안녕하세요, 이번주도 다른 도메인에서 취득한 데이터를 조합하며 효과적으로 visuomotor policy를 학습하는 기법에 대해 리뷰하려고 합니다. 지난 리뷰 연구가 수학적으로 모델링해 loss를 설계하는 방식이었다면, 이번 연구는 각자의 장점을 알아서 잘 implicit하게 학습시키는 연구라고 생각하시면 될 것 같습니다.
Introduction
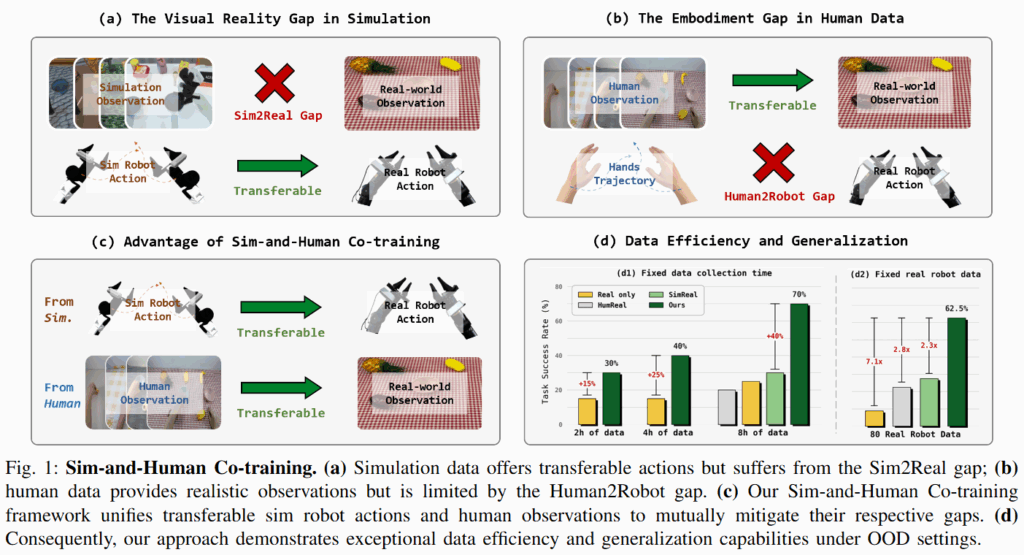
로봇 조작에서 실세계의 일반화를 이루는 것은 이제는 오래된 도전 과제가 됐습니다. 최근 gr00t나 pi0.5와 같은 거대 로봇 모델 연구들은 대규모 사전학습이 효과적임을 보여주었지만, 현실에서 다양한 로봇 데이터를 대량으로 수집하는 일은 매우 비용이 많이 듭니다. 늘 이야기하듯 이러한 데이터 부족 문제를 완화하기 위해 시뮬레이션 데이터와 human video 데이터가 대안으로 부상했습니다. 하지만 항상 문제는 도메인, embodiment간의 gap과 이것을 해결하는 것이었습니다. 시뮬레이션은 자동화된 데이터 생성 파이프라인 덕분에 대량의 로봇 데이터를 저비용으로 생성할 수 있지만, 시뮬레이터와 현실 간의 시각적 차이로 인해 학습된 정책을 real에서 적용할 때 성능 저하가 발생합니다. 반대로 human video 데이터는 실제와 가까운 photorealistic observation을 제공하지만, 인간과 로봇의 구조 차이로 인해 로봇이 인간 동작을 그대로 따라 하는 것에는 항상 어려움이 존재했습니다. 기존 연구들은 이러한 격차를 해소하기 위해 지난번 리뷰했던 도메인 정합 기법이나 co-training을 시도해왔으나, 복잡한 architecture, loss 설계를 요구하거나 다른 환경의 데이터를 단순 증강 정도로 취급하는 한계가 있었습니다.
저자들은 SimHum(Sim-and-Human Co-training) 프레임워크가 이러한 문제 의식에서 출발했다고 합니다. 저자들은 시뮬레이션과 인간 데이터가 자연스럽고 상호보완적인 강점을 지닌다는 점에 주목했다고 합니다. 즉, 시뮬레이션은 로봇으로 실행가능한 행동을 제공하지만 시각적인 현실성 부족하고, 인간 데이터는 현실적인 관찰을 제공하지만 로봇에 바로 쓰기 어려운 행동이라는 한계를 갖습니다. 저자들은 시뮬레이션에서는 로봇 운동학적 제어 능력을, 인간 시연에서는 실제 시각적 이해 능력을 배우고 이를 결합함으로써, 별도의 복잡한 정합 과정 없이도 두 세계의 장점을 모두 가진 정책을 학습할 수 있다고 주장합니다. 이런 논문을 볼때마다 생각이 드는거지만 ‘그러게,,? 시뮬레이션과 현실 로봇 데이터도 같이 학습했었는데 왜 생각 못 해봤을까’ 싶긴 합니다.
