안녕하세요, 2025 CVPR에 붙은 현재 인용 수 1인 따끈따끈한 논문을 소개해볼까합니다.

해당 논문이 풀고하는 문제는 GT가 없는 상황에서의 matching입니다.
위 그림을 보시면 알겠지만, multi-spectral뿐만 아니라, photo-Sketch처럼 sementic한 부분까지의 matching을 잘하기 위한 학습 방법을 제시합니다.
현재 제가 하고 있는 multi-spectral에서의 matching과 비슷하기도 하고, 대부분의 matching 학습은 GT가 있는 상황에서 학습을 시키는데(e.g. MAST3r, Superglue, RoMa 등등) GT가 없는 상황의 self-sup 방식의 학습이 궁금해서 찾아보게 되었습니다. 시작해보겠습니다.
Introduction
먼저 저자는 cross-modality에서의 문제를 잡고 시작합니다. pixel단위로 유사함을 측정할 수 있는 동일 modality와 다르게, cross-modality에서는 대응되는 pixel 위치여도 값이 다르기 때문에 비교가 불가능하다는 점입니다.
그래서 이 문제를 해결하기 위해서, Contrastive Random Walk(CRW)를 도입하였습니다.
CRW는 한 pixel이 대응되는 다른 이미지의 pixel로 갔다가, 돌아왔을 때 일치하면 정답, 그렇지 않으면 오답으로 loss를 주는 방식입니다.
그리고 modality가 달라서 visual patch가 일치하지 않고, 또 GT가 없는 상황에서 기하학적 관계까지 학습하게하는 것은 학습이 어렵습니다. 그렇기에 저자는 동일 modality상(intra modality)에서 random walk를 통해, model이 너무 엇나가지 않게 잡아두고, 궁극적으로는 다른 modality(inter modality)에서의 matching 관계를 학습시킵니다.
최종적으로 평가는 4가지 영역에서 진행합니다
- RGB-depth / RGB-Thermal (Geometric)
- Photo-Sketch / Cross style (Semantic)
특이한 점은 위 Geometric 평가 때는 backbone을 CNN 계열을 사용하고, Semantic 평가때는 DINOv2를 backbone으로 사용합니다. 이는 DINOv2가 Semantic한 부분에 강하기 때문이라고 생각됩니다. 그럼에도 CNN 기반의 backbone보다는 DINOv2가 geometric한 부분도 잘 잡아내지 않을까 싶기도한데, 이건 제 개인적인 생각입니다.
Method
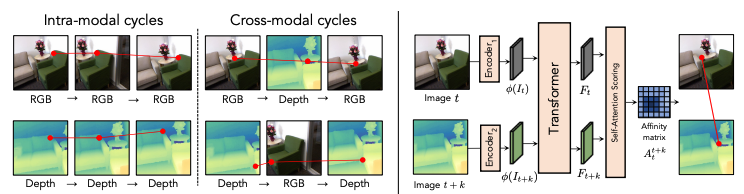
Global Matching Random Walk(GMRW) model을 도입해서 문제를 해결했습니다.
GMRW의 과정을 먼저 설명하자면
- 이미지 a, b의 feature embedding이 있을 때, dot product를 하여 affinity matrix(NxN)를 만듭니다.
- affinitiy matrix(NxN)에 row 방향으로 softmax를 취해 일종의 이미지 a가 b를 보는 attention map을 만듭니다.
- a가 b를 보는 attention map과 b가 a를 보는 attention map을 행렬곱하여, 이를 cycle 확률로 사용합니다.
즉, cycle 확률 행렬이 있으면, a에서 b로, 다시 b에서 a로 돌아오는 random walk 여부를 알 수 있습니다.
Cross-modal Transition Matrix
다시 논문의 method로 돌아와서, geometric(RGB-depth / RGB-Thermal) 때는 1/4로 downsampling된 ferature maping을 만들고, semantic(Photo-Sketch / Cross style) 때는 DINOv2로 feature embedding을 뽑습니다.
그리고 동일하게 positional embedding을 붙여, 6layer의 self-cross attenetion의 decoder(swin)를 통과시킵니다.
마지막 layer를 타고 나온 feature를 correlation features F^{m1}_t, F^{m2}_{t+k}라고 두겠습니다.
