Abstract
CLIP이 다양한 분야에서 성공적으로 적용이 되고있으나, 기존의 CLIP은 77 token이라는 한정된 숫자의 text를 처리할 수 있으며, 디테일한 시각·언어 정보를 파악하는 데는 어려움이 있다고 알려져있습니다. 해당 논문의 저자들은 long-text를 처리하고, 디테일한 정보를 고려할 수 있도록 하기 위해 FineLIP을 제안합니다. FineLIP은 Fine-grained alignment with Longer text input within the CLIP-style framework에서 따온 약자로, positional embedding을 확장하고, local 이미지와 text tokens을 aggregation 하여 fine-grained token-to-token crossmodal alignment를 강화하는 방법론 입니다. 저자들은 zero-shot cross modal retrieval과 text-to-image generation에서 자신들의 방법론의 효과를 입증하였으며, 기존 SOTA보다 개선된 성능을 달성하였다고 합니다.
Introduction
CLIP은 4억개의 이미지-텍스트 쌍으로 이루어진 web데이터를 이용하여 공통의 임베딩 공간으로 정렬하도록 대조 학습된 모델로, 다양한 시각·언어 태스크에서 좋은 zero-shot 성능을 보이며 시각적 특징 추출에 중요한 도구로 사용되고 있습니다. 그러나 기존 CLIP은 주로 짧은 캡션을 기반으로 학습되었기 때문에, 이미지 포함된 색상, 위치, 크기, 복잡한 관계, 속성 등의 풍부한 정보를 충분히 반영하기 어렵다는 한계가 있습니다. 이에 따라 최근 사람이나 LVLM의 캡션 생성을 이용하여 더 길고 상세한 캡션을 이미지와 쌍으로 제공하는 데이터 셋들이 제안되고있으며, 이러한 흐름은 CLIP 스타일 모델에서 긴 텍스트를 효과적으로 활용하는 방식에 대한 연구가 필요함을 보여줍니다.

그러나 CLIP 모델이 더 긴 캡션을 다루기 위해서는 몇가지 제한을 해결해야합니다. 먼저, CLIP은 77개의 토큰을 처리하도록 제한되어있으며, 사전학습 데이터에 짧은 캡션을 많이 포함하여 높은 인덱스에 해당하는 positional embedding은 충분히 학습되지 않은 상태로 남아있습니다. Figure 1은 이에 대한 예시로, CLIP은 뒷부분의 정보에 대해서는 반영을 잘 하지 못하여 성능이 저하되는 것을 확인할 수 있습니다. 그러나 긴 캡션 데이터를 이용하여 사전학습된 CLIP을 학습한다면, 기존 CLIP의 alignment가 손상될 수 있으며, 4억장의 데이터로 사전학습된 CLIP의 장점을 해치게 됩니다. 이를 해결하기 위해 저자들은 사전학습된 모델의 강점을 유지하면서도 긴 캡션을 활용할 수 있는 방식을 제안하며, 이를 통해 시각-언어 정보 사이의 alignment를 유지하면서도 성능을 개선시킬 수 있었다고 합니다. (Figure 1의 FineLIP 결과 확인)
또한, 기존 CLIP의 loss는 전역적인 특징을 정렬하는 데 초점을 두기 때문에, 복잡하고 세밀한 정보를 포착하는 능력을 제한한다고 합니다. 긴 캡션은 더 풍부한 문맥 정보를 포함하며, 이미지도 global 정보 뿐만 아니라 local 정보를 포함하고 있습니다. 그러나 기존의 연구들은 여전히 global 정보에 의존합니다. Long-CLIP은 긴 캡션과 짧은 캡션에서 모두 global feature를 추출하여 visual feature와 PCA를 활용하여 학습이 이루어지며, TULIP은 하나의 global visual feature를 두 종류의 캡션과 정렬하도록 학습합니다. 이처럼, global feature에 집중하다보니 이미지와 텍스트 사이의 더 세밀한 관계를 포착하기 위한 local detail을 간과하게 된다고 합니다. 따라서 저자들은 이미지와 텍스트의 local feature를 활용하여 fine-grained, token-level cross-modal alignment를 수행하는 방식을 제안합니다.
