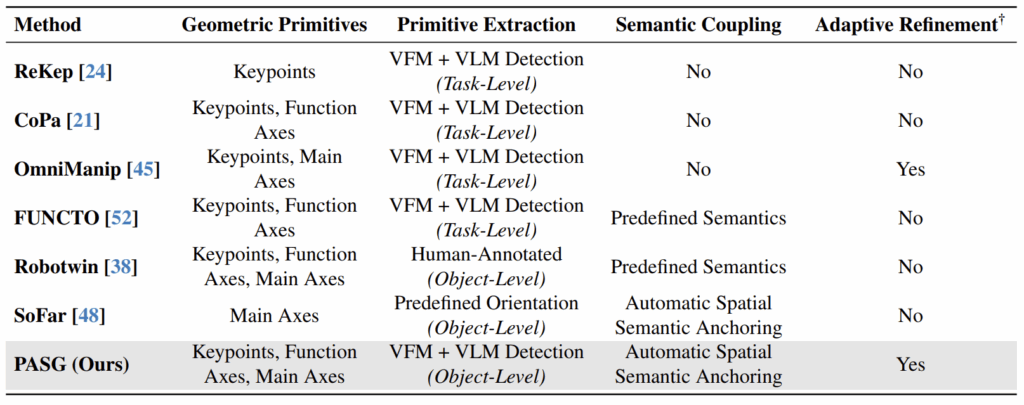
해당 논문은 ReKep, OmniManip와 같이 물체의 조작시 keypoint를 찾고 조작을 위한 방향과 같은 정보들을 primtive로 이용하는 논문이라 리뷰하게 되었습니다. 말이 참 복잡하지만, 정말 간단하게는 물체를 조작하는 데 있어서 의미에 따른 point와 axis를 설정하고, 작업에 대한 sub-task를 생성하여 매칭되는 point와 axis를 할당하는 것이라고 이해하면 좋을 것 같습니다. 이러한 과정을 자동화할 수 있으며, close loop방식으로 오류를 정정할 수 있도록 파이프라인을 구축하였다는 점도 함께 어필하고있습니다. 그럼 리뷰 시작하겠습니다.
Abstract
고수준의 작업 지시와 실제 로봇 작업을 수행하기 위한 구체적인 물리 정보와 같은 저수준의 기하학적 특징 사이의 단절로 인해 여전히 어려움이 있습니다. 최근 VLM을 활용하여 affordance를 고려한 시각적 표현 생성 방식이 유망한 성능을 보였으나, 실제 공간에서의 의미를 정확히 파악하거나 사람이 일일이 정보를 제공해야한다는 번거로움이 있었습니다. 따라서 로봇이 물체의 의미와 기능을 제대로 이해하고 조작하는 데 어려움이 있었습니다. 이러한 문제를 해결하기 위해, 해당 논문은 PASG(Primitive-Aware Semantic Grounding)이라는 closed-loop 프레임워크를 제안합니다. PASG는 조작 대상 물체의 핵심적인 기하학적 특징을 자동으로 추출하고, VLM을 활용하여 기하학적 특징들에 물체의 기능적 의미를 동적으로 연결합니다. 또한, 공간적-의미론적 대응에 대한 이해를 평가할 수 있는 새로운 벤치마크와 fine-tuning된 VLM(Qwen2.5VL-PA)를 제안합니다. PASG의 효과를 로봇 조작 작업의 다양한 시나리오에서 입증하였으며, 수동 어노테이션 방식과 비슷하거나 더 좋은 성능을 달성하였으며, 이는 PASG가 객체의 의미와 기능을 잘 이해하고 이를 바탕으로 유연하고 효과적인 조작이 가능하도록 함을 보여줍니다. 최종적으로, PASG는 기하학적 정보와 작업에 대한 의미론적 정보를 통합하는 새로운 방식을 제안합니다.
