안녕하세요, 3번째 x-review는 Apollo라는 논문입니다. (논문 기준) 현재까지 video-LLM 연구의 문제점을 짚고, 저자 자신들의 모델을 제안하는 구성이기 때문에 LVU task에 익숙하지 않으신 분들도 꽤(?) 재밌게 읽히지 않을까 하는 생각이 드네요. 바로 시작하겠습니다!
Introduction
언어 모델이나 VLM의 빠른 발전과 반대로, video Large Multimodal Models(video-LMMs) 연구는 발전이 느리다고 합니다. 그 이유는 어떤 것이 모델의 비디오 이해 능력으로 연결되는 지에 대한 이해가 부족하며, video LMM들의 학습 및 추론 시 굉장히 높은 연산 비용을 요구하기 때문입니다.
- video LMM 모델 설계가 성능에 미치는 영향에 대한 이해 부족 일반적으로 비디오에서는 프레임 수가 굉장히 많이 때문에 1초에 1개씩(1 FPS) 등의 방법으로 프레임을 샘플링하는 과정을 거치는데, 대표적으로 이 샘플링은 어떻게 할 것인가?, 중요한 샘플은 또 어떻게 남길 것인가?(resampling) 부터, 요즈음 모델 설계에서 자주 사용하는 longer context windows, agent workflows 등의 설계 전략이 모델 성능에 어떤 영향을 주는 지에 대한 이해가 부족하다고 저자들은 주장합니다.
- Video LMM의 연산 비용 문제 저자들은 학습 때의 막대한 연산 비용 문제를 극복하기 위해 작은 모델의 설계 방식이 큰 모델에도 효과적으로 유효한지 조사했습니다. 기존의 scaling laws(스케일링 법칙)은 from scratch로 학습된 모델의 성능에 대해서만 적용 가능했기 때문에, pretrained 된 인코더나 LLM을 통합해서 사용하는 video LMM에도 적용할 수 있을지는 미지수였습니다. 하지만 저자들은 실험을 통해 smaller LMM에서의 설계 방식이 larger model에도 적용된다는 사실을 발견했고 이를 Scaling Consistency(스케일링 일관성) 이라고 명명합니다.
이 인사이트를 통해, 저자들은 video LMM 설계 파트 전반에 걸친 연구를 수행했고, 더 자세히 들어가면 비디오 샘플링과 인코딩 방법, token resampling, ‘통합’ 전략, 데이터 구성 등 비디오-언어 모델링의 필수적인 측면들을 다룹니다. 미리 결과부터 스포하자면
- 비디오 샘플링 : FPS 샘플링 > uniform sampling
- vision 인코더 조합 : Perceiver Resampler > average pooling
또한 현재의 벤치마크 조사를 통해 현제 모델의 대부분의 성능 향상의 상당 부분은 언어 모델링으로부터 기인했다는 것을 알아내어, 양질의 평가가 가능하고 인퍼런스 시간을 단축시킨 ApolloBench라는 벤치마크를 제안합니다. 마지막으로 이러한 발견들에 기반해서 장시간 비디오 이해가 가능한 Apollo라는 LMM을 제안합니다.
<Contributions>
- video LMM의 모델링 설계 공간design space를 탐색, 성능을 결정짓는 핵심 요소를 밝히고 future work위한 actionable insight 제공
- Scaling Consistency 규명 : smaller LMM과 데이터셋에서 효과적이었던 모델 설계가 larger LMM에서도 유효하게 transfrer 가능하다 → 연산 비용 줄이고 효율적인 연구가 가능
- ApolloBench 구축 : 평가 시간 단축시키면서도 temporal reasoning 및 perception 작업에 대한 분석 능력 유지
- SOTA LMM family, Apollo : 특히 3B 모델은 현존 7B 모델 능가하며 Apollo-7B 모델은 30B 파라미터 미만 모델 중에서 최고 성능 기록
Related Work
Video LMM의 구조는 보통 다음과 같습니다.
Vision Encoder → Connector → LLM
CLIP, SigLIP 등의 VLM에서 가져온 이미지 인코더나 비디오 인코더를 그대로 (또는 튜닝해서) 가져다 쓰는데, 이때 비디오의 시간 정보까지 LLM에 전달하기 위해 Connector를 사용합니다. 학습 단계는 두 단계인데, 먼저 alignment 단계에서는 이미지 인코더가 출력한 visual feature를 이미지-텍스트 임베딩 공간으로 매핑합니다. 다음은 supervised fine-tuning으로, 모델이 사용자의 질문에 비디오 내용을 바탕으로 대답하도록 가르칩니다.