저자들은 FineLIP이라는 새로운 Fine-grained alignment with Longer text input with the CLIP 프레임 우커르를 젱나하며, 이를 통해 이미지와 텍스트의 디테일한 정보를 활용할 수 있도록 합니다. FineLIP은 CLIP의 77개 토큰 제한을 넘어 더 긴 캡션을 이해할 수 있도록 하며, token-to-token alignment 전략을 통해 local한 시각 및 언어 정보를 충분히 활용할 수 있도록 합니다. 이를 통해 시각 모달리티와 텍스트 모달리티 사이의 fine-grained alignment 성능을 크게 개선하였으며, 세부적인 정보를 효과적으로 추출할 수 있도록 합니다.
해당 논문의 contribution을 정리하면,
- 이미지와 텍스트 사이의 fine-grained, token-level contrastive learning을 가능하게 하는 token refinement 및 alignment 방식 제안하여 CLIP의 token 제한 문제를 효과적으로 해결하고, 긴 캡션에 대한 cross-modal alignment 개선
- 다양한 데이터셋에서 FineLIP을 평가하여 SOTA보다 유의미한 성능 개선을 보임
- 광범위한 ablation study를 통해 FineLIP의 각 구성요소의 기여를 검증
Method
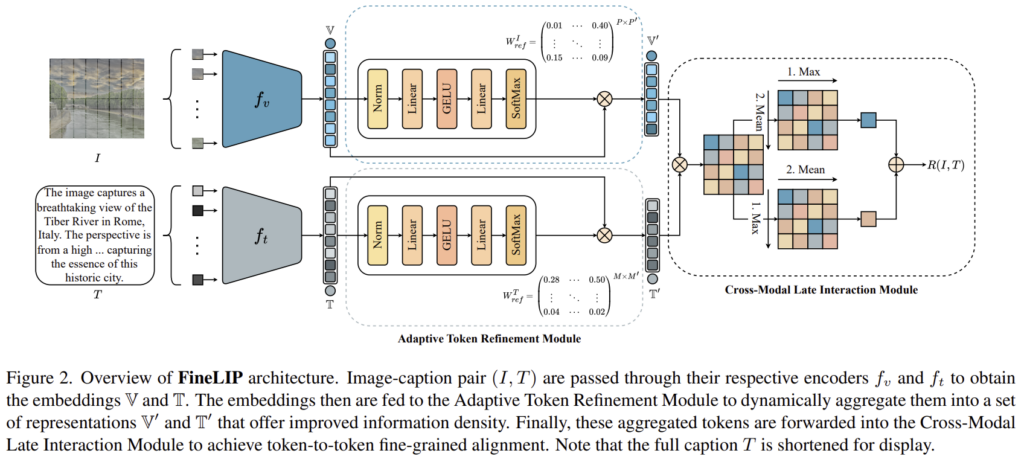
FineLIP은 먼저 positional embedding을 확장하고 사전학습된 CLIP 모델로 초기화한 뒤, 각각 처리된 이미지와 텍스트 토큰을 aggregation하여 fine-grained token-level cross-modal matching을 통해 alignment를 맞추게 됩니다. 전체적인 흐름은 위의 Figure 2에서 확인하실 수 있습니다.
[Preliminary]
이미지와 텍스트 쌍 (I,T)가 주어졌을 때, 사전학습된 CLIP의 vision encoder f_{v}( )와 text encoder f_t( )를 사용하여 visual embedding \mathbb{V}\{v_{cls},v_1,...,v_P\} \in \mathbb{R}^{(P+1)⨉d}와 textual feature \mathbb{T} =\{t_0, t_1, ... , t_{eos}, ... , t_{247}\} \in \mathbb{R}^{248⨉d}를 추출합니다. 이때 P는 패치 수를 의미하고, d는 feautre의 demension, v_{cls}는 [CLS] 토큰으로 글로벌 정보를 나타내며 v_i는 각 패치의 visual feature를 나타냅니다. 또한, t_0과 t_{eos}는 [BOS](Begin of Sentence)와 [EOS](End of Sentence) 토큰을 나타내며, 긴 텍스트를 처리하기 위해 최대 248개의 토큰으로 설정하였으며, t_0과 t_{eos} 사이의 토큰은 유효한 입력 토큰, t_{eos}이후는 padding입니다.
