이번 논문은 “CLIP은 정말 Bag-of-Words처럼밖에 이해하지 못하는가?”라는 질문에서 시작하는데요, CLIP의 compositionality failure 원인을 encoder 내부 정보 부족과 cross-modal alignment 문제로 분리해 분석한 연구입니다.

- Venue: ICLR 2026
- Authors: Darina Koishigarina, Arnas Uselis, Seong Joon Oh
- Affiliation: T ̈ubingen AI Center, University of T ̈ubingen
- Title: [ICLR 2026] CLIP Behaves like a Bag-of-Words Model Cross-modally but not Uni-modally
- GitHub: [Link]
0. Background
본격적인 리뷰에 앞서, 이 논문이 출발한 문제인 CLIP의 Bag-of-Words-like behavior를 먼저 살펴보겠습니다.
CLIP은 이미지-텍스트 검색이나 zero-shot classification 등 다양한 태스크에서 뛰어난 성능을 보인건 이미 다들 아실 것 같습니다. 하지만 이후 연구들은 CLIP이 문장을 정말 구조적으로 이해하는지에 대해서는 의문을 가졌습니다. 특히 문장 안에 등장하는 object와 attribute의 조합 관계를 제대로 구분하지 못한다는 연구들이 계속 나왔습니다

대표적으로 ICLR 2023의 NegCLIP 연구에서는 CLIP이 마치 Bag-of-Words 모델처럼 동작한다는 점을 보였습니다. 위 그림의 두 번째 예시를 보면, 정답 문장은 “the paved road and the white house”이고, 오답 문장은 “the white road and the paved house”입니다. 두 문장은 사용된 단어의 집합은 거의 동일하지만, paved가 road에 붙는지, house에 붙는지가 다르죠. 사람은 이 차이를 쉽게 구분할 수 있지만, 문제는 CLIP은 두 문장을 하나의 이미지와 비슷하게 매칭하는 경향을 보였다고 합니다.
이는 결국 CLIP이 “road”, “white”, “house”, “paved” 같은 개별 concept은 인식하지만, 어떤 attribute가 어떤 object에 연결되어 있는지까지는 충분히 반영하지 못하는 것처럼 보였죠. 따라서 이를 바탕으로 기존 연구들은 CLIP이 문장의 순서나 구조를 이해하기보다, 입력을 단어들의 집합처럼 처리한다고 여겨왔습니다.
1. Introduction
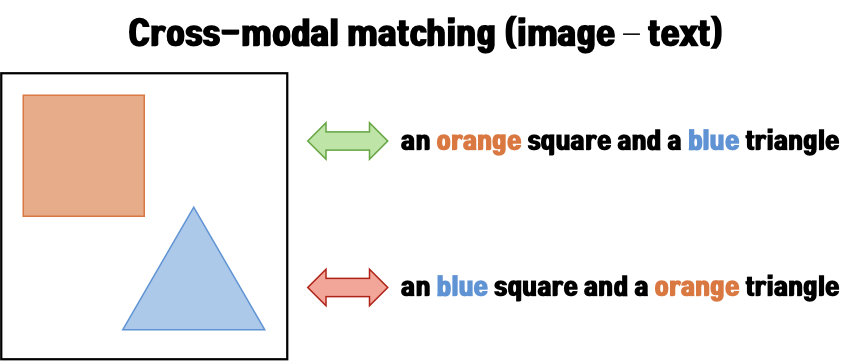
그런데 Background에서 살펴본 문제는 상단 그림처럼, 이미지와 텍스트를 얼마나 잘 매칭하는 지를 기준으로 살펴보았습니다. 즉, cross-modal matching을 통해 CLIP이 attribute-object binding 을 잘 하는지를 판단한 것이죠
그런데 저자는 cross-modal matching으로 CLIP의 binding 능력을 판단하는 것이 맞을까요? 다시말해, 지금 CLIP이 binding 정보 처리를 못한다고 하는데 이게 정말 CLIP의 image embedding이나 text embedding 내부에 binding 정보가 아예 없는 것일까요? 아니면 각 modality 내부에는 정보가 존재하지만, image와 text를 정렬하는 과정에서 그 정보가 제대로 활용되지 못하는 것일까요?
이번 논문은 바로 이 질문에서 출발하였습니다. 기존 연구가 “CLIP은 BoW처럼 행동한다”는 현상을 보여주었다면, 본 논문은 한 단계 더 들어가서 그 BoW-like behavior의 원인이 encoder 자체의 정보 부족인지, 아니면 cross-modal alignment의 문제인지를 분리해서 분석하고자 했습니다.
따라서 본 논문에서는 1) CLIP이 cross-modal하게 BoW처럼 행동한다는 기존 결과를 다시 확인한 뒤, 2) image embedding과 text embedding을 따로 분리해서 분석하였습니다. 결국 이 논문의 핵심은 CLIP의 compositionality failure를 단순한 encoder 한계로 보기보다, 정보는 이미 존재하지만 modality 간 정렬이 부족해서 발생한 문제로 재해석하는 것이 아닐까 하는데요. 지금부터 살펴보겠습니다.
