해당 논문은 작년 10월에 아카이브에 공개된 논문으로, MLLMs에 대한 도구 이해 능력을 평가하였다는 점에서 궁금하여 읽게 되었습니다. 어디에 제출하였는지는 잘 모르겠지만, 난이도에 대하여 단계적으로 구분한 것과, 실험 결과들을 잘 정리하여 좋은 인사이트를 제공하는 것 같습니다.
Abstract
도구를 사용하고 이해하고, 만들어내는 능력은 인간 지능의 특징이며, 이를 통해 물리적 세계와 정교하게 상호작용이 가능합니다. 범용 에이전트가 진정하게 다재다능하기 위해서는 이러한 능력이 확보되어야 하며, 최근 MLLMs의 일반화된 상식을 활용한 high-level planning을 수행하였으나, 물리적 도구에 대한 이해 능력을 정량화는 이루어지지 않았습니다. 따라서, 해당 논문은 MLLMs의 물리적 도구 이해 능력을 평가하기 위한 최초의 벤치마크인 PhysToolBench를 제안합니다. 해당 벤치마크는 1,000개 이상의 이미지-텍스트 쌍으로 이루어진 Visual Question Answering 데이터 셋 형태로 구성되며, 3가지 난이도에 걸쳐 능력을 평가합니다. (1) 도구 인식-도구의 주요 기능 인식, (2) 도구 이해-도구 작동 원리를 파악, (3) 도구 생성: 주변 객체로부터 새로운 도구를 만드는 능력. 해당 논문은 closed model/open-source/specialized embodied, VLA의 백본 등 32가지 MLLMs를 이용하여 비교 실험을 진행하며, 도구 이해 능력에 상당한 부족함이 있음을 확인하였으며, 심층적인 분석과 해결책을 제안합니다.
Introduction
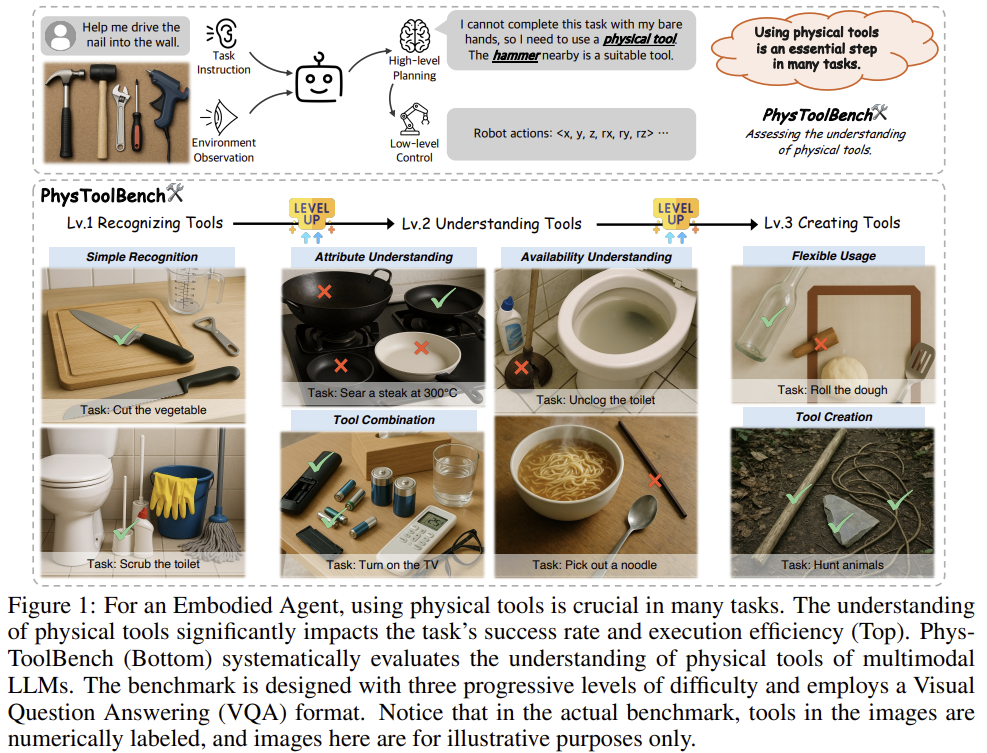
인간이 도구를 만들고 사용함으로써 발전해왔으며, 이러한 능력은 물리적 작업을 수행하도록 설계된 embodied intelligent agent에게 필수적입니다. 위의 Figure 1과 같이, 로봇이 벽에 못을 박기 위해서는 맨 손이 아닌 망치를 사용해야 하며, 이러한 물리적 도구를 이해하는 것은 중요합니다.
