안녕하세요 오늘은 로봇 데이터에 관한 논문을 가지고 왔습니다. NVIDIA에서 제시한 DreamGen이라는 방법론입니다. VLA를 보면 볼 수록 아무래도 데이터의 갯수가 많지 않다보니까 특정 데이터에 편향되는 모습을 보이는 것 같다는 생각이 들었는데 이런 문제들을 로봇 데이터 증강을 통해서 어떻게 풀어냈을지 궁금해서 리뷰해보게 되었습니다.

- Conference: arXiv 2025
- Authors: Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, Loic Magne, Ajay Mandlekar, Avnish Narayan, You Liang Tan, Guanzhi Wang, Jing Wang, Qi Wang, Yinzhen Xu, Xiaohui Zeng, Kaiyuan Zheng, Ruijie Zheng, Ming-Yu Liu, Luke Zettlemoyer, Dieter Fox, Jan Kautz, Scott Reed, Yuke Zhu, Linxi Fan
- Affiliation: NVIDIA; University of Washington; KAIST; UCLA; UCSD; CalTech; NTU; University of Maryland; UT Austin
- Title: DREAMGEN: Unlocking Generalization in Robot Learning through Video World Model
1. Introduction
기존의 로봇 학습을 위한 데이터는 인간 원격 조작 데이터로 수집이 되었지만 이러한 패러다임은 새로운 작업과 환경마다 원격 조작 데이터를 수동으로 수집해야 되며 이 과정에 많은 비용이 들기도 하고 데이터 수집을 하는 노동이 힘들기도 합니다. 물론 시뮬레이션 합성 데이터라는 방식도 있긴 하지만 해당 논문에서 말하는 바로는 sim2real의 간극으로 어려움을 겪고 있기 때문에 이러한 점을 해결하기 위해서 최소한의 수동 작업 또는 엔지니어링으로 현실적인 훈련 데이터를 대규모로 생성하기 위해 비디오 월드 모델을 활용하는 새로운 합성 데이터 파이프라인인 DREAMGEN을 제안한다고 합니다.
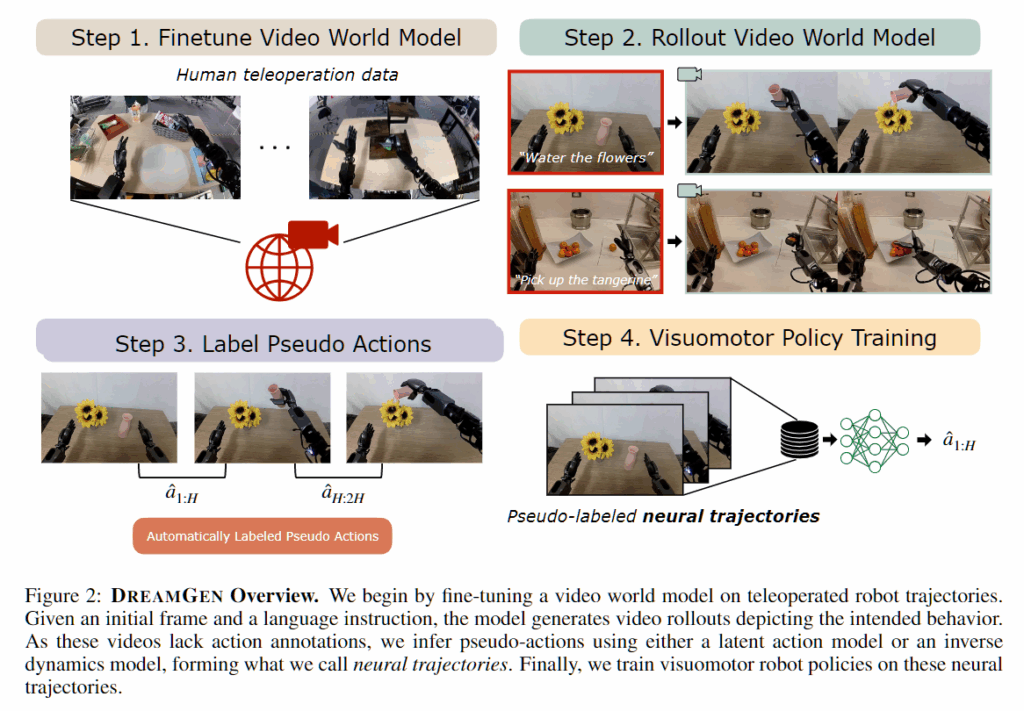
DREAMGEN은 최첨단 비디오 생성 모델인 비디오 월드 모델을 적용해 합성 훈련 데이터를 생성하는 4단계로 구성되어 있습니다. 해당 파이프라인은 특정 로봇, 환경, 작업이 아니라 범용적으로 사용될 수 있도록 설계되어 있다고 합니다. 4단계의 대략적인 동작 과정은 아래와 같습니다.
