Abstract
CLIP은 두드러지는 객체에 대한 단순한 설명을 인코딩하도록 학습되었으며, 이로 인해 복잡한 장면이나 밀도 높은 description에 대해서는 이미지와 텍스트 사이의 정력이 잘 맞지 않는 문제가 발생한다고 합니다. 최근 소규모의 long-caption을 이용하여 CLIP을 fine-tuning 하여 이를 완화하고자 하는 연구들이 등장하였으며, 해당 논문의 저자들은 이러한 연구들에서 검토하여 공동적인 편향 문제를 발견하였습니다. 저자들은 사람과 LLM이 생성한 캡션은 대체로 한 문장 짜리 요약으로 시작하고, 그 뒤에 자세한 설명이 이어지는 구조로 이루어져 있으며, 이러한 구조가 학습 과정에서 shortcut으로 작용하였다고 주장합니다.
이를 해결하기 위해 저자들은 DeBias-CLIP을 제안합니다. 이는 학습 시 요약 문장을 제거하고, 문장 단위의 샘플링과 토큰 padding을 적용하여 모든 토큰 위치에 supervision이 고르게 분포하도록 만드는 것 입니다. 실험을 통해 long-text retireval에서 SOTA를 달성하였으며, short-text retreival 성능도 개선할 수 있었다고 합니다. 또한, 문장 순서에 덜 민감하게 동작한다는 것을 실험적으로 확인하였습니다.
Introduction
CLIP 인코더는 이미지와 텍스트를 공동의 space로 임베딩하도록 학습되었으며, 이때 학습 데이터가 주로 짧은 캡션으로 이루어져 있어, 이미지 전체의 복잡한 관계와 긴 설명보다는 눈에 두드러진 객체와 텍스트 초반부에 민감하게 반응하는 경향이 있습니다. 또한, 기존 CLIP은 77개의 토큰으로 제한되어있으므로 문단 수준의 긴 설명을 처리하기는 어려움이 있습니다.
최근 이를 해결하기 위해 짧은 캡션 대신 정제된 긴 캡션으로이루어진 비교적 적은 규모의 데이터(적다고 해도 수백만장으로 구성.. 수백억보다는 적다는 의미입니다..)로 CLIP 인코더나 VLM을 학습하여 성능을 개선하기 위한 연구들이 이루어졌습니다. 또 다른 접근으로 Long-CLIP은 positional embedding을 확장하고, 사전학습된 CLIP 모델을 소규모 long-caption 데이터로 fine-tuning하여 토큰 길이를 확장하고자 하였으며, 그 결과 문단 수준의 텍스트에 대한 retirevla 성능이 향상되었다고 합니다.
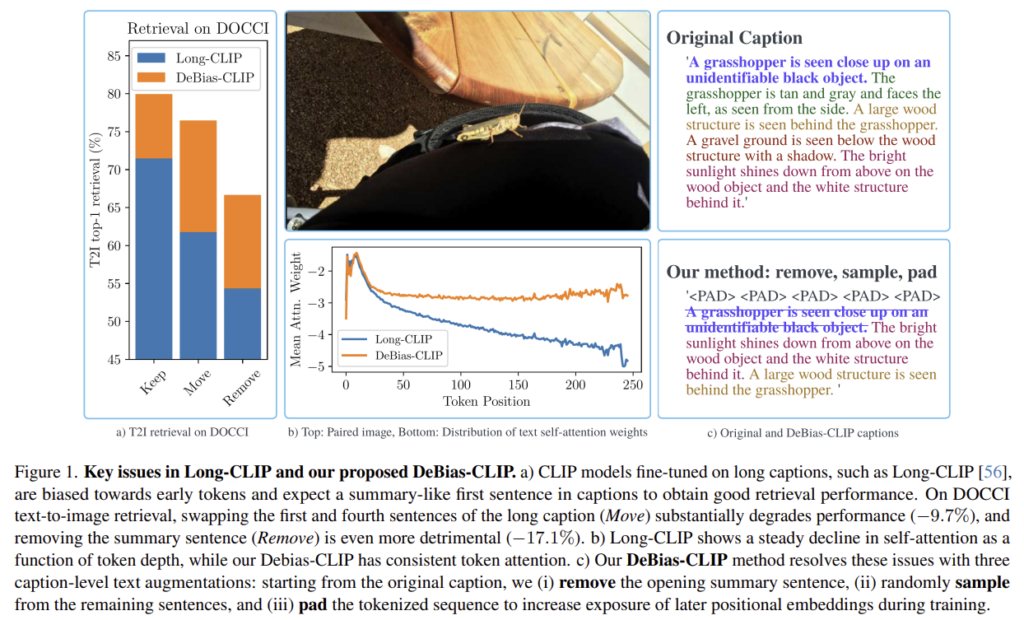
그러나, 이러한 연구들이 이루어졌음에도, 위의 Figure 1과 같이 표준 Lng-CLIP 모델은 캡션 문장의 순서를 섞거나, 첫 문장을 제거하였을 때 성능 저하가 발생합니다. 이러한 현상에 대하여 저자들은 CLIP과 CLIP 변형 모델들이 공통적으로 보이는 early-token bias와 일관된 현상으로 보았으며, 이는 CLIP 모델이 첫 문장에 맞추어 학습이 되는 경향이 있기 때문으로 보았습니다. long-caption 데이터 셋의 첫 문장은 주로 전체 텍스트를 요약하는 역할을 합니다. 그러나 기존의 CLIP은 대부분 짧은 텍스트로 학습된 모델로, 긴 캡션이 주어지더라도 첫 문장에 집중하여 학습이 될 수 있으며, 그 결과 뒷부분의 토큰에 대한 민감도가 감소하여, 문맥 파악 능력을 확장하려는 목적에 반대가 됩니다.
