Abstract
로봇 파지 시스템은 사람의 지시에 따라 다양한 시나리오에서 정확한 물체를 파지할 수 있어야 합니다. 그러나 기존 연구들은 추론이 포함된 대규모 affordance 데이터셋의 부족으로 인해 학습과 평가에 한계를 가지며, 이는 open-world 환경에서의 동작이 가능한지에 대한 우려로 이어집니다. 이를 해결하기 위해 해당 논문은 인간과 유사한 지시문을 포함한 대규모 grasping 중심 affordance segmentation 벤치마크인 RAGNet을 제시합니다. 이 데이터셋은 다양한 도메인을 포괄하며, 각 장면에 대해 affordance map이 함께 주어지며, 지시문에서 카테고리 이름을 제거하고 기능적 설명만을 제공함으로써 어렵게 구성하였다고합니다. 또한, 대규모 데이터로 사전학습된 VLM과, 대상 물체의 파지를 위해 affordance map을 조건으로 활용하는 grasping network로 구성된 AffordanceNet 프레임워크를 제안합니다. 다양한 실험 결과를 통해 제안 방법이 open-world 환경에서도 우수한 일반화가 가능함을 보였다고합니다.
Introducion
affordance 인식은 주변 환경과의 상호작용 관점에서 중요한 연구이며, 물체를 잡아야 하는 영역을 탐지하기 위해 객체의 기하학적 구조와 기능에 대한 이해가 요구됩니다. 그러나 unseen 객체와 이미지 도메인에 대한 일반화 능력과 사람과 유사한 고수준의 지시에 대한 이해 능력에 어려움이 존재합니다.
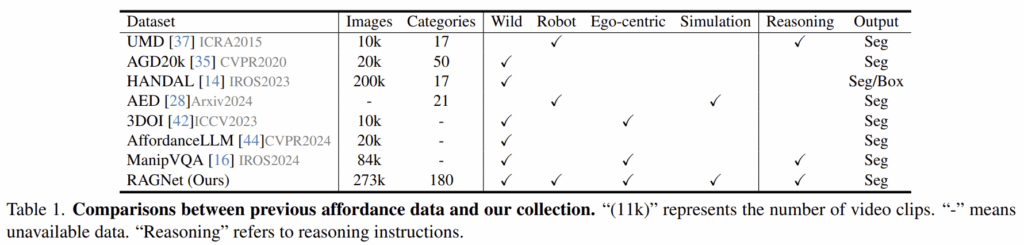
최근 VLM에 영감을 받아, open-world로 일반화하기 위해 VLM의 추론을 활용하여 affordance를 예측하려는 연구가 이루어지고 있습니다. 그러나, 다양한 데이터 셋의 부족과 효과적인 추론 메커니즘이 부족하여 open-world grasping을 수행에 어려움을 겪고있습니다. 위의 Table 1은 기존 데이터 셋에 대한 정보로, Wild/Robot/Ego-centric/Simulation과 같이 여러 도메인 중 특정 도메인으로 한정되어있습니다. Wild는 다양한 환경에서 다양한 카테고리에 대해 수집된 데이터이지만 자전거나 소파와 같이 로봇 조작에는 적합하지 않은 데이터를 포함하며, Robot은 작업 테이블 위에 상대적으로 안정적인 배경이 특징입니다. Ego-centric은 1인칭 시점이나 물체 중심에서 촬영된 이미지로 기존 데이터는 다양한 환경을 포괄하지 못합니다. 이를 해결하기 위해, 저자들은 Wild/Robot/Ego-centric/Simulation 도메인의 다양한 이미지를 포함한 대규모 데이터 셋인 RAGNet을 구축하였습니다. 총 273k개의 이미지와 180개의 카테고리가 포함되며, grasping에 적합한 영역을 라벨링하기 위한 affordance 어노테이션 툴을 설계하였다고 합니다. 또한, LLM을 이용하여 26k개의 추론 기반 지시문을 만들었으며, 하나는 객체의 이름이 포함되고, 다른 하나는 이름을 생략하였다고 합니다. (e.g. ‘Please provide a knife’ & ‘I want something to slice the bread’)
또한, 저자들은 affordance 기반의 grasping 프레임워크인 AffordanceNet을 제안합니다. 이는 AffordanceVLM과 Pose Generator 2가지로 이루어집니다. AffordanceVLM은 RGB이미지와 사람의 지시문을 이해하여 affordance map을 생성하고, Pose Generator는 예측된 2D affordance map과 depth 이미지를 활용하여 3D graspiong pose를 생성합니다. 저자들은 open-world generalization을 평가하기 위해 zero-shot 카테고리에 대한 검증 셋과 out-of-domain 세팅의 검증 셋을 구성하여 평가를 수행하였다고 합니다. 또한, 추론 능력을 평가하기 위해 물체 이름이 포함되지 않은 지시문에 대한 affordance map을 평가하였습니다. 마지막으로 RLBench의 시뮬레이션 작업을 평가하여 실제 AffordanceNet의 로봇 grasping에 대한 평가를 수행합니다.
