안녕하세요 이번에 리뷰할 논문은 2022년에 CVPR에 개제된 Contrasitive Test Time Adaptation 이라는 논문입니다.
Test Time Adaptation 이라는 Test time에 실제 그 도메인에 맞게끔 모델 자체가 스스로 가중치를 업데이트 하면서 그 상황에 적응하는 방법론이라고 합니다. 이번에 논문 서베이 과정 중에 잠깐 해당 개념에 대해서 처음 접하게 되었는데 흥미로워서 이번 기회에 TTA의 컨셉에 대해서 한번 알아보고자 그 중 하나를 찾아서 읽어보고 리뷰로 들고오게 되었습니다. 이만 리뷰 시작하도록 하겠습니다.
Introduction
먼저 저자는 딥러닝 모델이 학습 데이터(소스 도메인)와 테스트 데이터(타겟 도메인)가 같은 분포일 때는 잘 동작하지만 실제 배포되는 환경에서 도메인 시프트가 발생하면 성능이 크게 저하된다는 문제를 언급합니다. 전통적인 도메인 적응은 라벨이 있는 소스 데이터로 학습한 지식을 타겟 도메인으로 전이하는 설정인데 이 논문이 다루고자 하는 것은 좀 더 까다로운 Test-Time Adaptation(TTA) 나 Source-Free DA라고 불리는 방법론입니다. 구체적으로 설명드리면 추론 단계 어떻게 보면 적응 단계에서는 소스 데이터는 사용할 수 없고,라벨 없는 테스트 데이터만으로 모델을 배포 현장 환경에 맞게 적응시켜야 하는 상황인 것 입니다. 해당 방법론에 대해서 저자들은 소스 모델만 들고 나가서 테스트 시점에 바로 적응한다는 점에서 데이터 프라이버시나 전송 대역폭 같은 제약이 있는 현실 배포에서 매력적인 방식이라고 언급합니다.
근데 이 설정에 대해서 저자들은 어떻게 정답 라벨 없이 타겟 도메인의 표현을 어떻게 학습할 것인지 또 소스 도메인을 직접 볼 수 없어서 소스에서 학습된 모델만 남아있는 상황에서 이걸로 어떻게 티겟 도메인 모델을 구축할 것인지에 대한 질문을 던집니다. 논문은 기존 TTA 방법들이 대체로 타겟 스타일의 이미지나 피쳐 생성, 엔트로피 최소화, 수도 라벨 기반 학습 등과 같은 방향을 활용해 왔다고 정리합니다. 먼저 생성 기반 접근은 계산 자원이 크게 필요하고 엔트로피 최소화는 성능은 좋아질 수 있어도 모델 캘리브레이션(실제 모델의 예측 확률과 정답확률 차이)을 저해할 수 있다고 합니다.
이런 배경에서 논문이 제안하는 방법이 Contrasitive learning을 기반으로 하는 AdaContrast입니다. 간단하게 설명드리면 타겟 도메인에서 자기지도 대조학습을 수행하면서, 동시에 의사 라벨링 기반 자기학습도 공동으로 최적화하여 서로 보완하게 만드는 전략이라고합니다. 표현 학습과 의사 라벨링을 따로 돌리는 것이 아니라 테스트 시점에 같은 스텝에서 같이 학습시켜 서로를 보완시키겠다는 설계로 보시면 될 것 같습니다. 자세한 내용은 방법론에서 다루도록 하겠습니다.
