안녕하세요 최인하입니다. Robot이 다양한 task와 environment 에서 강건하게 작동하도록 하는 것은 robot domain에서 중요한 주제인데요. VLA model이 등장하면서 이러한 문제가 어느정도 해결되는 것처럼 보였습니다. 하지만 기존으 VLA model들은 VLM의 scaling에 집중하였는데요. VLM이 internet-scale의 vision 정보와 language 정보를 다루는 것은 맞지만 실제 환경과 상호작용하는 robot 특성상 action에 대한 표현력은 아직도 하나의 bottleneck으로 남겨져있습니다. 제가 이번에 리뷰하는 DexVLA 논문은 diffusion based action expert의 사용과 curriculum learning 방식을 사용하여 새로운 환경, task, robot hardware 에서도 강건하게 작동하는 모습을 보여줍니다. 제가 읽어봤을 때는 무작정 VLM의 크기를 키우는 것보다 로봇을 위한 학습 방식을 제안하는 것 같았습니다. 리뷰 시작해보겠습니다.
위에서 언급한 것 처럼 기존의 VLA model 들의 접근 방식은 데이터적으로 효율적이지 않고, action을 표현하는데 VLM의 scale을 키우는 방식은 non-sense합니다. 따라서 논문에서는 2가지 방식을 제안합니다.
- Billion-Parameter Diffusion Expert
- Embodied Curriculum Learning
우선 기존의 action expert는 cross-embodiment data를 처리하는데 제약이 있었다고 하며, 이를 해결하기 위해서 multi-head diffusion expert를 사용했다고 합니다. 각각의 head는 specific embodiment를 다룬다고 하네요. 그리고 모델 사이즈를 키워 10억개의 파라미터를 사용했다고 합니다. 제 생각이긴 하지만 visual generation bias가 있는 diffusion model을 action expert로 사용하는 점과 모델 사이즈를 키운 것이 앞에서 저자들이 말한 문제 정의와 뭔가 맞지 않는 것 같은 느낌이 들긴하네요.
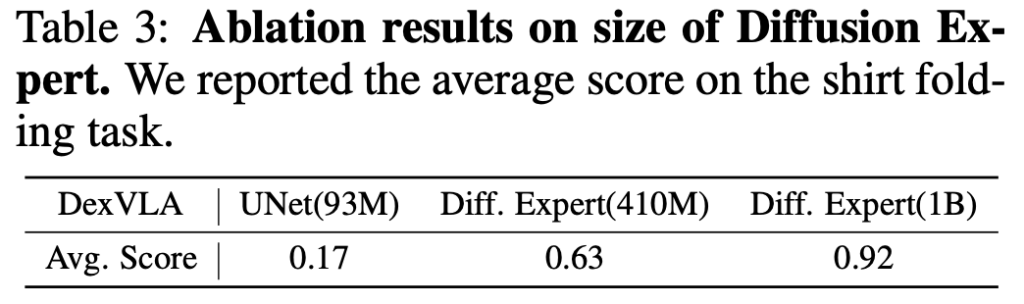
하지만 평가 지표에서 볼 수 있듯이 Diffusion expert가 그리고 파라미터 수가 늘어날 수록 모델의 표현력은 증가하여 성능이 올라가는 모습을 볼 수 있습니다.
두번째는 Embodied Curriculum Learning 방식인데요, 저는 이 부분이 논문의 킥인 것 같습니다. 로봇에게 맞는 학습 방식을 제안하는데요. 총 3가지의 stage로 구성이 되어있습니다. 이제 저자가 제시하는 2 가지 방식을 자세히 설명해보겠습니다.