Introduction
구조화되지 않은 환경에서의 로봇 조작의 일반화는 low-level의 상호작용에 대한 primitives(points와 축)와 high-level planning의 불일치로 인해 어려움으로 남아있습니다. LLMs와 VLMs의 상식적 추론 능력을 로봇 조작에 활용하기 위한 연구가 이루어지고 있으나, 대부분 high-level planning이나 task decomposition에 집중하고있으며, 3D 공간적 정보에 대한 추론 능력은 아직 미흡한 상황입니다. 이는 객체의 canonical space에 대한 불충분한 이해에서 비롯되며, 예를 들자면, 차주전자에 대한 수동 라벨인 손잡이 부분에 중심 포인트는 기능적 이해가 부족하여 부정확한 공간 제약을 추론하게 됩니다. 따라서, 로봇에 공간에 대한 이해 능력을 부여하기 위해, 일반적으로 대규모 조작 시연 데이터로 VLM을 fine-tuning하는 방식으로 이루어진다고 합니다.
로봇의 공간적 primitive 이해를 위해, VLM을 튜닝하는 방식들은 비용이 많이 들고 일반화를 방해하는 수동 기하학적 primitive(keypoints, axes)를 필요로합니다. 최신의 선행 연구는 사전학습된 VLM을 통해 상호작용의 feature를 인식하고, VLM 기반의 의미론적 필터링을 통해 작업과 관련된 primitives를 식별합니다. 그러나 이러한 방식은 SAM과 DINOV2와 같은 방식으로 자동으로 탐지된 요소들이 검증되지 못하여 오류를 전파하고 성공률을 저하시킬 수 있으며, 객체의 주요 축과 같은 필수적 방향의 특징을 간과하고 keypoint와 방향만을 포함하는 불완전한 정보는 로봇 작업의 실패를 초래합니다.
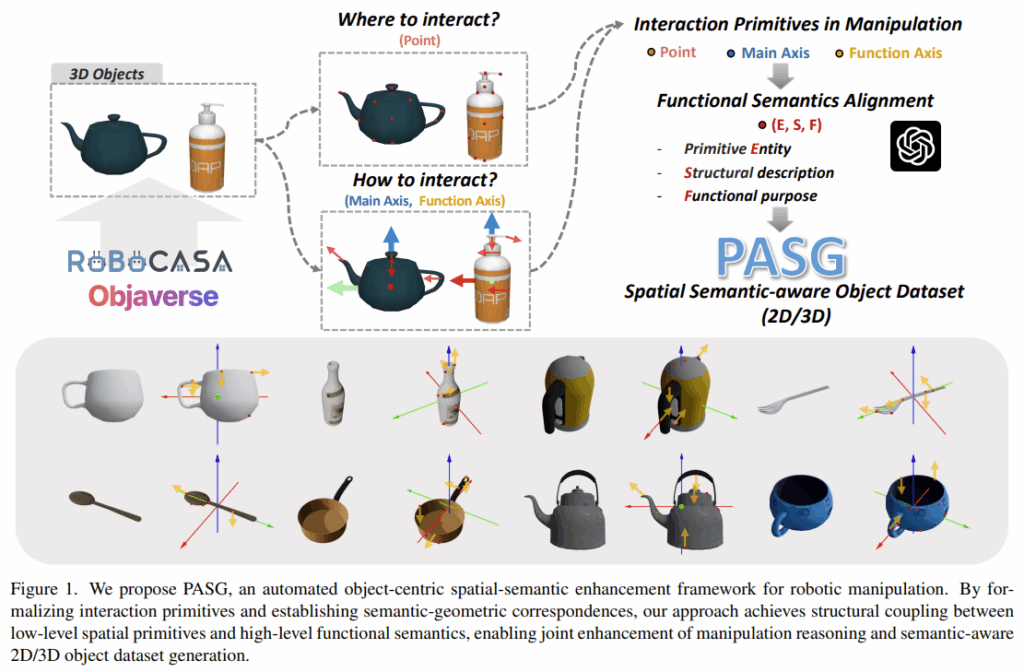
이러한 문제를 다루기 위해, Fig. 1과같이 closed-loop 프레임워크를 제안하며, 이는 다음의 주요한 개선점을 제공합니다. 첫째, PASG는 기하학적 특징 추출 모듈은 수동 라벨 없이 VFM과 기하학적 위성 분석을 통합하여 상호작용의 기본 요소인 keypoint와 방향, 주축을 자동으로 감지합니다. 둘째, VLM을 사용하여 low-level의 설명부터 high-level의 의도까지 다중으로 세분화된 의미를 추출하여 자체 수정이 가능한 특징 추출 루프인 동적 의미론적 고정 메커니즘을을 구현합니다. 셋째, 시뮬레이션 환경 내의 다양한 작업에 대한 광범위한 조작 실험을 통해 PASG의 실용성을 검증하였으며, 수동 라벨에 비해 경쟁력 있거나 우수한 성능을 달성하였습니다. 마지막으로, 조작 시나리오에서 기능적 요소에 대한 이해를 확장할 수 있으며, 객체 기반의 평가를 지원하는 광범위한 벤치마크인 Robocasa-PA를 제공하고, LoRA fine-tuning을 통해 Qwen2.5VL-PA를 개발하여 최소한의 cross-domain 편차로 77.8%의 정확도를 달성하였습니다.