2. Problem Setup
본격적인 분석에 앞서, 저자들이 말하는 binding problem이 무엇인지 다시 정리해보겠습니다. 이 논문에서 binding이란 여러 object와 attribute가 함께 등장할 때, 각 attribute를 올바른 object에 연결하는 능력을 의미합니다. 예를 들어 “red cube and blue sphere”에서는 red가 cube에, blue가 sphere에 연결된다는 관계를 이해해야 합니다.
이를 확인하기 위해 저자들은 정답 caption과, attribute-object 조합만 바꾼 negative caption을 만들어 비교하였습니다. 예를 들어 “red cube and blue sphere”를 “blue cube and red sphere”로 바꾸는 방식입니다.
이러한 설정에서 CLIP이 compositional하게 이해하고 있다면, 정답 caption을 negative caption보다 이미지와 더 가깝게 매칭해야 합니다. 반대로 BoW처럼 동작한다면, 두 caption에 포함된 단어 집합이 거의 같기 때문에 두 문장을 비슷하게 볼 가능성이 높죠

논문에서는 이를 평가하기 위해 real-world dataset과 synthetic dataset을 함께 사용했습니다.
– Real-world dataset: ARO, SugarCrepe, COCO, CC3M
– Synthetic dataset: CLEVR, PUG:SPAR, PUG:SPARE
synthetic dataset 는 object와 attribute를 마음대로 변경할 수 있어서 사용하였다고 합니다. real 데이터는 이것을 통제하는 것이 워낙 쉽지 않을 것 같긴 하네요. (추가로 PUG:SPARE는 기존 PUG:SPAR에서 attribute가 위치와 강하게 연결되는 bias가 있을 수 있는데 이를 없애기 새롭게 구성된 데이터셋입니다)
이제 데이터셋은 준비가 끝났으니… 기존 연구들이 말한 것처럼, CLIP이 정말 cross-modal matching에서는 BoW처럼 행동하는가를 살펴보겠습니다. 데이터셋 CLEVR, PUG:SPAR, PUG:SPARE에서 정답 caption과 attribute가 뒤바뀐 caption 중 하나를 고르게 했고, 그 결과 CLIP은 각각 0.56, 0.51, 0.50 수준의 정확도를 보였습니다.
거의 random guessing에 가까운 결과였기 때문에, 기존 연구들의 주장과 마찬가지로 cross-modal matching 기준에서는 CLIP이 attribute-object binding을 잘 구분하지 못한다고 볼 수 있습니다.
3. CLIP binds concepts Unimodally
앞서 확인한 것처럼, CLIP은 cross-modal matching에서는 attribute-object binding을 잘 구분하지 못했습니다. 하지만 이것만으로 CLIP의 image embedding이나 text embedding 내부에 binding 정보가 없다고 단정할 수는 없습니다. 그래서 저자들은 image와 text를 함께 비교하지 않고, 각 modality의 embedding을 따로 분리해서 분석해보았습니다.
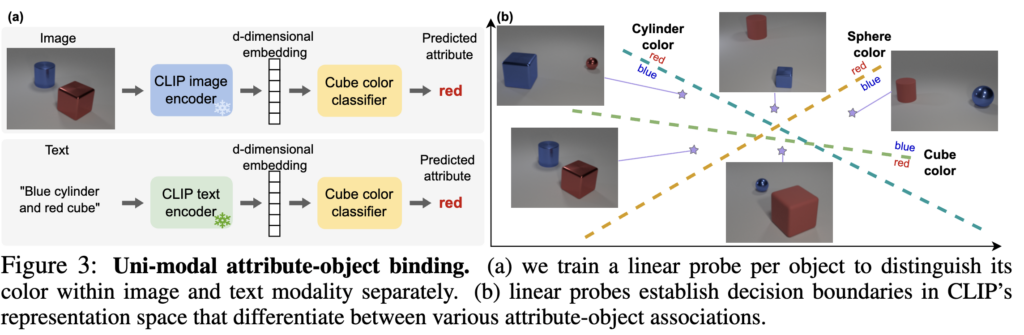
이를 위해 사용한 방법이 linear probing입니다. CLIP encoder는 고정한 상태에서, Figure 3처럼 object별 classifier를 학습했습니다. 예를 들어 “blue cylinder and red cube”라는는 입력이 있을 때, cube의 color가 무엇인지를 맞히도록 한 것이죠.