해당 논문의 contribution은 다음과 같습니다.
- We present a large-scale reasoning-based affordance segmentation benchmark, RAGNet, for general grasping. It is collected from diverse sources and carefully annotated with affordance mask and reasoning instructions.
- We introduce an affordance-based grasping baseline, AffordanceNet, which bridges the gap between VLM-based affordance prediction and real-robot general grasping.
- We conduct extensive experiments, including zero-shot and out-of-domain affordance segmentation, real-robot grasping evaluation, which show great performance.
Related work
먼저, affordance 분야에서 벤치마크는 UMD, OPRA, AGD20k, HANDAL 등이 존재하며, 각 데이터셋은 affordance segmentation, interaction heatmap, handle annotation 등 다양한 형태의 주석을 제공합니다. 그러나 기존 데이터셋들은 affordance category의 다양성, 이미지 품질, 장면 복잡성 측면에서 한계가 있으며, 주로 로보틱스 환경이나 1인칭 시점처럼 특정 도메인에 집중되어 있어 다른 환경으로의 확장성이 제한적이라고 지적합니다.
알고리즘 측면에서는 기존 affordance prediction 연구들이 주로 지도학습 기반으로 이루어져 왔으며, 이러한 방법은 학습한 환경 밖의 새로운 도메인으로 일반화하는 데 어려움이 있습니다. 이를 보완하기 위해 transfer learning이나 self-supervised learning을 활용한 연구들이 제안되었고, 최근에는 VLM의 발전에 힘입어 foundation model을 affordance prediction에 활용하려는 시도도 증가하고 있습니다. 다만 이러한 방법들 역시 대체로 제한된 affordance demonstration data에 의존하고 있어, open-world 시나리오에서의 일반화와 지식 추론 능력 향상을 위해서는 더 대규모이고 다양한 데이터가 필요하다고 강조합니다.
Dataset
Affordance Map Annotation
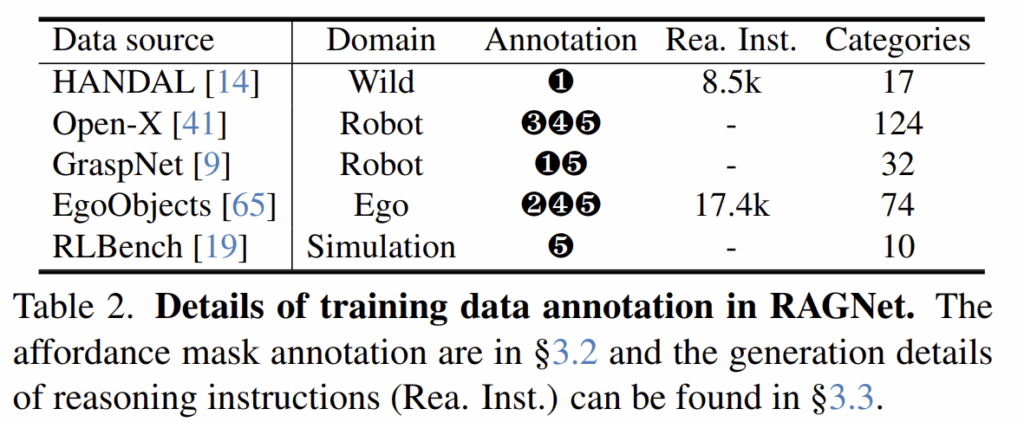
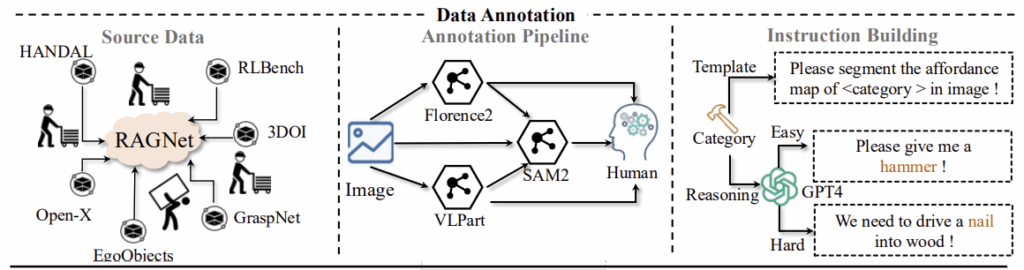
저자들은 다양한 도메인을 포함한 대규모 데이터 셋을 구축하기 위해 Wild/Robot/Ego-centric/Simulation에 해당하는 5가지 데이터를 사용하였으며, 이는 위의 Table 2에서 확인할 수 있습니다. 총 273K개의 이미지를 수집하였으며, affordance map을 편리하게 생성하기 위해 5가지 어노테이션 방식을 설계하였다고합니다. 5가지 방식 중 원본 데이터에서 제공하는 정보에 다라 다른 구성의 방식을 사용하며, 어떤 방식을 사용하였는지는 Table 2에서 확인 가능합니다.