Explore VQA Benchmarks
Video-LMMs의 빠른 발전은 수많은 VQA(Video Question&Answering) 벤치마크의 탄생으로 이어졌습니다. 그래서 종합적인 평가가 가능해졌지만, 평가해야할 테스트가 많아져 GPU 비용이 많이 들고, 여러 벤치마크가 이름만 다르고 비슷한 능력을 측정하여 불필요하게 반복적인 테스트를 하게 되는 redunduncy(중복성) 문제가 발생했습니다. 따라서 저자들은 현존 벤치마크의 퀄리티와 redunduncy를 분석하고, 그 인사이트를 바탕으로 ApolloBench라는 벤차마크를 제안합니다.
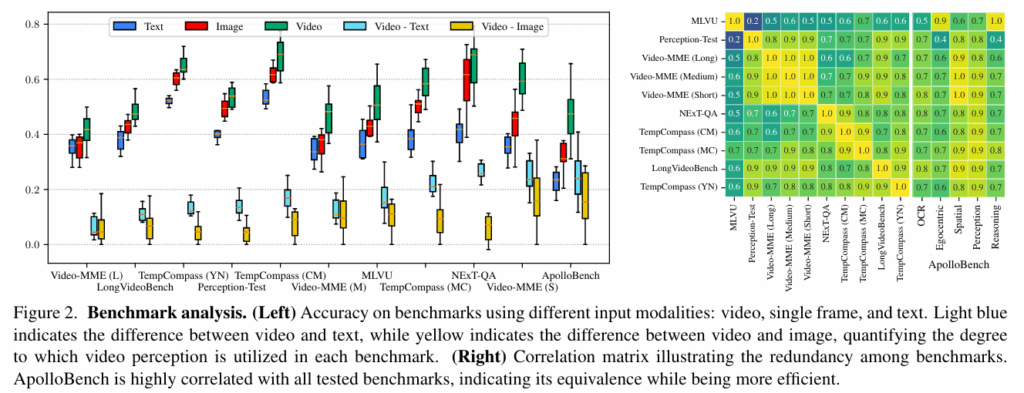
Left : 벤치마크 퀄리트 평가, Right : Redunduncy 평가
저자들은 10개의 오픈소스 LLM을 가지고 현재의 VQA 벤치마크를 평가했는데, 이때 입력 조건을 세 가지로 분류합니다. 비디오, 이미지(center frame), text only(질문과 보기 텍스트만 활용) 이렇게 세 가지 입력 조건을 구분해서 실험을 진행했습니다. Figure 2(Left)를 보시면 image나 text만 사용했을 때도 video에 버금가는 정확도를 찍을 수 있다는 점을 확인할 수 있어, 현존 벤치마크에서는 LLM이 video 이해 능력에 의존하지 않는다는 것을 보여줍니다.
Figure 2(right)는 각 벤치마크들의 redunduncy에 대한 correlation matrix입니다. 대체로 상관계수가 높은 것으로 보아 벤치마크 개수는 많으나 redunduncy를 가진다고 할 수 있습니다. 또한 질문 포맷의 영향을 고려하기 위해 객관식, yes/no, 캡션 매칭, 캡션 생성 등 다양한 포맷을 가진 TempCompass 벤치마크로 연구해본 결과 이 역시 highly correlated 되어있어 다양한 질문 포맷을 구성하는 것이 평가를 다각화하지는 않는다는 것을 확인했습니다.
위의 연구 결과를 바탕으로 저자들은 ApolloBench 라는 벤치마크를 고안했습니다. 비용 효율적인 평가를 위해 객관식 기반 질문을 선택했고, 텍스트나 정지 이미지만으로 정답을 맞힐 수 있는 문항을 필터링했습니다. 또한 각 질문을, 순수 비디오 인지 능력이 필수적인 5개 카테고리(Temporal OCR, Egocentric, Spatial, Perception, Reasoning)로 분류했습니다. 각 항목에서는 엔트로피를 기준으로 모델 간의 변별력이 높은 top 400개의 질문을 선별했다고 합니다. ApolloBench는 현존 벤치마크들과 highly correlated되어 있으면서도 평가 속도가 41배 더 향상되었으며, text/image가 아닌 video perception에 더 의존한다고 합니다.
Scaling Consistency
Video LMM들을 학습시키는 것은 엄청난 연산 비용을 요구하며 특히 large scale dataset를 수십억 개의 파라미터를 가진 LMM에 학습시킬 때 더 두드러집니다. 이때 smaller LMM에서 성능이 좋을 때 larger LMM에서도 성능이 좋아짐을 확인한다면 효율적인 학습이 가능하기 때문에 저자들은 이러한 경향성을 확인해보고자 했습니다.