저자들은 SimHum 공동 학습을 통해, 동일한 현실 데이터 취득 시간을 기준으로 기존 방법 대비 최대 40% 성능 향상을 이루고, 80개의 실제 데이터로 62.5%의 OOD 성공률을 달성하여 실제 데이터만 학습한 정책 대비 7.1배 높은 성능을 확인했다고 합니다.
Methods
Problem formulation 섹션이 있지만 특별할 것은 없습니다. 
저자들은 visuomotor policy P를 조건부로 액션 시퀀스를 생성하는 함수로 정의했습니다. 궁금하신 분들을 위해 원문을 첨부했는데, 시뮬레이션과 현실에서는 각 환경의 액션은 거의 똑같지만, 환경이 달라 같은 state가 주어졌을 때 각 환경의 observation을 통해 생성된 액션이 다르다는 것이 핵심이고, human data는 현실의 영상을 취득한만큼 photorealistic한 visual observation을 가질 수 있지만, 사람과 로봇의 구조 차이에 따른 액션이 다른 것을 보여줍니다.
저자들의 objective는 이 두 분포를 억지로 맞추는 대신, 하나의 policy에 시뮬레이션으로부터 로봇 제어에 유용한 운동학적 prior, 인간 데모로부터 실제 시각 이해에 유용한 semantic prior를 뽑아내어 결합하는 것입니다.
Data collection pipeline
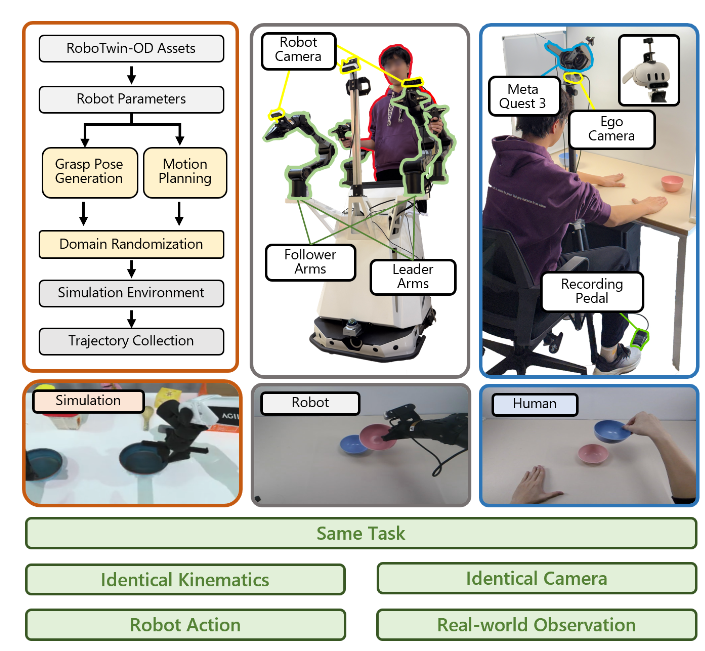
저자들은 시뮬레이션과 human video 데이터의 분포 차이를 최소화하기 위해 real robot, sim robot, human video에서 real 로봇 데이터를 기준으로 셋업을 일치시키는 프로토콜을 구현했다고 합니다. 시뮬레이션 데이터는 robotwin 2.0을 활용해 실제 로봇과 똑같은 URDF 모델을 사용했고, human video 데이터, real robot 데이터와 동일한 카메라 모델과 시점으로 촬영하여 로봇 기준 observation과 시각적 동일성을 확보했다고 합니다. 추가적으로 시뮬레이터에서는 task 당 500개의 로봇 궤적을 시각적, 물리적 augmentation을 부여하며 자동 생성했다고 합니다. human video 데이터는 12가지 서로 다른 현실 시나리오에서 총 500개 영상 시퀀스를 얻었다고 합니다. Real robot data의 경우, finetuning 용으로 80개 에피소드(기본 환경 50 + 복잡한 환경 30)만 수집했다고 합니다. (finetuning용으로만 80개가 필요한가보네요,, ㅎㅎ;) 세 종류의 데이터 모두 환경 요소들은 다양하게 조합하여 수집했고, 에피소드마다 물체 초기 배치를 무작위로 진행해 다양한 상황을 포함하도록 했다고 합니다
Modular Policy Architecture
SimHum의 정책 모델은 Diffusion Policy 방식이지만 DiT를 사용했습니다. Visual observation을 인코딩하는 비전 인코더와 proprioception을 넣어주는 MLP로 input을 받고, 토큰으로 Transformer에 입력하여 diffusion을 통해 액션 시퀀스를 예측합니다. 여기에 SimHum은 데이터 소스별로 특화된 모듈들을 추가해 하나의 정책 내에서 시뮬레이션과 인간 데이터를 동시에 학습하면서도 각자의 고유한 강점을 유지하도록 설계했다고 합니다. Vision 인코더에 adaptor나 human pose에 대한 state 인코더, human과 로봇의 decoder가 전부 따로 설계되었습니다. 전체적인 모듈 구조는 그림 2(a)와 같습니다.