❶ Original Mask: 일부 데이터 셋은 정밀한 affordance mask를 제공하며, 이러한 경우는 원본 affordance mask를 이용합니다. (참고로 HANDAL은 손잡이 부분이 어노데이션 된 데이터입니다)
❷ SAM2: 손잡이가 없고, Bbox만 사용 가능할 경우 SAM2를 적용하여 마스크를 생성합니다.
❸ Florence2 + SAM2: Open-X 데이터와 같이 언어 지시가 존재하고 손잡이가 없는 물체에 대하여, Florence2로 대상 영역을 찾고 SAM2로 정교한 마스크를 생성합니다. (Florence2는 객체를 감지하고 이미지 캡션을 생성할 수 있으며, 각 픽셀에 대한 segmentation이 가능한 모델임.)
❹ VLPart + SAM2: VLPart에 학습된 카테고리에 대해서는 VLPart를 이용해 knife handle, mug handle과 같은 물체 부위를 인식하고, 이후 SAM2를 적용하여 정밀한 affordance mask를 생성합니다.
❺ Human (+ SAM2): 위의 4가지 방식으로 affordance mask를 정확하게 생성하지 못한다면, 수동으로 어노테이션을 수행합니다.
Reasoning Instruction Annotation
VLM의 추론 능력에 대해서는 잘 알려져있으며, 저자들은 이러한 능력을 활용하여 지시문을 구성하였다고 합니다. 지시문은 템플릿 기반의 1가지 지시문과 추론 기반의 2가지 지시문으로 이루어집니다. 먼저, 템플릿 기반의 지시문은 “Please segment the affordance map of <category_name> in this image.”형태로, 전체 데이터 셋에 활용 가능합니다. 다음으로 추론 기반의 지시문은 VLM(GPT-4)의 추론을 이용합니다. 객체에 대한 명시적 언급이 포함되는 쉬운 지시문(e.g. ‘차를 마실 머그잔 찾아줘’)과 객체에 대한 지칭이 없는 어려운 지시문(e.g. ‘커피를 마실 무언가가 필요해’)을 만들어냅니다. 아래는 실제로 사용한 프롬프트이며, 이러한 방식으로 HANDAL 데이터에 대해서 8.5K개의 어려운 지시문, EgoObjects 데이터에 대해서 12.7K개의 쉬운 지시문과 4.7K개의 어려운 지시문을 생성하여 총 26K개의 추론 기반 지시문을 생성합니다.