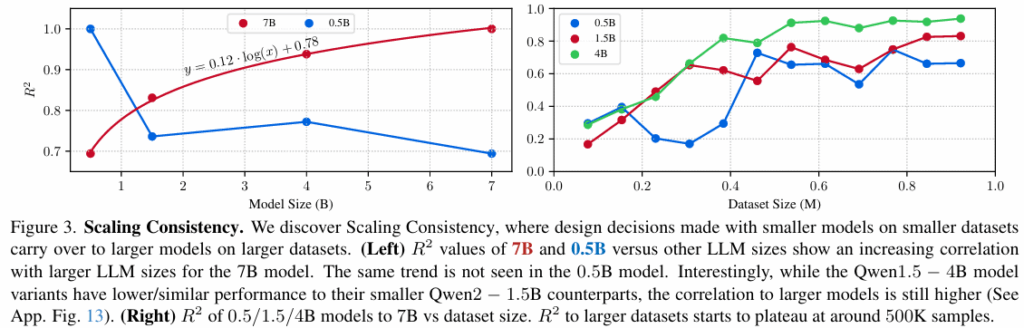
Figure 3(Left)는 서로 다른 사이즈의 LMM에 적용된 design decision 사이의 상관 관계 분석를 분석한 것으로 21개 모델 변형(설계)에 4개 LLM(qwen2 0.5B,1.5B,7B,qwen1.5 4B) 으로 학습시켜 총 84개 모델의 모델 간 R^2 score 를 나타낸 것입니다. 여기서 주목할 점은 7B 모델과 다른 크기 LLM들을 비교한 빨간 선인데, model size가 증가할 수록 7B 모델과 correlation이 log-linear하게 강해지는 것을 확인할 수 있습니다. 저자들은 2~4B 모델에서의 경향성이 larger size model에도 드러난다는 것으로 결론내리고 이 현상을 Scaling Consistency 라고 명명합니다.
Figure 3 (Right)는 데이터셋 크기가 모데 성능에 미치는 영향을 조사한 그래프이며, 데이터셋 크기에 따른 0.5B/1B/4B 모델과 7B모델의 correlation(R^2 score)을 나타냅니다. 4B LLM의 경우 7B와의 R^2 score가 500K dataset size 이상에서 높은 상태로 수렴하여, 500K 정도 데이터셋만 사용하면 작은 모델에서도 큰 모델 실험을 대신할 수 있다는 것을 발견했습니다. 결론적으로 4B 정도 LLM에서 500K 정도의 데이터셋으로 학습시키면, 그보다 큰 모델과 데이터셋으로 학습시켰을 때의 경향성과 비슷해지는 Scaling Consistency가 나타나는 것을 확인했습니다.
Exploring the video-LMM design space
저자들은 어떤 아키텍처적인 설계가 video LMM의 성능에 주요한 영향을 주었는지 탐구했습니다.
<실험 세팅>
- LLM 백본 : Qwen2.5 3B
- Dataset size : 750K
- 토큰 압축 : Perceiver resampler, 2fps 샘플링 + 프레임당 16개 토큰 추출
- 듀얼 인코더 : internVideo2 + SigLIP-SO400M
- 이미지 데이터 입력 : 이미지 복제하여 짧은 동영상처럼 만들고 비디오 인코더에 입력
Video Sampling
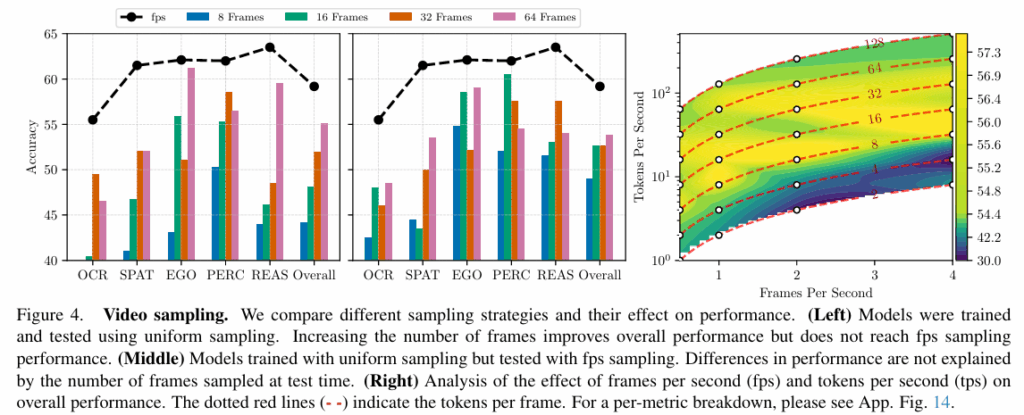
비디오 연구에서 비디오의 전체 프레임을 입력하기에는 계산 비용이 크고 메모리에 한계가 있기 때문에, 비디오의 핵심 정보만 뽑기 위해 frame sampling을 수행합니다. 초기에는 전체 비디오 duration에서 균일하게 프레임을 뽑는 uniform sampling을 많이 사용했는데, 샘플링하는 프레임 개수가 고정이기 때문에 학습 파이프라인 구축이 간편하다는 장점이 있지만, 프레임 간 시간 차이가 비디오마다 달라지기 때문에 모델은 비디오마다 재생 속도가 다르다고 느끼게 되고, 시간 감각을 학습하기 어렵게 됩니다. 