안녕하세요. 이번에 소개할 논문은 LLM 기반 텍스트 임베딩 모델의 설계에 대해 분석한 연구입니다. 최근 LLM 기반 임베딩 모델로 실험을 진행하던 중, 어떤 구조적 설계가 성능에 영향을 줄 수 있는지 살펴보기 위해 논문을 읽게 되었습니다. 이 논문은 새로운 모델을 제안하기보다는, LLM을 임베딩 모델로 활용할 때 pooling과 attention 같은 설계 요소가 성능에 어떤 영향을 미치는지를 실험적으로 분석한 연구에 가깝습니다. 그럼 자세한 내용은 리뷰에서 설명드리겠습니다.
1. Introduction
기존 자연어 처리 연구에서는 문장의 의미를 벡터로 표현하는 텍스트 임베딩(Text Embedding)이 다양한 작업에서 중요한 역할을 해왔습니다. 예를 들어 정보 검색(Information Retrieval)이나 문장 유사도(Semantic Textual Similarity)와 같은 작업에서는 문장을 벡터 공간으로 변환한 뒤 그 유사도를 계산하는 방식이 널리 사용됩니다. 특히 최근에는 검색 시스템이나 RAG(Retrieval-Augmented Generation)와 같은 구조에서도 이러한 임베딩 모델이 핵심적인 역할을 하고 있습니다. 실제로 OpenAI나 Cohere와 같은 기업들은 텍스트 임베딩을 API 형태로 제공하며 다양한 서비스에 활용되고 있습니다. 이러한 임베딩 모델들은 기존에는 주로 encoder-only 모델을 기반으로 만들어졌습니다. 대표적으로 BERT나 Sentence-BERT와 같은 모델들이 임베딩 모델로 널리 사용되어 왔습니다. 그러나 최근 LLM이 크게 발전하면서, LLM을 Base 모델로 사용하여 임베딩 모델을 만드는 연구가 활발히 진행되고 있습니다. 실제로 MTEB(Massive Text Embedding Benchmark)와 같은 임베딩 모델 벤치마크에서는 이러한 LLM 기반 임베딩 모델들이 기존 encoder-only 모델보다 더 좋은 성능을 보이며 리더보드를 차지하고 있는 상황입니다.
LLM을 임베딩 모델로 사용하기 위해서는 크게 두 가지 설계가 중요합니다. 하나는 Pooling 전략, 다른 하나는 Attention 전략입니다.
먼저 Pooling 전략은 입력 시퀀스를 하나의 고정된 벡터로 변환하는 방법을 의미합니다. 예를 들어 E5-mistral-7b-instruct나 SRF-Embedding-Mistral 같은 모델은 EOS 토큰의 마지막 hidden state를 사용하는 EOS-last token pooling 방식을 사용합니다. 반면 NV-Embed는 단순히 hidden state를 사용하는 대신 학습 가능한 pooling layer를 추가하여 최종 임베딩을 생성하는 방식을 사용합니다.
다음으로 Attention 전략은 토큰들이 서로 어떤 방향으로 정보를 참고할 수 있는지를 결정하는 요소입니다. 기본적으로 대부분의 LLM은 causal attention 구조로 사전학습됩니다. 이는 현재 토큰이 이전 토큰들만 볼 수 있도록 제한하는 구조입니다. 그러나 최근 연구에서는 이러한 causal attention이 representation learning에 한계를 가질 수 있다는 점이 제기되고 있습니다. 이에 따라 일부 연구에서는 LLM을 임베딩 모델로 사용할 때 bidirectional attention을 허용하여 모든 토큰이 서로를 참조할 수 있도록 해야 한다고 주장합니다.
