안녕하세요. 최근에 부쩍 HRI(Human Robot Interaction)에 관심이 많아져 이런 저런 논문을 찾아보고 있는데요. 마침 재밌는 논문을 찾아 읽어보게 되었습니다. 사람과 로봇이 상호작용할 때 로봇이 어떤 행동을 하는지 그 의도를 전달하자는 논문인데요. 그럼 시작하겠습니다.
1. Introduction
로봇이 점점 발전하고 상용화되면서 로봇이 사람과 물리적으로 직접 상호작용하는 상황이 점점 많아지고 있는데요. 대표적으로 목욕이나 식사, 옷 입히기 같은 보조하는 시나리오를 예시로 들 수 있을 것 같습니다. 이런 상황에서 로봇이 자율적으로 동작하는 경우 사용자에게는 애매하게 보일 수 있는데요. 예를 들어서, 로봇 팔이 내 팔 쪽으로 다가오는게 닦으려는 것인지, 멈추려는 것인지, 잡으려는 것인지를 모르면 사용자는 의도를 모르니 불안해질 수 있죠.
기존 로봇 개발자 같이 전문가는 궤적을 시각화하는 등의 전문가용 인터페이스를 통해서 로봇이 계획한 궤적을 해석하는데요. 그런데 이런 인터페이스는 일반 사용자에게는 어렵게 다가옵니다. 그래서 저자는 자연어가 처음 로봇을 쓰는 사용자도 바로 이해할 수 있는 방식이라고 봤는데요.
여기서 자연어로 로봇의 의도를 전달하는 CoRI(Communication of Robot Intent)를 제안합니다. CoRI가 전달하려는 정보는 3가지 인데요.
1. Overall intention
-> 로봇이 달성하려는 task-level goal을 전달합니다. 예를 들어서 “수건으로 팔을 부드럽게 닦으려 합니다”를 들 수 있을 것 같습니다
2. all aspects of motion
-> 궤적의 시작 위치, 끝 위치, 모양, 속도 변화, 힘 변화를 전달합니다. 단순히 숫자로 3 cm/s라고 전달하기 보다는 가까워 질수록 느려진다와 같이 사람이 이해하기 쉬운 설명을 만들어 소통합니다.
3. user cooperation
-> 로봇이 성공적으로 assitive task를 수행하기 위해서는 사용자의 협조를 받아야할때가 있는데요. 예를 들어서 식사를 보조할 때 입을 열어주세요와 같이 말할 수 있습니다.
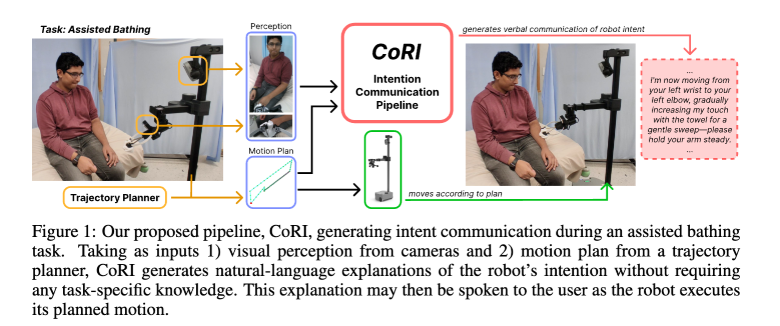
Figure 1은 목욕 보조하는 것을 예시로 보여주는데요. 로봇이 perception으로 카메라 이미지를 얻고, trajectory planner로 motion plan을 받습니다. CoRL은 이 둘을 합쳐서 intent communication을 만듭니다.
본 논문의 contribution을 정리하면 아래와 같습니다.