Evaluation Dataset
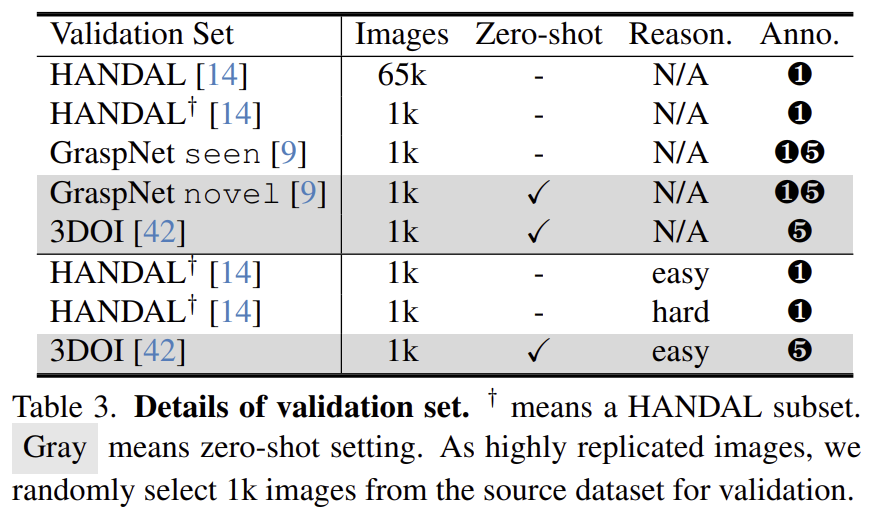
저자들은 affordance prediction 모델의 open-world 일반화 성능을 평가하기 위해 두 가지 zero-shot 시나리오를 구성하였습니다. 첫 번째는 학습 중 보지 못한 객체 카테고리에 대한 일반화 성능을 평가하는 것이고, 두 번째는 서로 다른 데이터 도메인에 대한 일반화 성능을 평가하는 것입니다. 이를 위해 HANDAL, GraspNet, 3DOI 등으로부터 검증 셋을 구성하였으며, 학습에 사용된 카테고리와 도메인, 보지 못한 카테고리, 보지 못한 도메인을 구분하여 총 네 가지 검증 셋을 제공합니다. (위의 Table 3에서 색깔로 구분한 4가지. 위의 1~3행은 seen 카테고리 in-domain, 4~5행은 unseen 카테고리 in-domain, 6~7행은 seen 카테고리 out-of domain, 8행은 unseen 카테고리 out-of-domain인 것으로 보입니다.)
또한, 저자들은 추론 능력을 평가하기 위해 reasoning-based affordance segmentation 검증 셋도 추가로 구성하였습니다. 각 검증 셋은 지시문의 난이도에 따라 easy와 hard로 나뉘며, 평가 지표로는 gIoU와 cIoU를 사용합니다.
AffordanceNet
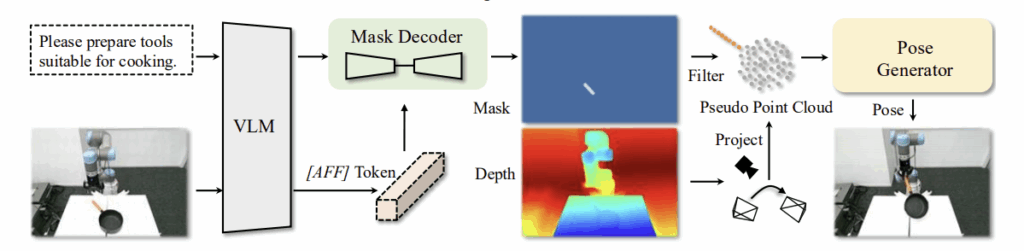
open-world grasping을 이해 저자들은 AffordanceNet을 제안합니다. 이는 affordance 마스크를 예측하는 AffordanceVLM과, 3D 공간의 그리퍼 위치를 구하기 위한 Pose Generator로 구성되며, 전체 프레임워크는 위의 그림에서 확인하실 수 있습니다.
AffordanceVLM
AffordanceVLM은 Vision-Language 모델인 LISA를 기반으로 이루어집니다. affordance에 대한 예측을 향상시키기 위해 affordance 작업에 맞는 시스템 프롬프트를 개발하였으며, <AFF>라는 토큰을 추가하였다고 합니다. 구체적으로, 입력 이미지를 ViT-CLIP 인코더로 처리한 뒤, LLM 임베딩 공간으로 투영하고, 텍스트 지시문과 함께 LLM에 입력합니다. 이때, 각 지시문은 embodied robot 관점의 프롬프트가 추가됩니다. 기존 LISA는 <SEG> 토큰을 통해 segmentation 정보를 표현하였으나, 저자들은 이러한 방식만으로는 affordance에 특화된 표현을 나타내기 어렵다고 보았고, <AFF> 토큰을 새롭게 추가하였습니다. 이후 SAM을 mask decoder로 이용하여 픽셀 수준의 mask를 생성합니다. 또한, 학습시에는 reasoning-based affordance segmentation 데이터 뿐만 아니라 일반 segmentation 데이터도 사용하였다고 합니다.
Pose Generator
affordance mask를 예측한 뒤, 로봇 작업을 수행하기 위해 2D Affordance map을 depth map을 이용하여 3차원 공간으로 투영합니다. 먼저 2D이미지 상의 포인트P에 affordance mask M을 이용하여 필터링한 \hat{P}를 구합니다. 이후 다양한 grasping model을 이용하여 그리퍼의 위치를 생성한뒤, 로봇을 조작하여 로봇 작업을 수행합니다. 해당 과정은 크게 컨트리뷰션은 없는 것 같습니다.
