안녕하세요. 저번 세미나 시간에 발표로 들고 왔던 Chain of Action 논문을 리뷰로 남기기 위해 가져왔습니다. ByteDance Seed에서 제안한 액션 역방향 생성의 새로운 패러다임인데요. 기존의 액션을 그리퍼의 ee pose로부터 순차적으로 생성하는 VA/VLA 방식의 액션 순방향 생성 패러다임에서 벗어난 아예 새로운 패러다임을 제시했으면서도 다른 방법론과 융합되기 좋거나 백본을 교체하기 좋은 베이스라인스러운 아키텍쳐 구조와 loss 구조를 가지고 있어서 꽤나 흥미로운 논문이었습니다. 더구나 본 논문도 아직은 해결해야할 문제가 쏙쏙 보여서, 문제정의와 연구주제의 논리를 좀 더 고민해보고 저의 다음 연구에 있어 적용여부를 고려해봐야할 것 같습니다.
1. Introduction
최근 로봇 제어 분야의 핵심인 e2e(end-to-end) visuomotor policy, 즉 VA 방법론은 너무나도 빠르고 눈부신 발전을 이루고 있지만, 실제 환경에 적용하기 위해서는 여전히 두 가지 고질적인 병목 현상을 해결해야 합니다. 첫째는 하나의 상황에서도 여러 가지 정답 액션이 multi-modal 분포로써 존재할 수 있는 Multimodal Action Distribution*의 문제이며, 둘째는 작은 오차가 시간이 흐름에 따라 걷잡을 수 없이 커져 궤적을 이탈하게 만드는 Compounding Errors** 및 Distribution Shift의 문제입니다.
* : 확률분포가 하나의 뚜렷한 피크 대신 둘 이상의 국소적인 최대값을 갖는 분포. 예를 들어 동일한 관찰 o에 대해 “서로 다른 여러 적절한 행동”이 생길 수 있음.
** : 데모데이터를 기반으로 supervised로 학습하는 Imitation Learning 방식은 시계열로 강하게 의존적인 state-action 데이터를 i.i.d.***로 가정해 학습하기 때문에, 전문가가 한 번도 방문하지 않은 상태에서는 올바른 행동을 배우지 못합니다. 그 결과, 작은 초기 오차가 분포 이동을 유발하고 이후 상태들에서 연쇄적으로 증폭되어 성능 붕괴로 이어질 수 있다는 문제가 생기고, 그것을 흔히 compounding error라고 합니다.(DAgger,2011 논문에서 거의 처음 언급)
***i.i.d.(independent and identically distributed) : 확률 변수나 데이터 포인트들이 서로 독립적이며 동일한 확률 분포를 따른다는 가정
아래는 뭐 전혀 다른 철학의 논문이긴 하지만 figure가 Multimodal Action Distribution의 이해를 돕기 쉬은 그림인 것 같아 가져왔습니다. 아래 그림처럼 VA방식의 action은 기본적으로 다봉분포의 확률적 가정을 가지게 됩니다.
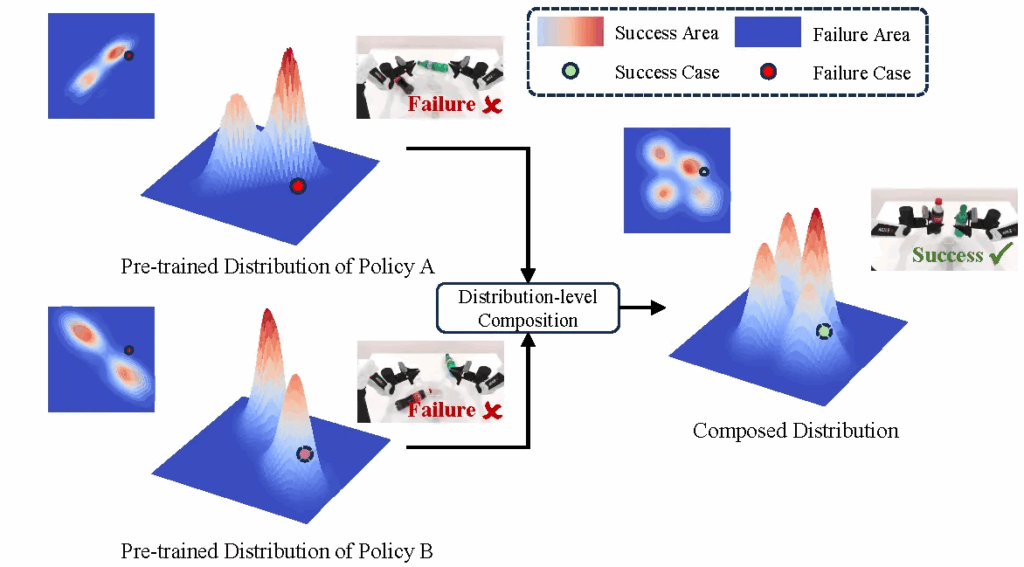
아무튼 현재의 policy learning 방법론들은 대개 마르코프 근사인 p(a_t|s_t) 를 기반으로 당장의 다음 행동을 예측하는 데 최적화되어 있어, Long-horizon에 대한 관점보다는 근시안적인 판단에 머물기 쉽습니다. 사실 ACT나 Diffusion Policy(DP)와 같은 오늘날 VA의 근간이 되는 굵직한 기법들이 Action Chunking 방식이나 Diffusion 예측의 분포로부터 액션을 continuous하게 예측하는 방식 자체를 통해 이러한 한계를 어느정도 극복하고 있다고는 본인들 논문에서 소개하고 있습니다. 더불어 이들을 발판삼아 더욱 다양한 VA 방법론 연구들이 상당히 많은 수가 나왔지만 대부분은 현재의 관찰을 기반으로 다음 단계의 행동을 예측하는 방식으로 자연스럽게도 forward prediction 패러다임을 따르고 있었습니다. 이는 곧 전체 작업을 아우르는 Global한 goal constraint이 부재한 상태를 만들고, 그러한 상태에서 당장의 다음 단계만을 예측하다 보니, 실제 실행 과정에서는 compounding error로부터 결국 목표 궤적에서 이탈하는 Action drift 현상이 발생하게 됩니다.
