안녕하세요 이번에 들고온 논문은 VLM 들도 사람과 비슷하게 착시를 겪는지? 를 분석한 논문입니다.
그럼 리뷰 시작하겠습니다.
Abstract
Vision-Language Models 즉 VLMs 들은 인간이 생성한 방대한 데이터로 학습되고 세계를 이해하는 인간의 방식을 모방한다고 합니다. 하지만 인간의 현실 인지 능력은 항상 실세계의 물리적인 특성을 정확히 반영하지는 않습니다. 저희가 흔히 알고있는 시각적 착시(Visual illusions)를 일컫는 것입니다.
저자들은 여기서 의문을 제기합니다.
- VLM들도 인간과 유사한 착시를 경험하는가?
- 혹은 현실을 사람보다 더 잘 이해하도록 학습하는가?
이 질문을 탐구하기 위해, 저자들은 다섯 가지 유형의 시각적 착시를 포함한 데이터셋을 구축하고, 최신 VLM을 대상으로 네 가지 과제를 설계하여 착시 현상에 대해 분석합니다.
실험 결과 전체적으로 인간과의 정렬은 낮았지만 모델 크기가 클수록 인간의 인지와 더 유사해졌으며, 동시에 시각적인 착시에 더 취약해졌습니다.
이 데이터셋과 초기 연구 결과는 인간과 기계의 시각적 착시 이해를 돕고, 향후 인간과 기계가 동일한 시각 세계를 더 잘 공유하고 소통할 수 있는 모델 연구의 발판이 될거라고 합니다.
Introduction
저자는 먼저 인간의 시각 인지 시스템이 완전히 객관적이지는 않다는 점에서 이야기를 시작합니다. 우리는 흔히 눈으로 본 것이 곧 현실이라고 생각하지만, 실제로는 물리적으로 동일한 자극이라도 다르게 지각하는 경우가 존재합니다. 이를 시각적 착시(visual illusion)라고 합니다.
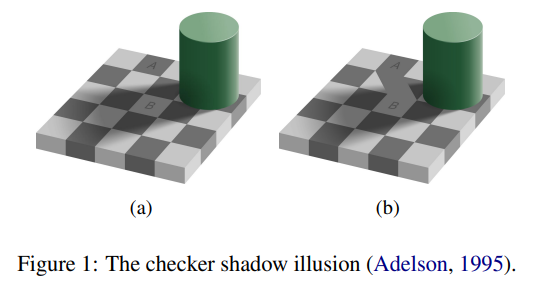
대표적인 예로 Figure 1에 등장하는 checker shadow illusion을 제시합니다. 체커보드 위에 원기둥이 그림자를 만들고 이 상태에서 A와 B 두 칸을 비교하게 합니다. 대부분의 사람들은 A가 B보다 더 어둡다고 인식하지만, 실제 픽셀 값은 완전히 동일합니다. 즉 물리적 속성은 같지만 인간의 지각은 다르게 작동하는 것입니다.
저자들이 여기서 강조하는 포인트는 단순히 “사람이 착시에 속는다”가 아닙니다. 이러한 지각의 왜곡이 언어 사용에까지 영향을 미친다는 점입니다. 예를 들어 두 사람이 동시에 이 그림을 본다면 “더 어두운 칸”이라는 표현은 자연스럽게 A를 가리키게 됩니다. 이는 두 사람이 동일한 착시를 공유하고 있기 때문입니다.
저자들은 여기서 질문합니다.
“인간과 기계가 같은 장면을 보았을 때, 기계도 더 어두운 칸을 A로 해석할까?”
최근 VLM의 발전으로 인간-기계 간의 시각 기반 언어 소통이 점점 중요해지고 있는 상황에서, VLM이 인간과 유사한 시각적 착시를 경험하는지, 그리고 어느 정도 인간 지각과 정렬(alignment)되어 있는지를 이해하는 것은 중요한 문제라고 합니다.
기존에도 착시 연구들이 존재하긴 했지만, 이들은 대부분 순수 vision 모델 내부 표현을 분석하는 방식이었고, 개별 사례 중심의 실험이었다고 합니다. 즉, 언어와 연결된 착시 현상을 체계적으로 분석한 연구는 없었다는 것이 저자들의 문제 정의입니다.
