해당 논문이 CVPR 2026에 제출된 것 같은데, 아직 정확한 정보 확인은 어렵습니다. 해당 논문은 다양한 VFM에 대하여 affordance 추론 능력에 대하여 분석한 논문입니다.
Abstract
저자들은 visuals system이 정말로 affordance를 이해한다는 것이 무엇일지에 대하여 고민하였고, 이를 위해서는 다음 두 가지 능력이 결합되어야 한다고 보았습니다. 저자들은 이러한 두 가지 능력을 geometric perception(물체와 상호작용이 가능한 부분 인식)과 interaction perception(에이전트가 해당 부위와 어떻게 상호작용 할 지 인식)라 보았으며, 이를 검증하기 위해 저자들은 VFM에 대하여 체계적인 검증을 수행하였으며, DINO와 같은 모델은 물체의 기하학적 구조를 인코딩하는 능력이 있고, Flux와 같은 생성 모델은 verb-conditonsed spatial attention map을 풍부하게 포함하며 이는 암묵적 상호작용에 대한 사전 지식을 제공한다는 것을 발견하였다고 합니다. 이러한 두 가지 능력이 단순 상관관계까 아니라 affordance의 구성 요소임을 입증하였으며, DINO의 기하학적 프로토타입과 Flux의 interaction map을 training-free zero-shot 방식으로 단순히 융합함으로써, weakly-supervised 학습 방식과 견줄만한 성능을 달성하였다고 합니다. 이러한 융합 실험을 통해 geometric perception과 interaction perception이 VFM에서 affordance 이해의 근본적인 요소임을 확인하였으며, 인식이 행동을 어떻게 뒷받침하는 지에 대한 메커니즘 설명을 제시하였습니다.
Introduction
visual affordance는 시각 정보를 기반으로, 장면 속 물체가 어떻게 작용할 수 있는지 설명하며, 시각적 인식과 실제 행동을 연결하는 역할을 합니다. 시각적 표현에 affordance를 부호화하여, 물체가 무엇인지 인지하는 것을 넘어, 어떻게 사용할 수 있는지까지 추론할 수 있으며, 최근 로봇 조작, 공간적 추론 등의 활용을 위해 연구가 활발히 이루어지고 있습니다. 그러나, 어떤 내부 능력이 이러한 이해를 가능하게 하는 지에 대해서는 아직 잘 알려져 있지 않으며, 해당 논문은 시각 시스템이 affordance를 정말로 이해한다는 것이 무엇을 의미하는지에 대하여 살펴보고자 하였습니다.
visual affordance 연구는 fully-supervised, weakly-supervised, open-vocabulary 방식 순서로 연구가 되어 왔습니다. 먼저, fully-supervised 방식은 픽셀 수준의 물체를 인식하는 방식으로, 기하학적 패턴을 학습하여 정밀한 예측이 가능하지만, 확장성의 한계가 존재합니다. weakly-supervised 방식은 사람과 물체가 상호작용하는 간접적인 단서를 활용하여 affordance 영역에 대하여 학습하는 방식으로, 확장성은 개선이 되었으나 공간적인 정밀도는 낮은 경향이 있습니다. open-vocaburary 방식은 대규모의 사전학습 모델을 이용하여 의미론적 정보를 기반으로 일반화가 가능하지만, 기능적 범주를 혼동하는 경우가 많습니다. 따라서, 여전히 affordance의 근본적 능력을 갖춘 모델은 부족한 상태이며, 이를 해결하기 위해 다양한 시각적 지식을 내포한 VFMs를 활용한 연구들이 등장하였습니다. 저자들은 VFMs의 어떤 능력이 affordance 이해를 가능하게 하며, 그 능력은 VFM에서 어떻게 드러나는지에 대하여 알아보고자 하였습니다.
저자들은 affordance의 핵심 원리를 물체 자체의 속성이라기보다, agent와 환경 사이의 상호작용 가능성으로 보았습니다. 따라서 affordance 이해는 다음 두 가지 상호보완적 능력을 요구한다고 정리하였습니다. (1) 상호작용이 가능하도록 하는 물체 부위와 공간적 정보를 인식하는 geometric perception과 (2) agent가 그런 구조와 어떻게 상호작용 하는지를 모델링하는 interaction perception 능력입니다. 예를 들어 의자는 좌판과 등받이가 몸을 지지하는 구조를 제공하기 때문에 sitting이나 leaning이 가능하며, 동시에 팔걸이나 다리와 같은 다른 부위는 손으로 잡거나 들어 올리는 상호작용을 가능하게 합니다. 이러한 예시는 affordance가 물체 자체의 속성이라기보다, 물체의 기하 구조와 agent의 행동 능력이 결합될 때 나타나는 관계가 임을 보여줍니다. 나아가 저자들은 이러한 이중 관점을 통해, VFMs 내부에서 affordance 관련 핵심 능력이 어떤 형태로 표현되고 드러나는지를 체계적으로 조사하기 위한 원리적 프레임워크를 제시합니다.
