안녕하세요 손우진입니다.
오늘 제가 소개드릴 논문은 단일 rgb 기반의 6D pose 입니다. 단일 rgb 같은 경우는 깊이정보가 없기 때문에 6D 정보를 찾아내는게 쉽지않습니다. 또한 6D pose추출을 하더라도 Depth 정보를 사용하는것 보다 상대적으로는 성능이 저조합니다. 그래서 refinement를 통해서 더 정밀한 pose를 예측하는 방법들이 도입되고 있습니다.
6D pose 정보를 model을 통해서 추출하고 3d mesh를 활용하여 예측된 pose값으로 rendering 하게됩니다. 그 후 target 물체 이미지와 비교하여 정밀한 6D정보를 추출하게됩니다. 이번에는 optical flow를 활용하여 6D task에 맞게 활용하는 방안을 제안한 논문을 리뷰해보려합니다. 그럼 바로 시작하겠습니다!
Introduction
최근 6D 객체 포즈 추정 연구들을 살펴보면 초기 포즈를 구한 뒤 이를 refinement하여 정확도를 높이는 방식이 주를 이루고 있습니다. 앞서 말씀드린 것처럼, 보통 초기 포즈를 기준으로 타겟 객체를 렌더링하고, 실제 입력 이미지와 렌더링된 이미지 사이의 대응점, 즉 Optical Flow를 추정하는 패러다임이 일반적입니다. 그 후 이 2D Optical Flow를 타겟의 3D 형태를 이용해 3D-to-2D 대응점으로 끌어올린 뒤, PnP(Perspective-n-Point) 알고리즘을 통해 새로운 포즈를 계산하게 됩니다.
하지만 저자들은 이러한 기존의 일반적인 Optical Flow 기반 파이프라인이 6D Pose Estimation 환경에서 근본적인 세 가지 약점을 가진다고 객관적으로 지적합니다.
첫째, 기존 Optical Flow 네트워크들은 매칭을 수행할 때 주로 픽셀의 밝기 일관성과 local smoothness에만 의존합니다.(한글로는 국소적 평활도라고 하라고 한답니다.). 여기서 local smoothness란 인접한 픽셀들은 서로 비슷한 움직임을 가질 것이라는 일반적인 가정을 의미합니다. 하지만 이 가정은 일반적인 2D 영상에서는 유효할지 몰라도, 객체의 실제 3D 기하학적 경계를 전혀 반영하지 못합니다. 즉, 타겟 객체의 3D 형태에 대한 사전 지식 없이 매칭을 시도하기 때문에, 탐색해야 할 매칭 공간이 불필요하게 커지는 문제가 발생합니다.
둘째 형태 정보가 누락된 채 매칭이 진행되다 보니, 물체의 3D 구조를 전혀 반영하지 못하는 결과가 나오게 되고 이는 결국 포즈 계산 과정에 치명적인 매칭 노이즈로 작용하게 됩니다.
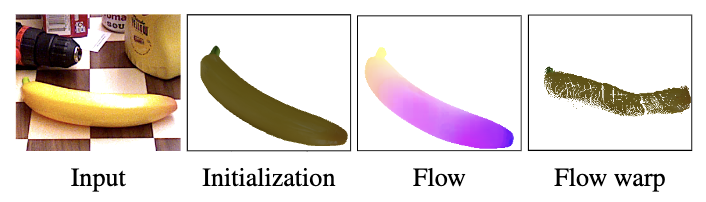
논문의 Figure 1입니다. 3D 구조를 전혀 반영하지 못한 채 예측된 Optical Flow를 사용하여 이미지를 와핑해버리면, 타겟 객체의 본래 형태가 깨지는 노이즈가 발생하게 됩니다. 이는 결국 6D 포즈 계산에 오차를 전달하게 되고, 좋은 결과를 낼 수 없는 구조가 됩니다.
셋째, Optical flow 추정과 PnP 기반 포즈 계산이 분리된 multi-stage 방식이라는 점입니다. 이는 최종 목표인 6D 포즈를 직접 최적화하는 것이 아니라 surrogate matching loss에 의존하게 만들며, 모델 전체를 End-to-End로 학습할 수 없게 만들어 최적화 관점에서 불리하게 작용합니다.