그래서 저자들은 다섯 가지 시각적 착시 유형을 포함한 새로운 데이터셋을 구축하고, 이를 기반으로 GVIL (Grounding Visual Illusion in Language)이라는 벤치마크를 제안합니다. 이 벤치마크는 네 가지 sub-task로 구성되어 있습니다.
- Same-Difference QA
- Referential QA
- Attribute QA
- Referential Localization
이 태스크들은 단순히 픽셀을 비교하는 것이 아니라, 언어를 통해 모델이 인간과 동일한 지각 왜곡을 보이는지를 평가하도록 설계되었습니다.
QA 기반 태스크에서는 대부분의 모델이 인간과 낮은 alignment를 보였습니다. 한마디로 인간처럼 착시에 속지 않는 경우가 많았습니다. 하지만 Referential Localization 태스크에서는 특히 큰 모델일수록 인간과 더 유사한 판단을 보였고, 오히려 착시에 더 취약해지는 경향을 보였습니다.
이러한 결과에서 이 논문의 contribution은 2가지입니다.
- 인간과 기계의 시각 착시 alignment를 언어 기반으로 처음 체계적으로 분석함
- 내부 representation 대신 언어 반응을 사용해 모델의 착시 여부를 평가함
저자들은 이러한 연구가 향후 인간과 기계가 동일한 시각 세계를 더 잘 공유하고 소통할 수 있는 grounded communication 모델 개발의 발판이 될 것이라고 주장합니다.
Machine Visual Illusion
먼저 저자들은 머신비전 분야에서의 시각 착시 연구들을 related work에 정리했습니다. 최근 몇 년간 시각 착시에 대한 체계적인 연구를 가능하게 하는 도구와 프레임워크들이 다수 제안되었다고 합니다.
예를 들어 착시 이미지를 계산하고 생성할 수 있는 도구들이 개발되었고, 새로운 착시를 합성하는 방법론들도 제안되어왔다고 합니다. 또한 기존 연구들이 이미 ImageNet이나 low-level vision task 로 학습된 CNN 들이 특정 시각 착시에 인간처럼 속는다는 점을 보여줬다고 합니다. 이는 VLM 들도 역시 인간과 유사한 방식으로 시각 정보를 처리할 가능성을 보여줍니다.
앞서 언급했지만 저자들이 기존 연구와의 차별점으로 언급하는 점은 단순히 모델이 착시에 속는지를 보는 것이 아니라 인간과 기계가 같은 착시를 공유한다면, 언어적 소통이 어떻게 이루어지는지를 분석하는것이 핵심입니다.
Data Collection
저자들은 먼저 데이터셋 구성을 인간의 생리적, 인지적 과정과 연결된 다섯 가지 시각적 착시 유형을 포함해서 만듭니다. 단순히 재미있는 그림을 모은게 아닌 인지과학쪽 논문들에 기반해서 체계적으로 유형을 구분했다고 합니다.
다섯가지 착시는 크게 2가지로 나뉘는데 첫번째는 색(color)착시이며 두번째는 기하(Geometric)착시 입니다.
Color Illusions
- Color constancy (색 항상성)
- 조명 조건이 바뀌어도 물체의 색은 일정하게 인식되는 현상입니다. RGB 값이 일정해도 조명 필터 때문에 다르게 보이는 경우입니다.
- Color Assimilation (색 동화)
- 인접한 색 영역이 서로 영향을 주어 지각되는 색 차이가 줄어드는 현상입니다. 실제 색은 같지만 주변 맥락 때문에 다르게 보이는 경우입니다.
- Color Contrast (색 대비)
- 주변 색과 반대 방향으로 지각 색이 왜곡되는 현상입니다. 동일한 회색이 밝거나 어두워 보이는 케이스라 생각하면 됩니다.
Geometric Illusions
- Geometrical Relativity (기하 상대성)
- 주변 객체의 크기나 배치에 따라 동일한 객체의 크기가 다르게 지각되는 현상입니다.
- Geometrical Perspective (기하 원근)
- 동일한 크기의 객체가 원근 때문에 다르게 보이는 현상입니다.
저자는 각 착시 유형마다 문헌과 온라인 자료에서 root image를 수집하고 착시 효과는 유지하면서도 변경 가능한 속성들을 수동으로 조정해 데이터 증강을 수행한다고 합니다.
