안녕하세요. 이번 X-Review에서는 super-class를 활용하여 attribute classification의 zero-shot 성능을 향상시킨 논문에 대해 리뷰해보도록 하겠습니다.
1. Introduction & Related Works
attribute classification은 객체의 color, size와 같은 속성을 분류하는 문제로, 속성 유형에 따라 모델이 집중해야 하는 visual context가 다릅니다. 기존 연구는 VLM 지식 활용의 유연성과, 모델 구조의 확장성이라는 두 관점에서 한계를 보였습니다.
첫 번째는 VLM 학습 전략 측면입니다. 주로 CLIP과 같은 pretrained VLM을 fine-tuning 하여 zero-shot 성능을 개선하고자 하는 시도가 있었습니다. 저자는 이 방식이 VLM이 이미 가지고 있는 일반화 성능을 제대로 활용하지 못한다고 지적하며, 동결된 VLM의 임베딩을 활용하는 것이 다양한 downstream 작업에서 open-vocabulary 세팅에 대해 좋은 성능을 달성할 수 있다고 주장하였습니다.
두 번째는 모델 구조 측면입니다. 기존에는 속성 클래스 별로 query를 사용하는 transformer 기반 방식에 대한 시도가 많았습니다. 이 방식은 fine-grained classification에서 강력한 성능을 보여주지만, 클래스의 수가 증가함에 따라 query도 선형적으로 증가하여 높은 연산량을 요구하고, 그만큼 확장성이 떨어지게 됩니다. 또한 seen class와 unseen class 간의 관계 활용이 미흡하여 최적의 일반화 성능을 보여주지 못합니다.
이러한 기존 문제들을 보완하여 저자는 zero-shot 환경에서 scalability와 generalizability를 모두 향상시키고자 했습니다. 제안하는 프레임워크의 이름은 Super-class guided transFormer(SugaFormer)입니다. 이름에도 있듯이 이 방법론의 메인 아이디어는 여러 attribute를 상위 개념인 super-class로 묶어, 계층적인 구조를 활용하는 것입니다.
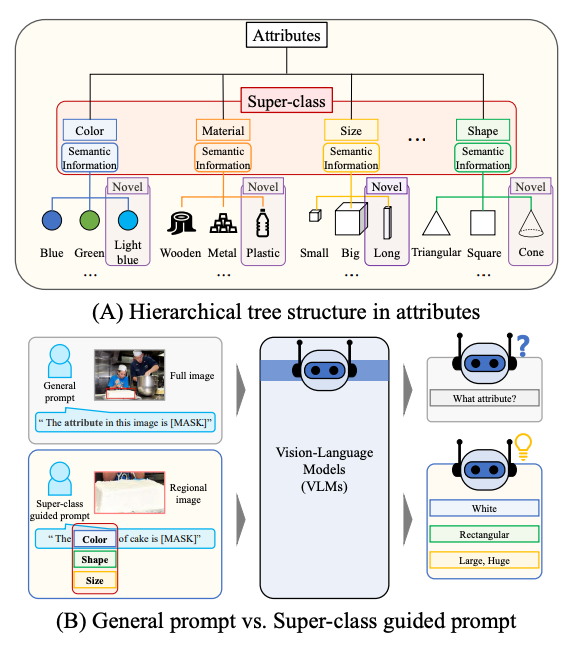
위 그림의 (A)에서 볼 수 있다시피 super-class(e.g., Material)와 attribute-class(e.g., Wooden, Metal, Plastic)를 활용하는 Super-class Query Initialization (SQI)을 통해, query 수를 줄이면서도 각 super-class 내의 공통된 의미 정보를 활용하여 확장성과 일반화 성능을 모두 향상시킬 수 있었다고 합니다. 또한 Multi-context Decoding (MD)를 통해 다양한 context를 고려하여 attribute를 예측하고자 합니다. (2.2절에서 설명)
다음으로 (B)의 좌하단에 표시된 Super-class guided prompt를 사용하여 training 중에는 Super-class guided Consistency Regularization (SCR)을 하고, inference 시에는 unseen attribute에 대한 예측을 개선하기 위해 Zero-shot Retrieval-based Score Enhancement (ZRSE)를 사용합니다. (2.3절에서 설명)
