안녕하세요. 이번에 리뷰할 논문은 RAL 2022년에 올라온 Socially CompliAnt Navigation Dataset (SCAND) A Large-Scale Dataset of Demonstrations for Social Navigation 이라는 데이터셋 논문입니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
먼저 해당 논문은 제목에 나와있듯이 Socially CompliAnt Navigation Dataset (SCAND)를 제안한 논문입니다. socially Compliant Navigation이라고 하면 자율적으로 움직이는 에이전트가 사람이나 혹은 다른 에이전트가 있는 환경에서 사회적으로 준수학게 이동하는 그런 능력이라고 합니다. 근데 여기서 사회적으로 준수한다는게 단순하게 충돌만 안나면 오케이 수준이 아니라 사람이나 다른 이동 주체의 의도나 규칙(우/좌측통행)과 같은 요소를 같이 고려하면서 경로나 속도를 조절하는 능력이라고 보시면 좋을 것 같습니다. 그리고 또 여기에 논문에서 언급한 부분이 하나가 더 있는데 에이전트가 단순히 피하는 것뿐 아니라 상대가 내 움직임을 예측하기 쉽게 신호를 준다는 projection이라는 개념이 들어가 있습니다. 결국 내가 어디로 갈지 상대가 알아챌 수 있게 움직임을 만들라는 얘기 인데 갑자기 확 꺾는게 아니라 미리 속도를 줄이면서 옆으로 빠진다든지 이런식으로 상대가 대응하기 쉬운 행동을 한다정도이지 않을까 생각이 듭니다.
기존 데이터셋은 크게 real world에서 수집된 데이터 셋들과 시뮬레이션 기반 데이터셋들이 존재합니다. 근데 저자들은 기존 데이터셋들이 로봇과 인간의 기본적인 trajectory는 제공하긴하지만 실제로 우리가 관심있는 in the wild에서 사회적 상호작용이 충분히 담겨져있지 않다는 문제를 언급합니다. 특히 기존 real world 데이터 셋 같은 경우에는 통제된 환경(연출된 환경)에서 제한된 상호작용만 포함하거나 실내 내비게이션 시나리오만으로 한정되는 경우가 많다고 합니다. 이런 통제된 조건에서는 국가별 차선 규칙따르기나, 도로 횡단과 같은 상황에서 발생하게 되는 사회적 상호작용이 많이 담길 수가 없다고 하고 또 추가적으로 지적하는 건 기존 데이터셋들에서 로봇이 데이터를 수집할 떄 보통 Point-to-point 내비게이션을 위한 단순 컨트롤러로 움직이는 경우가 많았고 해당 컨트롤러는 사회적 상호작용이 반영된 내비게이션을 보여주지 못한다고 합니다. 그리고 최근에는 모방학습이 모바일 로봇 내비게이션 컨트롤러를 설계하는데 있어서 많이 활용이 된다고 합니다. 하지만 저자들은 이런 모방학습에 활용할 수 있는 in the wild에서 수집된 대규모 사회적 내비게이션 데이터셋은 여전히 부족하다고 언급하면서 이런 부분을 해소하기 위해서 SCAND라는 데이터셋을 만들었다고 합니다.

해당 데이터셋 같은 경우에는 사람이 텔레오퍼레이션으로 수행하는 내비게이션 시연 8.7시간을 포함하고 Velodyne LiDAR, 오도메트리, 카메라 영상, IMU 정보를 서로 다른 두 종류 모바일로봇 Clearpath Jackal과 Boston Dynamics spot에서 텍사스 대학교 오스틴 캠퍼스 내에서 수집했다고 합니다. 총 25마일(약 40km), 138개 궤적으로 구성되어있으며 각 궤적마다 자연스럽게 발생할 수 있는 사회적 상호작용에 대한 라벨 태그도 함께 포함되는데 이는 뒤에서 자세하게 설명드리도록 하겠습니다.