Experiments on Visual Affordance
먼저 저자들은 앞의 affordance단계에 대한 검증을 수행합니다. 실험에는 Foundation 모델(VLPart, GroundingDNIO,Florence)과 MLLMs를 이용하여 평가를 수행하며, Foundation model의 출력은 bbox나 폴리곤 박스만을 예측하므로 SAM2를 이용하여 마스크를 개선하였다고 합니다.
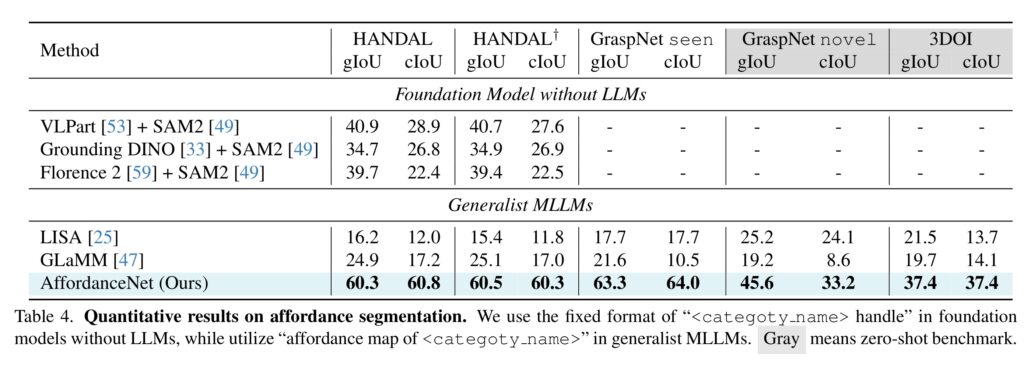
위의 Table 4는 affordance에 대한 정량적 평가 결과로, 저자들이 제안한 AffordanceNet이 다른 방법론들에 비해 성능이 좋다는 것을 확인할 수 있습니다. 아래의 Figure 4는 이에 대한 정성적 결과를 확인할 수 있습니다. 오른쪽의 Top-drawer까지 구분하여 인식한다는 것을 통해 VLM의 추론 능력이 도움이 된다는 것을 확인할 수 있는 것 같습니다.

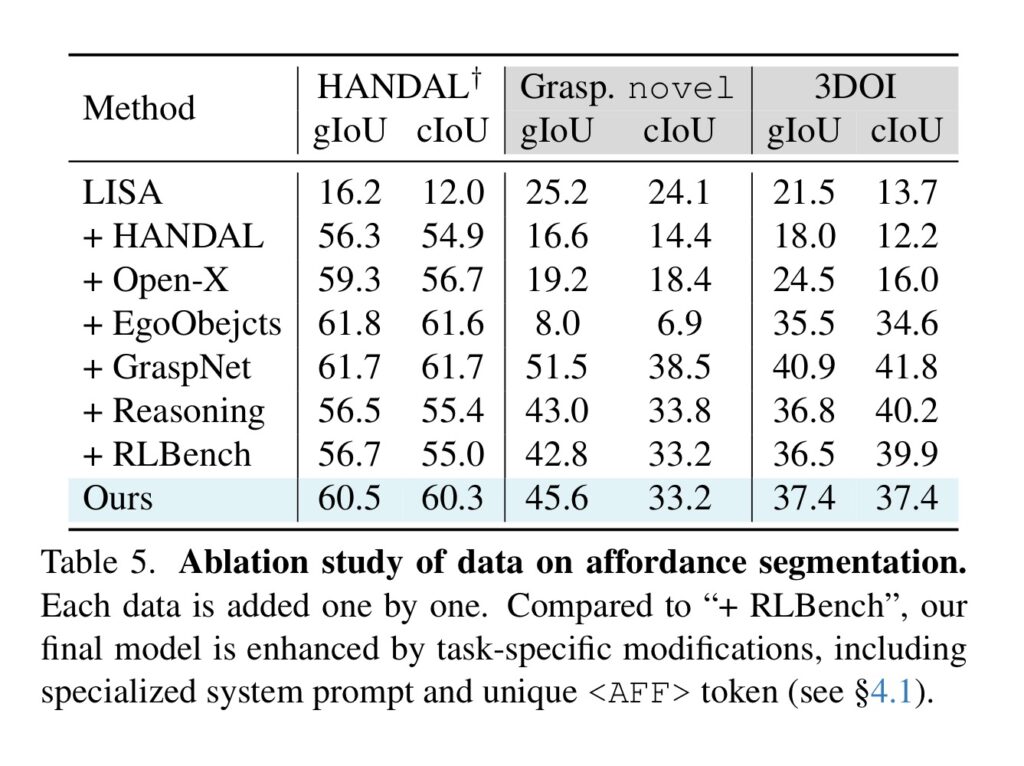
위의 Table 5는 ablation study 결과로, 각 데이터 셋들이 어떤 영향을 주는 지 실험하기 위해 하나씩 추가한 결과라합니다. 실험 결과 추론 데이터를 추가할 경우 약간의 성능 저하가 발생하였습니다. 실험 결과를 보면 GraspNet 데이터까지만 추가하는 게 좋아보이는데 이에 대한 이야기는 없습니다. 다양한 도메인을 추가하는 것과 난이도가 있는 reasoning 데이터를 추가함으로써 현재 평가 데이터셋에서는 성능 저하가 발생하지만, 다양한 분포를 학습해둘 수 있다는 점에서 받아들여진 것 같습니다..