시각 및 언어 정보를 모두 사용할 수 있는 MLLMs는 방대한 데이터로부터 학습을 통해 광범위한 지식을 습득하였으며, 이러한 지식을 로보틱스 분야에 활용하기 위한 연구들이 활발히 이루어지고 있습니다. 일부 연구는 MLLMs로부터 high-level planning을 수행하며, 다른 연구에서는 MLLMs를 VLA의 백본으로 활용하여 low-level control에 사용합니다. 이러한 연구들은 결국 물리적 세계와의 상호작용을 기반으로 하며, 이는 필연적으로 물리적 도구를 사용해야합니다. 일부 연구들은 MLLMs가 도구에 대한 이해가 있음을 보여주고 있으나, 물리적 도구에 대한 깊은 수준의 이해는 아직 연구가 부족한 상태입니다.
따라서, 해당 논문은 에이전트들이 물리적 도구에 대한 이해 능력을 평가하기 위해 PhysToolBench라는 벤치마크를 제안합니다. PhysToolBench는 에이전트의 도구 이해 능력을 평가하기 위한 최초의 벤치마크이며, 에이전트의 실제 능력을 평가하기 위해 로봇이 실제 작업을 수행하는 과정을 시뮬레이션하여 Visual Question Answering 데이터 셋을 설계하였습니다. 작업과 물체 이미지가 주어졌을 때, 적절한 도구를 선택해야하며, 위의 Figure 1의 하단 예시와 같이 3단계로 도구에 대한 이해 능력을 점진적으로 평가합니다.
- Easy(Recognizing Tools): 일반적인 도구와 도구의 주요 기능 식별 가능한지 판단 ←도구에 대한 기본적 이해
- Medium(Understanding Tools): 기능적으로 유사한 옵션에서 최적의 도구를 선택 / 작업에 필요한 모든 도구를 선택 / 각 도구의 물리적 상태에 기반하여 도구의 작동 가능성을 평가 ←도구에 대한 심화된 이해
- Hard(Creating Tools): 에이전트의 창의적 능력을 평가하기 위, 작업에 대한 일반적은 도구가 주어지지 않았을 때, 사용 가능한 물체를 재활용하거나 결합하여 해결책을 찾을 수 있는 지 평가 ←도구의 근간이 되는 물리적 원리에 대한 이해를 요구함
저자들은 32가지의 MLLMs에 대하여 물리적 도구 이해 능력을 평가하였으며, 실험 결과 가장 발전된 최신 모델 조차 63%의 점수를 나타내었으며, 이는 사람의 이해 숙련도인 90% 이상과 비교하였을 때, 큰 차이가 있음을 보여줍니다. 저자들은 분석을 통해 MLLMs이 다음의 문제가 있음을 밝혔습니다. 먼저, VLA 모델에 포함된 소형 MLLMs가 도구에 대하여 스스로 이해하는 능력이 없다는 것이며, 광범위한 도구를 인식하고 이해하는 데 있어 long-tail 분포 문제가 존재한다는 것, affordance와 avaliablity를 착각하는 경향이 있다는 것, 마지막으로 시각적 추론 능력이 부족하다는 것 입니다. 따라서 저자들은 MLLM 에이전트의 시각적 추론 능력을 강화하기 위한 vision-centric reasoning 프레임워크를 추가로 제안하며, 물리적 도구에 대한 이해에 대한 영감을 주고자 하였습니다.