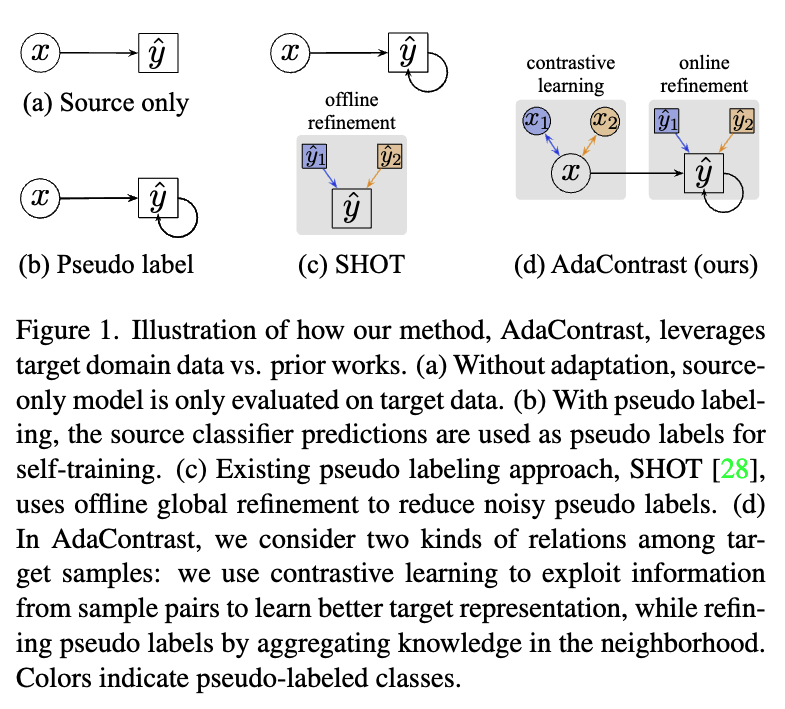
의사 라벨링 쪽에서도 저자의 AdaContrast의 차별점을 강조합니다. 기존 SHOT 같은 방법은 의사 라벨 노이즈를 줄이기 위해 전역 메모리 뱅크를 구축하고, 몇 epoch 단위로 오프라인 refinement를 수행하는 흐름이었다고 합니다. 반면 AdaContrast는 타겟 feature space에서 각 샘플에 대해 soft kNN voting으로 이웃들의 확률을 집계하고 배치 단위로 즉시 pseudo-label을 생성, refinement 한다고 합니다. 여기서 기존 방법과의 차별점은 epoch가 끝난 뒤 전체를 모아서 refinement 하는 것이 아니라 현재 들어온 배치를 처리하는 순간에 바로 refinement한다는 점입니다. 또한 전역 메모리 뱅크 대신 상대적으로 작은 메모리 큐에 의존기 때문에 계산 부담이 낮고, 로봇처럼 타겟 데이터를 다시 방문하기 어려운 온라인 스트리밍 환경에도 적합하다고 주장합니다.
Method
메서드 부분에 대해서 자세하게 설명드리도록 하겠습니다. 먼저 해당 논문은 이미지 분류에서의 클로즈드-셋(closed-set) 테스트 시점 적응(TTA) 문제를 다룬다고 보시면 좋을 것 같습니다. 적응 단계에서 소스 데이터는 사용할 수 없고 라벨이 없는 타겟 데이터만으로 소스에서 학습된 모델을 타겟 도메인에 맞게 조정해야 하는 상황에서 또 closed-set이므로 소스, 타겟이 동일한 라벨 공간을 가지여한다고 보시면 좋을 것 같습니다. 즉 학습때 봤던 라벨에 한해서 도메인 adpatation이 가능하다라고 보시면 좋을 것 같습니다.
모델 구조는 feature extractor f(\cdot)와 classifier head h(\cdot) 로 구성됩니다. 소스 학습은 크로스 엔트로피 손실을 사용해서 먼저 학습을하고 그리고 테스트 시점 적응을 시작할 때 타겟 모델 g_t = h_t \circ f_t 는 소스 모델 파라미터로 초기화됩니다.
이제 실제로 TTA의 핵심안 테스트 타임에서 모델이 어떻게 학습이 되는지를 설명드리도록 하겠습니다.
Online Pseudo Label Refinement
Adaptation 과정에서 가장 먼저 필요한 것은 라벨이 없는 타겟 데이터에 대해 pseudo-label을 만드는 일입니다. 해당 논문은 소스 가중치로 초기화된 타겟 모델의 예측을 기반으로 의사 라벨을 만들되 서두에 언급했던 것처럼 기존 연구들처럼 epoch 단위로 한 번씩 크게 정제하는 방식을 피합니다. 대신 배치 단위 로 수도 라벨을 예측하고 배치가 끝날 떄 마다 정제해서 학습에 반영하는 흐름으로 동작하는 방식을 제안합니다. 결국 모델이 적응하면서 조금씩 좋아지는 것을 바로 바로 가장 최신의 수도 라벨에 반영시킴으로써 좀더 모델의 업데이트된 정보를 즉각즉각 바로 활용하자는 전략인 것 같습니다.