예를 들어서 기하 착시에서는 색을 바꿔도 착시 효과는 유지된다거나 색 착시에서는 위치를 바꿔도 효과가 유지되는 케이스가 있습니다.
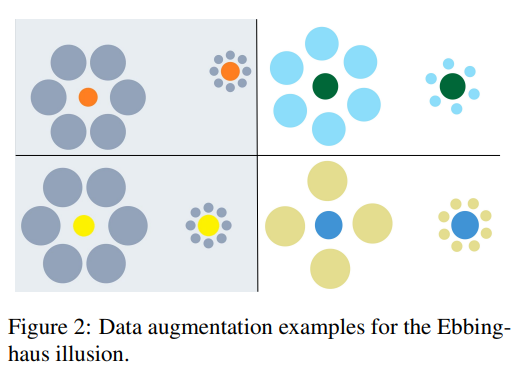
저자의 데이터셋이 대규모 데이터셋은 아니고 그 이유는 학습용이 아니라 평가용이기 때문입니다. 다만 구조적으로는 확장 가능하도록 설계되었다고 합니다.
Benchmark Tasks
저자들은 총 네가지 vision-language 태스크를 정의합니다. 이 태스크들이 단순히 착시에 속는지를 보는 것이 아니라 모델이 인간과 얼마나 유사하게 착시를 이해하고 언어로 소통하는지를 평가하기 위해 설계되었습니다.
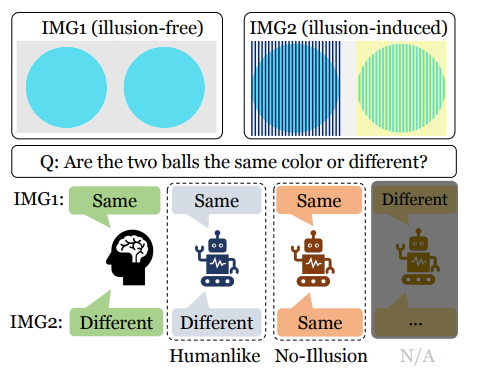
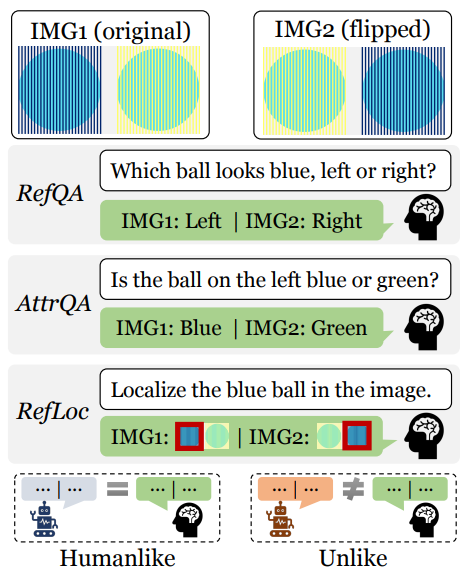
- Same-Different Question Answering (SameDiffQA)
- IMG1 과 IMG2의 두 개의 이미지로 구성됩니다. 첫번째는 착시가 없는 원본 이미지이며 두번째는 착시가 유도된 이미지입니다. 모델은 두 공이 같은색인지 다른 색인지를 답해야합니다.
- IMG1에 대해서는 same IMG2에 대해서는 Different라고 답하면 human-like, 모두 same이라고 대답하면 물리적으로는 정확하지만 인간처럼 착시에 속지는 않는 것입니다.
- 만약 IMG1에서 different라고 답한다면 시각 인지 능력이 부족하다 판단하고 평가 대상에서 제외합니다.
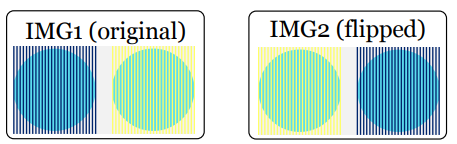
SameDiffQA가 단순 감지 문제였다면 다음은 착시가 존재하는 상황에서 인간-기계 간 언어 정렬을 평가합니다. 저자들은 모델이 텍스트만 보고 shortcut으로 답하는 문제를 막기 위해 paired test 구조로 설계했다고 합니다. 각 인스턴스는 두 이미지로 구성됩니다.
