안녕하세요. 오늘 리뷰할 논문은 Video-MME-v2입니다. Video-MME는 긴 비디오 이해 분야에서 가장 널리 활용되는 데이터셋입니다. 최근에 Video-MME 팀이 새로 데이터셋을 공개하여 해당 논문을 리뷰하려합니다.
Introduction
최근 GPT, Gemini, Qwen 등 다양한 멀티모달 언어 모델(Multimodal Large Language Model, MLLM)은 여러 벤치마크에서 강력한 성능을 보이고 있습니다. 또한, 최근에는 GRPO(Group Relative Policy Optimazation)를 도입하여 특히 비디오에서의 추론 능력을 강화하는 연구들 또한 공개되고 있으며 tool(여기서 tool은 )을 활용한 연구들도 공개되며 최근 비디오 이해를 위한 연구가 빠르게 발전하고 있습니다.
하지만, 이러한 빠른 발전 속에서 정작 모델을 평가하는 벤치마크들은 점차 saturate되고 있습니다. 벤치마크 리더보드의 성능을 지속적으로 상승하고 있지만 그 성능이 실제로 모델의 역량을 파악하고 있는지에는 의문이 있습니다. 저자가 지적하는 기존 벤치마크의 문제는 크게 두가지입니다.
- Multi-level Evaluation Hierarchy: 기존 벤치마크들은 계층적인 평가구조가 없습니다. 어떤 벤치마크들은 세밀한 동작 이해에 집중하여 평가를 진행하고, 어떤 벤치마크들은 긴 영상 이해에 집중하여 평가를 진행합니다. 저자들이 기존에 제안했었던 VideoMME 벤치마크는 여러 길이의 영상들을 다루며 범용적인 비디오 이해를 지향하지만 상대적으로 기초적인 수준의 평가라는 한계가 있습니다. VideoMME보다 복잡한 세팅의 평가를 진행하는 벤치마크들도 추후에 공개되긴 했지만 기초적인 인지능력(perception)부터 고차원 추론(reasoning)까지 아우르는 계층적인 평가 프레임워크는 여전히 부족합니다.
- Group-based Evaluation Strategy: 기존의 평가방식은 문항별 단순 정확도(per-question accuracy)에 지나치게 의존하는 경향이 있습니다. 모델이 관련된 여러 질문에 대해서 일관된 질문을 하고 있는지, 혹은 추론 과정이 실제로 논리적으로 타당한지 등을 평가할 수 없습니다. 즉, 기존의 평가 방법은 우연히 정답을 맞춘 경우와 모델이 실제로 비디오를 이해한 후에 정답에 도달한 것인지를 구분할 수 없습니다.
저자는 이러한 두가지 한계를 극복하기 위해 VideoMME-v2를 제안하며 점진적으로 난이도가 상승하는 계층적인 평가 계층 구조와 그룹 기반의 비선형 평가 전략을 제안합니다.
Benchmark Design
Progressive Capability Hierarchy
기존 벤치마크들이 각각이 하나의 능력을 독립적으로 평가하는 반면에 VideoMME-v2는 비디오 이해 능력을 3단계의 게층구조로 평가합니다. 이 계층 구조는 12개의 하위 카테고리와 30개 이상의 세부 유형으로 구성됩니다.