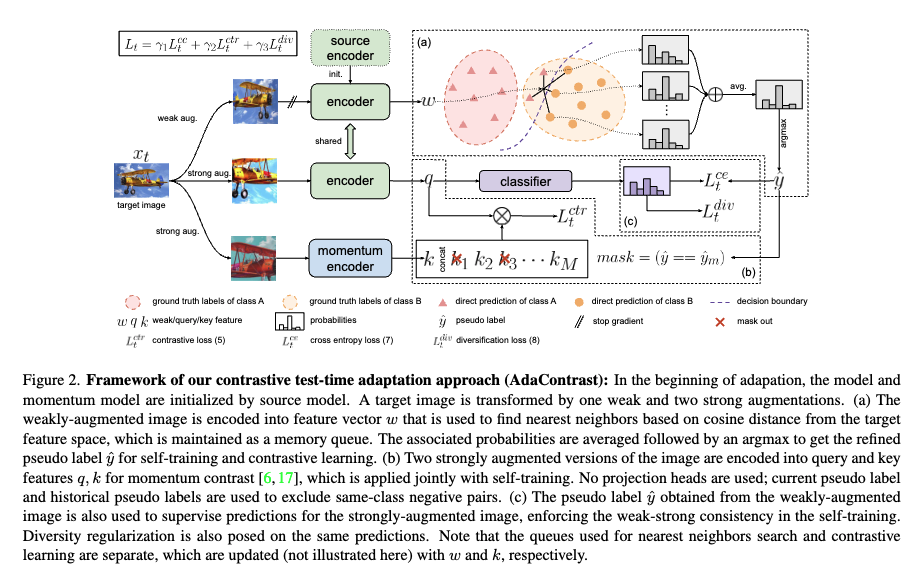
Figure 2에서 타겟 이미지 하나는 약한 증강 1개(weak aug) 와 강한 증강 2개(strong aug)가 적용됩니다.
먼저 각각에 대해서 간단하게 언급드리고 넘어가면, 약하게 증강된 이미지는 인코더를 통해서 특징 벡터 w를 뽑습니다. 그리고나서 이 w를 가지고 타겟 feature space에서 코사인 거리 기준으로 최근접 이웃 탐색이 수행되고, 그 feature space는 논문에서 메모리 큐형태로 유지됩니다. 그 다음에 현재 샘플의 예측만 보는 것이 아니라, 최근접 이웃들이 가지고 있는 예측 확률들을 평균내서 더 안정적인 확률 \hat{p}를 만들고 마지막에 \arg\max로 라벨을 확정해서 정제된 의사 라벨 \hat{y} 을 얻게됩니다.
다음으로 같은 타겟 이미지에 대해서 강한 증강을 두번 적용합니다. 이 두 버전은 각각 대조학습에서 사용할 query 특징 q와 key 특징 k로 인코딩 됩니다. 먼저 Key로 들어가는 부분에 대해서 설명드리면 여기서 논문이 쓰는 방식은 MoCo 계열과 비슷한 모멘텀 대조 학습 구조라고 합니다. 또 여기에 same-class negative를 masking 하는 장치도 있습니다. 같은 클래스라고 판단되는 샘플끼리는 negative로 밀어내지 않도록 처리함으로써 수도 라벨이 완벽하진 않더라도 이 과정을 통해 대조학습이 클래스 구조를 망가뜨리는 방향으로 가는 것을 줄이려는 의도라고 이해하시면 될 것 같습니다.
마지막으로 첫번째 얻은 정제된 수도 라벨 \hat{y}를 앞 문단에서 말한 강한 증강 샘플들의 예측의 감독 신호로 사용되게 됩니다. 약한 증강에서 상대적으로 신뢰할 만하게 만든 라벨을 기준으로, 강한 증강에서도 같은 결론이 나오도록 강제하는 weak-strong consistency 형태의 학습을 수행한다라고 보시면 됩니다.
이제 위에 내용에 대해서 메모리 큐의 역할 최근접 이웃 탐색 등등 좀더 자세하게 설명을 드리도록 하겠습니다.
Memory Queue
먼저 이 메모리 큐에는 약한 증강을 적용한 타겟 샘플들의 feature w' probability p'가\{w'_j, p'_j\}_{j=1}^{M} 형태로 저장이 되고 매 배치 스텝마다 enqueue/dequeue 방식으로 업데이트가 됩니다. 그리고 중요한 점은 여기 메모리 큐에 들어가는 feature와 probabilities를 그냥 업데이트 되고 있는 현재 모델로 뽑지 않고 모멘텀 모델 g'_t 로 계산한다는 점입니다. 모멘텀 모델은 타겟 모델의 파라미터를 EMA처럼 천천히 따라가면서 업데이트되기 때문에 큐에 저장되는 feature space가 갑자기 흔들리는 것을 줄여주는 역할을 합니다.
모멘텀 모델 g'_t의 파라미터 \theta'_tt는 적응 시작 시점에 소스 가중치 \theta_s로 동일하게 초기화되고 backprop으로 업데이트하는 대신에 배치 스텝마다 모멘텀 m을 사용해서 아래와 같이 업데이트 하게 됩니다.