Related Work
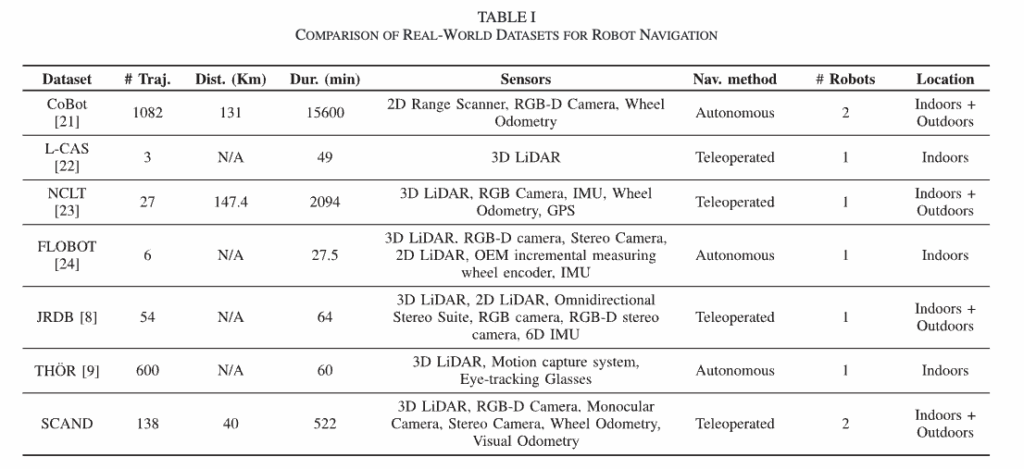
SCAND 이전에도 로봇 내비게이션을 위한 실제 환경 데이터 셋이 연구가 많이 되어왔습니다. L-CAS, FLOBOT, NCLT 같은 경우도 LiDAR 스캔, RGB-D 양상, GPS, IMU 데이터를 포함하긴 하지만 내비게이션에서의 perception 관련 과제를 다룬다고 합니다. 특히 JRDB라는 데이터셋이 SCAND 연구와 가장 가깝긴하지만 규모가 작기도 하고 마찬가지로 초점이 인간 추적이나 탐지 같은 perception 관련 문제를 해결하는데 집중이 된 데이터셋이라고 합니다. 반면 SCAND는 내비게이션 자체를 다루는데 초점을 뒀다고 하네요.
THÖR 데이터셋 같은 경우는 tracking helmets을 사용해서 로봇의 이동 궤적을 제공한다고는 하지만 마찬가지로 규모가 작고, 작은 실내 실험실에서 연출하여 수집한 데이터셋이라 intro에서 언급했던 사회적 고려가 없는 단순히 사전에 정의된 경로를 따라 이동한 데이터라는 한계가 있습니다.
저자들은 위와 같은 데이터셋 같은 경우는 localization, perception 관련 과제들을 연구하는데 어느정도 유용함이 입증은 되었지만 다른 자율 에이전트나 사람들이 존재하는 환경에서 사회적으로 준수하는 로봇 내비게이션을 할 수 있는데 도움이 될 수 있는 다양한 사회적 시나리오에서의 모션 명령이나 내비게이션 전략의 시연 정보가 부족하다는 점을 언급합니다. 저자들이 소개하는 SCAND 라는 데이터셋은 다양한 사회적 시나리오에서 풍부한 시연정보를 제공했다고 하며 이동 경로를 따라 발생한 12가지 서로 다른 사회적 상호작용에 대한 라벨 태그도 포함한다고합니다. 그리고 보통 다른 데이터셋들은 데이터 수집에 보통 하나의 로봇만 사용한다고 하는데(CoBots 데이터셋은 두 대를 사용하지만 형태적으로 동일한 로봇이라고합니다) SCAND는 서로 다른 형태의 로봇을 가지고 데이터를 수집함으로써 서로 다른 형태(바퀴형 vs. 사족보행형) 로봇에서의 사회적 내비게이션을 연구하는 데 유용하다고 주장합니다. (예를 들어 계단을 오를 수 있는 사족보행 로봇 Spot은 이동 중 계단을 선호하는 경로 선택을 할 수 있는 반면에 바퀴형 로봇 Jackal은 램프를 선택해 이동할 수 있을 수 있는 상황)
Data Collection Procedure
SCAND가 어떻게 데이터를 찍었는지(수집 프로토콜)랑, 로봇에 어떤 센서가 달려있는지, 그리고 사회적 상호작용 라벨을 어떻게 달았는지를 설명드리도록 하겠습니다.