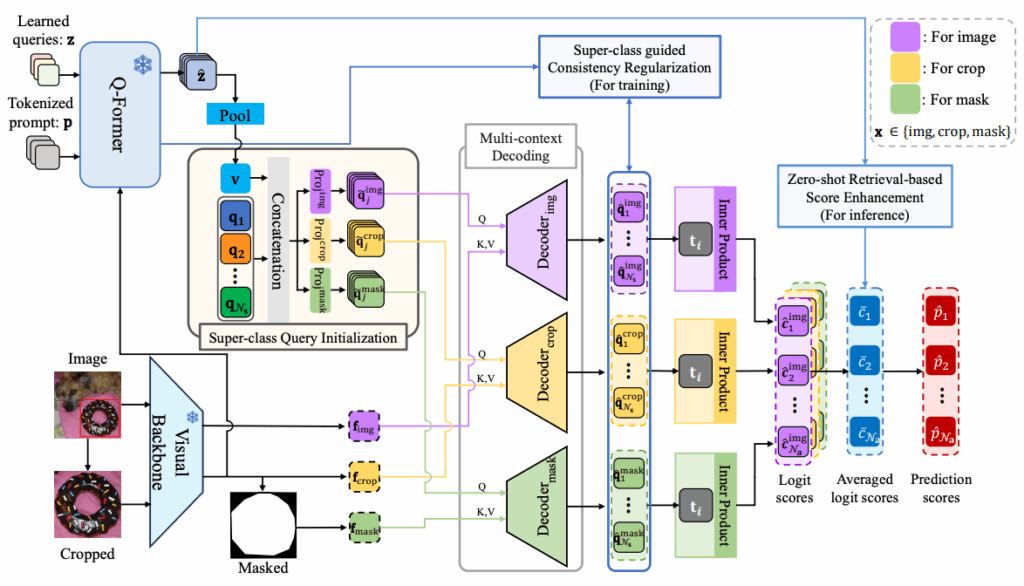
전체적인 model architecture는 위와 같으며, 세부적인 설명은 아래 2절에 기술하도록 하겠습니다.
2. Method
2.1. Preliminary
Problem setting
attribute classification은 target object (I, b, m, o) 가 주어졌을 때 label vector Y 를 예측하는 문제라고 정의할 수 있습니다.
- image: I ∈ ℝ^{H×W×3}
- bounding box: b ∈ ℝ^{4}
- segmentation mask: m ∈ ℝ^{H×W}
- object category: o
- label vector: Y ∈ {1, 0, -1}^{N_a} (N_a는 attirbute class의 개수이며, 1, 0, -1은 각각 positive, negative, unknown을 의미합니다.)
또한 train 시 base attribute class A_{base} 만을, inference 시에는 A = A_{base} ∪ A_{novel} 을 사용하여 zero-shot 성능을 평가합니다.
Base architecture
성능이 좋고 구조가 단순한 transformer 기반 multi-label classifier ML-Decoder를 base로 사용합니다.
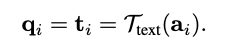
i번째 attribute class a_i 를 text encoder T_{text} 에 태워 text embedding t_i 를 얻고, 이 값으로 query q_i 를 초기화합니다.
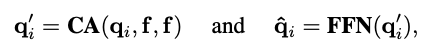
여기서 f는 visual feature map, CA는 cross-attention 연산, FFN은 feed-forward 연산입니다. 위 과정을 통해 output query \hat{q}_i 를 얻게 됩니다.
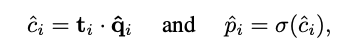
그 다음 t_i 와 \hat{q}_i 를 내적한 뒤 sigmoid 함수를 거쳐 최종적으로 i번째 attribute class의 prediction score인 \hat{p}_i 를 얻습니다.
2.2. Super-class guided Transformer
Super-class Query Initialization (SQI)
앞서 설명드렸듯이 이전 방법론들은 class 당 하나의 query를 생성합니다. 이러한 class-wise query를 사용하는 경우 속성이 많아질수록 query도 선형적으로 증가하며, query에 대응하는 class의 supervised signal만 받기 때문에 각 속성들 간의 semantic한 정보들을 학습할 수 없다는 문제점을 가지고 있습니다.
