안녕하세요 오늘은 VLA 모델 중 하나인 GR00T N1 논문에 대해서 설명드리도록 하겠습니다. GR00T 같은 경우에는 기존에 있던 VLA들과 차별점을 둔 VLA의 구조 자체도 정의하긴 했지만 데이터 증강 혹은 처리에 대해서도 집중적으로 다룬 느낌이 들어 두 부분에 대해서 집중해서 봐주시면 될 것 같습니다. (적다보니 알게된 사실이지만 GR00T은 G-R-O-O-T가 아니라 G-R-0-0-T입니다….)

- Conference: arXiv 2025
- Authors: NVIDIA: Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi “Jim” Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang Tan, Guanzhi Wang, Zu Wang, Jing Wang, Qi Wang, Jiannan Xiang, Yuqi Xie, Yinzhen Xu, Zhenjia Xu, Seonghyeon Ye, Zhiding Yu, Ao Zhang, Hao Zhang, Yizhou Zhao, Ruijie Zheng, Yuke Zhu
- Affiliation: NVIDIA
- Title: GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
1. Introduction
NVIDIA에서는 로봇이 인간 수준의 물리적 지능을 얻기 위해 세 가지 핵심 요소인 Hardware, Model(AI), Data를 통합하는 full stack 솔루션을 향해 나아가야 된다고 하고 있습니다. 또한 이러한 인간 수준의 지능과 함께 인간과 유사한 체격을 가지면서 다재다능한 휴머노이드 형태를 해당 논문에서는 사용을 했다고 서술하고 있습니다.
그러나 휴머노이드 로봇에 대해서는 기존의 foundation model과 같이 시각 및 텍스트 이해에 대해서 많은 데이터를 가지고 있는 것이 아니기 때문에 이러한 것을 그대로 백본으로 적용할 수 있는 방법이 존재하지 않고, 그렇다고 대규모 데이터를 획득하기에는 비용이 크게 들기 때문에 이런 점에서 효과적인 데이터 전략이 필요합니다.
기존에 다른 로봇들의 훈련 데이터를 모아 데이터셋을 확장하기 위한 cross-embodied learning 방식이 제시되었지만 이런 방식은 로봇 구현체, 센서, 액추에이터 자유도, 제어 모드의 다양성에서 진정한 일반화 모델을 학습하는데 일관성있는 정보를 모델에게 제공해주는 것이 아니라 Data islands의 군집을 초래, 즉 데이터들이 파편화 되어 있기 때문에 fitting하기가 어렵다고 합니다.
결과적으로 해당 논문, NVIDIA에서는 범용 휴머노이드 로봇을 위한 open foundation model인 GR00T N1을 소개합니다. GR00T N1 모델은 이미지 및 언어 지침 입력으로부터 행동을 생성하는 Vision-Language-Action (VLA) 모델로 table-top 로봇팔부터 정교한 휴머노이드 로봇까지 cross-embodiment에 대한 지원을 한다고 합니다. 아키텍쳐 구성은 인간의 인지 처리 방식에서 영감을 받은 이중 시스템 구성 아키텍쳐를 사용합니다.
System 2 추론 모듈은 NVIDIA L40 GPU에서 10Hz로 실행되는 pre-train된 VLM입니다. 이 모듈로 로봇의 시각적 인식과 언어 지침을 처리해 환경을 해석하고 작업 목표를 이해합니다. VLM에서 이해된 환경과 task에 대한 token은 action flow matching으로 학습된 Diffusion Transformer, System 1가 받아 Action moduledp동작을 출력합니다. VLM의 출력 토큰에 cross attend하며 동작 생성을 위해 가변적인 상태 및 액션 차원을 처리하기 위한 구현체별 인코더와 디코더를 사용한다고 합니다. 120 hz의 주파수로 closed-loop 모터 액션을 생성하며, System 1과 System2는 모두 트랜스포머 기반 신경망으로 학습 중에 공동으로 결합되어 최적화됩니다.
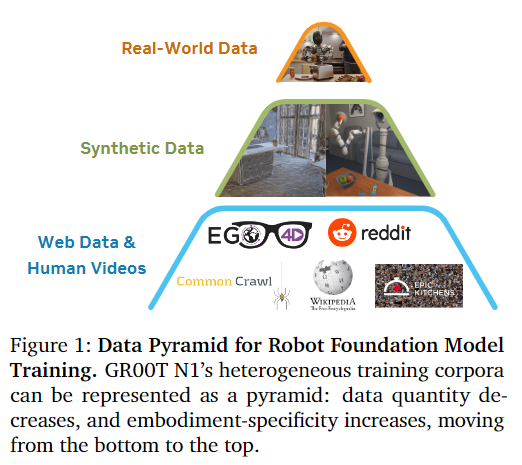
Data island 문제를 해결하기 위해 데이터를 피라미드 형태로 구성해, 대량의 웹 데이터와 인간 비디오가 피라미드의 기초, 물리 시뮬레이션으로 생성되거나 off-the-shelf neural model은 중간층, 실제 로봇 하드웨어에서 수집된 실제 데이터가 최상단에 위치합니다. 하위 계층은 광범위한 사전 지식, 상위 계층은 실제 로봇 실행에 대한 근거를 제공한다고 보시면 될 것 같습니다.
