오늘은 MLLM을 Embedding 모델로 활용하는 논문을 리뷰해보려고 합니다.
방법론 자체는 어렵지 않아서, 3가지 논문 (E5-V, VLM2Vec, VLM2Vec-v2)을 큰 흐름 위주로 리뷰해보겠습니다.
1. Introduction
최근 저희 연구실에서도 거의 모든 팀에서 멀티모달 태스크를 다루고 있을텐데요, 이미지와 텍스트를 같은 공간에 묶어주는 임베딩(Embedding) 모델의 중요성은 다들 이미 충분히 아실거라고 생각합니다
불과 얼마 전까지만 해도 이 분야의 표준이라고 할 수 있던 건, CLIP을 필두로 한 듀얼 인코더(Dual-encoder) 방식이었습니다. 텍스트 인코더와 비전 인코더를 각각 두고, Contrastive Learning을 통해 두 모달리티 사이의 정렬을 맞추는 구조였습니다
하지만 멀티모달 태스크가 고도화되면서 CLIP 구조의 몇 가지 한계가 드러나기 시작했습니다.
1. 얕은 텍스트 이해도
짧은 캡션 수준의 텍스트는 잘 매칭하지만, 길고 복잡한 문서나 맥락은 제대로 이해하지 못했습니다
2. 추론 능력의 부재
“빨간 지붕 옆에 있는 파란 차”처럼 복잡한 구성적(Compositional) 관계나 논리적 추론이 필요한 검색에서는 적절하지 못한 답변을 내기 마련이었죠
이러한 문제를 근거로 최근에는 LLaVA나 Qwen-VL처럼 텍스트 이해력도 압도적이고 시각적 추론까지 해내는 생성형 MLLM을 아예 범용 임베딩 모델로 쓰는 건 어떨까? 하는 관점의 연구들이 등장하고 있습니다. 하지만 ‘다음 단어를 예측(Next-token prediction)’하도록 만들어진 텍스트 생성 모델을, 의미를 압축해 고정된 길이의 벡터를 뽑아내는 임베딩 모델로 전환하는 것은 쉬운 일은 아니었죠
따라서 이번 리뷰에서는 이 문제를 해결하기 위해 등장한 굵직한 연구들을 살펴보려 합니다.
- E5-V (Arxiv 2024.07): Universal Embeddings with Multimodal Large Language Models
- VLM2Vec & VLM2Vec-V2 (ICLR 2025, TMLR 2026): Training Vision-Language Models for Massive Multimodal Embedding Tasks
연도별로 차례대로 어떤 방법론인지 설명해보겠습니다.
2. Papers
Phase 1. E5-V: Universal Embeddings with Multimodal Large Language Models