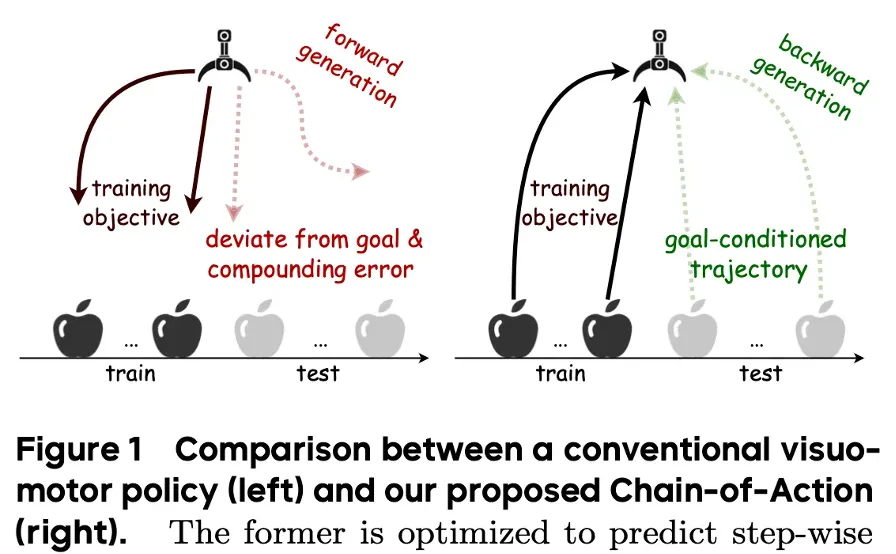
본 논문의 저자들은 이러한 문제를 해결하기 위해 위 Figure1과 같이 직관적인 motivation으로 forward manner기반의 action generation이 아닌, 그 과정을 근본적으로 뒤집어 goal-conditioned한 trajectory를 만들어내는 backward reasoning 컨셉의 Chain-of-Action(CoA) generation 기법을 제안하게 됩니다.
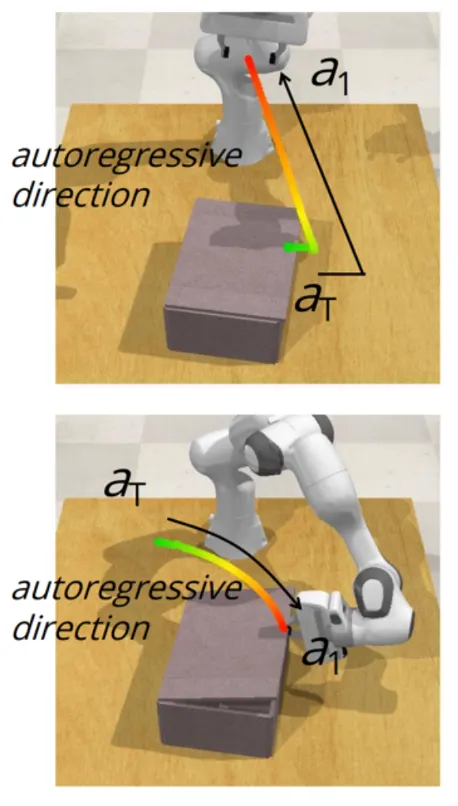
동작 원리를 직관적으로 보면 왼쪽 그림과 같은데요.
LLM의 CoT(Chain of Thought)기법에서 영감을 받아서, 어떻게 보면 단순하게 action 궤적 생성의 프로세스를 로봇의 ee → goal이 아닌 거꾸로 goal → ee 로 생성하는 과정입니다.
그래서 먼저 작업의 최종 goal이 되는 키프레임이 셀렉되어 있다면 그 때의 액션 $a_T$(6D EE Pose + gripper state)를 먼저 예측합니다.
그 다음 autoregressive하게 궤적을 backward해서 ($a_{T-1}, \dots, a_1$) 이렇게 현재 gripper position까지 액션을 뽑아냅니다.
이 방식의 가장 큰 장점은 전체 궤적이 최종 goal에 딱 anchored된다는 점입니다.
이로써 로봇이 실행 과정에서 발생할 수 있는 액션 드리프트를 억제하고, 전체 작업 흐름 속에서 현재의 움직임에 constraint를 주는 ‘Global-to-Local’ constraints를 갖게 됩니다.
결과적으로 단순하게 다음 단계 맞추기를 하겠다는 게 아니라, 목표로부터 거꾸로 현재 상태의 내(로봇)가 어떻게 동작해나가야했는지 역추정하는셈입니다.
2. Related Works
Hierarchical modeling in robotic manipulation
전통적으로 high-level의 Keyframe을 먼저 식별한 후, 사전 정의된 제어기를 통해 low-level action을 처리하는 방식이 널리 사용되어 왔었습니다. C2F-ARM, PerAct, RVT, RVT-2 등이 이 패러다임의 대표적인 예시인데, 최근에는 ChainedDiffuser나 HDP와 같이 신경망 기반 플래너를 도입하는 연구도 진행되었습니다. 그에 반해 본 CoA 방법론의 차이점은 기존 방식들은 대개 Keyframe 사이를 open-loop 방식으로 운영하여 동적인 환경 대응에 어려움이 있고 고정밀 3D 인풋을 필요로 하는데 반해, CoA는 Keyframe detection, trajectory 생성을 단일 autoregressive 프레임워크로 통합하여 환경에 대한 perception과 closed-loop 실행을 가능하게 한다는 점에서 차별점이 있다고 저자들은 주장합니다.
CoT-style methods in robotic manipulation
imagined image goal, visual trace, bbox, gripper pose 등 intermediate semantic representation을 가이드로 활용하여 후속 action을 생성하는 연구들이 있어왔습니다. 예를 들어 아래 방법론들인데, 이들은 보통 intermediate semantic representation을 활용해 VA의 궤적 생성 시 도움을 주는 추가적인 signal이 활용되면 좋더라. 에 관한 논문들인데,
- Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data
- Any-point trajectory modeling for policy learning.
- Cot-vla: Visual chain-of-thought reasoning for vision-language-action models.
- Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies.
그에 반해 CoA는 그러한 중간 representation 없이 액션들 간의 추론 과정 자체를 직접 모델링하는 데 집중하여 덕분에 다양한 proprioceptive 입력 및 정책 구조와 폭넓게 호환 가능한 파이프라인을 개발하게 되었다고 합니다. 개인적으로 이로 인해 CoA의 철학적 컨셉과 활용도가 높아지는 효과가 있지 않을까 생각합니다.
3. Methods
핵심 아이디어는 한마디로 말해서, 작업별로 각각 중간에 keyframe selection을 할 수 있게 되는데, 거기서 각 keyframe goal image에서의 keyframegoal action에서 시작해서 autoregressive 방식으로 행동을 거꾸로 예측하는 궤적 생성을 모델링하는 방식인 셈입니다.
3.0. Formulation
일단 keyframe인 sub-goal로부터 action을 롤아웃해나가는 방식으로 compounding error를 완화하는 global-local constraint 구조를 부여합니다.
C2F-ARM(제가 옛날에 리뷰한 Q-attention 논문의 ARM 프레임워크 후속논문입니다.)에서 처음 제시된 휴리스틱한 키프레임 selection 방식(이것 또한 Q-attention에서부터 이어진 방식)을 채택하는데, 여기서 키프레임은 그리퍼 상태가 변경되거나 조인트 속도가 0에 가까워지는 시점입니다. 해당 시점을 객체 파지 완료나 객체 배치 같은 의미론적으로 중요한 단계전환순간으로 포착해서 작업별로 sub goal로써 역할을 해주게 됩니다. 그렇게 되면 각 sub goal을 CoA가 action으로 표현하게 됨으로써 모든 다른 행동과 동일하게 임베딩 공간을 공유할 수 있게 되어, 원활한 역방향 생성을 가능하게 합니다.
