안녕하세요, 이번주 리뷰는 egocentric video pretraining에 대한 연구입니다. 최근 egocentric human video의 pretraining을 다루는 연구들이 늘어나고, 대부분 cam의 움직임을 노이즈로 다루는데, 오히려 해당 부분을 살리는 방향을 다룬 연구입니다. 리뷰 시작해보겠습니다.
Introduction
최근 로봇 조작 분야에서 핫한 VLA들의 일반적인 흐름은 pretrained VLM을 perception-language backbone으로 사용하고, 그 뒤에 action expert를 붙여 로봇 action을 예측하도록 학습하는 방식입니다. 하지만 이런 모델을 제대로 학습하려면 대규모 robot demonstration이 필요합니다. 늘 나오는 문제이지만 문제는 로봇 데이터가 비싸고, 수집 속도가 느리며, task diversity를 확보하기 어렵다는 점입니다.
이 지점에서 자연스럽게 등장한 대안이 human egocentric video입니다. 사람의 1인칭 영상은 로봇 데이터보다 훨씬 쉽게 수집할 수 있고, 일상적인 조작 행동을 다양하게 포함합니다. 하지만 기존 연구들에서 egocentric human video로 pretraining한 모델은 robot data로 pretraining한 모델보다 일관되게 낮은 성능을 보였다고 합니다.
저자들은 기존 연구들이 주로 사람 영상에 robot action label이 없다는 문제에 집중해 hand trajectory, hand point cloud, object motion 같은 proxy action label을 만들어 사용했지만 active perception이라는 특수한 데이터를 놓치고 있다고 합니다.
사람은 조작할 때 손만 움직이지 않고 물체를 더 잘 보기 위해 머리를 움직이고, 몸을 숙이고, 고개를 돌리는 작업을 자연스럽게 합니다. 즉, egocentric video에 나타나는 camera motion은 단순한 noise가 아니라 사람이 작업을 수행하기 위해 능동적으로 viewpoint를 조절한 데이터 입니다. 저자들은 기존 연구들이 이 camera motion을 불안정한 영상 변화나 제거해야 할 noise로 취급했지만, 이를 viewpoint action으로 취급했습니다.
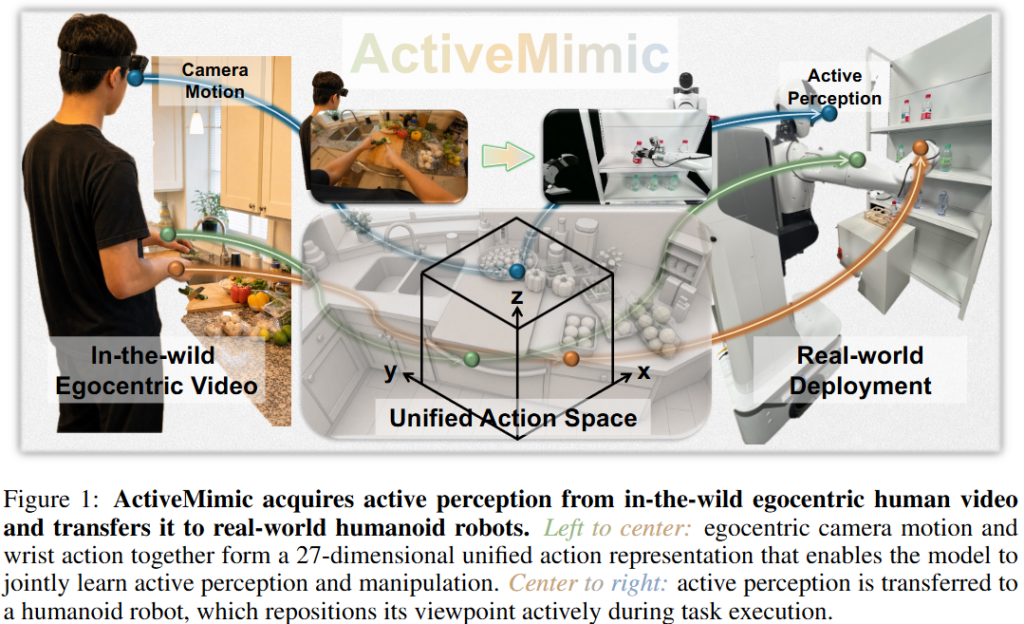
저자들의 contribution은 egocentric video에서 active perception과 manipulation을 동시에 학습할 수 있는 프레임워크를 제안하고, active perception이 egocentric pretraining의 중요한 점임과 동시에 충분히 로봇으로 transfer 될 수 있다는 것을 밝힌 점입니다.