- IMG1 : 원본 착시 이미지
- IMG2: 객체 위치를 뒤집은 이미지
즉 질문에 대해 정답도 함께 뒤집히도록 설계되었습니다. 모델이 진짜 이미지를 봐야 답할 수 있는 구조라 생각하면 됩니다.
Referential Question Answering (RefQA)
이 태스크는 착시의 영향을 받는 속성을 기준으로 객체를 지칭할 수 있는지를 평가합니다. 예를 들어 파랗게 보이는 공은 왼쪽인가 오른쪽인가? 를 묻고 IMG2 에서는 좌우가 바뀌어있기 때문에 대답도 반대로 해야합니다. 두 이미지에서 모두 인간과 같은 대답을 할 때만 human-like로 평가합니다.
Attribute Question Answering (AttrQA)
이 태스크는 착시 상황에서 속성을 어떻게 묘사하는가? 를 평가합니다. 예를 들어 왼쪽 공은 파란색인가 초록색인가? 에서 물리적으로는 동일하지만 인간은 착시 때문에 다르게 대답합니다. 모델이 인간처럼 속성 묘사를 하는지를 평가합니다.
Referential Localization (RefLoc)
이 태스크는 착시에 기반한 지칭 표현을 보고 객체를 정확히 localization 할 수 있는지를 봅니다. 예시로 파란 공을 찾아라 라는 질문에 인간은 착시 떄문에 특정 공을 파랗다고 인지합니다 모델은 해당 객체의 bounding b ox를 예측해야합니다. 위의 paired 이미지에서 두 이미지 모두 인간과 동일하게 localization을 해야 human-like로 평가합니다.
Annotation 방식
모든 착시 이미지에 대해 자연어 질문을 생성하고 인간이 착시 상황에서 답할 답을 미리 지정합니다.
referring expression + bounding box annotation 이 제공되고 각 샘플은 최소 3명의 annotator가 검증했다고 합니다. 언어적인 민감도를 위해 paraphrase된 문장도 제공한다고 합니다.
Experimental setup
Viison-Language Models
저자는 GVIL 벤치마크의 네 가지 태스크를 모두 수행할 수 있는 모델들을 선정해서 평가 대상으로 선택했습니다. 단순 QA 뿐만 아니라 object localization 능력도 필요로 하는 것입니다.
- unified-IO
- OFA
- LLAVA
- instructBLIP
을 최종 선정해서 진행하고 Unified-IO 와 OFA는 다양한 VL 태스크에 대해 학습된 모델로 zero shot 성능이 강력하다고 알려져 있습니다.
그 다음 LLaVA 와 InstructBLIP은 LLM을 이미지 이해에 적응시킨 최근( 2023당시의) 모델입니다. 이 모델들이 이미지 속 유머나 미묘한 개념적 뉘앙스까지 이해하는 능력을 이미 가지고 있음을 알기에 착시처럼 물리적으로는 같지만 지각적으로는 다른 상황을 해석하는 대상으로 적합했다고 합니다.
4가지 모델은 모두 모델의 크기가 작은버전부터 큰 버전이 존재하여 모델 사이즈에 따른 분석도 진행했습니다.
Metrics
- Humanlike Rate : 모델이 인간과 정확히 답한 비율
- No-Illusion Rate (SameDiFFQA 전용) : 이 지표는 모델이 착시가 있든 없든 항상 same 이라고 답한 비율입니다. 즉 모델이 물리적 현실에 충실한 정도입니다.
- N/A ( Not Applicable) : 착시 없는 이미지에서조차 동일성을 인지 못한경우, 혹은 엉뚱한 대답을 한경우는 제외합니다.