- 데이터 생성을 위한 특정 로봇의 dynamics와 kinematics를 포착하기 위해서 대상 로봇을 가지고 월드 모델을 미세조정합니다.
- 초기 프레임 쌍과 언어 지침으로 모델을 프롬프트해서 로봇 비디오를 대량으로 생성하고 이 비디오 생성 모델은 미세 조정을 하였기 때문에 익숙한 동작과 보지 못한 설정에서 새로운 동작을 포착?하는 능력을 가지고 있다고 합니다.
- latent action model 또는 inverse dynamics model(IDM)을 사용하여 의사 행동이라고 하는 pseudo-action을 추출합니다. 이 과정을 한마디로 설명드리자면 영상에서 무슨 동작을 하고 있는지 잠재적인 값들을 뽑아낸다 라고 보시면 될 것 같습니다.
- 마지막으로 이전 단계에서 추출한 pseudo-label을 통해 의사와 action 시퀀스가 쌍으로 이루어진 뉴럴 트랙토리 데이터를 사용해 로봇의 지시를 실제로 사용할 수 있도록 한다고 합니다.
이전 연구들에서는 비디오 월드 모델을 real-time planner로 두었지만 DREAMGEN은 이를 합성 데이터 생성기로 사용하면서 물리적 추론과 자연스러운 모션 및 언어 기반을 위한 강력한 사전 지식으로 활용한다고 합니다.
이를 활용한 실험 과정에서는 RoboCasa 벤치마크를 최대 333배까지 확장할 수 있다고 하고, 다양한 로봇과 작업에서 작업당 10개에서 13개의 실제 궤적을 사용했음에도 불구하고 대부분 기존 성능에서 1.5배 정도 향상된 수치를 보여준다고 합니다.
또한 DREAMGEN이 가능하게 한 두 가지 핵심 일반화 능력인 **행동 일반화(behavior generalization)와 환경 일반화(environment generalization)**이 가능해졌다고 합니다. 행동 일반화의 경우 GR1 휴머노이드가 실행 가능한 22가지의 새로운 행동을 원본 조작 데이터셋 pick and place만 가지고 실험을 진행했다고 하고, 환경 일반화에서는 10개의 새로운 환경의 초기 프레임을 프롬프트로 제공해서 단일 환경의 단일 작업에 대한 데이터만으로도 새로운 행동과 환경에 대한 일반화를 보였다고 합니다. 이를 통해서 단순히 pick and place 만으로 학습된 GR00T N1은 대부분의 새로운 행동 및 환경 실험에서 0%의 성공률을 달성하는 반면, DREAMGEN은 기존 환경에서 새로운 행동에 대해 43.2%, 완전히 새로운 환경에서 28.5%의 성공률을 가능하게 하였다고 합니다.
이외에도 DreamGen Bench를 제시했다고 하는데, 이 부분은 뒤에서 설명드리겠습니다.
2. DREAMGEN
그러면 이전에 간단히 4단계로 나누어서 설명드렸던 부분에 대해서 자세히 하나씩 설명드리도록 하겠습니다.
2.1 Video World Model Fine-tuning
이 부분은 이전에 4단계로 나누었던 부분 중 1단계에 해당하는 부분으로 모델이 기존에 대량으로 학습된 지식에 현재의 로봇에 대한 human teleoperation 데이터를 통해 물리적인 제약과 움직임 능력을 학습하는 fine tuning 과정이 됩니다.