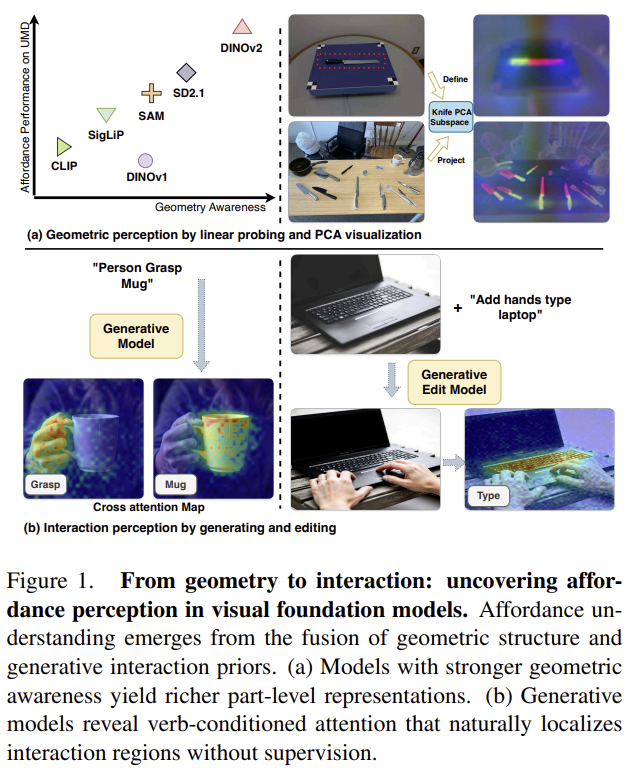
저자들은 affordance 이해를 geometry 와 interaction 두 가지로 보고, 이 능력들이 VFM 내부에서 어떻게 나타나는지 분석하였습니다. 그 결과 기하학적 이해 능력이 좋을수록 affordance 분할 성능이 높아지며, 깊이/표면법선과 같은 3D 단서가 추가되면 이러한 경향이 더 강화됨을 확인하였습니다.(Figure 1-(a) 참고) 또한, 상호작용의 사전지식을 내재한 모델은 weakly-supervised 방식과 유사한 성능을 보였으며, 상호작용 또한 중요한 역할을 함을 확인하였습니다. 추가로, 저자들은 이러한 관찰을 기반으로 VFMs에서 이러한 능력이 어떻게 표현되는 지 검토하였습니다. 그 결과, 기하학적으로 affordance 분할 성능이 좋을수록 시각 특징을 part-level로 구분하는 경향이 있으며, 동시에 생성 모델은 verb-conditioned attention을 통해 행동과 물체 영역을 연결하고, 이러한 상호작용 지식을 공간적으로 명시적으로 추출할 수 있음을 확인하였습니다. 마지막으로 두 단서를 training-free로 단순히 융합하여 zero-shot affordance estimation에서 경쟁력 있는 성능을 보이며, 상호보완적인 두 능력들이 VFM 안에 조합 가능한 요소로 존재함을 주장합니다.
해당 논문의 contribution을 정리하면,
- visual affordance를 기하학적 지각과 상호작용 지각의 두 축으로 분해하는 2차원 프레임워크를 제안하여 학습 방식에 덜 의존적인 통합 분석 제공
- 다양한 VFMs를 대상으로 affordance 능력을 처음으로 체계적으로 조사하여, geometric 인지가 prat-level의 분리를 가능하게 하고, 생성 모델이 verb-conditioned spatial interaction 사전지식을 내포한다는 것을 보임
- 최초로 생성 모델의 내부 cross-attention을 affordance 추정을 위한 training-free spatial priors로 활용하려는 시도
- 두 단서를 학습 과정 없이 단순히 융합하여 조합이 가능함을 입증하고, zero-shot 성능이 weakly-supervised 방법과 경쟁 가능함을 보임
Visual Affordance Investigation
해당 파트에서 저자들은 기존 VFM의 geometric 인식과 interaction 인식 능력이 affordance 이해에 어떻게 연관되며, 표현되는 지 분석합니다.