Stretching of Positional Embeddings
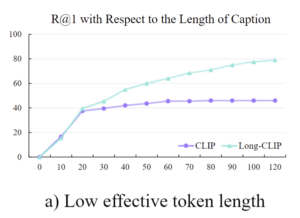
CLIP은 77개의 토큰으로 제한이 되며, 저자들은 이를 해결하기 위해 사전학습된 CLIP의 지식을 최대한 유지하면서 positional embedding을 확장하는 방식을 사용합니다. 우선 위의 그래프는 Long-CLIP에서 보인 실험으로, 실제 유효 토큰 길이는 20 토큰정도라는 것을 확인할 수 있습니다. 저자들은 이를 통해 앞의 20개의 토큰은 그대로 유지하고, 이후의 token에 대해서 adaptive interpolation방식을 적용하여 원래 길이의 4배로 확장합니다. 따라서 총 embedding 길이는 20+(77-22)⨉4=248이 되며, 긴 캡션을 충분히 인코딩할 수 있도록 합니다.
Adaptive Token Refinement Module (ATRM)
각 토큰은 그 자체로 충분한 정보를 가지지 못하므로, 완전한 이해를 위해서는 주변 토큰의 문맥이 필요합니다. CLIP 프레임워크는 이미지와 텍스트 encoder가 Transformer 기반으로 구성되므로, 토큰 표현의 모호성을 줄이기 위해서는 문맥정보를 포함하는 token refinement가 필요합니다. 기존 token refinement 분야의 일부 연구는 레이어가 깊어질수록 token간의 유사도가 증가한다는 관찰로부터, 의사결정에 중요한 일부 토큰을 선택하는 것에 집중하고 있습니다. 그러나 이러한 방식은 정보 손실을 일으키게 되므로, FineCLIP은 token을 선택하여 버리는 대신, 여러 token을 학습가능한 방식으로 aggregation하여 더 정보량이 높은 refined token 집합을 생성합니다.
visual feature \mathbb{V}와 textual feature \mathbb{T}에 대하여 표현력을 개선하기 위해 저자들은 Adaptive Token Refinement Module(ATRM)을 제안하였습니다. ATRM은 self-attention에 영감을 받아 설계되었으며, N개의 토큰을 aggregation하여 N’개의 토큰으로 변환하기 위해 aggregation matrix W_{ref} \in \mathbb{R}^{N⨉N'}, N'<N를 이용합니다. 이때, {N'} \over{N}는 aggregation ratio가 되며, \sum^{N}_{j=1}(W_{ref})_{i,j} = 1이 되도록 합니다. 즉, N’개의 토큰으로 변환할 때, N개의 토큰의 가중치가 총 1이 되는 것 입니다. 이러한 설계를 통해 end-to-end 학습이 가능하도록 하였다고 합니다. 아래의 식은 W_{ref}를 구하는 식으로, W_k와 W_q는 학습 가능한 projection matrix이며, \sigma는 비선형 함수(GELU), \tau는 temperature parameter로 얼마나 sparse하게 원본 토큰을 선택할 지 조절하는 파라미터입니다.

이미지와 텍스트 정보에 대하여 동일 구조의 서로 다른 파라미터로 구성된 별도의 브랜치로 적용됩니다. ATRM을 거쳐 visual feature \mathbb{V}는 \mathbb{V}'=\{v_{cls}, v_1', ... , v_{P'}'\}, textual feature \mathbb{T}는 \mathbb{T}' = \{t_1', ..., t_{M'}',t_{eos}\}가 되며, textual token에서 padding에 해당하던 값은 무시하게 됩니다.