The PhysToolBench
overview
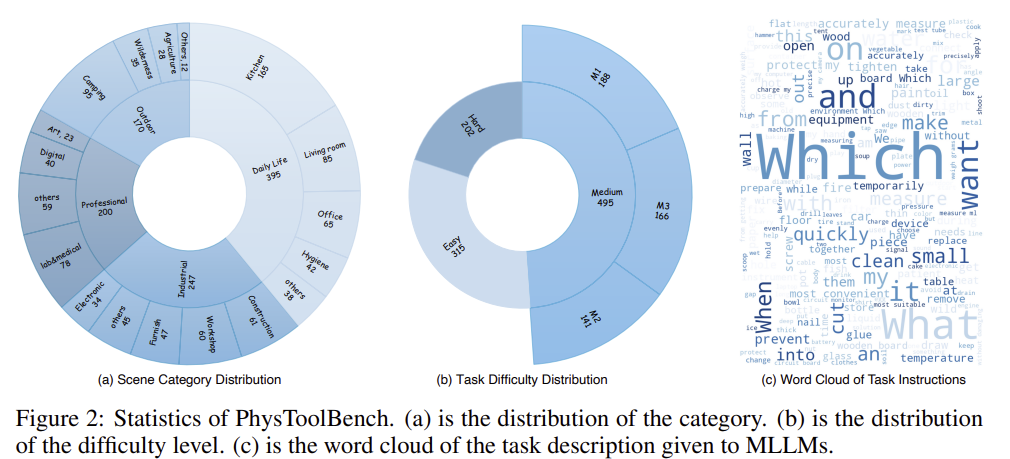
PhysToolBench는 VQA 벤치마크로 1,000개의 text-image 쌍으로 이루어져있으며, 각 쌍은 작업에 대한 텍스트 프롬프트와 여러 숫자 라벨이 지정된 tool 및 object를 1024×1024 해상도의 이미지에 표시되어있습니다. MLLMs는 이미지에 묘사된 물체 항목만 사용 가능하다는 제약을 받으며, 이를 기반으로 작업과 시각 정보를 분석하여 필요한 도구의 숫자 라벨이나 적합한 도구가 없을 경우 None을 반환하도록 합니다. PhysToolBench는 일상생활/산업/야외활동/전문환경 4가지 환경과, easy/medium/hard 3가지 난이도로 구성되어있으며, 해당 벤치마크에 대한 수치적 통계는 아래의 그래프에서 자세하게 확인하실 수 있습니다.
Design Principles
MLLMs의 도구에 대한 이해 능력 평가를 위해 PhysToolBench는 3단계로 구성됩니다. 1단계인 Easy는 기본적인 도구 식별 능력 및 상식적인 답변을 할 수 있는 지를 나타냅니다. 예를 들어, “채소를 자르기”라는 작업과, 주방 이미지에 칼이 포함되어있을 때 이를 인식할 수 있어야 합니다.
2단계인 Medium은 보다 깊은 이해를 요구하며, 특정 작업에 대한 제약 조건을 기반으로 한 추론이 요구됩니다. Medium은 그 안에 3가지 종류로 나누어집니다. 먼저, M.1은 도구의 속성을 이해해야 하며, M.2는 새로운 기능을 위해 다른 도구를 조합할 수 있어야 합니다. 마지막으로 M.3는 가능하지 않은 도구를 인식하는 것 입니다. 순서대로 예시를 들어보며, M.1은 채소를 자를 때, 빵칼과 쇠칼이 있으면, 쇠칼을 선택할 수 있어야 하고, M.2는 리모컨에 배터리를 넣고 이용한다는 것을 인식할 수 있어야 하는 것, M.3는 한 쌍이 없는 젓가락은 사용할 수 없다는 것을 인식할 수 있어야 한다는 것 입니다.
3단계인 Hard는 주변 객체를 창의적으로 활용할 수 있어야 하며, 예를 들어 나사를 조이기에 적당한 드라이버가 없다면, 동전을 사용하는 등의 대체품을 제시할 수 있어야 하는 것 입니다.