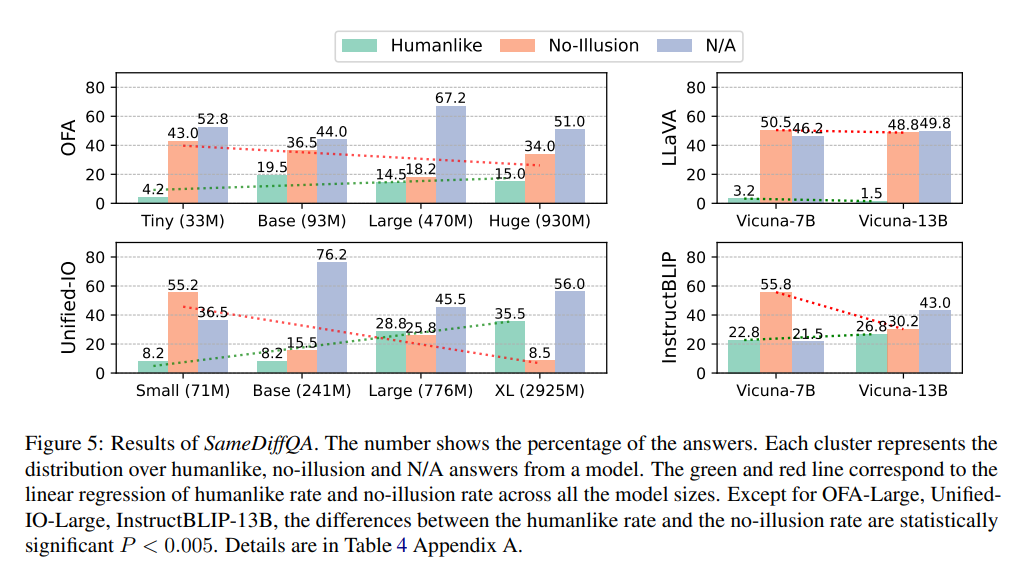
Figure 5 에서는 SameDIffQA에 관한 결과를 보여줍니다. 대부분의 모델에서 Humanlike rate는 크기가 증가할수록 증가합니다. 즉 모델이 커질수록 인간처럼 착시에 더 잘 속는 경향이 있다고 할 수 있습니다.
Results Analysis
저자들은 세 가지 연구 질문(RQ) 를 중심으로 결과를 분석합니다.
- RQ1 : VLM 은 인간처럼 착시의 존재를 인식하는가?
- RQ2 : 착시 상황에서 인간과 얼마나 정렬되는가?
- RQ3 : 착시 유형에 따라 정렬 정도가 달라지는가?
Illusion Recognition (RQ1)
위의 figure 5를 다시 보면 N/A의 비율이 상당히 높은 것을 알 수 있습니다. 즉 많은 모델들이 착시 여부를 떠나서 착시가 없는 이미지에서조차 두 객체가 동일하다는 것을 정확하게 인지하지 못합니다. 저자들은 이것을 착시 이전에 기본적인 vision-lanuage 추론 능력 자체가 앚기 부족하다고 합니다. ( 이건 더 최신 모델들의 refer가 존재하는지를 봐야할 것 같긴 합니다. )
N/A를 제외하면 모델들이 랜덤으로 대답하는 것은 아니고 최소한 착시 경향을 측정하는데에는 유효하다고 판단했습니다. 대부분의 모델이 인간처럼 속기보다 real world 에 충실한 대답을 합니다 특히 instructBLIP 은 거의 no-illusion 경향이 강하고 반면 Unified-IO XL 모델은 humanlike 반응이 강한 유일한 모델입니다.
저자들은 모델 크기에 따른 경향을 보기 위해 피어슨 상관 분석을 확인하는데 일부 태스크에서는 통계적으로 유의미한 양의 상관관계가 나타났다고 합니다.
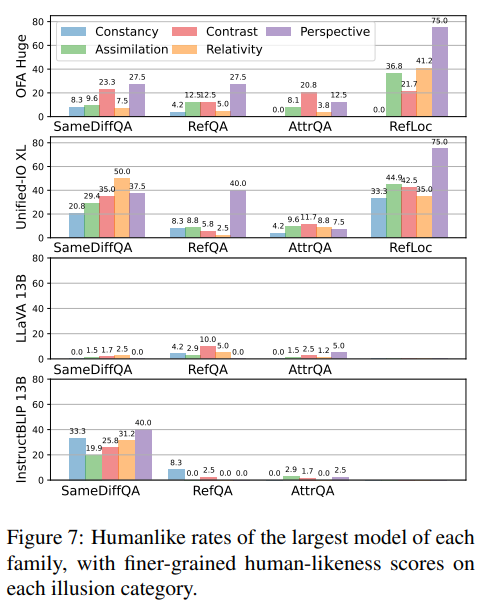
Figure7 에서는 각모델의 가장 큰 버전에 대해 착시 유형별 humanlike rate를 세분화해서 보여줍니다. 여기서 볼 수 있는 것은 색 착시와 기하 착시 간 차이가 존재하고 모델에 따라 특정 착시 유형에서 alignment차이가 존재한다는 것입니다.