Fine-Grained Cross-Modal Alignment
맥락 정보가 고려되도록 개선되 토큰들에 대하여 다음으로 시각적 요소와 텍스트 설명 사이의 alignment를 수행합니다. global한 정보들로부터 정렬을 수행하는 방식은 세부 정보 손실을 초래할 수 있으며, 저자들은 fine-grained alignment를 위해 이미지와 텍스트의 local token 사이의 복잡한 상호작용에 집중할 수 있도록 Cross-Modal Latent Interaction Module (CLIM) 을 제안합니다.
ATRM을 통해 정제된 visual token \mathbb{V}'와 textual token \mathbb{T}'에 대하여 각 토큰 사이의 cosine similarity S(v_i',t_i'1)를 구합니다. 이후 아래의 식을 통해 alignment score를 계산합니다.
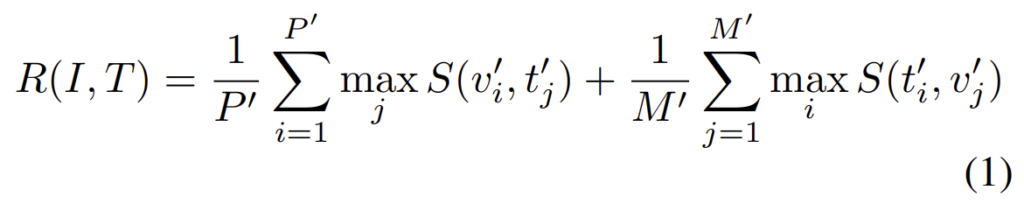
첫째 항과 둘째항은 각각 image-to-text와 text-to-image fine-grained similarity score를 의미하며, 이를 통해 이미지와 텍스트의 관계를 고려할 수 있도록 합니다.
또한, 학습시에는 Triplet Marginal Loss를 이용하여 positive 쌍과 similarity score가 negative 쌍보다 사전에 정의된 margin보다 크도록 보장하므로써, positive 쌍은 더 가깝고, negative 쌍은 더 멀어지도록 합니다. 식은 아래와 같이 정의되며, _q는 query, ^+, ^-는 각각 positive와 negative를 의미합니다.
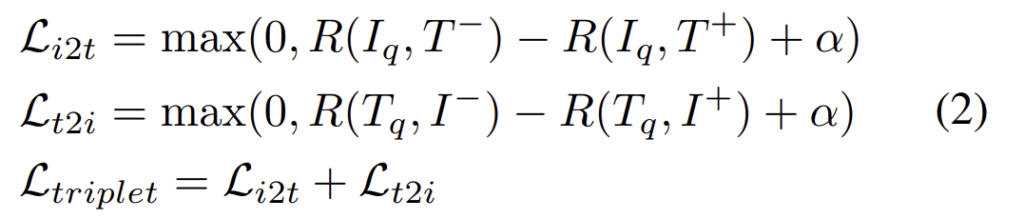
- \alpha: margin을 나타내며, 해당 논문에서는 0.2로 설정됨.
Experiments
Datasets
저자들은 120만개의 이미지-캡션 쌍으로 이루어진 ShareGPT4v 데이터를 이용하여 학습을 수행합니다. ShareGPT4V는 장면에 대한 세부 정보들로 이루어진 긴 캡션으로 구성되며 평균 143.6개의 단어로 이루어져 있습니다. 저자들은 zero-shot long caption cross-modal retrieval과 long-text-to-image generation에서 FineLIP을 평가합니다. 두 태스크 모두 길 상세한 캡션이 포함된 Urban1k와 DOCCI 데이터 셋을 이용합니다.
