지난번에 리뷰한 PhysToolBench 논문에 RoboBrain 논문이 있어서 궁금해서 읽어보게 되었습니다. 2025년 2월에 공개된 논문으로, 이후에 9월에 RoboBrain 2.0 리포트가 나온 것 같습니다.
Abstract
최근 MLLMs의 발전으로 다양한 멀티모달 맥락에 대한 이해 능력이 개선되었으나, 특히 long-horizion manipulation 작업과 같은 로봇 시나리오에서는 여전한 한계가 존재합니다. 이는 (1) 복잡한 조작과 관련되 하위의 subtask로 분해하는 Planning 능력의 부족, (2) 상호작용이 이루어지는 물체를 인식하는 Affordance Prediction 인식 능력 부족, (3) 작업을 수행하기 위한 로봇의 경로를 예측하는 Trajectory 예측 능력 부족과 같은 MLLMs이 로봇의 지능을 위해 요구되는 3가지 능력이 부족하기 때분입니다. 따라서 저자들은 ShareRobot이라는 고품질의 이종 데이터셋을 제안합니다. 이는 task planning, object affordance, end-effector trajectory 정보로 구성되며, 3명의 사람 annotator가 꼼꼼히 검수하였다고 합니다. 해당 데이터를 기반으로, 저자들은 RoboBrain이라는 MLLM 모델을 개발하여 조작 작업 성능을 개선하였다고 합니다. 해당 모델은 로봇과 일반 멀티모달 데이터를 결합하고, 여러 단계의 학습 방식을 이용하였으며, long-video와 고해상도 이미지를 통합하였습니다. RoboBrain은 광범위한 실험을 통해 다양한 로봇 작업에서 SOTA를 달성하였으며, 발전된 로봇의 지능의 가능성을 입증하였다고 합니다.
Introduction

최근 MLLMs의 발전으로, 범용 인공지능에 대한 활발한 연구가 이루어지고 있으나, 여전히 로보틱스 분야에서의 적용은 초기단계에 해당합니다. 특히, 로보틱스에서의 MLLMs 연구는 주로 자연어 이해 및 시각 관찰 작업에 MLLM을 활용하는 데 초점을 맞추고 있으며, long-horizon 작업과 같은 로봇 시나리오에는 한계를 보여주고있습니다. 저자들은 이를 MLLM이 세 가지 필수적인 로봇 지능을 갖추지 못하였기 때문이라고 보았습니다. 필수적 능력으로는 복잡한 조작 지침을 하위 작업으로 분해하는 Planning 능력, 상호작용 물체의 사용 가능 영역을 인지하는 Affordance 인식 능력, 작업 실행을 위한 Trajectory 예측 능력이 있으며, 이러한 능력 외에도, 로봇 작업에 특화된 대규모의 정교한 데이터셋이 부족한 점도 주요 원인으로 보았습니다.
해당 논문은 이러한 로봇 두뇌의 핵심 역량을 갖추기 위해, Planning, 물체의 Affordance, end-effector의 trajectory 등 여러 정보를 정교하게 레이블링한 고품질 데이터셋인 ShareRobot 데이터를 제안합니다. 해당 데이터셋의 다양성과 정확성은 세 명의 인간 어노테이터에 의해 세밀하게 보정되었으며, 이 데이터셋을 기반으로 로봇 및 일반 멀티모달 데이터를 통합하고 다단계 훈련 전략을 활용하며, 긴 비디오와 고해상도 이미지를 사용함으로써 로봇 조작 능력을 향상시킨 MLLM 기반 모델 RoboBrain을 개발하였습니다. 마지막으로 광범위한 실험을 통해 RoboBrain은 다양한 로봇 벤치마크에서 SOTA 성능을 달성하며 로봇의 지능 강화의 잠재력을 입증했습니다.