인간 비디오 및 신경망으로 생성된 비디오와 같이 액션이 없는 데이터 소스로 모델을 학습하기 위해 latent-action codebook을 학습하고 학습된 역동학 모델( inverse dynamics mod, IDM)을 사용해 pseudo-actions을 추론합니다. 이를 활용해 액션이 없는 비디오에 액션에 대한 주석을 추가할 수 있으므로 모델 학습을 위한 추가적인 로봇 구현체로 취급하여 사용할 수 있습니다. 피라미드 데이터 계층에 걸쳐서 모델을 end-to-end로 사전학습하며, 서로 다른 데이터 소스에서 배치를 샘플링해서 혼합 학습을 진행한다고 합니다. 저자가 말하기로는 통합된 모델과 단이 가중치 세트를 활용하면 단일 팔, 양팔, 휴머노이드 등에 걸쳐서 다양한 조작 행동을 생성할 수 있다고 합니다.
결과적으로 기존 최첨단 imitation learning 기준선에 비해서 표준 시뮬레이션 벤치마크 환경에서 평가했을 때 우수한 결과를 보인다고 합니다.
2. GR00T N1 Foundation Model
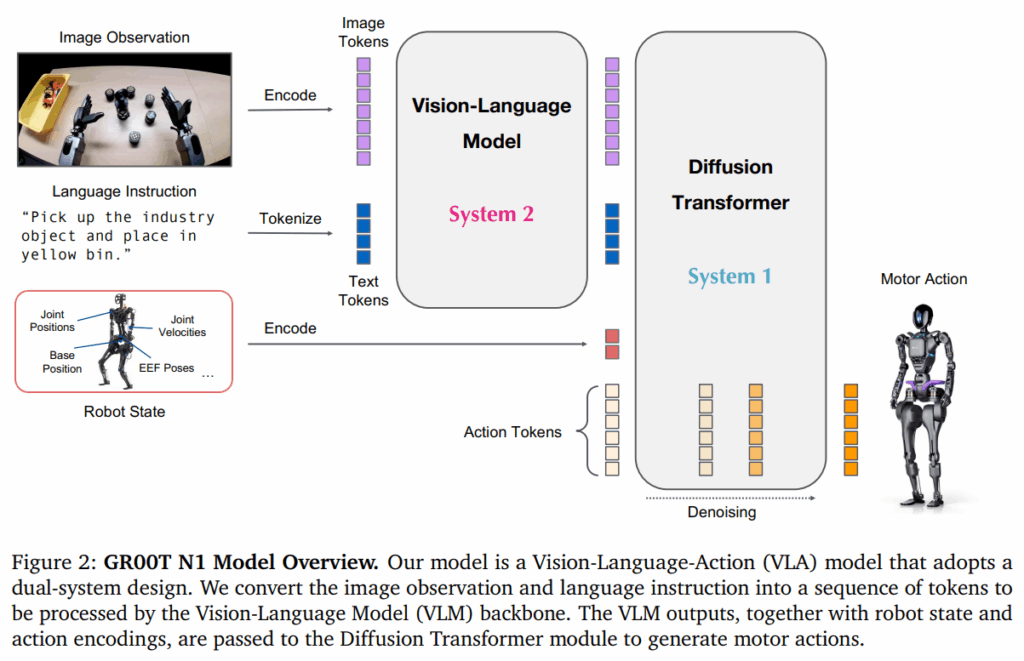
GR00T N1 모델은 Vision Language Action(VLA)모델입니다. 언어와 이미지를 입력받는 Eagle2-VLM을 통해 feature를 추출하고(System2), 이를 DiT 기반 flow-matching 정책을 출력하는 모델(System1)를 사용합니다.
총 2.2B개의 파라미터를 가지며 이 중에 1.34B은 VLM에 포함되어 동작됩니다. L40 GPU(NVIDIA Ada Lovelace 아키텍처, 48GB GDDR6 기반으로 동작)에서 bf16을 사용해 16개의 행동 청크를 샘플링하는데 63.9ms의 추론 시간을 가진다고 합니다.
GR00T N1의 핵심 특징은 아래와 같습니다
- VLM기반 추론 모듈(System 2)과 DiT 기반의 행동 모듈(System 1)을 통합하는 compositional 모델을 단일 학습 프레임 워크로 설계
- robustness를 위한 인간 비디오, 시뮬레이션 및 신경 생성 데이터, 실제 로봇 시연 데이터의 혼합을 사용하는 pretrain 전략
- 광범위한 로봇 embodiment를 지원하고 데이터 효율적인 post-training을 통해 새로운 작업에 대한 빠른 적응을 가능하게 하는 multi-task, language-conditioned policy를 학습
2.1 Model Architecture
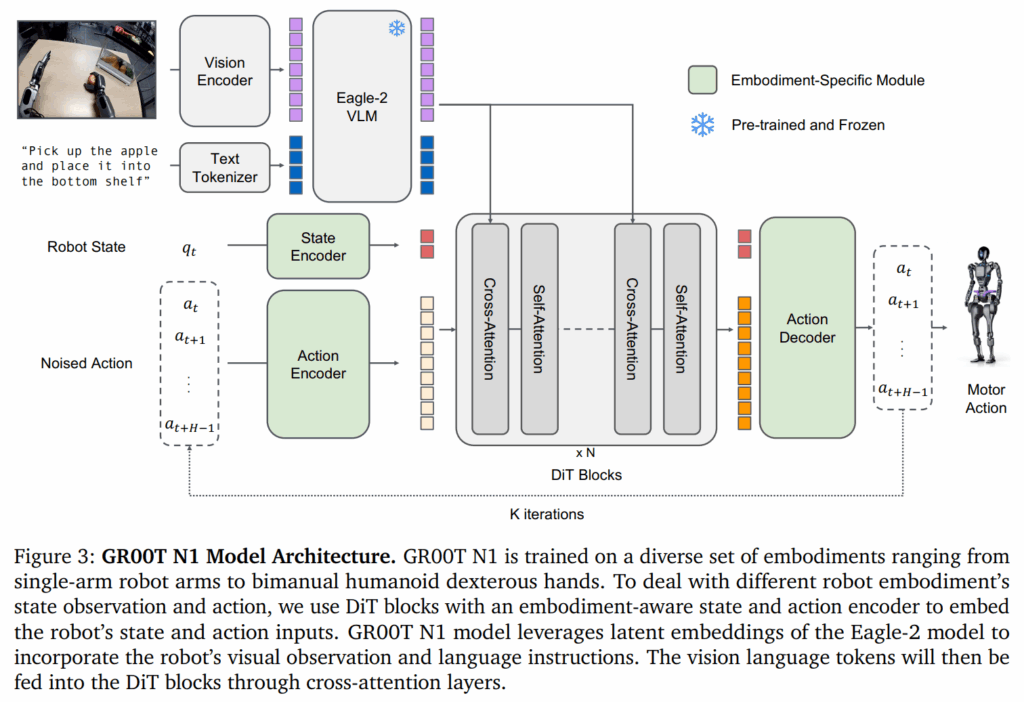
State and Action Encoders
다양한 로봇에 대하여 상태와 행동을 처리하기 위해서는 이에 대한 차원이 맞아야 하고, MLP를 사용해 공유 임베딩 차원으로 투영해 DiT의 입력으로 사용합니다. action encoder MLP는 노이즈가 포함된 action 벡터와 함께 Diffusion timestep도 인코딩한다고 합니다. 즉 “노이즈도 DiT에 넣게 좋게 바꾸어준다”라고 이해하시면 될 것 같습니다.