그래서 초당 특정 특정 개수의 프레임을 샘플링하는 fps sampling이 등장했고, 저자들은 uniform sampling과 fps sampling 중 어느 것이 더 좋을 지 비교합니다. 실험 결과 (right,middle) fps sampling이 uniform의 성능을 웃돈다는 것을 확인했고 이는 모델 학습과 인퍼런스 두 과정모두에 적용된다고 합니다.
fps sampling을 적용하면 token resampler를 통해 token으로 변환하는 과정에서 초당 token 개수(tps) 역시 고려해야 합니다. 전체 토큰 예산이 한정된 상황에서 FPS를 높여 영상의 흐름을 더 촘촘하게 파악하려면 프레임당 할당되는 토큰 수를 줄여야 하고, 반대로 TPS를 높여 각 장면의 디테일을 살리려 하면 처리할 수 있는 프레임 수가 줄어들게 되기 때문입니다. 이런 fps-tps trade-off을 고려해서, 저자들은 실험(figure 4 right)을 통해 프레임당 16~32개의 토큰을 할당하는 것이 가장 최적이라는 것을 발견했습니다.
Video Representation
비디오 데이터는 높은 메모리 코스트를 요구하기 때문에, 효율적인 Video Encoder를 선택하는 것 또한 하나의 과제입니다. 아직 어떤 이미지 또는 비디오 인코더가 video LMM에 적합한지 모르기 때문에, 다양한 언어 지도 학습(language-supervised) 및 자기 지도 학습(self-supervised) 방식의 비디오/이미지 인코더들을 대상으로 실험을 진행했습니다. (데이터셋은 이전에 저자들이 제안한 ApolloBench입니다.)
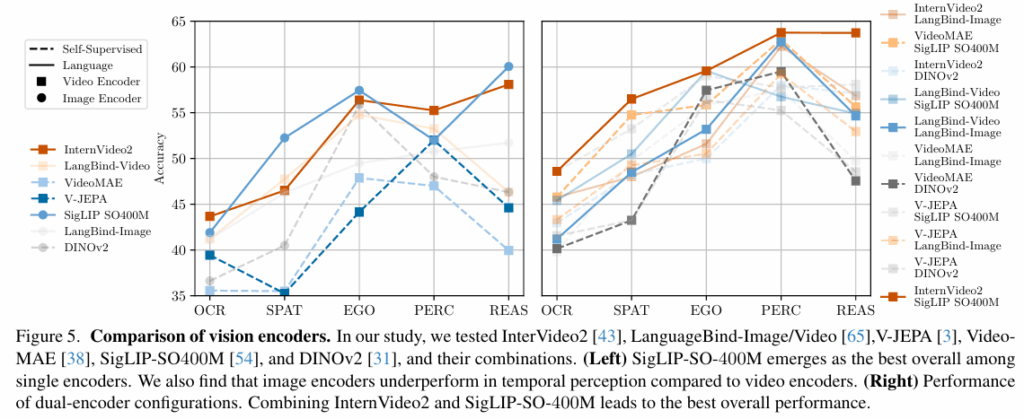
왼쪽 그래프는 single encoder 비교 실험, 오른쪽 그래프는 single encoder의 combination으로 구성한 dual encoder 비교 실험입니다. 결과적으로, language-supervised 인코더가 self-supervised 인코더보다 전반적으로 좋은 성능을 보여주었으며, 모든 이미지 or 비디오 인코더 중에서 이미지 인코더인 SigLIP-SO400M이 가장 좋았다고 합니다. (비디오 인코더는 이미지 인코더를 전체적으로 대체할 수 있도록 분발해야 된다고 하네요,,)
또 저자들은 이미지 인코더와 비디오 인코더를 같이 사용하면 서로의 단점이 상호 보완되지 않을까 라는 가정을 하고 듀얼 인코더 실험을 진행했습니다. 두 개의 인코더를 사용하고, 각 인코더에서 나온 임베딩 벡터를 interpolate+channel wise concat하는 방식으로 구성했습니다. 전반적으로 단일 인코더를 사용했을 때보다 듀얼 인코더를 사용했을 때 성능이 더 좋았으며, best는 InternVieo2(비디오)+SigLIP-SO400M(이미지) 이라고 합니다.