Dataset Collection Process
데이터 수집은 품질을 보장하기 위해 3단계를 거쳤다고합니다. 먼저, 사람이 작업 요구사항과 상세한 장면 설정으로 구성된 작업-장면 쌍을 설계한 뒤, 각 시나리오를 Easy/Medium/Hard 3단계 난이도에 맞춰 설계합니다. 이후 장면 설명을 GPT-4o-image에 입력하여 시각적 이미지를 생성한 뒤, 이를 사람이 직접 검토하였다고합니다. 이렇게 수집된 데이터는 전체의 90%이며, 너무 복잡하여 생성이 어려운 나머지 10%는 직접 배치하여 사진을 촬영하였다고합니다. 마지막으로 annotation은 아래의 예시와 같이 툴을 이용하여 사람이 직접 영상 내 객체에 숫자 라벨을 적용하였다고 합니다.
Experiments on PhysToolBench
아래의 4가지 카테고리의 32개의 MLLMs를 평가에 사용하였습니다. (각 항목은 이미지를 참고해주세요!) 모든 모델에 동일한 프롬프트를 사용하였으며, Chain-of-Thought 방식으로 답변하도록 최종 답변 전에 추론하도록 명시적으로 제시하였다고합니다. 다만, 내부적으로 ”thinking” 하도록 설계된 경우에는 기본 추론 과정을 하도록 허용하였다고 합니다. 또한, 5명의 인간 참가자를 모집하여 human의 물체에 대한 이해 능력도 함께 보여주었다고 합니다.
- General-Purpose Proprietary MLLMs : 해당 모델들은 API를 이용하여 평가
- General-Purpose Open-Source MLLMs
- Embodied-Specific MLLMs
- MLLM Backbones of Vision-Language-Action(VLA) models
Overall Results
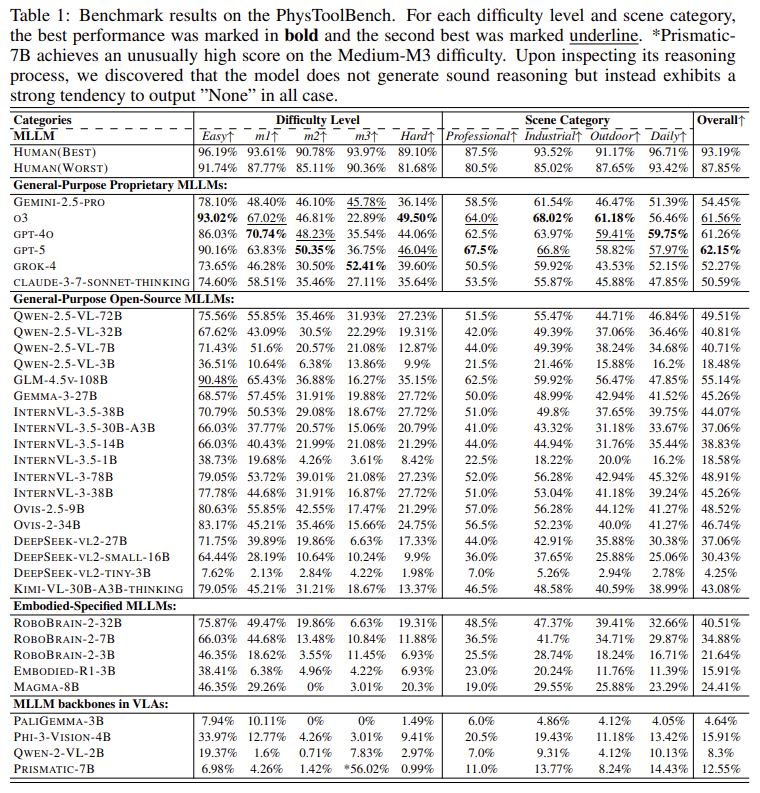
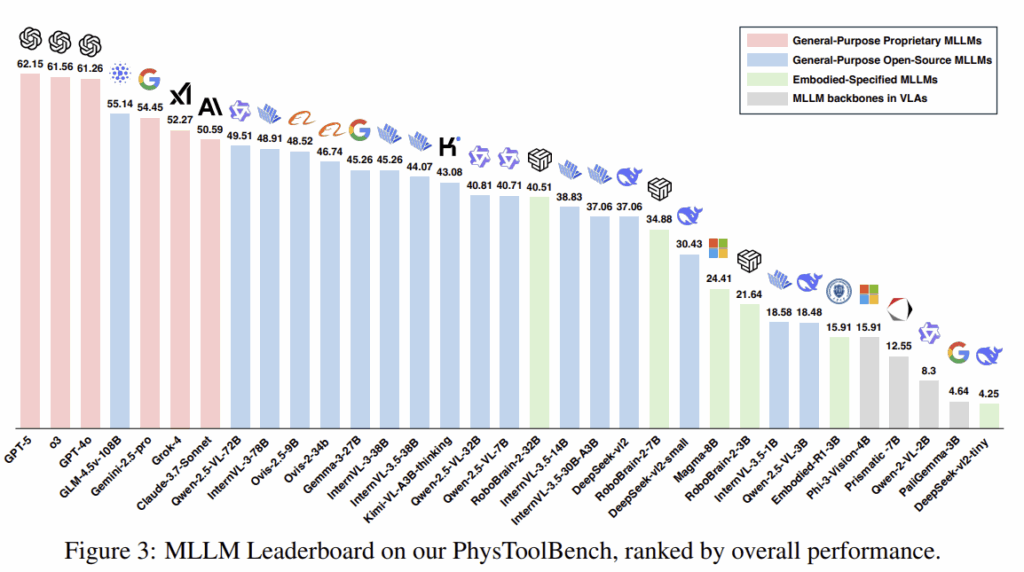
