지난주에 리뷰한 [ICLR 2026] CLIP Behaves like a Bag-of-Words Model Cross-modally but not Uni-modally 와 비슷한 계열의 의문을 제기한 페이퍼를 한번 리뷰해보겠습니다

- Venue: Arxiv 2026
- Authors: Imanol Miranda, Ander Salaberria, Eneko Agirre, Gorka Azkune
- Title: Revisiting Compositionality in Dual-Encoder Vision-Language Models: The Role of Inference, Arxiv 2026
- GitHub: [Link] (아직 미공개)
0. Background
본격적인 리뷰에 앞서, CLIP과 같은 dual-encoder VLM이 compositionality 문제가 왜 자주 발생하는지 먼저 살펴보겠습니다. 다들 알고계씨겠지만, Dual-encoder VLM은 이미지를 visual encoder로, 텍스트를 text encoder로 각각 encoding한 뒤, 최종적으로 나온 global embedding 사이의 cosine similarity를 계산하는 방식으로 이미지와 텍스트를 매칭합니다.
이 방식은 image-text retrieval이나 zero-shot classification에서는 효과적이었지만, compositional reasoning에서는 한계가 있었습니다. 예를 들어 black dog and white cat과 black cat and white dog 처럼 같은 단어들로 구성되지만 attribute-object binding만 다른 경우, 모델이 두 문장을 잘 구분하지 못한다는 것이죠. 그래서 기존 연구들은 CLIP이 문장을 구조적으로 이해하기보다는 Bag-of-Words (BoW) 처럼 동작한다고 보았습니다.
어찌보면 CLIP 같은 VLM이 BoW 처럼 동작한다는 것이 통념처럼 자리잡았었습니다. 그런데 최근 연구들에서 이런 의문을 가지기 시작했는데요, 바로 “정말 CLIP 내부 representation에 compositional 정보가 없는 것인가?”
(참고로 제가 지난주에 리뷰한 논문인 [ICLR 2026] CLIP Behaves like a Bag-of-Words Model Cross-modally but not Uni-modally 에서도 동일한 의문을 제시했었습니다. 여기서는 encoder들은 compositional 정보가 있는데 alignment 매칭하는 부분이 문제다라고 결론을 내렸죠)
이번 논문에서는 image embedding과 text embedding을 단순히 하나의 cosine similarity로 비교하는 inference 방식이 잘못된 것은 아닌가? 하는 의문을 제시하였습니다.
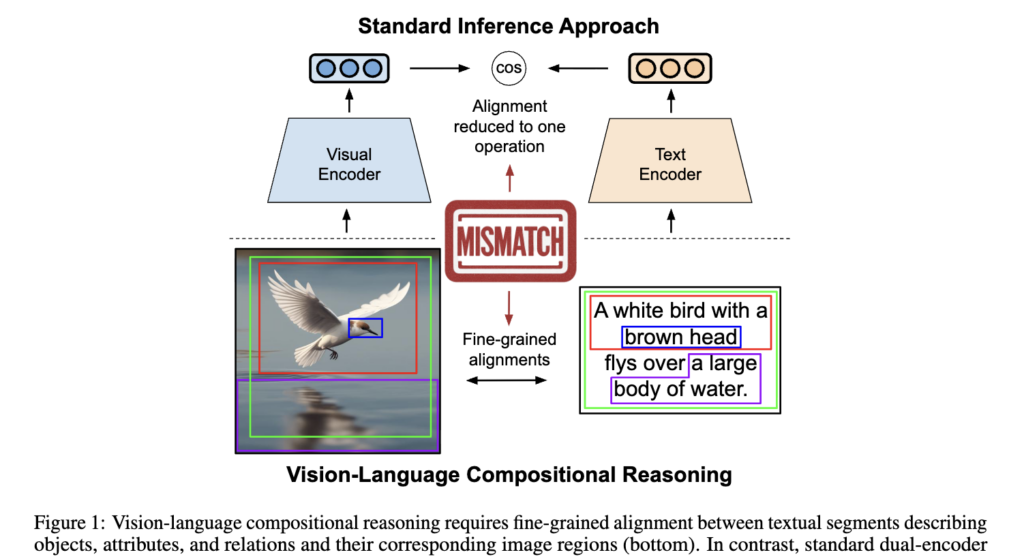
Figure 1은 이 문제를 잘 보여주는 것 같은데요, compositional reasoning에서는 텍스트의 각 segment가 이미지의 어떤 region과 대응되는지가 중요한데, 기존 방식은 이 과정을 하나의 global matching으로 줄여버렸습니다.