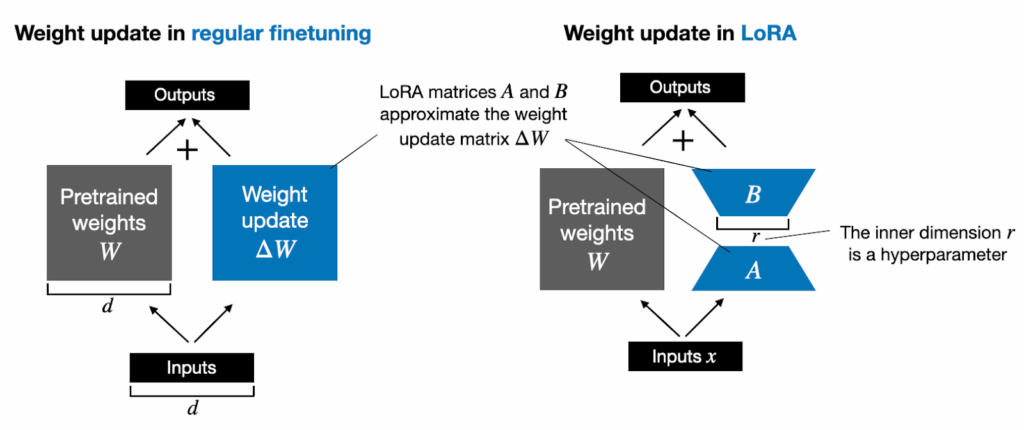
이때 fine tune 과정에서 기존의 인터넷 비디오를 가지고 대량으로 학습한 지식을 잊어버리는 것을 막기 위해서 LoRA를 활용해서 기존 가중치를 직접 업데이트하지 않고 low-rank의 행렬만 추가로 학습하는 방식으로 진행한다고 합니다.
모델을 미세조정할 때 로봇 도메인에 최적으로 적응되었는지 확인하기 위해 지시 따르기(instruction following)와 물리 따르기(physics following)라는 두 가지 지표를 중점적으로 본다고 합니다. 이 부분에 대해서는 섹션 4에서 자세히 다루도록 하겠습니다.
downstream robot 실험에서는 WAN2.1을 기본 비디오 월드 모델로 사용한다고 하고, 훈련 데이터셋에 여러 시점이 있는 경우 2 x 2 그리드로 연결해서 비디오 월드 모델을 미세조정 한다고 합니다. (비어있는 하나의 그리드는 검은색 픽셀로 구성한다고 하는데 이는 아래 사진처럼 구성된다고 보시면 될 것 같습니다)

2.2 Video World Model Rollout
비디오 월드 모델을 fine tuning한 후에는 다양한 초기 프레임과 언어 지침을 사용하여 합성 로봇 비디오를 생성한다고 합니다.

새로운 환경의 초기 프레임도 사용하지만, 비디오 월드모델의 훈련에서는 단일 환경에서 수집된 프레임으로 제한한다고 합니다. 이후 행동 일반화 실험을 위한 새로운 행동 프롬프트를 수동으로 만들고, 비디오 벤치마크에 이 후보들을 포함시킵니다.