MLLM을 임베딩 모델로 활용하려 할 때 직면하는 첫 번째 문제는 모델 내부의 ‘모달리티 갭(Modality Gap)’입니다. MLLM은 텍스트와 이미지를 모두 처리할 수 있지만, 아무런 조치 없이 임베딩을 뽑아보면 텍스트 벡터들이 모인 공간과 이미지 벡터들이 모인 공간이 뚝 떨어져서 분리되어 있었죠
이 갭을 없애려면 기존처럼 막대한 양의 이미지-텍스트 쌍 데이터를 구축하고 무거운 MLLM에 대해 다시 Contrastive Learning 시켜야 하는데, 이는 연산량 측면에서 너무 과다한 일이었죠. E5-V 저자들은 이 문제를 아주 쉬운 방법으로 해소하였는데요
1) 프롬프트(Prompt)를 통한 모달리티 갭 해소
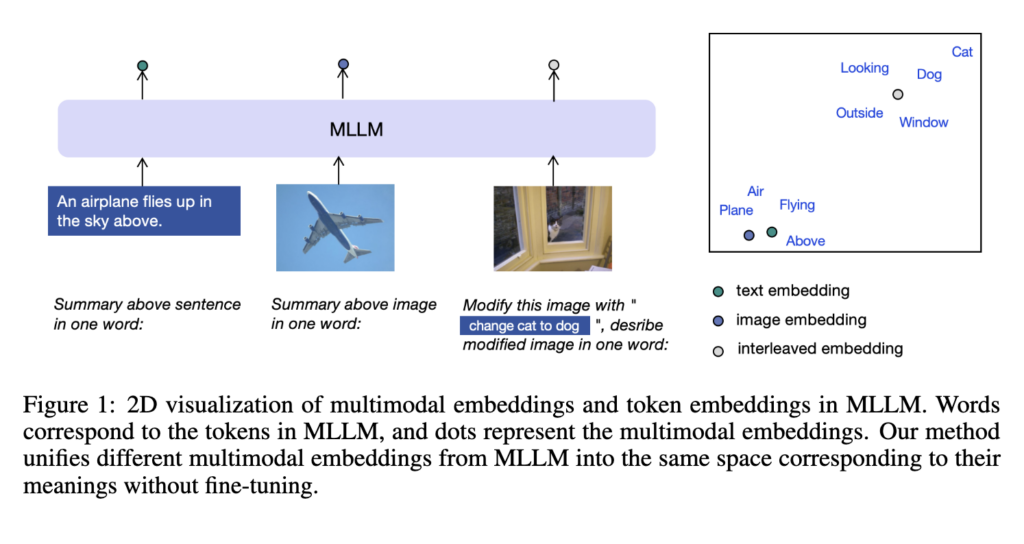
위 그림(Figure 1)처럼 프롬프트를 추가하는 것이었습니다. 즉, 단순히 이미지만 MLLM에 입력하는 것이 아니라, 명시적인 프롬프트를 함께 던져주는 것입니다. 프롬프트 예시는 아래와 같습니다
이미지 입력 시: <image> Summary above image in one word:
텍스트 입력 시: <text> Summary above sentence in one word:
이렇게 “한 단어로 요약해 줘”라는 지시를 내리면, MLLM은 이미지를 단순한 ‘시각적 특징’이 아니라 ‘의미론적(Semantic) 단어’의 관점에서 바라볼 수 있다고 합니다. 그 결과, 오른쪽 산점도에서 볼 수 있듯이 비행기 이미지 임베딩이 “Plane”, “Flying” 같은 텍스트 임베딩과 동일한 공간에 자연스럽게 섞이게 되며 모달리티 갭이 줄어들었다는 것을 보인 것이죠
2) 단일 모달리티 학습 (Single-modality Training)과 추론
프롬프트만으로 모달리티 갭이 해결된다면? 굳이 멀티모달 데이터로 학습할 필요가 없어집니다. 아래 Figure 2는 E5-V의 학습 및 추론 과정을 알 수 있습니다.
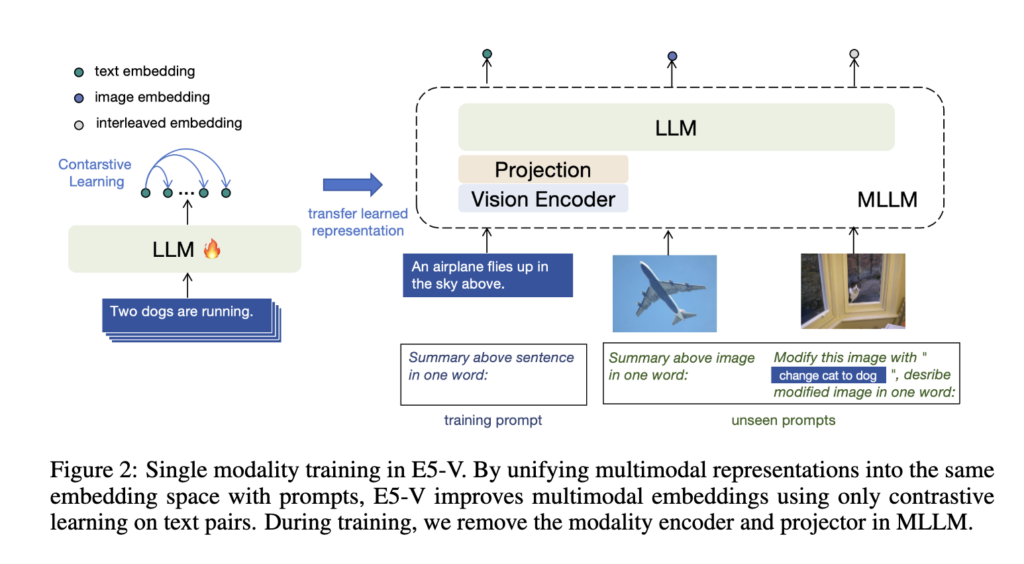
학습 (Training)
일단 프롬프트를 추가한다고 해서, 학습이 불필요한 건 아닙니다. 생성형 모델인 MLLM이 임베딩 벡터를 잘 추출할 수 있게 추가적인 학습 과정이 필요하기 때문이죠. 즉, 프롬프트는 생성형 MLLM이 임베딩을 잘 뽑아낼 수 있기 위한 보조 수단인 것이죠.
이 때, 학습은 텍스트 단일 모달리티로만 진행합니다. 기존 텍스트 임베딩 모델들이 주로 쓰는 NLI 데이터셋(텍스트 쌍)만 사용하여 Contrastive Learning을 수행하죠. 이 때, 이미지 정보는 불필요하니학습 중에는 아예 비전 인코더와 프로젝터를 제거합니다. 덕분에 멀티모달 학습 대비 학습 시간을 엄청나게(34.9시간 -> 1.5시간) 단축하며 연산량 문제를 해결하였습니다.