두 correlation feature들을 softmax를 취하면 (A^{m_1,m_2}_{t,t+k} = \text{softmax}(F^{m_1}_t (F^{m_2}_{t+k})^\top / \tau), modality m1 / 시간 t일때랑 modality m2 / 시간 t+k일 때의 likelihood를 나타냅니다. 이 행렬은 intra/inter matching에서 contrastive random walk때 이동 확률을 나타냅니다.
결국 하고싶은 것은 m1 modality의 patch의 위치를 얼마나 움직여서 m2 modality의 patch와 일치하는지를 평가하는 것이므로(flow, \Delta x, \Delta y), 아래와 같은 식을 통해 변화량을 구할 수 있습니다.
f^{m_1,m_2}_{t,t+k} = \mathbb{E}_{A_{t,t+k}}[A^{m_1,m_2}_{t,t+k} D - D]여기서 D는 patch의 위치 (x, y)입니다.
즉 A \cdot D를 통해 이동(walk)할 위치를 구하고, 원래 좌표랑 빼서 flow를 구할 수 있습니다
이건 개인적인 궁금증이였는데, LoFTR 등에서 쓰이는 dual-softmax가 Contrastive Random Walk(CRW)랑 dual-softmax랑 다른게 뭔지가 잘 이해가 안됐습니다.
수식적으로 보면, dual-softmax는 element-wise 곱셈이고, CRW는 matrix 곱셈입니다.
즉, 그래서 dual-softmax는 gradient가 i에 대응되는 j에만 흐르는 반면
CRW는 gradient가 기여도만큼 전체적으로 흐릅니다.
Learning Cross-modal Correspondences
Cross-modal cycle-consistency
결국 GT가 없는 상황이므로, cycleGAN처럼 cycle이 가능하냐를 supervision으로 사용합니다.
이를 위해 label-wrapping loss를 사용합니다
앞쪽 A는 이미지가 한 patch가 flow를 통해 이동했을때, 이동된 패치 기준으로 다시 돌아올 수 있는가를 얘기하는 행렬입니다. 그리고 뒤에 T_f^b(I)는 행렬을 그냥 identity matrix로 만들어버리면 loss를 떨굴 수 있기 때문에, 이미지를 약간의 wrap(random resize-crop)시킨 것을 label로 사용해 단순히 identiy matrix가 정답이 될 수 없게 만드는 규제화입니다.
Intra-modal cycle-consistency
아까 introduction에서 얘기했듯, 바로 다른 modality에서 flow를 학습시키는 것은 어렵습니다. 그렇기에 같은 modality에서의 loss를 추가하여 줍니다. 두 modality의 이미지를 각각 augmentation하여 loss로 사용합니다
L_{intra-crw} = \sum_{i=1}^2 L_{CE}(A^{mi}_{ori,aug} A^{mi}_{aug,ori}, \mathcal{T}_{\hat{f}}(I))Smoothness loss
flow 논문에서 많이 사용하는 loss입니다. flow가 튀는 것을 방지하기 위한 loss입니다. 자세히 다루지는 않겠습니다.
L_{smooth} = \mathbb{E}_p \sum_{d \in \{x,y\}} \exp(-\lambda_c I_d(p)) \left| \frac{\partial^2 f_{s,t}(p)}{\partial d^2} \right|Overall loss
그래서 전체 loss를 저 3가지를 전부 더하여 사용합니다
L_total = L_cross_crw+L_intra_crw+ \lambda_s L_smoothExperiments
학습 방식은 multi-spectral마다 다르게 학습되었습니다
Training Stage
- intra-modality에서 (이미지)-(augmented 이미지)로 학습 (i.g. RGB-augRGB + thermal-augThermal)
- cross-modality pair로 학습
- smooth loss를 추가하여 학습
Evaluation
RGB-Depth는 NYU dataset이 spatially aligned되어 있어서, point tracking method로 GT를 만들어주어 평가하였습니다.
RGB-Thermal은 Thermal-IM dataset은 manully annotate해주었고, KAIST는 aligned되어 있어서, NYU와 유사한 방법으로 GT를 만들어주었습니다.
Photo-Sketch는 GT가 존재하는 PSC6k dataset으로 평가했습니다.
Cross-style은 Flux text-to-image model로 imagenet dataset에서 blip으로 추출된 caption으로 생성되었습니다. 10가지의 style prompt(anime, dark, light, photorealistic, pixel art, watercolor, comic book, neon, pastel, and sci-fi)로 생성해주었습니다.