2.3 Pseudo Action Labeling
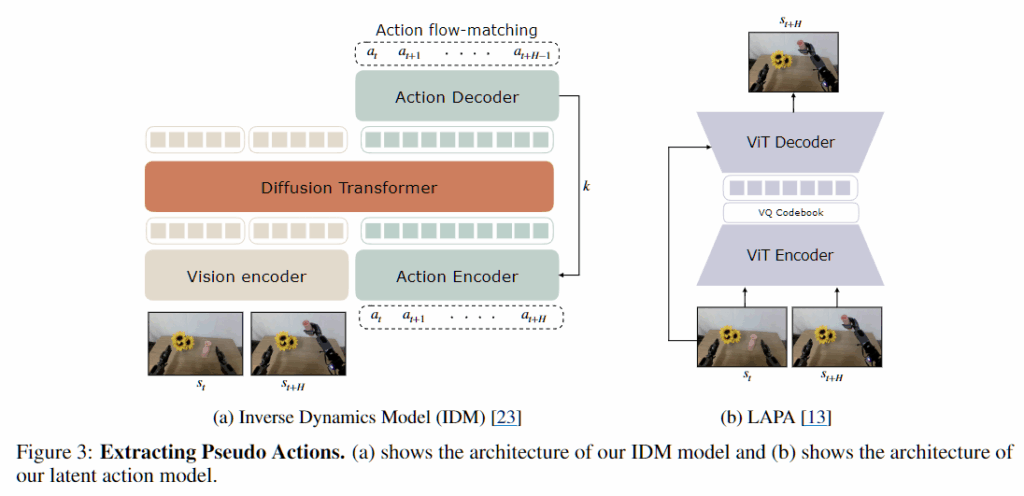
IDM Action
Vision encoder를 SigLIP-2로 사용하는 확선 트랜스포머를 사용하고 flow matching 목적 함수로 학습합니다. IDM은 두 개의 이미지 프레임에 조건화되며, 이미지 프레임 간의 action chunk를 예측하는 것이 목적입니다. 해당 모델은 로봇의 동역학 포착이 목적이기 때문에 언어와 같은 것을 명시적으로 사용하지 않고 VA와 유사한 방식으로 비디오가 주어지면 액션을 하나하나 뱉는 형태로 구성되는 것 같습니다. IDM 모델 학습에는 월드 모델 학습에 사용된 것과 동일한 데이터셋을 사용하고, 추론 과정에서 액션을 H개를 예측합니다.
Latent Actions
잠재 액션인 latent action에서는 트랜스포머 인코더와 디코더의 형태를 가지며 다양한 로봇 및 인간 비디오에 대해 학습된 LAPA 모델을 사용한다고 합니다. 해당 모델의 목적은 두 프레임(현재 프레임과 1초 뒤의 미래 프레임) 간의 시각적 delta 정보를 포착할 수 있도록 하는 것이 목적이기 때문에 VQ-VAE 목적 함수로 학습되고 잠재 액션을 예측하는 과정을 진행하게 됩니다. 잠재 액션은 GR00T N1에서 사용된 방식과 유사하게 미리 양자화된 연속적인 임베딩 형태로 사용된다고 합니다.
2.4 Policy Training on Neural Trajectories
해당 단계에서는 이미지 관찰과 언어 지시를 보고 Neural Trajectories에서 배운대로 가상의 동작, LAPA 혹은 IDM의 출력을 생성하도록 훈련됩니다. 쉽게 설명하자면 이미지 관찰과 언어 지시를 통해 Video World Model로 영상을 만들고 여기서 LAPA 혹은 IDM으로 액션을 만들어낼 수 있도록 하는 훈련 데이터를 만드는 과정을 Neural Trajectories를 만들게 되는데, 이를 Visuomotor Policies(일반적으로 아는 DP, pi zero, GR00T N1이 될 수 있음)에서 이를 통해 이미지 관찰과 언어 지시를 보고 실제 움직임을 결정하는 방법을 학습하게 됩니다. 신경 궤적의 상태 정보 같은 경우에는 성능에 악영향을 미치지 않음을 실험을 통해 확인하고 0으로 조건화한다고 합니다.
3. Experiments
실험에서 집중해서 보아야 할 부분은 크게 3가지 부분이라고 합니다.
- 기존 작업에 대한 훈련 데이터 증강
- 새로운 동작으로의 일반화 지원
- 새로운 환경으로의 일반화 지원
3.1 Training Data Augmentation
시뮬레이션 실험은 RoboCasa 벤치마크, 실제 실험은 GR 1휴머노이드 로봇, Franka arm robot, SO-100 구현체에서 9가지 실제 작업을 진행한다고 합니다.
