안녕하세요 오늘은 WorldVLA에 대해서 설명드리도록 하겠습니다. 최근 들어서 계속 VLA 관련 논문들을 읽고 있는데 세계에 대한 일반화? 능력에 대한 부분이 상당히 필요한 것 같다고 느꼈습니다. 그런 의미에서 행동과 이미지 이해 및 생성을 통합하는 월드 모델인 World VLA에 대해서 설명을 드리고자 합니다. 그러면 いきますよ~

- Conference: arXiv 2025
- Authors: Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, Hao Chen
- Affiliation: DAMO Academy, Alibaba Group; Hupan Lab; Zhejiang University
- Title: WorldVLA: Towards Autoregressive Action World Model
1. Introduction
VLA 모델의 개발은 로보틱스 행동 모델 연구에서 중요한 부분으로 발전해왔습니다. 단순히 Vision에만 의존하는 것이 아니라 언어의 문맥적 의미를 이해할 수 있도록 대규모 사전 훈련된 Multimodal Large Language Models (MLLMs)에 행동을 추가하였기 때문에 강력한 인식 및 의사 결정 능력을 제공해서 VLA 모델이 광범위한 로보틱스 작업에서 향상된 일반화 성능을 보이도록 해줍니다.
그럼에도 불구하고 이러한 모델들을 행동을 단순히 출력으로만 취급하여 행동에 대한 포괄적인 이해가 부족하다는 한계가 야기되고 있습니다.
이와 대조적으로 World Model은 현재 관측 및 행동을 기반으로 미래 시각 상태를 예측하는 능력을 보여주는 능력을 가지고 있지만 직접적인 행동 계획을 출력할 수는 없습니다.
결과적으로 이를 해결하기 위해서 통합된 행동 및 이미지 이해와 생성을 위한 자기회귀적 행동 세계 모델인 WorldVLA를 소개한다고 합니다. WorldVLA는 이미지 텍스트 행동을 인코딩하기 위해 세 개의 별도 tokenizer를 사용하고 서로 다른 modality의 토큰들은 동일한 어휘를 공유하도록 설정되어 modality 간의 이해와 생성이 단일 LLM 아키텍처 내에 통합될 수 있었다고 합니다. 또한 World model의 구성요소는 입력 행동을 기반으로 시각적 표현을 생성하기 때문에 환경에 대한 근본적인 물리역학을 포착하는 기능을 내재하고 있습니다. 이러한 행동 해석과 환경에 대한 물리 학습으로 인해서 행동 모델이 효과적인 의사 결정을 가능하도록 하고, WorldVLA에 내장된 행동 모델은 시각 데이터의 이해를 정제해서 world model이 수행하는 이미지 생성의 정확도를 향상시킨다고 합니다. 뭔가 움직임에 대한 시각 데이터의 상대적인 변화에 대해서도 학습을 할 수 있다고 주장하는 것 같습니다.
action chunking과 병렬 디코딩(parallel decoding)은 액션 모델의 성능에 상당한 영향을 미친다고 입증되었습니다만, 저자는 여러 액션을 순차적으로 생성하는 것이 자기회구 모델에서 성능 저하를 초래한다, 즉 오차가 누적?되어 chunking이 하나를 잘못 생성하면 나머지도 잘못될 수도 있다는 것입니다. 이러한 이유는 사전 훈련된 multimodal 언어 모델이 주로 액션보다는 이미지와 텍스트에 노출되었기 때문에 제한된 액션 일반화 능력을 가지게 된다고 말하고 있습니다. 이를 해결하기 위해서 저자는 현재 액션을 생성하는 동안 이전 액션을 선택적으로 마스킹하는 action attention masking 전략을 제안한다고 합니다.
LIBERO 벤치마크에서 WorldVLA가 동일한 backbone을 가진 액션 모델보다 4% 더 높은 grasping 성공률을 보이고, 일반적인 World Model과 비교하였을 때 비디오 생성 능력이 더 우수하여 LIBERO 벤치마크에서 Fréchet Video Distance (FVD)를 10% 더 감소시킨다고 합니다. 또한 액션 청크 생성의 맥락에서 어텐션 마스킹 전략은 그래스핑에서 4%에서 23%까지 성공률을 향상시킵니다.