이를 해결하기 위해 저자들은 DeBias-CLIP을 제안합니다. DeBias-CLIP은 긴 캡션을 샘플링하는 방식을 다르게 하여 이러한 편향을 완화하며, Long-CLIP에서 그대로 바꿔 사용할 수 있으며 학습 파라미터를 추가하지 않습니다. 이를 통해 long-text retrieval에서 SOTA를 달성하였고, short-text retireval에서도 성능 개선을 이루었다고 합니다. 또한, 문장의 순서가 섞이고, 요약 문장이 사라지더라도 retireval이 잘 동작할 수 있었다고 합니다.
해당 논문의 contribution을 정리하면
- 기존의 CLIP 모델과 CLIP 변형 모델들이 긴 캡션 데이터에서 나타나는 early token bias 문제를 실험적으로 확인하였으며, 정보가 캡션 뒤로 이동할 수록 성능 저하가 이루어짐을 발견함.
- early token bias를 완화하기 위해 캡션 문장을 샘플링하고, padding 토큰을 추가하는 간단한 augmentation 전략을 통해 새로운 학습 파라미터 추가 없이, CLIP을 긴 문맥에 적용할 수 있도록 함.
- long-text retieval에서 SOTA를 달성하였으며, 문장 순서가 바뀌거나 요약 문장이 없는 경우에도 잘 동작할 수 있음을 실험적으로 보임
Empirical Anlaysis of CLIP Biases
저자들은 CLIP과 CLIP 변형 모델들이 long-text retireval에서 어떻게 동작하는 지에 대하여 실험적으로 분석합니다. 먼저, long-text retireval 데이터셋에서 학습과 평가에 영향을 주는 공통 요소에 대하여 검토한 뒤, 사전학습된 CLIP 모델이 긴 문단 전체를 이해하지 못하는 제한된 effective context window를 가지고 있으며, 주로 굵게 표시된 객체 토큰과 전체 내용을 요약하는 문장에 편향되어있음을 실험적으로 보입니다. 또한, long-text로 fine-tuning한 뒤에도 이러한 편향이 해결되지 않는다는 것을 실험적으로 보입니다.
Text Retrieval Datasets
Long-CLIP의 방식을 따라서 저자들은 ShareGPT4V 데이터 셋으로 학습한 뒤, long-text retrieval 벤치마크인 Urban1k, DCI, Long-DCI, DOCCI 4가지와 short-text retrieval 벤치마크인 COCO와 Flickr30k에 대하여 평가를 수행합니다. 각 데이터에 대한 정보는 Table 1에 정리되어있습니다.

먼저, 저자들은 short-text retrieval 데이터셋의 토큰 길이가 CLIP의 토큰 제한인 77개와 SigLIP의 64개보다 적다는 점을 지적합니다. 또한, long-text retrieval 데이터가 유사한 형식으로 이루어졌다는 점을 강조합니다. 대체로 첫 문장이 전체를 요약하는 문장으로 시작되며, 세부적인 설명이 뒤에 이어지는 summary first sentence 구조를 가지고 있으며 평균 토큰 수도 유사합니다. 실제 image-text retrieval 상황에서는 첫 문장에 요약 정보가 들어가지 않을 수 있으며, 첫 문장에 요약된 정보로 인해 사실상 짧은 캡션으로 학습하는 것과 비슷한 효과를 주어 early token bias가 long-context 상황에서도 유지될 수 있습니다.
Biases in CLIP Text Encoders
실험에는 OpenAI CLIP 학습 데이터로 학습된 CLIP, LAION-2B로 학습된 OpenCLIP, Google의 SigLIP/SigLIP2 을 사용하였습니다. 학습 데이터는이미지와 단일 문장 캡션 쌍이 대부분이며, 저자들은 여러 문장으로 구성된 long-caption 데이터 셋을 사용하여 모델의 텍스트 인코더의 early-token bias를 확인하고, 내용이 요약된 첫 문장에 민감하게 반응한다는 것을 보입니다.