1. CoRI는 task-agnostic하고 robot-agnostic한 파이프라인으로 물리적 상호작용 중 로봇의 의도를 사람에게 자연어로 전달함
2. CoRI는 계획된 동작과 동역학 정보, 즉, 위치, 속도, 힘을 이미지에 임베딩하는 연산을 설계함. VLM은 해당 visual representaion을 보고 task-specific information 없이도 로봇의 의도를 해석함
3. 16명의 user study, 3개의 물리적 assitive task, 2개의 로봇 플랫폼을 통해 CoRI가 scripted baseline이나 no-communication baseline보다 사용자의 이해를 높였음을 확인함
2. Problem Statement and Assuptions
먼저, 본 방법론이 풀고자 하는 문제는 다음과 같습니다. 어떤 임의의 로봇이 physically assitive task를 수행하기 위한 동작을 가지고 있을 때, 그 동작을 바탕으로 사용자 지향 자연어 기반의 intent communication을 생성하는 것입니다.
여기서 가정할 것이 있는데, 사람이 로봇의 관찰 안에 있다는 것입니다. 왜냐하면 이 연구가 다루는 planning한 동작은 사람과의 상호작용을 포함하고 있기 때문입니다. 이를 기반으로 CoRI가 communication을 만들 때 사용할 수 있는 정보는 딱 2가지인데요.
첫째, image observation $o$ 입니다. $o$는 로봇 카메라가 본 RGB image인데요. 이동 로봇의 머리 장착형 카메라일 수도 있고, 고정형 로봇 팔을 보는 고정 카메라일 수도 있습니다. 로봇이 도구를 잡고 있고, environment image 만으로 도구가 잘 보이지 않으면 손목 카메라 이미지 $o_w$를 추가로 사용할 수 있다고 합니다.
둘때, trajectory $\tau = \{x_i : x_i = (t_i, p_i, g_i, v_i, f_i)\}_{i=1}^{N}$입니다. 여기서 $x_i$는 $i$번째 waypoint를 의미합니다. $t_i \in \mathbb{R}^{+}$는 timestamp, $p_i \in \mathbb{R}^{3}$는 robot base frame(에서 본 end-effector Cartesian position을 의미합니다. $g_i \in \{0,1\}$는 그리퍼가 open인지 closed인지 나타내는 상태를 의미하고, $v_i \in \mathbb{R}^{+}$는 속도 크기, $f_i \in \mathbb{R}^{+}$는 end-effector가 적용하려는 힘의 크기를 나타냅니다.
여기서 추가로 저자는 카메라 가시성을 가정 하는데요. 바로, trajectory가 실행된다면 로봇의 end-effector가 motion의 대부분 동안 카메라에 잡혀야한다는 것입니다. end-effector가 처음에 살짝 화면 밖에 있을 수는 있지만, 핵심 동작은 image frame 안에 있어야 한다고 합니다.
3. Method
CoRI 파이프라인은 크게 두 stage로 구성됩니다. 첫 번째 stage는 trajectory를 image observation $o$ 위에 visual encoding하는 것입니다. 이때 동역학 정보인 위치, 속도, 힘을 함께 표시하고, interaction event를 기준으로 trajectory를 나눕니다. 두 번째 stage는 VLM과 reasoning LLM을 이용해 최종적인 communication을 만드는 것입니다.
3.1 Interaction-based Trajectory Encoding
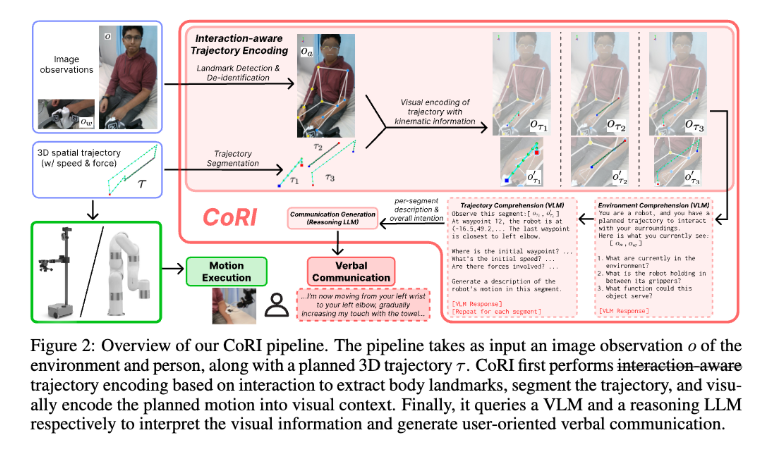
Body Landmark Detection and De-identification
CoRI는 image observation $o$ 안에 사람을 포함한다고 가정하기 때문에 먼저 미디어파이프를 사용해 body pose recognition을 수행합니다. 여기서 body landmark는 손목, 팔꿈치, 어깨, 입처럼 사람 몸에서 중요한 지점을 포함합니다.