추론 (Inference)
학습 때 단 한 장의 이미지도 보지 않았지만, 앞서 살펴본 프롬프트를 사용하여 텍스트와 이미지를 동일한 공간의 고정된 벡터로 추출해내는 능력을 가지게 됩니다. 심지어 학습 때 본 적 없는(Unseen) 프롬프트를 주더라도 모델이 지시를 잘 따를 수 있었다고 합니다.
3) 핵심 결과
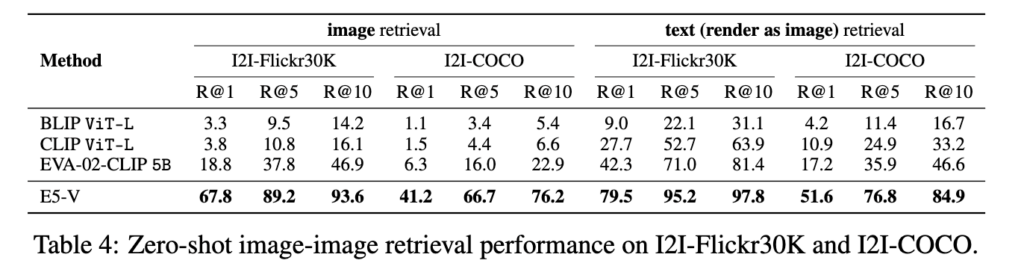
가장 놀라운 점은 Table 1에서 보여주는 Zero-shot 검색 성능입니다.
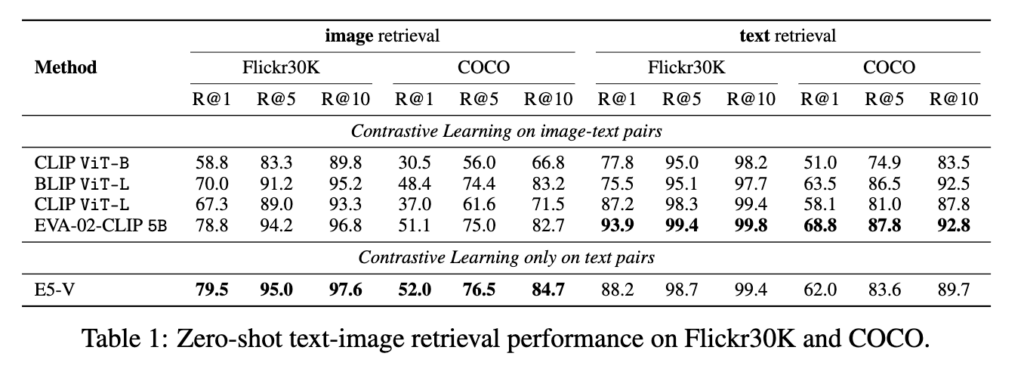
E5-V는 임베딩 튜닝 과정에서 멀티모달 데이터를 일절 사용하지 않고 텍스트 쌍만으로 학습했음에도 불구하고, 수많은 이미지-텍스트 쌍으로 학습한 5B 파라미터 크기의 베이스라인인 EVA-02-CLIP과 비교해도 오히려 더 높은 제로샷 이미지 검색 성능을 보여주었습니다. 특히, E5-V와 동일한 비전 인코더를 사용하는 CLIP ViT-L과 비교했을 때 성능 격차는 월등했습니다
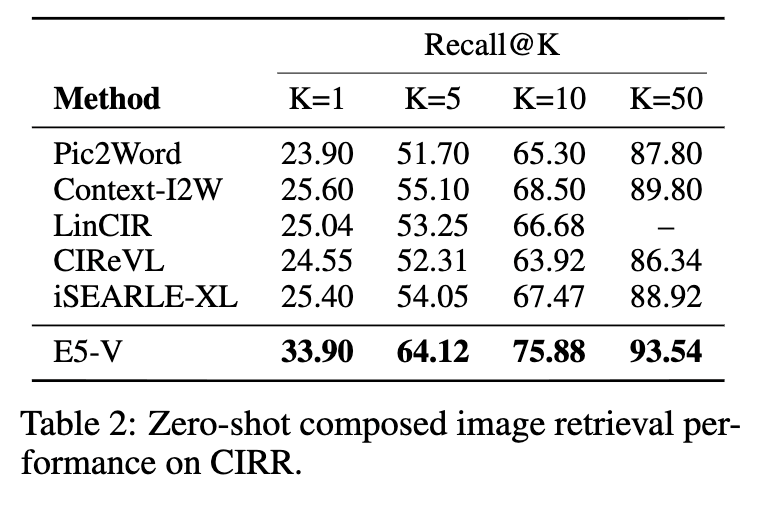
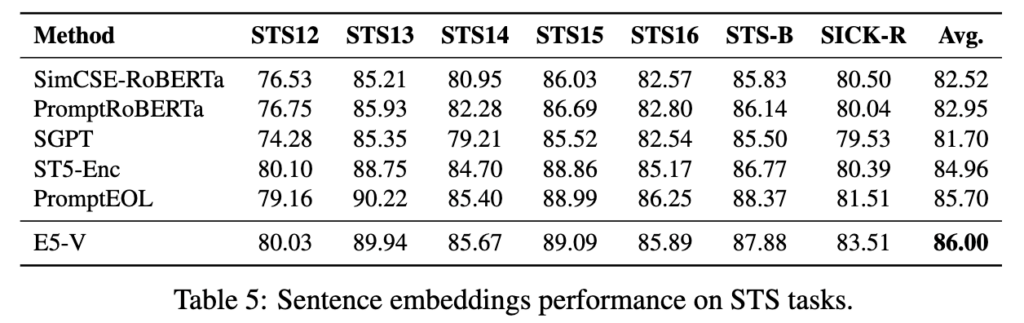
그 외에도, 아래 테이블처럼 Composed Image Retrieval (CIR), Image-Image Retrieval, Sentence Embeddings 이라는 다양한 태스크에서도 높은 성능을 보이며 프롬프트 만으로 MLLM을 임베딩 모델로 활용하는 것이 효과적임을 보였습니다.
정리하면 E5-V 모델은, 잘 설계된 프롬프트와 단일 모달리티 학습만으로도 생성형 MLLM을 훌륭한 범용 임베딩 모델로 만들 수 있다는 것을 처음으로 입증한 셈이죠. 실제로 이 뒤로 MLLM에게 ‘한 단어로 요약해줘’ 라는 프롬프트를 사용하여 임베딩 벡터를 만드는 어찌보면 표준처럼 사용되고 있습니다.