반면 super-class query는 해당 super-class 내의 속성들끼리 공유되는 semantic한 정보들을 포착할 수 있으며, 속성의 수가 많더라도 super-class의 개수만큼의 query만 사용하기 때문에 메모리 측면에서 매우 효율적입니다. 자세한 initialization 과정은 아래와 같습니다.
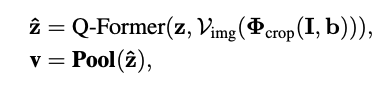
이미지 I를 bounding box b에 해당하는 영역만큼 크롭한 뒤, visual backbone V_{img} 에 태워 feature map을 생성합니다. 그 후 learned query 집합 z과 함께 Q-Former를 통과하면 output feature \hat{z} 를 얻게 됩니다.
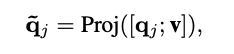
그 후 j번째 super-class query q_j 와 \hat{z} 이 pooling을 거쳐 얻은 visual feature v 를 concat한 뒤 d_q (query의 dimension)차원 특징 공간에 projection하여 decoder가 사용 가능한 query \tilde{q}_j 를 얻습니다.
Multi-context Decoding (MD)
성능 향상을 위해 다양한 contextual information을 활용하는 전략입니다. 속성 유형에 따라 모델이 집중해야 하는 visual context가 다르기 때문입니다. 예를 들어 color에 대한 속성이라면 정확히 객체에 해당하는 부분만을 집중하는 것이, size에 대한 속성이라면 더 넓게 이미지 전체에 집중하는 것이 올바른 예측에 도움이 될 것입니다.
먼저 cropped feature f_{crop} , masked feature f_{mask} , image feature f_{img} 로 총 세 유형의 feature map을 추출합니다.
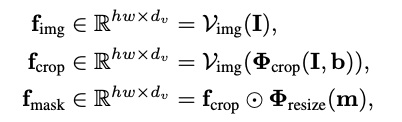
f_{crop} 은 local information을 뽑기 위해 bbox로 크롭된 이미지에서 추출하는 feature map이며, f_{mask} 는 오로지 객체에만 집중하기 위해 segmentation mask로 배경을 제거한 후 추출합니다. 마지막으로 f_{img} 는 global context를 위해 전체 이미지로부터 얻는 feature map입니다.
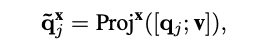
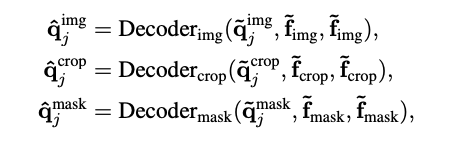
(x는 {img, crop, mask} 중 하나의 context를 의미합니다.)
최종적으로 위와 같이 각 context 별로 독립된 decoder를 사용해, 동일한 super-class query라도 context에 따라 다른 정보를 반영한 출력 \hat{q}^x_j 을 얻습니다.
Attribute prediction
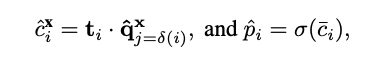
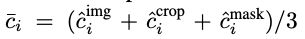
마지막으로 위와 같이 세 개의 context에서의 logit들을 평균내어 sigmoid를 거쳐 최종 prediction score를 얻습니다. (각 notation의 의미는 2.1절에서와 같으며, j=𝛿(i)는 i번째 attribute-class가 속하는 super-class의 인덱스가 j임을 의미합니다.)