각 학습 샘플에 대해 CoA는 autoregressive 디코더(TF layer)를 사용하여 행동 간의 역방향 인과 관계를 강제하여, 목표 조건부 추론 체인을 생성하는 방식으로 행동 시퀀스를 역순으로 모델링하는 방법을 학습하게 됩니다. 그래서 궤적분포는 다음의 수식과 같이 체인룰 형태로 모델링될 수 있게 됩니다. 이건 Trajectory 전체의 확률을, 조건부 확률들의 곱으로 분해한 것인데, 원래 수학적으로 Joint Probability 가 Chain Rule이 적용이 가능한 점을 활용했습니다.
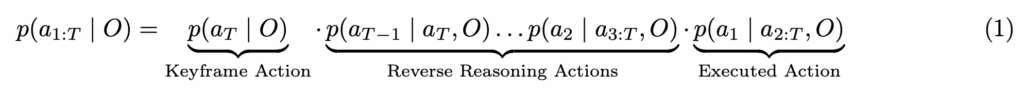
여기서 a_T는 키프레임 액션을 나타내고, O는 관측 context인데, 입력 이미지 I와 preprioceptive 상태 S를 합친 겁니다. 각 훈련 샘플은 전문가 시연에서 임의의 시간 단계에서 시작하여 다음 첫 번째 키프레임 행동으로 끝나는 세그먼트를 선택하여 sub-trajectory가 샘플링됩니다. 관측 O는 현재 단계에서 가져오고, a_{1:T}는 현재 단계부터 키프레임까지의 행동 시퀀스를 나타냅니다. 그리하여 각 (O, a_{1:T})쌍은 독립적인 학습 예제를 형성하게 됩니다.
3.1. Model Architecture / Pipeline
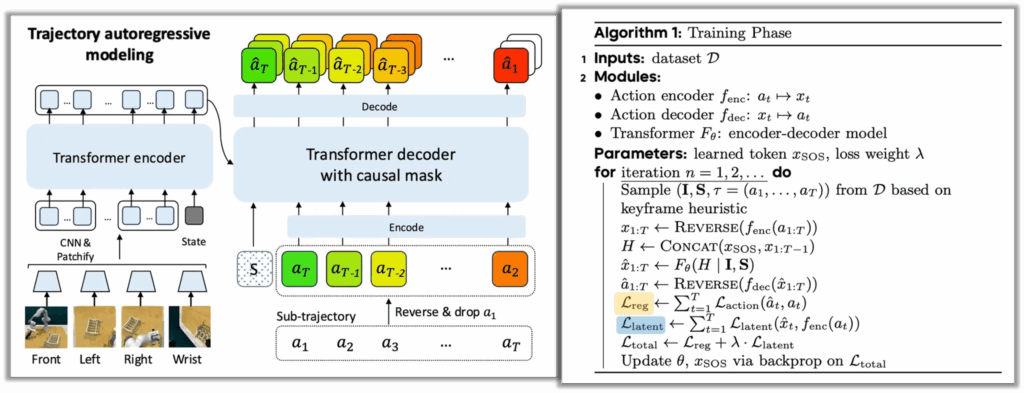
전반적인 모델 파이프라인은 위 그림과 같습니다. training은 오른쪽의 algorithm1 수도코드를 함께보면 이해가 잘 되는데요.
Training Phase: “Autoregressive” & “MTP(Multi-token Prediciton)” & “latent consistency loss“
인풋으로 4가지의 3rd view RGB이미지가 들어왔을 때 -> 각 이미지뷰는 ResNet-18 인코딩 및 패치화되고 -> 이미지토큰들과 로봇의 proprioceptive state 토큰을 인풋삼아서 transformer encoder(4x self-attention blocks layer)에서 context 임베딩이 됩니다. -> 그리고 그 관측 context 임베딩을 K, V로 삼아 -> transformer decoder(7x cross-attention blocks)에서 cross-attention 을 진행합니다.
이 때 쿼리로 역방향으로 reverse된 demo데이터셋에서 뽑혀 a_1 그리퍼 액션을 배제한 sub-trajectory와, 모델이 전체 궤적을 keyframe 중심으로 생성하도록 ‘앵커’ 역할을 할 학습 가능한 시작 토큰(SOS)를 입력으로 받게됩니다. 이 때 decoder는 causal mask가 적용된 autoregressive 구조를 따르게 됩니다. 이 mask도 결국 CoA의 trajectory autoregressive formulation을 구현하기 위한 조건인 셈인데, 일단 앞서 말했듯이 CoA는 전체 action trajectory a_{1:T}의 joint distribution을 역방향으로 factorize합니다. 즉, 모델은
p(a_T \mid O), p(a_{T-1} \mid a_T, O), … , p(a_1 \mid a_{2:T}, O)의 형태로 조건부 확률을 순차적으로 모델링해야합니다. 이런 조건부확률 수식 자체가 사실 각 시점의 action이 아직 생성되지 않은 미래 action에 접근하지 못하도록 엄격한 인과 구조를 요구하기에, Causal mask를 이러한 역방향 인과성을 강제하기 위해서 사용한 것입니다. 이를 통해 모델은 goal에 해당하는 keyframe과 이후의 reasoning chain에만 조건화된 상태에서 autoregressive하게 각 action을 예측하는 구조를 가지게 됩니다. 만약 이 masked 구조가 없다면, 학습 단계에서 디코더는 전체 action 시퀀스를 동시에 관측할 수 있게 되고, 이는 joint distribution을 autoregressive하게 근사한다는 CoA의 핵심 가정을 위반하게 되는 것 같습니다. 더구나 특히 이 backward generation 이라는 컨셉에서는, 마스크가 없을 경우엔 모델이 실행 시점에서는 물리적으로 존재하지 않는 액션정보에 의존하게 되는 어떤 shortcut을 학습할 위험이 클 것 같습니다.
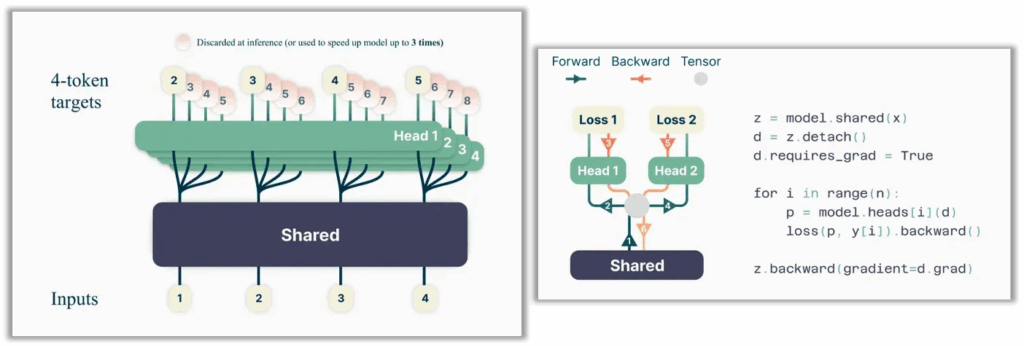
또한 figure 2의 action이 디코딩되는 부분을 살펴보면 액션토큰이 1가지씩이 아니라 여러가지가 중첩으로 나오는 모습을 볼 수 있는데요. 본 논문은 모델이 현재 토큰 시점에서 미래의 n개의 액션 토큰을 동시에 예측하도록 하는 Multi token prediction(MTP) 라는 LLM 학습에서 쓰이던 decoding 패러다임을 활용했습니다. 이는 위에 제가 가져온 그림에서도 보이는데요. 기존에 쓰이던 Next-token prediction(NTP) 방식은 현재 토큰 시점에서 다음 하나의 토큰만 예측하는 방식으로 학습되지만, MTP를 쓰면 학습 신호를 밀집시켜 데이터 효율성을 향상시킬 수 있다가 목적입니다. 저자들은 이 MTP방식을 action locality modeling을 위한 학습 시의 regularization 역할로써 사용했다고 합니다.