해당 논문의 contribution을 정리하면,
- 객체 interaction primitives에 대한 계층적 의미를 자동으로 어노테이션하는 새로운 프레임워크를 제안하여, low-level의 기하학적 특징과 high-level 작업 의미 사이의 간극 해소
- 3가지 작업에 대한 8,343개의 검증된 visual question을 포함하는 Robocasa-PA를 제안하며, 조작에서 기능적 primitives를 이해하고 평가하기 위한 벤치마크를 최초로 제안
- 실제 조작 시나리오에서 PASG 효과를 임증하였으며, 사람이 라벨링한 방식과 비교했을 때 경쟁력 있거나 개선된 성능을 달성
Method
해당 논문은 (1) 공간 기하학적 primitive를 어떻게 정의할지, (2) 물체에서 자동으로 기하학적 primitive를 어떻게 추출할지, (3) 동적으로 기하학적 primitive와 작업에 대한 의미 간의 정렬을 어떻게 맞출지, (4) 조작 작업에 추론을 어떻게 강화할 수 있을 지 4가지 질문에 대하여 탐구합니다.
1. Semantic Primitives in Robotic Manipulation
공간적 primitives는 planning과 실행을 위한 기본 요소로, 전통적으로 기하학적 요소 E (points/axes/orientations)로 정의됩니다. 그러나, 종종 단순 기하학적 요소를 넘어 의미론적 요소 S와, 기능적 정보 F를 모두 포함하기도 합니다. 예를 들면, 컵의 손잡이를 나타낼 경우, 기하학적으로는 돌출부이지만 의미론적으로는 잡아야 하는 영역을 의미한다는 것 입니다. 따라서, 이러한 방식으로 기하학적 primitives를 보강함으로써 물체의 용도와 기능을 더 잘 파악할 수 있을 것이라 보고, 기하학적, 구조적, 기능적 속성을 결합한 interaction primitives (E,S,F)를 정의합니다.
- E: 기하학적 요소
- S: 객체 구성요소의 구조적 설명
- F: 조작시의 기능적 역할
조작 작업의 의미론적 정보를 더 통합하기 위해, 조작 요구사항에 기반하여 interaction primitives를 point-based(\mathcal{P})와 axis-based (\mathcal{A})로 분류합니다.