그 다음 프라이버시를 보호하기 위해 얼굴 영역를 블러처리합니다. 이후에 검출된 body landmarks를 이미지에 표시합니다. Figure 2의 위 가운데를 보시면 이를 확인하실 수 있는데요. 앞으로 해당 annotated image를 $o_a$라고 부르겠습니다.
Trajectory Segmentation
CoRI는 trajectory를 한 문장으로 통째로 설명하지 않는데요. 사람이 이해하기 쉽게 interaction event를 기준으로 segment로 나눕니다. segmentation 기준은 세 가지인데요.
1. gripper가 open에서 closed로 바뀌거나, closed에서 open로 바뀌는 경우입니다. 이런 경우는 “물체 잡기”와 같은 의도를 나타낼 수 있습니다.
2. end-effector에 힘이 나타나는 경우입니다. 로봇이 사람이나 환경과 접촉하는 것을 계획하고 있음을 나타낼 수 있습니다.
3. 로봇의 end-effector가 2초보다 길게 정지하는 경우입니다. user action을 기다리는 상황일 수 있기 때문입니다.
저자는 segmentation index의 ordered set을 $I \subset \{1,\ldots,N-1\}$로 두고, 다음처럼 정의합니다.
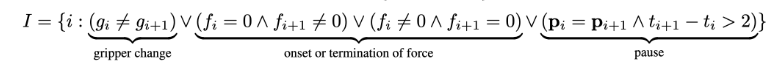
이 수식에서 $\lor$는 논리합, $\land$는 논리곱을 의미합니다. $i$번째 waypoint와 $i+1$번째 waypoint 사이에서 다음 중 하나라도 일어나면 그 지점을 자른다는 의미인데요. gripper 상태가 바뀌거나, 힘이 0에서 0이 아닌 값으로 시작되거나, 힘이 0이 아닌 값에서 0으로 끝나거나, 위치 $p_i$와 $p_{i+1}$가 같은데 시간 차이 $t_{i+1}-t_i$가 2초보다 크면 segment를 나눕니다.
만약 $I = \{i_k\}_{k=1}^{K}$라면, segment들은 다음과 같이 표현되는데요.
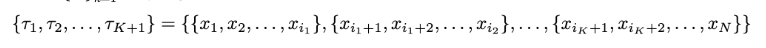
즉 원래 하나의 긴 trajectory $\tau$를 의미 있는 작은 trajectory segment $\tau_1, \tau_2, \ldots$로 나누는 것입니다.
이 segmentation의 장점은 최종 communication도 segment마다 한 문장씩 만들 수 있다는 점인데요. 예를 들어 첫 문장은 “손목 쪽으로 다가갑니다”, 둘째 문장은 “팔꿈치 쪽으로 닦습니다”, 셋째 문장은 “이제 접촉 없이 물러납니다”처럼 나누어 말할 수 있습니다.
Visual Representation of Planned Trajectory
CoRI는 3차원 직교좌표 trajectory를 VLM이 이해할 수 있도록 이미지 위에 올리는데요. 구체적으로 말씀드리면, 각 trajectory segment $\tau_i$의 waypoint를 annotated image $o_a$의 pixel space로 투영합니다.
논문에서는 기본 image를 흰색으로 옅게 만든 버전으로 만든 뒤, 그 위에 waypoint를 겹쳐 표시하는데요. 이렇게 하면 실제 image와 trajectory overlay가 서로 잘 구분된다고 합니다. 그리고 segment의 starting waypoint를 빨간색의 사각형으로, ending waypoint를 파란색의 사각형로 설정하였다고 합니다.