[ Early-Token Bias ]

실험을 위해 저자들은 DOCCI 캡션의 첫 두 문장을 이용합니다. 두 문장은 평균 46.6 토큰으로, 모델의 context window에 충분히 들어가는 길이입니다. 토큰 위치에 대한 민감도 실험을 위해 무의미한 문장인 "This is a photo"를 캡션 앞에 여러개 추가하는 방식으로 padding을 주어 유의미한 토큰을 뒤로 미루었다고 합니다. Figure 2는 이에 대한 실험 결과로, 앞쪽에 padding을 추가함으로써 retrieval 성능이 저하된다는 것을 확인할 수 있습니다. 특히, SigLIP 시리즈의 경우 성능 저하가 크게 발생하였으며, 단순히 토큰 수가 문제가 아니라고 주장합니다.
[ Sensitivity to Sentence Permutation ]
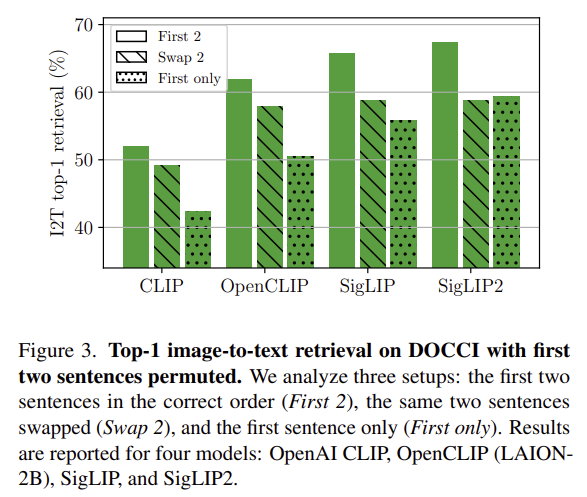
다음으로, 저자들은 DOCCI 캡션의 첫 두 문장의 순서를 바꾸는 방식으로 토큰 위치에 대한 민감도를 평가합니다. 두 문장이 올바른 순서로 있는 경우(First 2), 두 문장의 순서를 바꾼 경우(Swap 2), 첫 문장만 사용한 경우(First only) 3가지 케이스로 나누어 실험을 진행합니다. 위의 Figure 3이 이에 대한 결과로, 두 문장의 순서를 바꾸는 것이 요약 문장을 뒤쪽으로 밀어내게 되어 성능이 감소하는 것을 확인할 수 있습니다. SigLIP2는 가장 큰 성능 하락을 보였으며, 올바른 순서로 사용하는 경우와 첫 문장만 사용할 경우 short retireval 성능이 좋은 모델들이 DOCCI에서도 좋은 성능을 보이는 경향을 확인하였습니다. 그러나, 문장 순서를 바꿀 경우 이러한 경향성이 깨지며, SigLIP 시리즈에서 성능 저하가 크게 나타납니다. 이를 통해 저자들은 SigLIP 계열이 토큰 위치에 민감하다는 것을 확인하였으며, 두번째 문장이 추가적인 정보를 제공하더라도 요약 문장이 뒤로 밀려날 경우 그 장점이 상쇄될 수 있다는 것을 확인하였습니다.
[ Effects on Long-Text CLIP Variants ]
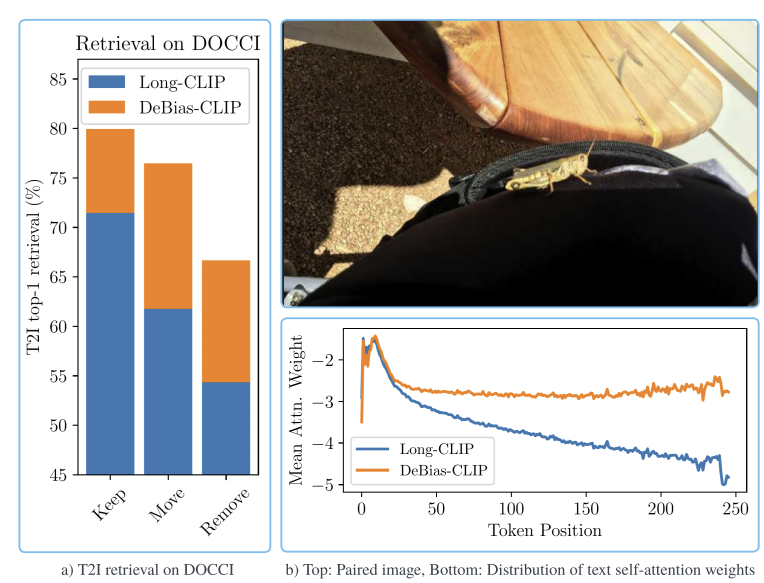
마지막으로 CLIP의 편향이 long-context 모델에서도 종재하는 지 평가하기 위해 Long-CLIP에 대하여 실험을 진행합니다. 위의 그림에서 a) 그래프는 문장 위치에 따른 실혐 결과로, 첫 문장과 네번째 문장의 위치를 바꾸거나(Move), 첫번째 문장을 아예 제거하는 경우(Remove) 성능이 크게 저하됩니다. 이는 모델이 요약 정보가 위치하는 앞의 토큰에 있는 경우에만 이를 잘 활용할 수 있으며, retrieval 성능에 큰 영향을 주는 것이 첫 문장의 요약문이라는 점을 의미합니다. 즉, Long-CLIP이 긴 문장을 처리하게 제안되었음에도, 여전히 전체 긴 맥락을 고려하지 못한다는 것을 의미합니다.