디코딩 과정에서 토큰이 확 증폭된다는 것 자체가 temporal locality를 도입한다는 의미를 주기에, global-to-local chain-like 구조를 유지하면서 action generation에 의한 loss 연산의 안정성을 향상시키고 long-horizon generation도 안정시키는 역할을 한다고 합니다. 그리고 이 MTP regularization은 학습 중에만 적용되고 추론 시에는 제거되어서 단순 NTP 방식으로 디코딩하게 됩니다. 학습할 때 그러면 gpu메모리 cost가 많이 드는 거 아니냐? 싶을 수 있지만 이는 MTP논문에서 위 그림 중 오른쪽 그림과 같이 학습 과정의 gradient 연산 시 병목이 안 생기는 최적화 전략을 사용하여 그리 큰 로드가 들지 않는다고 하네요. (MTP는 vocabulary size V가 latent representation의 차원 d보다 훨씬 크기 때문에, logits 벡터(형태 (n, V))가 GPU memory 병목 현상을 일으킬 수 있는 것. 이를 해결하기 위해 forward, backward 시의 output head에서의 logits과 gradients를 다음 output head에서 처리하기 전에 해제되는 방식으로 위의 그림에서의 오른쪽 구조처럼 사용되고, 지속적으로 사용되는 메모리는 trunk gradient밖에 없어서 메모리 사용량이 O(n*V + d)에서 O(V + d) 로 줄어든다고 함. 더구나 이 MTP구조는 논문에 의하면 실험적으로 모델 규모가 커질수록 성능향상폭이 높아지는 경향이 있었음.)
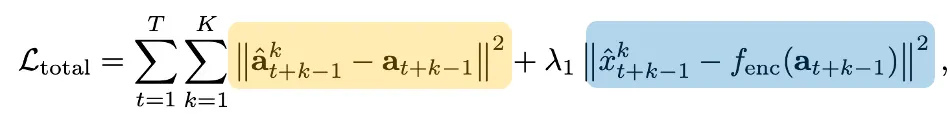
또한 위 수식이 학습 시의 total loss인데 두 텀으로 나뉘어져 있습니다. 노랑 loss(액션 시퀀스 L2 loss) + 파랑 loss(latent consistency L2 loss)로 이루어지게 되는데, 이 때 t는 autoregressive decoding step을 의미하고, k는 MTP에서의 future offset 을 의미합니다. 쉽게 말하면 노랑 loss는 action space에서의 loss이고, 파랑 loss는 latent space에서의 loss입니다.
저자들은 디코딩된 액션 토큰 시퀀스와 gt 액션 시퀀스만으로 직접 L2 loss를 적용하는 것은 autoregressive 디코딩 중에 latent space에서의 의미있는 정규화가 부족해져서 인코딩 시의 error가 autoregressive 프로세스를 통해 전파되고 증폭될 수 있게 만든다고 합니다. 그렇게 되면 temporal consistency를 주기가 어렵기에 저자들은 이를 해결하려고 latent action space에서의 L2 loss를 추가적인 latent consistency loss 텀으로 적용해주었다고 합니다. 그리하여 latent action space도 temporal한 dynamics에 align이 맞도록 하게끔 inductive bias로써 적용이 되며, 이것이 action generation 성능을 향상시키는 효과를 준다고 합니다. 저자들은 이 loss 설계를 Continuous action token representation 이라고 부르네요.
Execution Phase: “Dynamic Stop Mechanism” & “Reverse Temporal Ensemble”
이제 execution 시의 action이 generation되는 과정에 대해 저자 본인들만의 방식을 적용한 걸 설명하기 위해 도식화한 figure와 algorithm2의 inference phase 내용을 묶어서 설명해보도록 하겠습니다.

execution 단계에서 CoA는 역방향 autoregressive trajectory 생성을 그대로 유지하되, 실제 로봇 제어에 적합하도록 dynamic stop mechanism과 reverse temporal ensemble을 결합한 closed-loop 실행 방식을 채택하였습니다. 알고리즘 상으로는 한 번의 추론으로 전체 sub-trajectory를 생성할 수 있으나, 저자들은 실제 실행에서는 매 타임스텝마다 재추론을 수행하는 closed-loop 설정을 사용하여 이를 통해 매 실행 시점에서 예측된 action을 지속적으로 refine할 수 있었으며, 이 과정에서 reverse temporal ensemble이 핵심적인 역할을 했다고 주장합니다.
Reverse temporal ensemble은 여러 번의 역방향 rollout으로부터 생성된 sub-trajectory들을 예측된 keyframe action a_T를 기준으로 정렬한 뒤, 현재 시점에 해당하는 action들만을 집계하여 실행하는 구조를 가집니다. 모든 trajectory가 동일한 goal anchor에서 시작하기 때문에 시간 정렬 오차가 누적되지 않으며, 실행 시점에서는 항상 “현재에 가장 가까운 action” 하나만 선택적으로 적용되어 결과적으로 action 출력이 부드러워지고, autoregressive sampling으로 인한 분산이 완화되는 효과를 가져온다고 합니다.
Dynamic stop mechanism은 연속 action 공간에서 가변 길이 trajectory 생성을 가능하게 하기 위한 종료 조건인데요. 디코딩 과정에서 예측된 action이 현재 gripper 상태를 충분히 근사한다고 판단되면, 즉 두 상태 간 거리가 임계값 이하로 떨어지면 generation을 즉시 중단하는 휴리스틱한 메커니즘입니다. 코드 상으로는 0.01m, 즉 1cm error일때였는데요. 해당 stop 메커니즘은 EOS 토큰이 존재하지 않는 연속 제어 문제에서, 역방향으로 생성된 trajectory가 현재 시점에 도달했음을 의미하기에, 이 stop 메커니즘이랑 키포인트 액션이 있어야 사실 역방향 액션 생성의 의미가 있게 됩니다. 저자들은 해당 stop 메커니즘이 그리퍼 위치 수렴, 접촉 발생, 파지 완료 등 다양한 기준으로 일반화 가능하다고 하네요.