2.3. Knowledge transfer strategies
Super-class guided Consistency Regularization (SCR)
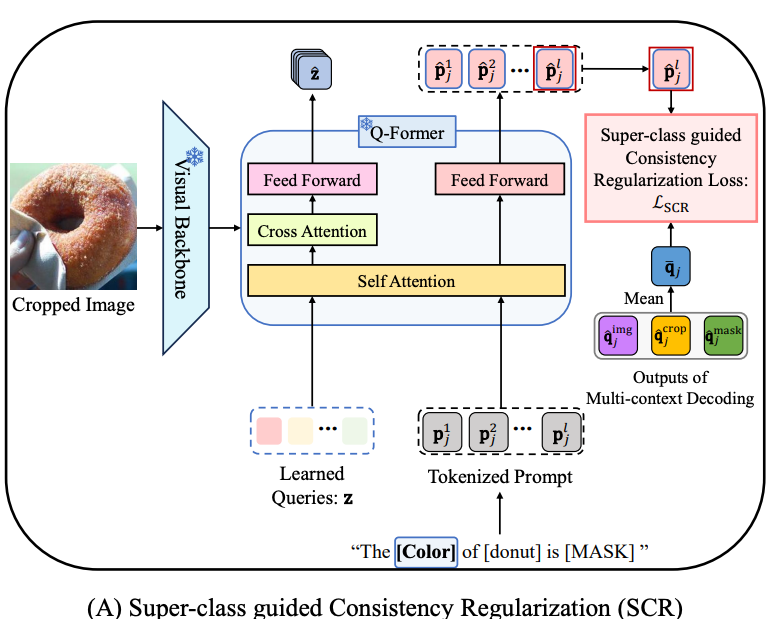
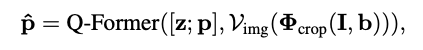
다음은 학습 전략입니다. p는 [MASK] token을 포함하는 prompt로, 그림 하단에 적혀 있는 것처럼 “The [Color] of [donut] is [MASK]”와 같은 형태입니다. 이 prompt는 j번째 super-class에 대해 l개의 token으로 tokenize 됩니다. 이 token들을 Q-Former에 통과시켜 \hat{p} 을 얻게 되는데, 그림의 우상단에 있는 \hat{p}^l_j 가 바로 [MASK]에 해당하는 token 벡터입니다. (BLIP2에서는 이 벡터를 이용하여 text generation을 하지만, SugaFormer에서는 이 단계가 불필요하므로 사용하지 않고 token embedding만 활용합니다.)
이렇게 Q-Former가 생성한 \hat{p}^l_j 와, 2.2절의 Multi-context Decoding에서 얻은 output의 평균인 \bar{q}_j 가 가까워지도록 학습합니다. 이때 L1 loss를 사용하며 아래 수식의 L_{SCR} 에 해당합니다.
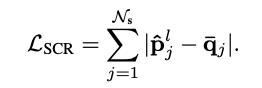
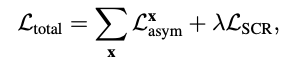
추가로 multi-label 분류에서 class 불균형을 완화하기 위해 고안된 asymmetric loss를 더하여 최종적으로 L_{total} 을 사용합니다.
Zero-shot Retrieval-based Score Enhancement (ZRSE)
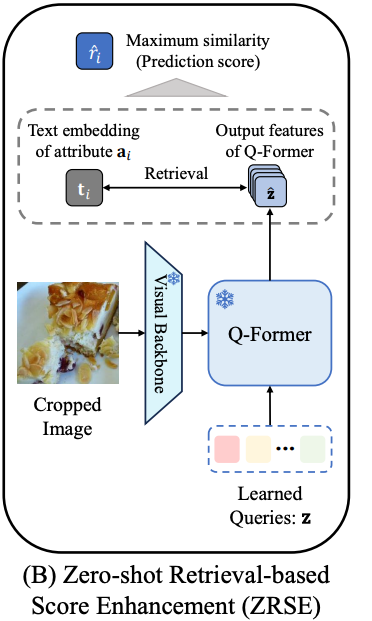
Q-Former의 prediction score를 활용하여 unseen attribute class에 대한 최종 예측을 향상시키기 위한 모듈입니다. Q-Former에서는 learned query z로 부터 생성된 output embedding \hat{z} 를 text embedding과 개별적으로 비교하고, maximum similarity score를 전체 similarity score로 선택합니다.
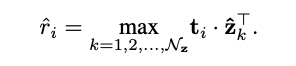
i번째 attribute의 text embedding t_i 와 output embedding \hat{z} 의 모든 query 중 가장 유사도가 높은 값을 선택합니다.
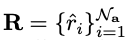
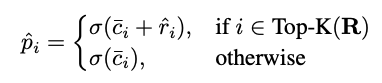
마지막으로 R의 Top-K score를 선택하여 대응하는 attribute class의 예측에 추가합니다.
정리하자면, Q-Former 유사도가 높은 소수의 속성들에 한해 \bar{c}_i 에 \hat{r}_i 를 더하여, decoder가 놓칠 수도 있는 unseen 속성들을 보완하는 기능을 합니다.