- Point Interaction Primitives (\mathcal{P}): 조작에 중요한 특정 위치
- Anchor Point (p_a):객체가 작업 공간에 배치되거나 정렬되는 방식을 결정하는 기준 위치 (e.g. 주전자의 주둥이 끝)
- Grasp Point (p_g): 로봇의 end-effector가 안전하게 잡기 위한 위치 (e.g. 컵 손잡이)
- Actuation Point (p_{act}): 눌리거나 조작될 때 기능을 트리거하는 지점 (e.g. 전원버튼)
- Axis Interaction Primitives (\mathcal{A}): 객체의 방향 및 움직임 제약을 명시
- Primary Axis(a_p): 객체의 주요 방향축으로, 기하학적 구조나 대칭성에 의해 결정됨 (e.g. 주전자의 수직 z축)
- Functional Axis(a_f): 객체의 조작 또는 기능과 정렬된 축으로, 객체의 동작 방향 (e.g. 망치의 헤드 방향)
- Approach Axis(a_{app}): 로봇의 end-effector가 특정 지점과 상호작용하기 위해 접근해야 하는 방향 (e.g. 손잡이를 잡기 위해 옆에서 다가오는 방향)
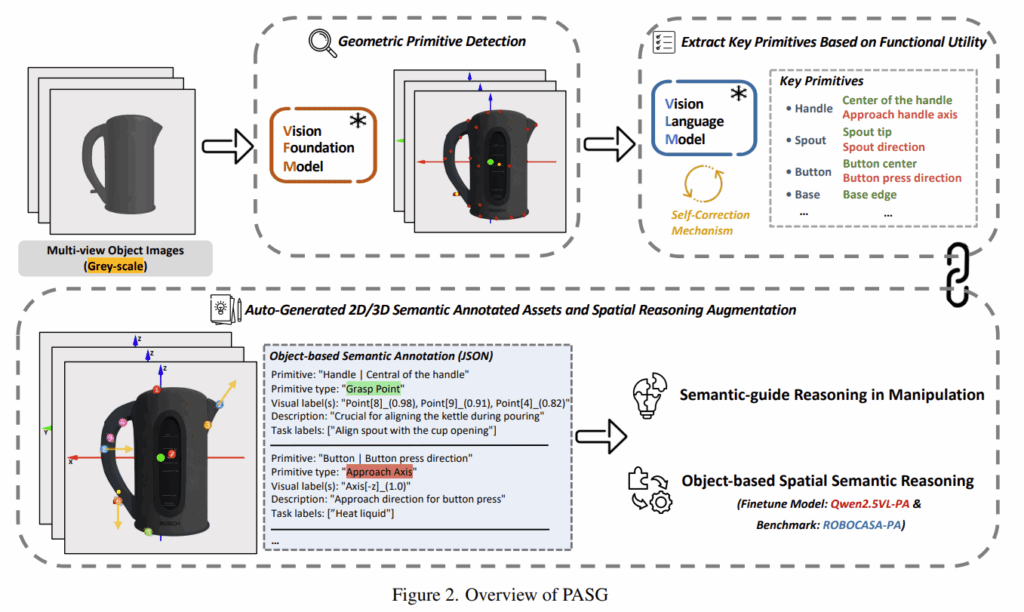
2. Geometry Primitive Extraction
다음은 어떻게 primitive를 자동으로 추출할지에 대한 섹션입니다. 저자들은 정밀한 영역 분할을 위해 VFM을 사용하였으며, 이후 keypoint 탐지 및 필터링 과정을 거칩니다.
VFM-Based Region Segmentation
3D mesh에 대한 멀티뷰 이미지(\mathcal{I} =\{I_1, …,I_n\})에 Semantic-SAM(ECCV2024논문)을 적용하여 segmentation masks (\mathcal{M} =\{M_1, …,M_n\})를 얻은 뒤, SoM(set-of-marker) 의 전처리 방식(마스크 크기별로 오름차순으로 작은 마스크를 먼저 남긴 뒤, 너무 작은 마스트와 겹치는 영역이 있는 마스크는 삭제)을 이용하여 작은 영역과 배경 노이즈를 제거합니다.
