# 들어가며
오늘 소개드린 논문은 video understanding 수행에 있어서 multi-agent를 사용하는 방법을 소개하는 논문입니다. 논문에 따르면 기존 방식은 추론 과정에서 초기 계획이 변하지 않는 fixed policy 방법이였는데요, 본 논문은 에이전트간의 소통을 통해 도구 사용을 동적으로 수정하는 협업 정책(collaborative policy planning, CPP)를 제안합니다. 즉, 멀티 에이전트를 활용한 비디오 이해 분야에서 에이전트가 문제 해결을 위한 초기 planning을 수정하는 최초의 시도라고 이해하시면 됩니다.
# 방법론
논문이 제안한 프레임워크는 VideoChat-M1입니다. 해당 프레임워크는 앞서 소개드렸다시피 에이전트가 협업을 하는 방법을 제시한 것입니다. 프레임워크 설계를 위해서는 Multi-Agent Reinforcement Learning과 실질적인 협업 방식(CPP)에 대해 알아야합니다. 우선 학습 방법을 먼저 알아보겠습니다.
1) Multi-Agent Reinforcement Learning (MARL)
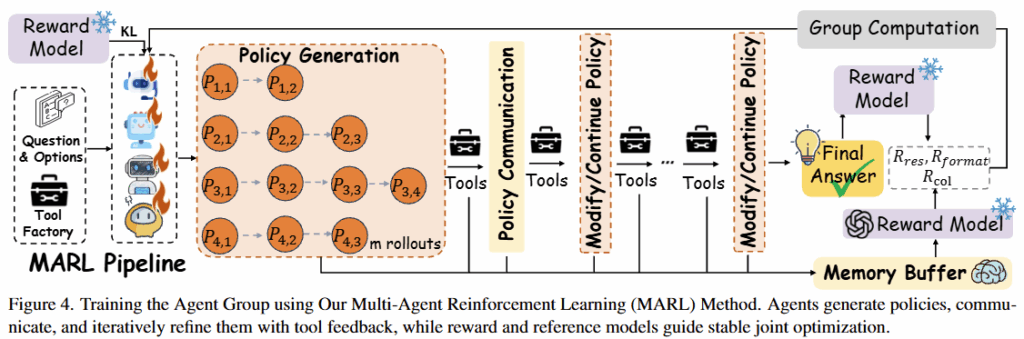
VideoChat-M1의 협업능력 개선을 위해 저자들은 학습 방법인 MARL을 제안했습니다. 저자에 따르면 본 논문이 최초의 multi-agent를 위한 policy learning framework라고 합니다. 많은 agent를 위한 RL 방법과 같이 해당 학습 전략도 warm-up을 위한 SFT(supervised fine-tuning)와 제안하는 RL 방법인 MARL(Multi-Agent Reinforcement Learning), 2 단계로 이루어집니다.
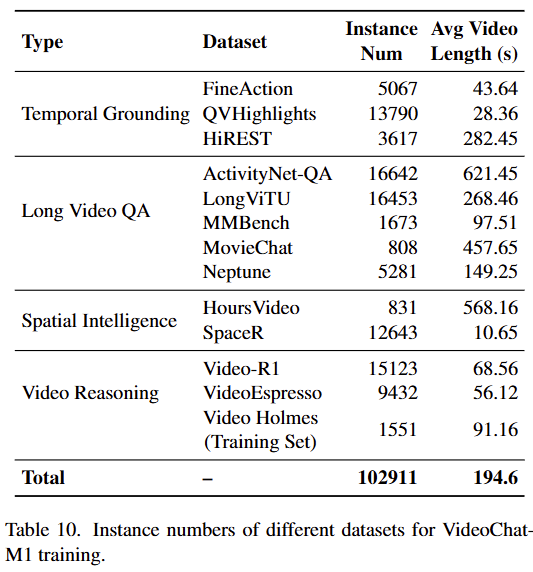
먼저 SFT를 위해 Table10에 정리된 open-source video datasets 을 활용하여 지도학습 가능한 policy set을 구축했습니다. 이때, policy plan에 대한 정답 라벨을 만들기 위해서는 GPT-4o와 DeepSeek-R1과 같은 성능이 좋은 MLLMs을 통해 제안하는 multi agent 소통기반의 예측 전략(CPP)를 수행합니다. 수행 결과가 정답과 일치하며, 협업하였을 때 의견을 수정하지 않은 plan을 GT로 하였습니다(CPP는 협업 기반 전력으로 추론과정 중 적절하지 않은 plan은 수정하게 됨). 학습은 각 agent가 정답 plan과 동일해지도록 cross-entropy loss로 학습했다고 합니다.