Collecting Data
일단 데이터 수집은 사람이 조이스틱으로 로봇을 텔레옵퍼레이션해서 사회적으로 준수하게 운전한 시연 데이터를 모은 거고, 이걸 4명의 시연자(첫 두 저자 포함)가 직접 수행했다고합니다. 수집 장소는 intro에서 언급했던 UT Austin 캠퍼스고, 장면 속 사람들은 주로 학생/교직원/캠퍼스 이용자들이라고 설명합니다.
그리고 138개 trajectory 각각에 대해서는 시연자는 항상 로봇 뒤를 따라가면서 평균적으로 약 2m 정도 거리를 유지했다고 합니다. 그리고 시연자는 군중과 직접 상호작용하지 않으면서 데이터를 취득햿다고하는데 사람들이 걷는 흐름에 대해 시연자가 비켜주세요라고 한다거나 사람을 유도해서 일부러 상황을 만들지는 않았다는 뜻이라고 보면 될 것 같습니다. 즉, 사람들은 그냥 평소처럼 움직이고,로봇이 그 사이를 지나가면서 자연 발생하는 상호작용을 그대로 담았다라는 것 같습니다.
여기서 중요한 차별점은, THÖR 같은 기존 데이터셋처럼 통제된 실내 환경에서 시나리오를 연출해서 찍지 않았다는 점입니다. JRDB랑 비슷하게 실내/실외 모두에서 in the wild 상황에서 수집했다고 강조를 하고 실제로 캠퍼스의 보도/도로/잔디/건물 내부에서 그리고 유동인구가 많은 피크 시간대에 사람들 사이를 주행시키면서 데이터를 모았다고 합니다.
속도 범위는 아래와 같습니다.
Spot: v \in [0, 1.6] m/s, \omega \in [-1.5, 1.5] rad/s
Jackal: v \in [0, 2.0] m/s, \omega \in [-1.5, 1.5]rad/s
위와 같은 속도 범위가 사람 걷는 속도 범위랑 비슷하게끔 실제 사람들과 같이 움직이는 상황을 의도한 것 같습니다.
Sensor Suite

Fig. 3는 두 로봇에 달린 센서들을 나타낸거고 공통 센서와 로봇별 센서가 나뉩니다.
두 로봇 공통 센서 같은 경우는 VLP-16 Velodyne LiDAR (10 Hz),6D IMU (16 Hz),전방 Azure Kinect RGB 카메라 (20 Hz)이고 Jackal에 별도로 달린 센서같은 경우는 전방 스테레오 카메라 (20 Hz), wheel odometry (30 Hz)이고 Spot에 별도로 달린 센서는 몸체에 5개의 monocular 카메라 (5 Hz) 라고 합니다. 그리고 Boston Dynamics SDK(APK)를 이용해 visual odometry와 다리 관절각(joint angles)까지 기록했다고 합니다. 그리고 데이터셋에는 각 센서 프레임이 로봇 바디 프레임에 대해 가지는 TF(transform) 정보도 포함이되고 데이터 수집 자체는 AMRL의 autonomy stack을 이용해서 다양한 센서 토픽을 ROS로 묶어서 받고, 최종적으로 rosbag 포맷으로 기록했다고 합니다.
그리고 SCAND는 카메라/라이다 정보가 풍부하긴 하지만, 사람 검출/추적용 GT 라벨(바운딩박스, 트랙 ID 등)은 제공하지 않습니다. 저자들은 SCAND가 JRDB처럼 perception 태스크(사람 검출, 트래킹)를 풀기 위한 데이터셋이 아니라, 해당 논문은 navigation 자체를 학습하고 연구하는 데 초점을 둔 데이터셋이라는 점을 강조합니다. 대신 SCAND에서 시연 데이터로 핵심인 건 시연자가 실제로 내린 조이스틱 명령 (선속도 v, 각속도 ω), 실시간 멀티모달 센서 스트림 긜고 trajectory마다 붙는 사회적 상호작용 태그(12종) 이렇게라고 보시면 될 것 같습니다.