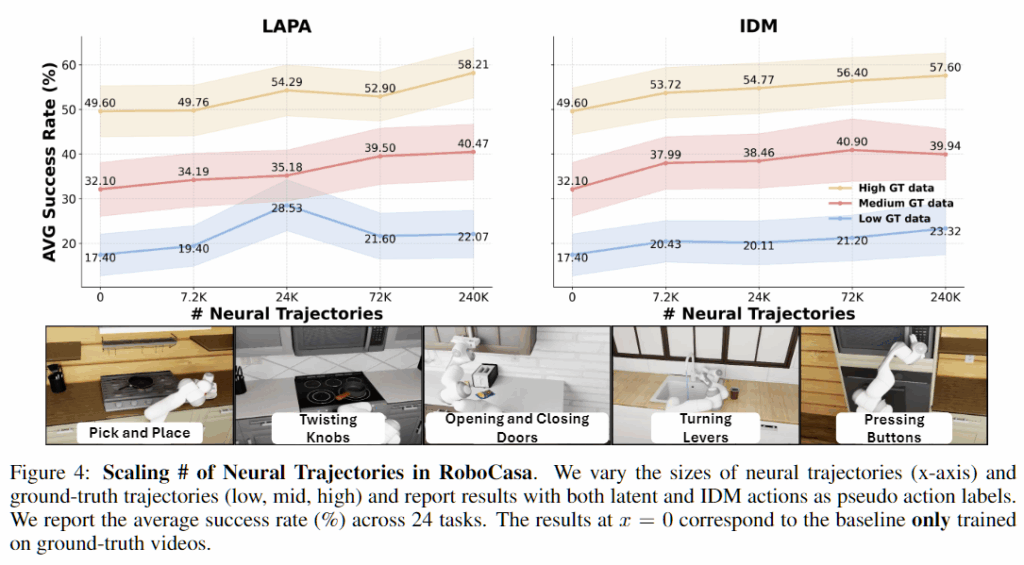
Simulation experiment
결과적으로 LAPA를 사용하거나 IDM을 사용해도 해당 논문에서 제시한 방식으로 생성한 신경 궤적의 총 갯수를 확장함에 따라 로봇의 정확도가 강력해지는 것을 볼 수 있습니다. 여기서 GT는 사람이 수집한 데이터를 의미하고, 결과적으로 사람이 수집한 데이터의 갯수도 720, 2.4k, 7.2k 개로 증가할 수록 Neural Trajectories도 크게 영향을 받는 것을 볼 수 있습니다. LAPA와 IDM을 비교하였을 때는 일부 구간을 제외하고는 IDM을 사용하는 것이 더 효율적이라고 논문에서 판단해서 나머지 실험에서는 IDM을 기준으로 사용하여 실험합니다.
Real-world Experiments
Real-world에서의 실험을 위해서 네 가지 GR1 작업과 세 가지 Franka 작업에 대해 작업당 100개의 궤적을 수집하고 SO-100의 딸기 따기 및 놓기 작업에 대해 40개의 궤적, 틱택토 작업에 대해 50개의 궤적을 수집하고, 이에 대한 평가 기준표를 만들어서 작업의 세부 부분마다 소수점 두번째 자리까지 배점표를 만들었다고 합니다.
데이터 효율성을 위해 수집된 궤적의 10%, 25% 정도를 사용하고, Neural Trajectories와 실제 궤적을 co-train하기 위해 1:1비율로 신경 궤적을 생성했다고 합니다.
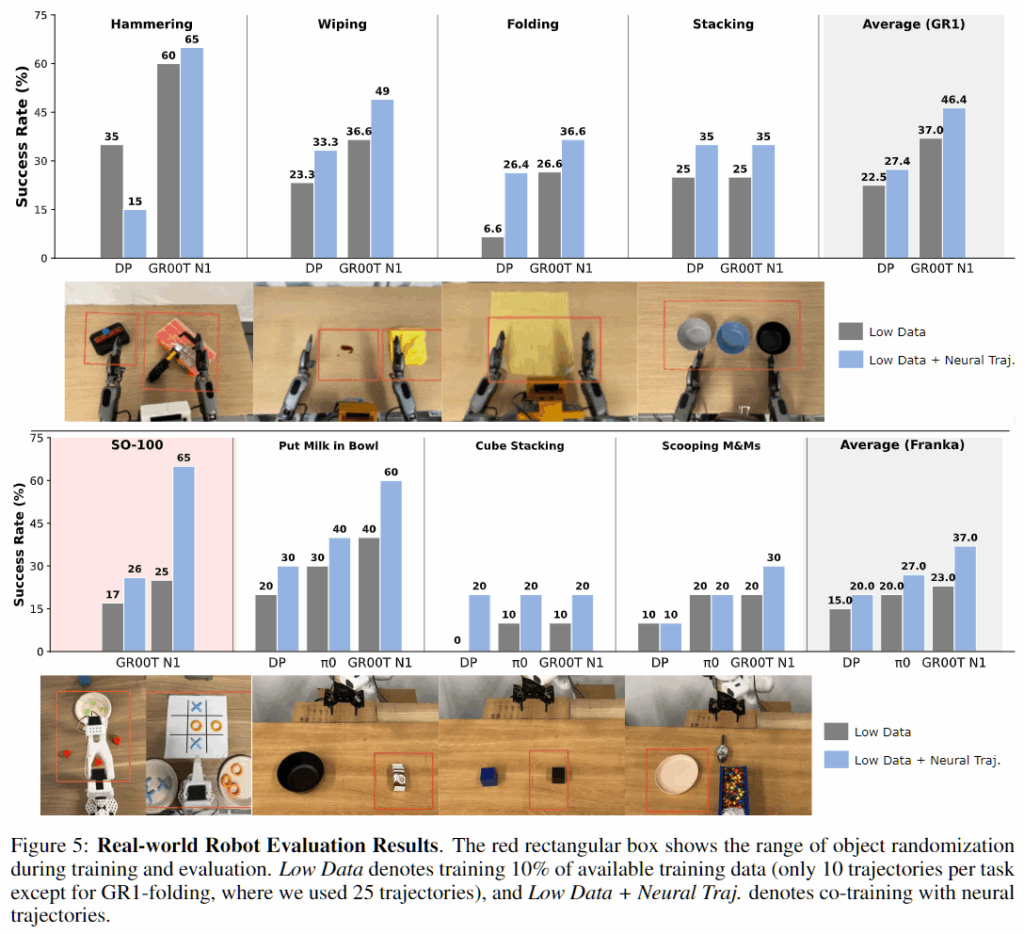
성능 지표를 보면 전체적으로 성능 향상을 보여주면서 대부분의 로봇 학습 방법에 대해서 데이터 증강을 통해 성능 향상을 이룰 수 있다고 주장하고, 시뮬레이션과 다르게 물리적인 특성을 현실과 맞추어줄 필요없이 거의 스스로 합성 데이터를 생성하기 때문에 이런 부분에서 좋아 보이는 것 같고, 특히 GR00T N1에서 더 높은 성능 향상을 관찰한다고 합니다.
3.2 Unlocking Generalization