Method
ActiveMimic의 핵심은 egocentric camera motion을 action으로 보는 것입니다. 예를 들어 선반에 물건을 넣을 때 사람은 먼저 테이블 위의 물건을 보기 위해 아래쪽을 보고, 물건을 잡은 뒤 선반의 빈 공간을 찾기 위해 고개를 들어 위쪽을 봅니다. 이때 손의 움직임만 보면 pick-and-place trajectory가 보이지만, task 성공에서의 다른 핵심은 작업 단계에 맞춰 시야를 바꾸는 행동이라고 합니다. 특히 humanoid robot이나 mobile manipulator처럼 head, waist, arm이 함께 움직이는 embodiment에서는 active perception이 조작 성공률에 큰 영향을 준다고 합니다. 따라서 저자들은 human video와 로봇 action을 통합한 unified action space를 제안합니다.
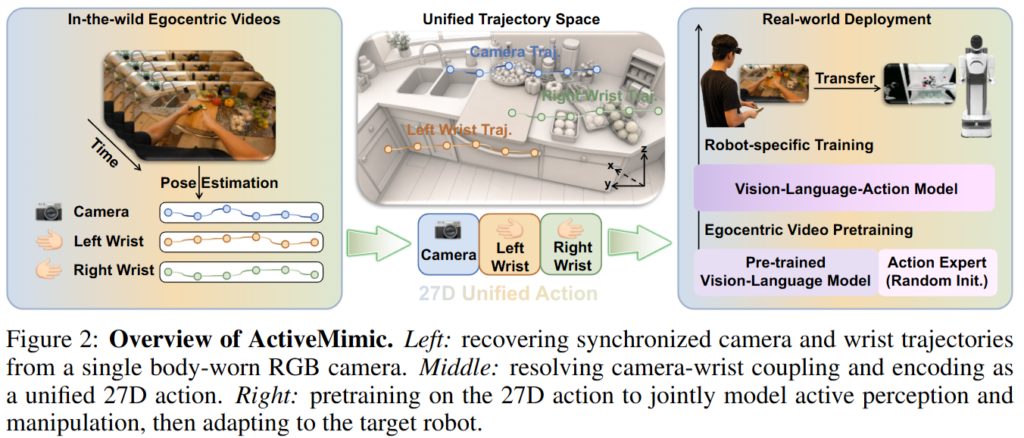
프레임워크에는 단일 body-worn RGB camera 영상만 사용합니다. 저자들은 Ego4D 데이터셋을 활용했다고 합니다. 먼저 각 episode에 대해 egocentric camera trajectory, left wrist trajectory와 right wrist trajectory를 추출합니다. 이 때 wrist pose들은 SAM-3D-Body를 사용한다고 합니다. 영상이 찍힌 camera trajectory는 VGGT를 사용해 복원합니다.
이 때 VGGT는 egocentric video의 camera path를 추정할 수 있지만, monocular reconstruction이기 때문에 metric depth를 복원하기 위해 UniDepth가 예측한 metric depth와 VGGT가 예측한 depth를 비교해 scale factor를 추정한다고 합니다. Frame별 depth ratio를 계산하고, 이를 episode-level scale로 aggregation하여 VGGT camera trajectory의 translation component에 적용해줍니다.

이후 wrist pose를 구해줍니다. 이 때 wrist pose는 보통 camera frame 기준으로 표현되기 때문에 egocentric camera 자체가 계속 움직이는 경우 frame 사이의 wrist pose 변화에는 실제 손목 움직임과 camera 움직임이 섞여 있습니다.
예를 들어 손은 가만히 있는데 사람이 고개를 돌리면, 현재 camera frame 기준 wrist pose는 변한 것처럼 보일 수 있습니다. 반대로 손과 camera가 함께 움직이면 실제 손의 움직임이 과소평가되거나 왜곡될 수 있습니다. 이 상태의 wrist pose를 그대로 action supervision으로 사용하면 모델은 손의 움직임과 camera 움직임을 분리해서 학습할 수 없게 됩니다.