각 segment의 overlay image를 $o_{\tau_i}$라고 부르는데요. 하지만 trajectory overlay가 image의 아주 작은 부분만 차지할 수 있기 때문에, 해당 trajectory segment 주변만 잘라낸 cropped version $o’_{\tau_i}$도 만듭니다. full overlay image $o_{\tau_i}$는 사람과 환경 전체에서 trajectory가 어디에 있는지 알려주고, cropped overlay image $o’_{\tau_i}$는 segment 자체의 모양, 속도, 힘을 자세히 보게 해줍니다.
3.2 Language-model Querying
이후에는 segmented 되고 시각적으로 인코딩된 trajectory를 VLM에 넣고, 마지막에는 reasoning LLM으로 자연어 communication을 만듭니다. 논문에서는 VLM으로 GPT-4o를 사용하고, reasoning LLM으로 o3-mini를 사용했다고 합니다. fine-tunning은 따로 하지 않았다고 하네요.
Environment Comprehension Stage
environment comprehension stage에서는 VLM에 annotated image $o_a$를 보여줍니다. 필요한 경우 wrist camera image $o_w$도 함께 보여줍니다. 이 단계에서 VLM은 “현재 environment에 무엇이 있는가?”를 설명하게 됩니다.
Trajectory Comprehension Stage
trajectory comprehension stage에서는 각 trajectory segment $\tau_k$마다 VLM에 두개의 image를 제공합니다. 하나는 full overlay image $o_{\tau_k}$이고, 다른 하나는 cropped overlay image $o’_{\tau_k}$입니다. 여기에 trajectory segment의 numerical information, 가장 가까운 body landmarks도 텍스트로 함께 넣습니다.
이때 VLM은 위치, 속도, 힘을 각각 묻는 간단한 질문에 답변하는데요. 예를 들어 “시작 waypoint는 어디에 있는가?”, “끝 waypoint는 어느 body landmark에 가까운가?”와 같은 질문에 답변하게 됩니다.
속도에 대해서는 두 배보다 큰 차이를 눈에 띄는 변화로 보는데요. 즉 속도가 절반 이하로 줄면 slowdown, 두 배 이상 늘면 speedup으로 설명합니다. 힘에 대해서는 nonzero force가 있을 때만 로봇이 외부 object나 사람과 접촉한다고 해석합니다.
마지막 segment에서는 VLM에 전체 trajectory의 overall intention를 묻습니다. 또한 각 segment에서 user cooperation이 필요한지도 묻게 됩니다.
이 stage가 끝나면 CoRI는 4 종류의 text output인 environment summary, per-segment summary, overall intention, desired user cooperation를 얻게 됩니다.
Communication Generation Stage
communication generation stage에서는 앞 단계의 text output을 reasoning LLM에 넣습니다. reasoning LLM은 사용자 지향의 intent communication을 만들게 됩니다. 해당 문장을 만들때는 일반 대중도 이해할 수 있고 전문용어는 피하도록 명시하여 만든다고 합니다.
CoRI는 trajectory segment마다 한 문장씩 출력하는데요. 각 문장은 overall intention, motion aspect, desired user behavior를 적절히 섞어 음성으로 출력하여 사용자에게 들려준다고 합니다.
4. Experiments
논문은 CoRI가 robot intent를 효과적으로 전달하는지, 그리고 서로 다른 로봇 형태에도 적용되는지 확인하기 위해 세 가지 physically assistive task 설계하였는데요. 이후 user study를 통해 참가자의 주관적 평가를 수집하였습니다.
4.1 Tasks and Robotic Systems
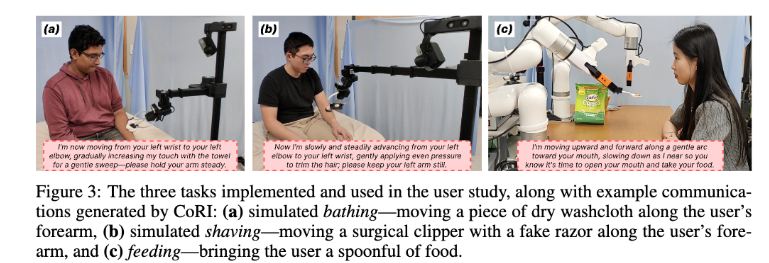
실험에는 두개의 robot setup이 사용되었는데요.