Video Token Resampling
비전 인코더의 출력 임베딩은 대개 LLM의 은닉층 차원보다 낮기 때문에, 이를 모델의 입력으로 넣기 위해서는 2~4배 정도의 up-projection 과정이 선행되어야 합니다. 초기에는 모든 비주얼 토큰을 LLM 공간으로 직접 투영했으나, 이 경우 정보의 양은 그대로인 반면 토큰 개수에 비례해 불필요한 부가 정보만 늘어나면서 ‘정보 병목(Information Bottleneck)’ 현상을 초래하게 됩니다. 다행히 이미지 LMM 연구를 통해 시각적 토큰을 리샘플링하더라도 성능 하락이 크지 않다는 점이 입증되었으며, 이는 특히 비디오 모델에서 매우 중요한 의미를 갖습니다. LLM의 컨텍스트 윈도우는 한정되어 있기 때문에, 다운샘플링을 통해 프레임당 토큰 수를 줄여야만 더 많은 프레임 정보를 수용하여 훨씬 긴 비디오를 처리할 수 있게 되기 때문입니다.
리샘플링 방식 중 Q-Former와 같은 텍스트 가이드 방식은 특정 질문에 맞춰 정보를 압축하기 때문에, 맥락이 계속 변하는 멀티턴 대화에는 적용하기 어렵다는 한계가 있습니다. 이에 따라 Apollo 모델은 듀얼 인코더에서 추출한 특징들을 채널 방향으로 결합(Channel-wise Concat)하여 하나의 토큰으로 통합한 뒤, 세 가지 리샘플링 방법론을 실험했습니다.
- MLP up-projection + average pooling
- 2D Conv + average pooling
- Perceiver Resampler → outperform
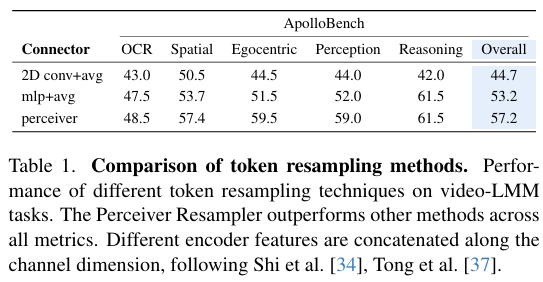
그 결과, Perceiver Resampler가 정보의 손실을 최소화하면서도 핵심적인 시각 정보를 가장 잘 추출하여 모든 지표에서 가장 뛰어난 성능을 보임을 확인했습니다.
Video Token Integration
리샘플링했던 비디오 토큰을 LLM이 이해할 수 있게 textual한 input sequence로 ‘합치는’ 과정입니다. 저자들은 강건한 통합 전략을 확인하기 위해 4가지 방법을 시도했습니다.
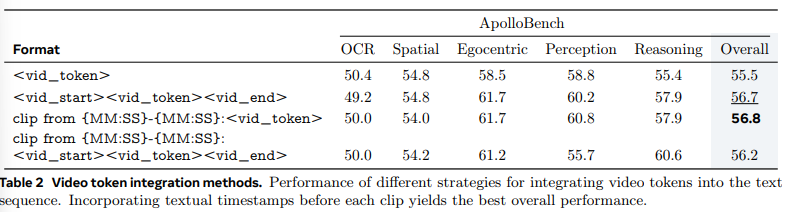
- direct insertion : 말 그대로 비디오 토큰을 쭉 이어붙여 입력
- Separation tokens : 토큰의 시작과 끝을 구분하는 토큰으로, 각 토큰의 의미는 모델이 학습해야 합니다.
- Textual Timestamps : 텍스트 형태로 타임스탬프를 붙여주는 방법입니다.