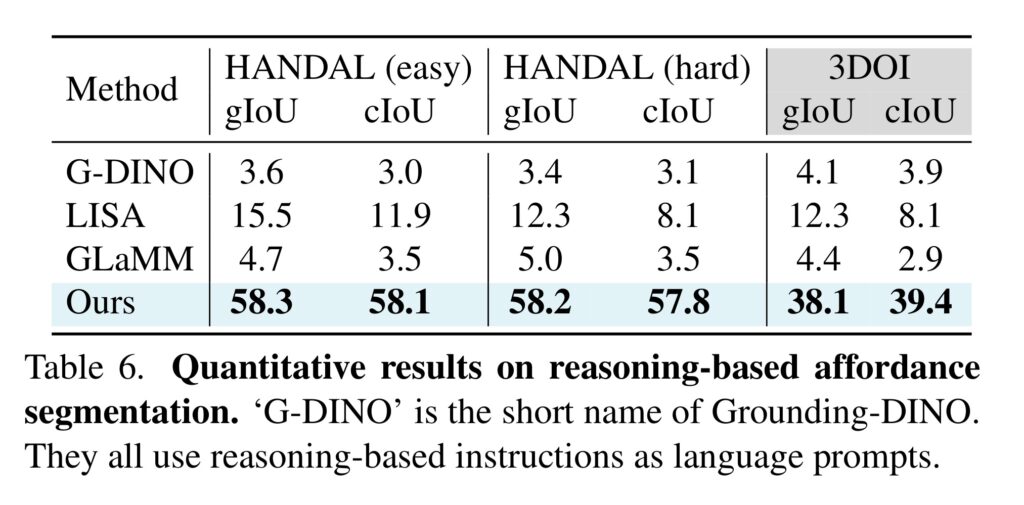
위의 Table 6는 foundation model과 MLLM의 추론 능력을 평가합니다. 다른 방법론들과 비교했을 때 저자들이 제안한 방식이 뛰어난 성능을 보여주었으며, 위의 Figure 5에서 정성적 결과도 확인하실 수 있습니다. Figure 5에서 마지막 두가지 예시는 물체에 대한 정보가 지시문에 명시되어있지 않음에도 불구하고 정확한 망치와 머그의 손잡이를 예측하고있는 것을 보여줍니다.