해당 논문의 contribution을 정리하면,
- 로봇 조작을 위해 통합된 MLLM인 RoboBrain을 제안하여, 추상적 명령어를 구체적 행동으로 변환
- 로봇 데이터와 일반 멀티모달 데이터의 비율을 세심하게 설계하고, 다단계 훈련 전략을 구현하였으며, long video와 고해상도 이미지를 통합하여 로봇 조작에서의 Planning 능력을 개선
- 작업 계획, 객체 효용성, 엔드-이펙터 궤적을 포함한 다차원 정보를 함께 라벨링하여, 다양한 로봇 기능을 효과적으로 향상시키는 고품질의 이종 데이터셋인 ShareRobot 제안
- 실험을 통해 RoboBrain이 다양한 로봇 벤치마크에서 SOTA 성능을 달성함을 입증하였으며, 로보틱스 분야의 실제 응용 가능성을 보임
ShareRobot Dataset
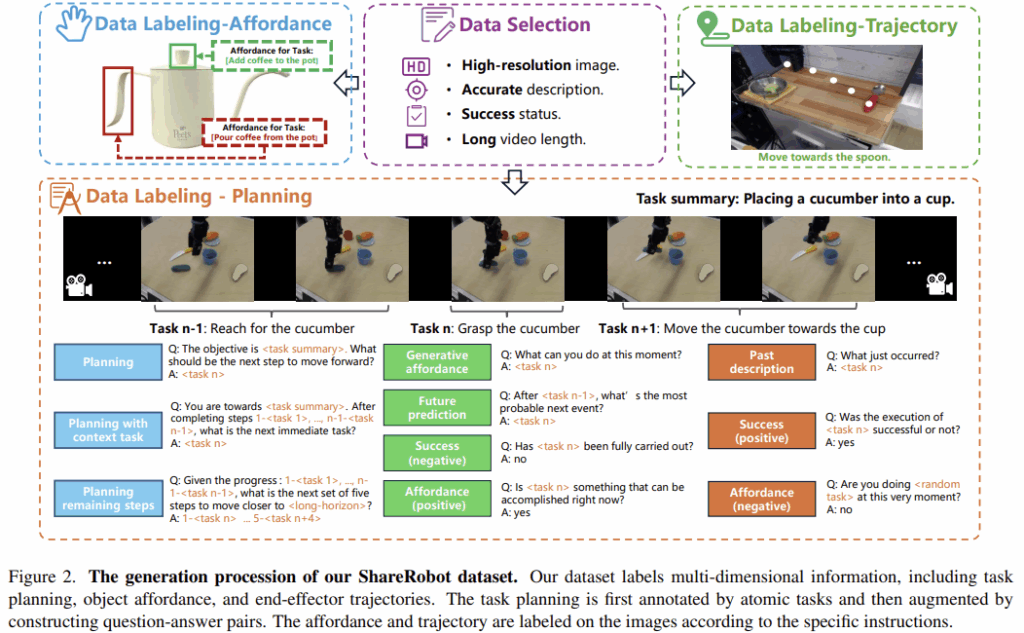
해당 논문에서 제안하는 ShareRobot 데이터셋은 대규모의 fine-grained 데이터셋으로, 위의 Figure 2는 데이터 셋 생성 과정을 나타냅니다. ShareRobot 데이터셋은 Open-X-Embodiment 데이터 셋에서 보다 구체적인 low-level planning 지시문을 제공함으로써, 모델의 정확도를 개선하고자 하였다고 합니다.
[ Data Selection ]
ShareRobot은 planning 뿐만 아니라 object affordance, end-effector의 경로와 같은 다양한 정보를 함께 제공하였으며, Open-X-Embodiment 데이터 셋에서 다음의 기준으로 51,403개의 시연 인스턴스를 선별합니다. 구체적으로는 저해상도 영상(128px 이하)과 모호하거나 부정확한 설명에 해당하는 경우 제외하고, 실패한 시연, 너무 짧은 영상(30프레임 미만), 목표 물체나 말단이 가려지거나 end-effector의 궤적이 불완전하거나 불명확한 시연 제거하였다고 합니다. 이렇게 하여 ShareRobot은 총 1,027,990개의 Question-Answer 쌍으로 이루어진 대규모 데이터로, 102개의 장면에 대하여 12가지 embodiment, 107가지 작업으로 이루어져있다고 합니다.