그리고 수도 라벨을 만들 때에는 업데이트가 진행중인 인코더가 사용된다고 보시면 됩니다.
Nearest-Neighbor Soft Voting
수도 라벨 정제는 최근접 이웃 소프트 보팅(soft kNN voting)으로 수행됩니다. 도메인 시프트 때문에 현재 분류기가 어떤 타겟 샘플을 틀리게 예측할 수 있는 상황에서 그 샘플 주변(가까운 feature를 가진 샘플들)의 예측 확률을 함께 집계하면 단일 예측보다 좀더 안정적인 추정을 할 수 있다는 점에서 해당 방식을
사용한 것 같습니다. 구체적으로는, 약한 증강으로 얻은 특징 w 에 대해 큐에 저장된 전체 특징들과의 코사인 거리를 계산해 N개의 최근접 이웃을 찾습니다. 그리고 그 이웃들의 확률 p' 를 평균내서 정제된 확률 \hat{p} 를 만들고, 마지막에 \arg\max 로 최종 수도 라벨 \hat{y} 를 확정합니다. 여기서 생성된 수도 라벨이 결국 뒤에서 수행되는 self-training과 contrastive learning의 감독 신호로 들어가게 됩니다. 그래서 수도 라벨이 덜 noisy해질수록 뒤 단의 학습도 안정화될 가능성이 높아집니다.
Joint self-supervised contrastive learning
기존 대조학습(MoCo 계열 포함)은 보통 사전학습 단계에서 representation을 만든 다음downstream으로 넘기는 방식이 대부분인데 여기서는 기존 방식과 다르게 그걸 TTA 단계에서 대조 목적함수를 자기학습과 공동으로 최적화하는 식으로 동작합니다. 학습 끝난 모델로 추론만 하는 것이 아니라 테스트 중에 representation을 더 좋게 만들면서 동시에 pseudo-label 기반 자기학습도 같이 돌린다라는 흐름이라고 보시면 좋을 것 같습니다. 여기서 대조 학습은 같은 이미지에서 나온 서로 다른 뷰는positive pair로 당기고 다른 이미지에서 나온 뷰 negative pair로 밀어내는 식으로 학습이 이뤄집니다. 그리고 여기서 서로 다른 뷰는 강한 증강으로 만들어집니다. 타겟 이미지 x_t에 대해 같은 분포 T_sT에서 강한 증강 t_s, t'_s 를 랜덤 샘플링해서 t_s(x_t), t'_s(x_t) 두 버전을 만들고, 그걸 각각 쿼리,키로 인코딩합니다. (여기서 T_s는 강한 증강 함수 집합 + 그걸 뽑는 랜덤 규칙을 통째로 묶어 표현한 것이라고 보시면 될 것 같습니다.)
Encoder initialization by source
타겟 인코더 f_t를 소스 모델 가중치로 초기화해서 재사용하고 MoCo 스타일의 모멘텀 인코더 f'_t도 같이 쓰는데 이것도 소스 가중치로 초기화합니다. 그리고 이 모멘텀 인코더 f'_t는 앞서 메모리 큐 Q_w 를 업데이트하던 그 인코더와 동일한 인코더 입니다. 해당 방법론은 모멘텀 인코더를 한쪽에서는 pseudo-label을 만들기 위한 이웃들의 memory feature 업데이트에 쓰고 다른 쪽에서는 대조학습 key feature 생성에도 그대로 재사용하는 구조로 가져갑니다.
Exclusion of same-class negative pairs
그리고 기본 MoCo에서는 InfoNCE가 q–k^+는 가깝게 q–Q_s 안의 모든 과거 키 k_j는 멀게 만들도록 학습합니다. 그런데 저자는 여기서 같은 클래스로 추정되는 샘플까지 네거티브로 밀어버리면 의미론적으로 분류학습에 있어서 방해된다고 주장합니다. 따라서 메모리 큐 Q_s에 과거 키 특징 k_j뿐 아니라그에 대응되는 의사 라벨\hat{y}_j
도 같이 저장하고 현재 샘플의 의사 라벨 \hat{y}와 동일한 \hat{y}_j는 네거티브 쌍에서 제외하는 방식으로 학습이 이루어집니다.
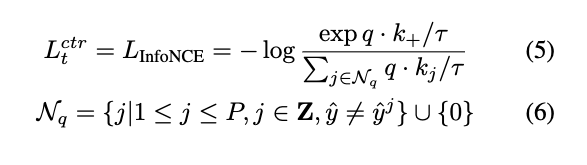
위는 대조학습 손실 L^t_{ctr} (수정된 InfoNCE)이고 \mathcal{N}_q는 쿼리 q에 대한 네거티브 인덱스 집합을 의미합니다.