또한, b) 그래프는 transformer의 마지막 layer에서 출력 token이 다른 text token위치에 얼마나 attention을 두는 지를 표현한 것으로, Long-CLIP은 앞부분 토큰에 집중하고 10개 이후부터 점차 감소하는 경향이 있다는 것을 확인할 수 있습니다.
Method
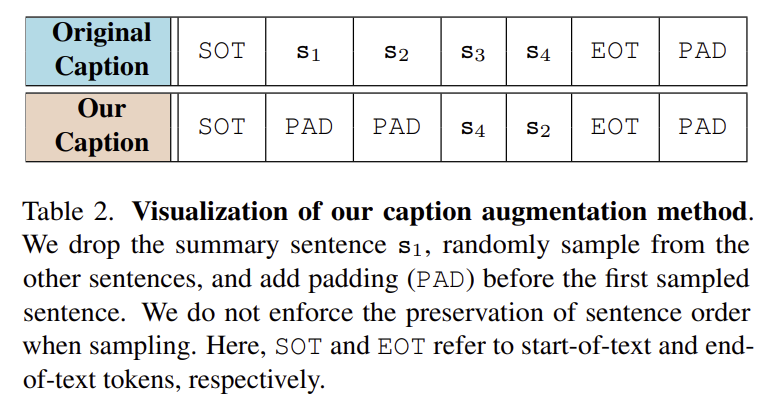
저자들은 앞선 실험을 통해 확인한 summary sentence shortcut을 완화하기 위해 ‘요약 문장 제거, 남은 long- cpation에서 무작위 샘플링, text sequence 앞에 padding 추가’ 3가지의 caption-level training augmentation 방식을 제안합니다. augmentation 방식은 위의 Table 2로 확인할 수 있으며, 그 외의 학습 방식은 Long-CLIP을 그대로 따릅니다.
[ Problem Definition ]
저자들은 캡션을 여러개의 문장이 이어진 집합으로 가정합니다. 각 문장은 여러 의미있는 semantic concept을 맏고있으며, 각 문장은 독립적인 단위로 보았습니다. k개의 문장으로 이루어진 long-caption C = [s_1, s_2, ... , s_k]는 tokenizer \varphi를 통해 token sequence T = [SOT, t_1, t_2, ..., t_k, EOT, PAD]로 변환됩니다. 이때, SOT는 시작 토큰, EOT는 종료 토큰,PAD는 padding 토큰입니다.
Long-CLIP 학습시에는 짧은 캡션(긴 캡션의 첫 문장만)C^{\mathcal{S}}_{LC}과 긴 캡션 C^{\mathcal{l}}_{LC}, 이미지를 모두 feature vector u^{\mathcal{S}}, u^{\mathcal{l}}, v로 인코딩한 뒤, 각각에 대해 contrastive loss를 계산하여 학습을 수행합니다.
[ 1. Replacing the Summary Sentence ]
DeBias-CLIP의 핵심 전략으로, 요약 문장을 제거합니다. Long-CLIP이 학습에 사용한 ShareGPT4V와 같은 long-caption은 대부분 첫 문장이 요약문으로, 요약 문장만으로도 이미지와 텍스트를 쉽게 맞출 수 있습니다. 저자들은 DOCCI에서 Long-CLIP의 image-caption similarity를 비교하였을 때, 전체 캡션을 사용하였을 때 0.308이였으며, 첫 문장만을 사용하였을 때 0.320으로 positive 쌍의 평균 유사도가 더 높다는 것을 확인하였습니다. 따라서, 긴 캡션에서 첫 문장을 제거하고 두번째 문장부터 마지막 문장까지 집중하도록 새로운 short caption C^{no-sum}=[s_2, ... , s_k]를 정의하였습니다.
[ 2. Sentence Sampling ]
긴 캡션과 C^{no-sum} 사이의 차이를 더 크게 하고, 모델이 텍스트와 이미지 전반의 세부 정보에 민감하도록 하기 위해 저자들은 C^{no-sum} 안의 문장을 sub-sapmling 하여 새로운 short captionC^{sam}을 만듭니다. 이는 새로 작성하는 방식보다 낮은 비용으로 더 다양한 캡션을 만들 수 있다는 장점이 있습니다. 샘플링 되는 문장 수는 무작위로 결정되며, 문장의 순서도 무작위로 결정됩니다. 이를 통해 모델이 특정 문장 위치나 순서에 의존하지 않고 다양한 위치의 세부 정보를 활용할 수 있도록 합니다.