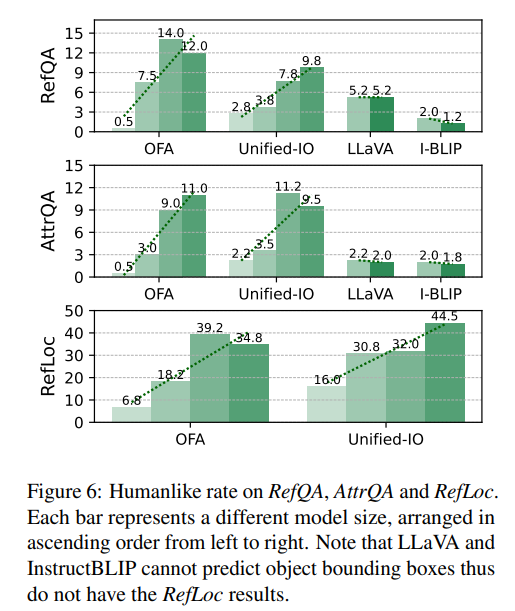
대부분의 모델은 착시 상황에서 인간처럼 지칭하거나 속성을 묘사하지 못했습니다. 다만 QA는 잘 못하지만 localization 이 가능한 모델들에 한해서는 상대적으로 잘 맞추는 경향이 있습니다. OFA 나 Unified-IO 계열에서는 scale과 humanlike 사이에 강한 양의 상관이 존재함을 위의 figure를 보면 알 수 있습니다. 또한 perspective illusion에는 human과 비슷하지만 Color constancy에 대해서는 alignment가 낮음을 보아 기하적 원근 착시는 상대적으로 위치 정보 기반이고 색 항상성은 저수준의 인지가 필요한 task이므로 모델이 고수준의 relational pattern에는 강하고 저수준 색 보정에는 약할 가능성이 있다고 합니다. 이러한 특성들이 가까운 것과 먼 것 같은 관계적인 정보가 embedding에 잘 녹아서 이미 bias를 모델이 학습했지만 Color constancy는 인간은 바로 색보정을 하는 반면 모델들은 직접적으로 모델링된 적 없기에 잘 못 맞추는 것으로 해석합니다.
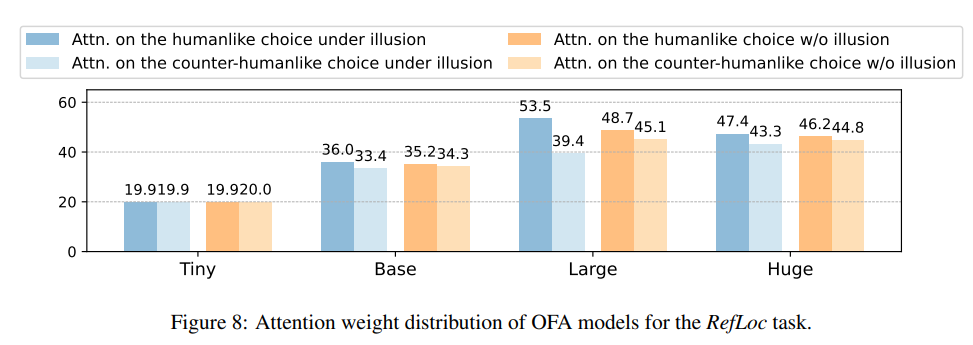
다음은 OFA 모델의 RefLoc 태스크에서 attention 분포를 보여주는데, 질문으로 the smaller orange ball 같은 착시 상황에서 두 공의 크기는 같지만 왼쪽이 더 작아보이는 경우를 보여줍니다. 진한 파란색은 humanlike에 준 attn 이 높은경우. 주황색 계열은 착시가 없는 이미지입니다. OFA 모델에서는 모델의 사이즈가 커질수록 humanlike 대상에 더 많은 attn 을 주는 것을 알 수 있습니다. 즉 착시가 attention 분포 자체를 인간과 유사하게 왜곡한다고 해석할 수 있습니다.