Keypoint Extraction
기하학적 keypoints(\mathcal{K}_{raw})를 탐지하기 위해, 마스크의 중심점(\mathcal{C} =\{c_1, …,c_n\})과 코너 특징점 (\mathcal{F} =\{f_1, …,f_n\})을 추출합니다. 추가로, PCA를 활용하여 마스크로부터 2개의 직교 축을 계산하여, 이 축들이 경계와 교차하는 지점을 보조 특징점으로 추출합니다.
Keypoint Filtering
탐지된 keypoints \mathcal{K}_{raw}로부터 2단계 필터링을 적용합니다. DBSCAN clustering을 통해 국소적으로 밀집한 점들을 제거하고, FPS(farthest point sampling)를 적용하여 전역의 특징을 선택하여 중심 포인트 집합 \mathcal{C}와 feature points 집합 \mathcal{F}fmf vhgkagksms 최종 keypoints \mathcal{K}_{filter}를 생성합니다.
Principal Axis Calibration
표준화된 축 표현을 위해, 대부분의 3D 객체는 데이터 셋에서 미리 정렬된 principal axis를 제공합니다. 상하단 마스크의 기하학적 중심을 연결하는 선으로 Z축을 정의함으로써 축을 보정하며, 직교 X/Y축은 이후 생성됩니다. 또한, 다양한 객체와 뷰포인트에 축을 동일 색상으로 표시합니다.
3. Task-Oriented Semantic Annotation
다음은 기하학적 primitive와 작업에 대한 의미 간의 동적 정렬을 어떻게 맞출지에 대한 내용입니다.
Object-Centric Semantic Primitive Identification
객체 o에서 의미론적으로 중요한 요소를 식별하기 위해, 작업 시나리오 구성 및 sub-goal decomposition을 수행합니다. 구체적으로는, 멀티뷰 이미지(\mathcal{I})의 기하학적 및 물리적 특징을 분석하기 위해 VLM을 이용하여 가능한 로봇 조작 작업 (\mathcal{T} =\{t_1, …,t_m\})를 추론합니다. 각 작업 t_i는 각 단계별로 명시적인 작업 목표로 구성된 하위 단계 (\mathcal{G}_i =\{ g_{i1}, …,g_{ik} \})로 분해됩니다. 이후 작업과 연관된 primitives를 식별하기 위해 각 하위 작업에 대한 기본 primitive 제약 조건을 설정합니다. (\mathcal{R}^o_{ij}(P^o_{ij},A^o_{ij}) ⇒ g_{ij}) 여기서 P^o_{ij} ⊆ \mathcal{P}^{o}, A^o_{ij} ⊆ \mathcal{A}^{o}로, 앞서 물체에 대해 정의한 points와 axis에 대한 primitives에 포함되어야 한다는 것을 의미합니다. 통합 primitive는 아래와 같이 구해지며, 결국 세부 작업에 해당하는 primitives들로 구성된다는 것을 의미합니다.
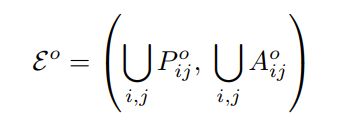
Visual-Semantic Primitive Alignment
객체 o에서 여러 기하학적 keypoint p_i \in \mathcal{K}^o_{filter}가 \mathcal{E}^o의 의미론적 설명과 일치할 때 신뢰도 점수 s \in [0,1] 와 모든 후보를 기록하고, 일치하지 않을 경우 None을 반환합니다. 의미론적 방향의 경우, principal axis와 기능적 용도에 따른 방향을 함께 활용하는 것 같습니다.