핵심을 정리하자면 아래와 같습니다
- 액션과 이미지의 이해 및 생성을 통합하는 자기회귀 액션 월드 모델인 WorldVLA를 제안함
- 자기회귀 모델에서 액션 청크 생성 작업을 위해 action attention masking 전략을 도입에 액션 오류 축적 문제를 해결함
- 독립적인 action과 world model보다 우수하다는 것을 보여주며 상호 작용을 통한 성능 향상을 강조
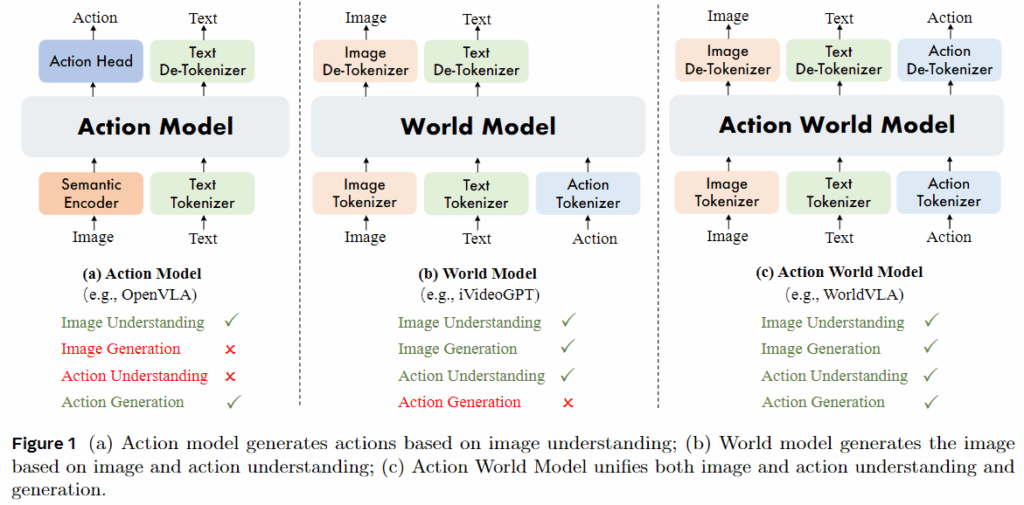
3. Methods
3.1 Problem Formulation
통합 모델 학습이라는 과제를 다루는 만큼, 행동 모델 \pi_{\theta}와 세계 모델 f_{\phi} 두 가지 주요 구성 요소를 정의한다고 합니다.
행동 모델 \pi_{\theta}는 이미지 관측 기록과 언어 지침에 조건화되어 행동을 생성하는 역할을 하여 아래 식과 같이 구성됩니다.
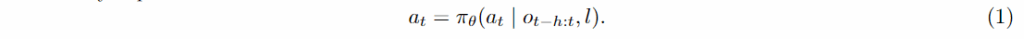
World Model f_{\phi}는 관측 기록과 해당 행동 기록을 기반으로 다음 프레임을 예측하는 식으로 구성됩니다.
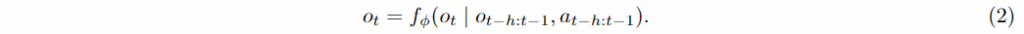
결과적으로 해당 논문에서 나온 방법론은 이 두가지 모델을 잘 통합하는 통합 행동 World Model을 개발하는 것입니다.
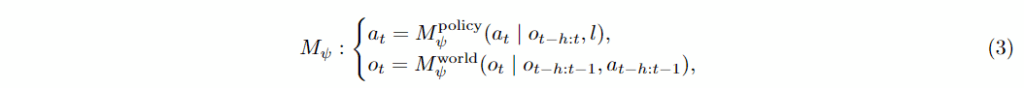
이러한 통합 모델은 행동 생성 구성 요소 M^{\text{policy}}_{\psi}와 M^{\text{world}}_{\psi}를 예측하도록 학습됩니다. 이를 학습함으로써 의사 결정과 환경 모델링 모두에 공유된 표현을 활용하는 간결하고 효율적인 프레임워크를 달성하는 것이 목표라고 밝히고 있습니다.