[ Data Labeling ]
- Planning Labeling
- 로봇 작업 시연 영상에서 30 프레임을 추출한 뒤, 해당 프레임과 high-level description을 이용하여 Gemini로 low-level planning instruction으로 분해합니다. 이후 3명의 사람 어노테이터가 이를 검토하고 수정하여 정확한 라벨을 생성합니다. 이후 10개의 질문 유형에 대하여 각각 5가지의 질문 템플릿을 설계하여, 각 질문마다 3개의 템플릿을 랜덤하게 생성하여 각 시연 작업 인스턴스에 대하여 Q&A 쌍을 생성합니다. 이러한 과정을 통해 51,403개의 로봇 작업 시연 인스턴스에 대하여 1,027,990개의 Q&A 쌍을 구축합니다.
- Training/Test: 100만개/2,050개로 구성
- Affordance Labeling
- 6,522장의 이미지에 대하여 high-level description에 대응되는 affordance 영역에 대한 bbox의 좌상단/우하단 좌표를 라벨링합니다.
- Training/Test: 6,000장/522장으로 구성
- Trajectory Labeling
- 6,870장의 이미지를 선별한 뒤, low-level planning instruction에 따라 그리퍼의 궤적을 최소 3개의 x,y 좌표로 라벨링합니다. 이후 지시문이 해당 궤적과 정확히 정렬되도록 사람이 검토하고 수정하였다고 합니다.
- Training/Test: 6,000장/870장으로 구성
- 10가지 질문 유형이란?
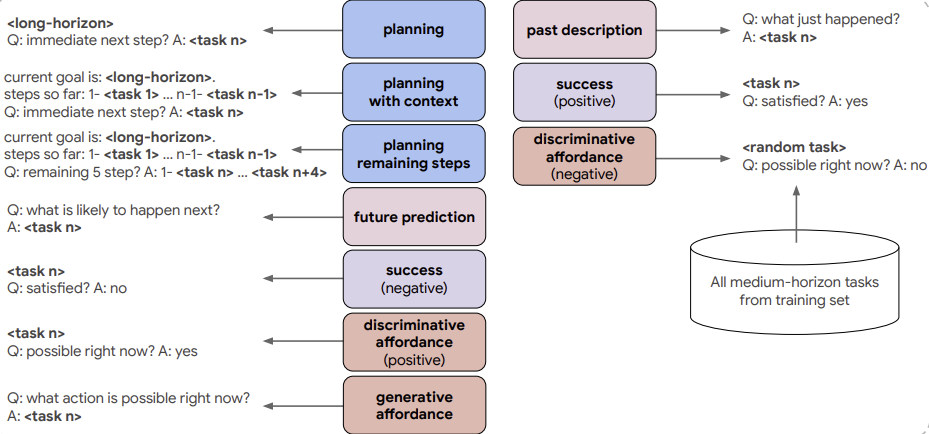
- RoboVQA논문(ICRA 2024)의 10가지 질문 타입을 따른 것으로, 아래의 그림이 이에 대한 예시입니다.
- Planning: 단순히 다음 step의 작업이 무엇인지 질문이 주어지고, 이에 대해 작업을 답변
- Planning with context: 어떠한 목적을 달성하기 위해, 지금까지 무슨 작업을 했는지 설명이 포함되고, 이후 다음 step이 무엇인지 질문이 주어지면, 이에 대한 작업을 답변
- Planning remaining steps: 위와 비슷하지만, 답변에 이후에 작업들을 모두 답변
- Future prediction: 어떤 일이 일어날 지 예측
- Past description: 방금 어떤 작업이 이루어졌는 지 질문
- Success(negative): 성공 여부를 묻고 답변은 Yes
- Success(positive): 성공 여부를 묻고 답변은 No
- Discriminative affordance(positive) : 가능한 케이스 질문, 답변은 Yes
- Discriminative affordance(negative): 불가능한 케이스 질문, 답변은 No
- Generative affordance: 가능한 행동에 대하여 질문하고 작업을 답변
- RoboVQA논문(ICRA 2024)의 10가지 질문 타입을 따른 것으로, 아래의 그림이 이에 대한 예시입니다.
