안녕하세요, 이번주는 VLA의 action steering이 되는가?에 대한 분석을 담은 연구를 리뷰해보려고 합니다. LLM 쪽에선 action steering이 활발하지만, VLA 쪽에서는 멀티모달 입력이나 closed-loop로 실제 로봇이 상호작용 해야하는 점 때문에 LLM의 연구를 그대로 옮겨오기 어려워 연구들이 넘어오지 못하고 있다고 합니다. 그런 의미에서 VLA의 내부 표현을 직접 건드려서 로봇 행동을 원하는 방향으로 조정할 수 있는지, 그리고 그 조정이 closed-loop 로봇 제어에서도 자연스럽고 안정적으로 작동하는지에 대해 알아본 연구입니다. 리뷰 시작해보도록 하겠습니다.
Introduction
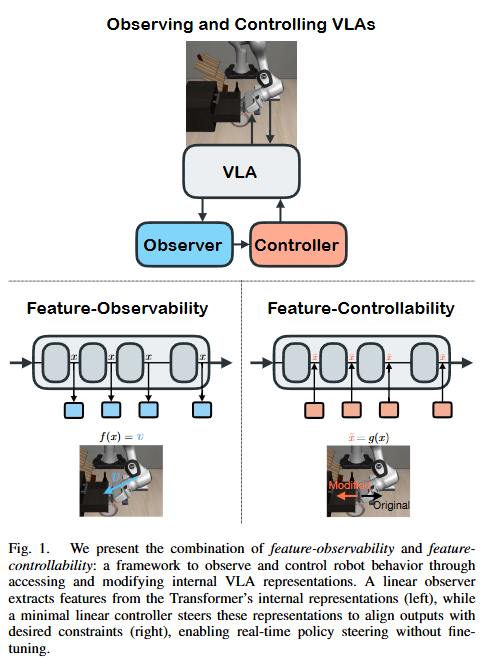
최근 로봇 공학에서는 이미지, 언어, 물리적 상태를 한 번에 이해하고 행동하는 VLA 모델이 큰 주목을 받고 있습니다. 하지만 챗GPT가LLM들에게 hallucination이 발생하는 것처럼, VLA도 결국 생성형 모델이기 때문에 행동을 예측하기 어렵고, 이는 실시간으로 교정하기 힘들며, 인간의 안전 기준을 벗어날 수 있다는 치명적인 한계가 있다고 합니다. 텍스트는 틀리면 지우면 되지만, 로봇의 실수는 현실 세계의 물리적 사고로 이어지기 때문에 저자들은 이 문제가 매우 중요하다고 합니다. LLM 쪽에서는 hallucination 해결을 위해 모델을 처음부터 다시 학습시키지 않고, 추론하는 과정에서 신경망 내부의 활성화 값을 steering 하면서 원하는 대답을 유도하는 activation steering 연구들이 진행되고 있다고 합니다. 하지만 LLM과 비슷한 구조를 가진 것 처럼 보이는 VLA에는 이 기술을 쉽게 쓸 수 있지 않다고 합니다. VLA는 항상 여러 모달리티를 처리해야 하고, 현실 세계에서 closed-loop interaction을 해야하기 때문입니다. 따라서 기존 VLA쪽 activation steering 연구들은 로봇의 속도나 방향을 강제로 바꾸는 데 그쳐, 행동이 부자연스러워지거나 모델이 원래 가지고 있던 유연한 능력이 망가지는 경우가 많았다고 합니다. 따라서 저자들은 VLA가 학습한 원래의 자연스러운 행동 능력을 해치지 않으면서 제어 목표를 달성할 수 있는 프레임워크와 방법론을 제안했습니다. 논문의 핵심 contribution은 정리하면 다음과 같습니다.