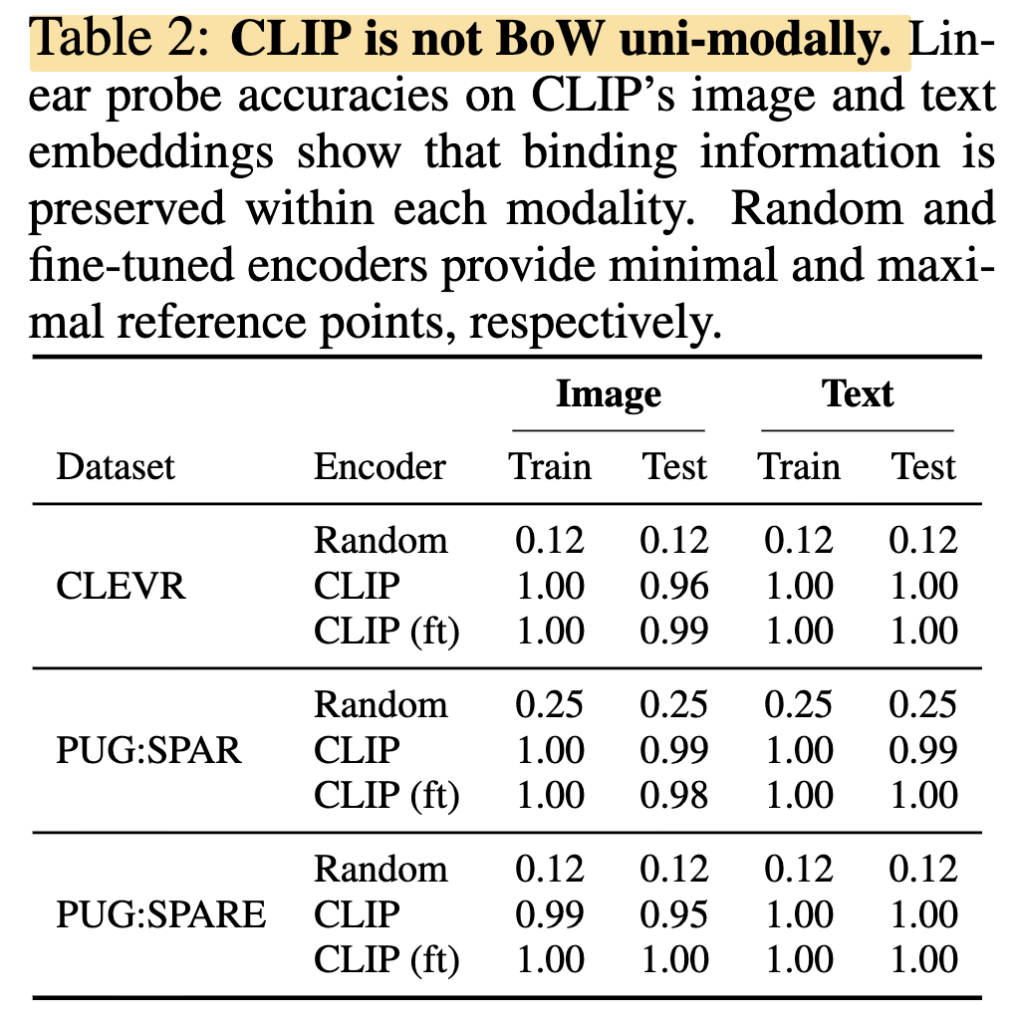
결과적으로 Table 2에서 image embedding과 text embedding 모두 높은 성능을 보였습니다. 이는 CLIP이 cross-modal하게는 BoW처럼 보이지만, 각 modality 내부에는 attribute-object binding 정보가 이미 존재한다는 것을 의미합니다. 즉, CLIP이 binding 정보를 아예 모르는 것이 아니라, 그 정보가 image-text matching 과정에서 제대로 활용되지 못했다고 해석할 수 있다는 것이죠!!
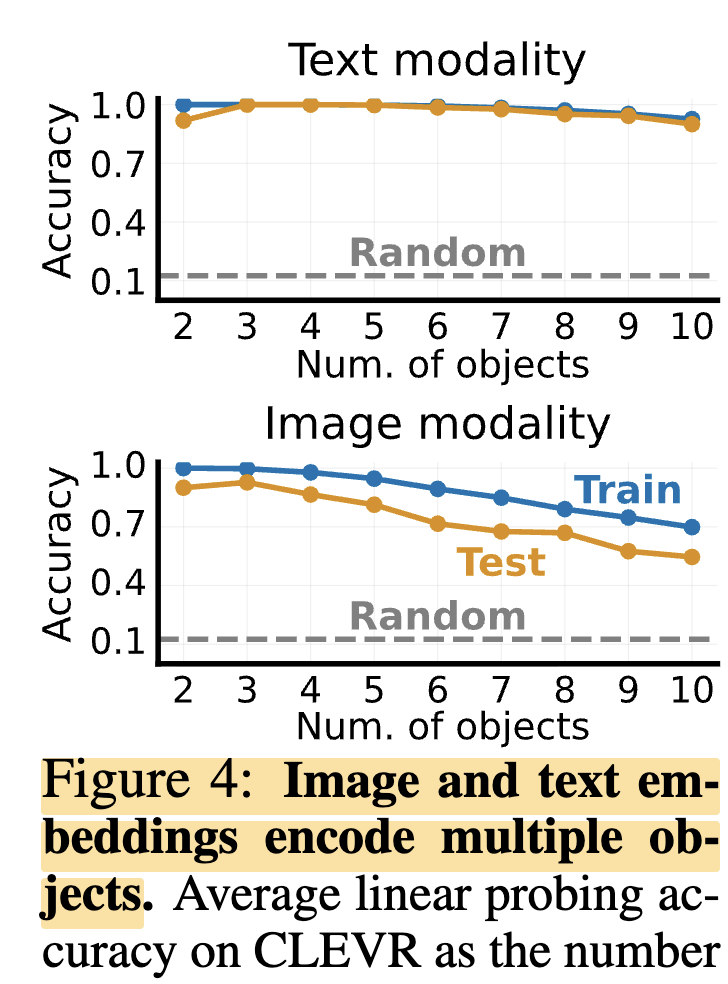
위의 실험을 봤을 때, 단순히 object가 하나라서.. 너무 쉽지않을까?라는 의문이 들었을 수 있을 것 같습니다. 그래서 저자들도 object 수를 늘려가며 실험했는데요. 그 결과 text embedding은 높은 성능을 유지했고 image embedding도 random보다 높은 성능을 보였습니다.