1. Introduction
앞서 본 것처럼, 기존 연구들은 dual-encoder VLM이 compositional reasoning에 약하다고 했습니다. 그러나 본 논문에서는 그 원인을 representation 자체의 부족으로 바로 결론내리지 않았습니다. 대신 “pretrained encoder 안에는 필요한 정보가 이미 들어있지만, global cosine similarity 기반 inference가 그 정보를 제대로 꺼내 쓰지 못하는 것은 아닐까?”라는 관점에서 문제를 다시 본 것이죠
이를 확인하기 위해 저자들은 먼저 encoder를 전혀 학습하지 않고 frozen 상태로 둔 뒤, inference 방식만 바꾸어 실험했습니다. 이미지를 여러 region으로 나누고, 텍스트도 object-attribute 단위의 segment로 나눈 다음, region과 segment를 직접 맞춰보는 방식입니다. 만약 이 방식만으로 성능이 좋아진다면, 문제는 representation 부족보다는 alignment 방식에 있을 가능성이 커집니다.
이후 저자들은 사람이 정한 규칙으로 alignment를 강제하는 데서 더 나아가, frozen patch embedding과 token embedding 위에서 lightweight transformer가 직접 fine-grained alignment를 학습하도록 했다고 합니다.
결국 이 논문의 핵심은 dual-encoder VLM의 compositionality failure를 encoder가 정보를 못 배운 문제가 아니라, inference 과정에서 fine-grained alignment를 활용하지 못한 문제로 재해석하는 데 있는 것 같습니다. 이제 이 주장을 어떻게 실험적으로 보였는지 살펴보겠습니다.
2. Diagnosing the Inference Bottleneck in VLMs
저자들이 제시한 가설은 dual-encoder VLM의 compositionality failure가 representation 자체의 문제라기보다 global cosine similarity 기반 inference의 문제일 수 있다는 것입니다. 이를 확인하기 위해 저자들은 먼저 BISCOR-CTRL이라는 controlled benchmark를 새로 구성했다고 합니다. 그리고 이 벤치마크로 가설이 맞는지 평가를 진행하였습니다.

Figure 2를 보면 Color, Size, Material, Quantity 네 가지 category가 있고, 각 예시는 정답 image-caption pair와 binding만 바뀐 hard negative pair로 구성되어 있습니다. 즉, 모델이 단순히 cube, red, sphere 같은 개별 요소만 인식해서는 맞히기 어렵고, 어떤 attribute가 어떤 object에 연결되는지를 정확히 봐야 하는 설정인 것이죠
Structure-Guided Inference (SGI)
저자들은 가설을 확인하기 위해 encoder를 frozen 한 뒤, inference 방식만 바꿔보았습니다. 다시말해, Similarity 계산할 때 글로벌 매칭만 하는게 아니라는 건데, 이를 Structure-Guided Inference 라고 부릅니다.
