안녕하세요
이번에 소개할 논문은 Long Video Understanding에서 기존 LLM에이전트들이 tool사용 과정에서 발생하는 불확실성과 그로인해 누적되는 오류 문제를 지적하고 이것을 해결하기위해 uncertainty-aware CoT와 plan-adjust기반의 추론 구조를 제안한 VideoAgent2 프레임워크를 다룬 연구입니다.
그럼 논문 리뷰 시작하겠습니다.
Intro
long video understanding task에서 이 장시간 비디오는 컨텍스트의 한계로 인해 한번에 처리가 불가능합니다. 따라서 LLM+tool을 쓰는 Agent방식이 대세로 떠오르고 있습니다
기존의 VideoAgent방식은 그냥 LLM의 추론 능력에만 의존하여 단순히 ‘생각해봐!’같은 수준으로 LLM을 VU에 맞춰서 어떻게 강화할지에 대한 설계가 부족했습니다. 또한 캡션이나 detection등의 오류가 생기면 LLM에 그대로 노이즈가 되어 잘못된 결론을 내리는 등의 외부 tool에 대한 노이즈 이슈도 존재했습니다.
또한 LLM을 사용함에 있어서도 기존의 방식들은 LLM이 현재까지의 정보로 답변을 확정해도 되는지의 self-reflection능력을 고려하지 않았 그 결과 불완전한 정보로 인한 hallucination이 발생할수 있습니다.
이러한 문제를 해결하기 위해 저자들은 Long Video Understanding에 특화된 Uncertainty-Aware CoT 과정을 제안했습니다. 이 방법은 간단하게 말하자면 LLM이 비디오를 이해하는 과정에서 지금 가진 정보로 충분한지를 지속적으로 확인하고 정보가 부족하거나 답변의 신뢰도가 낮다고 판단될 경우 추가로 또 정보를 찾아보면서 답변 추론방식을 수정하도록 만든 chain-of-thought(CoT) 구조입니다. 즉, 한번에 답을 내리기 보다는 대략적인 맥락을 파악하고 → 정보가 부족하면 계획을 세워 추가 탐색을 진행한 후 → 얻은 정보의 신뢰도를 고려해 다시 판단 하는 과정을 반복함으로써 long video에서도 안정적인 답변을 생성하는게 핵심입니다.
Method
VideoAgent2의 핵심적인 방법은 크게 두가지로 나뉩니다.
- plan-adjust CoT 계획을 세우고(Plan) → 새 정보 보고(Info) → 계획을 수정(Adjust) → 더 좁혀서 탐색 하는 과정을 반복합니다.
즉, 사람처럼 탐색 범위를 점점 좁혀가며(coarse→fine) 답에 도달하도록 설계되었습니다. - 불확실성(uncertainty)을 답변 추론에 공식적으로 포함합니다. Tool 선택 결과가 틀릴수도 있으니 결과 텍스트만 보지 말고 신뢰도도 함께보는 방법으로, 이것을 계획 수정하는 단계와 최종 답변을 통합하는 단계에 반영해서 답변을 더 안정적으로 생성하도록 합니다.
- 상태변수 정의 (Bt, Pt, At, cft)는 다음과 같습니다.
시스템 상태는 Bt, Pt, At, cft (1 ≤ t ≤ T)로 표현됩니다.