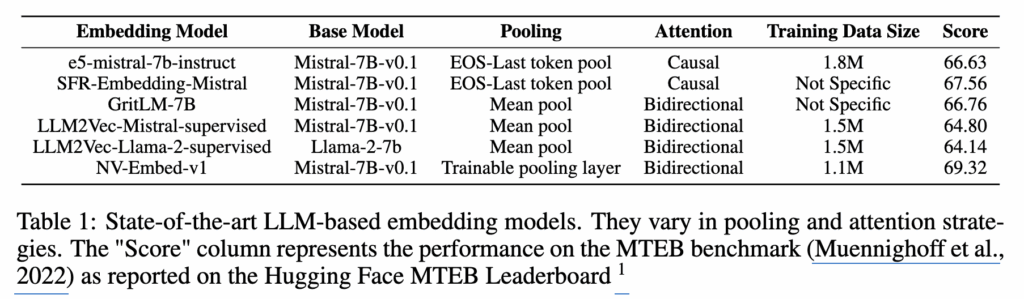
표 1은 LLM 기반 임베딩 모델들을 나열하고 있습니다. 현재 다양한 LLM 기반 임베딩 모델들이 제안되고 있지만, 어떤 모델은 다른 모델보다 더 좋은 성능을 보입니다. 그렇다면 자연스럽게 “임베딩 모델의 성능을 결정하는 요소는 무엇인가?”와 같은 질문이 생깁니다. 예를 들어 다음과 같은 요소들이 영향을 줄 수 있습니다.
- 더 좋은 파인튜닝 데이터셋
- 더 성능 좋은 base LLM
- 서로 다른 pooling 및 attention 전략
하지만 기존 연구들은 대부분 서로 다른 데이터셋과 서로 다른 base 모델을 사용해 실험을 진행했기 때문에, 각 설계 요소가 성능에 어떤 영향을 주는지 명확하게 분석하기 어려운 상황입니다. 이 논문에서는 이러한 문제를 해결하기 위해 동일한 데이터셋과 동일한 base LLM을 사용한 상태에서 pooling 전략과 attention 전략만 바꾸어가며 실험을 수행합니다.
저자는 이러한 실험을 통해서 모든 태스크에서 항상 가장 좋은 단일 설계는 존재하지 않는다는 점을 발견합니다.
예를 들어 bidirectional attention과 trainable pooling layer를 함께 사용하는 구조는 문장 유사도(STS)와 정보 검색 task에서는 좋은 성능을 보이지만, clustering이나 classification task에서는 오히려 단순한 구조보다 더 좋은 성능을 보이지는 않았습니다.
그리고 저자는 기존 pooling 전략을 비교하는 것에서 추가로 Multi-Layers Trainable Pooling이라는 새로운 pooling 방법을 제안합니다.
이제 이러한 아이디어를 이해하기 위해, 먼저 기존 LLM 기반 임베딩 모델에서 사용되는 대표적인 pooling 전략과 attention 구조를 살펴보겠습니다.
2. Commonly Used Pooling and Attention Strategies
앞서 introduction에서 설명했듯이, LLM을 임베딩 모델로 활용하기 위해서는 몇 가지 중요한 설계 요소가 존재합니다. 그 중에서도 특히 Pooling 전략과 Attention 전략이 핵심적인 역할을 합니다. 이 섹션에서는 기존 LLM 기반 임베딩 모델에서 널리 사용되고 있는 대표적인 pooling 방법들과 attention 구조에 대해 간단히 살펴보겠습니다.
2.1 Pooling Strategy
먼저 Pooling 전략에 대해 살펴보겠습니다.
Pooling 전략은 LLM이 생성한 hidden state들로부터 하나의 고정된 크기의 임베딩 벡터를 만드는 과정을 의미합니다. 논문에서는 LLM의 hidden state를 다음과 같은 형태로 표현합니다.
H ∈ R^(l × n × d)
여기서 l은 레이어의 개수, n은 토큰 시퀀스 길이, d는 hidden dimension을 의미합니다. 이 hidden state 행렬을 기반으로 임베딩을 만드는 방식에는 대표적으로 세 가지 방법이 사용됩니다.