위의 방법으로 warm-up 학습을 거친후, 본격적인 RL 학습을 진행하였습니다. 협업을 위한 RL의 Reward는 3개의 보상 조합으로 이루어졌습니다: Result Reward, Format Reward, Collaboration Reward. 1) Results Reward는 프레임워크를 수행했을때(즉 CPP를 통한 예측을 완료했을때) 응답이 정답과 일치하는 여부에 따라 보상으로, 정답일때는 양의 보상 오답일때는 음의 보상을 받게됩니다. 2) Format Reward는 도구를 호출하는 생성의 결과가 실행 가능한 형식인지, 도구 호출에 문제가 없는지를 다루기 위한 것으로 오류가 있을때 페널티(음의 보상)을 받게됩니다. 마지막으로 3) Collaboration Reward의 경우 GPT-4o를 활용하여 협업의 기록을 입력한 후 이에대한 평가를 기반으로 이진 보상ㅡ논리적 일관성이 있을경우 1 그렇지 않으면 0ㅡ을 받게 됩니다. 추가적으로 페널티 텀이 하나더 사용되는데, plan의 결과가 5개 이상의 tool을 호출시에는 강한 페널티를 받도록 설계되었습니다. 협업과정에서 각 에이전트의 메모리가 서로에게 영향을 미치며, 해당 메모리에는 에이전트의 이전 궤적이 들어가있기 때문에 5번 이상의 tool이 호출되는것은 효율성 측면에서 매우 좋지 않기 때문입니다. 위와 같이 설계된 보상을 통해 각 에이전트는 GRPO 방식으로 학습되게 됩니다.
2) Collaborative Policy Planning Pipeline (CPP)
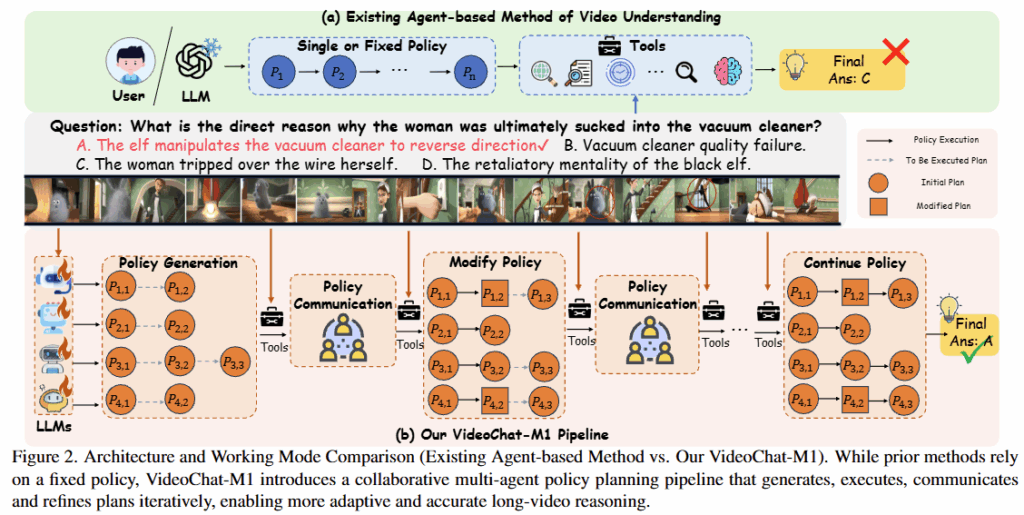
다음으로는 multi agent를 활용하여 실질적으로 응답을 생성하는 방식을 소개합니다. 해당 파이프라인은 Policy Generation, Policy Execution, Policy Communication로 구성됩니다. CPP는 policy agents, video perception tools, memory buffer를 구성요소로 갖습니다. 가장 먼저 policy agents 그룹이 비디오와 질의를 입력받아 policy plan을 생성합니다(policy generation) 이후, 해당 결과중에 첫번째 policy를 수행(policy excution)하고 그 결과를 기반으로 communication을 진행합니다. 이때 communication의 방법은 다음과 같습니다. 에이전트(g1) 은 첫번째 policy (a1) 를 수행한 결과(A1) 를 메모리(M)에 저장합니다. 두번째 에이전트(g2) 역시 자신의 첫번째 policy(b1)의 수행 결과(A2)를 메모리(M)에 저장합니다. 이후(policy communication) 첫번째 에이전트(g1) 은 자신의 두번째 policy(a2)의 수정 여부를 결정하기 위해 질문정보, Tool 목록, 메모리(M), 초기에 결정한 두번째 policy(a2)를 입력으로 하여 현재 정책(a2)를 유지할지 혹은 수정할지(a2′)를 결정하게 됩니다. 에이전트 g2도 마찬가지로 M을 활용한 검토를 동시에 수행하게 됩니다. 이렇게 수정된 정책을 수행(policy excution)하고 communication을 통한 수정을 정답을 생성할 때 까지 (모든 plan이 완료될때 까지) 반복하게 됩니다. 최종 답변의 경우 객관식 질문은 다수결로, 개방형 질문(grounding이나 주관식)의 경우 지정된 에이전트(Qwen3-8B)에 의해 통합하게 됩니다.