Results
[ Zero-shot Long Caption Cross-Modal Retrieval ]
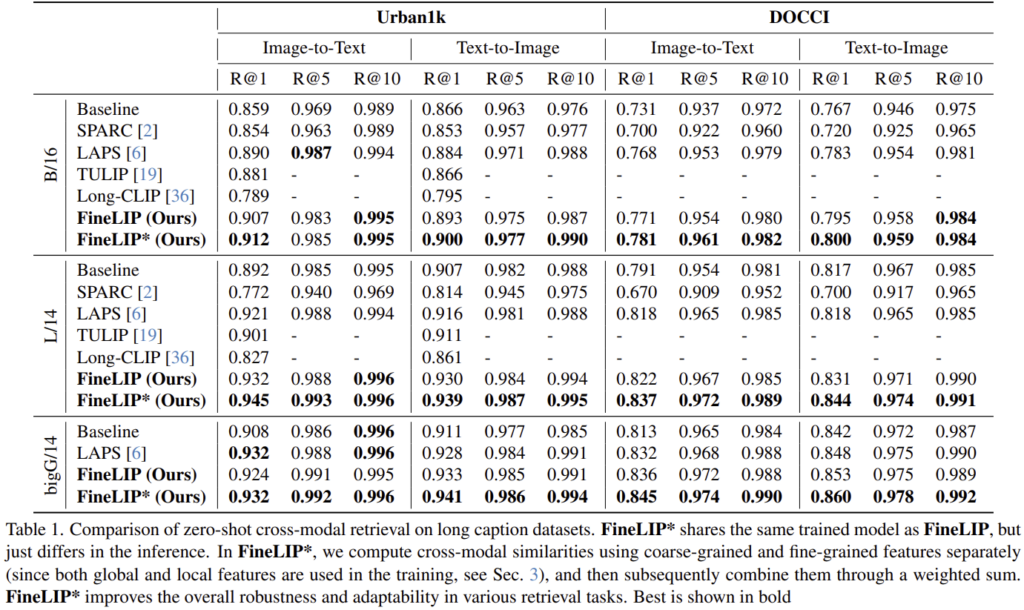
Table 1은 긴 캡션으로 구성된 Urban1k와 DOCCI에서 image-to-text(I2T)와 text-to-image(T2I)를 평가한 결과로, 대부분의 지표에서 좋은 성능을 달성하였습니다. I2T보다 T2I의 성능 향상 폭이 다소 작은 경향을 보였습니다.
[ Long-Text-to-Image Generation ]
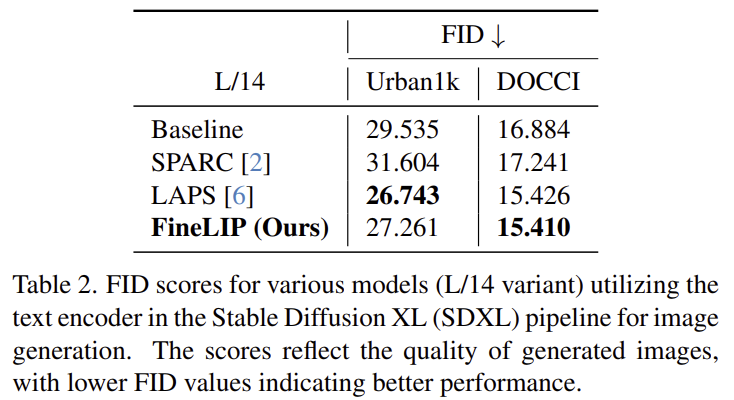
저자들은 Stable Diffusion XL, SDXL 모델을 이용하여 이미지를 생성하고, FID 평가지표를 사용합니다. Table 2는 이에 대한 실험 결과로, 저자들의 방식이 Baseline 방식에 비해 성능이 개선되었음을 어필하며, 아래의 Figure 3은 이에 대한 정성적 결과입니다.