1. EOS-Last Token Pooling
첫 번째 방법은 EOS-last token pooling입니다. 이 방법은 입력 시퀀스의 마지막 토큰 hidden state를 임베딩으로 사용하는 방식입니다. LLM은 기본적으로 next-token prediction을 학습 목표로 가지고 있습니다. 따라서 시퀀스의 마지막 토큰은 이전 모든 토큰의 정보를 반영하게 됩니다. 이러한 이유로 많은 연구에서는 입력 문장의 끝에 EOS(End-of-Sequence) 토큰을 추가하고, 마지막 레이어에서 EOS 토큰의 hidden state를 최종 임베딩으로 사용합니다.
OpenAI의 cpt-text 모델이나 E5-mistral-7b-instruct와 같은 모델들이 이 방식을 사용하고 있습니다.
2. Mean Pooling
두 번째 방법은 Mean Pooling입니다. 이 방식은 마지막 레이어에서 모든 토큰의 hidden state를 평균 내어 하나의 벡터를 만드는 방식입니다. 즉 시퀀스에 존재하는 모든 토큰 표현을 평균하여 문장의 전체 의미를 표현하는 방식입니다.대표적으로 GritLM-7B나 LLM2Vec 같은 모델들이 이러한 pooling 방식을 사용하고 있습니다.
3. Trainable Pooling Layer
세 번째 방법은 Trainable Pooling Layer입니다. 이 방식은 기존 pooling 방법들과 달리 LLM hidden state를 그대로 사용하는 대신 추가적인 학습 가능한 레이어를 통해 임베딩을 생성하는 방식입니다. 대표적으로 NV-Embed 모델이 이러한 방식을 사용합니다.
구체적으로는 LLM의 마지막 레이어 hidden state를 입력으로 받아 trainable network를 통해 의미 공간(semantic latent space)으로 변환합니다. 즉 단순한 평균이나 마지막 토큰을 사용하는 것이 아니라 추가적인 네트워크가 어떤 정보가 중요한지 학습하여 임베딩을 생성하는 방식이라고 볼 수 있습니다.
2.2 Attention Strategy
다음으로 Attention 전략에 대해 살펴보겠습니다. 대부분의 LLM은 기본적으로 causal attention 구조로 사전학습됩니다. Causal attention은 현재 토큰이 이전 토큰들만 참조할 수 있도록 제한하는 단방향 attention 구조입니다. 하지만 최근 연구에서는 이러한 구조가 representation learning, 즉 임베딩 학습에는 한계가 있을 수 있다는 점이 제기되었습니다. 그 이유는 causal attention 구조에서는 앞쪽 토큰들이 뒤쪽 토큰 정보를 볼 수 없기 때문에 문장의 전체 의미를 충분히 반영하지 못할 수 있기 때문입니다. 그래서 일부 연구에서는 LLM을 임베딩 모델로 사용할 때 attention mask를 bidirectional로 변경하는 방법을 사용합니다.
Bidirectional attention을 사용하면 문장 내 모든 토큰이 서로의 정보를 참고할 수 있기 때문에 더 풍부한 표현을 학습할 수 있습니다. 이 논문에서는 이러한 두 가지 구조를 각각
- Causal Attention
- Bidirectional Attention
이라고 정의하고 실험을 진행합니다.
2.3 Fine-tuning LLMs as Embedding Models
마지막으로 LLM을 임베딩 모델로 학습시키는 방법에 대해 살펴보겠습니다. 비록 기존 LLM 기반 임베딩 모델들이 서로 다른 pooling 전략과 attention 구조를 사용하고 있지만, 학습 방식 자체는 대부분 Contrastive Learning을 사용하여 LLM을 임베딩 모델로 파인튜닝합니다. 즉 의미가 비슷한 문장(positive example)은 가깝게 만들고, 의미가 다른 문장(negative example)은 멀어지도록 학습합니다. 이 과정을 통해 LLM은 문장의 의미적 관계를 반영하는 임베딩 공간을 학습하게 됩니다. 실제로 Table 1에 정리된 대부분의 LLM 기반 임베딩 모델들은 이러한 contrastive learning 방식으로 학습되었습니다. 다만 한 가지 중요한 점은 기존 연구들은 서로 다른 데이터셋을 사용하여 모델을 학습했기 때문에, 최종 성능이 모델 구조 때문인지, 아니면 데이터셋 때문인지 명확히 구분하기 어렵다는 문제가 존재합니다.