Geometry
먼저, 저자들은 기하학적 표현이 affordance 학습의 기반을 구성한다는 것을 확인합니다. geometric 인식과 affordance 분할 성능 사이의 정량적 연결고리를 확인하고, 주요 모델 내부 representation을 살펴보며 서로 다른 VFM계열이 기하 정보를 어떻게 인코딩하는 지 비교하고, part-level의 정보가 행동을 위해 강력한 특징임을 보입니다.
[Observation 1.1] Affordance Correlates with Geometric Representation
기하학적 표현이 affordance 이해의 기반이 된다는 것을 정량적으로 검증하기 위해, backbone을 고정한 뒤 linear head만을 학습하는 controlled linear probing 프레임워크를 채택하여 평가를 수행합니다. 평가 데이터는 7가지 affordance 카테고리와 11,800개의 training 이미지, 14,020개의 test 이미지로 구성된 UMD 데이터를 이용하며, affordance map 예측에 대하여 mIoU로 평가를 수행합니다. 또한, 명시적인 3D 정보가 어떤 영향을 주는 지 평가하기 위해 Metric3Dv2에서 추정된 depth와 surface-normal을 각 visual feature map에 추가하여 평가를 수행하였습니다.
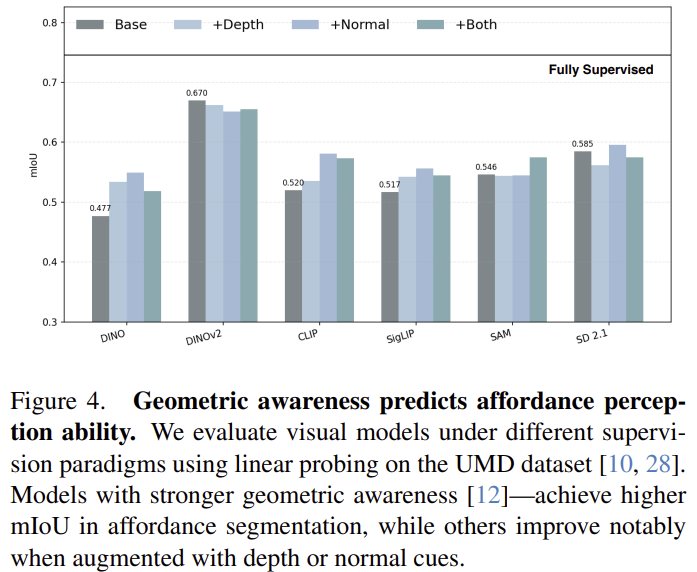
위의 figure 1에서 확인할 수 있듯, 기하학적 이해 능력이 좋을수록, affordance에 대한 인식 능력이 좋아진다는 것을 대략적으로 확인할 수 있으며, figure 4는 기본 모델에 대해 Metric3Dv2로 추정한 기하학적 정보를 추가한 실험 결과들을 함께 나타낸 것 입니다. 이를 통해 semantic한 표현을 주로 내포하는 CLIP과 SigLIP에서는 기하학적 정보가 추가되면 성능이 base보다 좋아지는 것을 확인할 수 있는 반면, DINOv2는 기하학정보가 추가되었을 때 성능 저하가 이루어지는 경향이 보였습니다. 이에 대해 저자들은 사전학습 자체가 이미 강력한 기하학적 사전지식을 내포하고있을 경우 성능 저하가 이루어진 것이라 보았으며, 이러한 실험 결과들을 기반으로 기하학적 표현이 affordance 추론의 기반이 된다고 보았으며, 서로 다른 VFM들이 내부적으로 기하학 정보를 어떻게 인코딩하고있는지에 대한 분석이 필요하다고 주장합니다.