Bt : 비디오V와 관련된 모든 정보를 저장하는 메모리 뱅크
Pt : 추가 정보 검색하기위한 계획
At : Bt기반으로 생성된 답변
Cft : At의 신뢰도 - VideoAgent2의 파이프라인은 크게 4단계로 나뉩니다
- General context acquisition : 비디오를 대략적으로 파악하는 과정으로 비디오의 전반적인 맥락을 파악합니다
- Answer assessment : 지금 정보로 답이 가능한지 판단하는 과정으로 해당 답의 confidence를 산출합니다
- Plan creation/adjustments: 정보가 부족하다고 판단되면 뭘 더 봐야하는지 와 관련된 계획을 생성합니다
- Information retrieval : 계획에 따라 tool호출해서 추가 정보를 획득합니다
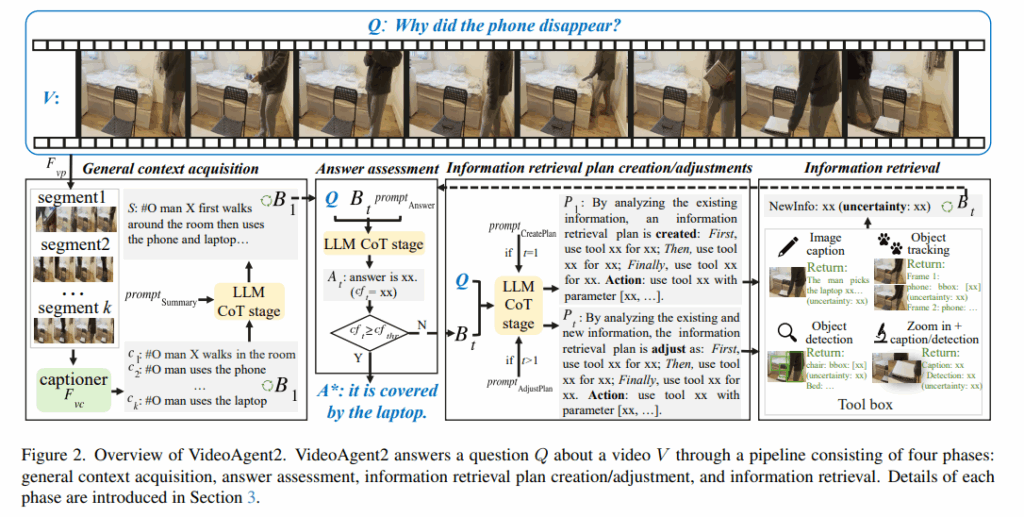
phase1 | General context acquisition
(일반적 맥락정보 획득)
앞서 언급했듯이 사람이 긴 비디오를 이해할때 먼저 대략적으로 비디오를 한번 싹 보고 질문에 따라 필요한 구간을 자세히 골라 본다는 점에서 영감을 받아, 먼저 비디오의 일반적인 전체 맥락 정보(general context information)를 획득하는 단계입니다.
해당 단계에서는 두가지 주요 고려사항을 바탕으로 일반적인 맥락 정보를 얻어야 합니다. 먼저 계산의 효율성(Computational efficiency)으로 해당 단계에서는 너무 세부적인 부분에 집중하지 않고 계산을 최대한 가볍게 유지해야합니다. 두번째로는 정보의 완전성(Integrity of information)으로 이후 뒷 단계들에서 핵심 구간을 놓치지 않도록 정보는 최대한 넓게 포함되어야 합니다
해당 단계에서는 3step으로 진행이되는데
- 비디오 전처리(Downsampling + Segmentation)
길이L초짜리 롱비디오를 프레임 rate를 낮춰서 n초 길이의 연속적인 세그먼트로 분할합니다. - Segment-level Video Captioning
프레임 단위가 아닌 구간별 정보를 보존하기 위해 각 세그먼트마다 경량 비디오 캡셔너를 사용해서 캡션을 생성합니다.
C={c1,c2,…,ck} (k=L/n) - Caption-to-Summary
앞서 뽑은 모든 세그먼트의 캡션C를 LLM에 넣어주어 모델이 모든 캡션을 읽고 CoT프롬프팅으로 통해 전체 비디오의 요약(S)을 생성하도록 합니다.
이 단계들을 거쳐 B1 = {C, S}를 얻게 됩니다. 여기서 C는 캡션들로 답변의 근거가 되는 raw한 정보들이고, S는 LLM이 이해한 전체적인 비디오 맥락입니다.
phase2 | Answer assessment
(답변 평가→ 정보가 충분한지/불충분한지만 가르는 게이트 )
사람들이 질문에 대답할때 보통 본인이 가진 정보가 대답하기에 충분한지를 생각하고 대답한다는 접근을 기반으로, 저자들은 LLM과의 대화 횟수를 줄이기 위해 single-step prediction-evaluation 과정으로 진행합니다.