Dynamic Self-Refine Matching Mechanism
primitives의 부정확성과 특징 추출기로 인한 정보 손실을 해결하기 위해, 아래의 알고리즘 1과 같은 동적 self-refine 매칭 방식을 이용합니다. 먼저, 0.5 미만의 낮은 신뢰도를 갖거나 None이 포함된 primitives는 계층적 분할을 통한 annotation을 하도록 하며, Semantic SAM의 다중 세분화를 활용하여 재샘플링을 통해 기하학적 primitives를 정제하고 segment-align-detect-resample이라는 closed loop 플로우를 형성합니다. 실험결과 이러한 방식이 저자들의 데이터셋에서 98%의 매칭 성공률을 보였으며, 열악한 분할로부터 오류를 효과적으로 완화하였다고합니다.

4. Semantic-guide Reasoning in Manipulation
기하학적 annotaion이 달린 object 데이터셋을 생성하는 것을 넘어, 해당 프레임워크는 공간적-의미론적 정보를 조작 작업에 통합하는 것을 목표로 합니다. 주석이 달린 객체와 멀티모달 입력을 활용하여 PASG 파이프라인이 다양한 객체 범주에 걸쳐 interaction primitives를 안정적으로 식별할 수 있음을 실험적으로 보였습니다. 수동 라벨링 된 데이터와 비교하였을 때 PASG로 생성된 주석이 더 다양한 의미론적 정보를 포함하는 것을 확인하였으며, 이러한 다양성을 기반으로 후속 작업과 다양한 조작 작업에 효과를 보였다고합니다.

Experiment
Semantic-aware Object Dataset
해당 논문은 RoboCasa와 Objaverse 데이터로부터 원본 데이터를 수집하였다고합니다. RoboCasa는 일상 작업에서 150개 이상의 카테고리를 포함하는 2,500개 이상의 고품질 3D 객체를 제공하고, Objaverse는 800,000개 이상의 주석이 달린 3D 객체를 포함하는 대규모 데이터입니다. 이 중 기능이 적거나 식품류와 같이 조작 가능성이 제한적인 물체는 제거하였다고 합니다. 이런식으로 5,231개의 객체를 선별한 뒤, 모든 객체를 적절한 크기로 조정하고, 여러 시점으로 렌더링하여 41,848개의 2D 이미지 데이터셋을 구축하였다고합니다.
이후, 해당 논문이 제안하는 PASG를 적용한 뒤, GPT-4o를 이용하여 시각적 프롬프트에 대한 공간적 의미론 annotation을 수행합니다. 이를 검증하기 위해, 무작위로 50개의 주석이 달린 객체를 샘플링하여 수동으로 검사를 수행하였다고 합니다.
Manipulation Task Evaluation
PASG 프레임워크의 효과를 검증하기 위해, 해당 연구에서는 RoboTwin 시뮬레이션 플랫폼을 사용하여 다양한 시나리오에 대한 평가를 진행했습니다. 평가 작업은 싱글/듀얼 암 조작, 복잡한 환경에서의 상호작용 등 6가지 대표적인 조작 작업((1) Block Hammer Beat, (2) Container Place, (3) Dual Bottles Pick, (4) Empty Cup Place, (5) Pick Apple, and (6) Messy Shoe Place-순서대로 아래 표의 약자에 해당)으로 구성됩니다.
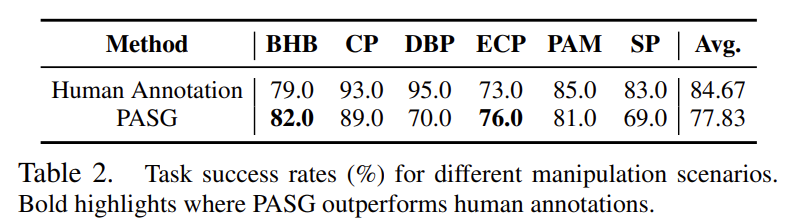
위의 Table 2는 수동 주석을 포함하는 베이스라인과 PASG 기반의 조작의 작업 성공률을 나타낸 것으로, 각 작업은 무작위로 초기화되어 100번 작업을 실행하였을 때 성공률입니다. PASG 기반의 방식은 수동 라벨링 방식과 비교했을 때, 경쟁력 있는 성능을 달성하였으며, BHB와 ECP 작업에서는 더 좋은 성능을 보였습니다. 이를 통해 PASG 방식으로 primitives를 라벨링하는 방식의 효과를 검증하였습니다. 아래의 그림은 정성적 결과로, 수동 라벨링 방식에 비해 다양하고 풍부한 interaction pritmitives를 얻을 수 있다는 것을 보여주고있습니다. 이러한 다양성은 조작 정책에 유연성을 제공하고, 강인성을 부여할 수 있습니다. 예를 들어 특정 포인트가 가려지거나 접근할 수 없는 경우에 다른 포인트로 대체가 가능하기 때문입니다.