정리하면, execution 단계에서 CoA는 goal에서 현재로 역방향 생성된 trajectory 중 “지금 실행해야 할 action”만을 closed-loop로 반복 추출하며, dynamic stopping으로 불필요한 생성을 방지하고, reverse temporal ensemble로 실행 안정성을 확보하는 구조를 가지고 있습니다.
4. Experiments
4.1. Settings
좀 정리해서 개조식으로 작성하였습니다.
- Simulation setup
- RLBench (CoppeliaSim + PyRep) , Franka Emika Panda (7DoF)
- RGB cams (front, left shoulder, right shoulder, wrist) – 128×128
- Real setup
- Fetch robot (7DoF) / nav -> 2D LiDAR-based / manip -> RGB 224×224
- 생성된 액션을 어떻게 실제 제어로 연결짓는가?
- 모델이 예측한 Action(EEF Pose) -> PD 제어기 (pose error -> EEF vel) -> Jacobian IK Solve (EEF vel -> joint vel)
- Baseline
- 1) training visuomotor policies from scratch (VA)
- ACT , DP
- 2) finetuned generalist robotic policies (VLA)
- Octo
- 3) 3D-based hierarchical method (3D inputs + Motion Planner = 3D-VA?? )
- PerAct , 3D Diffuser Actor, RVT-2
- 1) training visuomotor policies from scratch (VA)
- Training and evaluation protocol per task
- Trained on 100 demos
- Evaluated on 25 demos
4.2 Overall comparisons
60 tasks on RLBench (w/ ACT, DP)
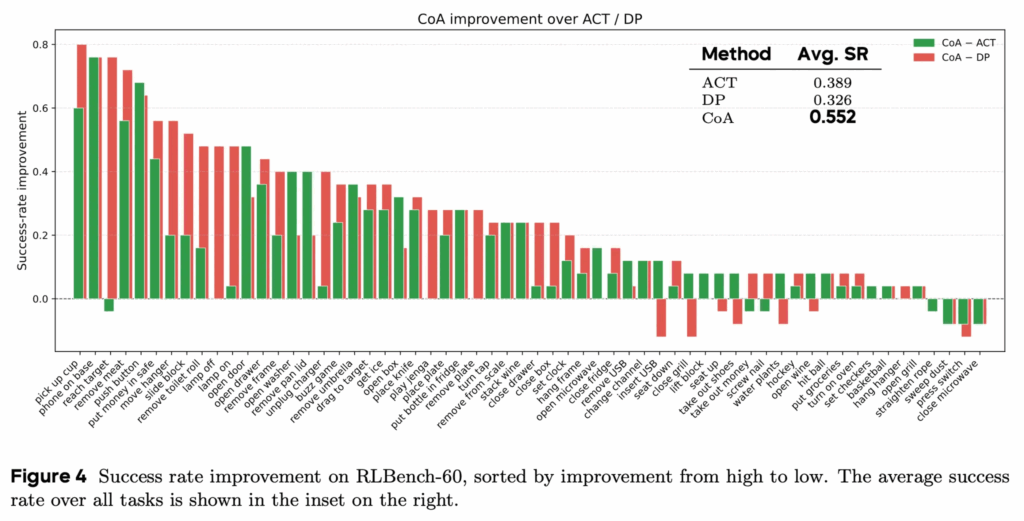
위 figure 4는 RLBench에서 60개의 각 작업에 대해 CoA가 기존 ACT 및 DP 대비 SR(Success Rate)를 내림차순으로 보입니다. 대부분의 작업에서 CoA가 ACT, DP보다 높은 SR을 보였고, 특히 객체 위치나 자세 변화가 큰 작업에서 개선 폭이 큰 모습을 보였습니다. 전체 평균 SR 역시 CoA가 ACT와 DP를 모두 유의미하게 상회하여, 이는 최대한 동일한 학습 파라미터, 유사한 아키텍처를 사용함에도 불구하고, 액션 시퀀스를 역방향으로 모델링하는 CoA의 설계가 공간적 일반화와 분포 이동 상황에서 효과적임을 보여주는 메인 결과로 볼 수 있었습니다.
10 tasks on RLBench (w/ 2D VA, 2D VLA)
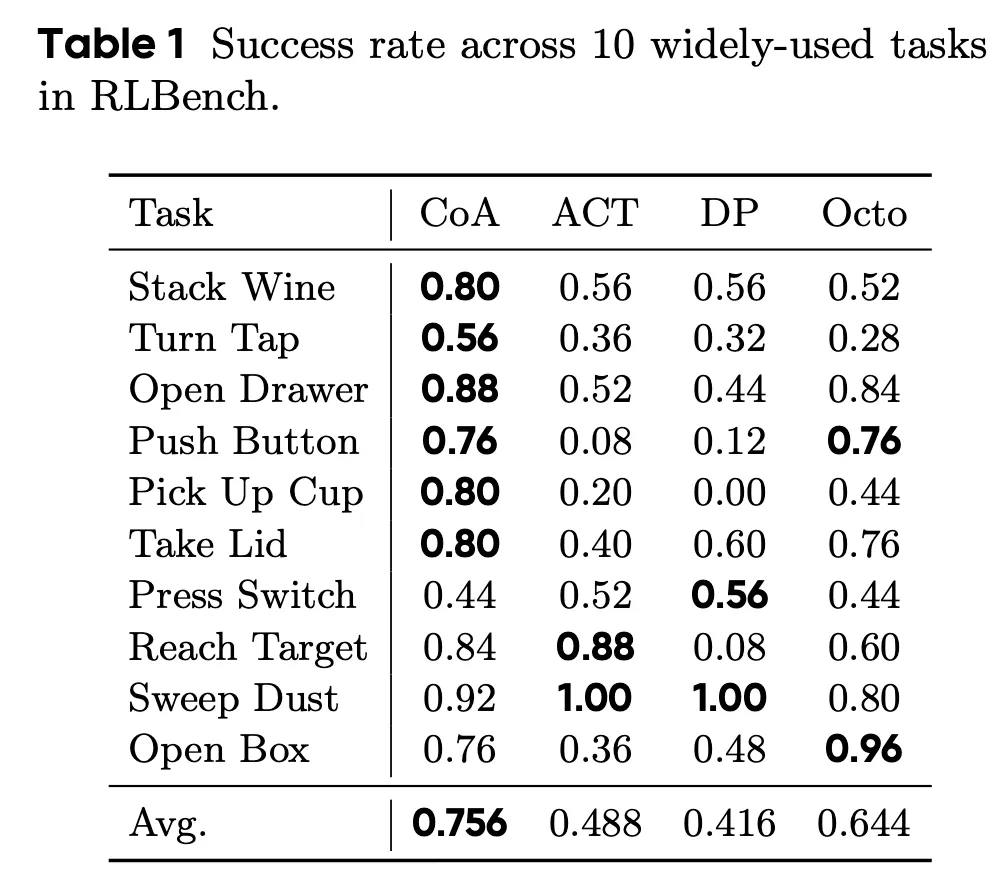
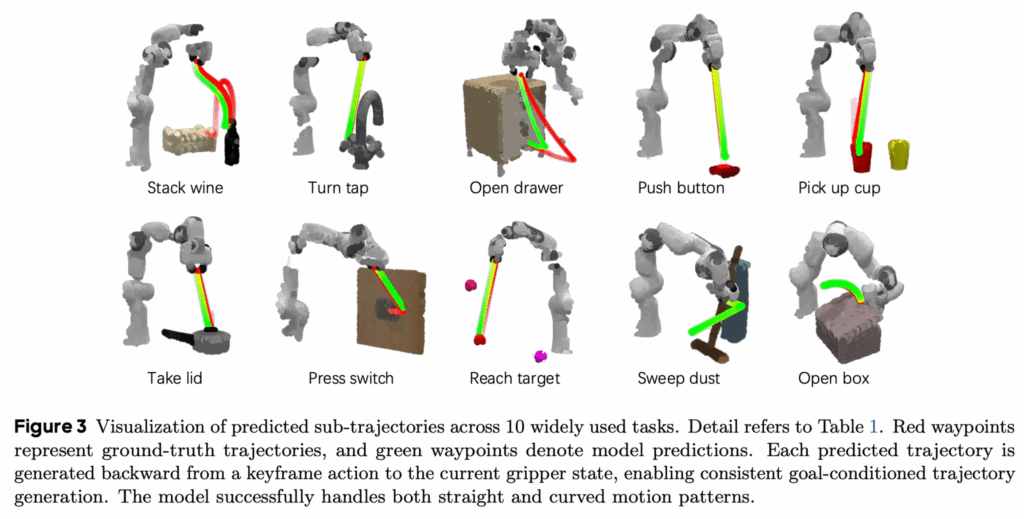