Geometric corresponsdence result
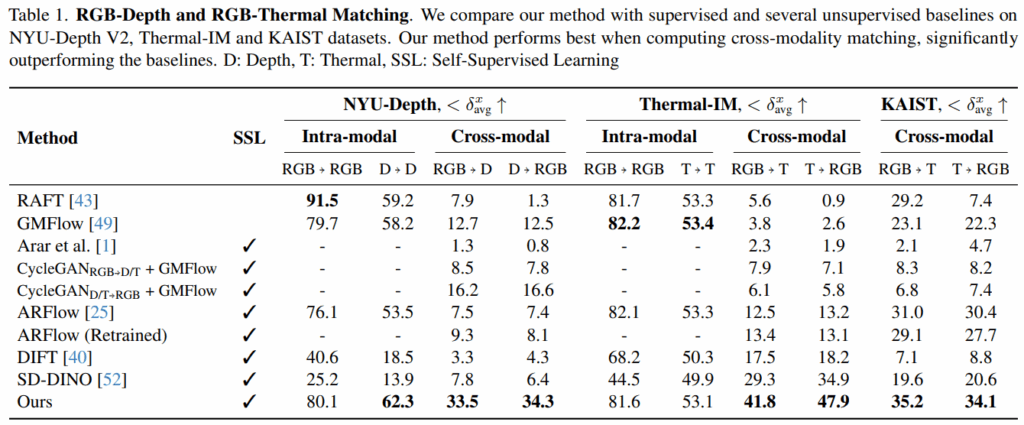
저자의 방법론이 intra-modality에서 GT가 있는 방법론과 유사한 수준까지 올라왔고, Cross-modality에서는 압도적인 모습을 보입니다.
GT가 필요한 RAFT나 GMFlow는 depth/thermal을 RGB인 것처럼 넣어줘서 평가했습니다. 그래서 CycleGAN으로 depth/thermal을 RGB로 그리고 vice versa로 실험도 진행해주었습니다.
그리고 figure를 통해, RAFT나 GMFlow가 noisy하거나 부정확한 match가 많은데 비해, 우리 방법론은 상대적으로 강건함을 주장합니다.


Semantic corresponsdence result
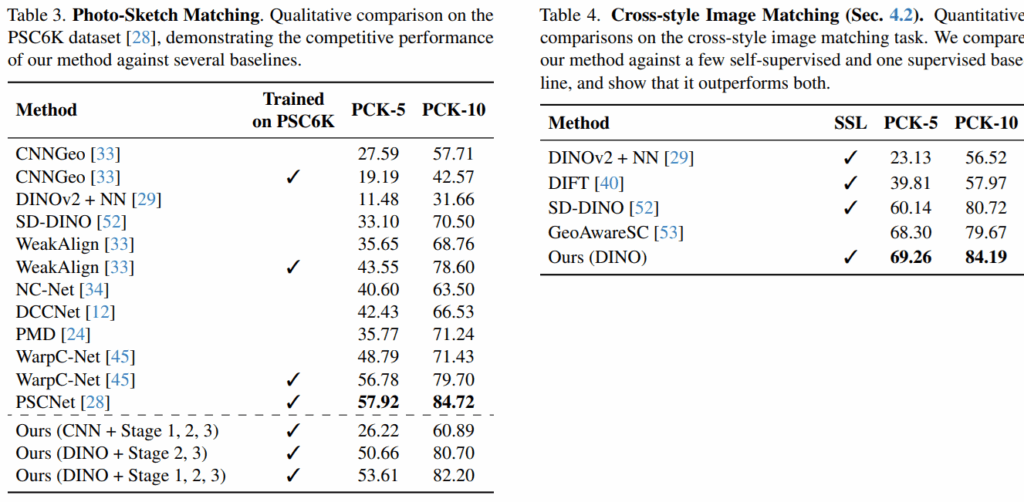
CNN기반의 방법론은 Semantic matching에서 약세임을 알 수 있습니다. 그리고 DINOv2+NN과의 차이를 통해 단순 DINOv2의 feature가 좋기 때문이 아닌 저자의 방법론을 통해 성능이 올랐음을 강조하고 있습니다.