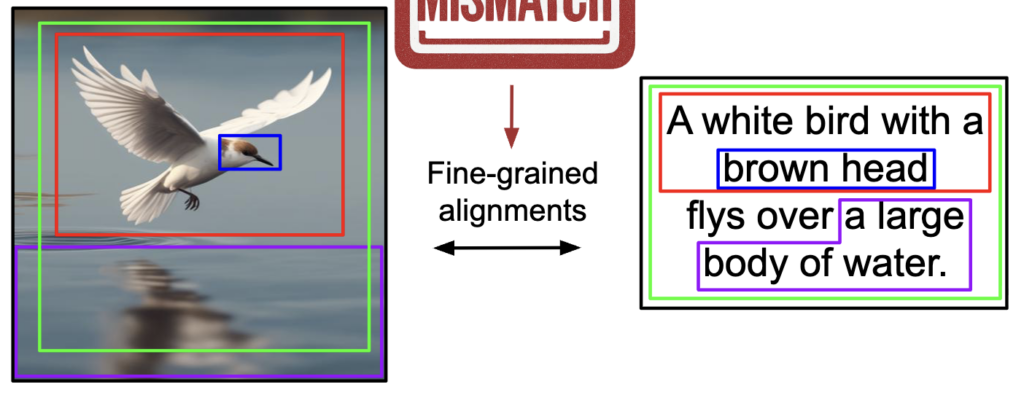
방식은 먼저 이미지를 여러 crop으로 나누고, 텍스트는 ‘black cat’, ‘white dog’처럼 object-attribute segment로 나눈 뒤, 각 text segment와 가장 잘 맞는 image crop을 찾아 similarity를 계산했다고 합니다. 기존 CLIP이 이미지 전체와 문장 전체를 한 번에 비교했다면, SGI는 이미지의 부분과 텍스트의 부분을 먼저 맞춰본 뒤 최종 score를 계산한 것이죠 (상단 그림 참고)
평가 메트릭으로는 group score를 사용하였습니다. 이는 image-to-text와 text-to-image retrieval을 모두 맞혀야 점수가 올라가는 metric 이라고 합니다. 즉, 하나의 방향만 맞히는 것이 아니라 두 이미지와 두 caption 사이의 양방향 매칭이 모두 정확해야 하기 때문에 compositional reasoning을 더 세밀하게 평가한다고 볼 수 있겠네요
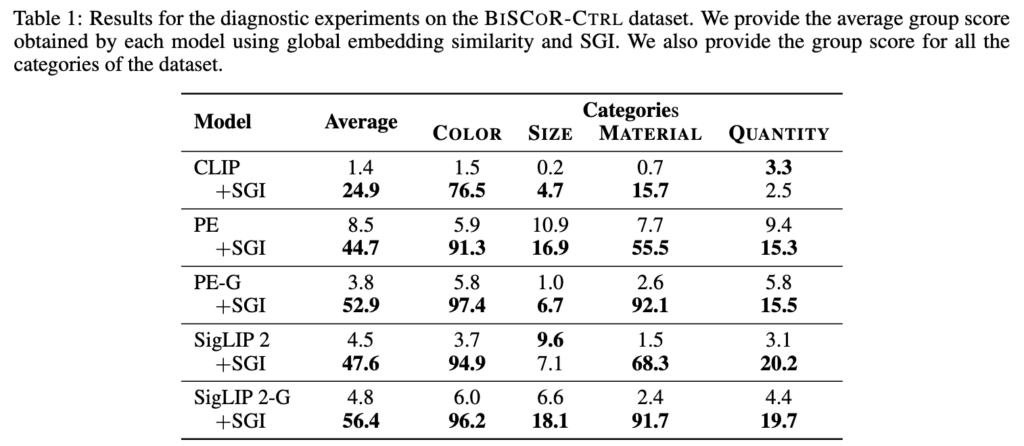
Table 1의 실험 결과, 기존 global cosine similarity를 사용했을 때는 CLIP, PE, SigLIP 2 모두 매우 낮은 group score를 보였습니다. 반면 SGI를 적용하자 모든 모델에서 성능이 크게 향상되었습니다.
encoder는 freeze 했기 때문에, CLIP이나 SigLIP 2가 가진 representation 자체는 그대로 두고, image crop과 text segment를 맞춰보는 inference 방식만 바꿨는데 성능이 크게 향상되었다는 것은… pretrained representation 안에 compositional reasoning에 필요한 정보가 어느 정도 존재했다는 것을 의미한다고 합니다. (애초에 데이터셋이 compositional에 집중되도록 설계되었으니까요)
(Findings) similarity 계산법을 바꾸는 실험 Table 1을 통해, pretrained VLM representation 안에 compositional reasoning에 필요한 정보가 어느 정도 존재하지만, 기존 global matching 방식이 그 정보를 제대로 활용하지 못하고 있음
3. Learning Fine-Grained Alignment from Frozen VLMs
앞선 SGI 실험은 inference 방식만 바꿔도 성능이 좋아질 수 있다는 것을 보여주었습니다. 다만 SGI는 사람이 정한 방식으로 이미지를 crop하고, 텍스트를 segment로 나누는 구조였죠. 그래서 저자들은 다음 질문으로 넘어갑니다. 그렇다면 이런 fine-grained alignment를 모델이 직접 학습할 수 있을까? 이를 확인하기 위해 pretrained visual/text encoder는 frozen한 상태로 두고, 그 위에 lightweight alignment transformer만 추가했습니다.