- Combination : SEP token + 타임스탬프 섞어 쓰기
결과는 비디오 토큰들 사이에 텍스트나 학습 가능한 토큰(Separation token)을 넣어주는 것이 2~3%의 성능 향상을 가져왔다고 합니다. 그래서 저자들은 학습을 필요로 하는 SEP token을 없앤 timestamp를 선택하여 token integration을 수행했습니다.
▪︎ How should Video-LMMs be trained?
비디오 LLM은 어떤 순서와 방법으로 학습해야 하는지를 탐구하기 위해 여러 실험을 진행한 파트입니다.
Training Schedules
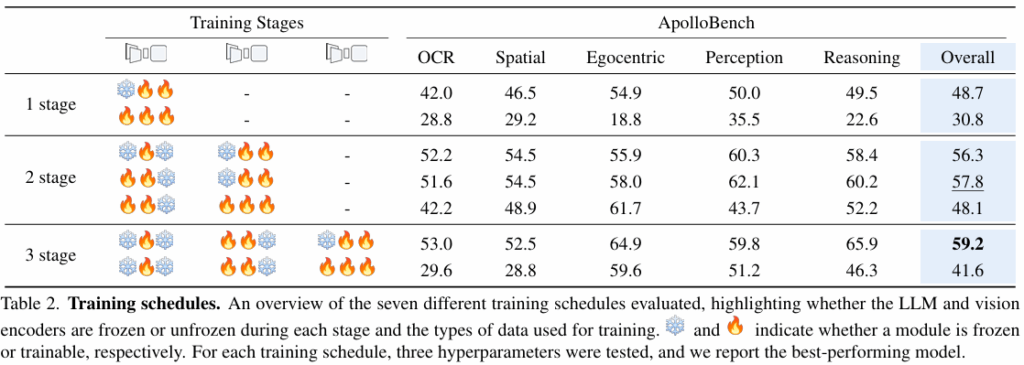
Video LMM에서 학습 대상으로는 인코더, Resampler, LLM이 있고, 이들의 학습 순서와 stage 수를 다르게 해서 실험을 진행했습니다. Table ❄️/🔥는 나열 순서대로 encoder/resampler/LLM을 의미합니다.
먼저 3 stage의 위쪽 스케줄처럼 각각을 점진적으로 학습시키는 것이 가장 성능이 좋았습니다. 또한 three stage 이상으로 구성했을 때 성능이 가장 좋았다고 합니다. stage를 여러 단계로 구성할 때는 각 stage마다 데이터 구성을 다르게 가져갔는데, 예를 들어 LLM이 freeze라면 encoder와 resampler는 비디오 데이터로만 튜닝되고, LLM을 학습시킨다면 텍스트+이미지+여러 장 이미지+비디오 의 혼합된 데이터를 사용했습니다.
Training Video Encoders
위에서 LLM의 freeze 여부에 따라 사용되는 데이터 구성이 달라진다고 했었는데, 만약 인코더와 LLM이 모두 unfreeze라면 인코더는 이미지와 비디오 데이터 모두 사용하여 튜닝됩니다. 저자들은 이것이 LLM의 성능을 하락시킨다고 합니다. 하지만 인코더를 학습시키는 것은 egocentric reasoning(1인칭 시점 영상 추론)에서 큰 성능 향상을 가져오기 때문에, 저자들은 LLM 따로, 인코더 따로 훈련시키는 방식을 선택했습니다
Data Composition
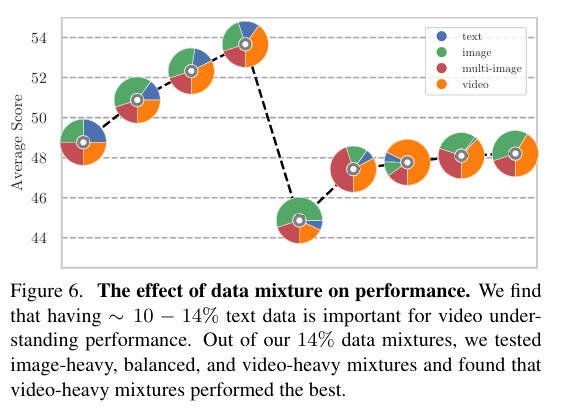
텍스트, 이미지, 비디오 데이터를 어떤 비율로 혼합해야 video LMM 성능에 좋은 지 분석하는 파트입니다. 여러 데이터 구성을 무작위로 선택해서 실험을 진행했습니다. 먼저 텍스트 데이터는 10~14% 정도만 포함하는 것이 필수적이었는데, 저자들은 이 정도 비율이 LMM의 catastrophic forgetting을 완화해주기 때문인 것으로 예상합니다. 또한 나머지 모달리티 중에서는 비디오의 비중을 약간 높게 가져가는 것이 가장 좋았습니다.