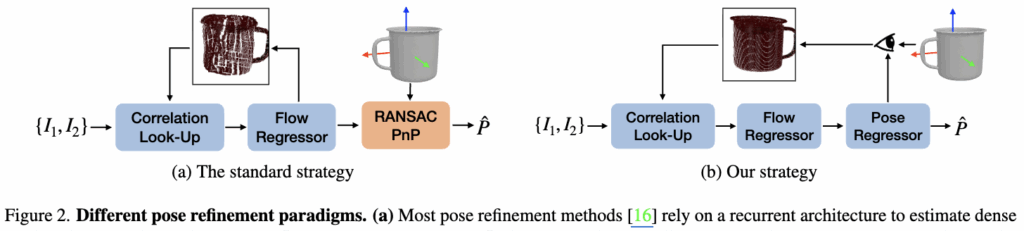
Figure 2에서는 매 iteration마다 복잡한 PnP solver를 사용하는 대신 현재 추정된 flow로부터 네트워크가 직접 객체의 포즈를 학습하도록 설계했습니다. 이를 통해 명시적인 PnP 없이 전체 파이프라인을 End-to-End로 학습 가능하게 만들고 연산 효율성까지 확보했습니다.
오늘 소개할 논문은 이러한 문제들을 해결하기 위해 shape-constraint recurrent matching framework(SCFlow)를 제안합니다. 논문의 핵심 아이디어는 네트워크가 무작위로 flow를 찾는 것이 아니라, 타겟의 3D 형태를 포함하는 ‘pose-induced flow’를 계산하고, 오직 이 범위 내에서만 매칭 공간 correlation map을 탐색하도록 강제하는 것입니다.
추가적으로, 매 iteration마다 복잡한 PnP solver를 사용하는 대신, 현재 추정된 flow로부터 네트워크가 직접 객체의 포즈를 학습하도록 설계했습니다. 이를 통해 전체 파이프라인을 End-to-End로 학습 가능하게 만들고 연산 효율성까지 확보했습니다.
저자들의 핵심 Contribution을 간단히 정리하면 다음과 같습니다.
- 6D 객체 포즈 추정에 특화된, 타겟의 3D 형태 제약을 optical flow의 상관관계 맵 구성에 임베딩하여 매칭 공간을 줄였습니다.
- Optical flow로부터 포즈를 직접 regression하는 네트워크를 도입하여, 명시적인 PnP solver 없이 포즈와 optical flow를 동시에 End-to-End로 최적화하는 프레임워크를 제안했습니다.
- LINEMOD, LINEMOD-Occluded, YCB-V와 같은 까다로운 데이터셋에서 기존 SOTA 대비 정확도와 효율성 모두 유의미한 성능 향상을 수치로 입증했습니다.
Method
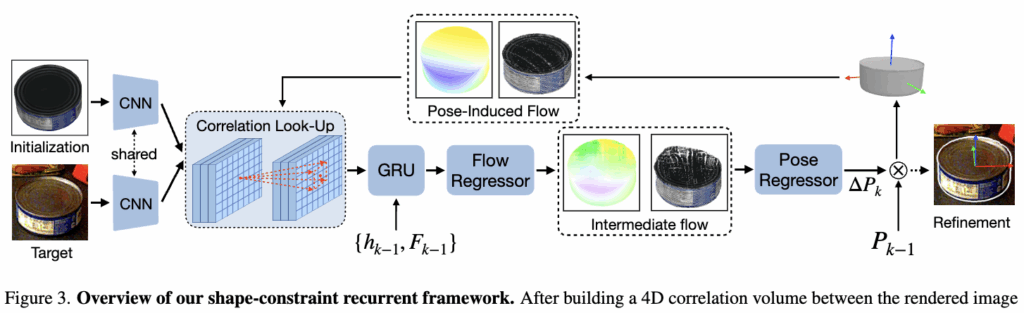
Method 파트에 대해 설명드리겠습니다. 위 그림은 제안하는 프레임워크의 Overview입니다. 이 논문의 기본적인 네트워크 뼈대는 Optical Flow 예측 모델인 RAFT 아키텍처를 기반으로 하고 있다고 합니다. 이를 저자들은 6D Pose Estimation을 위한 Render-and-Compare 방식에 맞게 개조하여 사용합니다.
우선 초기 포즈로 렌더링된 이미지와 실제 입력 이미지에서 각각 가중치를 공유하는 CNN으로 특징을 추출하여 4D Correlation Volume을 생성합니다. 이후 RAFT와 동일하게 GRU 모델을 통과하여 중간 단계의 flow를 예측하게 됩니다.