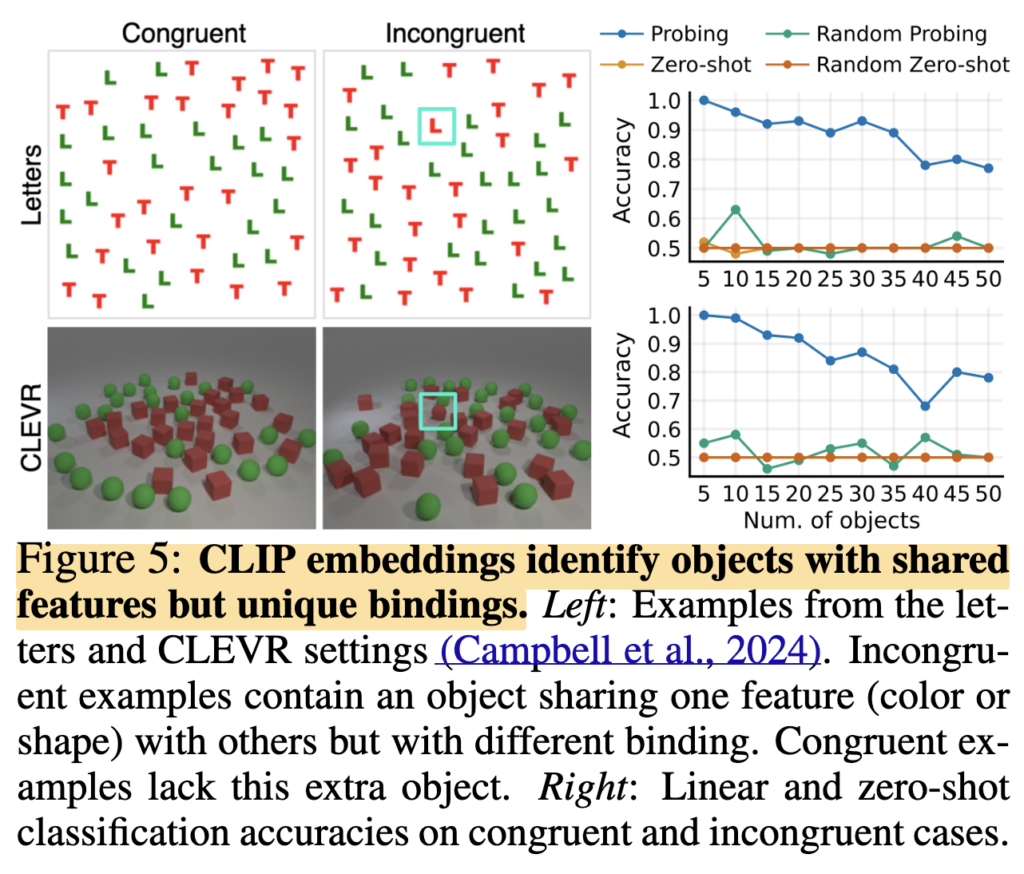
마지막으로 Figure 5의 conjunctive search 실험도 보였습니다. 예를 들어 이미지 안에 green sphere와 red cube가 많이 있을 때, red sphere가 있는지를 구분하는 문제입니다. 만약 CLIP이 정말 BoW라면 red와 sphere라는 feature만 보고 판단하기 때문에 red sphere의 존재 여부를 구분하기 어려워야 합니다. 하지만 linear classifier는 이를 꽤 잘 구분했습니다. 이는 CLIP의 visual embedding이 단순히 feature들의 집합만 담고 있는 것이 아니라, attribute와 object가 결합된 정보도 담고 있음을 보여줍니다.
정리하면, CLIP은 cross-modal하게는 BoW처럼 행동하지만, uni-modal embedding 내부에는 binding 정보가 존재했습니다. 따라서 문제는 encoder 자체의 정보 부족보다는, image와 text embedding 사이의 alignment 문제일 가능성이 높습니다.
4. Improving Cross-modal binding
앞선 실험을 통해 CLIP의 image embedding과 text embedding 내부에는 이미 binding 정보가 존재한다는 것을 확인했습니다. 그렇다면 문제는 encoder가 아니라, image와 text embedding을 서로 맞추는 cross-modal alignment 과정에 있을 가능성이 높다는 것도 따라오셨을 것 같은데요.
이를 확인하기 위해 저자들은 LABCLIP이라는 매우 간단한 방법을 제안했습니다. 기존 CLIP은 image embedding과 text embedding의 유사도를 바로 계산하지만, LABCLIP은 text embedding에 linear transformation A를 한 번 적용한 뒤 image embedding과 비교하자는 것입니다.