반복적인 디노이징을 통해 액션을 샘플링 하는 action flow matching 기반으로 동작을 하고 robot’s proprioceptive state, image tokens, text token의 인코딩 외에 노이즈가 추가된 액션을 입력으로 받습니다. 액션은 ACT와 같이 chunk단위로 처리되며 A_{t} = [a_{t}, a_{t+1}, \cdots , a_{t+H-1}]를 사용하며 t부터 t+H-1까지 시간의 액션 벡터를 사용된다고 합니다. 해당 논문의 구현에서는 H = 16로 설정했다고 합니다.
Vision-Language Module (System 2)
Vision과 Language 입력을 인코딩하기 위해 pretrain된 Eagle-2 VLM을 사용합니다. 이는 SmoLM2 LLM과 SigLIP-2 image encoder로부터 파인튜닝되었습니다. 이미지는 224 x 224 해상도로 인코딩된 후 pixel shuffle 통해 압축한, 프레임당 64개의 이미지 토큰 embedding로 생성된 후 Eagle-2 VLM의 LLM 구성 요소에 의해 텍스트와 함께 추가로 인코딩 되고 LLM을 통해 출력을 생성한다고 보시면 될 것 같습니다. (자세한 구조는 상단의 이미지를 참고해주시면 될 것 같습니다)
텍스트는 작업에 대한 설명이 채팅 형식(ex. ~~~를 ~~~해줘)으로 상황에 대한 이미지와 함께 들어간다고 합니다. 이를 LLM 통해서 batch size × sequence length × hidden dimension의 형태로 추출하고, SmolVLA와 유사하게 중간 레이어, 12번째의 LLM embedding을 사용한다고 합니다.
Diffusion Transformer Module (System 1)
action modeling을 위해서 adaptive layer normalization를 통한 denoising step conditioning을 갖춘 DiT의 변형 형태(V_{\theta})를 사용한다고 합니다. Cross Attention(CA)과 Self Attention(SA)이 번갈아 나타나는 구조로 구성이 되어 있고, SA는 노이즈가 추가된 action token embedding A^{\tau}_{t}와 상태 임베딩 q_{t}에 대해서 작동하며, CA 블럭은 VLM에서 출력된 vision-language token embedding \varphi_{t}를 conditioning으로 가져간다고 합니다. DiT에서 나온 H개의 token은 embodiment-specific Action Decoder(또다른 MLP)를 통해서 액션을 예측하는 방식으로 구성됩니다.
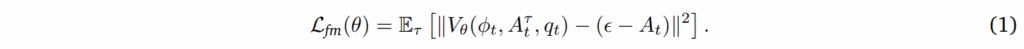
정답 액션 청크에 대해서 flow matching의 timestep \tau \in [0, 1]과 샘플링된 가우시안 노이즈가 주어졌을 때 노이즈가 추가된 액션청크를 계산하는 A^{\tau}_{t} = \tau A_{t} + (1-\tau)\epsilon이라는 식을 통해 모델 예측이 다음 손실을 최소화함으로서 미분한 velocity field \epsilon - A_t를 근사하는 것을 목표로 합니다.
pi zero와 마찬가지로 p(\tau) = \text{Beta}(\frac{s-\tau}{s;1.5,1}), s = 0.999를 사용하며 추론 중 K-step 디노이징을 사용해 action chunk를 생성합니다. 이를 사용해서 노이즈 초기 단계를 더 정밀하게 배우게 함으로서 행동을 안정적으로 찾아갈 수 하였다고 볼 수 있습니다. 결과적으로 액션 청크를 반복적으로 생성하면서 노이즈에서 디노이징 해가는 아래의 식을 따른다고 볼 수 있습니다.
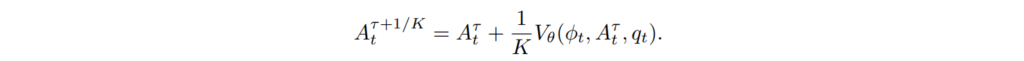
여기서는 K=4의 추론 단계만으로도 모든 embodiment에 걸쳐서 잘 작동되었다고 말하고 있습니다.