Phase 2. VLM2Vec & VLM2Vec-V2
앞서 E5-V가 프롬프트와 텍스트 단일 학습만으로 MLLM을 임베딩 모델로 쓸 수 있다는 가능성을 보여주었다면, VLM2Vec은 여기서 더 나아간 방법을 제안하였는데요. E5-V처럼 단순히 “요약해 줘”라고만 할 것이 아니라, 수많은 종류의 태스크마다 명확한 작업 지시어(Instruction)를 주고, 실제 멀티모달 데이터로 대조 학습을 시켜 완벽한 범용 임베딩 모델을 만들자!라는 것이 이 논문의 핵심입니다.
VLM2Vec은 버전 1과 버전 2로 나뉘어 제안되었는데, 특히 어떻게 임베딩을 추출(추론)하고, 어떻게 대규모로 학습시켰는지 그 구체적인 메커니즘을 중심으로 살펴보겠습니다.
1) VLM2Vec (버전 1): VLM을 범용 임베딩 모델로 변환
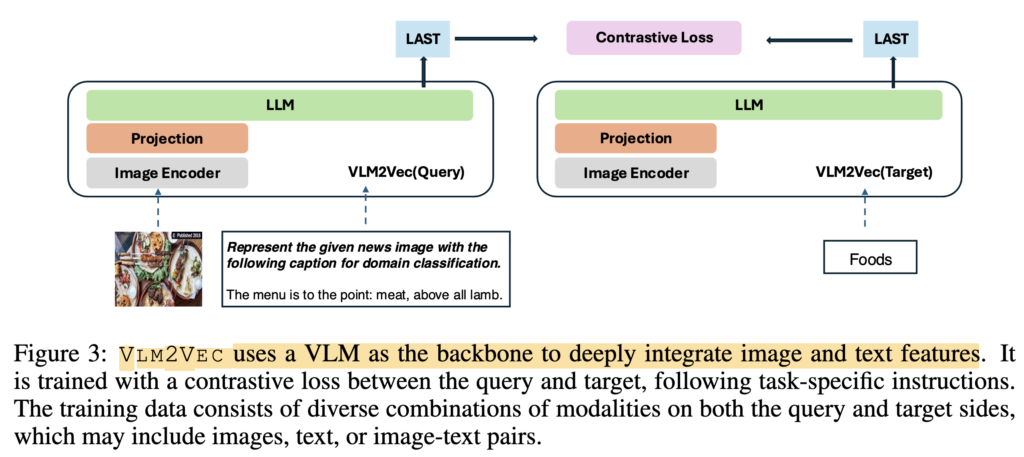
상단 그림(Figure 3)에서 VLM2Vec의 핵심 추론 및 학습 방식을 확인할 수 잇습니다. 기존 CLIP은 이미지와 텍스트를 각각 독립된 인코더로 처리했지만, VLM2Vec은 텍스트와 이미지가 섞인 어떤 형태의 입력이든 LLM 하나로 깊게 Deep fusion하여 처리하게 되었죠
추론(Inference) : Task Instruction & LAST Token
그림을 보시면 입력값 앞에 명시적인 작업 지시어가 붙어 들어가는 것을 볼 수 있습니다. (예: [IMAGE_TOKEN] Instruct: {이 이미지에서 빨간 사과를 찾아줘} \n Query: {입력 이미지}). 이렇게 모델을 통과시킨 뒤, 텍스트를 생성하는 대신 모델의 가장 마지막 토큰(LAST Token)에서 나오는 벡터를 추출합니다. 이 마지막 토큰 하나에 이미지, 텍스트, 그리고 지시어의 맥락이 모두 압축된 최종 임베딩 벡터가 담기는 것이죠.