Labeled Annotations of Social Interactions
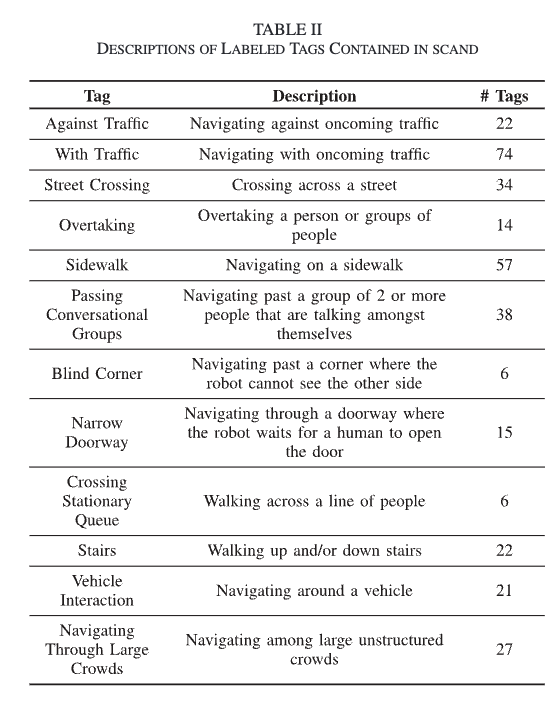
저자들은 SCAND의 각 trajectory에 대해서 이동 경로를 따라 발생한 사회적 상호작용을 설명하는 라벨을 주석으로 달게 되고 이 라벨들은 해당 궤적에서 일어난 사회적 상호작용을 나타내는 텍스트 캡션들의 리스트 형태입니다. SCAND의 라벨링은 프레임 단위의 디테일 라벨이 아니라, trajectory-level 태그라고 보시면 될것 같습니다. 단위는 trajectory(한 주행 기록)이고,각 trajectory에는 미리 정의된 12개 태그 중 일부가 리스트 형태로 붙게 됩니다. 그리고 Table II에 있는 # Tags는 데이터셋 전체(138 trajectories)에서 그 태그가 몇 개 trajectory에 등장했는지를 나타낸 값입니다.

Fig. 2는 다섯 가지 예시 시나리오와 그에 대응하는 태그를 보여주는 그림입니다.
Analysis
저자들은 수집된 SCAND 데이터를 가지고 분석을 수행하고 관련하여 두가지 질문을 던집니다.
- 하나의 씬에서 사회적으로 이동하는 전략이 하나 이상 존재하는지
- SCAND 데이터셋을 사용해서 사회적 내비게이션을 위한 로컬, 글로벌 플래너를 학습할 수 있는지
저자들은 질문 1에 대해서는 시연자 분류 문제로 풀고 질문 2에 대해서는 Behaviot Cloning으로 글로벌, 로컬 플래너를 동시에 학습하는 식으로 보여주는데 먼저 질문 1에 대해서 설명드리도록 하겠습니다.
시연자 분류(질문 1)
여기서 저자들이 주장하는 것은 사회적 상호작용을 고려한 주행 같은 경우는 이동 전략이 다양하게 존재할 수 있다는 것입니다. 예를 들면 어떤 시연자는 미리 크게 피해가는 스타일일 수도 있고 또 어떤 시연자는 끝에서 살짝 조정하는 스타일일 수 있고 그래거 저자들은 이런식으로 사회적 상호작용을 고려한 주행 전략이 하나만 존재하지 않는다는 가설을 세웁니다. 그리고 실험 세팅은 캠퍼스내 같은 루트를 두 명의 시연자가 운전한 traajectory를 모아서 총 16개를 쓰고 이 중 12개 궤적으로 학습하고 4개로 검증하는 방식으로 세팅을하고 입력은 10초길이 시퀀스로 그냥 라이다 한 장 넣고 끝이 아니라 10초동안의 관측과 조이스틱 명령도 같이 넣는다고 합니다. 아키텍쳐는 아래와 같습니다.