Ablation Study
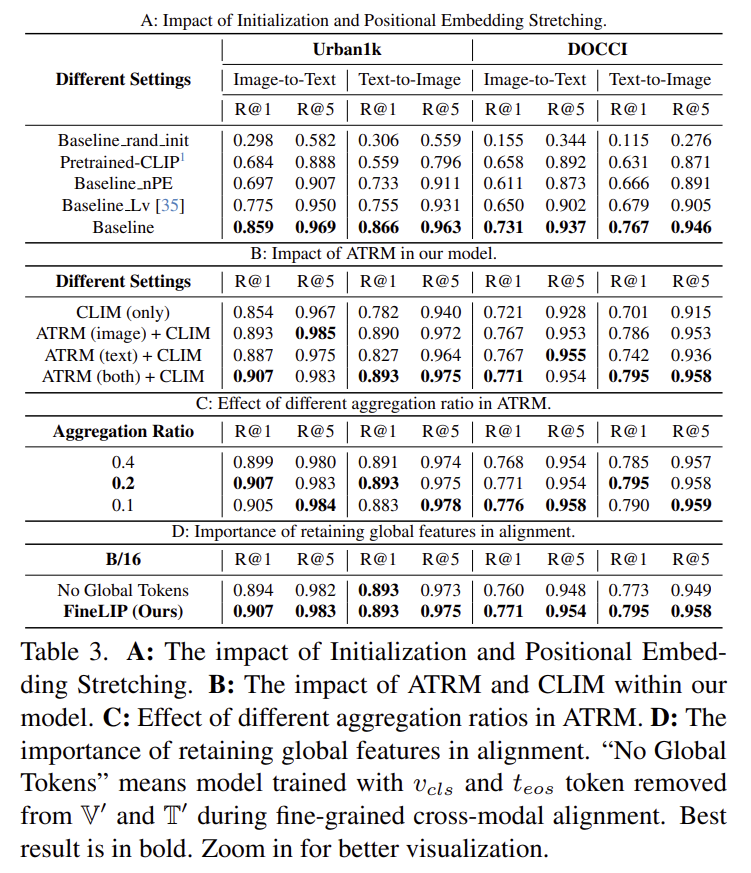
- Table 3의 A결과를 통해 긴 캡션을 처리하기 위해 CLIP을 어떻게 초기화하고 token limit을 확장할지에 대한 실험입니다. Baseline_rand_init은 token limit을 늘리고 랜덤 초기화 한 뒤 학습한 방식으로, 77개의 토큰 제한이 있는 사전학습된 CLIP이 더 좋은 성능을 보인다는 것을 확인할 수 있습니다.(1,2행) 즉, 사전학습된 지식을 활용하는 것이 중요하다는 것을 보여줍니다. 또한, Pretrained-CLIP을 긴 캡션 데이터셋에 직접 fine-tuning하는 방식(Baseline_nPE), CLIP의 vision encoder는 재사용하고 long-context text encoder를 처음부터 학습하는 방식(Baline_Lv)도 비교하였습니다. 실험 결과 사전학습된 CLIP을 유지하면서 positional embedding을 248개로 확장한 Baseline이 가장 좋은 성능을 보였습니다. 이를 통해 저자들은 긴 캡션을 효과적으로 처리하기 위해 CLIP을 활용하면서 PE를 확장하는 것이 중요하다는 것을 어필합니다.
- B 결과는 ATRM의 영향을 검증한 것으로, 이미지와 텍스트 모달리티에 모두 토큰 정제를 수행하는 것이 대체로 좋은 성능을 보인다는 것을 실험적으로 보였습니다.
- C 결과는 ATRM 과정에서 토큰 수를 변환할 때, aggregation ratio에 따른 실험 결과로, aggregation ratio를 늘리면 더 많은 token이 유지되지만, 정보의 밀도가 낮아져 성능 저하가 발생하고, 너무 aggregation ratio를 낮출 경우 토큰이 너무 압축되어 세부 정보 유지가 어렵다고 분석하였습니다. 따라서 저자들은 0.2가 가장 적절하다고 결론을 내렸습니다.
- 마지막으로 저자들은 loss를 계산할 때, aggregation 된 토큰 뿐만 아니라, [CLS]토큰과 [EOS]토큰 같은 global feature도 포함하였습니다. 이에 대한 실험 결과가 D에 해당하며, 저자들은 이를 통해 global 정보를 함께 학습하는 것이 cross-modal representation을 학습하는 데 더 도움이 된다는 것을 확인하였습니다.
리뷰 잘 읽었습니다
지난주에 Long-CLIP 기반의 페이퍼를 리뷰해주샸던거로 기억하는데, 이와 관련하여 질문이 있습니다.