2.2 Training Data Generation
GR00T N1 학습을 위해 데이터 피라미드를 구성하고 이를 기반으로 증강의 과정을 진행했다고 합니다. 인간 시점의 비디오 데이터, 사전 학습된 비디오 생성 모델을 사용하여 생성한 Synthetic neural trajectories, 자체 수집한 teleoperation 궤적 – 데이터 피라미드의 정점을 88시간에서 827시간으로 약 10배 증가시켰다고 합니다. 또한 다양한 시뮬레이션 궤적을 생성해 데이터 피라미드의 중간 부분을 확장해나갔습니다.
Latent Actions
인간 시점의 비디오 및 신경 궤적에서는 로봇이 학습할 수 없기 때문에 VQ-VAE 모델을 학습시켜 latent action을 생성한다고 합니다.
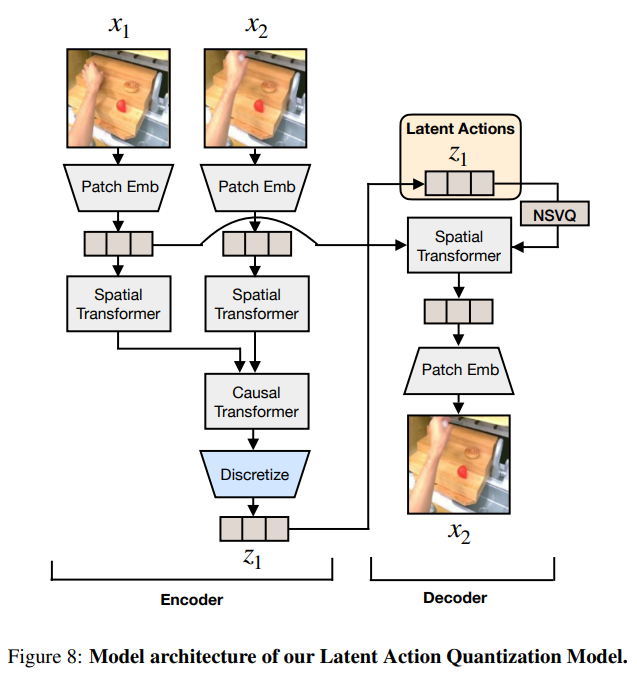
- encoder는 고정된 윈도우 크기 H를 가진 비디오의 현재 프레임 x_{t}와 미래 프레임 x_{t+H}를 입력받아 잠재 액션 z_{t}를 출력합니다.
- Decoder는 latent action z_{t}와 x_{t}를 받아 x_{t+H}를 재구성하도록 학습됩니다.
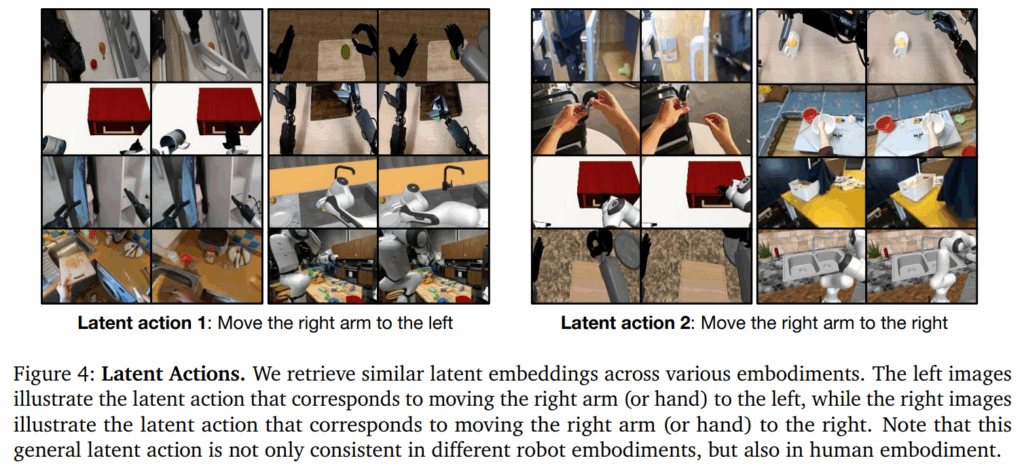
학습 후 encoder를 가져와 inverse dynamics model, IDM으로 사용합니다. 현재 프레임 x_{t}와 미래 프레임 x_{t+H}가 주어지면 연속적인 pre-quantized embedding을 추출하고 이를 pretrain 중 latent action 레이블로 사용하며 동일한 flow-matching 손실을 사용하지만 별도의 LAPA embodiment로 취급, 즉 latent action이 방대한 비디오 데이터에서 흐름 자체가 어떻게 되는지, latent action이 뭔지를 이해할 수 있는 정도의 모델이 될 수 있도록 구성을 하였다는 것으로 볼 수 있습니다. 이를 통해서 로봇의 embodiment 간 일반화를 향상시킬 수 있었고, 제어 신호가 없는 인간 동작 같은 영상에서도 행동의 의미를 추출해낼 수 있게 되었습니다. (아래 사진을 보시면 제어 신호가 없는 인간의 동작도 잠재 동작을 파악해 분류하는 것을 알 수 있습니다)
Neural Trajectories
로봇 데이터는 직접 만들기 때문에 최근 고품질의 제어 가능한 비디오 생성 모델이 상당한 잠재력을 보여주고 있다고 판단하고 해당 논문에서는 이러한 이미지-비디오 생성 모델이 로봇 분야에서 월드 모델 구축을 위한 길을 열어준다고 하고 있습니다. 이미지-비디오 생성 모델을 88시간의 원격 조종에 대해 파인튜닝하고 기존 초기 프레임과 새로운 언어 프롬프트를 사용해 827시간의 비디오 데이터를 생성함으로서 약 10배가량 증가시켜서 반사실적 시나리오를 포착하는 훈련 데이터를 생성할 수 있고, 원격 조종 데이터를 실제로 수집할 필요가 없다고 합니다.

