든 케이스에서 가장 높은 성공률을 보입니다.
위는 정량적 결과로 저자들의 모델은 직진 뿐만 아니라 회전 상황에서도 좋은 성능을 보입니다. 도시 환경처럼 방향 전환이 자주 발생하고 정밀한 조향이 요구되는 환경에서 저자의 방법론이 안정적으로 사용가능하다고 합니다.
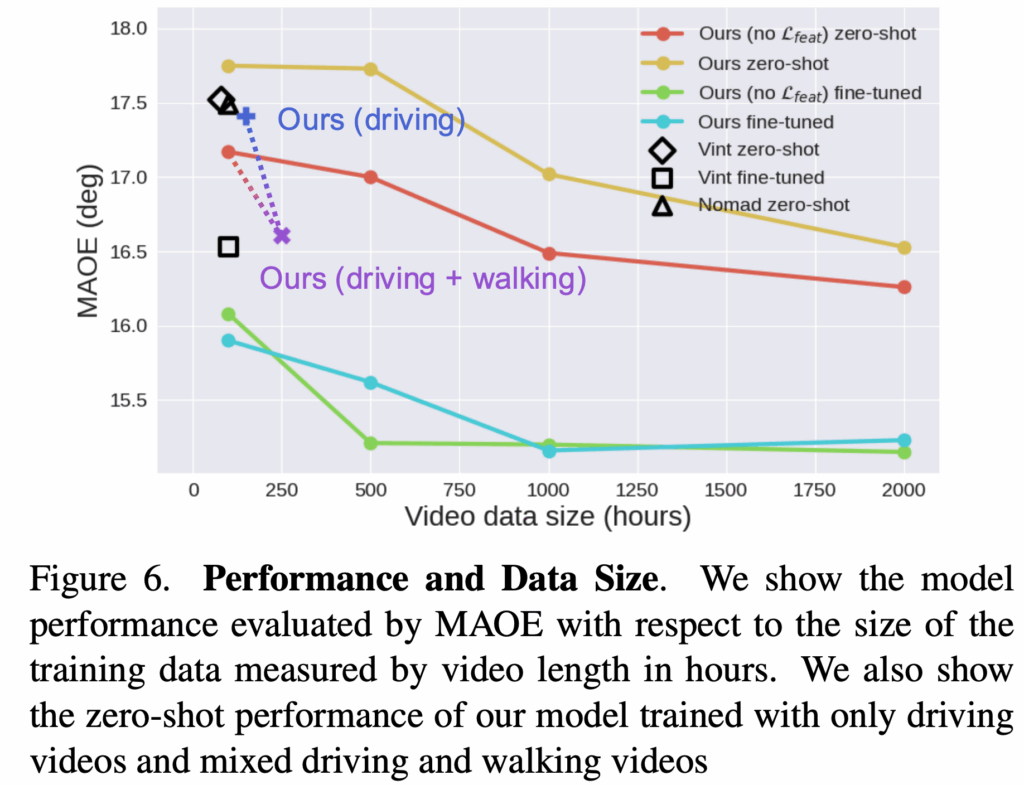
저자들은 Q2.학습 데이터 셋의 크기를 늘리면 도시 내비게이션 모델의 성능이 어느정도 까지 좋아지는지에 대한 답을 하기 위해서 학습 데이터의 크기를 비디오 길이(hours)로 측정하고, 그에 따른 모델 성능을 MAOE 기준으로 평가한 결과를 제시합니다. 위 그래프는 학습 데이터 양이 증가할수록 저자들의 zero-shot 성능이 향상되는 결과를 보입니다. 특히 1000시간 이상의 비디오로 학습했을 때 저자들의 zero-shot 모델(빨간 선) 이 fine-tuned ViNT 모델(□) 보다 더 좋은 성능을 달성하는 결과를 보입니다.
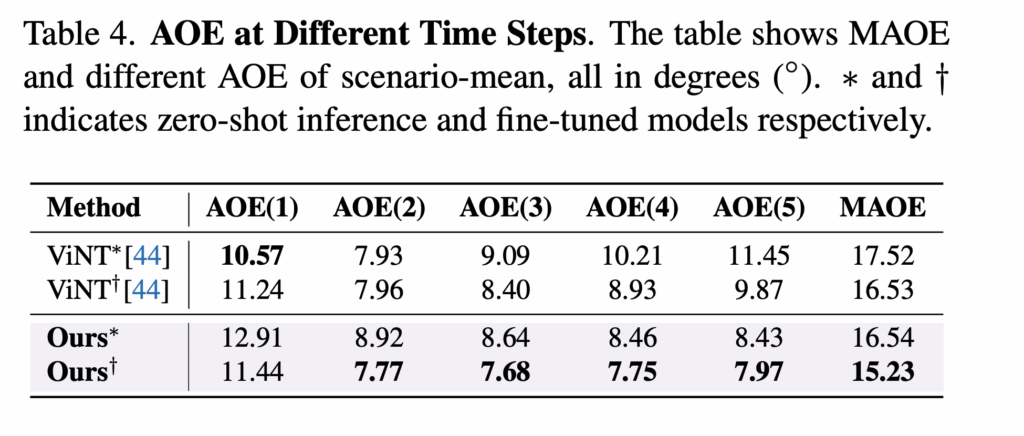
Q3. 파이프라인의 각 구성요소가 실제 도시 내비게이션에서 모델의 성능과 신뢰성을 어떻게 향상시키는가?에 대한 답을 하기 위해서 저자들은 위 테이블 처럼 서로 다른 시간 step에서의 AOE, k=1부터 k=5까지의 AOE(k) 를 분석합니다. ViNT는 예측 step이 진행될수록 orientation error가 증가하는 모습을 보이지만 저자들의 방법론은 2번째 step 부터 5번째 step까지 AOE가 비교적 일정하게 유지되는 모습을 보입니다.