다시 말해, 단순히 이미지와 텍스트를 묶는 것이 아니라, 명시적으로 ‘Task Instruction‘을 프롬프트에 포함시키는 방법이죠. 이 방식 덕분에 텍스트 단독, 이미지 단독, 혹은 텍스트+이미지 조합 등 어떤 형태의 입력이 들어와도, 모델이 지시어의 목적을 파악하고 그에 맞는 고정된 차원의 벡터로 압축할 수 있게 되었다고 합니다.
학습(Training) : 대조 학습과 GradCache
학습은 위에서 추출한 Query 벡터와 Target 벡터 간의 코사인 유사도를 구하여, Contrastive Learning을 수행합니다. 이를 위해 분류, VQA, 검색 등 36개 데이터셋으로 구성된 MMEB 벤치마크를 구축했습니다.
그런데 여기서 문제가 발생하였는데, Contrastive Learning은 배치 크기(Batch size)가 클수록 성능이 오르는 경향이 있습니다. 하지만 무거운 VLM에 이미지까지 태워서 배치를 키우면 당연히 OOM(out of memory)이 발생하겠죠. 저자들은 이 문제를 해결하기 위해 GradCache라는 그래디언트 캐싱 기법을 도입했습니다. 메모리에 올릴 수 있는 작은 서브 배치 단위로 그래디언트를 계산해 캐싱해두고 나중에 합치는 방식으로, GPU 메모리 한계를 뚫고 배치 크기를 무려 1024까지 늘려 대규모 멀티모달 학습을 수행할 수 있었다고 합니다
2) VLM2Vec-V2: 인터리브 서브-배칭 (Interleaved Sub-batching)
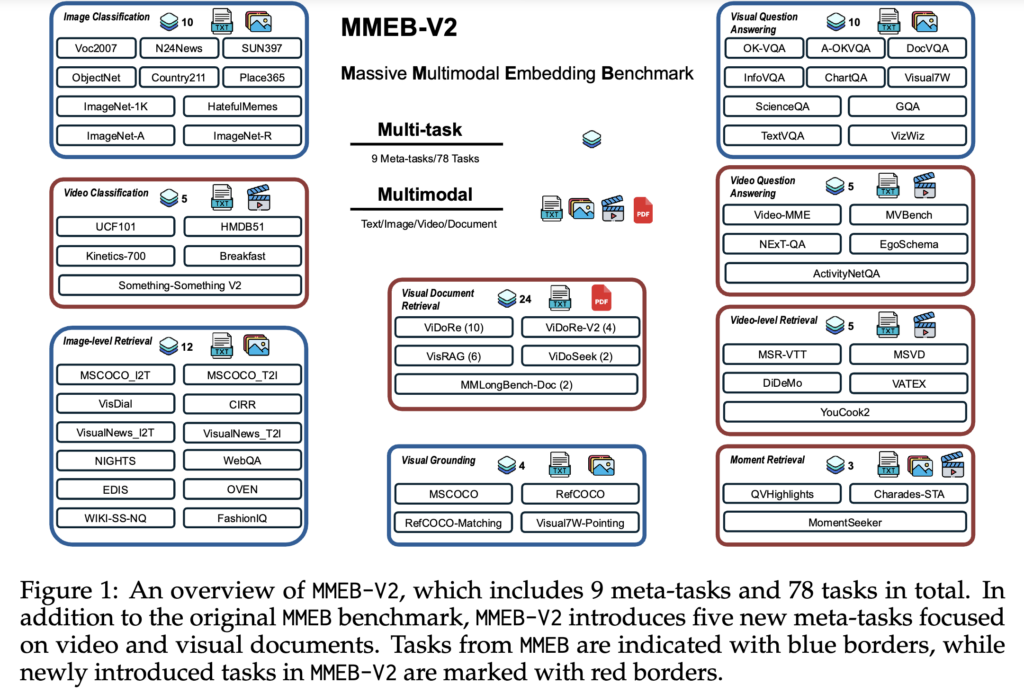
VLM2Vec v1 을 통해 어느정도 성능을 개선했지만, 여전히 처리할 수 있는 모달리티가 이미지에만 갇혀 있다는 한계가 있었습니다. 실제 환경에서는 PDF, 웹사이트 캡처, 비디오 등 훨씬 복잡한 데이터가 존재하는데 말이죠.