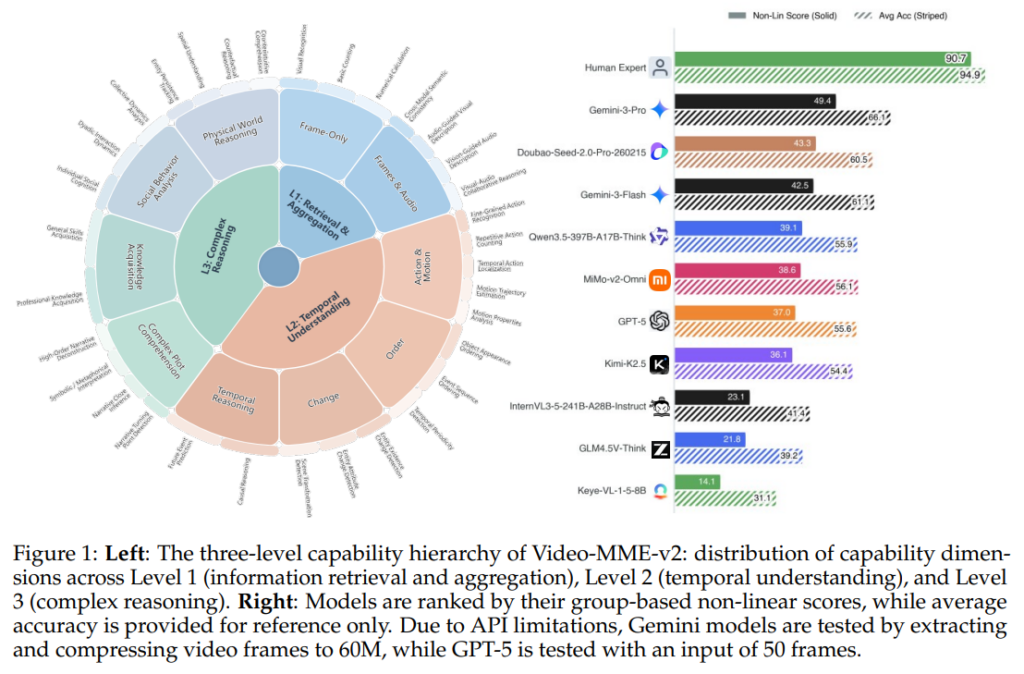
Fig 1.은 저자가 제안하는 VideoMME-v2의 3단계 계층 구조와 12개의 하위 카테고리를 보여줍니다. Level1은 Visual Information Aggregation으로 가장 기초적인 단계이빈다. 특정 시점의 정보를 통합하는 능력을 평가합니다. 이 단계는 3가지 능력을 평가합니다. 첫번째는 비디오 내 객체, 속성, 장면을 식별하는 능력인 Visual Perception입니다. 두번째는 Cross-Modal Consistency로 시각적 단서와 오디오 사이의 정합성을 판단합니다. 세번째는 Basic Counting & Calculation으로 객체의 수를 세거나 화면에 표시된 숫자를 이용한 간단한 연산을 평가합니다. 이 단계의 핵심은 비디오 프레임의 시간적 순서에 의존하지 않아도 풀 수 있는 문제들로 구성된다는 점입니다.
두번째 단계는 Temporal Dynamics로 Level 1위의 temporal evolution을 다루는 단계입니다. 세가지 sublevel로 나뉩니다. 첫번째로 Action & Motion Analysis는 모델의 움직임을 이해하고 trajectory를 추적하는 능력을 평가합니다. 두번째로 Sequential Orderging입니다. 사건이라 객체의 등장 순서를 파악하는 능력을 평가합니다. 세번째로 Causal Reasoning은 특정 사건의 원인을 파악하는 능력을 평가합니다.
세번째 단계는 Complex Reasoning 입니다. multi-hop 질문들을 요구하는 가장 고차원적인 단계입니다. 마찬가지로 세가지 sublevel로 나뉩니다. 각각 Narrative Understanding, Social Dynamics, 그리고 Physical World Reasoning입니다. Narrative Understanding은 줄거리, 메타포와 같은 비선형적인 서사 구조의 해석을 다룹니다. Social Dynamics는 dynamic interaction과 collective behavior 분석을 다룹니다. 마지막으로 Physical World Reasoning은 현실 세계의 물리적 제약에 대한 이해를 요구하는 질문입니다.
Group Type Definition
이미지 분야에서는 MME팀(저자)이 같은 질문을 두 가지 다른 방식으로 묻고 답이 각각 예/아니오가 되도록 하는 augmented group QA를 처음 도입했고 MMBench는 보기 내용을 swap시켜 답변의 안정성을 평가하는 circular evaluation 전략을 제안했습니다. 비디오 분야에서는 Video-TT가 augmented group question을 사용한 첫 벤치마크입니다. 하지만 저자는 기존의 방식들은 개별 질문의 augmentation에 집중하고 그룹 내 질문 간의 상호관계는 다루지 않는다는 것을 지적하고 있습니다. 따라서 새로 제안하는 Video-MME-v2는 perception과 reasoning 모두에 대해 관련 질문들 사이의 관계를 명시적으로 모델링하는 question group을 도입합니다. question group은 consistency-based group과 coherence-based group으로 나뉩니다.