- feature observability와 feature controllability라는 개념을 통해 내부 표현을 통해 로봇의 action과 연결지을 수 있는 feature가 있다면 어떻게 찾는지, 그것을 수정할 수 있는지에 대한 방법론을 제안함
- transformer layer에서 복잡한 연산 없이 의미있는 feature extraction이 가능한 linear observer를 제안함
- 해당 observation feature들을 기존의 지식을 해치지 않으면서 control할 수 있는 linear controller를 제안
- 해당 observer와 controller를 실제 closed-loop policy에 합칠 수 있는 online 알고리즘 제안
- 다양한 VLA 아키텍쳐에서 제안한 프레임워크 검증
Problem Statement
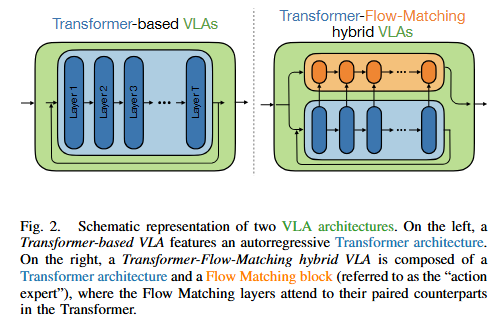
저자들은 먼저 VLA를 OpenVLA와 같은 transformer-based VLA와 pi 0.5와 같은 transformer–flow-matching hybrid VLA로 구분지었습니다. 전자는 vision encoder와 language model backbone을 통해 action token을 autoregressive하게 생성하고, 후자는 transformer가 멀티모달 문맥을 처리한 뒤 action expert transformer가 conditional flow matching을 통해 연속 action trajectory를 생성합니다. 저자들은 이 둘이 구조는 다르지만, 두 계열 모두 공통적으로 transformer representation을 핵심 내부 상태로 갖고 있다는 점에서 문제를 공통된 틀로 다룰 수 있다고 합니다.
저자들은 이러한 VLA에서 입력 시퀀스 S가 embedding map E를 통해 초기 hidden state x0로 바뀌고, 이후 T개의 transformer layer를 거치며 x1,x2,…,xT라는 representation sequence로 바뀐다고 합니다. 이 representation 안에 로봇 행동과 관련된 중요한 feature가 담겨 있다고 가정하고 연구를 진행했다고 합니다. 해당 feature는 로봇의 state나 action들이고, 최종 output인 액션 a는 이 내부 representation들로부터 계산된다는 가정도 있었습니다. Transformer-based VLA에서는 주로 최종 layer representation xT가 중요하고, hybrid VLA에서는 intermediate representation까지 action generation에 영향을 미칠 수 있다고 합니다. 다만 둘 다 핵심은 action이 결국 내부 representation을 통해서 생성된다는 점입니다.저자들은 이를 구조화 하고 연구하기 위해서 feature-observability와 feature-controllability라는 개념을 도입했습니다. Feature observability는 어떤 layer의 activation xl에서 관심 feature 를 복원할 수 있는 mapping f가 존재한다면, 그 feature는 해당 layer에서 observable하다고 정의합니다. 말하자면 hidden state만 보고도 action 관련 feature 정보를 읽어낼 수 있다면 observable하다고 생각하면 될 것 같습니다. Feature-controllability는 어떤 controller g를 통해 representation을 수정했을 때, 이후 레이어를 거쳐 생성된 feature가 원하는 집합 D 안에 들어가도록 만들 수 있다면, 그 feature는 controllable하다고 정의한다고 합니다. 저자들은 이런 구조를 통해서 VLA steering을 heuristic activation이 아니라 관측 가능한 feature를 representation space에서 제어하는 문제로 정의했다고 하빈다. 저자들은 이런 feature들을 관측과 컨트롤이 가능한 linear map을 제안했습니다.
Feature Observer

저자들은 입력 시퀀스 s가 embedding map E를 거쳐 초기 hidden state x0이 되고, 이후 각 transformer layer L을 통과하며 x1,x2,…,xT라는 representation sequence를 만든다고 합니다. 그리고 이 각 레이어의 latent representation xℓ 안에 행동에 중요한 feature가 이미 인코딩되어 있다고 가정합니다. 이 때 feature는 로봇의 state와 action입니다. Observer는 말하자면 어떤 레이어의 hidden state만 보고도 로봇의 현재 상태나 행동 관련 값을 읽어낼 수 있는 함수라고 생각하시면 될 것 같스빈다.
저자들은 observer를 각 레이어마다 하나의 선형 함수로 두었다고 합니다. f(x) = wx+b 형식의 선형 함수이기 떄문에 w와 b만 학습한다고 합니다. 이 설계는 LLM쪽 해석 분야에서 사용되는 linear separability hypothesis를 기반으로 했다고 합니다. hidden representation의 특정 방향이나 부분공간에 의미 있는 정보가 선형적으로 드러난다면, 굳이 무거운 비선형 head를 쓰지 않아도 선형 probe만으로 상당한 정보를 복원할 수 있다는 가정이라고 하네요.