본 논문에서 제안하는 FineLIP도 Long-CLIP처럼 positional embedding을 확장하는 방식으로 이해했습니다. Long-CLIP과 비교했을 때 핵심 차이는 ATRM과 CLIM을 통해 local token-level alignment를 추가했다는 점으로 이해하면 될까요? 혹시 학습 방식이나 사용한 데이터 측면에서도 차이가 있는지 궁금합니다.
댓글 감사합니다.
이해하신 바가 맞습니다. 우선, Long- CLIP도 FineLIP과 동일하게 ShareGPT4V으로 학습합니다. 두 방법론은 긴 텍스트를 처리하는 방식에 있어 초반의 20개 토큰은 유지하고 뒷부분을 활용해 더 긴 텍스트를 처리할 수 있도록 학습합니다. 다만 Long-CLIP은 PCA를 활용하여 긴 문장을 커버하고, 해당 논문의 저자들은 aggregation 방식으로 긴 문장을 처리합니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
ablation D에서 CLS, EOS 같은 global feature를 loss에 넣었을때 성능이 오르고있는데, global feature를 넣어야 성능이 좋아진다면 성능 향상의 실제 원인이 fine-grained 정렬인지 global feature 덕분인지 판단하기 어려운 것 같은데 결국 둘다 도움이 된다고 봐야할까요?
추가로 Urban1K나 DOCCI 같은 벤치마크 말고 기존의 ImageNet과 같은 벤치마크에서의 결과는 없을까요? 긴 캡션으로 구성된 벤치마크에서는 성능이 올랐는데 반대로 짧은 캡션으로 구성된 벤치마크에서는 성능이 어떻게 되는지도 궁금합니다.
감사합니다.
질문 감사합니다.
우선 global 토큰을 추가로 사용함으로써 성능 개선이 이루어지는 것은 맞지만, 앞선 실험들을 통해 fine-grained 정렬이 유의미한 성능 개선을 가져온다는 것을 보였기 때문에, 둘 다 도움이 된다고 판단하는 게 맞을 것 같습니다.
Supplementary Material에 성준님이 이야기하신 실험이 존재합니다. https://arxiv.org/pdf/2504.01916 해당 링크에서 Table 4가 이에 대한 실험 결과에 해당합니다. Flickr30k와 COCO에 대한 cross-modal retrieval 실험 결과로, I2T에서는 가장 좋은 성능을 보이지만 T2I에서는 Baseline 방식(사전학습된 CLIP을 유지하면서 positional embedding을 248개로 확장한 방식)이 더 좋은 성능을 보이고있습니다. 또한, zero-shot classification 성능도 Figure 4에 리포팅되어있는데, 실험 결과 CLIP-ViT-L/14에 비해서는 낮은 성능을 보이고 있습니다. FineLIP이 항상 좋은 결과를 보인다고 하기는 어려운 것 같습니다.
안녕하세요 승현님 리뷰 감사합니다.
ATRM이라고 하는 것이 토큰 정보량은 유지한 채 총 토큰 수만 맞춰주는 것으로 이해하면 될까요..? ATRM을 다룰 때 BOS/EOS 토큰은 사용이 안 되는 이유가 궁금합니다. 또 N’과 N의 비율이 1이 되는것도 이유가 무엇인지,, 이해가 안 돼서 조금만 풀어서 설명해주시면 감사하겠습니다!
질문 감사합니다.
ATRM는 토큰에 대하여 주변 토큰들의 정보를 주도록 하는 것이 목표입니다. A-B-C-D-E-F 형태의 토큰이 있다고하면, A~F는 패치단위로 처리되다보니 주변의 정보를 포함하지 못합니다. 저자들은 다른 토큰의 정보도 추가하여 표현력을 늘리면서 토큰 수를 줄인 a-b-c를 만들고자 한 것 입니다. 이를 위해서 a를 만들 때 A~F까지 가중치를 주어 정보를 합쳤으며 이때 가중합은 1이 되도록 합니다. 이때, N′