첫 번째 robot setup은 Stretch 3 로봇입니다. Stretch 3는 single-arm mobile manipulator인데요. 이 로봇으로 두개의 task를 수행하였습니다.
하나는 모의 목욕인데요. 로봇이 마른 수건 조각을 사용자 팔 위로 움직입니다. 다른 하나는 모의 면도입니다. 로봇이 수술용 clipper의 면도날을 3D 프린트된 플라스틱 면도기 머리로 교체한 도구를 잡고, 사용자 팔 위를 여러 패턴으로 움직입니다.
두 번째 robot setup은 xArm 7으로, 테이블에 장착된 7 degree-of-freedom manipulator입니다. 이 로봇은 식사 보조 task를 수행했는데요. 로봇이 숟가락에 음식물을 담아 사용자 입 쪽으로 이동합니다. Figure 3를 통해 예를 확인할 수 있습니다.
4.2 User Study
user study는 16명의 participant로 진행되었는데요.
communication strategy는 세 가지로 구성됩니다.
1. CoRI method
: CoRI가 생성한 문장을 음성으로 들려줍니다.
2. baseline scripted communication
: trajectory segment의 끝에 가장 가까운 body landmark를 찾아 “`I’m moving towards your <LANDMARK NAME>.`”라고 말합니다. 즉, “당신의 손목 쪽으로 움직입니다”처럼 정해진 template에 landmark만 넣는 방식이라고 보시면 되겠습니다.
3. no communication
: 로봇이 아무 설명 없이 움직이게 됩니다.
각 시행 뒤에는 참가자는 1점부터 7점까지의 다음과 같은 Likert 문항에 응답하였는데요. 7점은 strongly agree, 1점은 strongly disagree를 의미합니다. 문항은 다음 6개로 구성됩니다.
– L1. I felt confident predicting the robot’s next action.
– L2. I understood what the robot was going to do.
– L3. The robot’s actions matched its communications.
– L4. The robot correctly communicated its intentions.
– L5. The robot’s communications fully captured its actions in all notable aspects.
– L6. The robot clearly communicated what I should do in the interaction.
5.Results and Discussion
5.1 Likert Item Responses
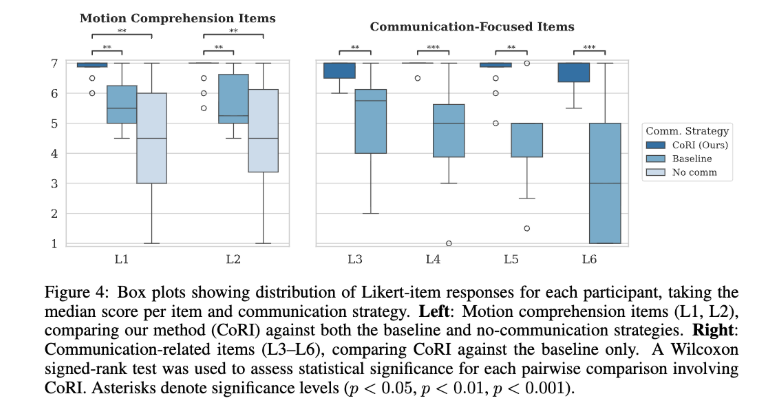
Figure 4는 box plot으로 설문 결과를 보여주는데요. 왼쪽은 L1과 L2 motion comprehension item, 오른쪽은 L3부터 L6까지 communication-focused item을 나타냅니다.
L1과 L2는 CoRI를 scripted baseline, no-communication strategy와 비교하였고, L3부터 L6까지는 no-communication strategy에는 적용하기 어렵기 때문에 scripted baseline과만 비교하였다고 합니다.
결과는 모든 비교에서 통계적으로 유의미한 차이를 보였는데요. L1과 L2에서 CoRI는 scripted baseline과 no-communication baseline보다 높은 평가를 받았다고 합니다. CoRI의 점수는 7점에 가깝게 모였고, baseline들은 더 낮았다고 합니다.