따라서 저잗르은 chunk-relative reference frame을 기준으로 정의합니다. Policy는 보통 학습, 예측할 때 전체 episode를 한 번에 예측하는 것이 아니라 fixed-length chunk 단위로 action을 예측합니다. 따라서 각 chunk의 첫 frame camera coordinate를 기준 좌표계로 삼고, 해당 chunk 안의 모든 camera pose와 wrist pose를 이 동일한 기준 frame으로 다시 표현해줍니다.
이러면 camera pose는 chunk 시작 시점 대비 viewpoint가 어떻게 이동했는지를 나타내고, wrist pose는 같은 기준 frame 안에서 양손이 어떻게 움직였는지를 나타냅니다. 이렇게 되면 camera action과 wrist action이 같은 spatial reference frame 기준으로 표현됩니다. 저자들이 pose estimation 이후 추정된 pose들을 로봇 학습에 사용할 수 있는 unified action supervision으로 정리했다는 점이 핵심이라고 보시면 될 것 같스빈다.
이후 각 pose를 3D Translation vector로, 6D rotation vector를 사용해 9D action representation으로 나타냅니다. Camera pose가 9D, left wrist pose가 9D, right wrist pose가 9D여서 최종 action vector는 27D입니다. 왜인진 모르겠으나 저자들이 27D라는 표현을 논문에서 자주 언급합니다,, 허허. Action은 앞으로 손이 어떻게 움직이는가와 더불어 앞으로 시야가 어떻게 움직이는가를 함께 표현합니다. 전체적인 모델은 Qwen3 3B 모델을 VLM 백본으로 사용하고 뒤에 0.6B의 action expert를 사용해 flow matching objective로 학습합니다. 모델 자체는 기존 VLA와 다를 것 없습니다.
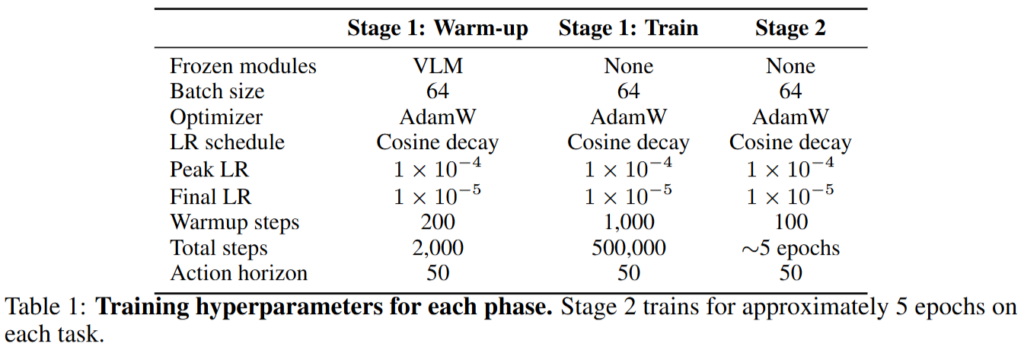
Training은 egocentric human video pretraining을 통해서 egocentric observation과 language instruction을 입력받아 chunk-relative camera-wrist action을 예측하도록 학습됩니다. stage1에서는 warm up때 action expert만 먼저 학습해 초기화된 모델을 좀 잡아주고 이후 pretraining 단계에서 다 열고 학습해 모델이 사람이 작업 중 시야와 손을 어떻게 함께 움직이는지 학습합니다.
이후 단계에서는 pretraining된 전체 모델을 target robot data로 fine-tuning합니다. 이때 action target은 robot action입니다. Robot-specific training에서 앞서 학습한 cam과 wrist의 움직임을 로봇의 camera, head, waist, arm action에 전이합니다.