3.2 Architecture
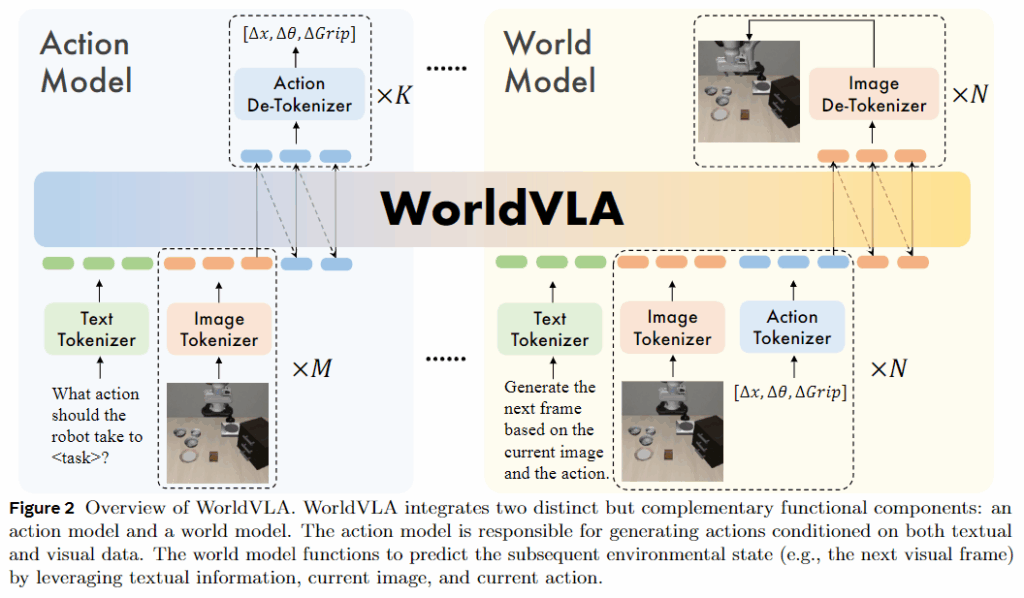
모델에서는 이미지 토크나이저, 텍스트 토크나이저, 행동 토크나이저를 포함한 3가지 토크나이저가 있습니다.
이미지 토크나이저는 특정 이미지 영역에 대한 추가적인 perceptual losses를 갖춘 VQ-GAN 모델입니다. 압축률은 16이고, codebook의 크기는 8192입니다. 이미지 사이즈 256 × 256 이미지에 대해 256개의 토큰을, 512 × 512 이미지에 대해 1024개의 토큰을 생성합니다. SmolVLM 같은 경우에는 이미지를 텍스트라는 식으로 변환하여 사용하는 느낌에 가까웠다면 여기는 독립적인 토크나이저를 통해 이미지를 처리하는 것을 확인할 수 있습니다.
액션 토크나이저는 연속적인 로봇 액션의 각 차원을 256개의 bin 중 하나로 이산화하며 bin의 너비는 훈련 데이터의 범위에 의해 결정됩니다. 액션은 3개의 상대 위치, 3개의 상대 각도, 1개의 절대 그리퍼 상태를 포함하여 7개의 토큰으로 표현됩니다. 즉 EE의 6D pose 정보와 그리퍼의 상태가 토크나이저에 들어간다고 볼 수 있습니다.
텍스트 토크나이저는 65536개의 어휘 크기를 가진 BPE 토크나이저로, 여기에는 8192개의 이미지 토큰과 256개의 액션 토큰이 포함됩니다.
3.3 Training Strategy
action model 데이터와 world model 데이터를 혼합하여 WorldVLA를 훈련한다고 합니다.
월드 모델 데이터를 통합하여 액션 생성을 향상시키는 이유로는 (i) World model은 현재 상태와 적용된 액션을 기반으로 미래 관측치를 예측하도록 학습함으로써 환경 물리학에 대한 이해를 습득해 조작 작업에 유용하고, (ii) World model은 시스템이 후보 액션의 잠재적 결과를 시뮬레이션하고 평가할 수 있게 하여 불리한 상태로 이어질 수 있는 액션을 회피하는데 도움을 주고, (iii) World model은 액션 입력에 대한 정확한 해석을 필요로 하며 액션 모델이 더 효과적이고 맥락에 적합한 액션을 생성하도록 지원합니다. 반면, 액션 모델은 시각적 이해를 향상시키고 다시 월드 모델의 시각 생성 능력을 지원합니다.