Joint optimization with self-training
테스트 시점 적응 단계에서 타겟 도메인에서 자기지도 대조학습을 수행하면서, 동시에 의사 라벨링 기반 자기학습도 공동으로 최적화하여 서로 보완하게 만드는 전략에 대한 부분입니다.
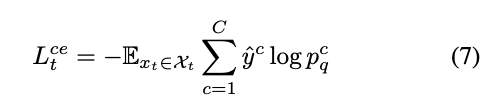
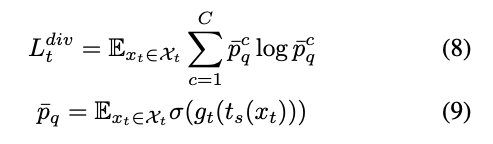
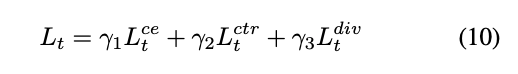
일단 (10)식처럼 멀티태스크 형태로 결합해서 TTA 동안 공동으로 최적화합니다. 논문 표현대로라면 해당 구조에서 대조학습은 더 좋은 representation을 만들어서 self-training이 더 안정적으로 돌아가게 돕고, 이 self-traing은 더 나은 pseudo-label prior를 제공해서 대조학습이 더 정확한 방향으로 정렬되도록 허는 상호보완 관계를 가지게 된다고 합니다.
Additional regularization
Weak-strong consistency
앞서 (7),(8),(9)의 수식설명이 빠져있는데 해당 수식에 대해서 자세하게 설명드리도록 하겠습니다.
여기서는 FixMatch 아이디어를 가져와서 약하게 증강된 타겟 이미지에서 얻은 의사 라벨 \hat{y}로 강하게 증강된 버전에 대한 모델 예측의 감독 신호로 쓰게끔 합니다. 다만 원래 FixMatch랑 똑같이 쓰는 건 아니고 몇 가지 차이를 둡니다. 정답 라벨은 전혀 없고, 수도 라벨은 사용 전에 정제하고confidence thresholding은 쓰지 않고, 모델은 소스 가중치로 초기화된 상태에서 시작한다는 점입니다.
이 정규화는 아래 처럼 표준 cross-entropy로 정의됩니다.
여기서 p^{q}=\sigma(g_t(t_s(x_t)))는 강한 증강이 적용된 쿼리 이미지 t_s(x_t)에 대한 예측 확률(softmax 출력)입니다.
Diversity regularization
초반에 설명드린 온라인 수도 라벨 정제는 노이즈를 줄여주긴 하지만 의사 라벨은 결국 GT만큼 이상적이지는 않습니다. 그래서 적응 과정에서 모델이 잘못된 라벨에 대해서 무조건적으로 신뢰하지 않도록 클래스 다양화 를 유도하는 정규화 항을 추가합니다.
L^{t}_{div} = \mathbb{E}_{x^t\in X_t}\sum_{c=1}^{C} \bar{p}^{q}_c \log \bar{p}^{q}_c여기서 \bar{p}^{q}는 타겟 데이터에 대한 예측 확률의 평균으로 \bar{p}^{q} = \mathbb{E}_{x^t\in X_t}\,\sigma(g_t(t_s(x^t)) 로 정의됩니다.
결국 TTA 동안 최종 손실은 (10)식처럼 세 항을 합친 형태이고 논문에서는 별도 튜닝 없이 \gamma_1=\gamma_2=\gamma_3=1.0으로 두고도 잘 동작했다고 주장합니다.
Experiments
평가는 주요 벤치마크에서 closed-set 도메인 적응 실험을 수행하고 제안한 AdaContrast를 기존 SOTA 방법들과 비교합니다. 평가에는 VisDA-C, DomainNet-126 두가지를 사용하여 평가하였다고 합니다. DomainNet은 원본 라벨 노이즈 문제가 있기 땨뮨에 저자들의 후속 작업을 따라 4개 도메인(Real/Sketch/Clipart/Painting)에서 126개 클래스로 구성된 subset을 사용합니다. 그리고 4개 도메인으로부터 구성되는 7개 domain shift를 만들고 각 shift의 top-1 accuracy와 7개 평균에 대해서 비교합니다. VisDA-C같은 경우는 여기에 클래스별 top-1 accuracy까지 비교합니다.