앞에서도 말했듯 관심 feature는 robot states, actions입니다. 구체적으로 robot state는 𝑠=(𝑥,𝑦,𝑧,roll,pitch,yaw,gripper)입니다. action은 이 state space에서의 상대 변위로 둡니다. 저자들은 이렇게 정의된 robot state와 action이 로봇 시스템의 가장 기본적인 observation/control space이고, 직접 측정 가능하며, 다양한 manipulation task에 자연스럽게 일반화되기 때문에 이렇게 설정했다고 합니다.
Observer를 학습하는 방식은 알고리즘 1에 대한 수도코드로 나와있습니다.labeled dataset 이 주어졌을 때, 각 샘플 입력 s(i)를 원하는 레이어까지 forward하여 activation을얻고, 이렇게 모은 activation–feature pair로 각 레이어별 observer를 따로 학습한다고 합니다. 저자들은 observer가 모든 레이어에 공통인 하나의 probe가 아니라, 레이어마다 따로 학습된 probe bank라고 합니다. 따라서 이 중에서 각 feature마다 가장 잘 반영하고 있는 레이어를 따로 찾습니다.
더 나아가서 저자들은 observer가 단순히 맞추기만 해서는 부족하다고 합니다. 어떤 레이어에서 probe 성능이 높더라도, 아주 작은 perturbation에 대해 예측 feature가 wildly unstable하면 제어에 쓰기 어렵기 때문입니다. 따라서 저자들은 observer를 찾은 뒤, representation에 empirical robustness를 따로 확인해주었다고 합니다. 실험 내용은 아래에 담겠습니다.
Feature controller

저자들은 feature controller를 g(x) = x + u 형태의 additive perturbation으로 두고, 여기서 핵심은 u를 어떻게 정하는지가 중요하다고 합니다. U를 사전 정의된 direction이나 임의의 벡터로 두지 않고, 현재 representation이 observer를 통해 읽힌 결과를 원하는 feature로 바꾸는 벡터로 정의했다고 합니다. 이렇게 해서 representation 자체를 크게 바꾸는 것이 아니라, observer가 읽는 feature 값이 원하는 조건을 만족하도록 하면서도 원래 representation을 최대한 덜 건드리는 쪽으로 steering이 가능하다고 합니다. u는 아래와 같이 정의되었스빈다.
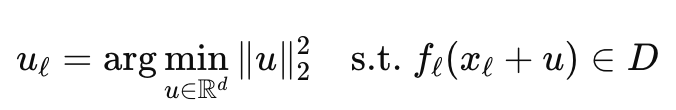
여기서 D는 control해서 나온 결과로 원하는 feature 값의 집합이고, f_l은 앞서 학습한 observer입니다. 목적은 현재 hidden representation xℓ이 원하는 범위인 D 밖에 있다면, 가능한 한 조금만 바꾸면서, observer가 읽어내는 feature 값을 원하는 범위 안으로 들어오게 만들어라는 식이라고 합니다. 이를 통해서 원래 가지고 있는 base policy의 능력을 최대한 살릴 수 있다고 합니다. 알고리즘 보실때 아래 숫자에 대한 내용을 넣어서 보시면 이해가 될 것 같습니다. 추가적인 내용은 댓글 부탁드립니다,, 하하
(1): 입력을 초기 latent로 변환
(2): 레이어를 지나며 latent를 업데이트