Consistency-Based Group은 제한된 수의 질문으로 특정 능력을 평가하기 위한 그룹입니다. 저자는 consistency group을 두 차원으로 구성합니다. Breadth 차원에서는 하나의 도메인 안에서 서로 다른 reasoning 측면을 다루는 다양한 질문 유형을 설계합니다. 예를 들어 spatial understanding 도메인에서는 object localization consistency와 relative motion reasoning 질문을 함께 포함시켜 정적 및 동적 공간 이해를 평가합니다. Granularity 차원에서는 하나의 질문 유형을 여러 spatio-temporal scale에 걸쳐 확장합니다. 예를 들어 fitness tutorial 영상에서는 운동의 전역적 순서를 묻는 질문(holistic understanding)과 단일 동작 내 sub-action의 순서를 묻는 질문(fine-grained action comprehension)을 함께 구성합니다.
Coherence-Based Group은 복잡한 비디오 reasoning 과제에서 모델의 reasoning coherence를 평가하기 위한 그룹입니다. 기존 벤치마크들은 일반적으로 최종 답 만을 평가하기 때문에 모델이 진짜로 multi-step reasoning을 했는지 우연히 정답을 추측한 것인지 구분할 수 없습니다. 몇몇 연구는 intermediate reasoning content를 평가하지만 처음부터 reasoning step을 명시적으로 점검하는 평가를 구조화하지는 않았습니다. Coherence-based group의 질문 집합은 사람이 복잡한 문제를 풀 때 따라가는 논리적 진행 과정을 모방하도록 구성됩니다. 저자는 이를 clue localization, anomaly verification, purpose explanation, conclusion closure라는 hierarchical verification process로 정리합니다.
Metrics
저자는 평가지표로 per-question accuracy(AvgAcc)와 group-level non-linear score를 사용합니다. AvgAcc는 모든 문항에 대한 정답률의 평균입니다. group-level non-linear score는 4개의 질문으로 구성된 그룹 내 정답의 joint correctness pattern에 기반하여 점수가 부여됩니다. Consistency-based group의 경우(N/4)^2으로 평가되는 그룹점수는 비선형적으로 평가되어 그룹 내 정답률이 높을수록 점수가 높게 부여됩니다. Coherence-based group은 first-error truncation 방식이 적용되어 첫 reasoning step이 잘못되면 이후 정답이 맞았어도 점수를 인정하지 않습니다. 예를 들자면 1, 2 번을 맞추고 3, 4번을 틀린 경우와 1, 2, 4번을 맞추고 3번을 틀린 경우가 같은 점수를 부여받습니다.
Dataset Construction and Annotation
저자는 12명의 어노테이터와 50명의 리뷰어가 참여하여 총 3300 human-hours를 투자했다고합니다. 저자는 800개의 비디오를 수집하고 각 비디오마다 4개의 질문과 질문 당 8개의 보기로 구성했습니다. 저자는 엄격한 verification을 통해 변별력있으면서도 좋은 벤치마크를 만들 수 있도록 설계했다고 강조하고 있습니다.
Video Curation
Recency-Oriented Collection To Mitigate Leakage
데이터의 contamination의 위험을 줄이기 위해서 저자는 temporal recency에 초점을 맞춰 인터넷에서 영상을 수집합니다. 데이터셋의 80% 이상이 2025년 이후에 공개된 영상이며 약 40%는 2025년 10월 이후 영상입니다. 이러한 temporal recency는 현재 MLLM들의 사전학습에 MME-v2의 영상들이 포함되어 있을 가능성을 매우 낮게 합니다.