모델 구조
모델은 feature encoder + classifier로 일반적인 분류 구조를 가정합니다. 실험에서는 백본으로 ResNet-18/50/101을 상황에 맞게 사용하는 한다고 합니다.
또 SHOT 설정을 따라 백본 뒤에 256-d bottleneck(FC + BatchNorm)을 붙이고, classifier에는 WeightNorm을 적용했다고 합니다. 저자들은 bottleneck으로 차원을 낮추는 구조라서 MoCo 계열에서 흔히 쓰는 projection head는 제거해도 성능 저하가 없다고 보고하면서 실제 실험에서도 projection head 없이 진행하였다고 합니다.
그리고 소스 학습은 ImageNet-1K 사전학습 가중치로 ResNet을 초기화하고 소스 학습 epoch은 VisDA-C 10, DomainNet-126 60으로 설정하고, 타겟 적응은(특별한 언급이 없으면) 15 epoch만 사용했다고 합니다.
베이스 라인
비교군은 크게 두 가지 인데, 첫번째는 UDA(unsupervised domain adaptation)계열 (DANN, CDAN, CDAN+BSP, CAN, SWD, MCC) 등과 비교합니다. 다만 UDA는 적응 단계에서 소스 데이터 접근이 가능하다는 전제가 있다는 점을 명확히 깔고 비교를 진행합니다. 그리고 두번째는 TTA(source-free/test-time adaptation)계열(MA, BAIT, TENT, SHOT, On-target)등을 비교합니다. 여기서는 이미지 생성, 프로토타입, 엔트로피 최소화, pseudo-labeling, contrastive+PL 결합 등 서로 다른 계열을 대표하는 방법들로 구성해둔 느낌입니다. 또 공정성을 위해 저자는 MCC/SHOT/TENT는 저자 코드로 직접 실행했고, 나머지는 논문 수치를 인용했다고 합니다.
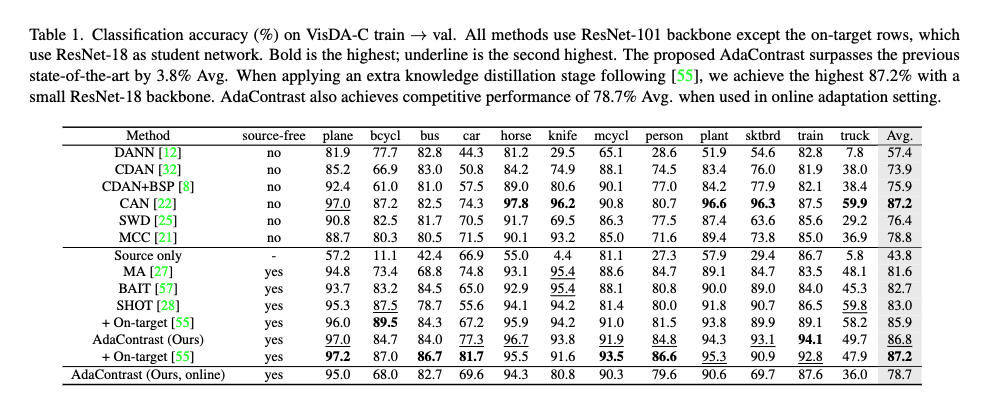
먼저 표 1은 VisDA-C의 train -> val 도메인 시프트에서 AdaContrast를 기존 SOTA 방법들과 비교한 결과입니다. 먼저 UDA 방법론과 비교했을 때 AdaContrast는 좋은 성능을 보이는 UDA 베이스라인인 CAN 과 거의 비슷한 성능을 보이면서도 다른 UDA 방법들의 성능을 넘어서는 결과를 보입니다. 저자는 여기서 AdaContrast는 테스트 시점 적응 동안 소스 데이터를 전혀 사용하지 않는데도 UDA 강자들과 맞먹는 결과를 낸다고 주장합니다.
TTA 설정에서는 차이가 더 커지는 결과를 보입니다. 클래스별 평균 기준으로 SHOT 대비 +3.8%의 성능을 보이고 또 SHOT 기반으로 구성된 On-target adaptation과 비교해도 더 좋은 결과를 보이는 것을 확인할 수 있습니다. 저자는 이에 대해서 AdaContrast의 공동 학습과 online refinement설계의 효과라고 합니다.