3. Multi-Layers Trainable Pooling
앞서 살펴본 것처럼, 기존 LLM 기반 임베딩 모델들은 대부분 마지막 레이어의 hidden state만을 사용하여 임베딩을 생성합니다. 예를 들어 EOS-last token pooling, mean pooling, trainable pooling과 같은 방법들이 모두 존재하지만, 결국 마지막 레이어의 hidden state를 기반으로 임베딩을 만든다는 점에서는 동일합니다.
하지만 마지막 레이어만 사용하는 것이 정말 최선의 방법일까하는 의문이 생기게 됩니다. 왜냐하면 기존 연구들을 보면 언어 모델의 각 레이어는 서로 다른 의미 정보를 담고 있다는 사실이 이미 알려져 있습니다.
예를 들어 encoder 구조의 BERT나 decoder 기반 LLM에서도 레이어마다 서로 다른 수준의 의미 정보를 인코딩한다는 연구 결과들이 있습니다. 이러한 관찰을 바탕으로 저자는 다음과 같은 가설을 세웁니다.
마지막 레이어뿐만 아니라 다른 레이어에도 중요한 정보가 존재할 수 있으며, 이러한 정보가 마지막 레이어의 표현을 보완할 수 있다.
그래서 이 섹션에서는 먼저 레이어별 hidden state가 실제로 서로 다른 정보를 담고 있는지 실험적으로 확인하고, 이후 여러 레이어의 정보를 활용하는 새로운 pooling 방법을 제안합니다.
3.1 Last Layer vs Other Layers
먼저 저자는 마지막 레이어와 다른 레이어들의 hidden state를 비교하기 위한 두 가지 실험을 진행합니다.
Experiment 1: 레이어별 hidden state는 서로 다른 정보를 담고 있는가
첫 번째 실험에서는 서로 다른 레이어의 hidden state 간 상관관계를 측정합니다. 이를 위해 HotpotQA, MS MARCO 두 가지 데이터셋을 사용하고, Mistral 7B, Llama 3 모델을 사용합니다. 그리고 이 모델들이 임베딩 모델로 파인튜닝되지 않은 base 모델을 사용해서 실험 합니다.

각 입력 문장에 대해 레이어별 EOS 토큰 hidden state를 추출하고, 서로 다른 레이어 간의 Spearman correlation coefficient를 계산했을때의 실험 결과는 Figure 1의 heatmap으로 나와있습니다. 결과를 보면 다음과 같은 특징을 확인할 수 있습니다.
- 인접한 레이어의 hidden state는 높은 상관관계를 보임.
- 멀리 떨어진 레이어일수록 상관관계가 낮아짐.
특히 중요한 점은 서로 멀리 떨어진 레이어들은 상당히 다른 표현을 가지며 서로 다른 정보를 인코딩하고 있을 가능성이 높다는 것입니다. 비록 이 실험은 임베딩 모델이 아닌 base LLM에서 수행되었지만, 이 결과는 LLM 내부의 서로 다른 레이어들이 서로 다른 정보를 학습하고 있다는 사실을 보여줍니다.
Experiment 2: 다른 레이어의 hidden state도 유용한가
두 번째 실험에서는 각 레이어의 hidden state가 실제 downstream task에서 얼마나 좋은 표현을 가지는지 평가합니다. 이를 위해 각 레이어에서 EOS 토큰의 hidden state를 임베딩으로 사용하고, 이를 MTEB benchmark에서 평가합니다.