또한 Photo-Sketch Matching에서는 stage1없이 학습을 하면, 약간의 성능 드랍이 있음을 보여주고 있습니다.
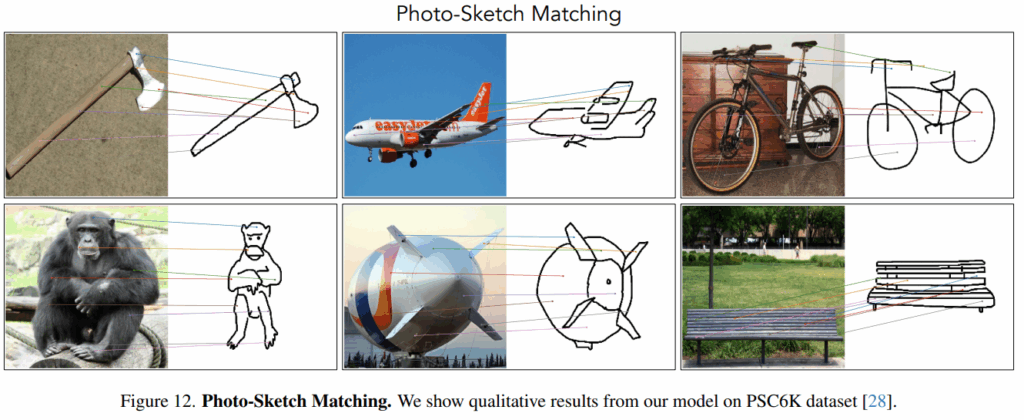
figure는 아래와 같습니다.

Ablation
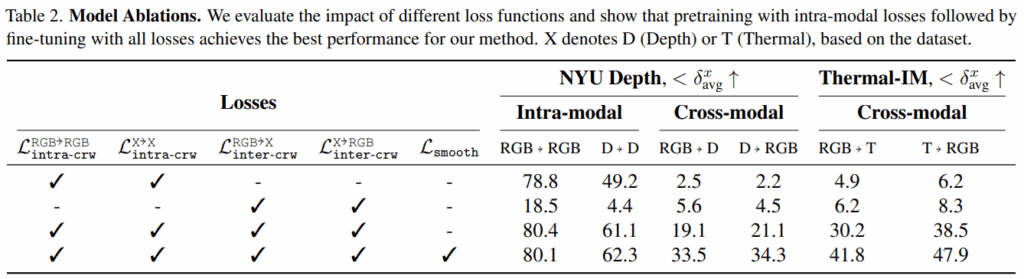
table2가 얘기하려는 건 두가지입니다.
- intra-modality는 필수적이다. 2번째 row에서 cross-modality 학습만으로는 성능이 처참한걸 확인할 수 있습니다. 그만큼 어려운 task기에 intra-modality 학습을 통해, 보조 수단이 필요하다는걸 증명했습니다.
- smooth loss는 꼭 필요하다 입니다. row3과 row4의 차이는 보면 cross-modaity에서 성능 차이가 많이 나는 것을 확인할 수 있습니다.
안녕하세요, 정우님. 좋은 리뷰 감사합니다.
“현재 인용 수 1인 따끈따끈한 논문”이라는 표현에 흥미를 느껴 읽어보게 되었습니다. Matching이라는 고전적인 computer vision 주제를 다루면서도, GT 없이 학습하는 self-supervised 방식으로 접근한 점이 인상 깊었습니다.
논문을 읽으며 몇 가지 궁금한 점이 생겼습니다.
1, Photo–Sketch와 같이 사진과 그림 간의 matching은 실제로 어떤 응용 분야에서 활용되는지 궁금합니다. 단순한 벤치마크 목적을 넘어, retrieval이나 cross-domain alignment 등 구체적인 downstream task에서의 활용 사례가 있는지 알고 싶습니다.
2. Table 1의 수치는 어떤 evaluation metric을 의미하는지 궁금합니다. 만약 accuracy 혹은 PCK 기반 지표라면, cross-modal setting에서 약 30% 수준의 성능이 실제 응용 관점에서도 충분히 의미 있는 수준인지 궁금합니다.
3. 본 방법이 global matching과 cycle consistency를 기반으로 한다는 점에서, 서로 초점 거리나 시점이 다른 동일 장면 이미지 간의 정합(예: panorama stitching)에도 확장 가능성이 있을지 궁금합니다.