Experiments
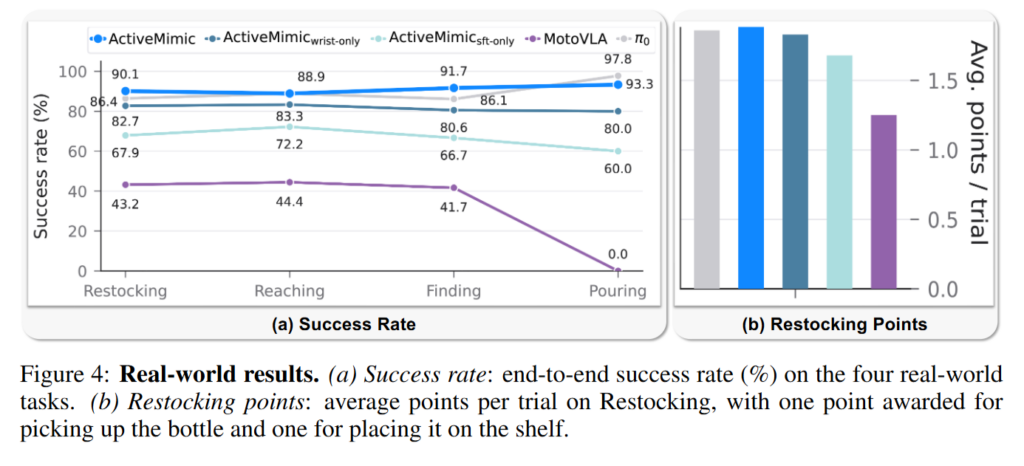
실험은 AGIBOT-G1 로봇을 활용해 real world task로 진행됐습니다. Task는 Restocking, Reaching, Finding, Pouring입니다. Baseline은 pi0, motoVLA(human pretrain VLA), ours(wrist only), ours(robot training only)로 구성돼있습니다.
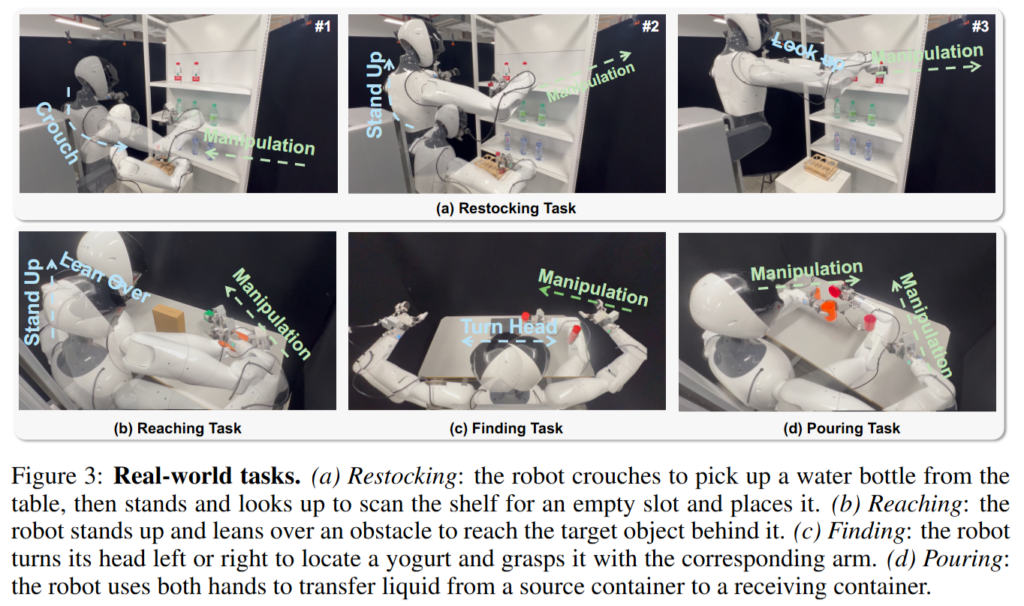
Figure 4를 보면 ActiveMimic이 모든 task에서 human-video-pretrained baseline과 robot-specific training baseline보다 좋은 성능을 보여줍니다. Wrist-only variant보다 full ActiveMimic이 더 좋은 성능인 것을 보면 단순히 Ego4D video를 사용했다는것 외에 camera motion supervision이 중요한 것을 볼 수 있습니다.
다음은 label fidelity에 대한 평가입니다. 저자들의 파이프라인이 얼마나 유효한 labeling을 할 수 있는지를 기존 egocentric dataset인 HOT3D로 평가했습니다. Figure 5를 보면 vision-only 방식으로 얻은 trajectory가 완벽한 motion capture 수준은 아니지만, pretraining signal로 사용할 수 있을 정도의 구조를 담고 있다고 합니다. 전반적인 움직임 경향이 GT스러운 것을 볼 수 있습니다.