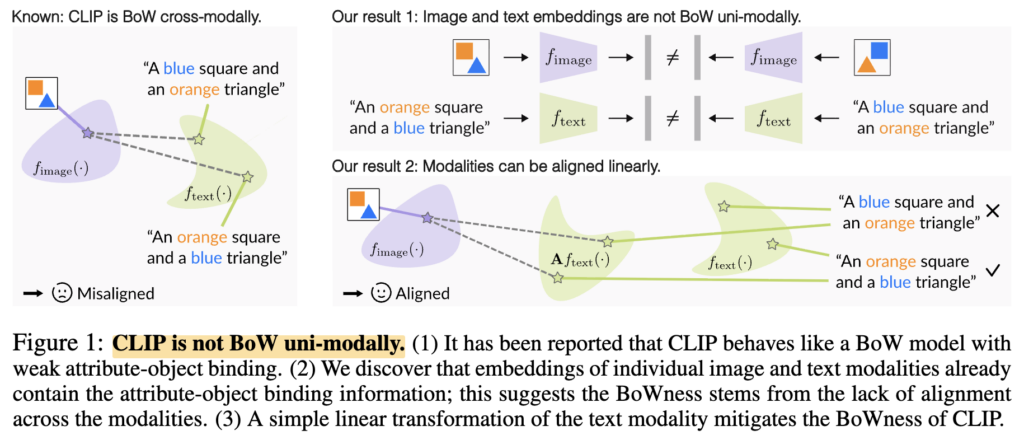
즉, CLIP encoder 자체는 전혀 수정하지 않고, text embedding을 image embedding 쪽의 linear layer를 추가하여, binding structure에 맞게 살짝 정렬해주는 방식입니다.
이때 학습에는 정답 caption과 attribute-object 조합만 바꾼 negative caption을 함께 사용합니다. 예를 들어 “red cube and blue sphere”를 “blue cube and red sphere”로 바꾸어, 모델이 단순 단어 집합이 아니라 올바른 조합을 더 가깝게 보도록 학습한 것이죠.
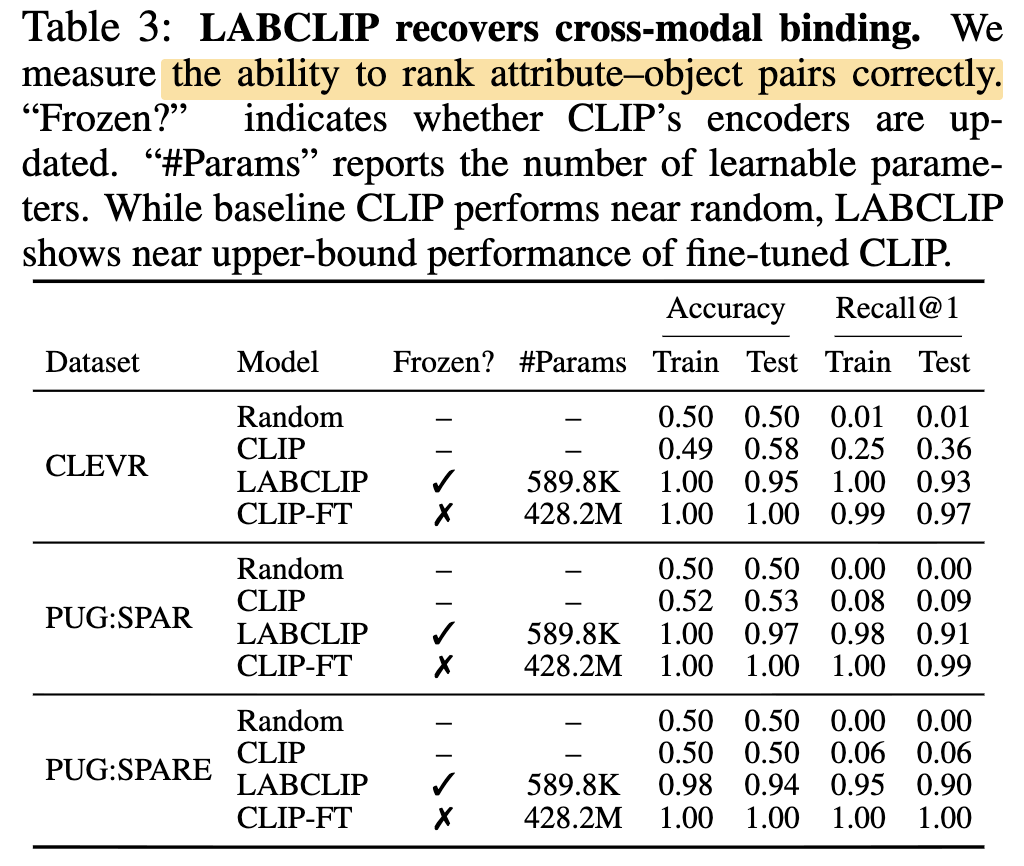
Table 3을 보면, 기존 CLIP은 CLEVR, PUG:SPAR, PUG:SPARE에서 거의 random에 가까운 성능을 보였습니다. 반면 LABCLIP은 encoder를 전혀 업데이트하지 않았음에도 fine-tuned CLIP에 가까운 수준까지 성능을 보였죠. 이는 CLIP이 binding 정보를 모르는 것이 아니라, 그 정보를 cross-modal matching에서 제대로 활용하지 못한 것이라는 얘기를 뒷받침하는 결과입니다.