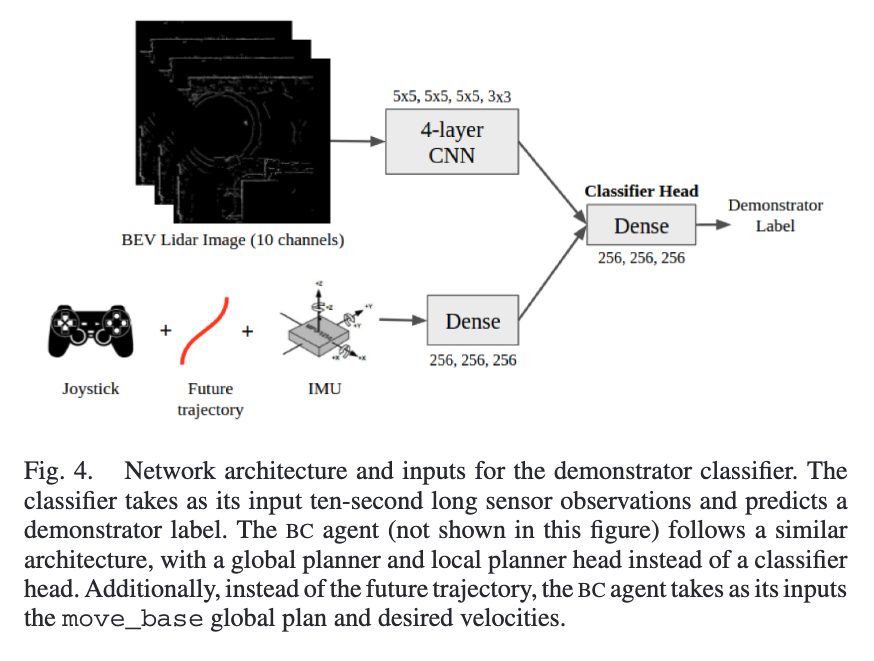
라이다 스캔을 1hz로 서브샘플링하고 10초 시퀀스에서 첫 번째 라이다 프레임을 기준으로 로봇이 얼마나 움직였는지(상대 좌표)를 같이 입력으로 넣어주고 가장 최근 라이다 프레임 좌표 기준으로 표현된 200개 포인트의 미래 궤적도 입력으로 넣어주게 됩니다.(시연자가 실제로 그 이후에 어떻게 갔는지를 로컬 좌표계에서 200개의 waypoints로 넣어준다고 보시면 될 것 같습니다.) 그리고 마지막으로 각 라이다 프레임에서 IMU 값과 조이스틱 값(선/각 속도)도 들어가게 됩니다. 전반적으로 라이다 히스토리 장면들 그리고 움직임 조이스틱 패턴을 입력으로 넣어주게 되면서 누가 운전했는지 A,B중 맞추는 구조라고 보시면 될 것 같습니다.
결과적으로 74.48%의 정확도가 나왔다고 합니다. 이게 이진 분류(A vs B)이기 때문에 사실 랜덤으로 찍어도 50%의 결과는 나오게 됩니다. 근데 10초 클립이라는 게 짧기 때문에 그 안에 사회적인 상호작용을 고려할 수 있는 이벤트가 나타나있다고 볼 수 도 없고 그냥 평범하게 직진하는 구간도 많을 수도 있습니다.(SCAND의 사회적 태그는 trajectory-level이라 전체 궤적에 대해서는 사회적 상호작용을 나타낼 수 있어도 10초 조각에는 안들어갈 수 있음.) 저자들은 그럼에도 불구하고 74% 까지 시연자를 구분했다는 것은 사람마다 사회적으로 운전하는 스타일이 일정하게 다르게 나타나는 것이라고 해석을 합니다. 그래서 저자들은 같은 시나리오에서도 사회적 맥락을 만족하는 전략이 하나로 고정되지 않고 여러 스타일 전략이 존재할 수 있다라고 주장합니다.