[ 3. Token Padding ]
앞선 샘플링 방식은 항상 성능 개선을 이루지는 못하였으며, 저자들은 원인으로 positional embedding의 학습이 불균형하기 때문이라고 추정하였습니다. 문장 샘플링을 하면 전체 캡션이 짧아지는 경우가 많으며, 그렇게 되면 실제 정보들이 앞부분에 배치가 되므로 다시 early token bias가 발생할 수 있습니다. 따라서 이를 해결하기 위해 저자들은 tokenized sample caption의 시작 부분에 임의의 개수만큼 padding token을 추가합니다. 이를 통해 실제 텍스트의 위치를 조금 더 뒤로 미루며, SOT 토큰 뒤와 EOT 토큰 뒤에 각각 PAD_{pre}, PAD_{post} 토큰을 추가합니다. (두 토큰의 개수는 임의로 결정)
[ 4. Multi-caption Training ]
저자들은 첫 문장을 제거한 long caption과 augmentation이 적용된 short caption을 사용하여 contrastive loss로 학습을 수행합니다.
Experiments and Results
학습은 ShareGPT4V 데이터를 사용하며, long-text retrieval 성능은 Urban1k, DCI, DOCCI 데이터 셋으로 평가하며, 모델이 긴 캡션에만 특화되어 short-text retrieval 성능을 잃는지 확인하기 위해 COCO와 Flickr30k에서도 평가를 수행합니다. 기본적으로 Long-CLIP의 학습 방식과 동일하며, 단순히 캡션 구성 방식만을 바꾼 것 입니다.
Long-Text Retrieval
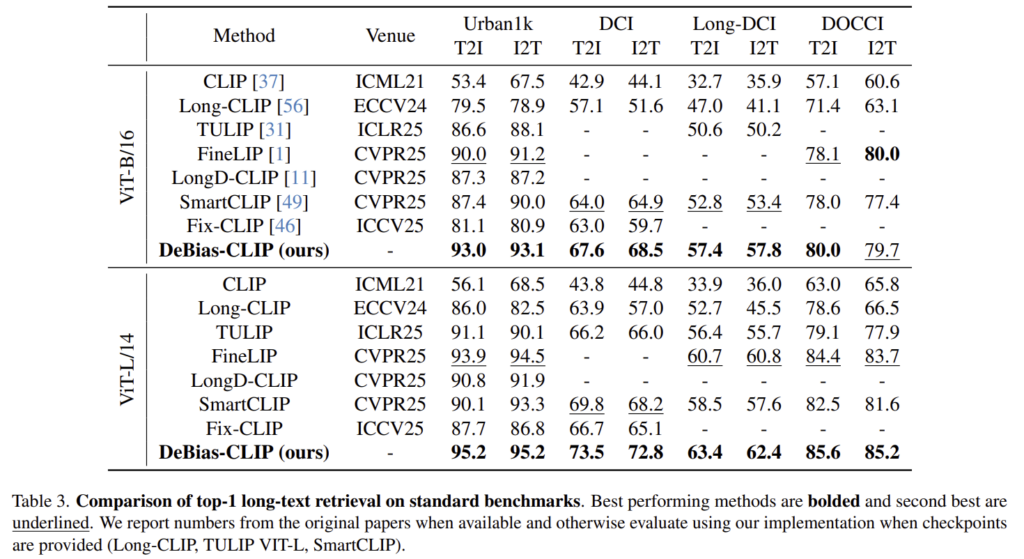
Table 3은 long-text retrieval 방식의 SOTA 방법론들과 비교한 실험 결과입니다. 대부분 DeBias-CLIP이 가장 좋은 성능을 달성하였으며, Long-CLIP 방식에서 캡션 구성만 수정하였음에도 대부분의 task에서 10% 이상의 성능 개선이 이루어졌습니다.
Short-Text Retrieval
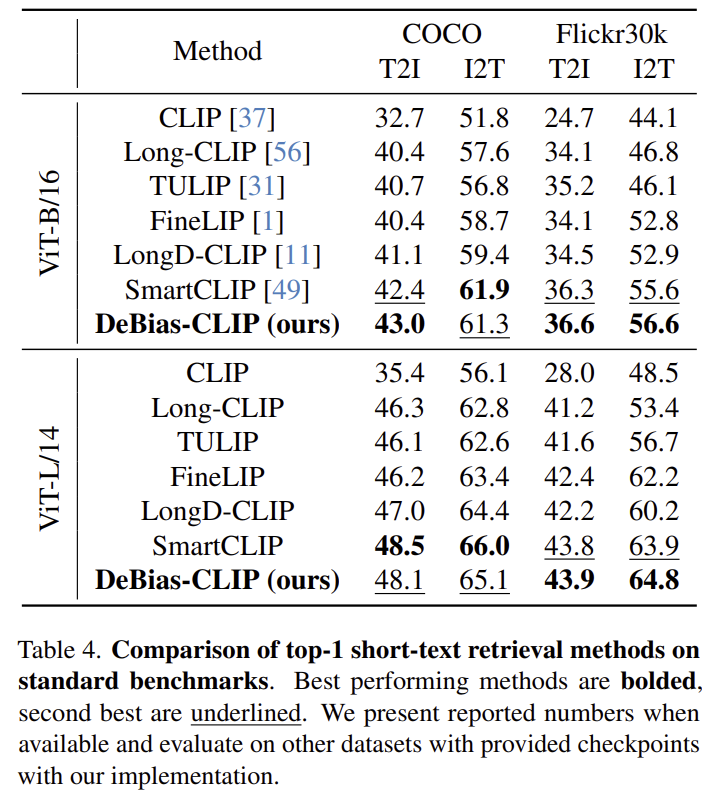
short-text retrieval 에서도 베이스라인인 Long-CLIP에서 일관된 성능 개선이 이루어진 것을 확인할 수 있습니다. Flicker 데이터에서는 DeBias-CLIP이 가장 좋은 성능을 보였으나, COCO에서는 SmartCLIP이 더 좋은 성능을 보이기도 합니다. 이에 대해 저자들은 long-text retrieval과 short-text retrieval 사이의 trade-off가 있을 수 있다고 보고 ablation 실험에서 추가로 분석을 수행하였습니다.