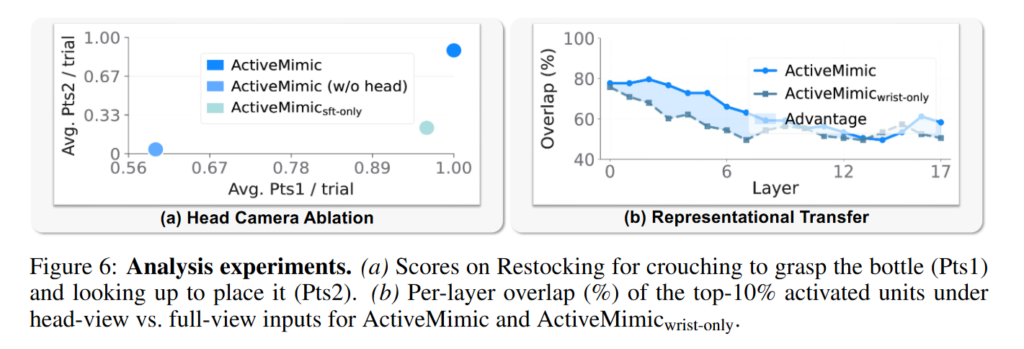
다음으로 저자들은 active perception capability가 정말 egocentric pretraining에서 온 것인지 확인하기 위해 Restocking task에서 head camera ablation을 진행했습니다. Figure 6를 보면 물체를 집는 단계 (가로축)에서는 로봇 데이터만 사용한 경우 어느 정도 수행할 수 있지만 선반을 보고 적절한 위치에 배치하는 단계 (세로축) 에서 성능 차이가 나는것을 볼 수 있습니다. Representational transfer을 봐도 ActiveMimic이 wrist-only variant보다 더 높은 overlap을 보입니다. Camera motion을 pretraining때 supervision 하는것이 human egocentric view와 robot observation 사이의 modality shift를 줄이고, perception representation이 더 안정적으로 전이되는 것을 볼 수 있습니다.
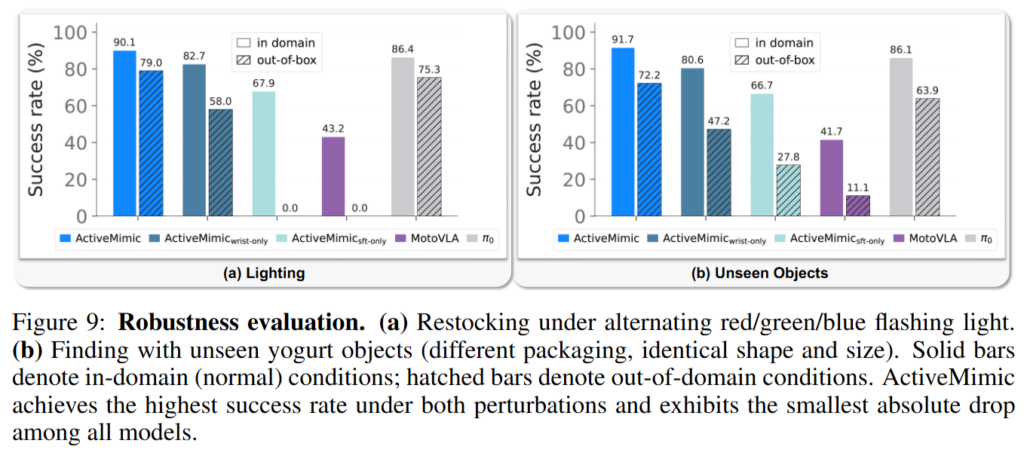
아래 Figure 8,9를 보면 lighting을 변화해주는 실험과 unseen object를 사용하는 Robustness 실험에서도 success rate를 지킬 수 있었다고 합니다. 이 또한 시야를 학습한 결과인 것인지.. 조금 의아하긴 하지만 실험 결과를 보면 더 높은 성공률과 더불어 낮은 하락을 볼 수 있습니다. Human pretraining이 없는 경우 성공률이 0퍼센트가 되는데, pretraining 데이터를 살펴봐야 할 것 같긴 합니다.

안녕하세요 영규님 좋은 리뷰 감사합니다.
제가 이해를 잘 못한거 같은데.. ego human video에서는 camera trajectory가 사람의 head motion인데 로봇에서는 이게 head joint command랑 연결되는건지 궁금합니다. camera trajectory가 로봇의 active perception action으로 어떻게 매핑되는지랑 pretrain할 때는 27d camera wrist action을 예측하고 파인튜닝때에는 robot action을 예측한다고 했는데 둘은 다른 아예 다른 action 값인건지도 궁금합니다.