방식은 기존처럼 image/text의 global embedding을 바로 비교하는 것이 아니라, visual encoder에서 나온 patch embedding과 text encoder에서 나온 token embedding을 transformer에 넣는 것입니다. 이 transformer는 patch와 token 사이의 cross-modal interaction을 통해 어떤 텍스트 표현이 어떤 이미지 영역과 대응되는지를 학습합니다. 중요한 점은 encoder 자체는 업데이트하지 않았다는 것입니다. 즉, 성능이 좋아진다면 이는 새로운 representation을 배운 결과라기보다, pretrained representation 안의 정보를 더 잘 align해서 사용한 결과라고 볼 수 있습니다.
이를 더 명확히 보기 위해 저자들은 세 가지 설정을 비교했습니다. 첫 번째는 encoder 전체를 업데이트하는 Full Fine-tuning, 두 번째는 global embedding 위에 transformer를 얹은 TFGlobal, 세 번째는 patch/token embedding 위에 transformer를 얹은 TFLocal입니다. 이 비교가 중요한 이유는 간단합니다. 성능 향상이 단순히 parameter가 늘어서 생긴 것인지, encoder를 fine-tuning해서 생긴 것인지, 아니면 정말 local alignment를 학습해서 생긴 것인지를 분리해서 볼 수 있기 때문입니다.
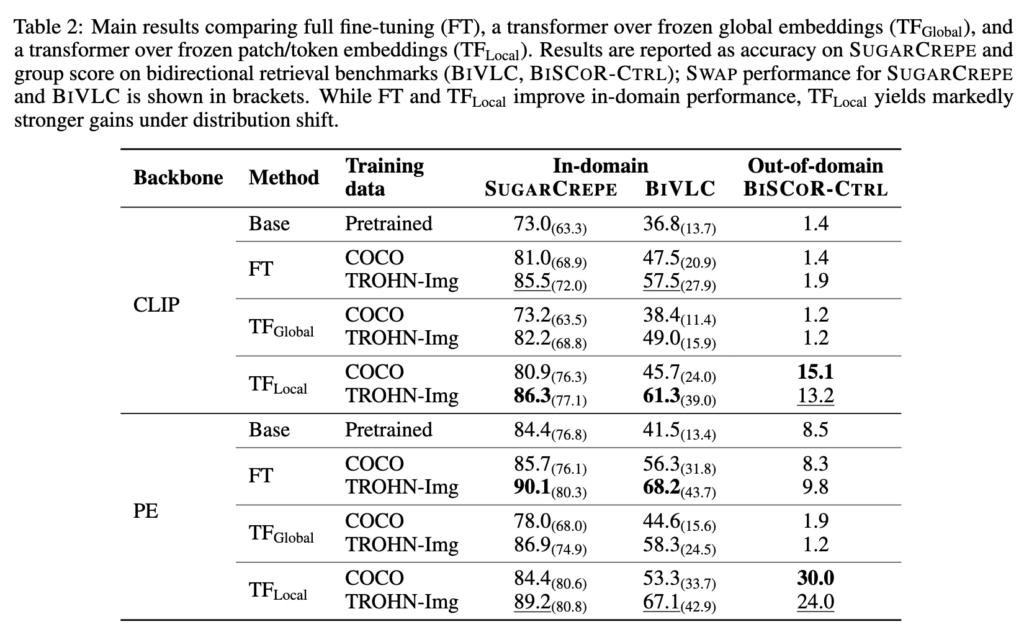
Table 2를 보면, SUGARCREPE나 BIVLC 같은 in-domain benchmark에서는 full fine-tuning도 성능을 꽤 올렸습니다. TFLocal도 비슷하거나 더 좋은 성능을 보였죠. 그런데 BISCOR-CTRL 같은 out-of-domain benchmark에서는 결과가 달랐습니다. Full fine-tuning과 TFGlobal은 거의 성능 향상이 없었지만, TFLocal은 CLIP을 1.4에서 15.1까지, PE를 8.5에서 30.0까지 크게 향상시켰습니다. 즉, 단순히 encoder를 더 학습하거나 transformer를 붙이는 것만으로는 부족했고, patch-token 수준에서 alignment를 학습하는 것이 compositional generalization에 더 중요했던 것입니다.