여기서 기존 모델과 다른 점은, 이 intermediate flow를 바탕으로 Pose Regressor가 객체의 포즈 변화량(P)을 직접 추정한다는 것입니다. 그리고 이렇게 업데이트된 포즈를 이용해 타겟의 3D 형태가 반영된 ‘pose-induced flow’를 계산한 뒤, 이 flow를 기준으로 다음 iteration의 Correlation map을 인덱싱(Lookup)하게 됩니다.
그럼 이 프레임워크에서 핵심이 되는 두 가지 모듈을 구체적인 수식과 함께 살펴보겠습니다.
Shape-Constraint Correlation Space
일반적인 RAFT 기반의 Optical Flow 네트워크에서 사용하는 표준 Lookup 연산은 현재 픽셀 위치 x=(u,v)에 추정된 flow f(u,v)를 더해 다음 매칭 위치 x'를 찾습니다. 하지만 이 방식은 6D 포즈 추정 시 모든 매칭점들이 타겟 객체의 3D 형태(shape)를 따라야 한다는 사실을 고려하지 않기 때문에 탐색 공간이 불필요하게 커집니다.
이를 해결하기 위해 저자들은 타겟의 3D 형태를 Lookup 연산에 직접 임베딩하여 형태가 제약된(shape-constraint) 위치를 생성합니다. 구체적으로는 타겟 3D 모델(mesh) 표면에 존재하는 3D 포인트 p_i를 이용해 투영 좌표를 계산합니다.
먼저, 초기 포즈 P_0(회전 행렬 R_0, 이동 벡터 t_0)를 기준으로 한 2D 픽셀 위치 u_{i0}는 카메라 내부 파라미터 K를 이용해 다음과 같이 구합니다:
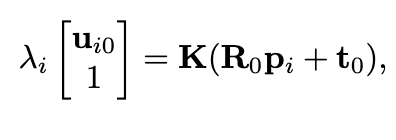
여기서 \lambda_i는 스케일 팩터입니다. 마찬가지로, 현재 iteration 단계에서 추정된 포즈 P_k를 기준으로 동일한 3D 포인트 p_i를 투영하여 새로운 2D 위치 u_{ik}를 얻습니다.
이때, 두 2D 투영 좌표의 변위가 바로 저자들이 정의한 pose-induced flow가 됩니다: f = u_{ik} - u_{i0}
이 flow f는 픽셀의 밝기 유사도로 찾은 값이 아니라, 실제 3D 모델 표면의 점들이 초기 포즈와 현재 추정된 포즈 사이에서 2D 이미지 상으로 어떻게 이동했는지를 나타낸 다고 저자들은 얘기를 합니다. 또한 연산의 효율성과 정확도를 위해 가려지지 않은 표면의 3D 포인트들에 대해서만 이 2D flow를 계산합니다.
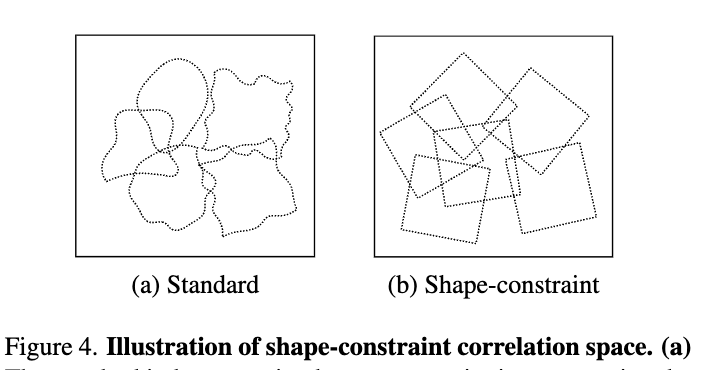
Figure 4는 다음 iteration에서 Correlation map을 만들 때 이 pose-induced flow를 기준으로 인덱싱을 수행하면, 탐색 공간이 객체의 3D 형태가 2D로 투영된 영역 내로 제한됩니다. 즉, 배경에서 불필요한 노이즈를 줄일 수 있게 됩니다.
Learning Object Pose From Optical Flow
앞서 설명한 기하학적을 위한 pose-induced flow를 계산하려면, 필연적으로 매 iteration마다 현재 시점의 포즈 예측값 P_k가 필요합니다. 원래 이 포즈는 현재 추정된 중간 flow를 바탕으로 PnP solver 예를들어, RANSAC-PnP를 적용하여 얻을 수 있습니다. 하지만 PnP 연산은 네트워크 학습 과정에서 안정적으로 미분 가능하게 구현하기가 매우 까다롭다는 단점이 존재합니다.