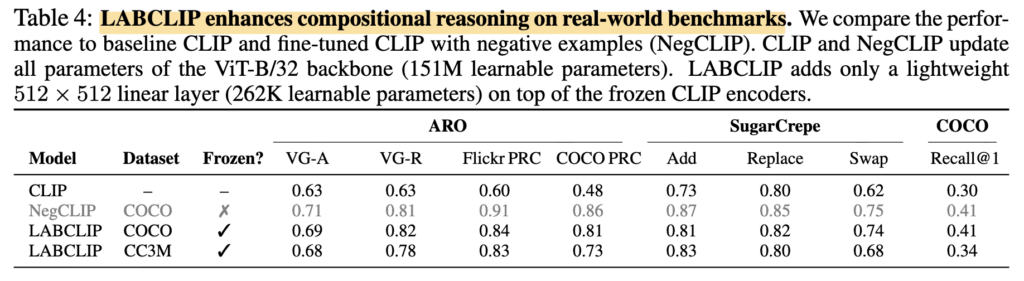
이러한 경향은 real-world benchmark에서도 보였다고 합니다. Table 4에서 LABCLIP은 ARO, SugarCrepe, COCO에서 기존 CLIP보다 전반적으로 높은 성능을 보였고, 일부 항목에서는 NegCLIP과 비슷한 수준까지 달성했죠. 다만 여기서 알아둬야하는 점은LABCLIP이 CLIP 전체를 fine-tuning한 것이 아니라, 작은 linear layer만 추가했다는 것입니다. (NegCLIP은 full-fineting 입니다)
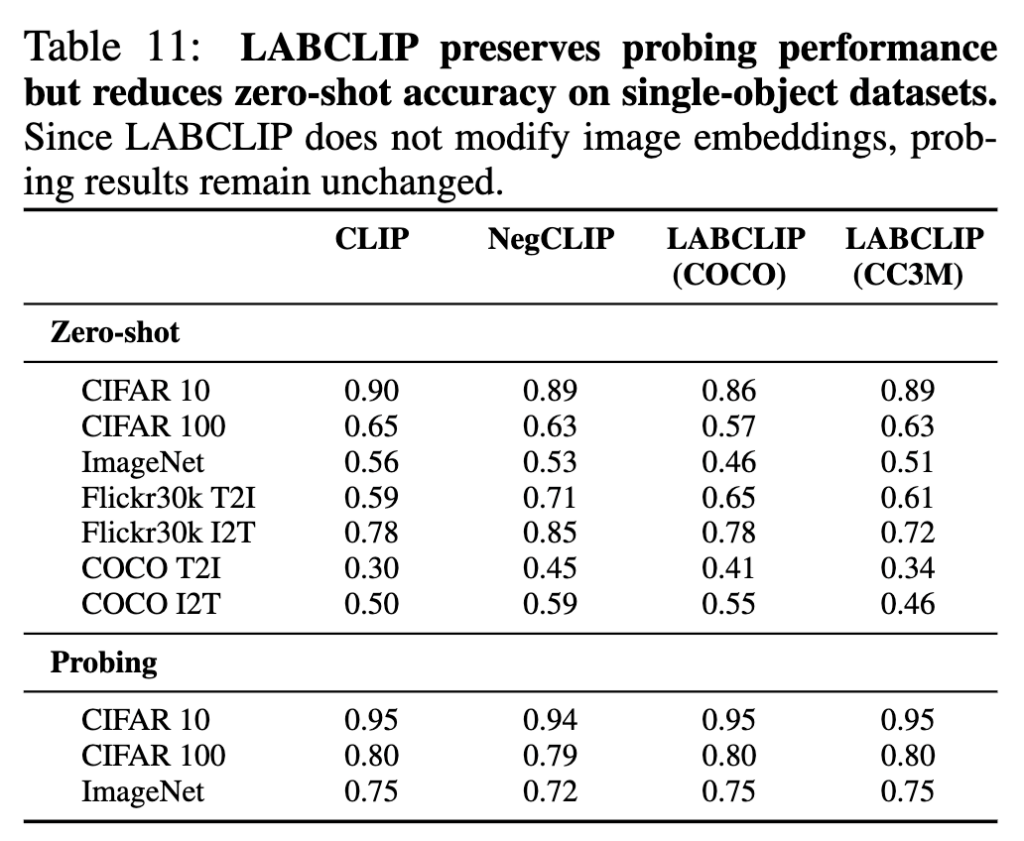
다만 appendix에 Table 11의 downstream 결과를 보면, LABCLIP이 모든 태스크에서 무조건 좋아지는 것은 아니었습니다. CIFAR나 ImageNet 같은 single-object classification에서는 기존 CLIP보다 약간 낮은 성능을 보였는데, 이는 binding에 맞춘 정렬이 coarse object recognition에는 오히려 약간의 trade-off를 가졌죠.