[Observation 1.2] Distinct Geometric Representations Across Model Families
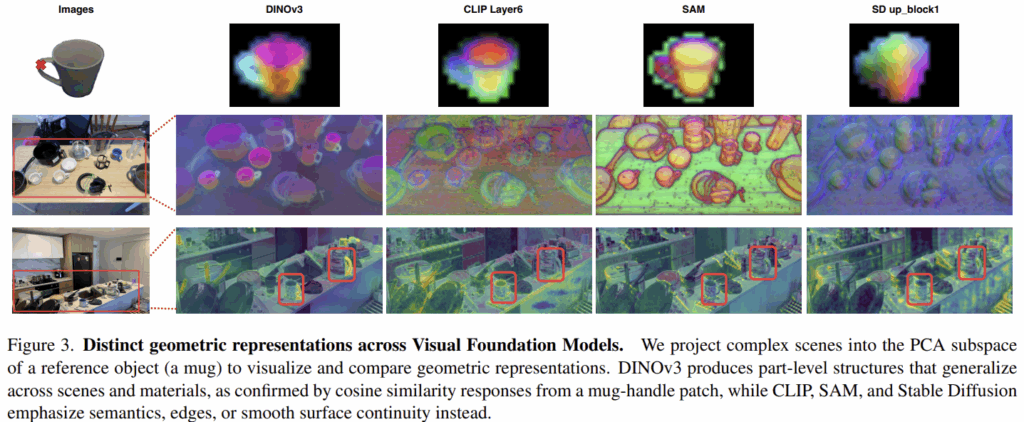
다음으로 저자들은 기하학적 정보가 다양한 VFM 내에서 어떻게 인코딩 되는 지 정성적으로 분석합니다. 위의 Figure 3은 이에 대한 예시로, DINO 계열은 장면을 의미론적으로 유의미한 part 수준으로 구조를 구분하며, 손잡이나 테두리 같은 기능적 구성 요소가 명확하게 구분됩니다. CLIP은 중간 수준의 기하학적 정보가 더 깊은 레이어로 갈 수록 붕괴되는 경향을 보였다고 하며(그림으로 확인하기는 어려워보입니다), SAM은 객체의 경계가 구분되며, Stable Diffusion은 물체의 특정 영역이 구분된다기보다는 물체를 전반적으로 연속적인 표면처럼 표현하는 경향을 보였습니다. 이러한 feature representation에 대한 분석을 통해, 저자들은 Affordance에 part가 중요한 역할을 한다고 하는 기존 논의들이, 실제로 part에 대한 구분력을 보이는 DINO 계열이 좋은 성능을 보였다는 관찰과 일치한다고 주장하였습니다. (그런데 굉장히 의문이 드는건.. 앞의 figure 1과 4의 실험에는 DINOv2를 이용하였는데, 여기부터는 왜 DINOv3로 바뀌었는 지 의문입니다. 따로 언급한 내용도 없어서 제대로 된 분석이라 할 수 있는 지 의문이 들고, 리뷰어에게 지적을 받을만은 부분인 것 같습니다.)
[Observation 1.3] Part Decomposition and Semantic Assimilation in DINO
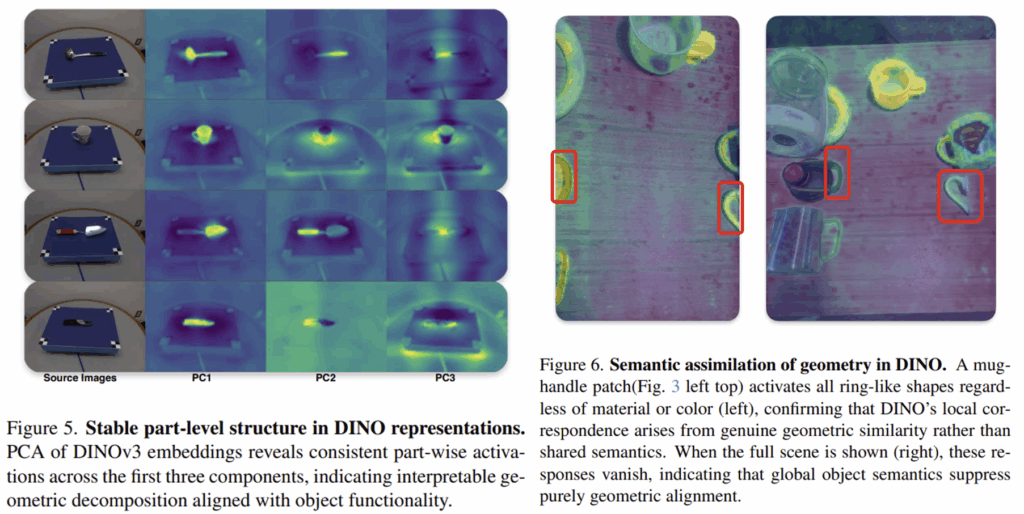
추가로 저자들은 DINO에 대하여 분석합니다. Figure 5는 UMD 물체 영상에 대한 중간 representation에 PCA를 적용한 결과로, 주요 구성 요소가 일관되게 유의미한 부분(손잡이나 날, 그립)에 나타나는 것을 확인할 수 있습니다. 그러나 DINO에서 이러한 부분이 기하학적 이해 보다는 의미론적 이해에서 비롯될 수 있다는 주장[1]도 존재하며, 저자들은 이를 확인하기 위한 추가 실험을 진행합니다.