Experiments on Object Grasping
Real-World Evaluation
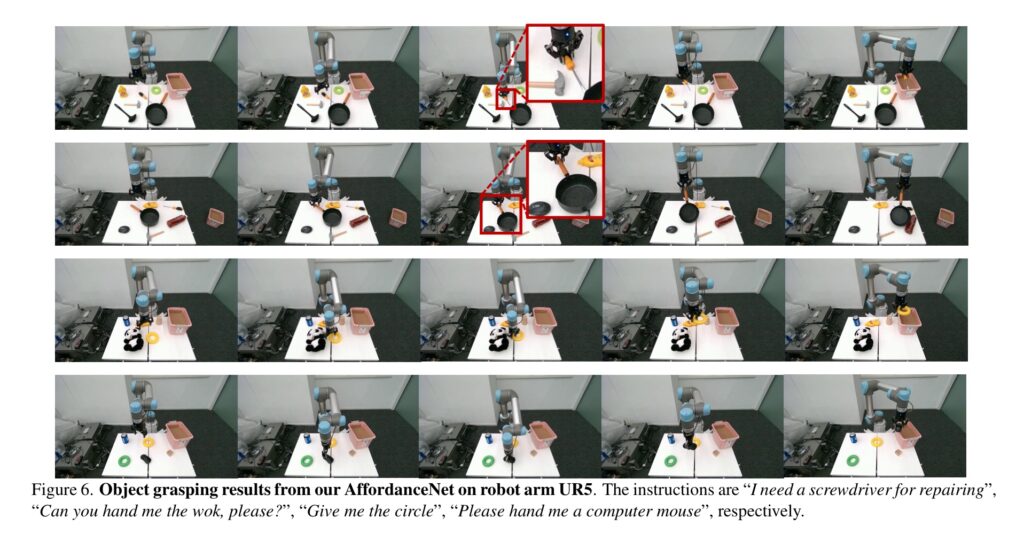
실제 real-world에서 로봇의 조작 능력을 평가합니다. RealSense를 이용하여 RGB-D 를 취득하며 UR5로 망치, 드라이버, 가위, 캔을 포함하는 10가지의 grasping 작업을 수행합니다. 10번 실행하여 성공률을 평가하며, 평가 환경은 학습한 적 없는 환경입니다. Pose Generator로는 GraspNet을 이용하였으며, affordance 영역을 찾은 뒤 그리퍼 포즈를 생성하는 저자들의 방법론과 전체 물체 정보를 이용하는 원본 GraspNet과 비교합니다.

위의 Table 7을 통해 저자들이 제안한 방식이 우수한 성능을 보여준다는 것을 확인할 수 있습니다.
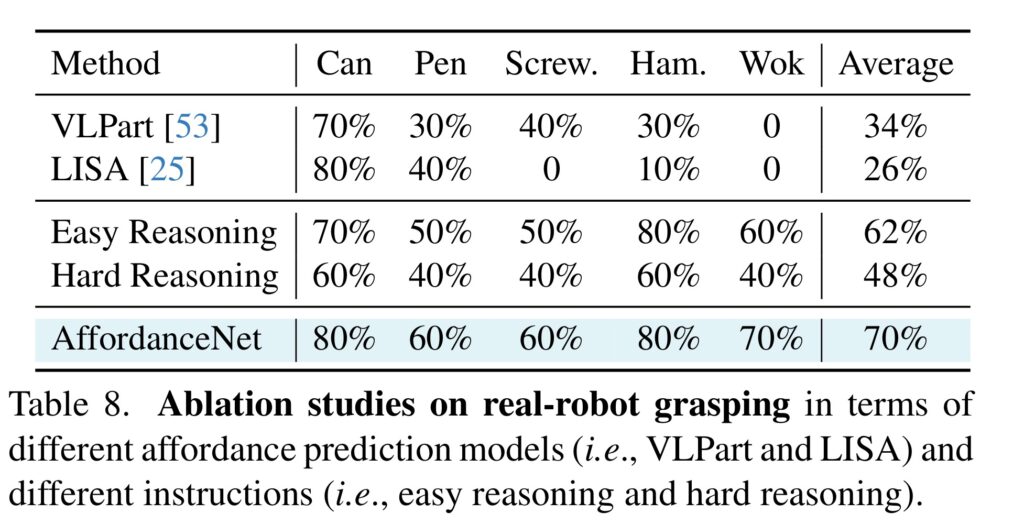
위의 Table 8은 5가지 작업에 대하여 affordance모델이 VLPart나 LISA로 변경될 경우와 지시문의 유형에 따른 실험 결과를 리포티안 것입니다. 마찬가지로 전반적으로 저자들이 제안한 방식이 우수한 성능을 나타내는 것을 확인할 수 있으며, 어려운 지시문이 주어지더라도 안정적으로 동작하는 것을 확인할 수 있습니다.