그러다보니 LABCLIP은 universal improvement라기보다는 attribute-object binding을 강화하기 위한 목적의 lightweight alignment 방법으로 보는게 좋을 것 같습니다
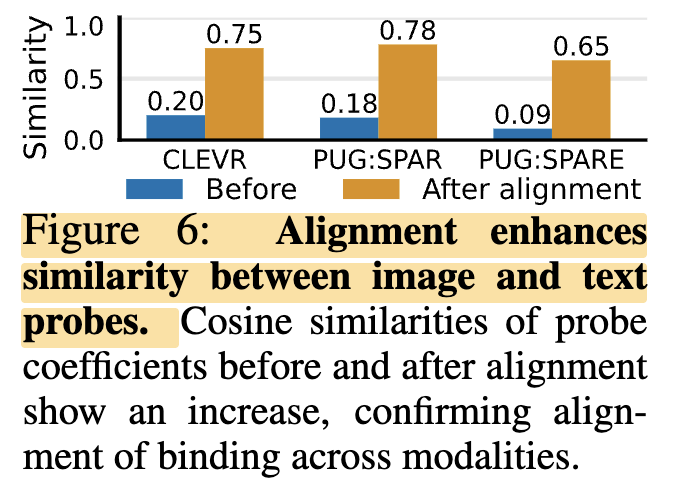
마지막으로 Figure 6에서는 LABCLIP이 실제로 image와 text의 binding signal을 더 잘 맞추었는지를 본 것인데요. image embedding과 text embedding 각각에서 학습한 linear probe의 coefficient를 비교했는데, alignment 전에는 두 coefficient의 유사도가 낮았지만 LABCLIP 적용 후에는 크게 증가했습니다. 이는 linear transformation이 단순히 성능만 올린 것이 아니라, image와 text modality 사이의 binding 구조 자체를 더 잘 정렬했다는 것을 보여주는 것입니다.
정리하면, LABCLIP은 새로운 정보를 학습한 것이 아니라, CLIP 내부에 이미 존재하던 binding 정보를 cross-modal하게 꺼내 쓸 수 있도록 정렬한 방법입니다.
5. Conclusion
논문은 여기까지 였습니다. 마지막으로 정리를 좀 해보면 .. “CLIP이 정말 binding을 모르는가?”라는 질문에서 출발한 것 같습니다. 저자들이 직접 실험을 해보니, 기존에 널리 알려진 정보처럼 CLIP은 cross-modal matching에서는 BoW처럼 행동했지만, image embedding과 text embedding을 따로 보면 그 안에는 attribute-object binding 정보가 이미 존재했죠
즉, 문제는 CLIP이 binding 정보를 아예 모르는 것이 아니라, image와 text를 정렬하는 과정에서 그 정보를 제대로 활용하지 못한다는 점이었습니다. 따라서 저자들은 LABCLIP을 제안해서, 단순한 linear transformation 만으로도 기존 CLIP embedding 안의 정보를 다시 꺼내 쓸 수 있음을 보였습니다.
따라서 이 논문의 내용을 한 문장으로 정리한다면…
CLIP의 compositionality failure는 정보의 부재라기보다, modality 간 alignment 부족에서 발생한 문제일 수 있습니다.
오랜만에 재밌게 읽은 논문입니다. 읽으면서 어 이거 이런 실험 필요할 것 같은데? 라고 생각하면 바로 다음 챕터에서 보여주고, 실시간으로 저를 설득하고 납득시킨 잘 쓴 논문 같네요. 개인적으로 이런식의 전개로 다음 논문을 다뤄보고 싶다는 생각이 들기도 했던 것 같네요 리뷰 마치겠습니다!
안녕하세요 주영님, 좋은 리뷰 감사합니다 !
기초교육 간 CLIP, SigLIP 등을 배우고 나니, 리뷰에서 CLIP에 대해 다루면 꼭 읽어보게 되는 것 같습니다!
질문이 있어서 댓글로 남기겠습니다!!
CLIP이 binding은 잘하지만, image-text 정렬 과정에서 정보를 제대로 활용하지 못한다고 했는데, 비슷한 내용을’ Is CLIP ideal?’ 이라는 논문의 리뷰에서 봤던 기억이 있습니다! 그 논문에서도 동일하게 attriute binding의 문제를 제기했었고, 추가로 spatial reasoning, negation(부정 표현) 등에 대한 문제를 제기했었던 것 같습니다.
그렇다면 혹시 이런 부분에 대한 언급은 없었는지 궁금합니다!
두 번째로, 논문과 직접적인 질문은 아니지만, SigLIP2 처럼 CLIP의 문제점들을 제시하고, 해결한 방안들이 등장했고, SigLIP2의 경우 CLIP 만큼 visual backbone으로 자주 사용하는 것으로 보입니다! 그럼에도 불구하고, CLIP을 기반으로 연구를 하는 논문들이 많은 이유가 궁금합니다!!
감사합니다!
좋은 질문 감사합니다.
Q1. 논문에 spatial reasoning, negation 같은 다른 문제는 언급 없음?