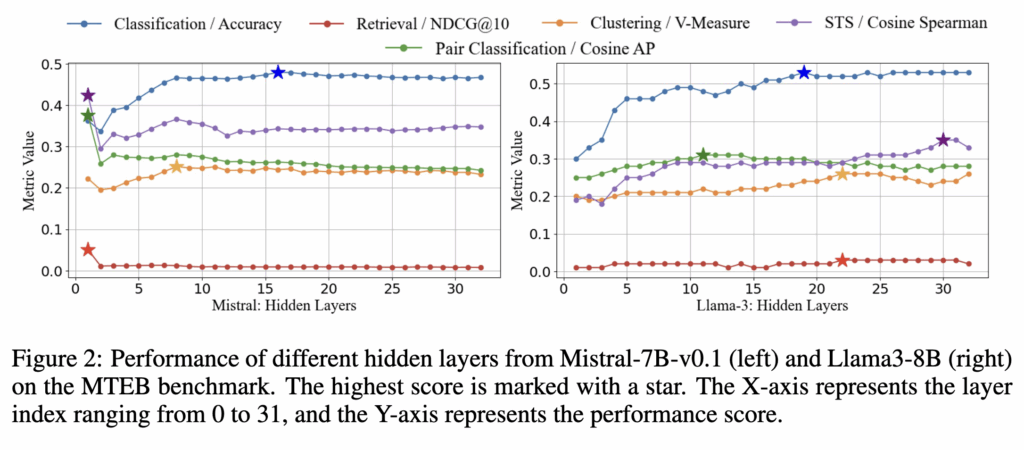
결과는 Figure 2에 나타나 있습니다. 그림을 통해서 알 수 있듯이 마지막 레이어의 hidden state가 항상 최고의 성능을 보이는 것은 아닙니다. 예를 들어 Mistral-7B에서는 초기 레이어가 오히려 더 많은 의미 정보를 담고 있는 경우도 있고 Llama3 모델에서는 중간 레이어가 의미 정보를 표현하는 데 더 효과적인 것으로 나타났습니다.
물론 임베딩 모델로 파인튜닝된 경우에는 레이어별 특성이 달라질 수 있습니다. 하지만 이 실험을 통해서 알 수 있는점은마지막 레이어만 사용하는 것은 최적의 방법이 아닐 수 있으며, 다른 레이어의 hidden state도 중요한 정보를 담고 있을 가능성이 있다는 것입니다.
3.2 Multi-Layers Trainable Pooling
앞선 실험 결과를 바탕으로 저자는 Multi-Layers Trainable Pooling이라는 새로운 pooling 전략을 제안합니다. 이 방법은 LLM의 모든 레이어 hidden state를 활용하여 임베딩을 생성합니다. 전체 구조는 Figure 3에 제시되어 있습니다.
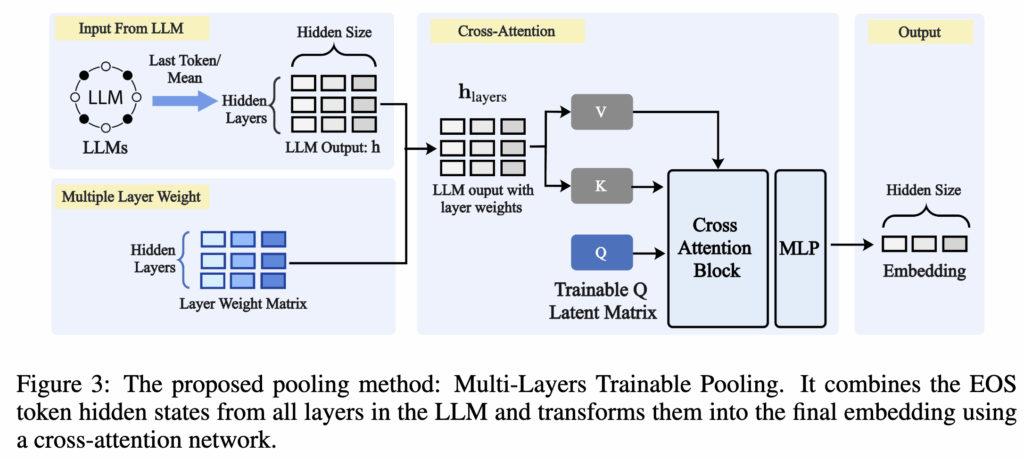
이 pooling 방법은 크게 세 과정으로 이루어집니다.