Action Model Data
텍스트 지침과 이미지 관측을 주어주면 액션을 생성하는 역할을 가지고 있으며, 텍스트 입력은 “What action should the robot take to + task instruction + ?”의 형태를 가지고 있습니다.
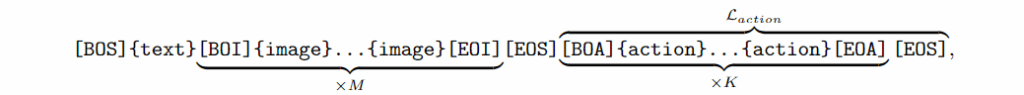
여기서 {text}, {image}, {action}은 이산화된 텍스트, 이미지, 액션 토큰을 나타내고, [BOS], [EOS], [BOI], [EOI], [BOA], [EOA]는 각각 문장의 시작, 문장의 끝, 이미지의 시작, 이미지의 끝, 액션의 시작, 액션의 끝 토큰을 나타냅니다. 입력은 M개의 이미지를 포함하고 출력은 K개의 액션을 포함합니다. 계산은 Action 토큰에 대한 L_{\text{action}}만을 계산합니다.
World Model Data
월드 모델은 현재 이미지 관측치와 액션을 주어진 상태에서 다음 이미지 프레임을 생성하는 역할을 합니다. 액션 자체가 다음 상태를 완전히 결정할 수 있기 때문에 작업에 대한 지침은 첨부하지 않고, 대신에 “Generate the next frame based on the current image and the action.”라는 텍스트를 넣어줍니다. 그래서 전체적인 토큰 sequence는 아래와 같습니다.
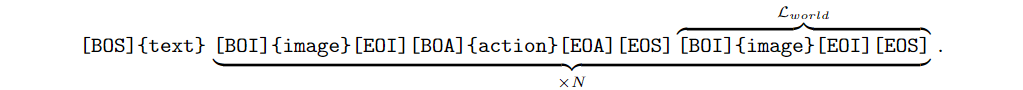
다음 프레임 예측은 액션에 조건화되어서 N번 반복되고 생성된 이미지 토큰의 Loss인 L_{\text{world}}만 계산합니다.
Attention Mask

일반적인 자기회귀(Autoregressive) 액션 월드 모델은 이전에 생성한 토큰을 참조하여 다음 토큰을 만들지만, 해당 논문의 방버론에서는 attention mask를 도입합니다. 이로 인해서 text및 시각적 입력에만 의존하도록 보장하며 이전 액션에 대한 접근을 금지합니다. 사진을 보시면 액션끼리의 attention을 마스킹하는 것을 확인할 수 있습니다. World model은 conventional causal attention mask를 따른다고 합니다.
Training Objective
이제 위에서 만들어놓은 Action model과 World model을 혼합해서 잘 활용할 수 있도록 해줍니다. 이를 위해서 아래와 같이 Loss 함수를 구성하였다고 합니다.
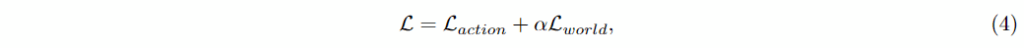
여기서 L_{\text{action}}과 L_{\text{world}}는 교차 엔트로피 손실을 나타냅니다. 이미지 토큰과 액션 토큰의 비중이 다른 것을 고려하여 alpha를 붙여서 손실 기여도를 조정해준다고 합니다.
4. Experiments
4.1 Evaluation Benchmark
실험에서는 LIBERO-Spatial(공간 관계에 초첨을 맞춤), LIBERO-Object(객체 인식에 초점), LIBERO-Goal(작업 목표에 초점), LIBERO-Long(장기 과제에 초점) 및 LIBERO-90(사전 학습을 위한 단기 과제 수행에 초점)을 포함하는 LIBERO benchmark를 사용합니다.
데이터셋은 OpenVLA와 같이 실패한 궤적과 무동작에 대한 행동을 먼저 필터링 합니다. 월드 모델 평가에는 정답 쌍으로 된 비디오 및 행동 데이터가 필요하기 때문에 궤적의 90%를 훈련에 나머지 10%를 검증 세트에 사용합니다.