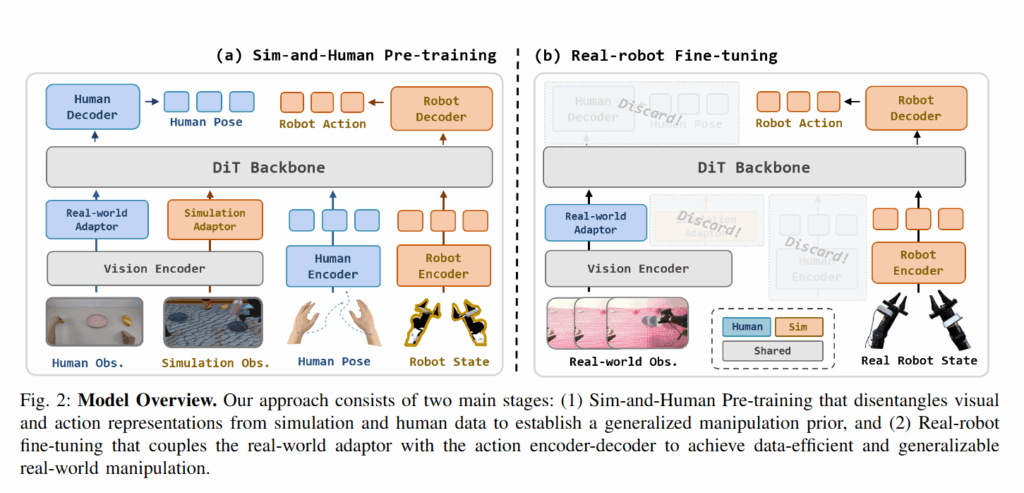
조금 더 설명하자면 방금 위에 말한것처럼 로봇과 인간의 action이 다름을 처리하기 위해 인코더와 디코더를 아예 두 종류로 나눕니다. Human pose용 state 인코더는 손목의 pose를 ee로 삼아, 각 손가락의 3D위치를 상대적으로 표현해 44차원(2 + 15 + 15 면 12개가 비는데,,?)으로 표현되는 hand pose를 토큰으로 변환하고, human 디코더는 예측된 latent action을 복원합니다. 로봇용 인코더는 7+7+2 (bimanual eepose + gripper) = 16차원의 state를 처리합니다. 이를 통해 공동의 DiT 백본은 인간과 로봇에 공통적인 상위 조작 개념을 학습하고, 구체적인 kinematics에 대한 것들은 인코더와 디코더 모듈에서 학습할 수 있다고 합니다.
또 시뮬레이션 영상과 인간 및 실제 영상 사이의 시각적 차이를 보정하기 위해, 1차적으로 공통된 비전 인코더를 통해 이미지를 임베딩한 뒤 도메인 벼롤 특화된 어댑터(MLP 구조라고 합니다)를 각각 통과시킵니다. 시뮬레이션 이미지 토큰들은 시뮬레이션 전용 비전 어댑터를, 실제 이미지 토큰들 (human video와 real robot이 해당합니다)은 real-world 비전 어댑터를 거치게 됩니다. 해당 어댑터들은 2개 layer의 MLP 구조로 되어 있어 두 도메인간 분포 차이를 보정한다고 합니다. 이전에 리뷰한 논문에서 이들을 잘 학습시키기 위해 loss를 따로 고안했던 것 같은데, 해당 내용을 기존 연구의 한계로 짚는것을 보니 그것보다 그냥 따로 어댑터를 설계하는게 이득인가봅니다. (아니면 트랜스포머를 활용하는거라 다른건가..? 까지는 정확히 모르겠습니다)
Two-Stage Training Paradigm
저자들의 SimHum 파이프라인은 위에서 제시한 아키텍쳐로 sim, human video로먼저 pretrain 단계를 거치고, 이후 finetuning을 적은 양의 real robot 데이터로 진행한다고 합니다.