Object-based Spatial-Semantic Reasoning
PASG 프레임워크가 객체에 대한 공간적 기본 요소를 얼마나 잘 포착하는지 평가하기 위해, Robocasa-PA라는 새로운 question-answer 벤치마크를 제안합니다. 이 벤치마크는 PASG를 사용하여 Robocasa 데이터셋에서 생성되었으며, 로봇 조작에서 기능적인 기하학적 기본 요소에 대한 모델의 이해도를 평가하도록 설계되었습니다. 해당 데이터셋은 다음 세 가지 주요 질문 유형으로 구성됩니다.
- Type Identification (Task 1): 시각적 특징을 기반으로 공간적 primitives의 기능적 유형을 결정
- Task Association (Task 2): 감지된 primitives를 특정 로봇 조작 작업과 연결
- Task-to-Primitive Mapping (Task 3): 주어진 작업을 수행하는 데 필요한 primitives를 식별
모델 일반화를 평가하기 위해 Robocasa-PA는 다음 세 가지로 나뉩니다. 먼저 기본 객체로 지정된 풀에서 6,979개의 질문을 생성하고, primitive 구조에 대한 기초적인 이해를 확립하기 위해 80%(5,583개 질문)를 fine-tuning용 학습 데이터로 할당합니다. 동일한 객체 풀의 나머지 20%(1,396개 질문)로 in-distribution test 셋을 구성합니다. cross-domain adaptability를 엄격하게 평가하기 위해, 객체 및 primitive 모두에서 학습 인스턴스와 격리된, unseen 객체에서 파생된 1,364개의 질문으로 구성된 out-of-distribution test 셋을 구성합니다.
Fine-Tuning
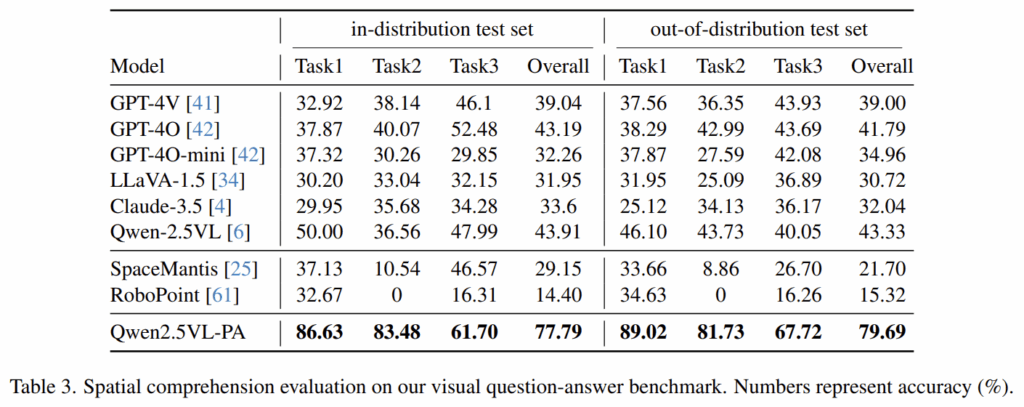
Qwen-2.5VL 모델에 LoRA 방식으로 fine-tuning하여 VQA 벤치마크가 primitive compositional reasoning에 대한 지식을 화보할 수 있는 지 평가합니다. Qwen2.5VL-PA가 fine-tuning된 모델로, 베이스라인 대비 상당하 성능 개선이 이루어졌음을 확인할 수 있으며, 기하학적-의미론적 지식을 작업에 적용하는 저자들의 프레임워크의 효과를 입증하였습니다. 특히, 해당 모델은 out-of-distribution인 경우에도 강인하게 작동함을 입증하였습니다.