Simulation Evaluation
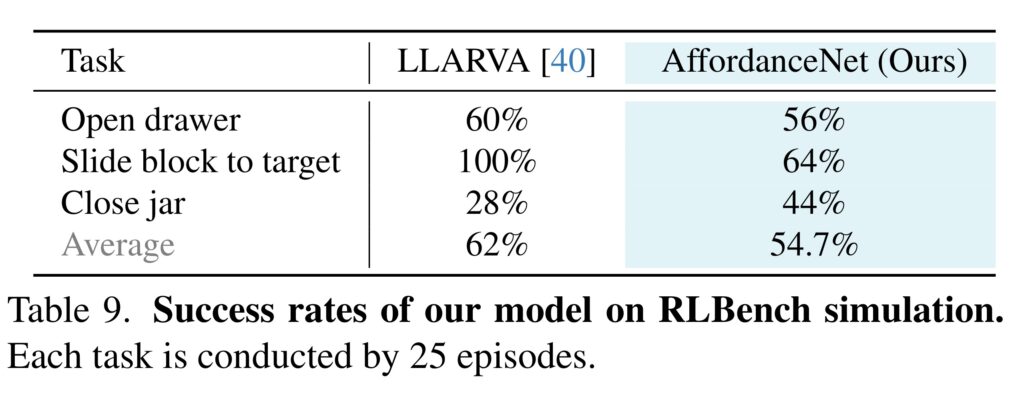
추가로, RLBench에서 평가를 수행하였으며, 작업을 여러개의 keyframe으로 나누어 affordance를 추론하고 grasping을 수행하였다고 합니다. 25번 실행하였을 때 성공률을 평가하였다고하며, 비교에 사용한 LLARVA는 해당 환경으로 fine-tuning된 결과입니다. 실험 결과 학습 방식과 비교했을 대 유사한 성능을 달성하였다는 점에서 저자들의 방법론이 효과가 있다는 점을 어필합니다.
안녕하세요 승현님 좋은 리뷰감사합니다. 토큰을 통해 segmentation 정보를 표현하였다고 했는데, AffordanceVLM은 segmentation 데이터에서 토큰없이 토큰만은 사용하나요? 혹시 두개다 사용한다면 이에 대한 Ablation 결과도 있는지 궁금합니다.
AffordanceVLM에서 질문이 있습니다. 기존 LISA는
감사합니다.
리뷰 읽어주셔서 감사합니다.
저자들은 기존의 LISA가 사용하는 토큰을 사용하고, 추가로 라는 Affordance 토큰을 사용한다고 합니다. Table 4의 LISA와의 결과를 비교하면, 토큰만을 이용하는 방식(LISA결과)과 와 를 모두 이용하는 방식(AffordanceNet)에 대한 ablation으로 볼 수 있을 것 같습니다.
안녕하세요 승현님 리뷰 감사합니다.
Table 5를 보면 reasoning data 추가했을때 오히려 성능이 조금 하락하는 것 같은데, (제가 이해한게 맞나요..?) reasoning data가 그 자체로 성능 향상을 시켜주는건 아니지만, affordance 데이터 규모와 토큰 같은 구조적인 면 때문에 성능이 향상되는 설계라고 이해해도 될까요?
질문 감사합니다.
네 영규님이 이해하신 게 맞습니다. reasoning 데이터가 추가되면 성능이 약간 하락하는 경향을 보입니다. 그러나 이게 기존 다른 데이터들과 워낙 분포가 달라서가 아닐까 하는 생각도 듭니다. 만약 LISA에 HANDAL 추가된 후 바로 Reasoning이 추가된다면 어떻게 될 지 이런 실험이 있었다면 reasoning 데이터의 영향을 더욱 명확히 확인할 수 있었을 것 같은데 그런 실험은 따로 없어서 아쉬웠습니다. 또한 이야기하신 것처럼, reasoning 데이터 자체가 segmentation mask에 대한 성능 개선에 긍정적 영향은 주지 못하지만, 토큰과 같은 구조를 위한 설계로 이해하시면 좋을 것 같습니다.
안녕하세요 승현님 리뷰 감사합니다.
제가 올바르게 이해했나 의문(?)이지만 몇가지 질문 남깁니다.
VLM에 embodied robot관점의 지시문이 들어간다고 하셨는데 이러한 관점에서 보면 지시문만 바꿔주면 다양한 embodied robot에 적용할 수 있는건가요?
혹시 논문에는 다양한 embodied robot이나 gripper에 적용한 평가는 없을까요?
감사합니다.
질문 감사합니다.
로봇 관점의 지시문이라는 게, “You are an embodied robot.”와 같이 명시하는 표현이 같이 들어간다는 의미인 것 같습니다. 저자들이 cross-embodiement에 대한 고려는 따로 없긴 한데, 이런 명시적 표현에 어떤 로봇인지, 어떤 그리퍼인지를 명시한다면 그래도 VLM의 추론 능력을 활용해볼 여지가 있지 않을까 합니다.
또한, 아쉽게도 인하님이 이야기하신 것 처럼 다양한 embodied robot이나 gripper로 변형한 실험은 따로 없습니다.