또한 Neural Trajectory의 다양성을 높이기 위해 commercial-grade multimodal LLM을 사용해 초기 프레임이 주어졌을 때 “pick up {object} from {location A} to {location B}”의 물리적으로 가능한 조합을 지시하도록 합니다. 또한 생성된 비디오에는 commercial-grade multimodal LLM을 판정자로 사용한 필터링과 re-captioning을 포함한 후처리를 통해 영상을 더 로봇스럽게? 만들어냈습니다.
Simulation Trajectories
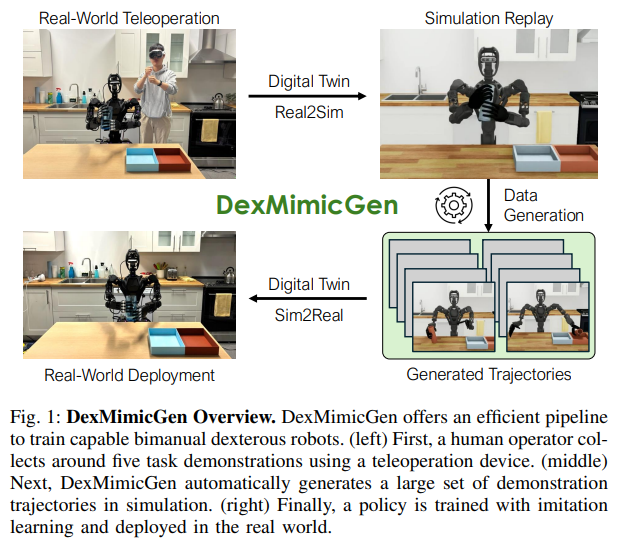
시뮬레이션에서 훈련 데이터 생성을 위해 DexMimicGen을 활용해 대규모로 로봇 조작 궤적을 합성해냅니다. DexMimicGen은 소량의 인간 시연을 기반으로 하여 시뮬레이션 상에 데이터 셋을 확장하는 방식으로 작업을 하위 작업 시퀀스로 분해해서 세세한 작업마다 상대적인 자세를 보존해 새로운 환경에 적응할 수 있도록 한다고 합니다. 최종적으로 작업 성공 여부를 simulation 상에서 평가하여 성공된 시연만을 저장해서 11시간만에 780,000개의 시뮬레이션 궤적, 9개월간 연속적으로 인간이 모아야 되는 수준의 데이터를 최소한의 인간 작업으로 증강할 수 있게 됩니다.
2.3 Training Details
학습 단계는 Pre-training, Post-training, Post-training with Neural Trajectories로 나누어 진행됩니다.
Pre-training 단계에서는 다양한 실제 및 합성 로봇 데이터 셋과 인간 모션 데이터를 포함하는 포괄적인 embodiment에 대해서 flow matching을 통해 학습됩니다. 인간 비디오와 같이 ground-truth action이 없는 경우, latent action을 flow matching의 타겟으로, 로봇 embodiment 데이터셋 같은 경우 정답 로봇 액션과 latent action을 모두 flow matching의 타겟으로 사용합니다. 생성형 모델로 만든 Neural trajectories 데이터는 latent action과 학습된 inverse-dynamics model로부터 예측된 액션을 사용하는 방식으로 진행됩니다.
Post-training에서는 사전 학습에서 포괄적인 embodiment에 대해서 학습을 진행했다면, 단일 embodiment에 대해서 사전 학습된 모델을 파인튜닝합니다. VL backbone은 사전 학습과 마찬가지로 freeze 하고 사용합니다.
Post-training with Neural Trajectories에서는 post training에서 부족한 데이터 문제 해결을 목표로 신경 궤적을 생성하여 각 다운스트림 작업에 대한 데이터를 보강합니다. 비디오 모델을 미세 조정해서 이미지를 생성하는 방법, 시뮬레이션에서는 랜덤한 환경에서 초기화된 동작으로 데이터를 생성하는 방법, 확산 모델을 통해 새로운 초기 프레임을 생성하는 방법 등이 있다고 합니다. 생성된 데이터, 즉 비디오에는 액션 레이블이 없기 때문에 IDM과 labeled actions를 통해 데이터를 쓸 수 있게 만들고, 사후 학습 중에는 실제 세계 궤적과 신경 궤적을 1:1 샘플링 비율로 정책과 함께 co-train합니다.