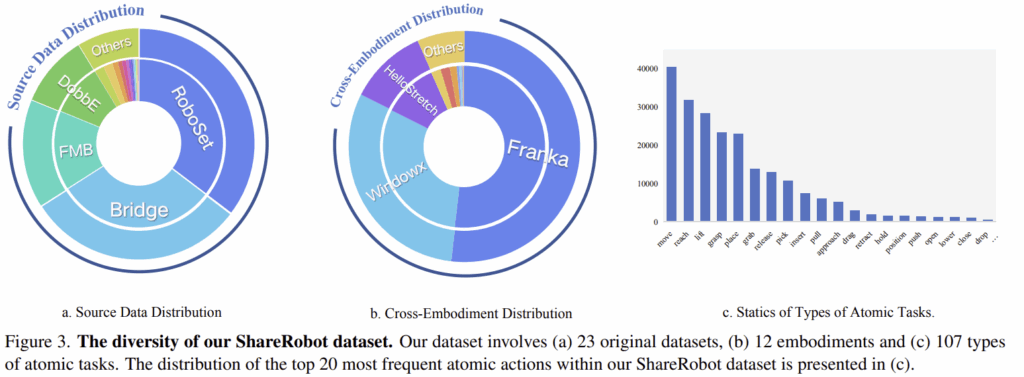
[ Data Statistics ]
Open-X-Embodiment 데이터셋에서 23개의 원본 데이터를 선택하였으며, 데이터 분포는 아래의 Figure 3에서 확인하실 수 있습니다. 데이터는 침실, 주방, 사무실 등 102개의 장면을 포함하고, 12종의 서로 다른 embodiment로 구성됩니다. 또한, Figure 3의 (c)는 다양한 작업에 등장하는 단어 빈도로, move/reach/lift/grasp/place/grab/release/pick 등의 순으로 이루어져있습니다.
RoboBrain Model
저자들은 추상적인 지시를 이해하고 물체의 affordance 영역과 trajectory를 명시적으로 출력할 수 있게 하여 구체적으로 행동을 할 수 있도록 하는 MLLM을 만들고자 하였습니다. 이를 위해 여러 단계의 학습 전략을 사용하였으며, 1단계는 강한 이해 능력과 지시를 따르는 능력을 갖춘 MLLM을 만드는 것을 목표로하였으며, 2단계는 추상적인 지시에 대하여 구체적 행동으로 변환하는 능력을 강화하는 데 집중하였습니다.
Architecture
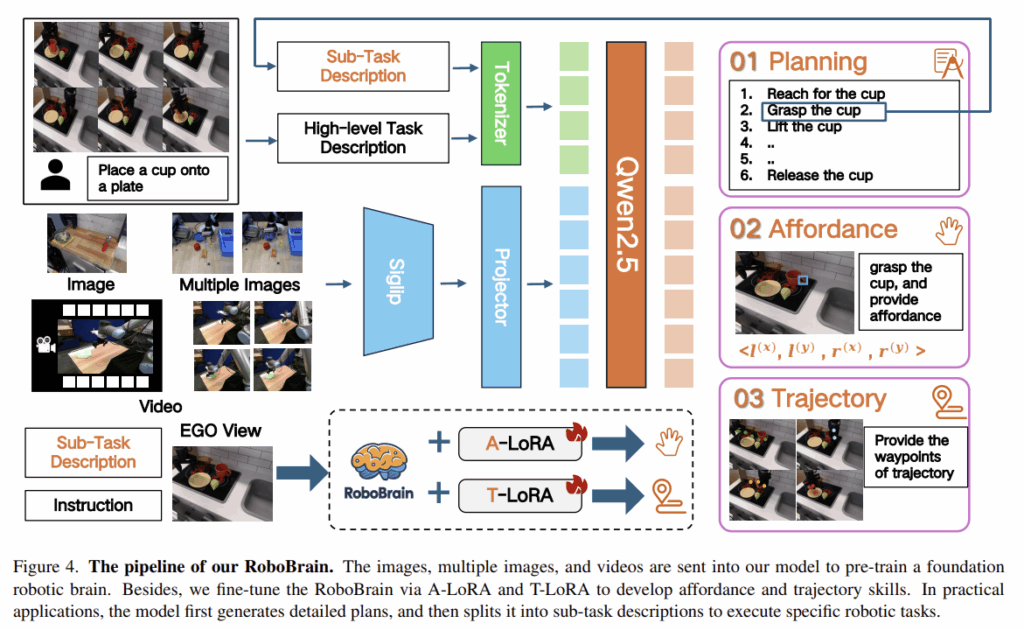
먼저 해당 모델은 LLaVA를 기반으로 설계되었으며, Planning을 위한 기반 모델, Affordance 인식을 위한 A-LoRA 모델, trajectory 예측을 위한 T-LoRA 모델 3가지 모듈로 구성됩니다.