여기서 한 가지 더 재밌는건 hard negative 데이터의 효과인데요. TROHN-Img로 학습했을 때 in-domain 성능은 전반적으로 더 좋아졌지만, OOD인 BISCOR-CTRL에서는 COCO로 학습한 TFLocal이 더 좋은 경우도 있었습니다. 이는 hard negative를 많이 넣는 것이 항상 compositional generalization으로 이어지는 것은 아니며, 오히려 학습 데이터의 shortcut에 맞춰질 가능성도 있음을 보인다고 합니다.
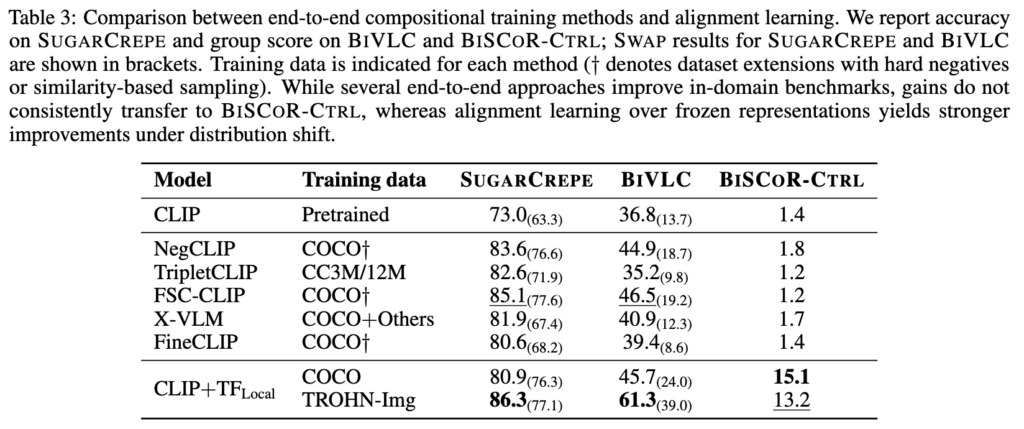
마지막으로 Table 3에서는 NegCLIP, TripletCLIP, FSC-CLIP, X-VLM, FineCLIP 같은 기존 compositional training 방법들과 비교했습니다. 이 방법들은 대부분 in-domain benchmark에서는 성능을 올렸지만, BISCOR-CTRL에서는 기존 CLIP과 거의 비슷한 수준에 머물렀습니다. 반면 TFLocal은 encoder를 frozen한 상태에서도 OOD benchmark에서 훨씬 큰 개선을 보였습니다. 결국 이 결과는 compositionality failure의 원인이 단순히 encoder 학습 부족이 아니라, global cosine similarity inference가 pretrained representation 안의 fine-grained 정보를 제대로 활용하지 못한 문제일 수 있다는 저자의 주장을 다시 뒷받침한다고 합니다.
4. Conclusion
논문은 여기까지였습니다. 마지막으로 정리해보면, 이 논문은 dual-encoder VLM의 compositionality failure를 다른 관점에서 살펴본 연구라고 볼 수 있는데요, 기존에는 CLIP 같은 모델이 compositional reasoning을 못하면, encoder가 애초에 attribute-object binding 정보를 잘 배우지 못했다고 해석하는 경우가 많았습니다. 그런데 이 논문은 그 원인이 representation 자체의 부족이 아니라, global cosine similarity 기반 inference가 fine-grained 정보를 제대로 활용하지 못하기 때문일 수 있다고 본 것이죠
다만 개인적으로는 이 논문의 분석의 깊이나 방법론적 결론은 좀 아쉽네요. 특히 이전에 리뷰한 [ICLR 2026] CLIP Behaves like a Bag-of-Words Model Cross-modally but not Uni-modally 논문과 비교하면 더욱 아쉬운데.. 두 논문 모두 “CLIP의 compositionality failure가 representation 자체의 부재가 아니라 cross-modal matching 문제일 수 있다”는 비슷한 관점에서 출발하긴 합니다.