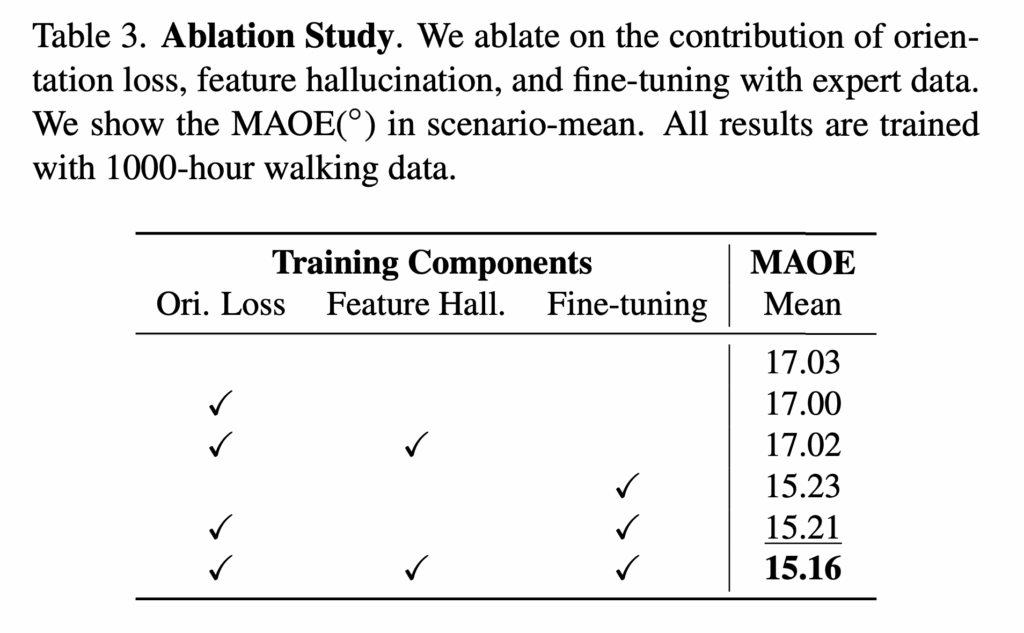
마지막으로 ablation study 입니다. expert data로 fine-tuning을 수행했을 때 MAOE가 개선되는 모습을 보이고, 결과적으로로봇 도메인(in-domain)의 전문가 정보를 사용하는 것이 효과적이다라는 것을 보여주는 결과라고 보시면 좋을 것 같습니다. 반면에 저자들이 제안한 orientation loss와 feature hallucination loss로 인한 개선은 미미한 모습입니다.
Conclusion
VO로 라벨 뽑아서 데이터셋 확장하는 건 흔하기도하고 기존 방법론과도 파이프라인 자체가 크게 다를게 없다는 생각은 들었지만 저자들이 Embodied Urban Navigation을 명확한 과제로 세팅하고 이를 풀기위해서 웹스케일 도시 보행 비디오를 navigation용 행동학습 데이터로 바꾸고 실제 도심 내비게이션 수행하는데 있어서 중요한 사회적 규범을 고려한 핵심 시나리오에 대해서 스케일링이 실제로 먹힌다를 실증했다는 점에서 기존 방법론들과는 차이점은 있는 것 같습니다. 이만 리뷰 마치도록 하겠습니다.
감사합니다.
안녕하세요 우현님, 좋은 리뷰 감사합니다.
해당 방법론에서 진행한 시나리오가 비교적 단순한 시나리오인데 로터리나 대형 교차로처럼 진입·합류·출구 선택이 동시에 필요한 복합 상황에서는 모델이 어떻게 행동하는지, 그리고 이러한 시나리오가 모빌리티 쪽에서 기본이 되는 시나리오인지 궁금합니다.
좋은 리뷰 감사합니다.
안녕하세요 우현님,
좋은 리뷰 감사합니다.
제가 여쭤보고싶은거는 평가방법인데요 저자들이 평가가 MAOE 라는평가 지표가 메인인거같은데 이는 어떻게 계산되는건지 궁금합니다. 단순 궁금한 질문이긴한데 로봇개가 계속해서 연속적인 값을 output으로 주는거같은데 멈춰야할때 정지값도 내뱉기도 하나요?
감사합니다
안녕하세요 우현님 좋은 리뷰 감사합니다.
DPVO를 이용한 pseudo-labeling 부분이 궁금합니다.
이를 통해 GT가 없는 수많은 데이터를 학습에 쓸 수 있을것 같은데
실제 데이터와 성능차이가 많이 나는지 궁금합니다.