# 실험 결과 요약
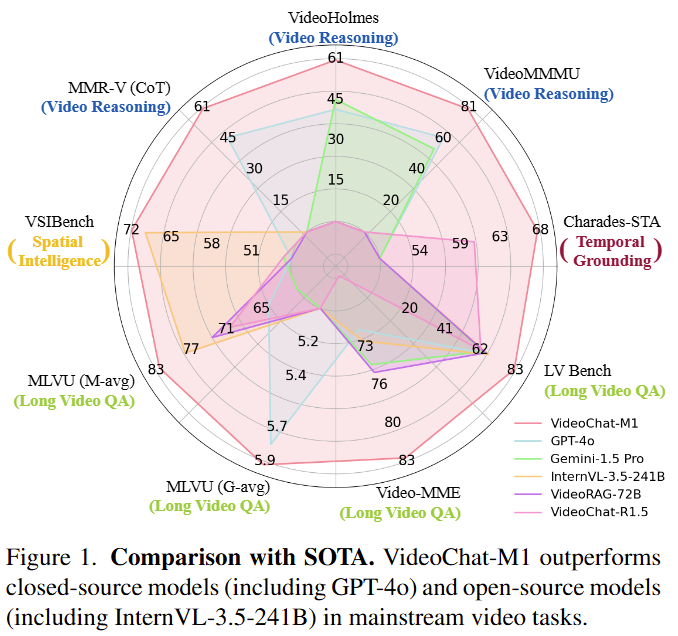
VideoChat-M1은 Figure1에서 확인할 수 있듯이 8개의 벤치마크에서 SOTA를 달성했습니다.
특히 LongVideoBench(LVBench)에서는 Gemini 2.5 pro와 GPT-4o를 앞섰다고 합니다.
(Gemini 2.5 pro는 아래 Table1 참조)
# 실험 결과 세부
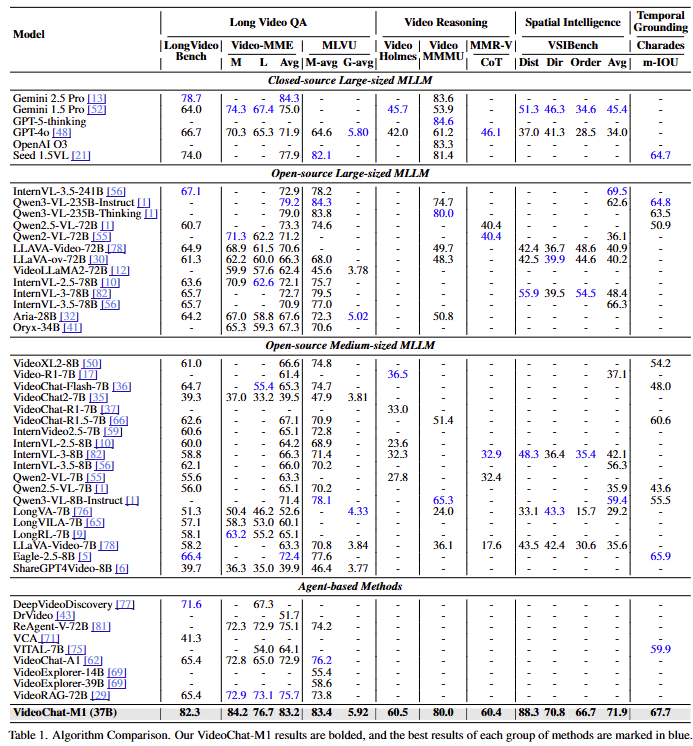
실험은 8개의 video understanding benchmarks에 의해 수행되었습니다. 수행한 결과는 Table1과 같으며 데이터셋 별로, 제안한 알고리즘을 제외한 그룹(closed-source large/open-source large/open-source medium/agent-based)별 최고 성능은 파란색으로 표시되었습니다. 실험 결과 80B 이하의 모델에서는 VideoChat-M1이 모든 벤치마크에서 SOTA를 달성했으며 LVBench의 경우 32B로 Gemini 2.5 Pro와 GPT4o를 뛰어넘는 성능을 보였습니다. 특히 Video-MME, MLVU, VideoMMU 벤치마크에서 훨씬 큰 스케일의 모델(Qwen3-VL-235B, Gemini 2.5 pro)과 비슷한 성능을 달성하고 있음을 확인할 수 있습니다.