베이스 라인은 Diffusion Policy, Octo, DiT Policy, UVA와 같은 확산 기반 행동 모델, Seer와 OpenVLA-OFT, OpenVLA와 같은 이산 행동 모델을 사용합니다.
훈련에서 우선 기본 입력 이미지 수는 2개, 행동 청크 크기는 LIBERO long의 행동 청크 크기는 10, 나머지는 5로 설정됩니다. 실험 설정에서 alpha는 0.04로 고정됩니다.
평가 지표는 50번의 Rollout으로 성공률 SR을 기록합니다. 월드 모델 평가를 위해선느 검증 세트를 사용하고, FVD, PSNR, SSIM, LPIPS 값을 기록합니다.
4.2 Evaluation Results and Discussion
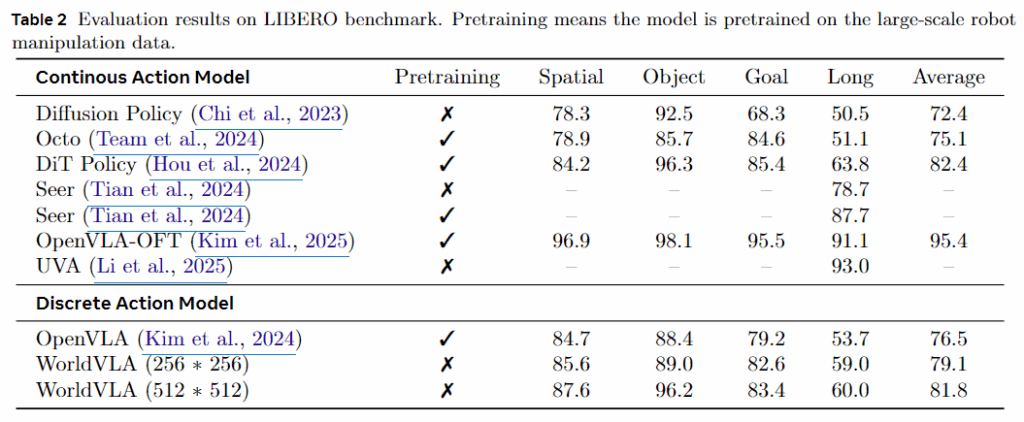
사전 학습이 없는 WorldVLA는 OpenVLA에 비해서 우수한 성능을 보이고 있다고 설명하고 있고, 이 결과는 WorldVLA 설계가 효과적임을 증명합니다.
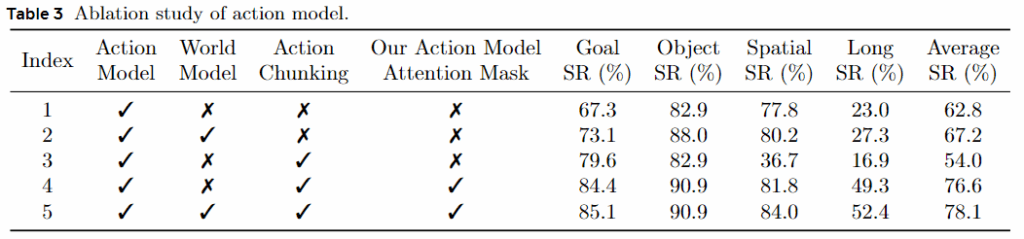
해당 표를 통해서는 월드 모델의 통합이 성능을 크게 향상시킴을 확인할 수 있습니다. 논문에서는 월드 모델의 근본적인 기능인 주어진 행동과 현재 상태에 조건화하여 환경의 후속 상태를 예측하기 때문에 이런 점에서 본질적으로 시스템의 근본적인 물리적 역학에 대한 이해를 습득할 수 있도록 해서 그리핑과 같은 숙련된 조작 작업에서 성공적인 실행을 위한 중요한 조건이 될 수 있다고 합니다. 또한 미래를 예측할 수 있는 능력까지 가지고 있기 때문에 잠재적 행동의 결과를 예측할 수 있도록 한다고 합니다.