Method
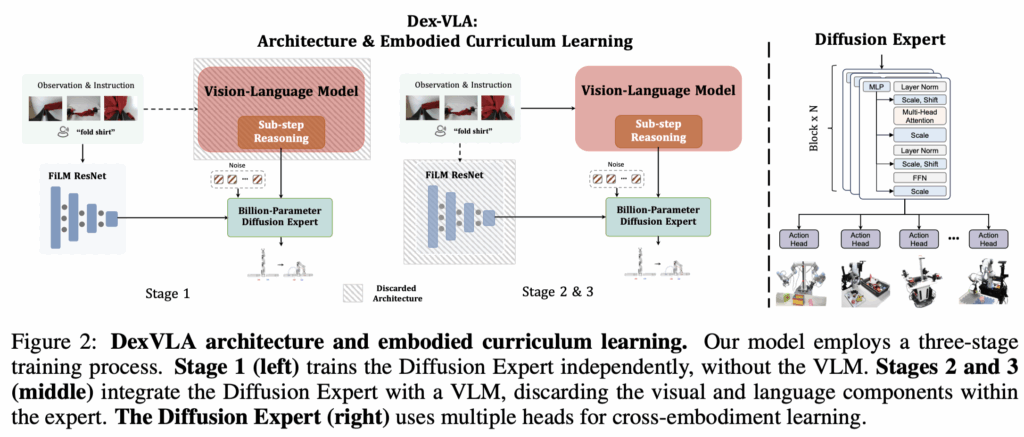
설명에 들어가기 앞서 전반적인 architecture에 대한 설명을 해보면 model을 처음 딱 봤을 때 DP와 매우 유사한 구조라고 생각했습니다. transformer 기반 DP에 VLM을 추가한 느낌? 요약하면 Diffusion expert에 VLM의 action token이 input으로 들어가고 FiLM layer로 인한 reasoning token이 주입된다고 생각하시면 될 것 같습니다. VLM은 Qwen2-VL을 사용했고, Diffusion model은 ScaleDP 1B 모델을 사용했다고 합니다.

하지만 ScaleDP는 cross-embodiment를 수용하도록 설계되지 않았으니까 위에서 언급한 것 처럼 multi-head를 추가해줬다고 하네요. 실험에 사용한 embodiment setting은 위와 같습니다.
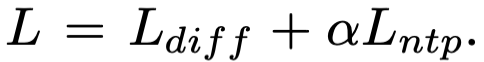
Loss function은 위와 같습니다. diffusion loss와 next token prediction loss의 가중합입니다. 알파 값은 1로 설정했다고합니다.
Embodied Curriculum Learning
Curriculum Learning이란 실제 사람이 배우는 것처럼 model에게 학습 시킬 때 simple to complex 방식으로 학습시키는 전락을 의미합니다. 저자는 어떻게 curriculum을 구성했을지 각 stage 별로 살펴보겠습니다.
위의 model architecture 그림을 보면서 이해하시면 편할 것 같습니다. 먼저 요약해서 설명해보자면,
- Stage 1 : model이 cross-embodiment data로 전반적인 motor skills을 배웁니다. model 입장에서는 아하~ 로봇의 움직임이 이렇게 구성되어있구나~ 를 배우는거죠.
- Stage 2 : 이제 hardware specific한 data로 배우면서 실제 작업에 수행할 hardware의 움직임에 대해서 더 자세히 배우게 됩니다. 여기서는 모델 입장에서는 stage 1에서 전반적인 motor skills를 배웠으니까 더욱 익히기 쉽겠죠? 마치 우리가 더하기 빼기 배우고 곱하기 나누기 배우는 것 처럼 말이죠
- Stage 3 : 이제 마지막으로 로봇이 수행해야 할 specific한 task를 배우게 됩니다.
저희가 실습했던 smolvla 같은 경우에도 데이터 모아서 바로 model을 fine-tuning 시키는 거였는데 여기서는 curriculum 을 이용해서 로봇에게 사람처럼 학습을 시키는 방식을 사용합니다. 하지만 그만큼 stage를 잘 구성해야 되겠구나 생각이드네요. 이제 전반적인 curriculum에 대해서 알았으니 하나씩 뜯어보겠습니다.
stage 1에서는 model 그림에서 본 것 처럼 VLM component를 decoupling 시키고 학습을 진행합니다. 왜냐하면 VLM model은 real-environment 에서 물리적인 부분을 이해하는데 부족한 모습을 보이고 이는 action 학습 과정에서 noise로 작용할 수 있다고 합니다. 또한 FiLM layer를 통해 language grounding 없이 학습을 진행함으로써 조금 더 강건한 action을 생성할 수 있는 능력을 model에게 부여한다고 하네요. 이렇게 되면 그냥 DP 구조인 것 같은데 visuomotor policy를 학습 시킨다는 의도 같습니다.
stage 2에서는 stage 1에서 cross-embodiment data 를 통해서 visuomotor skill을 배웠으니까 이제 target embodiment data로 학습을 진행해야겠죠. 수학 개념 배웠으니까 문제 푸는 느낌인 것 같습니다. 이제는 VLM 도 visual encoder를 freeze 한 상태로 학습에 참여하며 action expert는 VLM의 high-level vision language 정보 이해 능력의 도움을 받아 target robot의 motor control space에 대한 이해를 갖추게 됩니다.