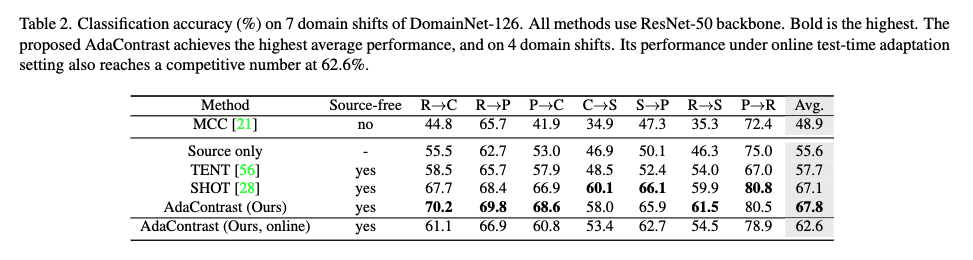
표 2는 DomainNet-126에서 4개 도메인(Real/Sketch/Clipart/Painting)으로 구성된 7개 domain shif에 대한 비교 결과입니다. 마찬가지로 도메인 시프트별로는 7개 중 4개에서 최고 성능을 보여주고 전체 평균도 가장 높은 것을 확인하실 수 있습니다.
Analysis and Discussion
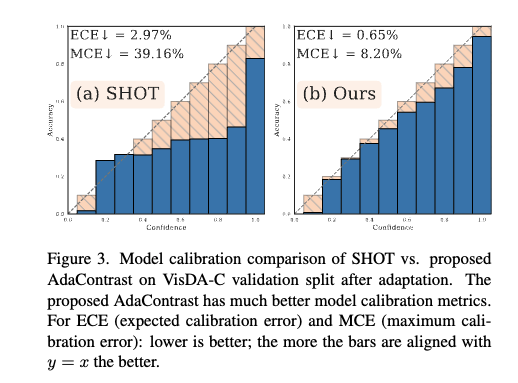
AdaContrast는 SHOT 대비 calibration이 더 좋다라는 주장에 대한 분석
저자는 엔트로피 최소화 기반(TENT, SHOT 등) 방법들은 타겟 예측에서 모델의 낮은 엔트로피를 유도해 성능을 끌어올리기는 하지만 정답 라벨과 무관하게 엔트로피를 직접 최적화하기 때문에 캘리브레이션이 깨질 수 있다는 문제가 있습니다. fig3은 VisDA-C validation split에서 SHOT vs AdaContrast의 reliability diagram을 비교합니다. 확률 구간 [0,1]을 10개 bin으로 쪼개고 각 bin에서 평균 정확도 vs 평균 confidence를 계산한 뒤에 막대가 y=x 그래프 에 가까울수록 calibration이 좋다고 해석합니다. 결과적으로 SHOT은 막대가 y=x 아래로 크게 떨어져 over-confident 경향이 강한 반면AdaContrast는 y=x에 훨씬 더 잘 정렬되는 결과를 보입니다.
AdaContrast는 하이퍼파라미터에 둔감하다라는 주장에 대한 분석
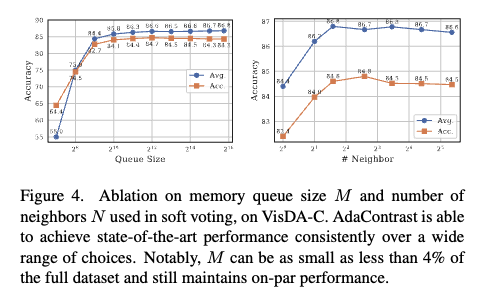
TTA에서 하이퍼파라미터 민감도는 실제로 자주 언급되는 문젝라고 합니다. Fig. 4에서는 AdaContrast의 핵심 하이퍼파라미터인 큐 크기 M 과 soft voting 이웃 수 N 를 넓은 범위로 바꿔도 VisDA-C에서 성능이 일관되게 유지됨을 보입니다.
M \in {128, 256, \ldots, 32768, 55388}
메인 실험 결과는 M=55388, N=11 설정으로 보여주기는 하지만, M을 훨씬 작게 쓰거나 N을 바꿔도 성능 저하가 거의 없고, 대략 Acc는 84.5% per-class Avg는 86.7% 수준을 안정적으로 보인다고 합니다. M=512만 써도 per-class Avg 84.4%로 SOTA급 성능을 보이고, M=2048은 메인 실험 버전(M=55388)의 4% 미만인데도 86.3%로 비슷한 성능을 보여줍니다.