Pretraining 단계에서는 시뮬레이션 데이터로부터 로봇 kinematics에 관한 prior를, human video에서는 현실의 visual적인 prior를 학습합니다. 일반적인 diffusion의 loss와 같습니다.
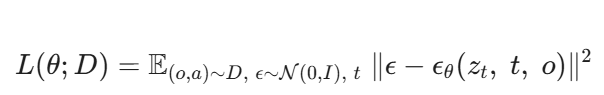
다만 다른 co-training 연구에서 배치 구성 비율을 정한것 처럼 시뮬레이션과 human video의 loss를 가중합으로 구성해서 가중치를 특정 비율로 정의합니다. 결국 알파값이 배치 구성의 human video 구성비율인데, 해당 단계에서는 실험적으로 0.5에서 성능이 제일 좋았다고 합니다.
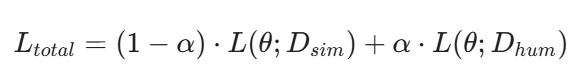
이후 finetuning 단계에서는 real world의 인코더와 robot state 인코더만 학습시키면서 둘을 결합하는 방식으로 학습합니다. 이를 통해서 두 데이터의 이점을 고루 챙기고 있는 사전학습된 모델을 현실에서 로봇이 잘 작동하는 방향으로 finetuning해줄 수 있다고 합니다.
Evaluation
Settings
저자들은 SimHum의 성능을 검증하기 위해 목표 객체, 시각적인 방해, 조명, 배경, 초기 배치의 5가지 환경 요인을 변화하며 OOD 상황을 만들어 평가했다고 합니다. 이런 세팅에서 bimanual manipulation task를 아래와 같이 선정했습니다. 데이터 수집 단계에서 사전학습용으로는 시뮬레이션과 human video를 task당 500개 에피소드씩 촬영했다고 합니다. Finetuning용 real robot 데이터는 task당 80개의 실제 로봇 에피소드(기본 50개, 변화된 환경 30개)를 촬영했스빈다. Baseline으로는 현실데이터로만 학습한 Real only, 시뮬레이션과 real robot데이터만 활용한 ‘SimReal’, 인간 데이터와 공동학습한 ‘HumReal’을 기준으로 삼았습니다. 평가지표는 pi시리즈처럼 task progress와 Success ate 두가지를 사용했습니다. task별로 score를 subtask당 1점씩 부여하여 진행했습니다.


Results
저자들은 아래와 같은 4개의 질문에 답하는 실험을 진행했다고 합니다.
- SimHum은 시뮬레이션+인간 공동학습을 통해 얼마나 효과적으로 강인한 실제 조작을 달성하는가?
- 정책은 시뮬레이션으로부터 어떤 prior를, 인간 데이터로부터 어떤 prior를 얻는가?
- SimHum은 데이터 효율성 및 확장성 면에서 우수한가?
- SimHum의 핵심 설계 선택들은 성능에 어떤 영향을 미치는가?