Apollo : family of Video LLMs
지금까지 분석했던 내용들의 인사이트를 바탕으로 저자들은 Apollo라는 family of video LMMs(직역하면 모델 시리즈?? 모델 군..??)를 제안합니다. 지금까지 살펴본 대로 다음과 같이 모델을 구성했다고 합니다.
- LLM 백본 : Qwen2.5 1.5B, 3B, 7B
- 인코더 : SigLIP-SO400M(Image-Text), InternVideo2(Video encoder)
- 각 인코더가 출력한 피처들은 interpolate+channel-wise concat
- 32 tokens/frame으로 resampling(downsampling)
- 3 stage training schedule
데이터셋은 텍스트, 이미지-텍스트, multi-image, 비디오 데이터를 혼합했고, 비디오 데이터와 LLaMA3.1 70B 모델을 가지고 multi-turn 대화를 통한 annotation을 구성했다고 합니다.
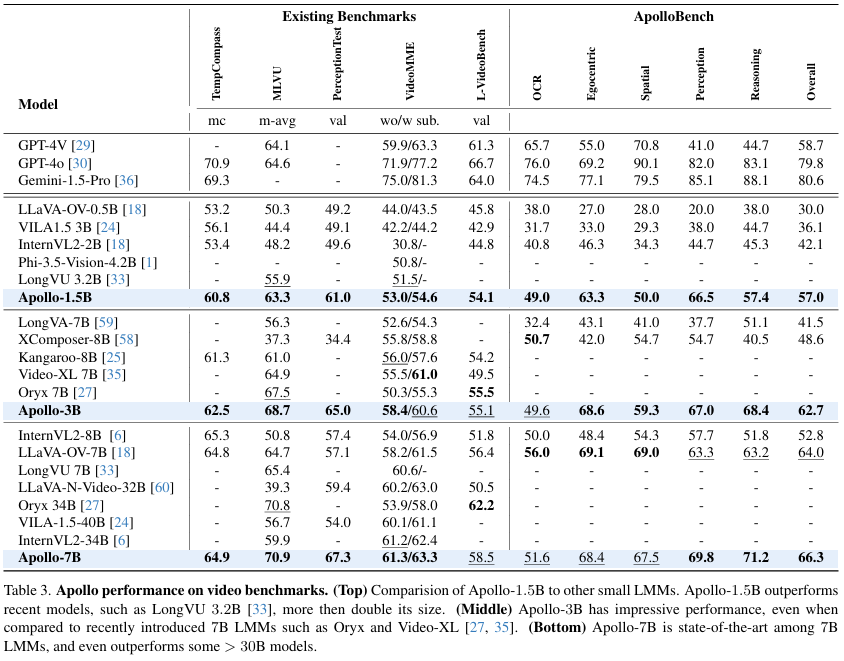
성능 비교 결과는 위의 Table 3에 명시되어 있고, 여기서 저자가 강조하는 점은 Apollo의 smaller model이 다른 기존의 larger model 성능을 앞섰다는 점입니다. 예를 들어, Apollo-3B 모델은 기존의 다른 7B 모델들보다 높은 성능을 보여주었으며, 7B SOTA 모델이 된 Apollo-7B은 다른 30B 모델의 성능도 뛰어넘었을 정도로 좋은 성능을 보였다고 합니다. 이를 통해 작은 모델로도 PoC(proof of concept) 구현에는 충분할 수 있다는 것을 시사합니다.
Conclusion
본 논문은 아키텍처부터 데이터 배합까지 비디오 LMM의 설계 전반을 재검토하여, 효율적인 모델 개발을 위한 명확한 가이드라인을 제시했습니다. 저자들이 개발한 Apollo는 정교한 설계와 훈련 전략이 무조건적인 모델 크기 확장보다 중요하다는 것을 입증했습니다. 실제로 Apollo-3B는 대부분의 7B 모델을, Apollo-7B는 최신 30B 모델들을 압도하며 ‘체급을 뛰어넘는 성능’을 달성했습니다. 또한, 작은 모델에서의 실험 결과가 큰 모델에도 유효하다는 Scaling Consistency와 새로운 벤치마크ApolloBench를 제안하여 연구 진입 장벽을 낮추는 데 기여했습니다. 결론적으로 이 연구는 효율적인 설계만으로도 SOTA 성능 달성이 가능함을 증명하며 비디오 LMM 연구의 새로운 이정표를 세웠습니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
Video Token Resampling 부분에서 Q-Former 같은 텍스트 가이드 리샘플링은 멀티턴 대화로 일반화가 어렵다고 설명하셨는데, Table 1의 성능 비교는 멀티턴 대화가 포함된 벤치마크인지, 아니면 단일 턴 QA 중심인지 궁금합니다.