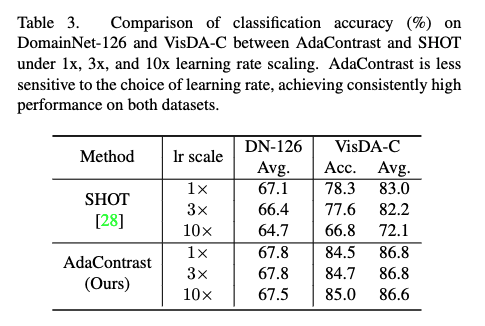
그리고 표 3에서는 학습률을 1x/3x/10x로 바꿔도 AdaContrast는 VisDA-C와 DomainNet-126에서 성능이 안정적이지만, SHOT은 특히 VisDA-C에서 성능 하락이 크게 나타납니다. 성능이 좋은 것뿐 아니라 세팅이 바뀌어도 잘 버틴다는 점을 위와 같은 실험을 통해서 보여주는 것 같습니다.
Online TTA에서도 성능이 강하다는 주장에 대한 분석
AdaContrast는 전역 메모리 뱅크를 미리 채우거나 전체 데이터셋을 먼저 처리하는 방식이 아니라 타겟 데이터가 배치 스트림으로 들어오고 각 샘플을 한 번만 보는 실제 배포상황에서의 온라인 적응에 구조적으로 잘 맞는다고 저자는 주장합니다.
온라인 설정에서는 초기 X개 샘플 동안은 pseudo-label refinement를 끄고(단, 수도 라벨은 배치마다 즉시 생성하되 refinement 없이 직접 예측값을 사용), 메모리 큐 Q_w에 feature–probability pair가 X개 쌓이면 그때 refinement를 켭니다.
실험적으로는 VisDA-C에서 X=2048(전체의 4% 미만), DomainNet-126에서 X=1024(평균 4% 미만)만 누적해도 온라인 setting에서 큰 폭으로 성능이 잘 나오는 것을 보여주고 DomainNet-126에서는 7-shift Avg 62.6%로 MCC 대비 +13.7%의 성능을 보여줍니다.
AblationStudy
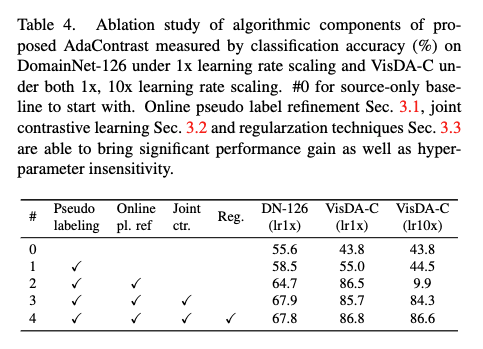
위는 각각 방식들에 대한 어블레이션과 학습률 실험입니다. 저자는 VisDA-C에 대해 10x 학습률 실험을 함께 포함한 이유를 표 1의 메인 결과에 사용한 학습률 대비 의도적으로 불리한 학습률 선택 상황을 설정함으로써 AdaContrast의 각 구성 요소가 수행하는 역할을 보다 명확하게 보여주기 위함이라고 합니다.
Conclusion
이렇게 테스트시점에서 adaptation 하는 연구에 대해서 가볍게 한번 알아보고자 읽었던 논문인데 꽤나 수식도 복잡하고 핵심 개념들도 전반적으로 이해하기 쉽지 않았던 것 같습니다. 그래도 이런 방법론을 제대로 활용할 수 있다면 파운데이션 모델급의 큰 모델들을 파인튜닝 하지 않아도 상대적으로 적은 리소스만으로 테스트 환경에 빠르게 적응시켜 적용할 수 있다는 점에서 메리트가 있는 것 같습니다.
이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
TTA 라는 기법을 저도 한번 적용해본 적이있는데 제일 문제점이 시간 문제인것 같습니다. 추론할때 고려해야하는 것이 inference time 인데 해당 논문의 방법론이 얼만큼의 추론시간이 걸리는지 궁금하고 저자들의 한계또는 추론시간에대한 실험도 진행했을거 같은데 이에 대해 저자들의 언급이 없었는지 궁금합니다!
감사합니다
안녕하세요 우진님 좋은 댓글 감사합니다.
TTA를 적용해보셨다니 멋지십니다. 추론할 때 고려해야하는 것이 inference time인거에 대해서 저도 동의하는 부분입니다. TTA자체가 추론과정중에 가중치를 업데이트 하기 때문에 리소스나 추론시간에 대한 실험도 있으면 좋을 것 같지만 아쉽게도 해당 논문에서 저자들의 언급은 없었습니다. 일단 먼저 해당 태스크 자체가 image Classification 이다 보니깐 추론시간에 대해서 저자는 별다른 언급이 없었떤 것 같고 로봇같은 실시간 스트리밍이 중요한 상황에서는 TTA라는 방식이 추론시간/리소스 또한 중요하게 평가되어야할 요소라고 생각합니다. 감사합니다.