L3부터 L6까지에서도 CoRI는 scripted baseline보다 높은 중앙값 점수를 받았다고 합니다. 이를 통해CoRI가 성공적으로 “왜 움직이고, 사용자는 무엇을 해야 하는가”까지 설명하는 데 있음을 보여준 것을 알 수 있습니다.
5.2 Entailment within Ground Truth
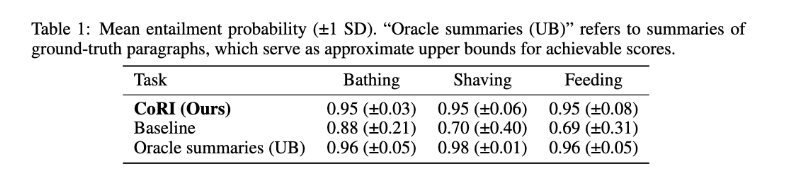
Likert 문항은 참가자의 주관적 평가을 보는 방식인데요. 논문은 여기에 더해, CoRI-generated 문장이 ground-truth paragraph에 얼마나 잘 포함되는지도 평가하였습니다. 여기서 ground-truth paragraph는 trajectory planner의 intent, motion, dynamics feature, possible collaborative user action을 모두 담은 긴 설명을 의미합니다.
Table 1을 통해 해당 결과를 확인할 수 있습니다. CoRI가 3개의 task 모두에서 0.95의 높은 수치를 보였고, 오랔클 요약이랑 거의 비슷한 수치를 보이는 것을 확인할 수 있습니다. 즉 CoRI는 image와 planned trajectory(만으로도 로봇 의도를 비교적 정확하게 추론하고, ground-truth paragraph에 가까운 communication을 생성했음을 알 수 있습니다.
이상으로 리뷰를 마쳐보겠습니다. 로봇과 사람이 소통하는 과정에서 로봇의 의도를 전달할 필요가 있음을 느낄 수 있었던 논문이었습니다. 읽어주셔서 감사합니다.
안녕하세요 주연님 좋은 리뷰 감사합니다.
읽다가 문득 궁금한 점이 생각나 질문드리는데, HRI 분야인만큼 로봇과 사람의 상호작용에 초점을 맞춘다면 충분히 필요한 연구를 진행한 것 같습니다. 사실 로봇이 이러한 인간과의 상호작용에서 고려해야할 점이 많아 단순 노동작업용 로봇보다 갈 길이 멀다고 생각할 수 있겠지만, 궁극적으로는 어떠한 상황에서도 로봇이 스스로 어떠한 일을하는지, 어떤 목적인지에 대한 communication이 가능해야 한다는 관점에서 저자의 방법처럼 휴리스틱해보이는? 가령 그리퍼의 상태나, 외부 force에 대한 것이나 segment를 나누는 기준이 휴리스틱해진다면, 다양한 일을 해야하는 로봇의 경우 대화를 생성해야 하는 부분을 rule based 만으로는 구현하기 어려울 것이라 생각합니다. 이러한 측면에서 주연님이 어떻게 생각하시는지 궁금합니다.
감사합니다.
안녕하세요. 인택님, 댓글 감사합니다.
저도 비슷하게 생각하는데요. 지금은 사람이 이해하기 쉽게 interaction event를 기준으로 rule-base로 분리하였는데, 앞으로는 더 많은 기준들이 생기고, rule-base로 하기 힘든 애매한 기준들도 생길 것이라 생각이 듭니다. 다만 제 생각에는 결국에는 interaction event를 기준으로 segment를 나눌 것이고, 추후에는 interaction event만을 segment하는 모델을 사용하지 않을까 싶기도 합니다. 이 부분은 생각할 부분이 많은 것이 빠르게 segment 해야 뒷단에서 latency가 길어지지 않기 때문에 제 생각에는 가장 좋은 방법은 많은 case를 생각하여 rule을 촘촘히 만드는 것이 아닐까 싶기도 하네요.
감사합니다.