3. Experiments
데이터셋은 VAW, LSA, OVAD 세 가지를 사용하며, 평가 지표는 AP를 사용합니다. 이때 base class, novel class, all class에 대해 AP_{base} , AP_{novel} , AP_{all} 로 나누어 평가합니다. 또한 visual backbone으로는 ViT-g/14를 사용했고, 동일한 backbone을 가지는 MLDecoder를 활용한 구조를 baseline으로 삼았다고 합니다.
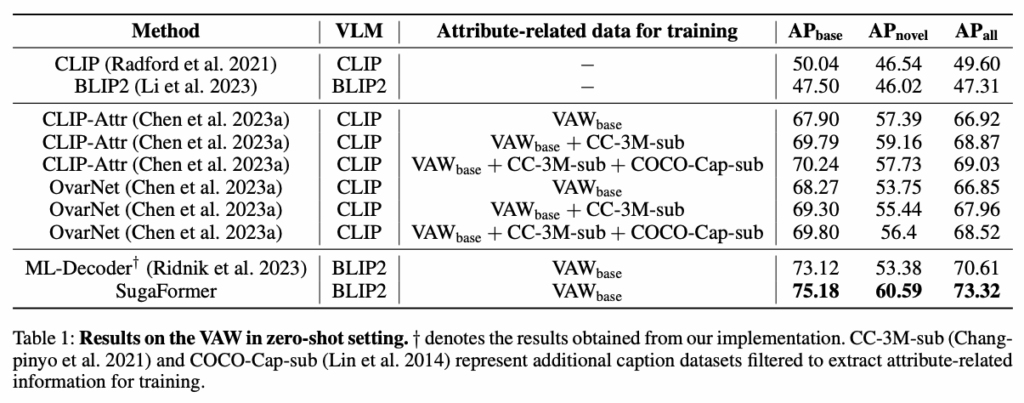
table 1은 VAW dataset의 zero-shot 성능에 대한 표입니다. SugaFormer의 성능은 baseline인 ML-Decoder에 비해 향상되었음을 확인할 수 있습니다. 특히 novel class에 대해서는 53.38에서 60.59로 AP가 크게 향상되었습니다. 즉 SugaFormer가 unseen 속성에 대한 일반화 능력이 더 좋다는 것을 보여주며, VAW base 데이터셋만으로 학습하였음에도 불구하고, 더 다양한 데이터셋으로 학습된 기존 방법론들을 능가하는 성능을 보여줍니다.
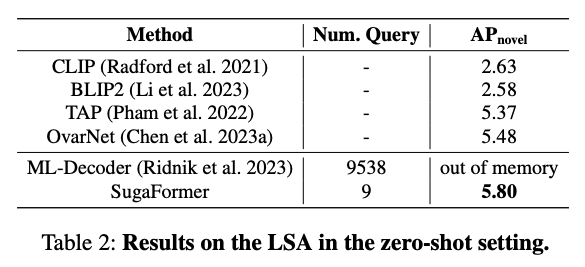
table 2는 LSA dataset에 대한 성능을 나타내는데, ML-Decoder에서는 class 개수만큼 query가 생성되어 메모리 부족 문제로 인해 train을 할 수 없었습니다. 반면 SugaFormer는 단 9개의 query만으로 AP_{novel} 5.80을 달성하였습니다.
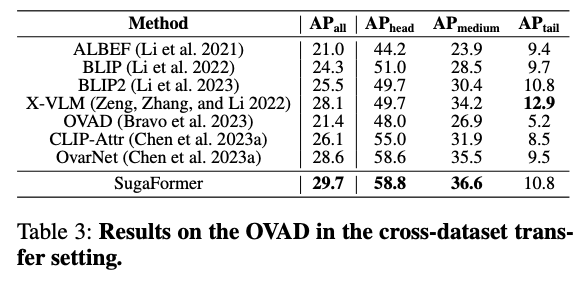
마지막으로 table 3은 OVAD dataset에 대한 실험 결과로, VAW dataset으로 학습된 SugaFormer를 OVAD dataset으로 평가하는 cross-dataset transfer setting입니다. AP_{tail} 은 X-VLM에 비해 낮은 AP를 보이지만, head와 medium에서는 최고 성능을 보여 가장 높은 AP_{all} 을 달성하였습니다.