LLM은 정보 메모리(Bt)에 저장된 모든 정보를 바탕으로 질문 Q에 대한 답변 At를 생성하는데, 이때 동시에 그 답변에 대한 신뢰도 Cft를 0~5의 값으로 함께 생성합니다. 이 신뢰도 점수는 정답일 확률이 아닌, 직관적으로 지금 가진 정보로 판단을 내려도 되는 상태인가! 에 대한 자기 인식 점수입니다.
이 Phase에서는 LLM의 불확실성(self-reflection,자가성찰)을 활용해서 현재의 정보가 대답하기에 충분한지를 판단합니다. 이때 정보가 충분하지 않은 경우에는 LLM이 retrieval plan을 조정하도록 유도하며 도구 호출을 조정하고 정보를 다시 해석하는 반복적인 CoT구조를 구축하도록 합니다.
- Cft≥Cft_thr : LLM이 질문에 답하기에 충분한 정보를 가지고 있다고 판단! 이 경우 현재 답변 At를 A*로 확정한다.
- Cft<Cft_thr : LLM이 답하기에 정보가 부족하다고 판단! 이 경우 Phase3으로 넘어간다.
이때 Cft_thr을 수동으로 지정하는 이유는, 해당 단계가 학습의 대상도 아니고 학습기법(ex. RL)이나 verifier를 붙이면 구조도 복잡해지고 비용적으로도 이득이 없기 때문에 저자들은 추론 구조만을 바꿔서 안정성을 얻어보자! 하는 방향으로 의도적으로 수동 임계값을 선택했다고 합니다.
phase3 | Information retrieval plan creation/adjustments
(정보 검색 계획/생성)
사람은 질문에 대답할때 가진 정보가 충분하지 않다고 판단되면 가진 기억을 바탕으로 되돌아볼 부분을 떠올리고 그 구간을 다시 자세히 관찰합니다. 쉽게 말하자면 정보 부족하네? 그럼 질문에 답하기 위해 이제부터 뭘 어떻게 찾아보지? 하는 계획을 세우는데 phase3에서는 바로 이 과정을 담당합니다
사람의 방식을 예로들자면 “비디오 초반에 남자가 손에 들고있는 사진 속 동물은 무엇임?”이라는 질문이 주어졌을때, 사람은 초반 구간에서 남자를 찾고 → 남자의 손 위치를 찾고 → 손에 들린 사진을 자세히 관찰한다는 계획을 세웁니다.
하지만 실제로는 해당 단계들에서 플랜을 약간씩 조정합니다. 이를테면 구간이 약간 달라질수 있고, 사진이 잘 안보이면 몇프레임 뒤에서 다시 관찰할수도 있고, step이 늘어날수도 있고..!
이 논문에서 저자들이 언급하는 plan-adjust CoT 모드가 바로 이걸 말합니다. Phase1에서 얻은 정보와 질문을 기반으로 먼저 정보를 retrieval할 계획을 세우고, 이후 각 단계에서 새롭게 얻은 정보를 바탕으로 계획을 지속적으로 수정하고 보완하며 탐색을 진행합니다
즉, 고정된 절차를 따르는 것이 아니라 현재까지의 관찰 결과에 따라 retrieval 범위나 순서, 단계를 바꿔가며 점진적으로 필요한 정보를 좁혀가는 구조입니다.