동일한 객체의 feature를 추출하고, 두 패치 사이의 cosine similarity를 계산하였습니다. 하나는 최소한의 맥락정보를 제공하고 다른 하나는 완전한 맥락 정보를 제공한 것으로(figure 6의 왼쪽은 손잡이의 최소한의 정보만을 제공하고 오른쪽은 전체 맥락 정보를 제공), 이 두 쌍은 동일한 기하학적 구조에 대하여 의미론적 맥락이 어떤 영향을 주는지를 보이기 위한 것 입니다. 실험 결과, 단순히 손잡이의 고리 부분만 보이는 영상에서 DINO는 기하학적 정보로, 재질이나 색상에 무관하게 모든 고리 구조가 강하게 활성화되었습니다. 그러나, 완전한 맥락 정보가 제공되는 경우 이러한 경향이 약화되었으며, 이러한 실험을 통해 최종적으로 DINO의 표현이 기하학적 정보와 의미론적 정보의 결합이라고 결론을 내립니다. 또한, Part 수준에서 더 확실하게 형태 중심적인 기하학적 지식을 추출하기 위해 저자들은 이후의 융합 파이프라인에는 PCA를 적용한 결과를 이용하였다고합니다.
**[1] El Banani, Mohamed, et al. “Probing the 3d awareness of visual foundation models.” CVPR 2024.
Interaction
다음으로 interaction은 agent가 객체의 부분이 어떻게 작용하는지를 이해해야하며, 저자들은 Vision Foundation 모델들이 동사(verb)에 대한 이해를 평가하고, 생성 모델이 상호작용에 대한 사전 지식을 인코딩해야한다는 것을 발견하였다고 합니다.
[Observation 2.1] Emergent interaction cues from genertive VFMs
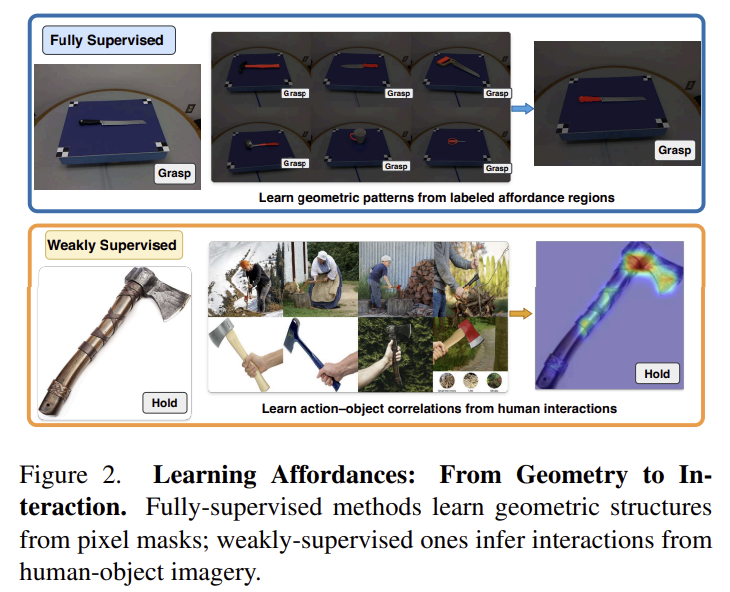
weakly-supervised 방식은 사람이 물체를 이용하는 영상을 관찰하여 행동과 객체 사이에 대한 대응 관계를 학습시키는 것으로, 명시적인 기하학 정보보다는 verb와 맥락에 대한 정보를 통해 물체의 행동이 이루어지는 영역을 추론합니다. 이로부터 저자들은 “만약 이러한 사전지식이 관찰로부터 학습이 된다면, 상호작용을 합성하는 능력이 있는 생성 모델이 이미 상호작용에 대한 단서를 학습했을 수 있지 않을까?” 라는 의문을 제기합니다. 따라서, 저자들은 diffusion 모델을 비교하였으며, Flux.1-dev 모델이 가장 일관된 verb-scene alignment를 보인다는 것을 확인하였다고 합니다. (아래의 Observation 2.2의 Figure 9에 해당하는 것으로 보입니다.)