(3): latent에서 feature를 읽는 observer
(4): observer를 학습하는 목적하무ㅅ
(5): latent에 intervention을 더하는 controller
(6): 원하는 feature 조건을 만족하는 최소 intervention 최적화
(7): 최적화의 closed-form 해Experiments
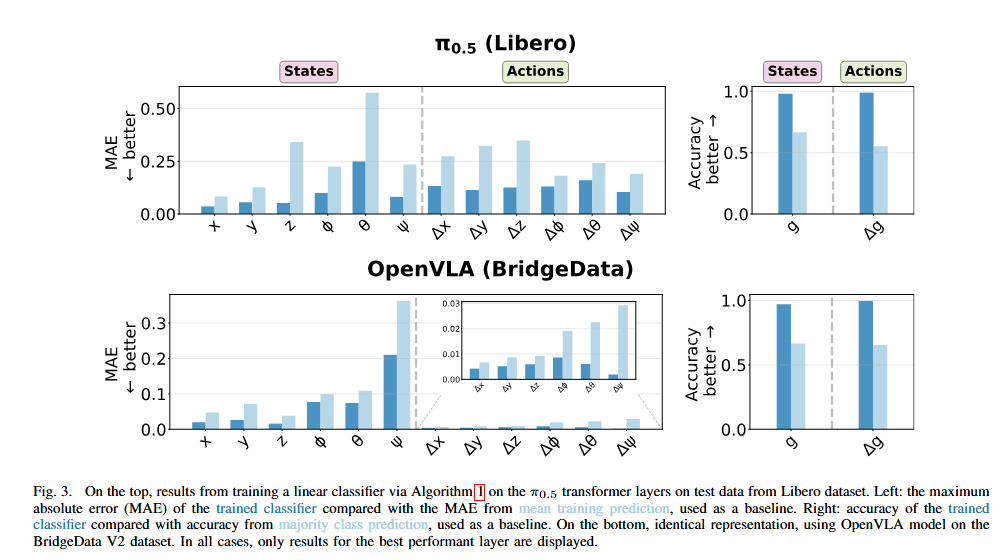
Figure 3은 저자들이 각 레이어마다 observer를 학습한 뒤, 가장 잘 되는 레이어의 결과만 뽑아서 보여준 그림입니다. π0.5는 Libero 데이터셋, OpenVLA는 BridgeData V2에서 평가했고, 위치·자세 같은 연속값은 regression probe, gripper state/action은 binary probe로 다뤘습니다. 결과를 보면 양쪽 모두 로봇의 state와 action 관련 정보가 hidden state 안에 선형적으로 읽힐 정도로 구조화되어 있다는 것입니다. 즉, VLA 내부 표현은 완전한 블랙박스가 아니라, 적어도 low-level robotic feature에 대해서는 linear observer로 복원 가능함을 보이는 실험이라고 합니다.
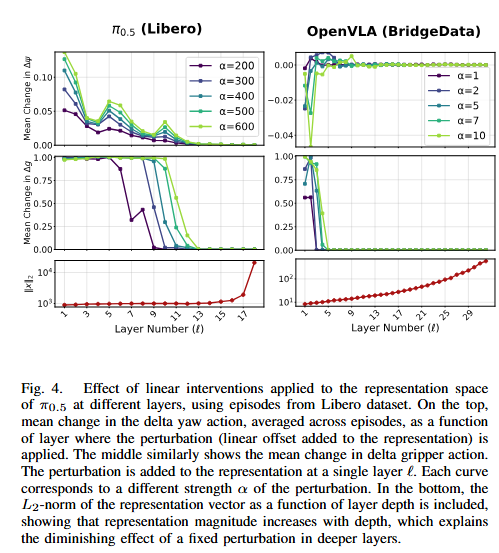
Figure 4는 representation을 바꿨을 때 observer가 읽는 action feature가 예측 가능하게 변하는가를 보는 그림입니다. 저자들은 각 generation에서 한 레이어만 perturbation하고, perturbation strength α를 바꾸면서 delta yaw와 delta gripper의 평균 변화를 측정했습니다. 아래쪽 그래프에는 레이어 깊이에 따라 representation의 L2 norm이 커지는 것도 함께 보여줍니다.
다만 pi0.5에서는 α가 커질수록 observed action change가 비교적 smooth하게 증가하지만 OpenVLA에서는 delta yaw가 robust하지 않고, delta gripper는 어느 정도 ordering은 보이지만 깔끔하지 않다고 저자들이 직접 설명합니다. 모든 모델이 똑같이 잘 제어되는 것은 아니고, π0.5 쪽이 representation-level steering에 더 잘 반응한다고 합니다. 또 perturbation 효과가 일반적으로 얕은 레이어에서 더 크고 깊은 레이어로 갈수록 약해진다고 합니다. 저자들은 깊은 레이어일수록 hidden vector 크기 자체가 커지기 때문에, 같은 크기의 변화에도 둔감하다고 합니다.

Figure 5는 저자들이 제안한 controller와 기존의 activation addition과의 차이를 보여줍니다. 저자들은 representation을 probe가 정의한 classifier image space로 투영해서, intervention 전후에 점들이 어디에 놓이는지 시각화했다고 합니다. 결과를 보면 아무 intervention이 없을 때도 점들은 퍼져 있고, fixed-size vector α를 더했을 때도 target bounds 바깥에 남는 점들이 많습니다. 반면 제안한 controller는 최적화 문제의 hard constraint 때문에, intervened representation의 image가 원하는 범위 안에 있다고 합니다.