왼쪽의 Table 1은 RLBench에서 자주 사용되는 10개 태스크에 대해 CoA, ACT, DP, Octo의 성공률을 비교한 결과입니다. CoA는 평균 성공률 0.756으로, ACT와 DP를 크게 상회하며 80M 쯤되는 초기 VLA인 Octo보다도 전반적으로 높은 평균 성능을 보입니다. 근데 물론 일부 작업에서는 좀 밀리는 모습이 보입니다. 사실 이는 시각적인 결과물을 보면 어느정도 왜 그런지 유추를 해볼 수 있는데, 오른쪽의 Figure 3은 동일한 10개 작업에 대해 예측된 서브 트래젝터리를 시각화한 결과인데, 빨간 점은 실제 시연 궤적을, 초록 점은 모델이 예측한 궤적을 의미합니다. 각 궤적은 키프레임 액션에서 시작하여 현재 그리퍼 상태로 역방향 생성되며, 이를 통해 목표에 정합된 궤적을 일관되게 생성할 수 있음을 보여줍니다. 저자들은 직선 이동뿐 아니라 곡선 형태의 동작에서도 예측 궤적이 실제 궤적과 잘 정렬되어 있어, CoA가 다양한 공간적 동작 패턴을 효과적으로 모델링함을 확인할 수 있다곤 했지만, 저는 사실 이 부분에서는 아쉽게도 문제점을 생각해보게 되었습니다. CoA의 키프레임기반의 goal-conditioned 방식 자체가 Multimodal Action Distribution 문제를 그저 매우 RLBench에 핏하게 만든 inductive bias인 Global-to-local contraint를 사용해서 제약을 쎄게 떼려버린 탓에 궤적을 외워버린 건 아닐까 의문이 들기도 합니다. 인코더에서의 시각적인 임베딩과 그걸 K,V삼은 디코더에서의 컨디셔닝이 시각적 변화가 두드러지는 동적 객체나 동적인 시각변화가 있는 상황에서는 반응하지 못할 문제가 있다고 생각이 듭니다.
18 tasks on RLBench (w/ language-conditioned 3D VA , 2D VA)
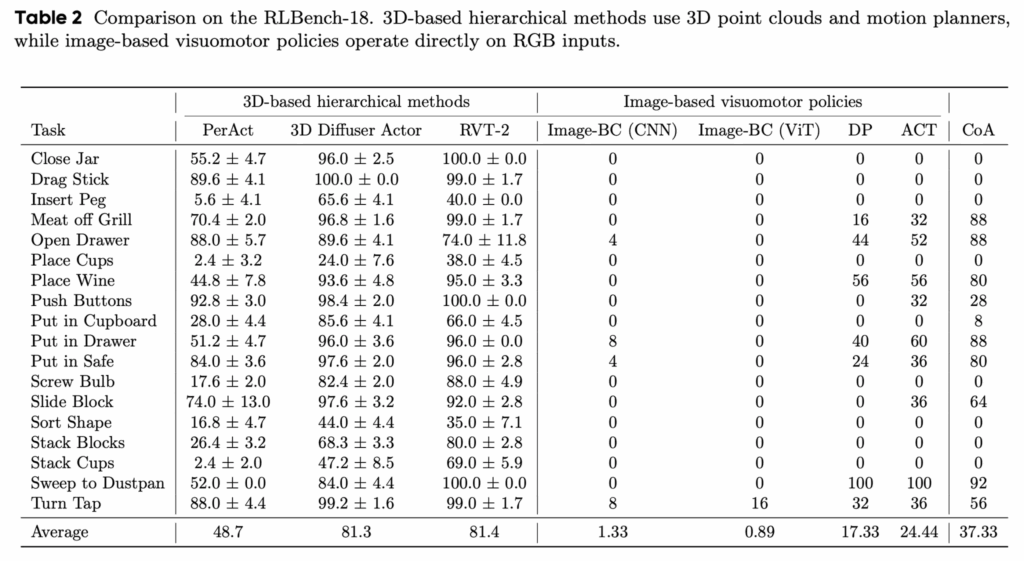
Table 2는 RLBench의 18개 태스크에서 3D 인풋 기반 계층적 방법들(이라고 말하지만 language-conditioned 3D VA인 방법론들)과 2D 인풋 기반 VA 정책들을 비교한 결과입니다. 여기서 언급한 3D 기반 방법들은 포인트클라우드와 예측된 ee pose에 대한 모션 플래너를 활용해 로봇의 액션 제어하는데요. 전반적으로 3D VA 방법론들이 평균 SR에서 높은 모습을 보였고, 2D 인풋 기반 방법 중에서는 CoA가 가장 높은 평균 SR을 보였습니다. 그럼에도 좀 낮은 결과같긴한데.. 저자들이 말하길 이는 CoA가 추가적인 3D 입력이나 명시적인 모션 플래너 없이도, 액션 시퀀스 생성 방식을 개선하는 것만으로 2D 기반 VA 정책의 한계를 상당 부분 완화할 수 있음을 시사한다고 합니다. 다만, 제가 생각했을 때는 3D VA로 소개한 방식들이 사실은 중간에 language conditioned가 들어간 형태였었는데, 3D정보랑 langauge 정보를 둘 다 적용하는 데 과연 pair한 comparison이 맞긴 한걸까라는 생각도 듭니다. 오픈리뷰에서의 리뷰 프로세스보니, 어떤 리뷰어가 해당 실험을 추가해달라는 부탁을 한 것 같긴 합니다.