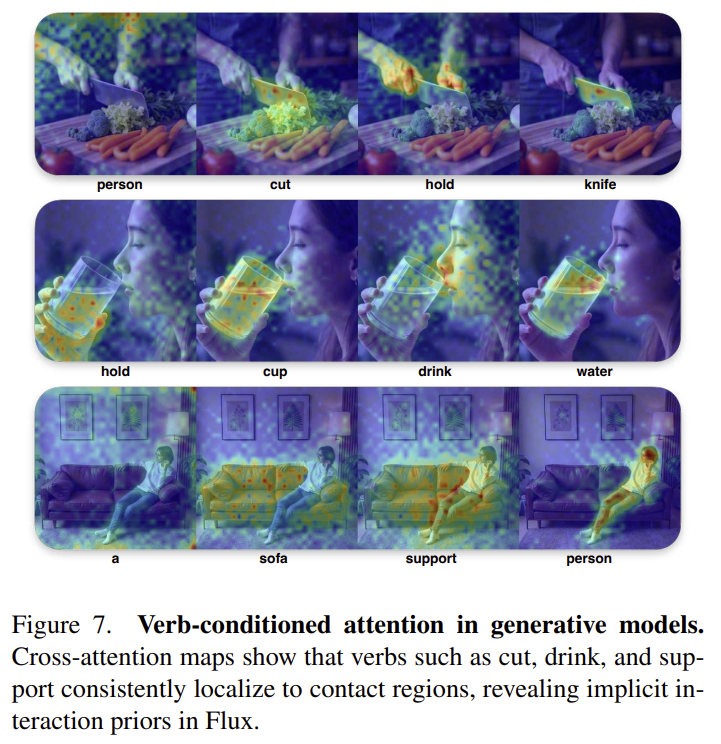
저자들은 FluX를 이용하여 text-image에 대한 cross-attention을 평가하였으며, 위의 figure 7은 이에 대한 시각화 결과입니다. hold,use,support와 같은 동사는 사람이 객체와 접촉하는 영역에 일관적으로 활성화가 되어있는 반면, person, sofa와 같은 객체 토큰에 대해서는 대응되는 객체에 집중하고있는 것을 알 수 있습니다. 이러한 관찰을 기반으로 저자들은 생성 모델이 동사에 대한 사전 지식이 인코딩 되어있으며, 동사를 조건으로 주어 생성되는 정보 뿐만 아니라 어디에 생성이 될지도 제어할 수 있다고 보았습니다.
[Observation 2.2] From attention to interaction understanding
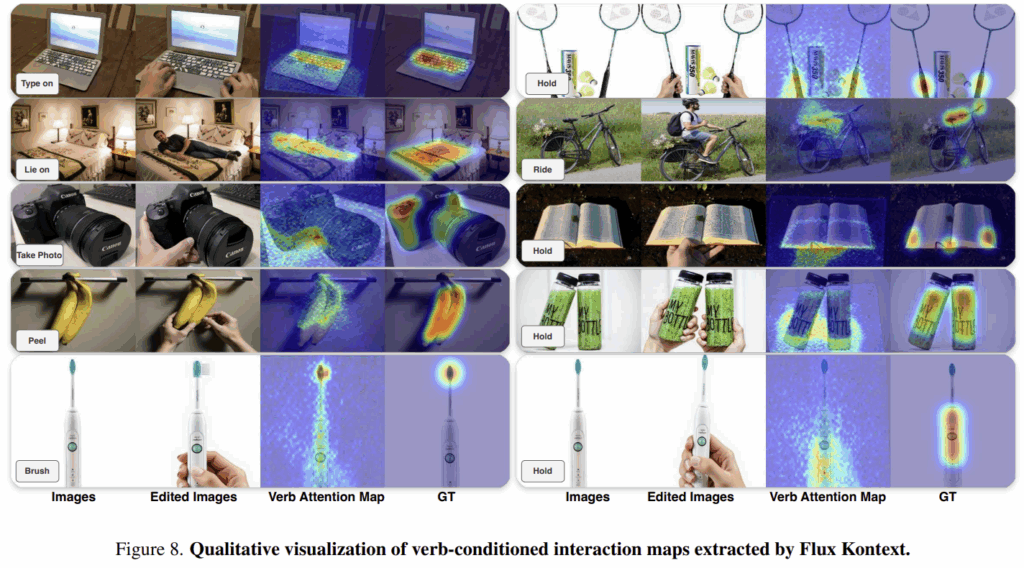
위의 Figure 8은 생성 모델이 본질적으로 상호작용에 대한 사전 지식을 인코딩한다는 것을 보이기 위한 것으로, Flux 기반의 생성 모델인 Flux Kontext를 이용하여 생성 과정에 동사를 조건으로 활용하는 이미지 편집 프레임워크를 설계하였다고 합니다. 각 상호작용은 agent와 객체, 동사 3가지로 표현되며, 템플릿으로 되어있는 프롬프트를 기반으로 특정 상호작용 장면을 생성하는 과정에 여러 layer의 verb-token에 대한 cross-attention을 분석합니다. 그 결과, 공간적 분포를 드러낼 수 있다는 것을 확인하였다고 합니다.