따라서 상단 그림(Figure 1)의 빨간 테두리에서 보이는 것처럼, 저자들은 V2에서는 비디오 검색, 시각적 문서(PDF 등) 검색 태스크를 대거 추가해 총 78개의 데이터셋(MMEB-V2)으로 벤치마크를 확장했습니다. 이를 소화하기 위해 다양한 해상도와 시공간 정보를 잘 파악하는 Qwen2-VL로 백본 모델을 교체했죠.
왜? 찌그러진 PDF 표나 시간 흐름이 있는 비디오 프레임을 처리하기 위해, 다양한 해상도의 입력값을 동적으로 처리하고 시공간 정보(M-ROPE)를 잘 파악해야했기 때문입니다. 그래서 당시 가장 성능이 좋은 Qwen2-VL로 백본 모델을 교체하였다고 합니다.
데이터가 78종류나 되다 보니 학습 전략이 매우 중요해졌습니다. 배치를 마구잡이로 섞으면 모델이 정답을 너무 쉽게 맞히고, 한 종류로만 채우면 학습이 불안정해집니다. 그래서 도입한 것이 ‘인터리브 서브-배칭(Interleaved Sub-batching)’ 입니다.

우선, 전체 배치(1024)를 64 크기의 작은 ‘서브 배치’들로 쪼갭니다. 하나의 서브 배치 안에는 오직 동일한 출처의 데이터(예: 영수증 문서들만)로 채워서 모델이 미세한 차이를 구분하도록 학습 난이도를 올립니다. 그리고 이 서브 배치들을 전체 배치 안에서 교차(Interleaving)시켜서 한 스텝 안에서 다양한 태스크를 경험하게 만들어 학습 안정성을 확보하였다고 합니다. Table 4 를 보시면 이 서브 배치 크기를 조절함에 따라 비디오/문서 성능이 오르는 것을 볼 수 있습니다.
3) 핵심 결과
결과 부분은 V1과 V2 논문에서 가장 중요한 테이블을 하나씩 보면서, 이 모델이 어떻게 진화했는지 수치로 확인해 보겠습니다.
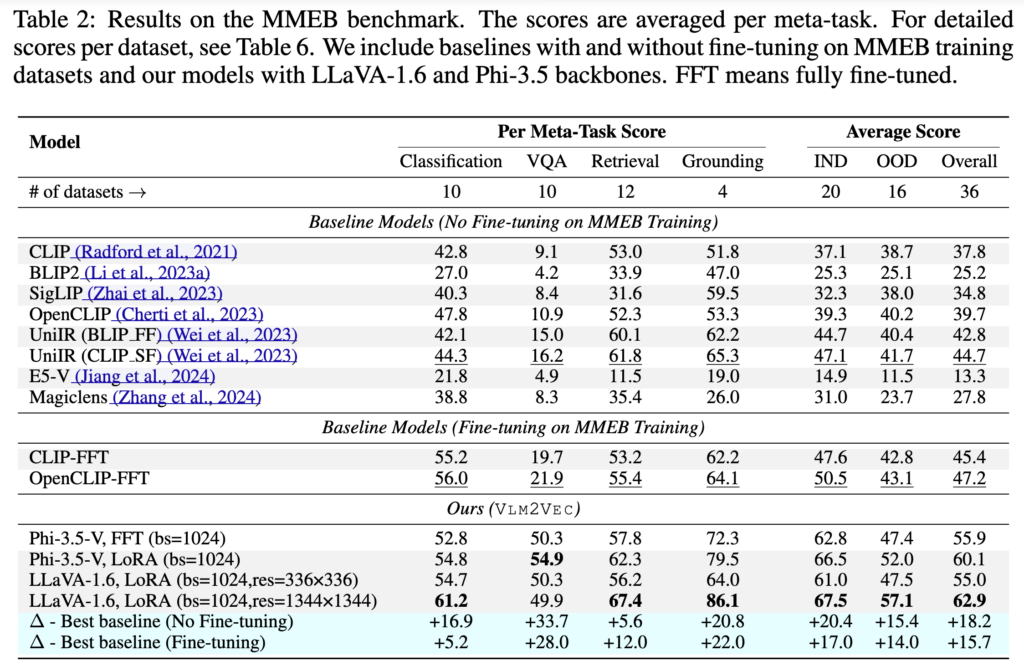
첫 번째로 볼 결과는 VLM2Vec (V1)의 Table 2입니다. 이 표를 통해 저자들은 기존 CLIP 방식과 작업 지시어 (task instruction) 를 사용한 VLM의 범용성 차이를 확인하고자 하였습니다. 표에서 가장 우측에 있는 OOD (Out-of-Distribution) 열을 보면, (OOD는 모델이 학습할 때 한 번도 보지 못한 완전히 새로운 태스크)
기존 최고 모델인 CLIP을 MMEB 데이터로 파인튜닝한 버전(CLIP-FFT)의 제로샷 성능이 43.1점에 그친 반면, VLM2Vec(LLaVA-1.6, LoRA)은 57.1점을 보였습니다. 무려 14.0%나 성능이 오른 것이죠. 전체 36개 태스크 평균으로도 62.9점이라는 압도적인 차이를 보였습니다. 이는 MLLM에 task instruction을 주면, 처음 보는 태스크의 의도까지 파악해서 알아서 임베딩해 낸다는 것을 보여줍니다.