- Foundational Model for Planning
- 저자들은 vision encoder로 SigLIP을 이용하였으며, 2개의 MLP로 Projector를 구성하고, Qwen2.5-7B-Instruct를 LLM으로 이용하였다고 합니다. 이미지나 비디오가 입력되면 vision encoder를 거처 시각적 특징을 생성한 뒤, Projector로 LLM의 의미론적 공간과 매핑하여 시각적 토큰 시퀀스 H_v를 생성합니다. 최종적으로 LLM은 사람의 언어지시와 시각적 토큰 H_v를 활용하여 autoregressive 방식으로 텍스트 응답을 생성합니다.
- A-LoRA Module for Affordance Perception
- 해당 연구에서 affordance는 사람의 손이 닿는 영역으로 정의됩니다. affordance 영역은 물체별로 여러개 있을 수 있으며, 좌상단과 우하단의 bounding box 좌표값으로 표현됩니다.
- T-LoRA Module for Trajectory Prediction
- Trajectory는 로봇 팔의 end-effector가 2D상에서 이동하는 좌표들의 시퀀스로 정의됩니다.
Training

위의 그림과 같이 학습은 크게 2단계이며, 4개의 stage로 구성됩니다. 먼저, 1단계는 Genaral OV Training과정으로, LLaVA-OneVision의 학습 데이터와 전략을 사용하여 일반적인 멀티모달 이해 능력을 갖춘 모델을 구축합니다. 구체적으로 Stage 1에서는 LCS-558K 데이터를 이용하여 Projector를 학습하므로써 시각적 정보와 LLM의 의미론적 정보 사이의 align을 돕습니다. 또한, 400만개의 고품질 image-text 데이터를 활용하여 전체적인 멀티모달에 대한 이해 능력을 강화합니다. Stage 2는 LLaVA-One-Vision 데이터에서 320만개의 단일 이미지와 160만개의 이미지·비디오 데이터를 사용하여 전체 모델을 추가학습하여 영상에 대한 이해 능력을 개선합니다.
다음 2단계는 Robotic Training과정으로 로봇 조작 및 Planning에 더 적합한 모델을 만드는 것을 목표로 합니다. Stage 3에서는 공개 로봇 데이터셋과 해당 논문에서 제안한 ShareRobot-200K 데이터를 모아 130만개의 대규모 로봇 데이터로 planning 능력을 개선하고자 하였으며, 지속적인 학습으로 앞의 지식을 잊어버리는 catastrophic forgetting 문제를 줄이기 위해, 1단계에서 사용한 데이터 중 약 170만개의 데이터를 일부 선택하여 함께 학습에 사용하였다고 합니다. Stage 4는 ShareRobot과 affordance 및 trajectory 예측에 대한 공개 데이터를 활용하여 두 LoRA 모듈을 학습합니다.