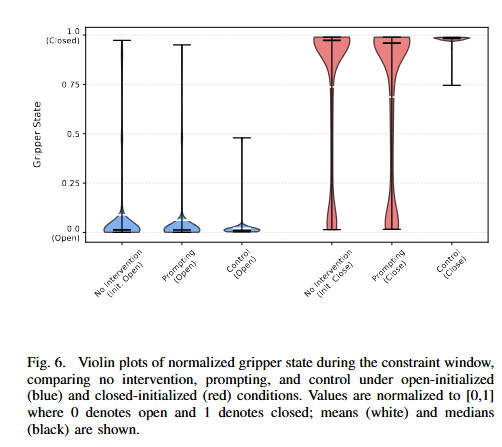
Figure 6은 closed-loop 실험의 첫 번째 결과로, gripper state(open/close) 를 제어했을 때의 분포를 보여줍니다. 결과를 보면 gripper처럼 직접적이고 간단한 low-level action feature는 representation intervention만으로도 매우 안정적으로 조정할 수 있다고 합니다.
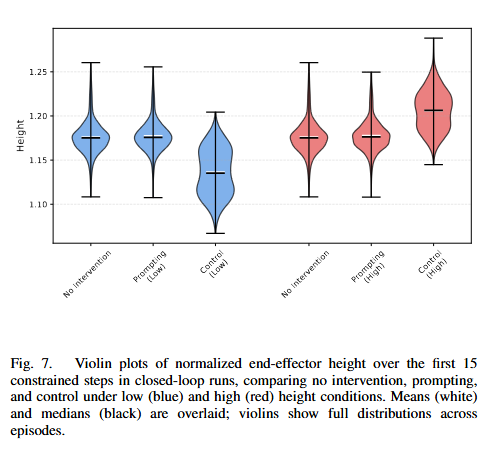
Figure 7은 end-effector height를 low / high 조건으로 제어했을 때의 분포를 보여줍니다. 저자들은 첫 15 step 동안의 normalized height 분포를 비교합니다. 결과를 보면 height steering이 효과적으로 되는것을 볼 수 있습니다. 특히 initial condition을 기준으로 더 낮게 혹은 더 높게 유지하도록 제약을 걸었을 때, control은 원하는 방향으로 분포를 명확히 이동시키는 것을 확인했다고 합니다. 그리퍼와 같은 간단한 binary feature 뿐 만 아니라 연속적인 공간적 feature도 control이 가능함을 보여주는 실험이라고 할 수 있습니다.
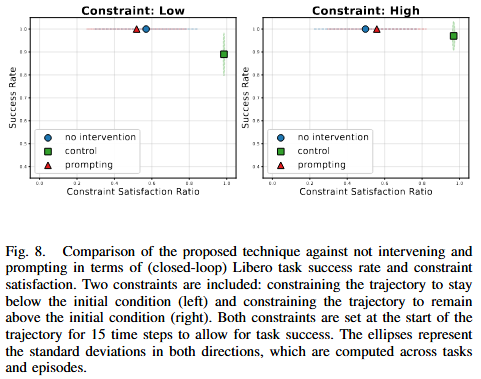
Figure 8은 Figure 7의 분포 그림을 성공률과 제약 만족률의 2차원 trade-off로 다시 요약한 그림입니다. 왼쪽은 trajectory가 initial condition보다 아래에 머물도록 하는 제약, 오른쪽은 위에 머물도록 하는 제약입니다. 저자들은 height constraint satisfaction은 거의 완벽하게 달성하지만 이런 경우 constrained task는 unconstrained task보다 본질적으로 더 어려워지기 때문에, control에서 success rate가 감소한다고 합니다.
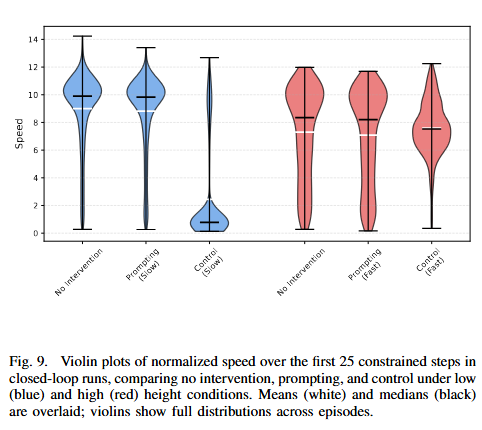
Figure 9는 speed control에 관한 내용입니다. 모델의 출력값을 바꾸는것이 아니라 (x,y,z)에 대한 델타값을 시간에 따른 변화량으로 계산한 값입니다. 실험 결과를 보면 빠르게 하는것은 불안정하지만, 느리게 만드는 것에 대해서는 reliable한 결과를 볼 수 있었다고 합니다. 이와 관련해서 저자들은 fast speed에 대한 training데이터가 부족하다는 가능성을 제시하였습니다. 그러면서 hidden state를 조절하는 것이 base policy의 데이터 분포와 학습 범위를 완전히 개선하는 것은 어렵다는 말도 했습니다.