Diversity via A Hierarchical Taxonomy
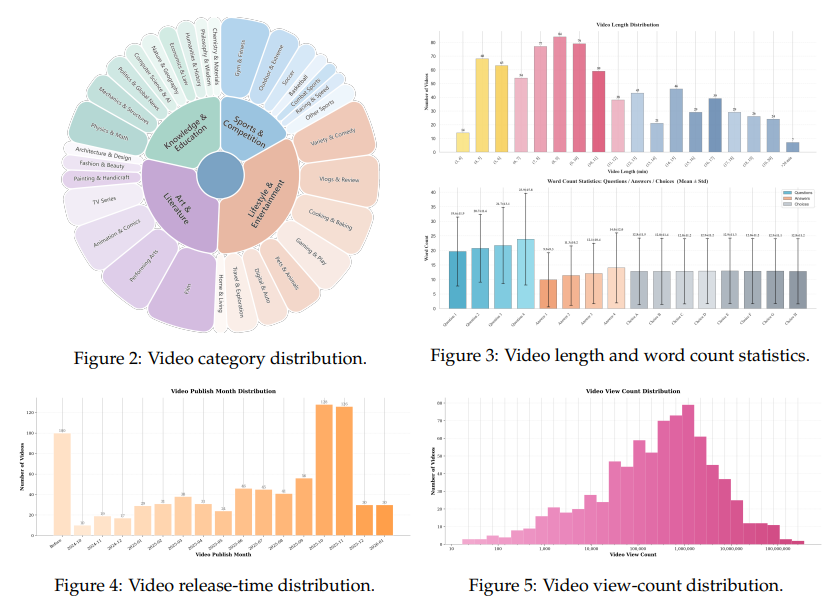
Fig. 2는 MME-v2의 카테고리를 보여줍니다. 4개의 상위 도메인과 아래의 31개의 fine-grained subcategory가 존재합니다. Fig. 3은 영상의 길이 통계와 질문, 답의 평균 길이입니다. 영상은 평균적으로 10분입니다. 질문의 길이는 Q1에서 Q4로 갈수록 길이가 길어집니다. 이는 저자의 reasoning coherence 설계 철학이 들어가있습니다. 시퀀스의 후반일수록 더 큰 logical depth를 요구하기 때문에 더 많은 맥락과 세밀한 답변이 필요합니다. 저자는 8개 보기의 평균 단어 수는 일정하게 유지하는 것으로 모델이 길이 편향을 이용해 정답을 추측하지 못하도록 합니다.
Quality Control with View-Count Thresholding
저자는 조회수를 콘텐츠 품질의 proxy로 사용합니다. 저자가 수집한 영상들의 평균 조회수는 483만 회, 중앙값은 35만 5천 회입니다. 선정된 비디오의 84.3%가 1만 회 이상, 94.4%가 1천 회 이상의 조회수를 가집니다.
Manual Decontamination.
저자는 직접 영상을 확인하고 classic film, television work, influencer의 flagship 콘텐츠를 제외합니다. 이는 모델 성능이 학습할 때의 기억을 통해 답변하는 것이 아닌 실제 perception과 reasoning을 반영할 수 있도록하기 위함입니다.
Question and Option Design
저자는 capability consistency와 reasoning coherence를 모두 보장하기 위해서 group-based construction 방식을 사용합니다. Q1에서 Q4로 갈수록 질문의 길이가 점점 길어지도록 설계하여 logical chain이 생성되도록합니다. 저자는 어노테이션을 하는 과정에서 사람이 수행하기는 했지만 Gemini 3 pro와 같은 모델을 활용하여 실시간으로 검증도 같이 수행했다고 합니다. 후보 질문은 underspecified premise, language-only shortcut 등등을 지속적으로 테스트하고 충분한 변별력을 가질 수 있도록 반복적으로 수정하며 질문, 보기를 생성했습니다. 보기는 8지선다로 기존의 4지선다 혹은 5지선다보다 더 다양한 보기를 제공합니다 이는 랜덤하게 답변을 고를때의 성능이 낮아지기때문에 모델의 성능이 랜덤성을 반영하고 있는지 아닌지를 판단하기에 더 적합합니다. 저자는 추가로 보기의 길이로 인한 편향이 생기지 않도록 보기의 길이를 비슷하게 설계했습니다.
12명의 어노테이터들이 직접 질문과 보기를 선정했다고 앞서 언급했었는데 추가로 50명의 퀄리티 검증팀을 따로 구성하여 한번 더 검토를 진행했습니다. 질문과 보기에 문제는 없는지, 퀄리티는 문제가 없는지 등을 검토합니다. 저자는 text-only baseline test, multi-round cross-validation, independent blind test를 통해 문제의 퀄리티를 검증했습니다. text-only baseline test는 Gemini 3 Pro에 비디오 없이 입력하는 것으로 편향을 제거했고 multi-round cross-validation은 서로 다른 어노테이터가 서로 검증해주는 것을 의미합니다. 마지막 independent blind test가 50명의 퀄리티 검증팀의 검토를 의미합니다.