구체적으로 먼저 t=1인 경우에는 시스템이 초기 상태라는 말로 LLM은 phase1의 B1과 질문Q를 기반으로 retrieval 계획 P1을 생성합니다.
t>1인 경우에는 스템이 이미 retrieval 과정을 진행 중이기 때문에 LLM은 Bt와 질문Q를 기반으로 기존 계획 Pt-1을 조정해서 새로운 계획Pt를 생성한다
즉 LLM이 직접 ‘어디를 볼지’와 ‘도구를 어떻게 쓸지’를 판단하고 이후 계획을 조정하게 하는 것으로, 초기 가설이 틀려도 전체 실패로 이어지지 않을 수 있도록 설계됩니다.
phase4 | Information retrieval
(정보 검색)
이 단계에서는 Phase3에서 생각으로 세운 계획을 실제 행동으로 옮기는 단계로, 단독으로 진행되기보다는 Phase2,3과 loop구조로 진행됩니다. 구체적으로 LLM이 현재 계획(Pt)에 따라 하나의 특화된 도구를 호출해서 목표 구간에서 정보를 검색합니다.
이때 그 tool로 인해 결과가 틀릴수도 있고(ex. 이미지 캡션이 잘못 설명함) 이런 경우 계획 수정을 망가뜨려서 점점 엉뚱한 방향으로 오류가 누적될 수 있습니다. 이를 방지하기 위해 tool사용해서 검색한 정보를 보낼 때 그 도구결과에 대한 confidence score를 같이 줌으로 uncertainty를 CoT과정에 반영합니다.
LLM은 다음 단계에서 내용은 그럴듯하지만 신뢰도가 낮으면 덜 믿고 다른 증거를 더 찾거나, 신뢰도가 높으면 그 방향으로 더 계획을 좁혀 나갑니다.
이러한 uncertainty-aware CoT를 통해 계획 조정을 더 안정적으로 할 수 있게됩니다.
phase2에서 생성된 LLM self-confidence(Ctf)와 도구의 confidence가 합쳐져서 LLM 스스로도 의심하고 도구도 의심하는 uncertainty-aware CoT가 완성됩니다

최종적으로 답을 해도 될만큼 확신이 생길때 까지 계획을 세우고 → 찾아보고 → 다시 판단하는 과정을 confidence기반으로 반복하는 위와 같은 알고리즘이 완성됩니다.
Experiment
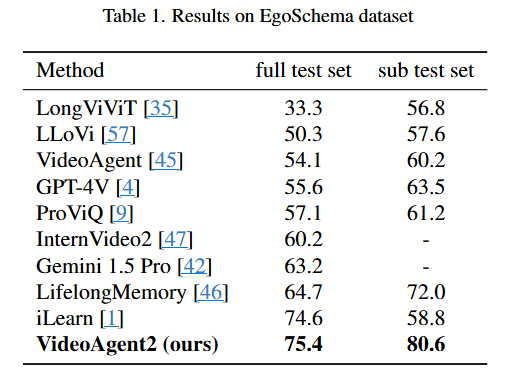
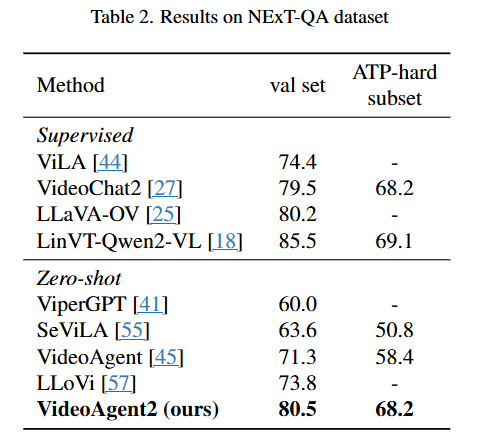
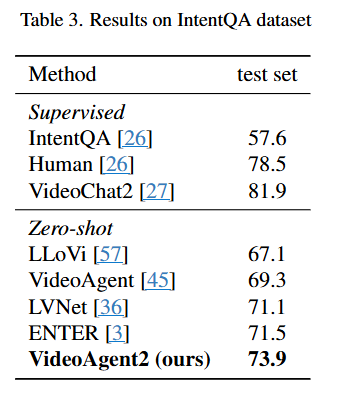
VideoAgent2는 EgoSchema, NExT-QA, IntentQA에서 성능 실험을 진행했고 벤치마크에 대해 추가적인 학습 없이도 기존 Agent기반 방법들에 비해 가장 좋은 성능을 달성했습니다.