4.3 Dive into spatial generalization
Correlation with spatial distribution
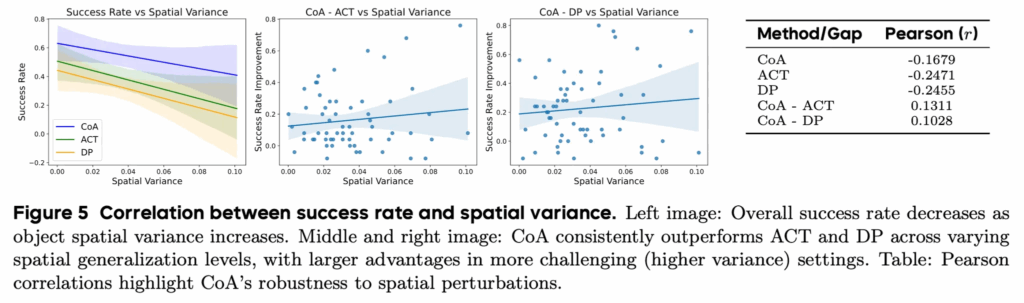
Figure 5는 객체 배치의 공간적 분산과 성공률 간의 관계를 분석한 결과입니다. 모든 방법에서 객체 위치의 분산이 커질수록 성공률이 감소하는 경향이 나타나며, 이는 공간적 일반화가 어려워짐을 의미합니다. 그러나 CoA는 전 구간에서 ACT와 DP보다 일관되게 높은 성능을 유지하며, 특히 공간적 분산이 커질수록 성능 격차가 더 크게 벌어지는 경향을 보입니다. 오른쪽의 Pearson 상관계수 기반의 비교를 보면 CoA가 상대적으로 더 완만한 성능 저하를 보임으로써 정량적으로도 실험결과를 뒷받침하는 모습을 보입니다.
Interpolation vs. Extrapolation case study (on Push Button task.)
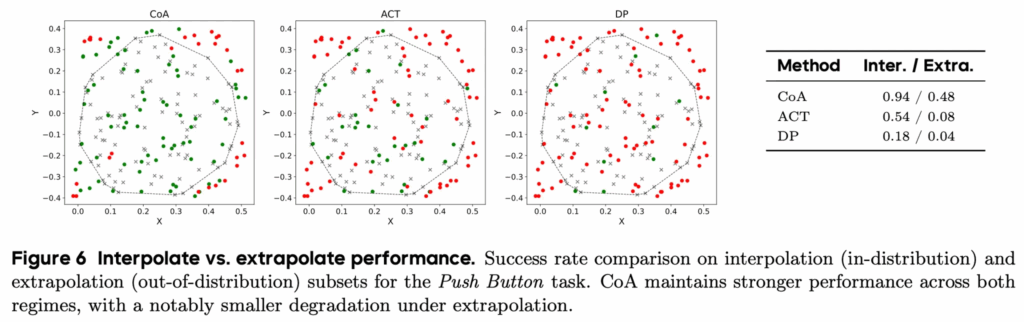
Figure 6은 Push Button 작업에서 공간적 일반화 특성을 분포 내부(interpolation)와 분포 외부(extrapolation) 설정으로 나누어 분석한 결과입니다. figure에서 회색 십자 표시는 학습에 사용된 100개의 데모 샘플을 나타내며, 색깔로 표시된 점들은 테스트 샘플로서 초록은 성공, 빨강은 실패를 의미합니다. 검은 점선은 학습 분포 범위에 해당하는 50개의 분포 내부 샘플과, 이를 벗어난 50개의 분포 외부 샘플을 구분하는 선을 그려넣은 것이라고 하는데요.
기존 ACT와 DP와 같은 순방향 VA policy들은 학습 중 관찰된 국소적인 공간 패턴에 강하게 의존하는 경향이 있어, 학습 데이터에서 자주 등장한 위치 근처에서는 비교적 안정적으로 동작하지만, 버튼 위치가 분포 외부로 이동할 경우 성능이 급격히 저하되는 모습을 보였습니다. 반면 CoA는 goal keyframe에 정렬된 역방향 궤적 생성을 통해 행동을 추론하기 때문에, 학습 분포를 벗어난 위치에서도 비교적 일관된 성공률을 유지했다고 합니다. 이는 CoA가 단순한 위치 기반 패턴 매칭이 아니라, goal conditioned 기반으로 공간적 추론을 수행하고 있음을 보여준다고 하네요.
Attention-based analysis of action chain

Figure 7은 Transformer 디코더 내부의 액션 토큰 간 self-attention을 시각화한 결과입니다. 대부분의 레이어에서 인접한 이전 액션들에 집중하는 체인 형태의 국소 의존성이 관찰되며, 이는 CoA가 액션 시퀀스를 연쇄적으로 추론하고 있음을 보여줍니다. 동시에 일부 레이어에서는 초기 키프레임 액션에 대한 장거리 의존성이 나타나, 목표 조건 정보가 전체 궤적 생성 과정 전반에 걸쳐 유지되고 활용됨을 확인할 수 있습니다. 이는 CoA가 global-to-local 추론 구조를 실제로 학습하고 있음을 구조적으로 뒷받침하는 분석 결과인 것으로 보입니다.