-> A1. 먼저, 말씀해주신 spatial reasoning과 negation은 본 논문의 메인 주제는 아니었습니다. 따라서 그 부분에 대한 직접적인 언급은 없었습니다 (본 논문이 집중한 문제는 attribute-object binding)
다만 appendix에서 spatial reasoning을 간단히 다루긴 했습니다. 정확히는 “attribute-object binding을 개선한 LABCLIP이 spatial reasoning에도 일반화되는가?”를 확인한 실험이었는데요.
근데 저자들이 말하길 spatial relation을 attribute-object binding과는 별개의 문제라고 합니다. 예를 들어 attribute-object binding은 “red cube”처럼 속성과 객체의 연결 문제라면, spatial reasoning은 “object가 위/아래/왼쪽/오른쪽에 있는가” 처럼 객체 간 위치 관계를 이해하는 문제이기 때문입니다.
실험 결과에서도 binding을 위해 학습한 LABCLIP이 spatial reasoning까지 자동으로 개선하지는 않았습니다. 그래서 이 논문의 결론은 “CLIP의 모든 compositionality 문제가 alignment 문제다”라기보다는, attribute-object binding에 한해서는 CLIP 내부에 정보가 이미 존재하고, cross-modal alignment가 주요 병목일 수 있다 정도로 이해하는 것이 맞을 것 같습니다. Negation의 경우 논문에서 다루진 않았습니다
—————
Q2. SigLIP2가 대세인데, 왜 아직도 CLIP 기반의 연구를?
-> A2. 제 생각이긴 하지만 아무래도 CLIP이 여전히 가장 널리 쓰이기 때문이 아닐까요? 멀티모달 모델의 어찌보면 표준 처럼 자리잡게된 현 시점에… 공개된 모델과 코드, 기존 benchmark 결과, downstream 적용 사례가 많다보니 새로운 방법을 제안했을 때 비교와 해석이 쉽다는 점도 큰 영향이 있는 것 같습니다.
또한 많은 VLM이나 retrieval 시스템이 이미 CLIP embedding을 기반으로 구축되어 있기 때문에, CLIP의 구조적 한계를 분석하거나 가볍게 개선하는 연구는 여전히 의미가 깊다 생각이 드네요!
주영님 좋은 리뷰 감사합니다.
우선, binding problem에 대하여 검토할 때, attribute 조합을 바꾸어 만든 negative caption과 정답 캡션에 대한 유사도가 어느정도 되는 지에 대해서는 따로 확인이 어려울까요?
Figure 5에 해당하는 실험의 결과는 Probing에 집중하면 되는 것 일까요?
또한, LABCLIP이 이미지가 아닌 text embedding을 변환하도록 학습하는 이유는 컨트롤이 쉬워 학습 데이터 수집이 편리하기 때문일가요? 또한, Table 3의 실험 결과엣 fine-tuned CLIP에 가까운 수준의 성능을 보였다고 하셨는데, LABCLIP의 학습 데이터가 fine-tuned CLIP의 데이터에 변화를 준 것인지, 별도의 데이터로 학습한 뒤 zero-shot으로 적용한 결과인지 궁금합니다.
좋은 질문 감사합니다!
Q1. 유사도 수치는 확인할 수 없나?
-> A1. 먼저 negative caption과 정답 caption의 유사도 자체는 논문에서 별도로 수치로 제시되지는 않은 것 같습니다. 다만 실험 결과를 보면 기존 CLIP이 거의 random 수준을 보였다는 점에서 정답/negative caption을 충분히 구분하지 못하기도 하고, 유사도 역시 큰 차이가 없을 것 같습니다.
Q2. figure 5는 probing 을 보면 되는가?
-> A2. 넵 probing 결과에 집중해서 보면 될 것 같습니다. 핵심은 CLIP의 visual embedding이 단순히 red, sphere 같은 개별 feature만 담는 것이 아니라, red sphere처럼 feature가 결합된 정보를 담고 있는지를 확인하는 실험입니다. Zero-shot은 잘 안 되지만 linear probe는 이를 잘 구분했기 때문에, visual embedding 내부에는 binding signal이 존재한다고 본 것입니다.
Q3. linear transformation을 text에만 적용하는 이유?
-> A3. 아! 이 부분은 논문에서도 언급을 했던 부분인데, LABCLIP이 text embedding을 변환한 이유는 “실용적인 이유”가 크다고 합니다. 이미지 embedding은 이미 vector DB 등에 저장되어 활용되는 경우가 많기 때문에 그대로 두는 편이 유리하고, negative sample도 이미지를 바꾸는 것보다 caption에서 noun/adjective를 섞어 만드는 것이 훨씬 쉽기 때문이라고 하네요.
Q4. Table 3에서 학습 데이터가 뭐임?
-> A3. Table 3의 경우에는 synthetic dataset에서 같은 설정의 train split으로 LABCLIP을 학습하고 test split에서 평가한 결과라고 합니다. 즉 완전한 zero-shot이라기보다는, attribute-object 조합이 겹치지 않도록 split한 controlled setting에서 일반화 성능을 본 것이죠. fine-tuned CLIP도 같은 문제 설정에서 encoder 전체를 학습한 upper bound에 가깝고, LABCLIP은 encoder를 frozen한 채 작은 linear layer만 학습했는데도 그에 가까운 성능을 보였다는 점이 저자들이 보이고 싶던 결과입니다