[Ablation study]
uncertainty-aware CoT의 역할을 분석하기 위해 네 가지 실험 설정을 비교했습니.
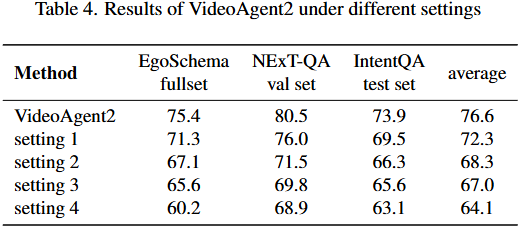
- setting (1) : tool confidence 제거 (도구 불확실성 인식x)
setting (2) : setting (1) + plan-adjust 제거 (LLM이 계획은 한 번 세우고 수정 안 함)
setting (3) : setting (2) + CoT 자체 제거 (LLM이 CoT과정(생각) 없이 tool → 답)
setting (4) : setting (3) + tool 호출 전부 제거 (LLM이 Phase1의 B1만 보고 답)
Table4에서 볼수 있듯이 setting (1),(2)는 VideoAgent2의 성능에 가장 크게 부정적인 영향을 미치며 정확도가 4.3%p, 4.0%p씩 감소한 것을 확인할수 있습니다.
이 결과는 도구의 uncertainty를 정량화하는 과정과 정보 retrieval plan의 반복적으로 조정하는 과정이 uncertainty-aware CoT에서 매우 중요함을 보여줍니다.
또한, setting (3),(4)의 결과는 CoT 기반의 추론 구조 없이 단순히 tool을 호출하거나, tool 자체를 사용하지 않는 경우 성능이 더욱 크게 저하됨을 보여주며 성능 향상이 단순히 도구를 사용했기 때문이 이나리 도구 호출을 계획적으로 조정하고 활용하는 구조적인 설계로 인한 것임을 확인시켜 줍니다.
[Ablation of different LLM]
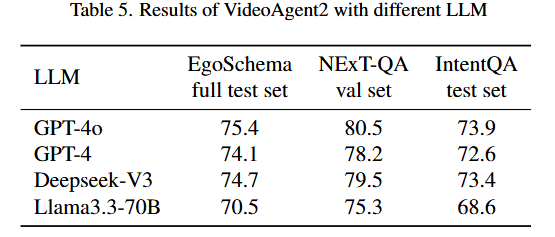
같은 파이프라인(Phase1~4, uncertainty-aware CoT)을 쓰더라도 LLM이 추론이나 계획,판단을 얼마나 잘 하느냐에 최종 정확도가 달라진다는 점을 확인할수 있습니다.
또한 API 기반 상용 모델뿐만 아니라 DeepSeek-V3와 같은 오픈소스 LLM도 충분히 경쟁력 있는 대안으로 활용 가능함을 알 수 있습니다.
(한가지 아쉬운 점은 이 논문이 LLM의 추론 능력 위에 uncertainty-aware CoT의 효과가 결합되어야 성능이 향상된다는 점을 강조하는 만큼 서로 다른 LLM설정에 대해서도 Table 4와 유사한 ablation 실험이 추가로 제시되었으면 제안한 구조의 기여도가 더 일관적으로 검증 될수 있어서 좋았을것 같다는 생각이 듭니다.)
안녕하세요 찬미님 리뷰 감사합니다
Table 1-3 에 대해 질문이 있습니다. 리포팅된 VideoAgent2의 경우 GPT-4o를 기반으로 설계한 에이전트 같은데, 혹시 다른 방법론의 에이전트 모델이 동일한지 궁금합니다
phases2에서 self-reflaction은 프롬프트로 요청한 모델이 출력한 확신도를 사용하는것인가요? 혹시 해당 접근법에 레퍼런스된 연구가 있었는지 궁금합니다.