글로벌 및 로컬 플래닝을 위한 모방학습(질문 2)
앞선 분석은 사람마다 사회적 맥락을 고려한 내비게이션 전략이 다를 수 도 있다는 것을 분류로 보여줬다면 두번쨰 질문에 대해서는 해당 데이터로 실제로 플래닝 정책을 학습할 수 있는지를 보여주는 분석이라고 보시면 될 것 같습니다. 저자들은 SCAND에 Behavior Cloning을 적용해서 사회적 맥락을 고려하는 글로벌 플래너 + 로컬 플래너를 end-to-end로 동시에 joint 학습을 진행합니다.
먼저 글로벌 플래너는 현재 로봇 위치 기준 10m horizon안에서 시연자가 실제로 갔던 미래경로 궤적을 예측하는 것이고 로컬 플래너는 당장 어떻게 움직일지를 조이스틱 명령인 선속도 각속도를 예측하는 것을 목표로하는 친구들이라고 보시면 좋을 것 같습니다.
아키텍쳐는 시연자 분류기와 비슷한 구조라고 합니다. 센서 입력을 처리하는 인코더를 각각 공유해서 쓰고 출력만 두갈래로 나눕니다. 시연자 분류기에서는 분류 head하나 였다면 여기서는 글로벌 head(trajectory 예측), 로컬 head(속도 명령 v,w 예측) 두개를 두고 둘다 단순히 3-layer 짜리 FC 헤드를 썼다고 합니다.
여기서 인풋으로 들어가는 것은 2초 길이의 센서 시퀀스가 들어간다고 합니다. 한 프레임 보다는 여러 프레임을 보는 것이 시간 변화(사람의 움직임, 나의 움직임)을 보는게 유리하기 떄문인 것 같습니다.
2초 입력에는 시연자 분류기와 마찬가지로 서브샘플링된 라이다 스캔(대신 2hz) , 그리고 프레임간 상대 위치(첫 라이다 프레임 기준으로 이후 프레임들의 상대 포즈), IMU정보(각 프레임 별)으로 구성이 되어있습니다. 그리고 학습시에는 데모 trajecotry가 있으니깐 10m ahead 지점을 subgoal로 두고 move_base라는 고전 내비게이션 알고리즘이 계산한 추천 경로, 추천속도를 힌트로 준다고 합니다.
해당 분석 파트의 목적은 SCAND로 기존 IL이 학습가능함을 보여주기라서 간단하게 네트워크를 설계한거 같고 센서 관측을 처리하는 인코더를 사전학습하기 위한 별도의 설계나 학습을 하진 않았다고 합니다.
글로벌 플래너는 시연 경로를 얼마나 잘 따라 예측하는지를 Hausdorff Distance 로 평가합니다. Hausdorff Distance는 두개의 경로(점들의 집합)에 대해서 서로 얼마나 멀리 떨어져있는지를 최대 오차 기준으로 재는 거리라고 합니다. (한번이라고 크게 잘못가면 점수가 확떨어져서 사람을 향해 틀어버리는 이런 사회적으로 문제가 되는 큰 편차를 잡아내기 좋아서 사용한 것 같습니다.)
글로벌 플래너 같은 경우는 move_base 알고리즘을 베이스로 비교를 진행하는데 move_base가 예측한 global path와 시연 경로간 HD는 평균 1.25 BC로 학습한 글로벌 플래너의 예측 경로와 시연 경로간 HD는 0.26으로 큰 차이를 보입니다.