Generalization to other CLIP-Style Encoders
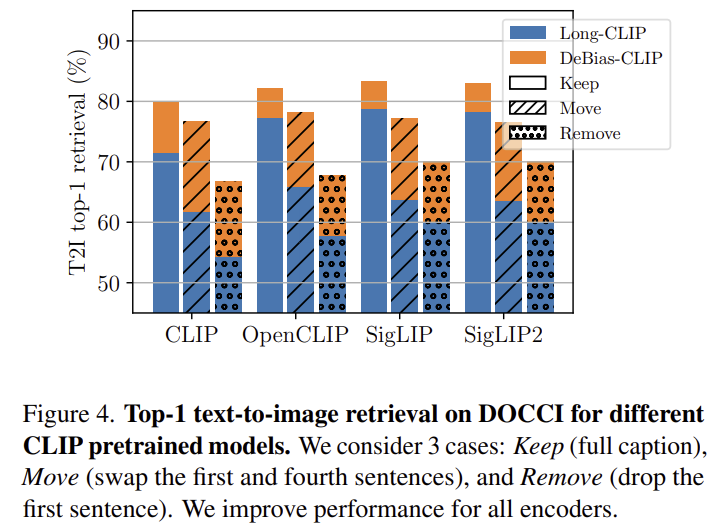
해당 실험은 DeBias-CLIP이 OpenAI CLIP에만 잘 맞는 방법인지, 아니면 다른 CLIP-style encoder에도 적용 가능한지를 확인하기 위한 것으로, OpenCLIP, SigLIP, SigLIP2에 동일한 방식으로 캡션을 샘플링하였다고 합니다. Figure 4는 이에 대한 실험 결과로, 서로 다른 데이터 분포와 학습 loss 등의 차이가 있음에도 전체적으로 성능 개선이 이루어지는 것을 확인할 수 있습니다.
Robustness to Text Permutations
또한, 저자들은 문장 순서 변화나 요약 문장을 제거한 경우에도 강인하게 동작하는 지에 대하여 검토하였습니다. Figure 4의 대각선 줄무늬와 점은 각각 요약 문장을 뒤로 옮기거나 제거한 실험으로, Long-CLIP은 첫 문장을 뒤로 미뤘을 때 성능이 크게 저하되는 반면, DeBias-CLIP은 하락폭이 더 작은 경향을 보였습니다. 또한, 요약문을 아예 제거한 경우에도 Long-CLIP보다 성능 저하가 덜 일어난다는 것을 실험적으로 보였습니다.
Ablation study
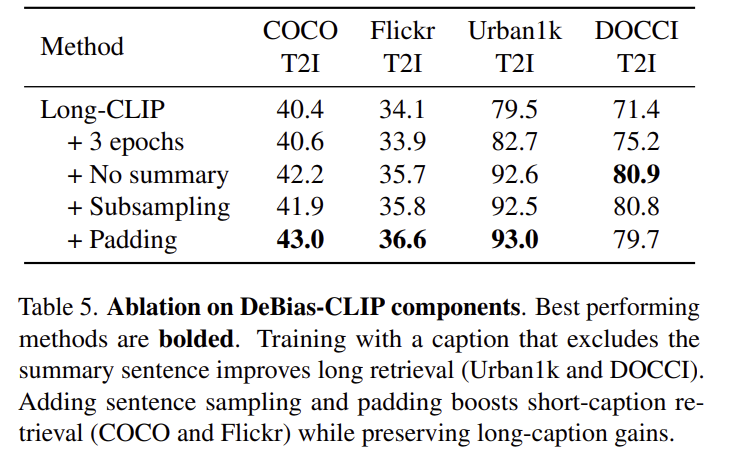
위의 Table 5는 해당 논문에서 제안한 caption-level augmentation 방식에 대한 실험입니다. 요약 문장 제거, 문장 샘플링, 앞쪽 padding 추가에 대한 결과를 확인한 것으로, long-text retrieval에서 요약 문장을 제거하는 것이 가장 핵심이라는 것을 확인한 실험입니다.