해당 파트에서는 로봇 학습에서 DREAMGEN이 일반화 능력을 어떻게 확보할 수 있는지 확인하도록 합니다. GR1 휴머노이드가 다양한 물건 집기 및 놓기 동작을 수행하는 2884개의 궤적에 대해 목표 비디오 월드 모델을 학습시키고, (1) 알려진 환경에서의 새로운 동작과 (2) 새로운 환경에서의 알려진 및 새로운 동작으로 모델을 프롬프트하여 신경궤적을 생성합니다. 일반화에 대해서는 아래의 그림의 수준으로 객체나 환경을 변경하여 실험을 진행하고, GR00T N1을 기본 정책으로 사용합니다.


Behavior Generalization
해당 부분의 목적은 인간의 원격 조작 없이 Neural Trajectories만으로 로봇이 완전히 새로운 동작을 학습할 수 있는지 확인하는 것이 목적입니다. 결과적으로 초기 프레임과 언어 지시만으로도 비디오 월드 모델이 완전히 보지 못한 동작의 비디오를 생성하는데 일반화할 수 있다고 합니다. 결과적으로 기존 GR00T N1은 11.8%의 성공률을 가져오지만, Neural Trajectories를 사용하니 43.2%의 성능을 보이며 완전히 새로운 동사를 학습할 수 있음을 보여준다고 합니다.
Environment Generalization
해당 과정을 평가하는 과정에서는 video world model이 일반화되어 있어서 완전히 새로운 환경의 초기 프레임으로 프롬프트되었을 때 매우 사실적인 로봇 비디오를 생성하면서 학습한 운동학을 잘 구사하고 있다고 합니다. 기존의 GR00T N1은 0%의 성능을 보이지만 DREAMGEN을 같이 사용하면서 28.5%로 향상된 모습을 볼 수 있었습니다. 기존에 pi 0.5와 달리 실험실 설정을 넘어서 물리적 데이터 수집을 하지 않았다고 합니다. 즉 실험실 안에서도 어디서든 동작한 Neural Trajectories를 생성해서 학습을 진행하면 다양한 환경에 대해서 일반화를 가지고 있다는 공간적 제약을 벗어날 수 있다는 획기적인 실험과 결과를 보여주었다고 생각되었습니다.