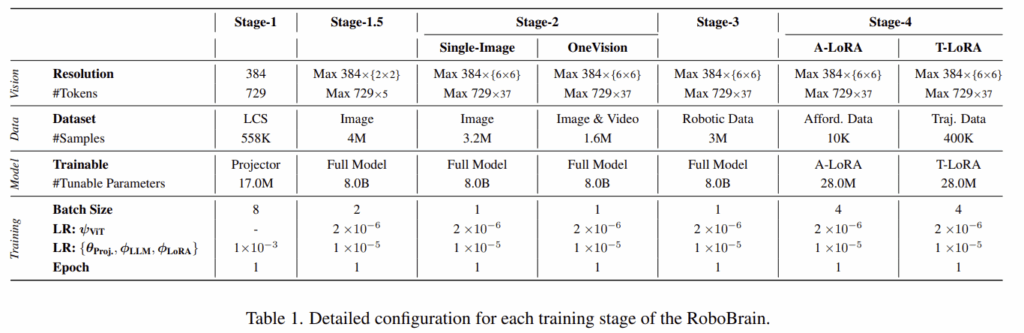
위의 Table 1는 각 학습 단계에 대한 데이터 및 파라미터 정보입니다. 학습에는 8개의 A800 GPU를 이용하였다고합니다.
Experiment
실험은 Planning/Affordance Perception/Trajectory Prediction 3가지에 나누어 이루어집니다.
[ Evaluation on Planning Task ]

planning 능력을 검토하기 위해 GPT-4V, Claude3, LLaVA-1.5, LLaVA-OneVision-7b, Qwen2-VL-7b, RoboMamba 6가지의 MLLM과 비교를 수행합니다. Figure 5는 이에 대한 실험 결과로, RoboBrain은 3가지 로봇 벤치마크에서 모두 베이스라인 모델들보다 좋은 성능을 달성하였습니다.(빨간선이 RoboBraion) 특히 OpenEQA와 ShareRobot 벤치마크에서는 베이스라인 방법론들 대비 성능이 크게 개선되었는데, 이는 로봇 작업과 긴 비디오를 이해하는 능력이 개선되었기 때문이라고 설명합니다. 또한, RoboVQA 벤치마크에서도 RoboBrain(주황색바)이 꾸준히 뛰어난 성능을 보여, Planning에서의 해당 방법론의 성능을 입증하였습니다.
[ Evaluation on Affordance Prediction ]
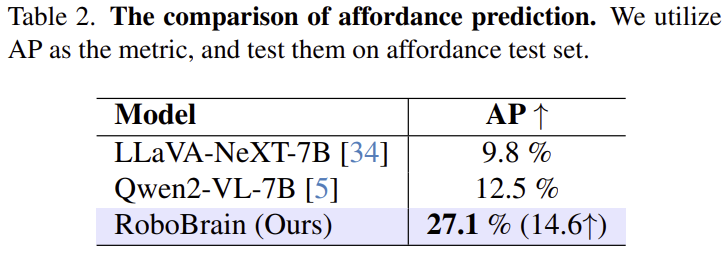
Table 2는 affordance 인식 능력에 대한 결과로, 시각적 grounding 능력이 좋은 Qwen2-VL와 시각적 이해 능력이 뛰어난 LLaVA-NeXT-7B를 함께 비교한 결과입니다. 평가에 사용된 데이터는 AGD20K로, affordance 연구에서 가장 많이 사용되는 벤치마크이며, 다른 모델들 대비 뛰어난 성능을 보이는 것을 확인할 수 있습니다. 저자들은 이를 통해 RoboBrain이 물리적 속성을 이해하고 affordance를 정확히 인식할 수 있었다고 어필합니다. bbox를 예측한 뒤 SAM을 쓴건지, bbox의 영역을 비교한 것인지는 언급되어있지 않습니다.