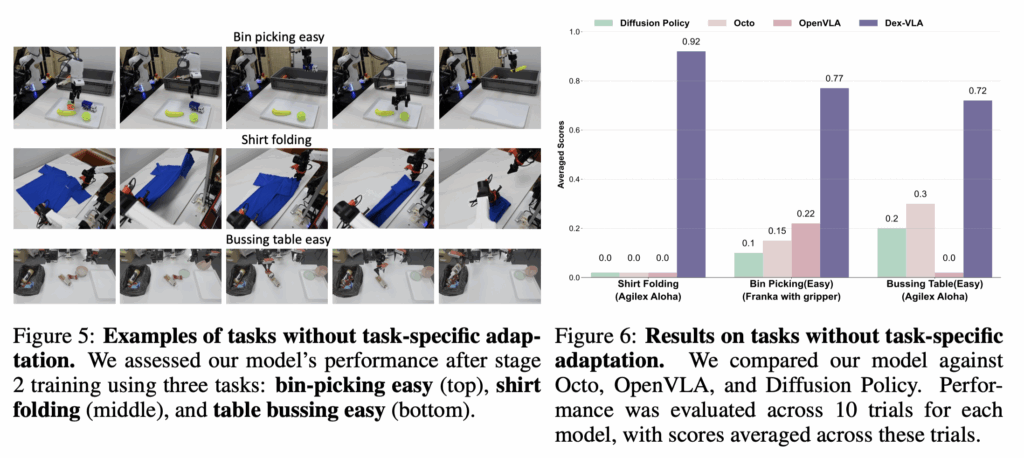
stage 2만 진행하고 deploy를 진행했을 때 기존의 VLA, VA model 보다 성능이 좋은 모습을 확인할 수 있는데요. 여기서 without task-specific은 model을 domain-specific data 로 fine-tuning하기 이전이라고 생각하시면 됩니다.
stage 3은 model을 domain-specific 한 data로 fine-tuning 시키는 과정입니다. 이 때 저자는 model이 복잡하고 dexterity한 task를 수행하기 위해서 학습 과정에서 sub-step 방식을 사용한다고 합니다. 신기한 점은 밑에 사진에서 보이는 것처럼 sub-step 자체를 모델에게 input으로 사용하는 대신 모델이 sub-step 언어 설명을 스스로 학습하고 생성하도록 합니다. pi-0에서 사용하는 SayCan 같은 기법이 아닌 VLM backbone이 sub-step을 생성하고 이를 policy에 반영하여 action을 생성하는데 도움을 준다고 하네요.

아래 표는 Appendix에 나와있는 표로 sub-step을 SayCan 을 사용하여 나누는 것과 VLM-backbone 자체가 생성해내는 것 두가지를 모델에 적용하여 비교한 결과입니다.

high level policy model에게 의존하는 것이 아닌 VLM backbone 자체를 implict high level policy로 보고 sub-step을 생성해 내는 것이 model 내적으로 action에 대한 이해가 더 늘어나는 것 같습니다.
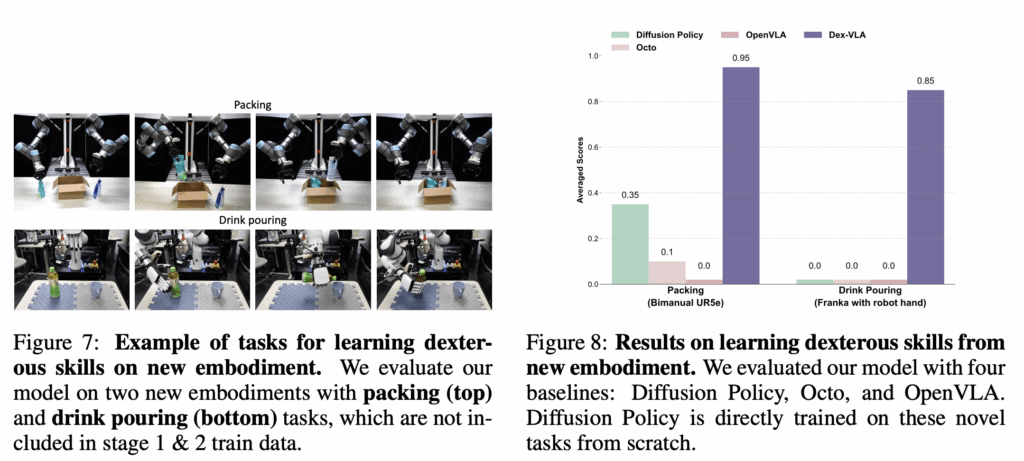
위 평가지표는 새로운 embodiment를 stage 3로 학습을 시킨 결과를 보여주는데요, 다른 baseline model과 비교했을 때 높은 성능을 보여줍니다. 특히 robot hand가 사용되었을 때 다른 model들은 한번도 성공하지 못한 모습을 보여주는데요. task 자체가 어려워서 그런가 아니면 고차원의 데이터가 사용돼서 그런가 DP 또한 0 퍼센트의 성공률을 보이는 점이 놀라웠습니다. curriculum learning 방식 때문인지 DexVLA model은 높은 성공률을 보이는 것 같습니다.