3. Pre-Training Datasets
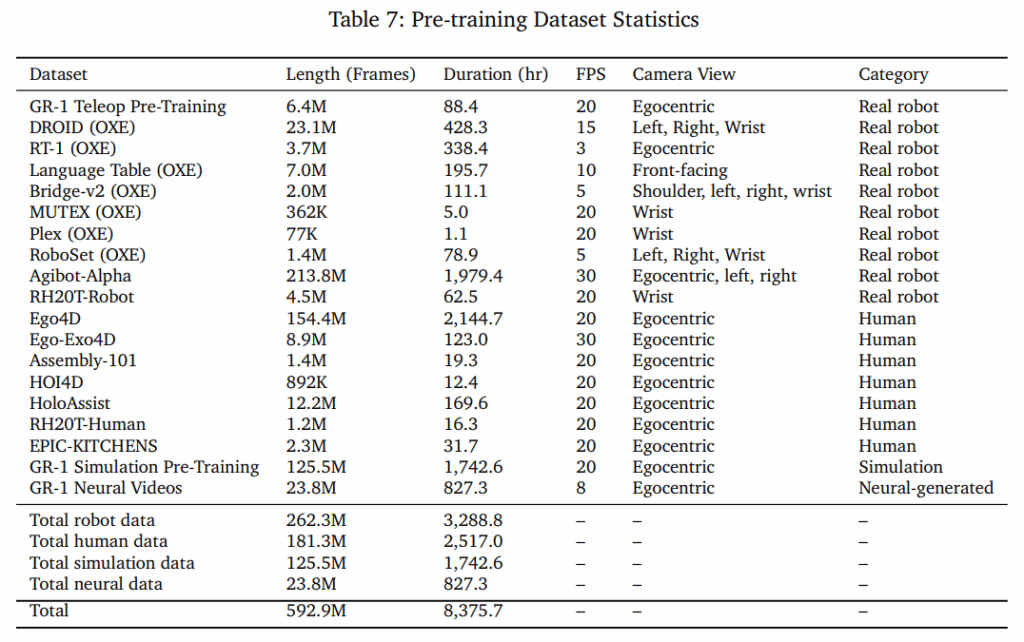
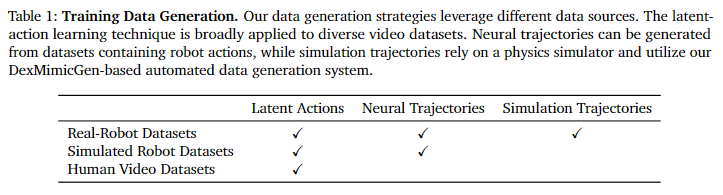
Table 7은 사용된 데이터의 크기에 대한 시트입니다. Table 1은 사전 학습 데이터, Human video에 대해서는 Latent Action만을 생성하도록 하고, Sim에 대해서는 Latent Action과 Neural Trajectories, Real Robot에 대해서는 모든 방식을 데이터 생성에 사용한다고 설명하는 표입니다.
3.1 Real-World Datasets
- GR00T N1 Humanoid Pre-Training Dataset.
- Open X-Embodiment.
- AgiBot-Alpha.
데이터 셋을 활용했다고 합니다.
3.2 Synthetic Datasets
합성 데이터 셋은 물리 시뮬레이터 내에서 소수의 인간 시연으로부터 자동으로 증식된 sim 궤적과 신경망 생성 모델에 의해 생성된 비디오에서 파생된 신경망 궤적으로 구성됩니다.
sim 궤적 같은 경우에는 무작위로 객체를 배치하고 장애물을 포함시켜 동작을 하도록 합니다. sim 내에서 사람이 조종하는 소수의 데이터를 가지고 DexMimicGen을 통해 데이터 생성을 진행한다고 합니다. 결과적으로 해당 논문의 실험에서는 540k개의 시연을 생성해냈다고 합니다.
Neural Trajectories 생성 단계에서는 GR00T N1 Humanoid Pre-Training 데이터셋에 오픈 소스 이미지-비디오 모델을 파인튜닝합니다. 언어 주석을 포함하여 주었기 때문에 새로운 언어 프롬프트가 주어졌을 때 고품질의 반 사실적인 궤적을 생성해내고, 인터넷 규모의 데이터로 학습되었기 때문에 강력한 일반화 능력을 보여준다고 합니다. 생성된 비디오(약 827시간 분량)는 latent action및 IDM 기반 의사 행동으로 labeling됩니다.
3.3 Human Video Datasets
1인칭 기반으로 명시적인 행동 레이블을 포함하진 않지만 인간과 객체 사이의 상호 작용에 대한 sequence를 포함하고 있기에 자연스러운 모션 패턴을 포착해내는데 도움에 되는 데이터입니다. 데이터 셋은 Ego4D, Ego-Exo4D, Assembly-101, EPIC-KITCHENS, HOI4D, HoloAssist, RH20T-Human을 사용했습니다.
4. Evaluation
시뮬레이션 실험에서의 평가, Real-World에서의 평가로 진행됩니다. 테이블탑 조작에 대한 모델의 능력을 평가하며, 여러 데이터 셋을 기반으로 학습되었기 때문에 소수의 인간 시연만으로 새로운 기술을 습득하는 것을 목표로 하고 있습니다.
4.1 Simulation Benchmarks
- RoboCasa Kitchen (24 tasks, RoboCasa): sim 환경에서 주방 작업에 대한 평가
- DexMimicGen Cross-Embodiment Suite (9 tasks, DexMG): 여러 Robot embodiment에 대해 생성된 sim 데이터를 기반으로 작업 진행 평가
- GR-1 Tabletop Tasks (24 tasks, GR-1): GR-1휴머노이드 기반으로 다양한 작업을 진행하도록 진행. sim 환경이기 때문에 데모를 DexMimicGen 기반으로 1000개를 생성해 이에 대한 평가를 진행
4.2 Real-World Benchmarks

사진의 예시 작업을 기반으로 평가가 진행됩니다. 정밀한 객체 조작, 공간 추론, 양손 동작, 협업 능력에 대한 평가를 하기 위한 task로 구성되어서 동작된다고 합니다. 품질이 좋지 않은 데이터는 필터링하였으며 단일 로봇의 동작과 여러 로봇의 협업까지 능가하는 task 요구사항을 통합해 평가를 진행하였다고 합니다.