위의 Table 1은 32개 모델에 대한 전체적인 성능을 나타낸 것으로, MLLMs의 성능이 전반적으로 60%에 못미치는 성능을 보이는 것을 확인할 수 있습니다. 최소 87.85%인 사람에 비하면 월등히 낮은 성능으로, 아직 MLLMs 모델들이 도구 활용에 대하여 이해가 충분하지 않다는 것을 보여줍니다. 평가 모델 중 General-Purpose Proprietary MLLMs에서 대체로 좋은 성능을 보였으며, OpenAI 시리즈가 모두 60% 이상의 성능을 보였다는 것이 두드러집니다. Open-source MLLMs가 두번째로, 일반적으로 40% 이상의 성능을 보였으며, 다음은 Embodied-Specified MLLMs, VLA의 백본이 가장 낮은 성능을 보였습니다. 이에 대해 저자들은 파라미터가 제한적이기 때문으로 보았으며, 아래의 그래프는 성능에 대하여 정렬하여 나타낸 것 입니다.
Findings on PhystoolBench
1. A foundational ability to understand tools emerges in large models with sufficient scale.
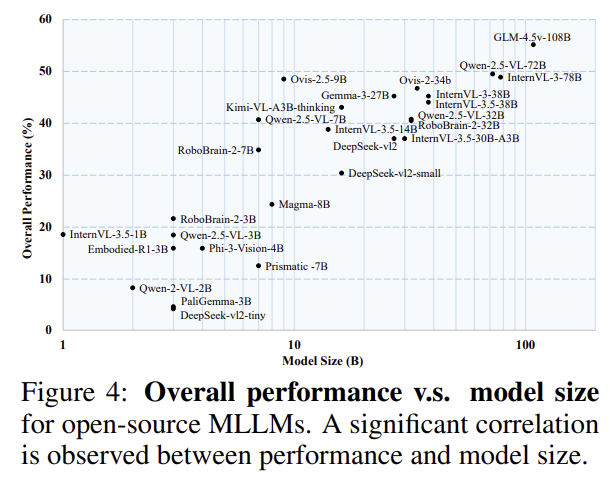
Figure 4에서 확인할 수 있듯이, open-source 모델에서 도구에 대한 이해 능력은 모델 크기와 상관관계가 있다는 것을 확인할 수 있습니다. 또한, Table 1의 easy 케이스에 대해서는 모델이 특정 규모 이상일 경우에는 기본적인 도구에 대한 이해 능력이 있다는 것을 확인할 수 있으며, 이는 약 100억개의 파라미터를 넘는 경우인 것 관찰됩니다.이러한 경우 easy에 대해 60~70%의 정확도를 달성하며, 작은 모델일 경우 성능이 크게 저하되어 5B 미만의 모델은 50% 미만의 성능을 보이고 overall에서 25% 미만의 성능을 보였습니다. 따라서, 저자들은 이러한 관찰을 기반으로 100억개 이상의 매개변수를 가진 MLLMs를 선택하는 것을 권장합니다.