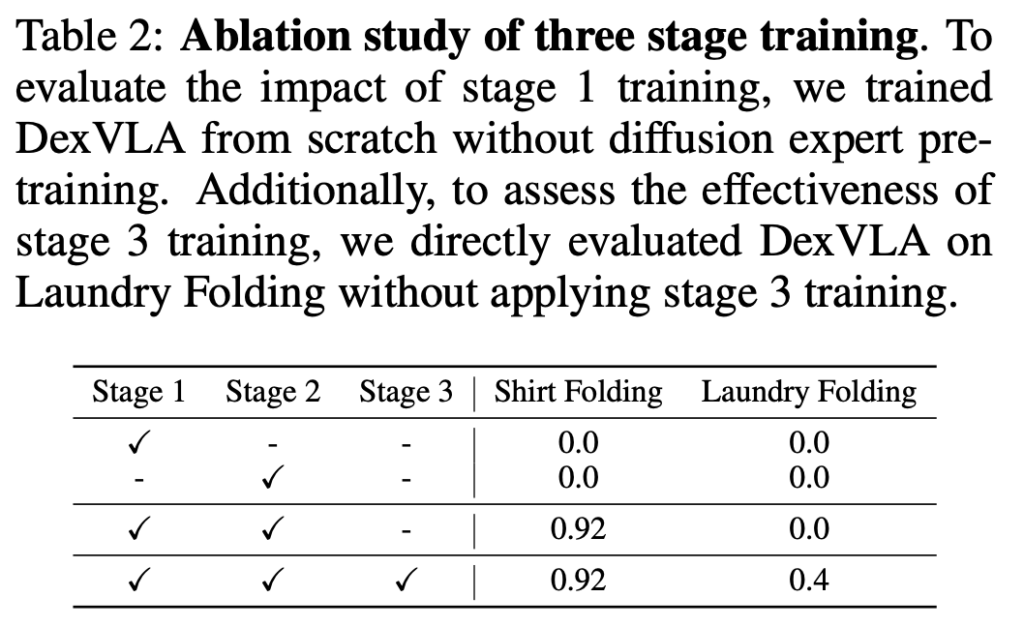
마지막 평가지표입니다. 각각의 stage가 모델에게 어떤 영향을 미치는지 보여주는 표인데요. stage 1만 진행하면 DP의 구조와 일치한다고 생각을 했는데요 성능이 0이 나왔습니다. task specific하지 않은 데이터 즉 cross-embodiment 데이터로 학습을 진행한 이유 같습니다.
제가 생각하는 이 논문은 기존 VLA 방식들이 VLM scale에 의존하는 문제를 이야기하며, robot domain에 맞는 학습 방식과, sub-step reasoning을 통한 VLM의 action에 대한 표현력을 높이는 접근 방식이 main – contribution인 것 같습니다. 단순히 데이터를 늘리고 VLM을 scaling 하는 방식도 있겠지만 VLA에 맞는 VLM, VLA에 맞는 학습 방식도 중요하다고 생각이드네요! 감사합니다!
안녕하세요 인하님 좋은 리뷰 감사합니다.
‘VLM backbone이 sub-step을 생성하고 이를 policy에 반영’하는 방식이라고 설명해주셨는데 정확히 어떤 과정인지 궁금합니다. sub-step에 대한 정보가 모델의 latent space에 implicit하게 포함되는 것이라 이해했는데, 올바른 planning이 어떻게 가능한 것인지, 이 관점에서 VLM 쪽의 학습은 어떻게 이뤄지는지 궁금합니다.
감사합니다.
안녕하세요 인하님 리뷰 감사합니다.
몇가지 궁금증이 생겨 질문 남기고 가겠습니다
Q1. 혹시 다양한 Dextrous Hand에 대한 강인성을 보이는 내용에 대한 실험은 없었을까요?
Q2. Dexhand들은 joint space에서 액션들이 다 출력되는것으로 알고있는데, 2지 그리퍼와 dex hand에 대한 general한 모습을 보이는게 multiple head 덕분인가요? 조금만 추가설명 부탁드립니다
Q3. 같은 아키텍쳐라도 학습 전략에 따라서 성능이 많이 차이날 수 있는데 stage1과 2&3을 분리시켜 학습하는 것에는 어떤 의미가 있나요?