다른 모델들에서 동사와 객체 관계가 어떻게 인코딩 되는 지 확인하기 위해 저자들은 대표적인 Vision-Language프레임워크들인 Grounding DINO와 MaskCLIP, EVF-SAM을 비교하였습니다. EVF-SAM은 part-level의 분할이 가능하지만 동사가 주어질 경우 정확한 영역을 찾지 못하는 반면, Grounding DINO와 MaskCLIP은 global한 의미 정보를 잘 추론하지만 part-level로 분할하는데는 어려움이 있다는 것을 확인할 수 있습니다. Flux Kontext는 동사와 행동에 대하여 보다 일관성 있는 결과를 보인다는 것을 확인하였으며, 저자들은 이러한 실험을 통해 해당 모델에 집중하였다고 합니다.

앞서 Figure 8 시각화 결과를 통해 Flux Kontext에서 추출된 동사에 대한 attention map이 물리적으로 그럴듯한 접촉 영역에 활성화 되는 것을 확인하였으나, 위의 Figure 10과 같이 실패하는 케이스도 존재합니다.
Geometry-Interaction Integrated Affordance Estimation
저자들은 앞선 분석을 기반으로 training-free 방식의 프레임워크를 제안합니다. geometric 정보와 interaction 정보를 융합하는 방식으로, 저자들은 이 두가지 정보가 affordance에서 근본적 정보라면 이 두가지를 명시적으로 결합하는 방식으로 추가 학습 없이 affordance 추론이 가능할 것이라고 보았습니다.
Fusion Procedure
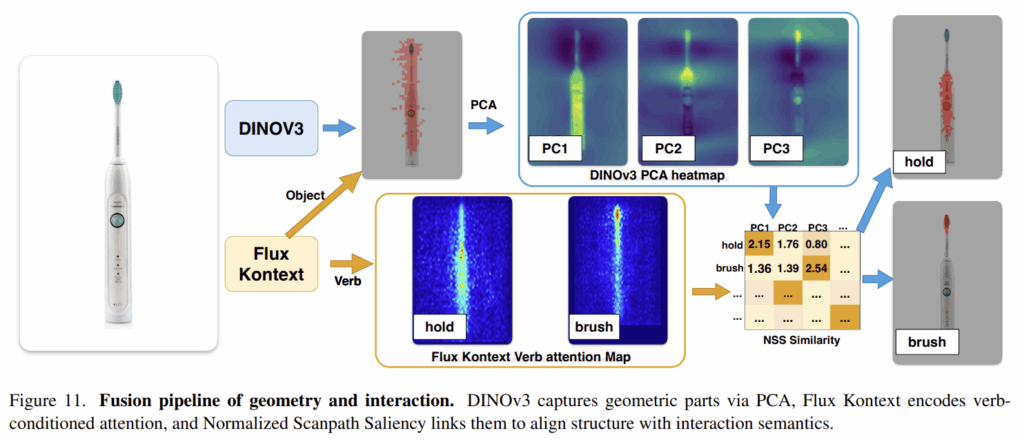
앞서 분석들을 기반으로 저자들은 DINOv3와 Flux Kontext를 채택하였습니다. DINOv3는 dense한 기하학적 정보를 제공하고, Flux Kontext는 상호작용에 대한 단서(verb와 객체)를 인코딩하는 attention map을 제공합니다. 객체에 대한 attention map을 기반으로 DINOv3의 관심 영역을 crop하며, 관심 영역의 feature에 PCA를 적용하여 part-level의 기하학적 bases로 분할합니다. 동시에 행동이 이루어지는 영역을 나타내는 verb에 대한 attention map과 앞의 기하학적 bases 사이의 NSS(Normalized Scanpath Saliency)를 계산한 뒤, 가장 잘 정렬된 base를 선택하여 다시 verb에 대한 attention과 융합하여 동사별 affordance mask를 생성합니다.
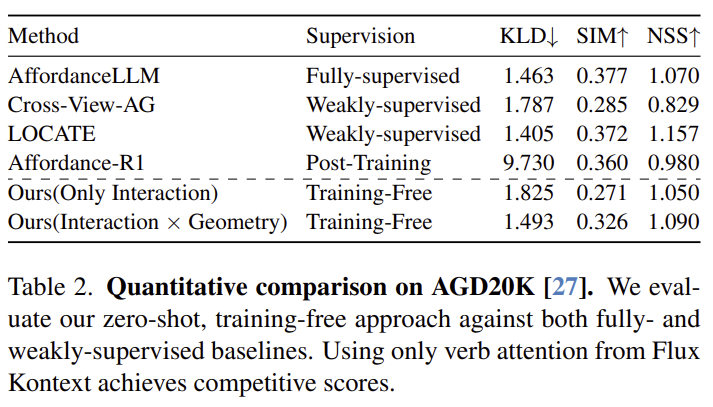
저자들은 AGD20K에 대하여 평가를 수행하였으며, Table 2의 Only Interaction과 Interaction ⨉ Geometry에 대한 결과를 통해, 두 정보를 함께 활용하였을 때 성능이 개선되는 것을 확인할 수 있습니다. 조금더 구체적으로, KLD 값이 줄어든 것은 기하학적 단서를 통해 불가능한 영역을 억제함으로 써 더 뚜렷한 영역을 예측할 수 있었다고 분석하였으며, SIM과 NSS가 동시에 개선된 것을 통해 예측 결과가 정답 분포를 더 잘 포괄하면서도 행동의 특정 영역이 두드러지도록 예측이 되었다고 분석하였습니다.