2. A long-tail problem persists in tool recognition and understanding, even for the most advanced MLLMs.

가장 발전된 MLLMs는 일반적인 객체 식별에는 좋은 성능을 보이지만, 익숙하지 않은 항목에 대해서는 성능 저하가 발생하였다고합니다. 특지 디지털 제품에 대한 구분을 어려워하는데, HDMI나 DP케이블, Type-C 와 Lightning 충전 포트와 같이 시각적으로 유사한 항목을 잘 구분하지 못하며, 이는 위의 Figure 6의 (c)에서 확인할 수 있습니다. type-c 포트만 있는 노트북은 HDMI 케이블과 어뎁터를 이용하여 연결해야한다는 요구사항을 인식하지 못한다는 것 입니다. (굉장히 복잡한 이해 능력을 요구하기는 하는 것 같습니다.)
3. Embodied-specific MLLMs show no significant advantage on PhysToolBench.
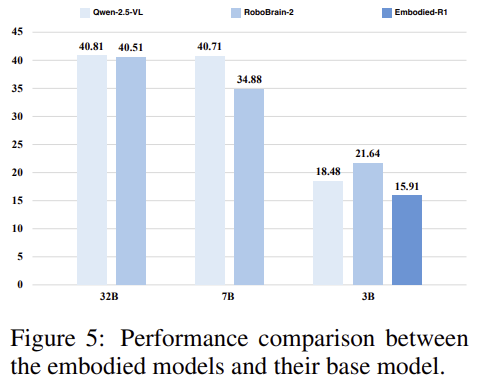
RoboBrain2와 Embodied-R1과 같은 embodied에 특화된 모델들은 PhysToolBench 벤치마크에서 주목할만한 성능을 보이지 못하였으며, Qwen2.5VL-3B모델에서 초기화 된 뒤, 미세조정된 RoboBrain2는 Figure에서 확인할 수 있듯 원본 모델보다 약간 낮은 성능을 보여주었으며, Embodied-R1-3B에서도 원본 모델과 유사한 경향을 보이는 것을 확인할 수 있습니다. 미세조정을 수행하며 도구에 대한 이해를 제공하지 못하였다는 것으로 분석하였으며, 저자들은 로봇 데이터가 도구에 대한 이해를 포함하도록 개선될 필요성을 언급합니다.
4. MLLMs exhibit a critical deficiency in comprehending tool availability, failing to grasp the fundamental principles of their utility.
MLLMs는 도구에 대한 기능적 이해가 부족합니다. 저자들이 설계한 Medium의 M.3은 올바른 도구를 작업에 제공하지만, 사용 불가능한 형태로 제시하는 함정을 통하여 이에 대해 조사하고자 하였습니다. Table 1을 보시면 Hard에 비해 M3에서 더 낮은 성능을 보이는 MLLMs가 많다는 것을 확인할 수 있습니다. Figure 6의 (d)는 이러한 예시로, 모든 모델이 도구에 대한 피상적 이해를 기반으로 상식선에서 답변을 하지만, 실제로 사용이 불가능하다는 것을 인식하지 못하는 것을 확인할 수 있습니다. 이는 실제 로봇 작업에서 작업 실패로 연결되는 문제로, embodied AI에서 굉장히 중요한 능력이며, 이를 고도화 하기 위한 연구가 필요하다고 저자들은 주장합니다.