이를 해결하기 위해 저자들은 PnP를 제거하고, 네트워크가 직접 객체의 포즈를 학습하도록 설계했습니다. 구체적으로 모델은 현재 예측된 intermediate flow(그리고 내부적으로는 GRU의 hidden state feature)를 기반으로 포즈의 잔차인 \Delta P_k를 회귀합니다. 이를 통해 포즈를 다음과 같이 반복적으로 업데이트합니다:
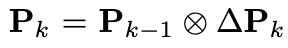
이때 잔차 회전 \Delta R은 신경망 학습의 연속성을 위해 6D 표현으로 인코딩되며, 잔차 이동 \Delta T는 이미지 평면 상의 2D 오프셋과 스케일링 형태로 파라미터화됩니다. 이렇게 업데이트된 현재 포즈 P_k를 바탕으로 초기 포즈와의 변위를 계산하여 새로운 pose-induced flow를 만들게 됩니다. 이 과정을 거쳐 도출된 flow는 타겟의 3D 형태를 온전히 보존하게 되며, 다음 iteration의 correlation map을 구성하는 데 핵심적으로 사용됩니다.
결과적으로 이러한 Pose Regressor의 도입은 단순히 PnP를 대체한 것을 넘어, Optical flow 최적화와 포즈 최적화를 동시에 수행하는 End-to-End 파이프라인을 완성했다는 데 가장 큰 의의가 있습니다. 전체 파이프라인이 하나로 연결되었기 때문에, 모델은 매 반복마다 발생하는 포즈 손실(\mathcal{L}<em>{pose})과 흐름 손실(\mathcal{L}{flow})을 결합하여 다음과 같이 직접적으로 최적화할 수 있게 됩니다.
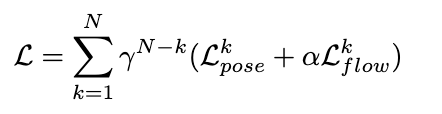
수식에서 볼 수 있듯, 학습은 총 N번의 iteration에 대해 지수 가중치(\gamma)를 적용하여 후반부 반복 결과에 더 큰 비중을 두는 방식으로 진행됩니다. 초기 반복 단계에서는 추정값이 상대적으로 부정확할 수밖에 없는데, 모델이 정확도를 올리기 위한 설계입니다.
여기서 핵심인 포즈 손실(\mathcal{L}<em>{pose})은 객체 3D mesh 표면에서 무작위로 추출한 1,000개의 3D 포인트를 활용하여, 정답(GT) 포즈와 예측 포즈 간의 3D 거리 오차를 계산합니다. 또한 흐름 손실(\mathcal{L}{flow})은 정답 흐름과 예측된 중간 흐름 간의 L1 오차를 구하되, 가려지지 않은 객체 영역에 대해서만 계산하여 정확도를 높였습니다.
이처럼 surrogate loss에 의존하던 기존 방식에서 벗어나 실제 6D 포즈 오차를 직접 목적 함수에 반영함으로써, 제안된 프레임워크는 객관적으로 빠르고 안정적인 최적화가 가능해졌습니다.
Experiments
저자들은 LINEMOD, LINEMOD-Occluded, YCB-V라는 세 가지 벤치마크 데이터셋을 사용하여 기존 SOTA 방법들과 성능을 비교했습니다.
Table 1 기존의 베이스라인이었던 PFA 모델과 비교했을 때, 가장 까다로운 YCB-V 데이터셋(ADD-0.1d 지표 기준)에서 PFA가 62.8%를 기록한 반면, 제안된 모델은 70.5%로 성능을 큰 폭으로 향상시켰습니다. 그리고 저자들의 초기 포즈 추출은 PoseCNN을 사용하였다고 합니다. 그래서 PoseCNN의 결과에서 ours 성능을 보시면 성능향상이 큰 폭으로 향상하였습니다. 이로써 Refinement 과정이 큰 성능향상이 일어날 수 있음을 볼수있습니다.

정확도 향상뿐만 아니라 연산 효율성 측면의 결과도 눈여겨볼 만합니다. Table 3의 실행 시간 분석을 보면, 기존 PFA가 이미지 내 단일 객체를 처리하는 데 37ms가 소요되는 반면, 본 논문의 모델은 단 17ms만에 처리를 완료합니다. 앞서 연산 bottle-neck을 유발하는 RANSAC-PnP 과정을 신경망 기반의 Pose Regressor로 완전히 대체한 것이 이러한 속도 향상의 결정적인 원인이라고 저자들은 분석합니다.