Experiments
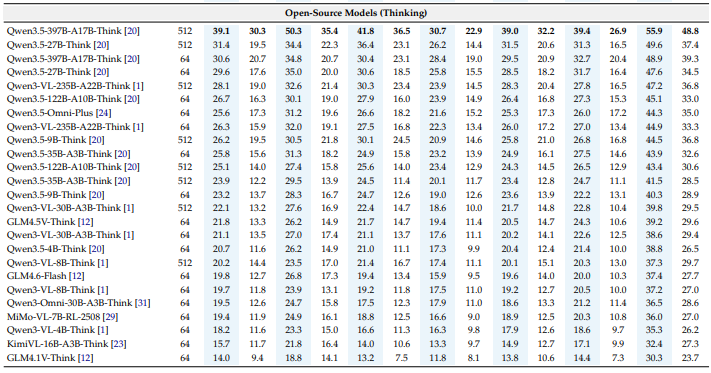
저자는 다양한 SOTA MLLM을 Video-MME-v2에 평가하였습니다. w.sub는 자막을 활용한 성능이고, wo sub은 자막을 활용하지 않은 성능입니다. Non-Lin Score는 저자가 제안하는 비선형적인 평가방식으로 기존의 accuracy와는 다르게 평가됩니다. Metrics 섹션에서 설명했었던 그룹마다 (N/4)^2의 방식으로 평가됩니다. Level 1, 2, 3는 Fig 1.에서 설명한 레벨에 해당하고 Consistency와 Coherence는 두 그룹의 성능을 의미합니다.
저자는 Commercialization 모델들의 성능이 월등히 뛰어남에 집중하고 있습니다. 저자는 이 모델들이 open-source 모델들에 비해 좋은 성능을 보이고 있으며 subtitle/audio와 같은 부가적인 정보가 없을때 open-source 모델들의 성능이 떨어지는 반면 Commercialization 모델들은 성능방어가 잘 되고 있음을 강조하고 있습니다. 다만 주의해야할 점이 frames가 다르기 때문에 성능차이가 어느정도 있을 수 있습니다. 영상의 길이가 길어질수록 1fps로 입력하는 Commercialization 모델들이 더 많은 정보를 입력받기 때문에 성능이 높을 수 밖에 없습니다. 아쉽게도 저자는 이에 대해서는 언급하고 있지 않습니다.
추가로 저자는 omni 모델에서 audio와 같은 부가 정보의 활용도가 높음을 주목합니다. 그리고 저자가 또 강조하는 것은 모델의 스케일이 성능의 유일한 결정 요인은 아니라고 주장합니다. Qwen3.5-27B-Think 모델은 Qwen3-VL-235B-Instruct보다 높은 성능을 보입니다. 저자는 단순히 모델의 스케일을 올리는 것이 비효율적일 수 있고 training recipe, data curation 등의 방법이 단순한 parameter scale보다 효율적일 수 있음을 실험 결과를 통해 확인할 수 있다고 주장합니다.
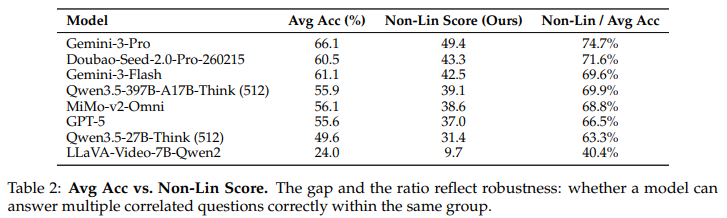
Table 2는 저자가 Avg Acc보다 저자가 제안하는 평가 메트릭인 Non-Lin Score 사이의 차이를 보여줍니다. 저자는 위 실험을 통해 일반적인 Avg Acc는 consistency와 robustness 평가에 취약하다는 것을 강조합니다.