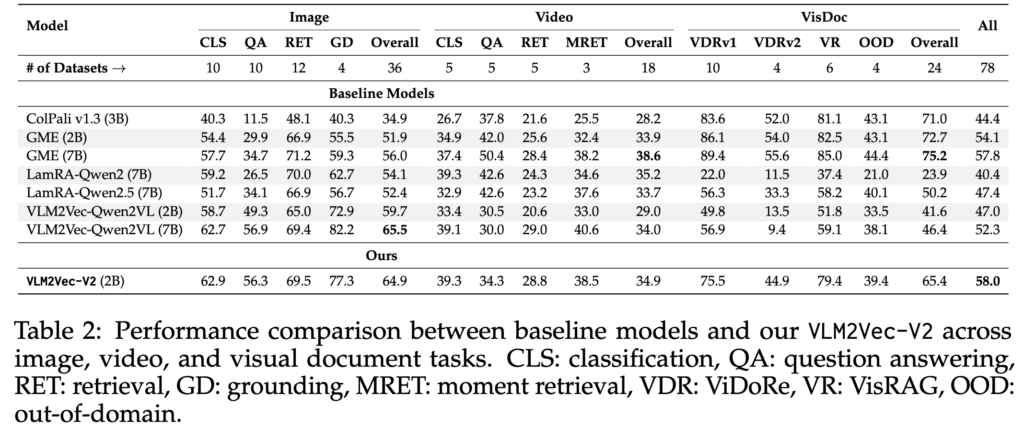
두 번째는 VLM2Vec-V2 논문의 Table 2입니다. V1이 훌륭했지만, 비디오나 복잡한 문서 앞에서도 잘 동작했을까요? 이 표에서는 상단의 Video와 Vis Doc 열을 비교해보면 될 것 같습니다.
동일하게 Qwen2-VL 백본을 사용했더라도, 기존 V1 방식(VLM2Vec-Qwen2VL 2B)으로 학습한 모델은 Vis Doc Overall에서 41.6점에 머물렀습니다. 하지만 서브-배칭 전략을 비롯해 V2의 방식으로 학습한 모델(VLM2Vec-V2 2B)은 65.4점으로 성능이 대폭 상승했습니다. 78개의 전체 태스크 평균(Overall)에서도 58.0점이라는 최고 성능을 달성하며 비디오와 문서까지 커버가 가능함을 보여줬습니다.
결론적으로 이 두 표를 통해, task instruction 도입으로 일반화 성능을 향상시켰고(V1), 정교한 데이터 샘플링 전략으로 비디오와 문서라는 복잡한 모달리티까지 확장할 수 있었다(V2) 고 해당 연구를 정리할 수 있을 것 같습니다.
3. Conclusion
이렇게 해서 MLLM을 범용 임베딩 모델로 전환하는 굵직한 연구 흐름을 살펴보았습니다. 오늘 리뷰한 내용을 짧게 요약해 보겠습니다.
E5-V
멀티모달 데이터 없이 텍스트 단일 학습만으로도, ‘프롬프트‘로 MLLM의 모달리티 갭을 허물고 임베딩 모델로 쓸 수 있음을 확인.
VLM2Vec (V1)
단순 프롬프트를 넘어 Task Instruction를 본격적으로 도입했고, GradCache 기술을 통해 대규모 멀티모달 Contrastive Learning 을 통해 일반화 성능을 향상시킴.