4. DreamGen Bench: A Video Generation Benchmark for Robotic
월드 모델링 벤치마크인 DreamGen Bench를 제시하였다고 하였으며 (1) 지시를 잘 따르는지(Instruction Following, IF) (2) 물리학적으로 잘 움직이는지(Physics Alignment, PA)를 평가할 수 있도록 되어 있다고 합니다.
IF같은 경우에는 Qwen VL 2.5와 같은 VLM 모델을 사용해서 명령을 비디오가 잘 따랐는지 0또는 1로 반환할 수 있도록 한다고 합니다. PA는 비디오가 얼마나 물리적으로 그럴 듯 한지, 물리 법칙 준수를 평가하도록 훈련된 VLM을 사용해서 0에서 1사이의 점수를 부여한다고 하고, VideoCon-Physics가 멀티뷰 비디오나 다양한 로봇 환경에 대해 충분히 훈련되지 않았을 수 있다는 점을 고려하여, Qwen-VL-2.5와 같은 일반 VLM을 사용하여 물리 법칙 준수에 대한 추가적인 평가를 수행하도록 한다고 합니다.
평가를 하는 프롬프트는 아래와 같다고 합니다.


이 부분에서는 평가를 중점적으로 제시하고 있기 때문에 이 정도만 설명하고 넘어가도록 하겠습니다.(궁금하신 점은 댓글로 받겠습니다.)
6. Conclusion
결과적으로 합성 비디오를 생성하고 의사 행동(pseudo-actions)을 추출함으로써 수동 시연에 의존하지 않고 visuomotor policies을 학습할 수 있게 합니다. 이를 통해서 기존 작업을 증강하면서 보지못한 환경에서 완전히 새로운 행동을 학습할 수 있는 능력을 로봇에게 제공해줄 수 있다고 합니다.
7. Limitation
해당 논문에서 제시한 방법론으로 실험한 단계에서는 크게 복잡한 실험을 하지 않았기 때문에 이런 점에 대해서 비디오 월드 모델을 더 넓은 범위에서 학습시키면 더 다양하고 숙련된 동작에 대해서 일반화를 개선시킬 수 있다고 합니다.
또한 컴퓨팅 자원을 많이 먹기 때문에 컴퓨팅 자원을 줄이는 방법에 대해서도 고안해야 된다고 말하고 있습니다.
GiHyeon 피셜 정리 Part
추가적으로 제가 생성된 영상들을 보고 좀 정성적으로? 조사한 자료를 기반으로 설명드려보고자 합니다.


우선 전자레인지 문을 닫는 동작입니다. 손가락이 물리적으로 겹치긴 하지만 Real Robot Execution을 보면 안정적으로 수행하는 모습을 확인할 수 있었습니다.
다음으로는 환경에 대한 강건성인데 이 부분에서도 연구실 환경이 아님에도 불구하고 이러한 영상을 생성하고 안정적으로 수행하는 모습이 인상적으로 보였습니다.

그리고 환경과 객체에 대해서 변화시키고 강건성을 테스트 하는 모습입니다.

보시다시피 물을 붓는 모습에 대해서도 별도의 물리적 학습을 시키지 않아도 일반화가 잘 되어있기 때문에 Sim과 같이 부자연스러운 모습이 아니라 비교적 자연스러운 모습을 보여주는 것을 볼 수 있습니다.
마지막으로는 wrist cam에 대해서도 강건한지 확인하고 싶어서 점검한 자료입니다.

CogVideo같은 생성의 경우에도 잘 생성은 하지만 갑자기 화면이 뒤틀린 모습?을 확인하였습니다. 그러나 Cosmos SFT는 안정적으로 동작하는 Wrist Cam View를 만들어냈습니다. 이를 통해서 DreamGen이 실제 로봇 데이터의 Wrist Cam에 대해서도 생성할 수 있지 않을까? 라는 생각이 들었습니다.