또한 액션 world model이 단순한 World model보다 더 긴 비디오 시퀀스를 생성할 때 우수하다고 합니다. 행동이 내재되었을 때 월드 모델의 전반적인 성능을 향상한다고 하고 사진을 본다면 단순히 그냥 월드 모델은 실패하는 경우가 많이 등장하지만, action world model은 성공률이 높다고 합니다. 뭔가 잘 안보이실 수도 있지만 그릇과 같은 게 사라지는 모습 등을 확인하실 수 있습니다. 이를 통해서 월드 모델이 단순히 이미지에 종속되기보다는 행동과 연관하여서 종속되는 것이 더 좋다는 것을 설명할 수 있습니다.
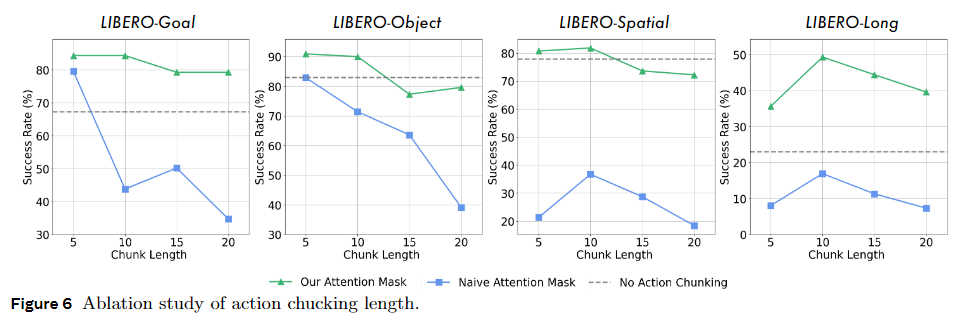
다음으로는 attention mask에 대한 실험입니다. 해당 지표를 통해 masking의 성능이 있음을 확연하게 보여주고, 청크의 길이가 길어질 수록 오류가 누적되기 때문에 이에 비해서 naive attention mask보다 높은 성능을 보여줍니다.

마지막으로 월드 모델에 대한 사전 학습을 진행했을 때에 대한 성능 비교를 진행했을 때의 결과를 보여주고 있습니다. 한마디로 정리하자면 사전 학습을 진행했을 때 General 한 지식을 더 학습한다 라고 논문에서 설명하고 있고, 전체적인 성능이 향상된 것을 확인할 수 있었습니다.
5. Conclusion and Future Work
결론적으로 해당 연구는 액션 및 시각적 이해와 생성 기능을 통합하는 새로운 Autoregressive 프레임워크인 WorldVLA를 소개합니다. 해당 아키텍처를 통해서 월드 모델링과 action 모델링의 통합이 성능의 상호 향상을 가져올 수 있다고 하고, attention mask를 통해서 청킹 오류 누적을 예방했다고 말하고 있습니다.
결과적으로 보면 약간 월드 모델을 적용한다라는 중요한 점도 있긴 하지만 액션의 맥락을 이해하는데 World model을 가져와 쓴다는 느낌도 강하게 들었습니다. 보면서 느낀 점이지만 해당 논문은 뭔가 VLA보다는 World model에 맞추어져있다는 생각도 드는 것 같습니다. 좀 신기했던 점은 동작을 World model에 넣으니까 성능이 올랐다는 점입니다. 현재 World 모델은 action에 대한 정보가 없어서 NVIDIA의 DREAMGEN이나 GR00T N1 같은 경우에도 IDM과 같은 방식을 통해 영상에서 액션을 추출해내는 방법을 쓰는데 이런 방식을 사용하게 된다면 action까지 내재되어 있는 모델이 될 수 있겠구나 라는 생각을 하게 된 것 같습니다. 그리고 World Model에 대해서 자세한 내용이 논문에서 거의 없기도 하고, 제가 알고 있는 점도 크게 없어서 이 부분에 대해서는 좀 공부를 해보아야 될 것 같습니다.
그리고 보면서 뭔가 이상하다는 생각이 들었던 점은 추론 시간에 대한 컴퓨팅 리소스와 시간이 안나와있고, 모델의 크기는 어느정도 되는지 직접적으로 제시하지 않았다는 점입니다. World 모델을 로봇에 적용했으면 당연히 규모가 클텐데 이러한 인퍼런스 시간에 대해서는 어떻게 대응할 수 있는지 아니면 이미 소규모로 구성되어 있는 모델인지, 이런 점은 추가로 찾아보거나 해야 될 것 같습니다.