5. The MLLM backbones in current VLAs are extremely weak.
VLA 모델들의 백본이 다른 MLLMs에 비해 성능이 크게 낮다는 것을 통해, VLA가 MLLMs의 상식을 효과적으로 전이받아 일반화를 달성할 수 있다고 하는, 이러한 가정에 대한 의문을 제기합니다. 적당한 규모의 로봇 데이터로 일반화가 어렵다는 것을 통해, 추후 VLA의 연구에 있어 백본을 더 크고 좋은 성능을 보이는 MLLMs로 변경하거나, 로봇 데이터의 크기와 다양성을 확장해야한다고 주장합니다.
6. Reasoning ability is important and useful, but still insufficient.
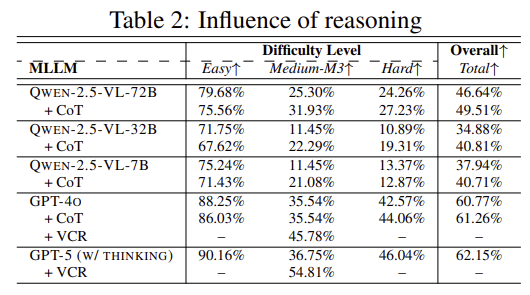
저자들은 CoT 프롬프팅을 사용한 경우와 그렇지 않은 경우에 대하여 평가하였으며, Table 2는 이에 대한 결과입니다. CoT 프롬프팅 방식이 더 좋은 성능을 보였으며, 모델 자체가 추론을 하도록 설계된 경우에 특히 좋은 성능을 보이는 것을 확인하였습니다. 그러나 여전히 추론 능력이 부족하여 특정 작업에 대하여 환각이 생성되기 쉬우며, 공간에 대한 추론 능력도 부족합니다. Figure 6의 (b)와 같이, 어떤 모델도 적절한 크기의 일자 드리아버가 십자 나사를 풀 수 있다는 것을 이해하지 못하였으며, 저자들은 이러한 시각 중심의 추론이 중요하다고 주장합니다.
A preliminary solution
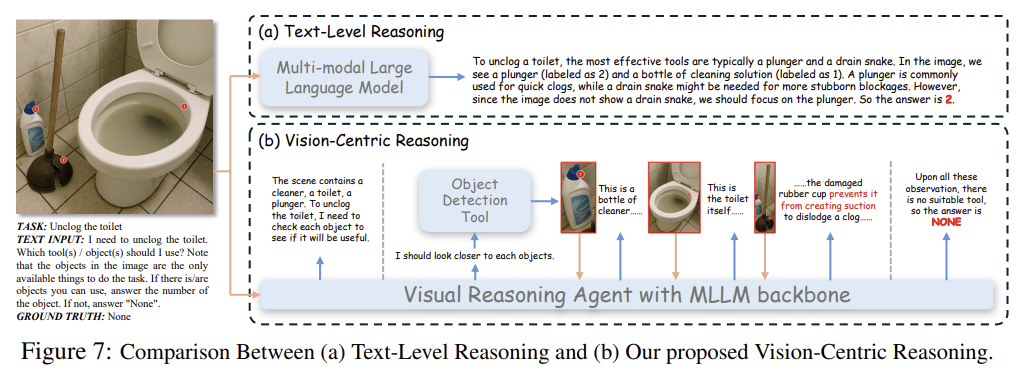
저자들이 주장하는 시각 중심의 추론을 강화하기 위해, 저자들은 위의 Figure 7의 (a)와 같이 시각 정보를 간과하는 경향을 완화하기 위해 Figure 7의 (b)와 같은 시각 중심 추론 에이전트를 개발하였습니다. 답변 과정을 3단계로 구분하였으며, 1단계는 Global Analysis 단계로, 이미지 맥락에서 사용자 쿼리에 대한 전체적 이해를 형성합니다. 두번째 단계는 In-depth Analysis로, 객체 탐지 도구(DINOX)를 호출하여 bounding box를 기반으로 객체를 식별하고 잘라냅니다. 이렇게 잘린 물체들은 심층적 분석을 거치며, 마지막으로 Multi-level Evidence Integration and Reasoning을 수행하여 초기의 global 이해와 잘린 객체에 대한 상세한 분석을 종합하여 답변을 생성하도록 합니다.