4.3 Experiment Setup
GR00T의 사전 학습을 입증하기 위해서 BC-Transformer와 Diffusion Policy에 대해서 비교합니다. sim 평가에서는 100회 시도에 대한 평균 성공률을 정리하고, 마지막 5개의 체크포인트(500 학습 스텝 간격으로 저장된)의 최대 점수를 사용합니다. Real world 평가는 각 task에 대해 10회 시도의 평균 성공률을 사용하고, 부분 점수를 매겨 성공률을 보고한다고 합니다. (Pack Machinery는 제한시간내에 몇 개의 객체를 배치하였는지, 시간 제약으로 5회의 시도만을 수행) 모델 효율성 평가를 위해 10%%를 하위 샘플링하고 여전히 효과적인 행동을 학습할 수 있는지에 대해서도 평가한다고 합니다.
4.4 Quantitative Results
사전 학습에 대해서 일반화 능력을 평가했을 때 왼손으로 물체를 잡고 오른손으로 선반에 놓는 동작에 대해서 76.6%의 성공률을 보이고 새로운 물체 조작을 포함하는 두번째 평가에서는 73.3%의 성공률을 표현합니다. 이를 통해서 대규모로 사전 학습을 하는 것이 일반화가 잘된다고 나타내는 것 같습니다.
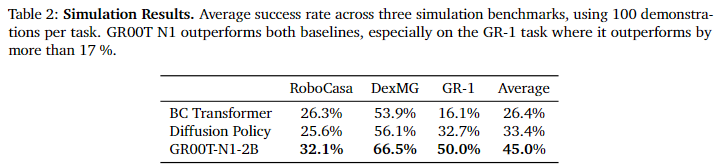
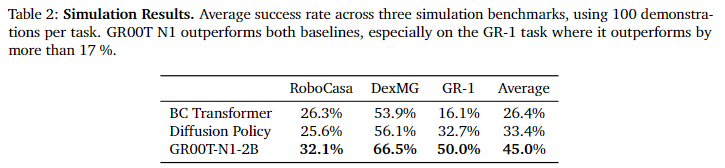
post-training에 대해서는 베이스 라인 모델보다 일관되게 우수한 성능을 보인다는 것을 보이고 있습니다. 특히 10%의 데이터만으로 학습된 GR00T N1 2B는 전체 데이터로 학습된 Diffusion Policy보다 3.8% 낮은 성능보이며 데이터 효율 측면에서도 유리하다는 것을 보입니다.
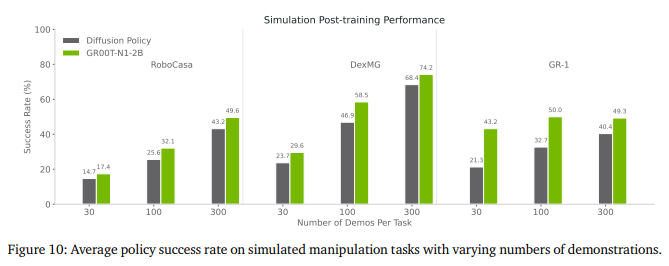
Post-training w/ Neural Trajectories Evaluations에서는 일관되게 성능향상을 보였습니다. RoboCasa에서 30, 100, 300 데이터 체제에서 4.2%, 8.8%, 6.8% 성능 향상을 보이며 GR-1 Humanoid의 경우 8개 작업 전반에 걸쳐서 5.8% 평균 향상을 보였습니다. 이를 통해서 Neural Trajectories가 로봇의 성능 향상에 도움을 준다는 것을 보입니다.
4.5 Qualitative Results
RoboCasa의 “Turn Sink Spout” 작업에서 100개 샘플 체제에서 DP는 11.8%의 성공률을 보이지만 GR00T는 42.2%의 성공률을 보입니다. 아마도 데이터가 적더라도 의미론적으로 잘 이해를 해낸 것으로 보입니다.
또한 “Pick up the red apple and place it in the basket,”에서 양손 협업을 스스로 생각해서 수행해냈다고 합니다. 명시적으로 배우지 않은 환경에 대해서 Foundation Model이 잘 처리를 해냈다고 저자들은 보고 있습니다.

그 외에도 데이터 구성을 잘못하였을 때(오른손만 사용하는 작업들을 후반 데이터에 배치) 양손 전이 능력을 잃어버릴 수도 있는 것에 대해서 설명하고 DP와 다르게 동작이 유연하게 움직인다는 것을 강조하고 있습니다.
5. Conclusions
결과적으로 범용 휴머노이드 로봇을 위한 open foundation mdoel을 제시하였고, 이중 시스템 모델 설계, 다양한 로봇 embodiment 지원 등을 이점으로 삼으면서 높은 데이터 효율성과 강력한 일반화 능력을 동시에 가져갔다고 말하고 있습니다.
결과적으로 보자면 시스템 1, 2로 분리해서 제시, 생성형 모델 적극 활용, 데이터 처리 등의 방법들로 로봇에 대해서 일반적으로 인간이 이해할 수 있는 행동, 혹은 잠재된 action 들을 학습을 위해서 배우고자 한 것 같습니다. 기존에도 VLM과 Action을 같이 사용하는 방식은 있었지만 데이터를 더 잘 생성하는 방법에 대해서 고민한 논문 같습니다. 다만 부록에서 볼 수 있는 사진을 보면 영상 생성에 대한 정확도가 그렇게 높지 않은 것 같습니다. 아래 사진을 보시게 된다면 오히려 객체가 일그러지는 변형? 등이 일어나는 모습이 간간히 보이게 됩니다.