또한, 저자들은 초기 포즈의 노이즈에 얼마나 강건한지를 평가한 Figure 6(a)의 실험 결과 입니다. PoseCNN이 추정한 초기 포즈에 의도적으로 강한 회전 노이즈를 섞었을 때 베이스라인인 PFA의 성능은 11.9%로 떨어졌습니다. 반면 본 논문의 모델은 동일한 노이즈 조건에서도 성능 하락이 약 6.2%에 그쳤습니다. 이는 Optical flow 매칭 과정에 타겟의 3D 형태라는 기하학적 제약을 걸어둔 덕분에, 초기 추정이 매우 부정확한 상황에서도 매칭이 튀지 않고 안정성을 유지한다는 사실을 객관적으로 입증합니다.
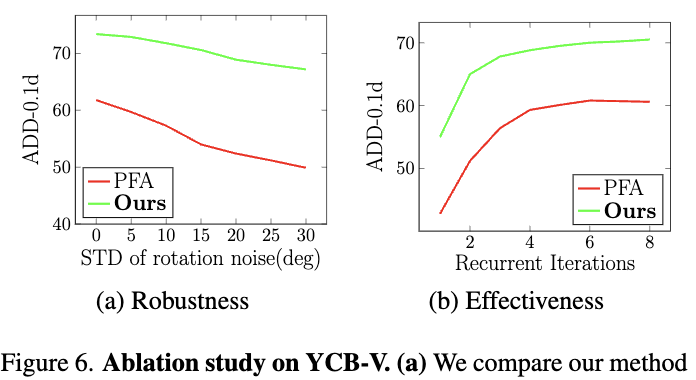
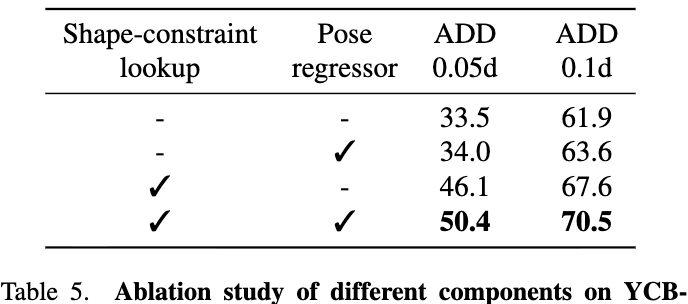
마지막으로 Ablation Study 결과입니다. 기본 PFA(Baseline) 구조에서 시작하여 Shape-constraint lookup 연산만 추가해도 YCB-V 데이터셋 기준 성능이 61.9%에서 67.6%로 상승합니다. 여기에 Pose Regressor까지 추가하여 프레임워크를 End-to-End로 구성했을 때 최종 성능인 70.5% 찍었습니다.
마지막으로 정성적 자료입니다. 베이스라인인 PFA 모델의 3D 형상 깨짐과 Pose가 더 정밀한것을 보실 수 있습니다

optical flow로 pose refinement를 하는 흐름이 거의 자리잡다보니 pose 추출기가 좀 약하더라도 충분히 성능을 끌어올리는데 사용할 수 있을거 같습니다. 감사합니다
인녕하세요 우진님 좋은 리뷰 감사합니다.
수식에서 f = uik-ui0로 정의했는데 여기서 ui0는 초기 추정 포즈로 렌더링한 기준 좌표로 고정이고 uik 만 업데이트되는 구조인건가요?? 그럼 lookup은 항상 처음 렌더 좌표계를 기준으로 잡는 건지, 아니면 iteration마다 기준이 바뀌는 건지 궁금합니다. 감사합니다.
안녕하세요 우진님 좋은 리뷰 감사합니다.
RAFT 기반의 Optical Flow를 기반으로 6D에 잘 적용한 논문으로 이해했습니다.
Optical Flow쪽에서는 이후에는 GMFlow와 같은 논문을 시작으로 Transformer의 강력한 힘을 기반으로 flow를 예측하는 방향으로 나아가고 있는걸로 알고 있습니다.
6D도 transformer을 이용하여 correleation을 구하는 방향으로 가고 있는지, 아니면 다른 방법론이 대세가 되고 있는지 궁금합니다