저자가 Limitation 에도 언급하지 않은 내용이지만 사실 OFA 와 Unified-IO 그리고 LLaVA와 InstructBLIP은 end to end VLM 과 vision encoder + LLM 이라는 구조적 차이가 있는만큼 그 경향성이 다르게 나타나고 있습니다. 앞의 end to end 방식의 모델들은 vision language를 joint하게 training하여 scale과 humnalike 경향성이 더 뚜렷한 것이라 생각하고 LLM중심의 VLM 모델들은 projector 만사용했으므로 language prior가 강해 pixel-level 의 착시에 좀 둔감하여 human like 한 특성이 안나타나는게 아닌가 하는 생각을 했습니다.
저자가 scaling 이라는 모델의 크기에만 집중하고 아키텍처적 분석이 없는게 좀 아쉽게 생각합니다.
Conclusion
저자는 GVIL 이라는 자연어 기반으로 모델의 시각 착시를 체계적으로 평가하는 최초의 데이터셋을 제안했다는 contribution이 있습니다. 또한 4가지의 최신 VLM 모델로 이를 평가하였고 위에 언급했던 모델의 사이즈별 human like의 상관관계, QA 태스크에서는 인간 관점을 잘 재현하지 못하는 점 등을 밝혀냈다고 합니다.
감사합니다.
리뷰 잘 읽었습니다. 초반부 introduction이 굉장히 흥미로우면서도 궁금한 점이 생기는데요
Human-like를 ‘착시에 속는 답’으로 정의한 것 같습니다. 그런데 이게 ‘인간과 같은 지각’을 의미하는지, 아니면 단순히 ‘편향을 학습했다’에 가까운지 헷갈리네요. 예를 들어 큰 모델이 human-like가 늘었다 = 더 인간적이다로 해석해도 되는지, 아니면 데이터/언어 priors로 ‘사람이 보통 그렇게 말한다’를 맞춘 결과일 것 같기도 해서요
안녕하세요 주영님 좋은 질문 감사합니다.
저자가 해당 부분에 대해서 직접적으로 언급한 부분이 없긴 하지만 결론 내릴 수 없어서 그랬다고도 생각이 듭니다. 모델이 인간과의 perceptual 한 착시를 경험한다라기 보다는 인간과의 alignment가 증가한다는 수준으로 해석한다고 이해하면 될 것 같습니다.
감사합니다.
안녕하세요 인택님 재밌는 리뷰 감사합니다.
먼저 SameDiffQA에서 IMG1(착시 없음)에서 틀리면 N/A로 제외하는데, 그러면 착시에 속느냐가 아니라 기본 인지 가능한 샘플에서만 착시 반응을 보는 느낌이 되는 거 같은데 이걸 N/A 자체를 별도 성능으로 해석하거나 N/A가 높은 모델을 동일 선상에서 비교해도 되는지 의문이 듭니다!
그리고 이 벤치마크가 궁극적으로 원하는 방향이 인간처럼 착시에 속는 모델인지, 아니면 착시를 인지하고도 인간과 소통 가능한 모델 인지가 궁금합니다. 해당 벤치마크의 목적성(?)이 궁금합니다. 감사합니다.
안녕하세요 우현님 좋은 답글 감사합니다.
우선 N/A 처리 부분에서는 착시 반응을 보기전에 기본적인 시각적 동일성 판단 능력이 있는지 여부를 필터링 했다고 생각합니다. 후자의 생각에 대해서는 저도 정량적으로 좀더 깊은 고찰이 있었으면 좋았겠지만 어떻게 검증할지가 떠오르지는 않네요.
그리고 두번째 질문에 답해드리자면 벤치마크의 목적성은 궁극적으로 인간의 지각을 이해하고 인간과 동일하게 소통할 수 있는 모델로써의 분석이 아닐까 싶습니다.
감사합니다.
인택님 안녕하세요. 좋은 리뷰 감사합니다.
그렇게 패치를 세세하게 들여다보는 모델들이 색깔 하나 제대로 못본다는게 신기하긴 하네요. 또 그 사이에 나온 최신 모델들은 어떻게 반응할지도 궁금하여 재미있게 읽게 되었습니다.