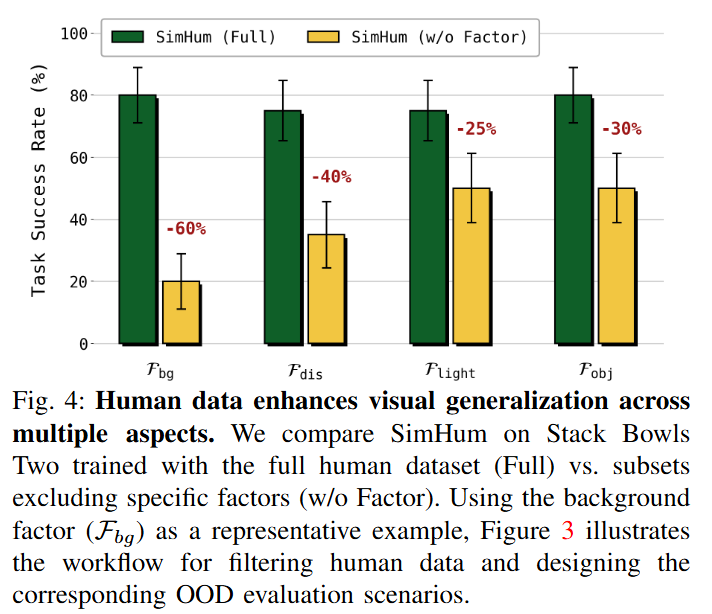
table1을 보면 real robot으로만 평가한 경우보다 OOD 시나리오에서 SR, PR 모두 증가함을 볼 수 있습니다. 이것이 VA 자체의 한계인 visual correlation에 치우친 채 task invariant한 action representation을 학습하지 못 한다는 것을 증명합니다. 하나의 source가 추가된 경우들 역시 제한된 성능 향상을 보이고, 저자들의 방법이 제일 향상 폭이 크다고 합니다. 해당 실험은 모든 co-training 논문들이 공통으로 보이고자 하는 부분입니다.
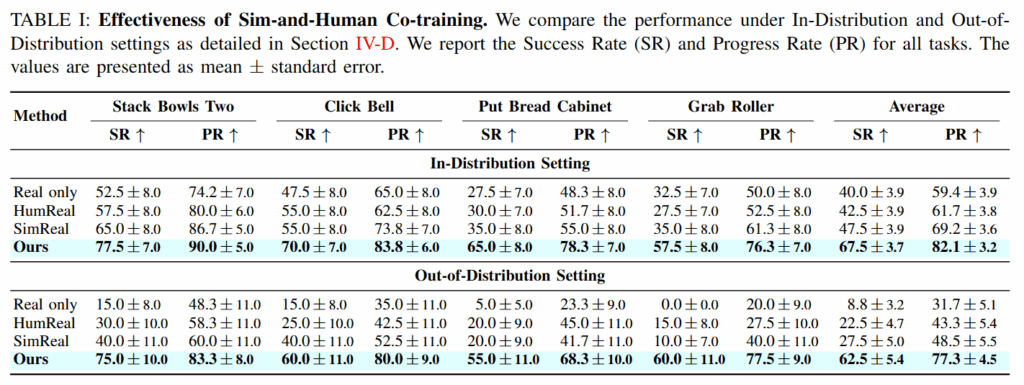
Fig4는 데이터 구성에 관한 실험입니다. Evaluation settings의 데이터셋 구성에서 특정 요소들을 제하며 비교실험을 진행한 결과 OOD 환경에서 실험결과입니다. 다른 논문들에선 의외로 background에 대해서는 강인하다고 리포팅이 됐었는데, 해당 연구에서는 bg의 부재가 가장 큰 하락을 보였습니다. F_dis 인 방해물 추가 세팅에서도 많은 성능 하락을 볼 수 있습니다.
다음은 spatial OOD 상황에서의 결과입니다. 35 * 35 cm의 크기를 16구간으로 나누어 각 구간마다 10개의 에피소드를 평가해 success rate가 아닌 task progress rate로 평가했습니다. SimHum 방법이 확실히 spatial generalization에 강한 것을 확인할 수 있습니다

Fig 6을 보면 SimHum이 모든 time budgets에서 Real only보다 일관되게 향상된 성능을 보여줍니다. 적은 양의 data collection time에서 SimReal, HumReal보다 더 높은 성능을 기록했습니다. SimHum이 각 도메인별 시너지 효과를 통해 real world에서 일반화 성능을 제한된 데이터에서도 보이며 효율성을 입증했다고 보시면 될 것 같습니다
안녕하세요, 영규님 좋은 리뷰 감사합니다.
이에 대해서 사람 동작과 로봇 동작 사이에 무언가를 공유하 비슷한 방법을 gr00t에서 본 것 같기도 합니다.
보면서 fig 2에서 vision 인코더는 심과 real을 공유하고, 동작에 대한 것은 다른 인코더를 쓰는 것 같은데 이런 방식을 쓰면 sim이 뭔가 시각적으로 현실과 다른 느낌이라고 생각이 되어왔는데, 이런 부분이 기술적으로 해결이 된 것인지, 아니면 vision 인코더가 공유하면서 사용하는 것이 더 좋은 것에 대한 근거가 있는지 궁금합니다.
좋은 리뷰 감사합니다.