또한 Table 1에서 사용한 Perceiver Resampler는 Q-Former처럼 텍스트 의존적으로 토큰을 줄이는 방식인지, 아니면 텍스트와 독립적인 고정 latent 기반 리샘플링인지도 궁금합니다.
감사합니다.
안녕하세요 의철님, 좋은 질문 감사합니다.
1) Table 1에서 평가에 쓰인 ApolloBench는 객관식 위주의 벤치마크로 멀티턴 대화가 포함되지는 않았습니다. 여기서 멀티턴 대화에 약점을 보인다고 언급한 이유는 토큰이 첫 번째 질문에 맞춰 다운샘플링 되기 때문입니다. 멀티턴 대화의 경우 Apollo 계열 모델을 학습시킬 때 학습 데이터의 늘려주기 위한 용도로 사용되었습니다.
2) perceiver resampler는 고정 latent 기반 리샘플링으로, latent query가 입력 토큰과 cross attention을 수행하여 고정된 개수의 토큰으로 resampling하는 방법론입니다.
안녕하세요 재윤님. 좋은 리뷰 감사합니다.
1) Video Token Resampling에서 perceiver가 정확히 어떤 리샘플링 방법인가요? 또한 해당 방법이 mlp+avg 방식에 비해 나머지 모든 카테고리에서 더 나은 성능을 보이는데 왜 reasoning 카테고리만 성능 차이가 없는건지 재윤님의 생각이 궁금합니다.
2) 비디오 데이터셋을 잘 몰라서 드리는 질문인데요, 텍스트와 비디오 외에 image-text, multi-image는 무엇인지 궁금합니다.
감사합니다!
안녕하세요 예은님, 좋은 댓글 감사합니다.
1) Perceiver Resampler는 저도 자세히 알아보진 않았지만, 나이브하게 설명드리면 고정 latent 기반 리샘플링(다운샘플링)으로, 고정된 개수의 학습 가능한 쿼리가 입력 토큰과 cross-attention을 수행해서 더 적은 개수의 토큰에 입력 토큰 정보를 담도록 downsampling합니다. 제가 생각했을 때 reasoning에서 mlp+avg방식이 perceiver resampler와 비슷한 성능을 보인 이유는, reasoning은 비디오의 전역적인 맥락 파악을 물어보는 질문들이 많이 분포하는데, 이때 mlp+avg 가 방법론적으로 semantic한 맥락을 잡는데는 이점이 있어 꽤 괜찮은 성능이 나오지 않았나 싶습니다.
2) image-text는 하나의 이미지와 캡션(or 질문-답변) 쌍으로, 보통 비디오의 프레임이 일반적인 정지 이미지보다 화질이 떨어지는 경우가 많아 사물을 정확하게 식별하는 능력을 학습시키는 용도로 사용합니다. multi-image는 이미지 여러 장을 넣어 여러 시각 정보 간의 상관관계를 파악하도록 합니다.
안녕하세요 재윤님 글 잘 읽었습니다.
몇가지 질문이 있는데 우선
1. 500K 데이터셋이 충분하다는 것으로 판단되는데 이게 dataset마다 편차가 존재하는 것은 아닐지 궁금합니다.
2. Scaling Consistency라는게 사전학습된 모델에서만 성립하고 스크래치부터 학습하는거에서도 보장되는건지?
3. FPS 방식과 uniform 샘플링 방식이 영상의 길이에 따라 뭐가 더좋은지는 달라질 수 있는게 아닌가?
각각에 대한 재윤님의 생각이 궁금합니다.
안녕하세요 재윤님 리뷰 감사합니다
Scaling Consistency가 작은모델에서 잘 되는 설계는 큰 모델에서도 잘 된다!! 라는 주장인것 같은데, 혹시 작은 모델에서의 설계효과가 왜 큰 모델에서도 동일한 방향으로 나타나는지 논문에 구조적인 설명이 있는지 궁금합니다.
단순히 실험해보니까 비슷하게 나왔다는건지 아니면 모델 구조나 표현학습 관점에서 설명이 가능한 부분인건지.. 따로 설명이 없다면 재윤님은 어떻게 생각하시는지 궁금합니다.