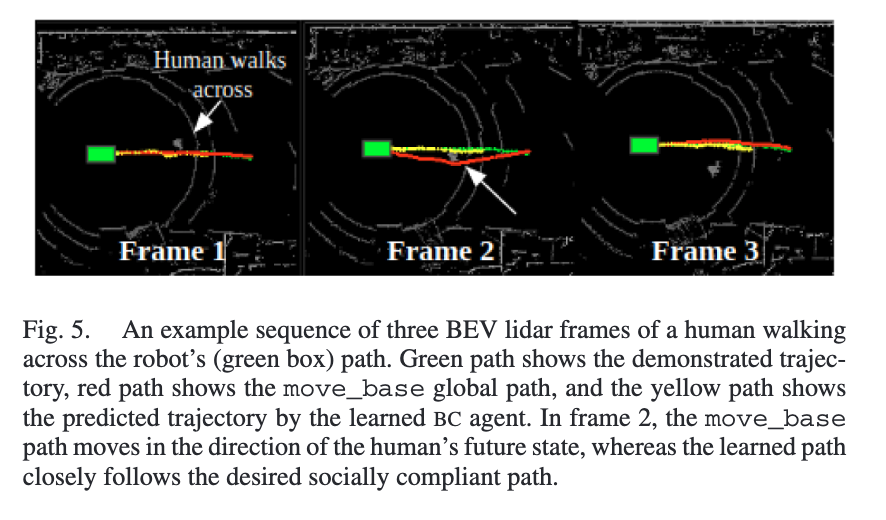
Fig.5가 정성적 결과인데 저자는 사람이 로봇 진행 경로를 가로지르는 상황에서 노란색(학습된 BC 경로)은 초록색(시연 경로)을 잘 따라가는데, 빨간색(move_base)은 사람의 미래 위치 방향으로 회전하는 상황을 만든다고 설명합니다.

로컬 플래너는 fig.6 와 같은 상황에서 실내에서 Spot 로봇으로 14명 참가자를 대상으로 실제 실험을 했다고합니다. 시나리오는 두 가지입니다.
정적 상황: 로봇 경로 위에 사람이 가만히 서 있고, 로봇은 사람 앞 5m에서 출발해서 사람 뒤 5m 지점 goal로 가야 함
동적 상황: 사람과 로봇이 서로 마주보고 10m 떨어진 상태에서 시작해서 서로의 출발 지점으로 이동 (마주보며 지나가야 하는 상황)
참가자들은 두 시나리오 모두에서 로봇의 행동을 관찰하고, 각 알고리즘(move_base vs BC 정책)에 대해 설문 조사하는 식으로 평가를 합니다.
질문은 아래와 같이 2개로 구성했다고 합니다.
- (1점에서5점 척도에서) 로봇이 얼마나 사회적으로 준수했다고 생각하는가(사회적 준수는 로봇이 당신의 존재를 얼마나 배려했는지를 의미한다고 생각할 것)
- (1점에서5점 척도에서) 로봇 주변에서 얼마나 안전하다고 느꼈는가
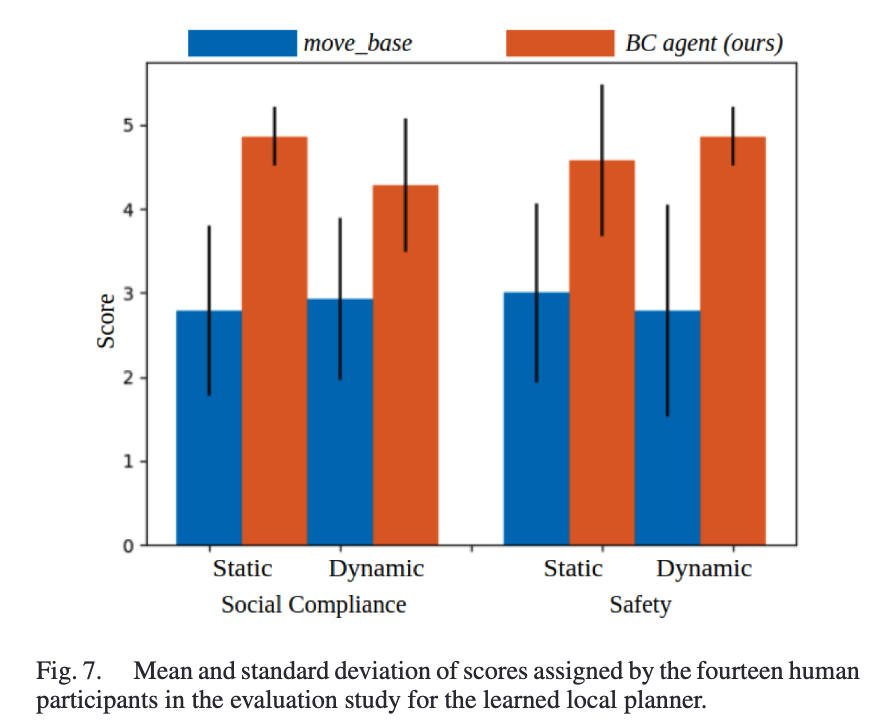
결과는 Fig.7에 정리돼 있고 순서는 랜덤으로 섞어서 보여줬다고 합니다.