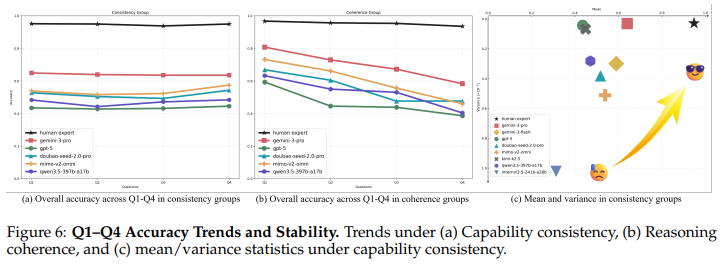
Fig. 6은 대표 모델(성능이 좋은 Gemini, GPT와 같은 모델들)의 두 그룹에서의 accuracy 경향성을 보여줍니다. 데이터의 관점으로보면 capability consistency 그룹에서는 Q1~Q4에 걸친 모델 정확도가 대체로 비슷하게 유지되는데 이는 질문 인덱스 전반에 걸쳐 난이도가 상대적으로 균형 있게 설계되었음을 의미합니다. 그에 비해 reasoning coherence 그룹에서는 모든 모델이 Q1에서 Q4로 단조 감소 경향을 보이는데 이는 저자가 의도적으로 설계한 점진적 난이도 상승과 reasoning chain을 따라 점차 엄격해지는 logical dependency를 반영한다고 볼 수 있습니다.
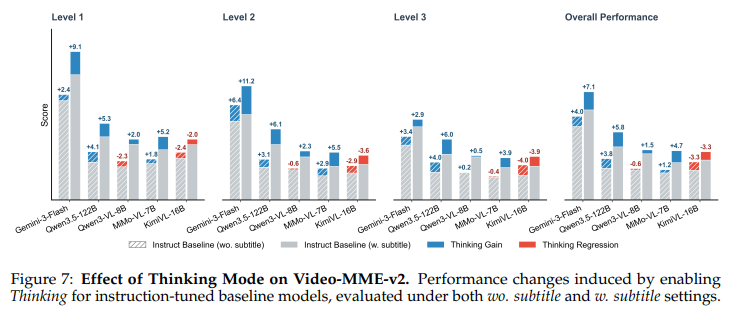
Fig 7.은 Thinking Mode의 효과를 실험 결과를 통해 확인합니다. 전반적으로 thinking 모드를 사용하는 것은 wo subtitle에서보다 w. subtitle에서 높은 성능 향상을 보입니다. 저자는 이 결과를 통해 subtitle이 reasoning mechanism의 효과를 상당히 증폭시킬 수 있음을 보여준다고 설명합니다. 일부 모델에서는 thinking 활성화 후 성능 드랍(regression)이 관찰되며 wo. subtitle 설정에서 더 두드러집니다. 저자는 이 결과가 text modality가 없는 환경에서 reasoning mechanism이 노이즈를 유발할 수도 있음을 보여주고 있다고 설명합니다.
감사합니다.
안녕하세요 성준님, 좋은 리뷰 감사합니다.
Fig 7에서 일부 모델에서는 thinking 활성화 후 성능 드랍(regression)이 관찰되며 wo. subtitle 설정에서 더 두드러지는데, 저자는 이 결과가 text modality가 없는 환경에서 reasoning mechanism이 노이즈를 유발할 수도 있음을 보여주고 있다고 설명했다고 언급하셨습니다. 그렇다면 이 벤치마크가 진정한 visual, audio 정보 기반 비디오 이해 능력을 평가하는 건지 아니면 text bias 의존성을 평가하게 되는건지 의문이 드는데, 논문에서 일종의 text shortcut을 방지하고 오디오/시각 정보만으로 복잡한 추론을 할 수 있는지 평가하는 다른 설계가 있는지 궁금합니다.
안녕하세요 이재윤 연구원님 좋은 질문 감사합니다.
저자는 text shortcut 방지를 위해 몇 가지 설계를 적용했습니다. 어노테이션 단계에서 Gemini 3 Pro에 비디오 없이 질문과 보기만 입력하는 text-only baseline test로 언어 단서만으로 풀리는 문제를 걸러냈고 language-only shortcut과 underspecified premise를 지속적으로 테스트했습니다. 또한 8지선다 보기 구성과 보기 길이 통일로 length bias를 차단했고 w./wo. subtitle 분리 평가를 통해 텍스트 의존도 자체를 측정할 수 있게 했습니다. 다만 재윤님 의문대로 이 장치들이 text bias를 완전히 제거한다고 보긴 어렵습니다. 오히려 Fig 7의 wo. subtitle에서의 regression은 벤치마크가 text bias를 평가한다기보다 현재 MLLM들이 reasoning 시 텍스트 모달리티에 얼마나 의존하는지를 드러내는 도구로 기능한다고 해석하는 게 적절해 보이며 audio-visual only subset 같은 명시적 분리 평가는 후속 연구에서 보완되어야 할 부분이라고 생각합니다.
감사합니다.