다시 한번 좋은 리뷰 감사합니다.🖼️
안녕하세요 기현님 질문 감사합니다.
Q1. Photo-Sketch와 같은 matching이 실제로 사용되는지는 잘 모르겠습니다. 왜냐하면 이 논문이 사실상 처음 제시한 방향이기 때문입니다. DINOv2의 휼룡한 semantic extraction과 GT가 있을 수 없는 cross-modality를 CRW 방식을 통해 이런것도 가능하다~를 처음 보여주었습니다. 그래서 이 논문은 어떻게 dataset을 만들었는지에 대해 긴 부분을 할애해서 설명을 해주고 있습니다.
Q2. table1에서의 metric은 accuracy metric이 맞습니다. 예측값과 정답이 threshold 기준으로 얼마나 차이나는지를 나타내는 지표입니다. 물론 명확한 기준이 있는건 아니지만, 제 생각에는 아직 실사용에는 문제가 많은 정도라고 생각합니다. intra-modality와 50%가 넘는 성능차이를 보이기에 여전히 많은 문제가 남은 task라고 생각합니다.
Q3. 네 맞습니다. 애초에 GT가 없는 상황에서의 matching을 구하기 위한 방법론입니다. 당연히 matching쌍을 구한다면 정합은 바로 가능합니다. 하지만 RGB-RGB상에서는 이미 GT가 존재하는 데이터셋이 많기에 굳이 self-sup 방식의 필요성을 많이 못느껴서, 해당 논문 역시 Cross-modality에서의 self-sup 연구를 하지 않았나 싶습니다
감사합니다
안녕하세요 정우님 리뷰 감사합니다
GT없이 이미지가 rgb-thermal같이 다른 모달리티 간의 대응점을 해당 점이 갔다가 다시 돌아오면 맞다! 라고 하는 사이클 기반의 아이디어라고 이해했습니다.
method중간에 Cross-modal Transition Matrix 부분에서 CRW를 사용하는게 핵심인거 같은데 왜 CRW가 dual-softmax보다 구조적으로 적합한건지 잘 와닿지 않아서 질문 남깁니다! 해당 방법론 관점에서 좀더 쉽게 설명해주실수 있나요?!
안녕하세요 찬미님 좋은 질문 감사합니다.
dual-softmax는 softmax라는 sharp하게 만들어주는 연산을 통해서, 집중하는 영역이 아니면 다 무시됩니다.
그렇기에 gradient가 흘러야하는 입장에서는 self-sup 방식이기에 여러 가능성을 찾아가면서 정답을 찾아가야하는데,
dual-softmax 방식으로는 이미 모델이 확신해버린 부분 말고는 다른 부분에 대한 학습을 하기가 어렵습니다.
그렇게 단순 행렬곱으로 이루어진 CRW 방식을 통해, 다양한 가능성을 열어두면서 학습을 하는 방식을 사용했다고 생각하시면 될것 같습니다.
감사합니다
안녕하세요 정우님 좋은 리뷰 감사합니다.
cross-modal transition matrix에서 쓰는 decoder의 역할이 중요한 것 같은 생각이 듭니다. 제가 잘 이해했는지는 모르겠지만 단순히 backbone feature dot product로도 CRW를 돌릴 수 있을 텐데 decoder가 성능을 얼마나 끌어올리는지 없으면 얼마나 떨어지는지에 대한 어블레이션이나 저자의 언급이 있었는지 궁금합니다. 감사합니다.
안녕하세요 우현님 좋은 질문 감사합니다.
질문을 듣고 나니 저도 의문이 들어 생각을 해봤습니다.
일단 decoder가 꼭 필요한 이유는 결국 Cross-attention이 decoder에 들어가있기 때문입니다.
둘의 관계를 파악하는 affinity matrix를 잘 뽑기 위해서는 self-cross attention으로 둘의 관계를 잘 modeling해야 CRW를 제대로 학습할 수 있다고 봅니다.
저 decoder는 GMFlow부터 이어진 전통(?) 있는 방식이여서, 당연한듯이 저자도 사용했습니다.
Decoder랑 CRW 없이 단순 NN(최근접 이웃) 방식으로 matching을 평가한 방식은 실험이 있지만
decoder없이 CRW를 적용한 실험은 없습니다.
감사합니다