긴 리뷰 읽어주셔서 감사합니다!

기현님 좋은 리뷰 감사합니다.
world model과 action model을 융합하는 방식이 굉장히 단순한 것 같고, 이전 action에 대하여 마스킹한다는 게 흥미롭습니다.
이와 관련하여 몇가지 질문드릴 것이 있습니다.
사전 훈련된 multimodal 언어 모델이 주로 액션보다는 이미지와 텍스트에 노출되었기 때문에 제한된 액션 일반화 능력을 가지게 되며, 이를 해결하기 위해서 저자는 현재 액션을 생성하는 동안 이전 액션을 선택적으로 마스킹한다고 하셨는데,
즉, 액션에 대한 결과를 신뢰하기 어렵기 때문에 이전의 결과의 영향을 덜 받도록 하기 위한 것이라 이해하면 될까요?
또한, 해당 논문은 world model을 통해 이후의 행동에 대한 프레임을 추론하는 과정이 있는 것으로 이해하였는데, 이에 대한 시각화 결과는 따로 없는 지 궁금합니다.
안녕하세요, 승현님 답글 감사합니다.
질문에 대해서 순서대로 답변해드리자면 첫번째로, 액션은 위에서 보실 수 있듯이 예측한 값을 다음에 사용하는 식으로 되물림되는? 과정을 통해서 이루어집니다. 이런 부분에서 동작이 한번 잘못된다면 계속 오차가 누적되기 때문에 누적 오차를 막고자 이러한 해결책을 제시한 것 같습니다.
그리고 두번째 질문은 figure 5에 기존 World model과 our action world model이라고 적혀있는 부분이 있는데 이 부분을 참고하시면 좋을 것 같습니다.
좋은 질문 감사합니다!
기현님 좋은리뷰 감사합니다.
위에 승현님이 말씀해주셨긴한데 궁금한것이
WorldVLA의 action attention masking이 “청크 길이가 길수록 생기는 오류 누적”을 줄였다고 하셨는데 이것이 이전 행동을 못 보게 해서 단순히 예측하게 만든 효과일까요?
감사합니다
안녕하세요, 우진님 답글 감사합니다.
이 부분은 단순히 “이전 행동을 못 보게 해서 예측이 쉬워졌다”기보다는, 오류가 누적되는 경로 자체를 차단한 설계에 가깝다고 생각합니다. 기본 autoregressive 구조에서는 각 행동이 이전 행동을 조건으로 생성되기 때문에, 초기에 작은 오차가 발생하면 이후 행동들에 계속 영향을 주며 점점 증폭될 수 있습니다.
결과적으로 제안된 action attention masking은 이전 행동 토큰을 차단함으로써, 각 행동이 시각·텍스트 정보에 직접적으로 의존하도록 만들고, 잘못된 행동 예측이 다음 단계로 전달되는 구조를 완화하여서 안정성을 높인 것으로 보는 것이 적절하다고 보입니다
좋은 질문 감사합니다!
안녕하세요 기현님 좋은 리뷰 감사합니다.
간단한 질문이 있는데요.
“액션 토크나이저는 연속적인 로봇 액션의 각 차원을 256개의 bin 중 하나로 이산화하며 bin의 너비는 훈련 데이터의 범위에 의해 결정됩니다.”의 부분해서 bin의 너비도 학습을 통해 결정되는건지 아니면 그냥 지정되는건지 궁금합니다.
만약 지정되는 것이라면, 범위가 다른 데이터가 들어온다면 재학습되어야하는지도 궁금합니다
안녕하세요, 정우님. 댓글 감사합니다.
우선 한마디로 정리해 드리면, 데이터 통계에 기반해 결정되는 정적인 값에 가깝다고 보시면 될 것 같습니다.
데이터의 구간을 균등하게 나누어서 처리되는 전처리의 느낌의 표현이 저렇게 표현되어 있다고 설명드릴 수 있을 것 같습니다.
좋은 질문 감사합니다!