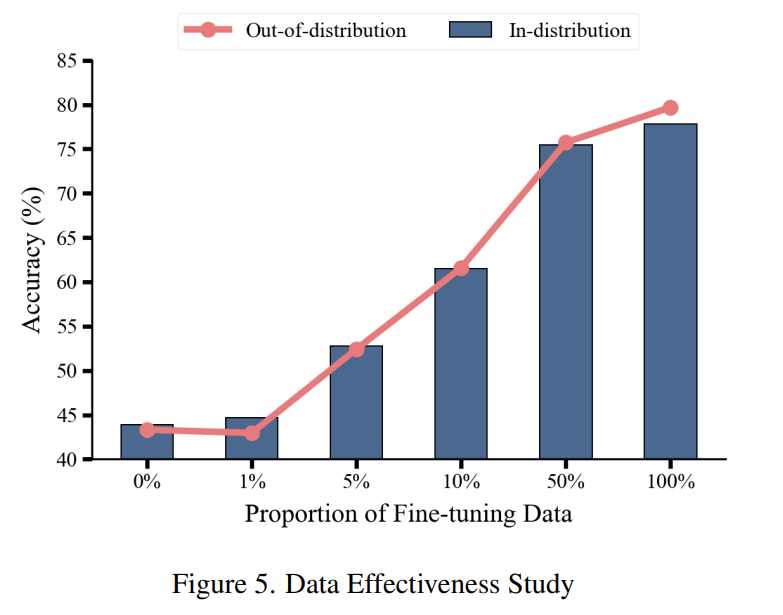
Data Effectiveness
마지막으로, 데이터 효율을 확인하기 위해, 원본 학습 데이터에서 무작위로 1%, 5%, 10%, 50%의 데이터를 샘플링하여 실험을 수행하였습니다. 아래의 figure 5가 이에 대한 실험 결과로, 5%부터 베이스라인(Qwen-2.5VL)대비 10%정도의 성능 개선 뿐만 아니라 기존의 다른 방법론들보다 더 개선된 성능을 보여주는 것을 확인할 수 있습니다. 뿐만 아니라, out-of-distribution 결과에 대해서도 성능 격차가 ±2% 이내로 안정적이었다고 합니다.(아래 그래프의 분홍 선)
Conclusion
해당 논문은 로봇 조작에서 작업 의미론과 기하학적 primitives를 연결하는 closed-loop 프레임워크인 PASG를 제안하며, 자동화된 기하학적 primitives 추출과 VLM 기반 의미론적 앵커링을 결합함으로써, PASG는 동적 공간-의미론적 추론을 가능하게 합니다. 또한, 다양한 조작 작업에 걸친 RoboTwin 플랫폼에서의 평가는 PASG가 인간 주석과 경쟁력 있는 성능을 보이며, 특정 작업에서는 더 좋은 성능을 보임을 입증합니다. PASG의 다양한 interaction primitives 생성 능력은 작업 유연성과 강건성을 향상시켜 실제 응용에 적합하게 만듭니다. 추가로, Robocasa-PA 벤치마크와 파인튜닝된 Qwen2.5VL-PA 모델을 통해 프레임워크의 효과를 입증하였으며, 로봇 조작에서 일반화 및 cross-domain adaptability를 향상시키는 고품질 annotation 데이터를 생성하기 위한 자동화된 파이프라인을 제공합니다.