기존의 데이터가 적어서 생성을 하는데 생성된 데이터가 오히려 더 노이즈를 가지고 있다면 IDM 자체도 제대로 동작을 뽑아낼 수 있을지, 시각 정보에 대해서 객체가 변형을 일으키는 것에 대해서 혼란을 주지 않을지에 대해서는 보완해야 할 점이 있다고 생각합니다.
긴 내용의 리뷰 읽어주셔서 감사합니다.

안녕하세요 기현님 좋은 리뷰 감사합니다.
State and Action Encoders 파트 부분에서 궁금한 부분이 있습니다. 제액션은 ACT와 같이 chunk단위로 처리된다고 하셨는데 실제로는 매 step마다 다시 chunk를 재샘플링하는 구조로 동작하는 것인지 아니면 chunk를 끝까지 실행하게 되는 건지가 궁금합니다! 감사합니다.
안녕하세요 우현님, 댓글 감사합니다.
제가 기존에 ACT 리뷰를 작성해서 그런지 해당 부분에 대해서 자세히 적지를 못했습니다.
우선 ACT는 액션 chunk를 계속 생산하는 방식으로 활용합니다. 따라서 매 타임스텝마다 observation을 계속 받고, 연산을 한 후에 청크들을 출력하여 동일한 타임스텝에 대한 청크 조각들을 모아서 가중 평균 내는 방식으로 동작을 결정합니다. 이렇게 사용하면서 청크의 이점도 잘 살리고, 유연한 동작도 만들어 내는 것이 ACT의 액션 청킹의 특징입니다.
질문 감사합니다.
안녕하세요 기현님 리뷰 감사합니다.
저도 흐릿해지는 시점에서 정리가 잘 돼있어서 다시 생각하며 읽게된 것 같습니다. 읽으면서 기현님하고 얘기도 나눴었던 질문들이 다시 떠올라 몇개만 남겨보겠습니다.
Q1. System 1과 System 2가 학습에서 공동으로 최적화된다고 표현해주셨는데요, figure를 보면 기현님이 이야기하셨듯 VLM은 freeze 상태입니다. System 1,2의 공동 최적화와 실제로 VLM을 학습하는 것과는 어떻게 다른건가요?
Q2. IDM이 생성 비디오의 오류까지 그대로 올바른 action으로 학습하는 위험은 없을까요? 학습때 neural trajectory를 real과 1:1로 학습한다고 하는데, web data나 human video 데이터를 그대로 다같이 학습하면서 생기는 embodiment gap 문제는 없을까 싶습니다. 혹시 이에 대한 실험 결과가 논문에 있었나요?
안녕하세요 영규님, 답글 감사합니다.
질문에 순서대로 답해드리겠습니다.
1. 우선 공동 최적화라는 말이 freeze와 혼동되어서 저도 이해가 잘 안되었습니다. 단순히 설명드리자면 공동 최적화라는게 파라미터를 다 바꾸는 것이 아니라 System 1, 2를 지난 출력을 한번에 loss 함수에 계산을 한다는 것입니다. 즉 System이 나누어져있다고 각각에 대해서 따로 loss를 계산하는 것이아니라 한번에 지나온 값에 대해서 loss를 계산하기 때문에 공동 최적화라는 말을 쓴 것 같습니다. 제가 번역을 이상하게 하였을 수도 있을 것 같아서 원문의 해당 부분을 보시면 좋을 것 같습니다.
2. 저도 이부분에 대해서 궁금한 점이 많았는데 이번주에 리뷰하게된 DREAMGEN에서 이에 대해 해당 논문보다 자세히 설명한 것 같습니다. 간단히 정리해서 설명드리자면 co-training을 통해 이 부분을 완충하고자 한 것 같고 직접적인 Torque가 아니라 Latent action을 생성하도록 하여서 이런 gap을 줄인 것 같습니다. 그래서 안전한 선에서 real과의 비율을 1:1 정도로 한 것 같습니다. 이에 대해서 자세한 논문의 실험 결과는 논문에 없는걸로 기억합니다.
좋은 질문 감사합니다!
안녕하세요 기현님 자세한 좋은 리뷰 감사합니다
Simulation Trajectories 부분에서 질문이 있습니다
DexMimicGen를 통해 teleoperation 데이터를 세세하게 분해해서 데이터를 증강한다고 이해했는데, 정확한 방식이 궁금하여 질문드립니다.
그리고 예를들어 1분의 데이터가 있다면, 몇분의 데이터까지 늘릴 수 있고 그 데이터가 얼마나 성능향상에 도움이 되는지 궁금합니다(image augmentation처럼 성능향상의 한계가 있는지)
안녕하세요 정우님 답글 감사합니다
우선 DexMimicGen에 대해서 제가 자세히 읽어본 적은 없어서 간단히 설명드리도록 하겠습니다. 우선 데이터를 분해한다는 것은 데이터를 접촉 이벤트를 기준으로 나눕니다. 컵을 잡아서 반대 손에 주는 동작이라면 컵을 잡고, 건내주고, 이를 다시 내려놓는 식으로 세분화해서 작업간의 상대적인 점을 저장한다는 느낌으로 이해하시면 될 것 같습니다.
그리고 데이터 증강은 에피소드 단위로 이루어집니다. 한 에피소드를 사람이 만들면 이를 증강하는 식으로 진행됩니다. 그래서 컴퓨팅 리소스만 충분하다면 얼마든지 만들어낼 수 있는데, 초기에 휴먼 데이터가 얼마나 드는지는 찾아봐야 할 것 같습니다. 아마 사람 데이터의 갯수에 따라서 더 다양한 데이터를 만들어낼 수 있는가에 대해서 DexMimicGen에 차트로 나와있으니 그 부분을 확인하시면 될 것 같습니다.
좋은 질문 감사합니다!