안녕하세요 기현님 댓글 감사합니다.
질문에 대해 맞게 이해한것인지는 모르겠으나 vision 인코더는 하나의 인코더를 쓰지만 각 도메인별 adaptor가 있고, 이를 통해 현실과 시뮬레이션의 vision gap을 줄입니다. 액션의 경우는 각각 다른 인코더를 통해 행동을 학습하고 (이 때 human video의 양이 많아 scaling 됩니다) 후에 real robot 데이터로 소량만 finetuning 하는 것으로 해결한 것이 논문의 요지입니다.
안녕하세요 영규님, 좋은리뷰 감사합니다.
시뮬레이션 영상과 인간 및 실제 영상 사이의 시각적 차이를 보정하기 위해, 공통 vision encoder 다음 어댑터가 각 도메인 별 하나씩 붙는 것이 기존 연구에서의 loss 설계보다 더 효과적일 수 있는 것 같다고 생각한다고 언급해주셨는데요. 두 도메인을 배치 섞어서 동시에 학습할 때 loss 설계방식은 gradient가 섞이면서 학습시그널에 더 노이지한 영향을 줄 수 있을 것도 같고,,, 대신 어댑터를 두면 공통 vision encoder보다 도메인별 파라미터에 자연스레 분리되어 그라디언트가 흘러가 학습시그널을 더 안정화시켜서이지 않을까싶은데, 제 생각이 맞을지,, 영규님의 생각은 어떠신가요?
감사합니다.
안녕하세요 재찬님 댓글 감사합니다.
제가 생각했을 때도 단순히 loss를 같이 거는 방식은 두 도메인의 gradient가 shared encoder에서 충돌날 수 있는데, domain-specific adapter를 두면 공통 encoder는 공통 feature를 배우고 도메인 차이는 adapter가 흡수해서 sim,real과 같이 도메인이 다른 경우에 특히 학습이 더 안정적일 수 있을 것 같습니다.
영규님 좋은 리뷰 감사합니다.
SimHum이라는 새로운 컨셉을 제안한 논문으로, 서로의 장점을 활용하려는 컨셉이 인상적입니다.
데이터 소스별로 특화된 모듈로 구성하여 각 방식의 장점을 유지하도록 하였다고 하셨는데, 동일한 vision encoder로 임베딩 된 뒤, 각 도메인의 adaptor를 통과하는데, 학습 과정에는 DiT backbone 안에서는 어떤 소스에서 생성된 정보인지는 구분하지 않는 것 인가요?
또한, Fig. 11을 보면, ID와 OOD에 대한 구분이 모호한 것 같습니다. 주황 조명과 파란 조명환경은 OOD로 보지 않는 이유가 있나요??
마지막으로, 해당 방법론은 human video와 simulation 환경에서 동일 카메라를 이용한다는 것이 어찌보면 추후 해결해야할 문제가 될 수 있을 것 같습니다. 각 카메라별로 해당 논문에서 필요하다고 하는 데이터가 요구되어야한다면, 일반화를 위해 적당한 데이터가 필요하다고 할 수 있는지에 대한 영규님의 생각이 궁금합니다.
안녕하세요 승현님 댓글 감사합니다
네 맞습니다. DiT 백본에서는 각 어댑터에서 얻은 비전 정보와 인코딩된 액션을 다같이 학습합니다.
OOD로 보지 않는 이유는 학습 데이터 분포 내에 들어있기 때문입니다.
일반화에 대한 적당한 데이터,,가 무엇인지 잘 와닿지는 않지만 현재 카메라 종류나 시점에 굉장히 민감한 부분은 해결해야할 문제라고 생각합니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
영규님 생각처럼 sim-human 듣고나서 그리고 읽고나서 그러게..?라는 생각을 동시에 하게되었습니다.ㅎㅎ
위에서 재찬님의 질문처럼 노이즈가 섞이지 않을까 싶기도하고 robot이 추론할때 관절들이 Fig 10 에 나와있는것 처럼 관절이 많이 꺽이고 사람이 하지않는 행동도 하느거같은데 human pose 에 대한 ablation 이나 아니면 손 pose에 대해서만 실험한거는 없나요 ?
감사합니다
안녕하세요 우진님 댓글 감사합니다.
Human pose의 종류(?)에 대한 ablation은 확인하지 못 했고, 카메라 상으로는 저렇지만 저자들의 말에 따르면 생각보다 동일한 액션을 하려고 많이 노력했다고 합니다.