Conclusion and Limitations
해당 연구는 CLIP 기반의 텍스트 인코더가 long-text retrieval을 방해하는 early token bias와 summary sentence bias를 보인다는 것을 실험적으로 보였으며, 이에 대하여 학습 데이터의 캡션 첫 문장이 일반적으로 요약 정보를 담고있기 때문임을 보였습니다. 이를 해결하기 위해 DeBias-CLIP을 제안하였으며, 이는 첫 문장인 요약문을 제거하고, 문장을 샘플링한 뒤 padding을 추가하는 방식으로, 이를 통해 다양한 위치에 있는 텍스트를 고려할 수 있도록 하였습니다. 이를 통해 long-text retrieval에서 SOTA를 달성하였으며, 문장 순서와 요약 문장 제거에도 강인하게 동작이 가능하였습니다. 그러나 기존의 벤치마크들도 여전히 첫 문장에 요약 정보가 들어가는 구조이므로 여전히 한계가 존재하며, 저자들은 교과서나 보고서처럼 여러 문단으로 이루어진 새로운 벤치마크가 필요하다고 어필합니다.
리뷰 재밌게 읽었네요 감사합니다
1. Long-CLIP을 기반으로 해당 연구가 진행된 것 같은데, Long-CLIP의 동작 방식이 궁금합니다. 단순히 그냥 long caption 만들어서 학습한건가?싶었는데 Figure 3(b)에서 Long-CLIP이 앞쪽 토큰에 더 attention을 준다고 해서 다른 기법이 또 있는건가 궁금해지네요. 그리고 여기서 말한 attention bias가 학습 전 CLIP에서도 이미 있던 것인지, long-caption fine-tuning 과정에서 더 강화된 것인지 궁금합니다.
2. 논문에서는 첫 문장이 보통 summary sentence라고 (데이터셋 특성인가?) 가정한 것 같은데… 실제 데이터에서 첫 문장이 항상 요약문인지 확인하는 기준이 있어야할 것 같은데요. 이런 판단 기준이 있나요? 만약 첫 문장이 세부 정보이거나 중요한 장면 설명인 경우에는 제거가 오히려 손해가 될 수도 있을 것 같아서요.
댓글 감사합니다.
1. Long-Caption 방식은 긴 문장을 처리하기 위해, primary component matching을 통해 positional embedding을 확장하고 fine-tuning합니다. 조금 더 구체적으로 설명을 드리자면, 잘 학습된 초기의 positional embedding 토큰 20개는 유지하고, 나머지 57개에 대하여 보간 방식을 활용하여 긴 길이의 토큰으로 확장합니다. 또한, fine-tuning 시 PCA를 활용하여 세밀한 특징을 여러 벡터로 분해하고, 중요도에 따라 필터링한 뒤, 선택된 벡터로 특징을 재구성합니다.
early-token bias는 기존 CLIP에도 있었고, Long-CLIP에서도 attention bias 결과를 통해 앞 부분에 집중되는 결과를 보여준 것 입니다.
2. 기존의 데이터 셋들이 주로 첫 문장이 summary sentence이며, 실제 환경에서는 항상 그렇지 않으므로, 전체 맥락을 고려할 수 있도록 해야한다는 것이 해당 논문의 저자들의 입장입니다. 즉, 앞 부분에 요약이 있을 경우에도 맥락을 통해 유의미한 영역에 집중해야한다는 것이 저자들의 연구 방향인 것으로 보입니다. 따라서 기존의 CLIP 및 Long-CLIP이 데이터 셋에 의해 앞부분에 집중하고 있고, 따라서 앞 부분의 요약 문장을 없앤 실험을 통해 기존 CLIP들의 경향을 확인하고, 저자들이 제안한 DeBias-CLIP이 이를 완화하였다는 것을 보였습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
저자의 검증방식이 완전 타당한지에 대해 읽으면서 계속 의문이었지만, 어느정도 신빙성이 있는 것 같기는 합니다. 사실 좀더 엄밀하고 납득 가능한 실험 세팅이었다면 좋았을텐데, 예를들어 첫문장과 둘째문장의 위치가 바뀌어도 문맥적으로 어색함이 없다거나, padding token이 앞에 두번 추가되었을때 왜 유독 siglip2 에서 성능 드랍이 컸는지에 대한 설명이 있었는지 궁금합니다. 그리고 저자의 발견을 CLIP 이 학습과정중 실제 중요한 위치를 찾기보단 첫 문장에 요약된 caption 이 존재할 비율이 높다는 것을 shorcut으로 학습했고, 이게 Long-CLIP 에서도 동일 편향이 존재하니 그러한 학습 데이터의 분포적 bias 를 없앰으로써 해결했다고 이해하면 되나요?
감사합니다.
댓글 감사합니다.
첫 문장과 둘째 문장에 대한 분석과, padding 위치에 따른 분석 결과가 있었으면 하는 아쉬움이 있으신 것 같습니다. 저자들은 첫 문장과 둘째 문장 위치가 문맥적으로 분리된다는 가정에서 이루어지고 있긴 합니다. 그러나 실험적 결과를 보았을 때, 문맥의 흐름이 바뀌었다고 하더라도 두 문장이 모두 주어지는 데, 그 순서가 바뀌었다는 이유로 성능이 저하되는 것은 early token bias에 대한 근거로 활용이 가능하다고 생각합니다. 또한, padding 토큰이 앞에 두번 추가되었을 때 SigLIP2에서 성능 드랍에 대해 저자들이 단순히 SigLIP2은 영향을 크게 받는다고 단순히 설명하고 추가적인 설명이 없어 아쉽습니다. 마지막 질문에 대해서는 인택님이 제대로 이해하신 것 같습니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
1. 문장 샘플링이 문장 간 의미 관계를 파괴하는 부작용은 없는지 궁금합니다.