사회적 배려(사회적 준수)같은 경우에는 SCAND(BC) mean = 4.39 (sd 0.99) vs move_base mean = 2.86 (sd 0.82)결과를 보이고 안전같은 경우는 SCAND(BC) mean = 4.71 (sd 0.70) vs move_base mean = 2.89 (sd 1.18)의 결과를 보입니다.
저자들은 이게 당연히 move_base는 원래 사회적 준수를 목표로 설계된 게 아니니까 그렇다고 하고 결과적으로 사회적 준수가 반영이 된 SCAND를 가지고 모방학습을 하면 사회적 준수 내비게이션 정책을 학습시킬 수 있다고 주장을 합니다. 다만 저자들은 여기서는 비교적 단순한 시나리오만 검증했기 때문에 SCAND에 포함된 더 복잡한 상황을 다루려면 더 좋은 IL 알고리즘이 필요할 수 있다고 언급하긴 합니다.
Conclusion
SCAND라는 사회적 내비게이션 시연 데이터셋(8.7h/138 traj/25 miles)을 공개했고 이게 그냥 데이터 공개로 끝나는 게 아니라 해당 데이터 셋을 가지고 두 부분에 대한 분석을 실험으로 보여준 논문이라고 보시면 될 것 같습니다. 한가지는 시연자 분류로 사회적 준수 내비게이션도 사람마다 스타일이 달라서 전략이 하나만 있는 게 아닐 수 있다는 걸 보였고, 다른 하나는 BC로 글로벌(10m 경로), 로컬(v,ω) 플래너를 학습해서 실제 사람 평가까지 돌려보니 고전 적인 방식인 move_base보다 더 사회적으로 준수하고 안전하게 느껴졌는 결과를 제시하면서 BC를 통해서 글로벌 로컬 플래너 정책학습도 가능하다라는 가능성을 보여준 정도로 마무리한 것 같습니다. 사실 분석파트에서 질문1에 대한 실험에 대한 가정과 그에 대한 검증에 대한 이유는 아직 와닿지가 않는 것 같습니다. 뭔가 저자의 깊은 의도와 전달하고자 하는 메세지를 제가 잘 파악을 못한 것일 수 있지만 사회적 상호작용이 고려가 잘 되어있는지를 평가한 것이 아니라 갑자기 사회적 상호작용을 고려한 내비게이션 전략에는 여러가지가 있을 수 있다는 가정을 검증한게 와닿지 않기도하고 가정 또한 당연한 것이 아닌가 싶기도 한데, 다양한 데이터셋 논문들을 읽어본 후에 다시 한번 읽어봐야할 거 같습니다. 이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 리뷰 잘 읽었습니다.
데이터셋 논문인만큼 크게 구조적으로 이해해야할 부분이 많지는 않네요.
마지막 conclusion에서 사회적 상호작용을 고려한 내비게이션 전략에 여러가지가 있을 수 있다는 가정을 검증한 부분이뭐 contribution 을 하나 만들어서 생긴거일수도 있고 아니면 누구나 당연하게 생각하지만 실제로 이게 맞나? 를 검증해본정도로 저도 이해했습니다. 이걸 검증하려면 사실 짧은거리보단 긴거리를 해야 좀더 신뢰성이 가는게 아닌가 싶기도 합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
단순 네비게이션을 넘어서 사회적 tagging을 한 dataset은 흥미롭네요.
질문2에서 사회적 준수를 사람에게 설문을 받아 평가를 매긴 부분에서
해당 데이터셋으로 사회적인 행동을 배운다면, 그걸 평가하는 부분은 사람의 평가가 필요하다는 점이 연구를 어렵게 할 것 같다는 생각이 듭니다
그래서 사회적 상호작용을 제시한게 이 논문이 처음인지, 그리고 아니라면 다른 논문들에서도 사람이 평가를 하는지 궁금합니다