# 추가 분석 실험
– Effects of the Number of Homogeneous Agents:
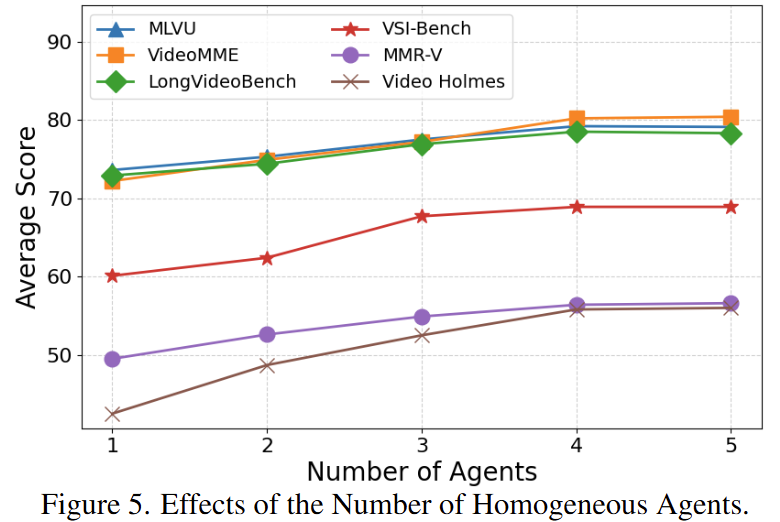
Qwen3-8B 모델을 통해 에이전트 개수 증가가 성능 향상에 미치는 영향을 확인한 결과 대부분의 벤치마크에서 1개에서 4개로 증가하는 동안 성능이 개선되었으나, agent가 4개 이상으로 증가하면 개선폭이 적은 성능 포화상태임을 확인할 수 있습니다.
좋은 리뷰 감사합니다. 읽다 궁금한 점이 있어 댓글 남겨두겠습니다!
1. 논문에서 지적하는 fixed policy는, 예를 들어 추론 시작 시 특정 시간 구간 선택, 도구 사용 종류(caption, OCR, object detection 등), 그리고 reasoning 순서를 미리 설계한 뒤, 추론 도중 해당 계획이 부적절함을 인지하더라도 이를 수정하지 않고 동일한 policy 흐름을 끝까지 수행하는 방식으로 이해해도 될까요?
2. 그리고 self-reflection이나 single-agent re-planning과 비교했을 때, CPP의 핵심 차별점이 planning 수정 자체인지, 아니면 multi-agent 상호작용에 기반한 수정인지 궁금합니다!
안녕하세요 주영님 리뷰 읽어주셔서 감사합니다.
1. 네 이해하신 바가 맞습니다. 추론 도중 계획이 부적절함을 인지하거나 평가하는 모듈이 없기 때문입니다
2. self-reflection 등의 자가 수정 방법으로는 CoT등이 포함된다고 생각합니다. CPP와 CoT와같은 자가수정은 서로 다른 방법론이기에 차별점 비교가 어렵다고 생각합니다..!
좋은 리뷰 감사합니다.
이번 주 정의철 연구원이 세미나에서 다룬 논문도 그렇고, 요즘 multi-agent를 활용하는 논문이 많이 보이는데, 제가 agent 기반의 task들을 아직 잘 몰라서 그런지 볼 때마다 개인적으로 ‘api 사용 비용이나 local 소스가 굉장히 많이 사용될 것 같다’는 생각이 듭니다.
아직 리소스 효율을 고려할 정도로 성숙하지 않았을수도 있겠지만 리뷰어들이 한번씩은 리포팅 요청을 할 것 같은데, 논문에서 multi-agent 사용 시의 추론 시간이나 리소스 관련 언급이 있나요??
안녕하세요 재연님 리뷰 읽어주셔서 감사합니다
해당 논문에서는 추론 시간에 대한 리포팅은 확인하지 못했습니다.
다만 추론이 무한하게 늘어날 수 있다는 한계를 지적한 리뷰어들은 종종 보았습니다.
이에 대한 대응으로 저자들은, 무한한 반복을 위해 생성하는 policy의 길이나 multi-turn 최대 횟수를 정해놓는 전략을 취합니다.
안녕하세요 유진님
리뷰 감사합니다!
간단한 질문이 하나 있는데요, 한번 추론시에 에이전트(MLLM) 4개가 고정으로 최종 추론까지 변동없이 동작한다고 이해했는데 이때 4개의 MLLM이 다 같은거로 수행이 되는건지 아님 각 다른 mllm으로 구성되어 있는건지 궁금합니다!
안녕하세요 찬미님 리뷰 읽어주셔서 감사합니다
중요한 내용인데 어펜딕스에 있는 내용이여서 제가 작성을 놓쳤습니다. 평가를 위해서 Qwen3-8B, Qwen3-4B, Qwen2.5-7B, and Qwen2.5-3B 모델을 agent group으로 세팅했다고 하며 총 파라미터 수는 22B라고 하네요