DeBias-CLIP의 sentence sampling은 문장을 무작위로 선택하고 순서도 무작위로 섞는 것 같은데 long caption 내 문장들 간의 관계가 항상 독립적인 건 아니라고 생각이 듭니다. 예를 들어 “왼쪽에 고양이가 있다. 근데 그 옆에 물그릇이 놓여 있다”처럼 대명사나 지시어나 시공간적 관계로 묘사된 게 있을 것 같습니다(grounding 느낌). 이런 문장을 개별 단위로 분리하고 섞으면 지시어의 참조 대상 같은 게 사라지거나 공간 관계 논리가 깨질 수도 있게 되는데, 이것이 모델이 문장 간 논리관계나 시공간적 순서를 학습하는 데 오히려 방해가 되지는 않을까요? 논문에서 문장을 독립적인 단위로 가정한 거 같아가지고 그 근거에 대해 저자들이 제시한 바가 있는지 제가 놓친 게 있는 것 같아 질문드립니다.
2. 읽으면서 figure 2에서 SigLIP 시리즈의 경우 CLIP에 비해 성능 저하 폭이 크게 발생하는 이유가 의문이 들었었는데,, 승현님이 적어주신대로 SigLIP(64)은 CLIP(77)보다 13 토큰정도 짧은 것 같은데, “This is a photo”를 반복 추가하면 유의미한 토큰이 뒤로 밀리고, context window가 상대적으로 짧은 SigLIP의 64 토큰 안에서는 더 빠르게 잘려나가거나 유의미한 정보가 뒤쪽에 몰리게 되어서 같은 양의 padding이라도 SigLIP에게 더 불리했던 것은 아닌지, 아님 CLIP의 학습 데이터는 “a photo of a {class}” 이런게 많았어서 overfitting 된건지. 이거 말고 다른 이유가 있었을지 제가 맞게 이해한 것인지 궁금합니다.
질문 감사합니다.
1. 우선 해당 논문에서는 그러한 근거를 밝히고 있지 않습니다. 저도 재찬님이 이야기하신 것 처럼 문장간의 연관성을 고려하지 못하게 된다는 점은 한계라고 생각합니다. 그래도 기존의 방식들이 앞 부분에만 집중하여 뒤에 있는 유의미한 정보들을 고려하지 못하던 것에 비해, 저자들의 샘플링 방식으로 학습을 수행하면서 전체적으로 유의미한 내용을 파악할 수 있었다는 점에서는 의미가 있는 것 같습니다.
2. 말씀하신 것 처럼, 64 토큰을 처리한다는 점에서 같은 수의 padding이라도 유의미한 정보가 빠르게 뒤로 밀리거나 잘려 성능 저하 폭이 커졌을 가능성이 있습니다. 그러나, 단순 context length의 차이로만 보기에는, 문장 순서를 바꾼 경우에도 성능 저하가 크게 발생합니다. 문장 순서를 바꾸었다고 하여 64개의 토큰을 넘어가는 것은 아니기 때문에, 앞쪽 token에 집중하도록 early token bias를 가진 것으로 해석한 것 같습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
리뷰에서는 summary sentence shortcut을 중심으로 설명했는데, 논문이 encoder 구조적 원인과 데이터 구성상의 원인을 어떻게 구분했는지 궁금합니다. 단순히 positional encoding이나 pooling 방식을 바꾸는 것만으로는 early-token bias가 해결되지 않는다는 실험이 있을까요?
감사합니다.
질문 감사합니다.
제가 이해하기로는 해당 논문에서는 early token bias의 원인을 데이터 및 학습 구성상의 문제로 해석한 것 같습니다. 따라서 모델 구조를 수정하기보다는, caption-level augmentation을 통해 이를 완화하고자 한 것으로 보입니다.
해당 논문의 supplementary에는 이야기하신 실험이 포함되어있습니다. encoder 디자인에 대한 대안도 실험으로 absolute positional embedding 대신 particularly rotary positional embeddings를 사용하는 빙식도 비교하였으나, 첫 문장을 뒤로 이동하거나 제거했을 때 성능저하가 크게 발생하였습니다. 또한, EOT 토큰 하나에 정보를 모으는 pooling 방식이 문제일 수 있다고 보고 token average pooling에 대한 실험도 진행하였지만 마찬가지로 early token bias를 해결하지 못하고 성능 저하가 일어났다고 합니다.
따라서 해당 논문은 positional encoding이나 pooling 같은 인코더 구조 수정만으로는 early-token bias 해결이 어렵다고 보고 summary-firste caption 구조와 그로 인한 training shortcut을 문제로 보고 캡션 augmentation 방식으로 이를 완화하고자 한 것으로 보입니다.