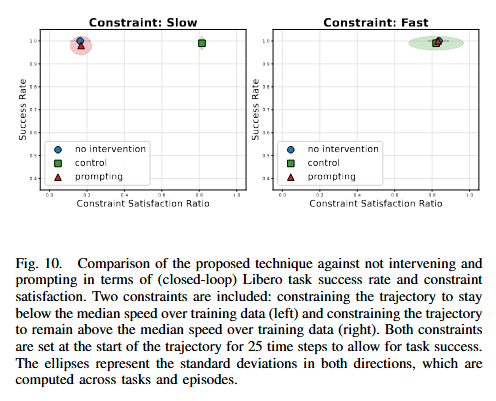
Figure 10은 speed 제어를 constratint satisfaction과 success rate의 축으로 나눈 그림입니다. 느리게 만드는 것은 reliable하고 빠르게 하는것은 좀 덜 reliable 하지만, 그들 모두 task의 success rate를 떨어뜨리지는 않는다고 합니다. 이로 인해 speed와 같은 요소도 조절이 가능할 뿐만 아니라 controller를 통한 control이 원래의 policy가 가진 closed-loop capability를 훼손하지는 않는다고 합니다.
영규님 좋은 리뷰 감사합니다.
실험 결과 π0.5와 OpenVLA를 서로 다른 데이터에서 평가하는 이유가 있을 지 궁금합니다.
앞서 Feature Observaer에서 , hidden representation의 특정 방향이나 부분공간에 의미있는 정보가 선형적이라면 굳이 무거운 비선형 head를 쓰지 않아도 될거라는 가정이 있다고 하셨는데, Fig. 3에 대한 분석이 이에 해당하는 것인지 궁금합니다. 또한, feature에 대한 선형성을 고려하는 것으로 이해하였는데, Fig. 3은 이를 나타내는 실험인가요?
안녕하세요 영규님, 좋은 리뷰 감사합니다.
우연히 저희가 이번에 본 논문 리뷰 방향이 은근 비슷하네요!
기존 transformer 기반 VLA 구조의 representation 안에 로봇 행동과 관련된 중요한 feature가 담겨 있다고 가정한다는 사실 자체가 결국에 실험파트에서 궁극적으로 해당 representation 활용하여 feature observability와 feature-controolability라는 feature 표현의 중간자를 생성해서 policy steering하니 분석 결과가 유의미하더라~ 라고 귀납적으로 판단해야 의미가 있을 것 같다고 생각하며 읽었습니다.
결과를 보니 VLA 내부 구조의 representation이 블랙박스가 아닌 것처럼 관측가능한 특성을 보이고, 간단한 task에서는 intervention에 적절하게 steering이 가능했다는 점이 인상깊었습니다.
궁금한 게 있습니다.
1. figure 4에서 OpenVLA 구조보다 π0.5 쪽이 representation-level steering에 더 잘 반응한다는 이유가 flow-matching 구조에 그 차이가 있을까요?
2. hidden state를 조절하는 것이 base policy의 데이터 분포와 학습 범위를 완전히 개선하는 것은 어렵다 -> 이것에 대해서는 결국은 영규님이 그리시는 대로 base policy가 대규모 데이터로 scaling이 되거나, 혹은 pi*0.6처럼 online RL 방식으로 지속 개선해야된다는 방향으로 읽히시는 지 궁금합니다.
안녕하세요, 영규님. 좋은 리뷰 감사합니다.
논문에서는 end-effector height, gripper state, speed와 같은 low-level state feature를 representation에서 읽고 제어할 수 있음을 보여주었는데요. 이러한 feature controllability가 모델이 실제로 환경의 물리적 동역학을 이해하고 있다는 것으로 볼 수 있는지 궁금합니다.
즉, 이러한 접근이 로봇이 물리적 관계를 이해하는 Physical AI에 가까운 방향이라고 볼 수 있는지, 아니면 단순히 학습된 행동 패턴을 representation 수준에서 통계적으로 조절하는 것에 가까운지에 대한 저자들의 의견이 궁금합니다.
다시 한번 좋은 리뷰 감사합니다!🤖