해당 논문을 보면서 궁금한 점은 Neural Trajectories가 많이 생성되서 특정 부분에서 동작하는 것이랑 똑같이 생성되어서 성능이 나온것인지, 이를 통해서 일반화가 된 것인지 궁금해졌고, SO-100에 대해서 Wrist Cam을 적용하면 어떻게 될지 궁금해졌습니다. 그리고 성능 지표에서 GR00T N1이 0이 나온 경우를 보았는데 GR00T N1 자체가 일반화가 안 좋은 것인지, DREAMGEN가 일반화에 좋은 이점을 준 것인지 이런 부분은 GR00T N1의 후속 모델인 1.5와 1.6을 보거나 직접 실험을 해봐야 알 수 있을 것 같다는 생각이 들었습니다.
이런 실험을 보고 리소스가 많이 들어도 로봇 일반화를 위해서 이런 방식이 필요한지 지금 진행하고 있는 Xlerobot에 적용해볼 수 있으면 해보고 싶다는 생각을 하게 되었고, 로봇 데이터 증강이 일반화에 진짜 유리한지 추가적인 리서치를 통해서 알아보아야 겠다는 생각이 들었습니다.


긴 리뷰 봐주셔서 감사합니다!
안녕하세요 기현님 리뷰 감사합니다.
DreamGen 파이프라인을 SO-101에 옮겨보고 싶으시다고 말씀해주셨는데, 해당 파이프라인을 다른 embodiment로 옮길 때 발생하는 문제점들은 뭐가 있을까요? 또 결국엔 video 모델을 finetuning 해야할텐데, 실제로 teleop 데이터를 취득하는것과 video 모델 finetuning용 데이터를 수집하는것에 cost 차이는 어떻게 될 것 같은지 의견도 궁금합니다!
안녕하세요 영규님 댓글 감사합니다.
우선 embodiment에 대한 부분은 논문에서 로봇에 맞는 dynamics로 fine tune하면 된다고 제시되어 있듯이 크게 문제가 없을 것으로 생각이 되었습니다. 다만 한 가지 우려되는 점은 로봇의 베이스가 움직이는 장면에 대해서는 video world model을 사용하지 않은 것으로 보였습니다. 그래서 아직까지는 base가 고정된 환경에 초점을 맞추어서 데이터 증강을 해야 된다고 생각되었습니다.
그리고 데이터를 수집하는 과정 자체에는 확실히 적은 cost가 들 것이라고 생각됩니다. 객체 위치를 계속 바꿔가면서 다른 위치인지 점검하지 않아도 되고, 환경을 변화시키지 않아도 생성이 가능하고, 이에 반해서 인간 조작은 최소로 들기 때문에 적은 cost로도 많은 데이터를 획득할 수 있는 방법론이라는 생각이 드는 것 같습니다
질문 감사합니다!
안녕하세요 기현님 좋은 리뷰 감사합니다.
IDM은 두 프레임에 조건화되어 action chunk를 직접 예측하고, Latent Action은 두 프레임 간의 시각적 delta 정보를 VQ-VAE 기반으로 잠재 액션 형태로 학습하는 것으로 이해했습니다.
이 두 방식이 각각 로봇의 동역학 포착과 시각적 delta 표현이라는 서로 다른 강점을 가지는 것 같은데, IDM Action과 Latent Action의 장점을 결합하여 공동으로 활용하거나 학습하는 방향은 고려되지 않았는지 궁금합니다.
감사합니다.
안녕하세요 의철님 댓글 감사합니다.
우선 논문에 대해서 매우 잘 이해를 해주신 것 같습니다. 저도 IDM과 Latent Action의 장점을 결합하면 어떨까 라는 생각이 들었습니다. 근데 이 부분에 대해서는 논문에서 따로 실험을 진행한 것 같고, 전체적으로 성능 자체도 IDM이 더 좋았다고 하고 있습니다. 액션에 대한 이해를 더 명확히 하였다고 기억을 하고 있어서 물리 세계에서 적용하기에는 시각적 표현에서는 아무래도 한계가 존재하기 때문에 IDM만 사용하는 편이 더 좋다고 느껴집니다
질문 감사합니다!