4.4. Ablation on architectural components
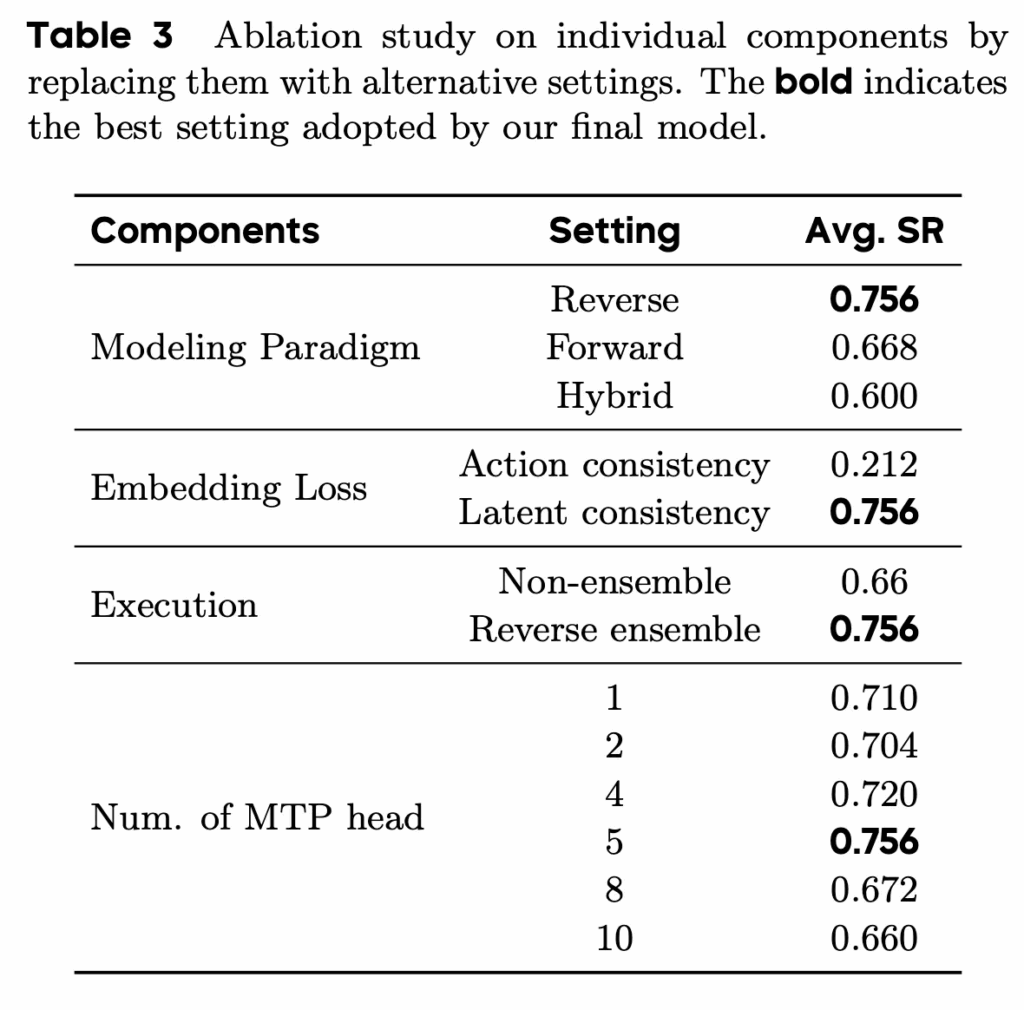
table 3은 모델 학습 시 아키텍쳐 구조나 loss에 대한 ablation study입니다. 먼저 모델링 패러다임 측면에서, 역방향 궤적 모델링이 순방향이나 혼합 방식보다 가장 높은 평균 성공률을 보였는데, 이 때의 hybrid 방식은 reverse 와 forward를 섞은 방식으로 goal에 해당하는 keyframe action으로부터 현재의 action을 예측하긴 하지만, reverse에서의 chain reasoning 과정을 아예 제거한 형태를 취합니다. 쉽게 말하면 keyframe action을 쿼리로 했을 때 goal에서부터의 액션 trajectory를 모두 추론하면서 와가지고 현재 시점의 action을 뱉겠다는 게 아니라, 그냥 keyframe action 보자마자 현재 시점의 action을 뱉어보겠다인 것입니다. 그렇게 했을 때는 forward보다 더 안 좋은 모습을 보였고, 해당 결과를 미루어보았을 때 reverse action generation으로 인한 action chain reasoning의 모델링 패러다임 자체가 유의미하다는 것을 확인할 수 있었습니다. loss에서는 action space에서의 텀과, latent action space에서의 latent consistency 텀 손실을 적용했을 때 비교하면 후자가 성능이 크게 향상되는 모습을 보였습니다. 이로써 loss수식의 당위성을 좀 보인 것 같구요. 실행 방식에 대한 분석에서는 단일 궤적 실행보다 reverse temporal ensemble을 적용한 경우 성능이 유의미하게 개선되어, 추론 단계에서의 안정화 기법이 효과적임을 보여줍니다. 마지막으로 MTP head 개수에 대한 실험 결과, 너무 적거나 많은 설정에서는 성능이 저하되며, 중간 규모인 5개의 head에서 최적의 성능을 기록하는데, 이는 MTP가 학습 안정성과 표현력 사이의 균형을 필요로 함을 나타냅니다.
4.5. Real-world experiments

위는 real 환경에서 Fetch robot (7DoF)의 navigation은 2D LiDAR-based로 수행하고, manipulation에 대해 좀 더 중점적으로 비교 실험을 보인 정성, 정량적 결과인데요. ACT와만 비교를 수행했는데, 생각보다 ACT보다 못하는 모습이 보여서,, real 실험을 보자마자 사실 RLBench 실험의 효용성을 좀 의심하게 됐습니다ㅋㅋ.. 사실 로봇은 시뮬레이터 뿐만 아니라 real에서 정말 잘해야되는데 말이죠. 또한 ACT말고 DP나 Octo하고는 비교를 하지 않았는데, 이는 저자들이 의도적으로 실험을 하지 않은 것인지, 아니면 실험을 했는데 전략적으로 리포팅을 하지 않은 것인지 의문이 들긴 합니다. 뭐가 됐든 DP, Octo가 왠지 더 성능이 좋았을 것 같다는 생각도 드네요. 더구나 또 맘에 걸리는 건 본 논문의 이미지 인풋이 4장이나 필요한데,, 이게 RLBench의 시뮬레이션 세팅을 따라서 그런거라지만 real에선 이미지 인풋을 언제나 3rd view로 4개 꽉 채워서 받을 수가 없기 때문에 성능이 그렇게 예쁘지 않은 것으로 보입니다. 실제로 real 실험 시 single RGB 이미지를 640 × 480으로 받았다가 224 × 224로 resize해서 인코더에 태우고, 학습용 데모 데이터는 각 태스크마다 좀 갭이 좀 있었는데, 적게는 35개에서 많으면 81개를 사용했다고 합니다. 평가는 10회 시도해서 SR를 산출한 것입니다.
본 논문은 액션 궤적을 autoregressive하게 모델링하되 이를 액션 레벨에서의 역생성 과정으로 패러다임을 바꾼 Chain-of-Action을 제안했습니다. 저자들의 문제정의였던 compounding error 에 대한 딥한 분석은 없어서 사실 실험결과의 결과론적인 내용으로만 만족을 해야했지만, spatial generalization 성능에 대한 몇가지 실험을 추가해주어 어느정도 문제정의에 대한 해소를 위한 실험을 추가해주었다는 사실을 엿볼 수 있었습니다. 또한 모델 설계에서 강조하길 backward action generation인 CoA가 global-to-local 구조를 강제로 제약시킨다는 말을 자주했는데, 사실 이 제약이란 말이 어떻게 보면 양날의 검인 것 같습니다. 결국 현재의 모델링 방식이 궤적 분할을 위해 휴리스틱한 키프레임 선택에 의존하고 있어서, 다양한 작업 유형으로의 일반화에는 한계가 있을 수 있기에, 해당 문제만 해결된다면 꽤나 큰 반향을 일으킬 패러다임일 수도 있을 것 같습니다. 저자들은 conclusion에서 말하길 향후 연구에서 키프레임 셀렉션 구조를 비지도 학습 방식으로 학습하는 방향을 탐색할 수 있을 것이라고 말하네요.
안녕하세요 재찬님 리뷰 감사합니다.
Action을 반대로 예측하는 구조에서 goal pose가 주어지기 때문에, implicit 하게 공간적 정보를 학습하는 VA 구조가 더 강화된다고 이해할 수 있을까요? KRoC가서 본 goal pose와의 relative ee 차이를 학습때만 예측하게 하는 방식이랑은 어떤 식의 차이점이 있다고 생각하시는지 궁금합니다!