VLM2Vec-V2
‘인터리브 서브-배칭(Interleaved Sub-batching)’과 Qwen2-VL 백본을 결합하여, 단순 이미지를 넘어 비디오와 복잡한 문서(PDF)까지 아우르는 임베딩 모델을 제안.
생각보다 간단하죠? 물론 한계점도 기존 CLIP 같은 가벼운 듀얼 인코더 모델들에 비해, 2B~7B에 달하는 무거운 생성형 MLLM을 매번 통과시켜야 하므로 Inference Cost와 Latency 문제가 반드시 뒤따른다는 점입니다. 그렇다고 경량화가 주된 연구로 포커싱되기엔 아직 발전할 방향성이 많은데요. 이미지 말고 비디오에서는 어떤식으로 확장했는지도 알아보면 좋을 것 같습니다.
안녕하세요 주영님 좋은 리뷰 감사합니다
VLM2vec 학습 부분에서 질문이 있어서 댓글 남깁니다
배치를 무작위로 섞으면 모델이 쉽게 정답을 맞힌다고 말씀해주셨는데 혹시 그 이유를 알 수 있을까요?
무작위로 학습하는게 기본적인 학습 데이터 구성 방법으로 친숙해서 질문 드립니다.
감사합니다
좋은 질문 감사합니다.
Q. 배치를 무작위로 섞으면 모델이 쉽게 정답을 맞힌다는 이유?
-> 핵심은 배치 내 Negative 샘플 난이도 때문이라고 할 수 있을 것 같은데요.
V2 학습 데이터는 영수증(문서), 강아지 사진, 요리 비디오 등 형태가 다양합니다. 여기서 Contrastive learning 은 동일 배치 안에 있는 다른 데이터들을 negative로 활용하는데,
완전히 랜덤으로 섞어버리게 되면 “이 영수증에 맞는 이미지를 찾아줘”라는 문제의 오답으로 ‘강아지 사진’이나 ‘요리 비디오’가 나오게 되는거죠. 그럼 모델은 텍스트를 파악하지도 않고 ‘형태만 대충 보고 하얀색 문서’ 를 정답으로 출력하는 문제가 발생할 수 있다고 합니다.
따라서 비슷한 데이터(e.g. 영수증만 64개)끼리 서브 배치로 묶어서, batch 안에 있는 positive 를 제외한 negative pair들을 아주 헷갈리눈 Hard Negative 만들어 모델이 미세한 차이까지 확실하게 학습하도록 한 것입니다!
안녕하세요 주영님 리뷰 잘 읽었습니다!
mllm을 임베딩모델로 써보자라는 관점이 신기하면서도 결론부분에 언급하신것 처럼 감당가능한가? 하는 생각도 들고, 근데 또 이런 관점으로 접근하면 벡본에 따라 비디오 쪽으로도 넓힐수 있다는게 인상적이기도 했습니다
제가 이번에 리뷰한 논문도 텍스트로 비디오를 설명할때 필요한 부분을 더 설명하도록 쿼리를 함께 넣어주는게 핵심이였던 논문인데, 리뷰해주신 VLM2Vec (버전 1)부분도 llm 모델이 지시어의 목적을 파악하고 그 목적에 더 잘 맞는 표현을 출력한다는 맥락이 비슷한것 같았습니다. task instruction 단순히 마냥 프롬프트 하나 띨롱 추가 수준이 아니구나 하고도 생각하게 되었습니다.
혹시 주영님께서는 비디오처럼 비용부담이 불가피한 영역에서도 이 멀티모달을 활용한 임베딩이 앞으로 꽤 확장성 있는 방향이라고 보시는지 궁금합니다!
네, 말씀해주신 대로 Task Instruction은 이제 단순한 프롬프트를 넘어, 모델에게 어디에 집중해야 할지 직접적으로 알려주는 역할을 하는 것 같습니다.
Q. 비디오처럼 비용 부담이 불가피한 영역에서도 MLLM 임베딩이 확장성 있는 방향일까?
-> 결론부터 말씀드리면, 당장의 연산량 부담은 있지만 결국 이 방향으로 갈 것 같다고 생각합니다.
비디오는 단순한 이미지의 나열이 아니라 ‘시간적 흐름’과 ‘복잡한 인과관계’까지 포함되어 있죠. 그러다보니 기존 CLIP처럼 프레임만 결합하는 방식으로는 이를 임베딩 벡터 하나에 담아내기 어렵기 때문에, MLLM 수준의 Reasoning 능력이 개입되어야만 제대로 된 검색이나 QA가 가능해지지 않을까 생각이 듭니다.
그리고 비용 문제는 결국 시간이 해결해주지 않을까 싶은데요,
실제로 백본 경량화나 토큰 압축 등 비디오 처리에 있어 연산량을 줄이는 연구는 계속 진행되고 있따는 것이 그 근거라고 생각합니다.