[ Evaluation on Trajectory Prediction ]
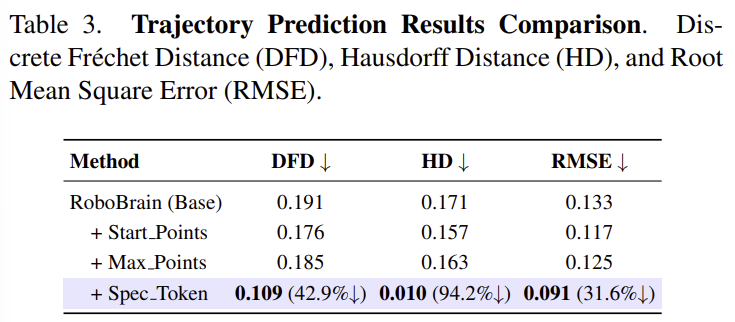
마지막으로 Trajectory에 대한 예측 능력을 비교하기 위해 저자들은 RoboBrain에 변형을 주어 실험을 진행하였습니다. Table 3은 이에 대한 실험 결과로 Start_Points는 end-effector의 2D 시작점을 추가하는 것, Max_Points는 waypoint를 균일한 10개의 샘플로 제한하는 것, Spec_Token은 end-effector의 위치와 special 토큰을 추가하여 waypoint와 시작 및 목표 지점을 강조하는 방식으로, 해당 변형을 최종 모델로 선택하였다고 합니다.
[ Visualization ]
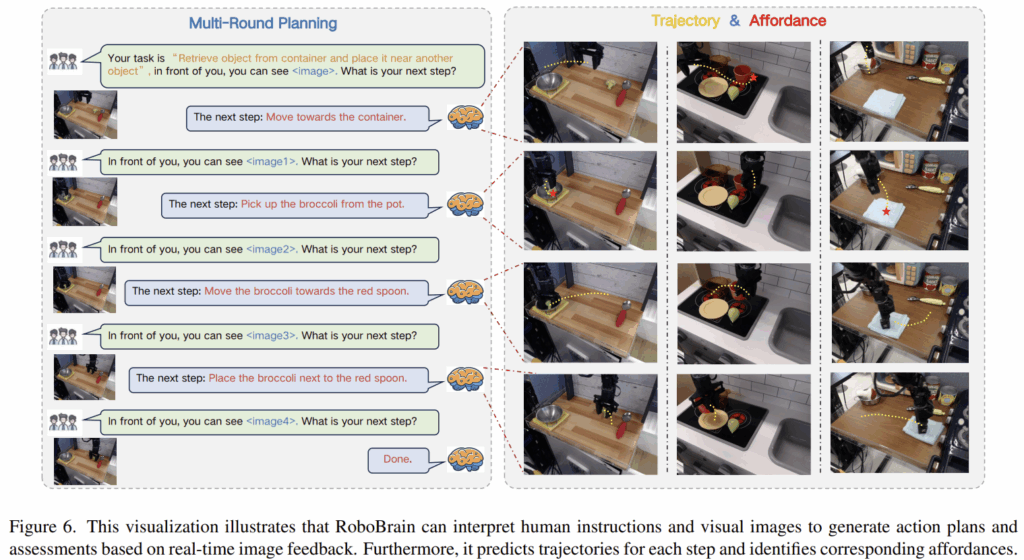
위의 Figure 6은 RoboBrain의 결과를 시각화한 것으로, 사람의 지시문과 시각 정보가 주어졌을 때, 사람과 상호작용을 하며 다음 과정을 이해하고 계획하며 구체적인 affordance와 trajectory도 생성하는 것을 확인할 수 있습니다. (오른쪽 시각화결과)
안녕하세요 승현님 리뷰 감사합니다.
ShareRobot Dataset의 데이터셋 라벨링 부분에 high-level description이라는게 있는데 혹시 이건 뭔지 알려주실ㅍ수 있으실까요? 맥락상 제가 이해한 바로는 해당 프레임의 task 설명글(?) 같은 것 으로 이해했는데 단순히 이렇게 이해하면 되는건지 궁금합니다~!
리뷰 읽어주셔서 감사합니다.
high-level description은 ‘Closing a drawer’, ‘Opening a microwave’와 같은 작업 명령에 해당합니다. 어찌보면 어떤 작업을 수행해야하는 지 작업 목적이 드러나도록 표현된 지시문이며, 이런 high-level의 표현을 ‘grasp the handle-> Pull the drawer open’, ‘grasp the handle-> Pull the microwave open’과 같이 세부적인 작업들을 나타내는 low-level instruction으로 분해하게 됩니다.