이전 연구는 문제 분석부터 결론까지 엄청난 실험들로 인해 저를 온전히 설득시킬 수 있었느나, 이번 페이퍼는… global cosine similarity가 bottleneck이다 말고는, ‘그래서 앞으로 VLM을 어떻게 학습해야 하는가?’에 대한 결론이 없다는게… 좀 아쉽네요. 또 실험마저도 흠,,, 글쎄요,,, SGI는 사람이 정한 crop과 text segment를 사용하는 간단한 실험에 가깝고, TFLocal도 frozen patch/token embedding 위에 transformer를 얹는 후처리 방식에 가까워서….
물론 이 결과를 통해 local alignment가 중요하다는 메시지는 분명해진 것 같긴 합니다. 하지만 VLM pretraining 단계에서 어떤 objective를 써야 하는지, 어떤 supervision으로 region-token alignment를 학습해야 하는지, 기존 contrastive learning을 어떻게 바꿔야 하는지까지는 명확히 제안하지 않기에 많이 아쉬움이 남네요 리뷰 마치겠습니다
안녕하세요 주영님. 좋은 리뷰 감사합니다!
질문이 있어 댓글로 남기겠습니다.
1) 어떻게 실험을 구성한 것인지 궁금한데, Transformer를 추가하는 것이 기존의 cosine similarity 를 통해 유사도를 구하는 방식을 제거하고 대체한 것인지 궁금합니다. 또한, Global Embedding 에 Transformer를 붙히는 것이 기존의 방식이라고 하셨는데 ViT의 CLS 토큰과의 비교를 의미하고, TFLocal의 경우는 ViT의 각 patch 단위를 Transformer에 넣어서 실험한 것일까요?
2) 두번째로, CLIP의 경우, train 시에 cosine similarity를 기반으로 학습을 수행하였는데, inference시에 cosine similarity를 통해 비교하는 것에 대해 의문이 들었다면, 학습 시에도 misalignment가 있을 수도 있지 않나라는 의문이 들었습니다. 논문에서 명확한 결론이 있지 않았다는 것에 위에 대한 내용도 포함이 되는 걸까요?
확실히 명확한 방법론을 제시한 것이 아니라, 말씀하신대로 VLM을 어떤 방식으로 학습해야하는지 의문이 들었던 것 같습니다!
감사합니다!
좋은 질문 감사합니다. 질문은 크게 두 가지 같습니다
Q1. TFLocal의 Transformer는 기존 cosine similarity를 대체하는 것인가? TFGlobal과 TFLocal은 무엇을 비교한 실험인가?
-> A1. 네, TFLocal의 Transformer는 기존 cosine similarity 기반 matching을 대체하는 모듈에 가깝습니다. 기존 CLIP은 image/text의 global embedding을 cosine similarity로 비교하지만, TFLocal은 frozen encoder에서 나온 image patch embedding과 text token embedding을 Transformer에 넣고, 그 위에서 image-text matching score를 학습합니다.
TFGlobal은 patch/token을 쓰지 않고 global embedding만 Transformer에 넣은 ablation입니다. 즉, 단순히 Transformer를 추가해서 좋아진 것인지, 아니면 patch-token 수준의 local alignment를 활용해서 좋아진 것인지를 구분하기 위한 실험입니다. 결과적으로 TFLocal이 OOD benchmark에서 훨씬 좋은 성능을 보였기 때문에, 저자들은 local alignment가 중요하다고 주장한 것으로 보입니다.
Q2. Train 단계부터 cosine similarity를 썼다면, 학습 과정 자체에도 misalignment 문제가 있는 것 아닌가?
-> A2. 저도 그 가능성이 충분히 있다고 생각합니다. CLIP은 학습 단계에서도 global cosine similarity 기반 contrastive learning을 사용하기 때문에, inference뿐 아니라 training objective 자체도 fine-grained alignment를 충분히 반영하지 못했을 수 있습니다.