다만 저자들은 기존 연구와는 다르게 착시를 모델의 언어적 능력 관점에서 해석하는게 contribution이라고 했는데, 여기서 언어적이라는게 어떤 포인트라고 보면 되는것인지 궁금합니다. 단순히 분류나 회귀만 할줄아는 모델이 아니라 VLM을 평가해서다 라고 이해하면 되나요?
안녕하세요 현우님 좋은 답글 감사합니다.
맞게 해석하신 것 같은데 제가 생각해본 예시를 드리자면 두 색의 RGB 값의 차이가 존재하는가? 가 아닌 which ball is blue? 같은 방식으로 착시를 perception이 아닌 인간처럼 communication하는 형태로 이해하려고 한 부분 때문에 저자가 그렇게 주장한 것 같습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
end-to-end VLM과 vision encoder+LLM 구조에 경향성 차이가 있다는 점이 흥미롭네요. 해당 논문이 ‘인간과 기계가 같은 착시를 공유한다면, 언어적 소통이 어떻게 이루어지는지를 분석하는것이 핵심’이라고 하셨는데 이 언어적 소통이 무엇을 의미하나요? 해당 연구의 목적이 단순 비전 모델에서의 착시 분석과 어떤 점이 다른 건지 와닿지 않아서 질문드립니다.
감사합니다.
안녕하세요 예은님 좋은 답변 감사합니다.
위에 현우님 질문과 유사한 질문인데 기존의 착시 연구들이 모델이 착시에 영향을 받는지를 단순 분류 결과를 통해 판단 했다면 저자는 단순 perception이 아니라 언어 표현에도 영향을 주는지를 생각했고, 결과적으로 모델이 착시에 속느냐가 아니라 착시 상황에서 인간과 모델이 동일한 지각 기준을 공유하는지를 판단했다고 생각하면 될 것 같습니다.
감사합니다.
안녕하세요 인택님 좋은 논문 리뷰 감사합니다!
VLM 모델의 사이즈가 커질수록 인간과 같은 판단을 한다는 것이 신기하네요.. internet – scale로 학습을 진행하다 보니 human – bias가 생기는 것 같습니다.
글을 읽으면서 궁금했던 점은 그렇다면 과연 인간과 같이 실수를 하는 모델(?) 착시를 경험하는 모델을 만드는 것이 과연 좋은건지 의문입니다. VLM의 scale을 키워 표현력을 높여도 human – bias를 배워 인간과 같은 실수를 하거나 인간과 같은 부정확환 생각을 하게 된다면 저희가 바라는 인공지능 모델인지 궁금하네요!!
감사합니다!!
안녕하세요 인하님 좋은 답글 감사합니다.
이 논문이 사실 그 질문을 할 수 있게하는 시작점 같은데, 정확성 중심에서와 human-alignment관점에서 사람마다 생각이 다를 것 같습니다. 물론 모두를 이해할 수 있는 모델이 더 범용적이지 않을까 싶네요
감사합니다.
안녕하세요 인택님, 리뷰 재미있게 잘 읽었습니다.
논문에서는 착시에 대한 언어적 소통을 평가한다고 이해했는데, 단순히 생각했을 때 결국 머신은 이미지를 숫자로 인식하기 때문에 언어 소통이 아니라 내부 표현을 역추적해 보는 방안도 있을 것 같습니다. 혹시 이러한 접근에 대해서는 어떻게 생각하시나요?
안녕하세요 재윤님 좋은 답글 감사합니다.
VLM 이나 LLM 등의 내부 블랙박스로 여겨지던 부분들을, 단순 인지가 아닌 소통의 관점에서 어떻게 분석할 수 있을지는 조금 생각을 해봐야할 것 같습니다. 사실 해당 부분만 분석하더라도 새로 논문을 낼 수 있을정도의 contribution이 나올 것 같기는 한데, 아마 vision encoder 를 타고나온 영상 표헌들과 기존 LLM 들의 textual 표현들이 어떻게 상호작용하는지에 대한 분석을 해야할거라고 생각됩니다. 제가 좀 더 해당 쪽 논문을 읽어봐야 구체적으로 답변해드릴 수 있을 것 같네요 하하..
감사합니다.