감사합니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
해당 분야의 논문은 처음 읽어 용어 관련한 질문이 많은데요. egocentric video란 camera가 고정된 view를 가지는 것이 아니라, 한 task를 동작하기 위해서 camera view가 계속해서 바뀌는 video라고 이해해도 되는 걸까요? 또한, introduction 부분에서 말씀하신 “기존 연구들에서 egocentric human video로 pretraining한 모델은 robot data로 pretraining한 모델보다 일관되게 낮은 성능을 보였다고 합니다.”부분에서 robot data는 robot이 수집한 데이터를 말하는 걸까요? 아니면 camera-view가 고정된 data를 말하는 걸까요?
그리고 추가로 궁금한 점이 해당 방법론의 경우, egocentric video로 학습이 됐는데, 그럼에도 불구하고 robot data를 사용해도 working할 수 있는지 궁금합니다. (egocentric video만 사용가능한 방법론인건지 궁금)
감사합니다.
안녕하세요 영규님 좋은 리뷰감사합니다
간단하게 궁금한것이 생겨 질문 드립니다..
혹시 head가 움직일텐데 그런 부분에대한 처리는 어떻게 되는지 궁금합니다. 상대적으로 머리와 팔의 관계로 푸는건가요 ?
감사합니다
영규님 좋은 리뷰 감사합니다.
active perception이라는, 작업시 주변을 더 잘 인식하기 위한 사람의 움직임을 활용하고자 한 컨셉이 흥미롭습니다.
chunk로 나누어 손과 고개의 상대 좌표를 표현하는 것이 손과 고개의 움직임을 분리할 수 있도록 하는 것으로 이해하였는데 맞을까요? 맞다면, 이러한 chunk로 나누어 표현한 것이 해결책이 될 수 있다는 게 잘 이해가 가지 않아 설명 부탁드립니다. (chunk로 나누지 않아도 상대적 이동을 표현하면 되는 게 아닌가요?)
또한, 이런 고개 움직임이 유의미한지 확인하기 위해서는 평가 작업이 장기 작업이여야 할 것 같습니다. 실험 파트에 있는 restocking, reaching, finding, pouring은 일련의 작업인가요?
안녕하세요 영규님, 좋은 리뷰 감사합니다.
1. 데이터셋의 Ego-view 카메라는 안경인가요?
2. pre-training 된 VLM에서 다음 Robot data 로 fine-tuning할 때, VLM에서 뱉은 27D의 cam pose를 condition으로 받는건가요? 추정된 pose를 supervision으로 활용했다길래요! 아니면 VGGT에서 27D cam pose 뱉는 head를 걍 떼버리나 싶기도 하구요. 이쪽부분이 어떻게 처리되는지 궁금합니다.
3. 각 chunk의 첫 frame camera coordinate를 기준 좌표계로 삼는다고 언급이 되어있는데, 이거 각 chunk라는 말이 각 cam 의 chunk라는 것인가요?
안녕하세요, 영규님. 좋은 리뷰 잘 읽었습니다.
human egocentric view는 의도를 가지고 움직이기도 하고 자연스럽게 목적에 따라 무의식적으로 움직이기도 할 것 같습니다. 몸의 전반적인 움직임에 따라 view가 많이 달라질 것 같은데, 로봇의 허리, 목, 다리 등이 사람과 비슷하게 움직이도록 설계가 된 것일까요?
안녕하세요 영규님 좋은 리뷰 감사합니다.
간단한 질문 남깁니다!
experiments에 비교 대상으로 사용된 model에서 pi0는 저자들이 제시한 방법과 비교했을 때 거의 유사한 성능을 보인 것 같습니다. 2026년 논문인데 pi0 말고 pi0.5 등등 후속 연구와 비교를 왜 수행하지 않았을까요?
감사합니다!
안녕하세요 영규님, 좋은 리뷰 감사합니다!
작업을 잘 수행하기 위해서 사람처럼 egocentric camera를 움직일 수 있으면 이상적이겠다고 생각한 적이 있는데 그 가능성을 보여주는 논문인 것 같아 신기하네요.
제가 잘 이해하지 못한 부분인 것 같은데, chunk 시작 프레임에서 장면의 움직임 등을 통해 head pose의 변화를 계산하고, 이 변화를 가정한 뒤 wrist pose의 변화를 계산하는 것인가요? 동일한 좌표계로 표현하는 과정이 잘 이해가 가지 않아 질문드립니다.
감사합니다!