SugaFormer는 super-class를 활용함으로써 적은 수의 query를 사용하여 확장성을 가지면서도, unseen class에 대한 일반화 성능을 확보하고자 하였습니다. 앞으로의 제 attribute detection 연구에 참고할 점이 있을 것 같아 이 모델의 핵심 방법론인 SQI, MD, SCR, ZRSE에 대해 상세히 살펴보았습니다. 전반적으로 이해하는 데 시간이 꽤 걸린 것 같지만 하나하나 따라가며 읽다보니 재미있게 읽은 것 같습니다. 많은 댓글 달아주시면 감사하겠습니다! 읽어주셔서 감사합니다.
리뷰 잘 읽었습니다.
저자가 문제 삼은 첫번째인 FT보다 zero-shot 을 활용해야한다는 측면에서 저도 공감이 많이 되는 것 같네요. 궁금한 점이 있어 댓글 남겨두겠습니다
1. 논문에서 사용하는 super-class(e.g., material, color 등)는 VAW/LSA/OVAD 데이터셋에 원래 정의되어 있는 정보인가요, 아니면 저자들이 별도로 설계한 semantic grouping인가요? 만약 후자라면, super-class 정의를 어떻게 할 지에 따라 성능이 많이 달라질 것 같다는 생각이 드네요
2. novel attribute 성능 향상이 super-class 단위 semantic 공유에서 오는 효과인지, 아니면 ZRSE와 같은 retrieval 기반 보정의 영향이 더 큰지 개인적으로 좀 헷갈리는데요, 리뷰하실 때 이 부분은 어떻게 해석하셨는지도 궁금합니다!
3. 기존 ML-Decoder가 LSA에서 query 수 문제로 학습이 안 됐다는 부분이 신기한데, 이게 단순히 메모리 문제인지, 아니면 query 수 증가 자체가 optimization이나 학습 안정성에도 영향을 주는 구조적 문제인지 어떻게 이해하면 좋을까요?
안녕하세요 예은님, 좋은 리뷰 감사합니다.
간단한 질문이 3가지 있는데요.
1-1. table 2에 LSA데이터셋에 대한 성능이 전반적으로 AP 5정도에 해당하는 정말 낮은 결과를 보이는데, 이건 LSA데이터셋이 타 데이터셋 대비 상대적으로 매우매우 어려운 데이터셋인건가요? 그렇다면 어떤 부분때문에 처참할 정도로 어려운건지, 학습을 table1의 경우랑 유사하게 LSA_base로 학습하고 LSA_novel로 평가한건지 궁금합니다.
1-2. 계속해서 table2에서 다른 베이스라인들의 num query는 왜 명시되지 않은건지 궁금합니다.
2. 같은 슈퍼클래스일지라도 구분이 모호한 하위속성들이 있을 수도 있을 것 같습니다. 예를 들어 shape이라는 슈퍼클래스에서 round와 oval이 시각적으로 구분이 모호한 경우가 있을 수도 있을 것 같습니다. 하위 attribute들의 종류가 모두 서로간에 배타적이면서도 유니크한 속성인지가 학습시그널에 좋은 영향을 줄 것 같기도 한데, 예은님의 생각은 어떠신지 궁금합니다.
감사합니다.
예은님 좋은 리뷰 감사합니다.
속성을 기반으로 해당하는 물체를 찾는 것 이 아닌, 물체에 해당하는 속성을 인식하는 것으로 이해하였습니다. 예은님이 해당 연구에 대해 서베이 해보셨을 때, 두 방식은 근본적으로 어떤 차이가 있는 지 정리가 되셨으면 설명 부탁드립니다.
제가 이해하기로, super-class는 속성의 타입, attribute-class는 세부적인 속성을 나타낸 것으로 이해하였습니다. 방법론에 대한 설명을 보기 전에는 물체에 대한 super-class 별로 attribute-class를 예측하는 줄 알았는데, 모든 super-class 속성을 활용하여 attribute-class 예측에 활용하는 것으로 이해하였습니다. 그렇다면, 통합된 정보만으로는 세부적인 attribute-class에 대한 정보를 제공하는 데 약간의 어려움이 있을 것 같습니다. 즉, 직접적으로 attribute 예측에 각 super-class 쿼리들이 영향을 줄 수 있을 것 같은데 이를 Decoder에서 융합해버리면 이에 대한 정보가 약화되는 것 같습니다. 이를 개선하기 위한 방식을 고안해보면 좋을 것 같습니다.