Table 2에서 +VCR이 이에 대한 실험 결과로, 가장 성능이 낮았던 M3 난이도에서 평가한 결과로, GPT-4o와 GPT-5는 각각 10.24%와 18.06%의 성능 개선이 이루어졌으며, 이는 시각 중심 추론의 중요성을 나타냅니다.
Conclusion
해당 논문은 MLLMs의 도구에 대한 이해 능력을 평가하기 위한 벤치마크로, PhysToolBench를 제안하였으며, 이는 1,000개의 VQA 데이터 셋으로 구성됩니다. 다양한 시나리오와 세분화된 난이도로 구성되며, closed/open-source/embodied-specified/VLA의 백본 등 4가지 그룹으로 구성된 32개의 MLLMs에 대하여 평가를 수행합니다. 다양한 분석을 통해 아직 도구에 대한 이해능력이 부족함을 보였으며, MLLMs의 한계에 대하여 분석하고 추후 연구가 이루어져야 하는 방향을 제시하였습니다.
안녕하세요 승현님 리뷰 감사합니다.
실험의 3번 인사이트 “Embodied-specific MLLMs show no significant advantage on PhysToolBench.” 를 생각하면 tool use에 대한 이해도 embodied AI가 가져야할 필수적인 능력인게 당연하다고 생각됩니다. 다만 robobrain과 같은 embodied AI를 위한 MLLM의 데이터셋 분석을 보면 affordance 쪽에 나름 힘을 많이 주었다고 생각하는데, 모델의 크기가 커봤자 32B인 것 또한 확인했습니다.
따라서 단지 모델의 크기가 작아 수용력이 부족한 것인지, affordance와 tool use는 구분지어야 한다고 생각하시는지 궁금합니다. Tool use에 대한 성능을 올리는 것이 승현님이 생각하는 affordance에 기여한다고 보면 될까요?
질문 감사합니다.
우선, 해당 논문에서 affordance는 단순히 tool use 뿐만 아니라, 실제 원하는 행동을 수행하는 데 적절한가, 다른 물체들로부터 원하는 작업을 하기 위한 도구를 만들 수 있을 까 하는 관점이 모두 포함되어있어서 조금 더 넓은 범위라고 할 수 있는 것 같습니다. 제가 자주 리뷰하고 실험했던 내용들은 조금 더 한정된 범위에서, 물체에서 어느 부위와 상호작용해야하는지를 인식하는 affordance grounding으로, 레벨상 한 단계 더 들어간 것 같습니다.
또한, tool use에 대한 성능을 올리는 것이 affordance에 기여한다고 생각하는 지 물어보셨는데, 저는 도움이 된다고 생각합니다. 어쨌든 도구와 작업에 대한 이해 능력을 높인다는 관점에서 둘이 동떨어진 연구는 아닌 것 같습니다.
안녕하세요 승현님 좋은 질문 감사합니다.
preliminary solution에서 객체 정보를 추가해서 3단계의 추론을 거쳤을때 추가적으로 성능이 향상되는 경향을 확인할 수 있었는데, gpt 말고 다른 모델에도 적용했을때 추가적으로 성능이 향상되는지 궁금하고, 물체들은 심층적 분석 어떻게 진행되는지도 궁금합니다.
감사합니다.
질문 감사합니다.
우선 GPT가 아닌 다른 모델에 적용한 실험 결과는 따로 없었습니다. 아무래도 gpt에 대한 두가지 버전에 실험 해본것만으로 주장을 뒷받침하기에는 어려움이 있어보이긴 합니다. 해당 논문이 리뷰를 거친다면 보완되지않을까요..?ㅎㅎ
또한, 물체에 대한 심층 분석에 사용된 정확한 프롬프트는 공개가 되어있지 않습니다.. 다만 Figure 7의 예시를 보시면 crop된 이미지에 해당하는 물체에 대해 묘사하도록 되어있는 것 같습니다. 특히 뚫어뻥에 대해서는 고무 부분이 손상된 것 까지 언급하고 있어, 제 기능을 할 수 있는 지 에 대한 검토도 함께 요청되어있지않을까 합니다.