UMD 데이터 셋의 경우 heatmap 형태가 아니 mask만을 제공하므로, 기하학적 일관성에 대하여 정성적으로만 확인하였다고 합니다. 위의 Figure 12를 통해 예측 결과가 특정한 영역에 잘 나타난다는 것을 보였습니다.
리뷰 잘 읽었습니다. 궁금한 점 몇 가지를 댓글로 남겨두겠습니다.
1. Figure 1과 4에서는 DINOv2, 뒤에서는 DINOv3를 쓰는 것 같은데, 왜 바뀐 건지 궁금하네요. 리뷰에 적어주신 것처럼 모델이 바뀌면 “기하학적 표현이 part-level로 분해된다”는 주장도 영향을 받을 수 있을 것 같다 생각이 들어서요.
2. 그리고 DINOv2에서 depth/normal을 추가하면 성능이 오히려 떨어졌다는 것 같은데, 이게 ‘이미 지오메트리를 알고 있어서 중복’인지, 아니면 ‘외부 지오메트리 추정 노이즈가 들어가서’인지 뭐 이런 저자의 분석이 있나요?
리뷰 읽어주셔서 감사합니다.
1. 우선 저도 Observation 1.2부터 DINOV2에서 V3로 변경되어있고, 그 이유에 대한 설명은 작성이 되어있지 않아서 의문입니다. 아무래도 리뷰어에게 지적을 받을 포인트인 것 같습니다.(혹은 .. 앞의 실험들에 DINOv3를 추가하지않을까요??) 또한, Figure5와 6도 DINOv3에 대한 representation을 PCA 적용하여 나타낸 결과인데, 어느정도 part-level로 표현이 가능해보입니다.
2. 저자들은 DINO모델 자체에서 내부적으로 이해하는 기하학적 정보와 추가해준 기하학적 정보가 서로 충돌한다고 보았습니다. 즉, 외부 geometry 추정의 노이즈는 고려하고 있지 않고, 이미 알고있는 지오메트리와의 충돌 때문이라고 보고있습니다.
안녕하세요 승현님 리뷰 감사합니다.
DINO가 pretraining 하면서 part-level geometry는 잘 학습했고, 여기에 verb에 해당하는 signal을 정렬시키는 방식으로 이해했습니다. 다만 A4-agent와 같은 large model의 reasoning과 planning 능력을 활용하는 접근과 비교했을 때 성능이 괜찮을까..? 하는 생각이 들기도 했습니다.
Q1. 승현님이 목표하시는 실제 로봇 조작과 연결하는 부분에 있어서 geometry 와 interaction 을 정렬하는 방식이 agent 기반 방식에서 어떤 한계들이나 이점이 있을지 의견이 궁금합니다.
Q2. 좀 다른 질문이지만 AGD20K와 같은 affordance 쪽에 시뮬레이터라도 실제 로봇 액션과 연결되는 벤치마크가 있을까요?
리뷰 읽어주셔서 감사합니다.
1. 해당 논문을 통해 저자들은 affordance에 대한 기반 능력이 geometry를 이해하고 interaction을 이해해야한다는 것을 보였습니다. 두가지 정보만으로 충분하다고는 이야기하기 어렵지만, 두 정보를 사용하는 게 도움이 된다는 점을 입증하고, training-free 방식으로 접근 가능함을 보였다는 게 포인트인 것 같습니다. 저에게는 저 두가지 정보들을 고려하도록 알고리즘을 설계해야한다는 근거?로 사용 가능하지 않을까요?
2. 3D에 대한 Affordance 연구는 존재하지만, Affordance에 대한 일반적으로 사용되는 시뮬레이터는 따로 없고, affordance를 기반으로 인지한 뒤, 실제 시뮬레이션에서 로봇 작업을 수행하는 연구들은 존재합니다. 그러나 정해진 벤치마크는 아닙니다.