1. Input: LLM Hidden States Across All Layers
먼저 LLM의 출력 hidden state를 pooling 연산의 입력으로 사용합니다. 만약 모델이 causal attention 구조라면,
h_causal = H[:, -1, :]
즉 각 레이어의 EOS 토큰 hidden state를 사용합니다. 반면 bidirectional attention 구조에서는
h_bidirectional = (1/n) Σ H[:, i, :]
즉 토큰 차원에 대해 평균을 취한 representation을 사용합니다. 이렇게 얻은 벡터가 이후 pooling 네트워크의 입력이 됩니다.
2. Layer Weight Matrix
다음으로 레이어별 중요도를 반영하기 위한 weight matrix를 추가하는데, 이를 추가하는 이유는 레이어마다 임베딩에 기여하는 정도가 다를 수 있기 때문입니다. 이를 위해 학습 가능한 행렬을 사용하고 이를 hidden state와 결합하여 아래의 형태로 사용합니다.
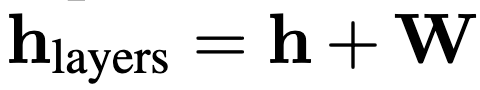
3. Cross Attention Matrix
마지막으로 이 방법에서는 cross-attention 구조를 사용하여 여러 레이어의 정보를 하나의 임베딩으로 결합합니다.
구체적으로는 먼저 앞서 얻은 hlayers를 두 개의 선형 변환을 통해 Key matrix(K)와 Value matrix(V)로 변환합니다. 그리고 여기에 학습 가능한 query 행렬 Q를 사용하여 cross-attention 연산을 수행합니다. 여기서 중요한 점은 K와 V는 입력으로 들어온 hidden state로부터 만들어지는 반면, Q는 입력 데이터와는 무관하게 모델이 학습을 통해 얻는 벡터라는 점입니다. 즉 모델은 Q라는 벡터를 통해 “어떤 정보를 중요하게 볼 것인지”를 학습하게 되고, K와 V는 실제 여러 레이어의 hidden state 정보를 담고 있는 역할을 합니다.
cross-attention 연산에서는 Q와 K의 유사도를 계산하여 각 레이어의 중요도를 결정하고, 그 중요도를 기반으로 V를 가중합하여 최종 임베딩을 생성합니다. 결과적으로 이 과정은 여러 레이어의 hidden state 중에서 중요한 정보를 선택적으로 모아 하나의 표현으로 만드는 과정이라고 볼 수 있습니다.
이후 결과는 MLP를 통과하여 최종 임베딩 벡터로 변환됩니다.
4. Pooling and Attention Experiments
앞서 살펴본 것처럼, 기존 LLM 기반 임베딩 모델들은 다양한 pooling 전략과 attention 전략을 조합하여 사용하고 있습니다. 하지만 이전에 설명드렸다시피 어떤 설계가 실제로 효과적인지 판단하기는 쉽지 않습니다. 그래서 이 논문에서는 동일한 데이터셋과 동일한 학습 설정을 사용한 상태에서 pooling과 attention 전략만 바꿔가며 비교 실험을 진행합니다.
4.1 Pooling and Attention Combinations
실험에서는 총 5가지 모델 조합을 비교합니다.

이 조합에서는 EOS pooling과 bidirectional attention 조합이 빠져있습니다. 이러한 이유는 bidirectional attention 구조에서는 EOS 토큰이 특별한 의미를 갖지 않습니다. 왜냐하면 모든 토큰이 서로를 볼 수 있기 때문에 마지막 토큰이 전체 문장을 대표한다고 볼 수 없기 때문입니다. 그래서 기존 연구들에서도 bidirectional attention을 사용할 때는 mean pooling 이나 trainable pooling 같은 방법을 사용하는 것이 일반적입니다. 따라서 이 조합 역시 실험에서 제외되었습니다.
5. Empirical Analysis
이제 실험 결과를 살펴보겠습니다.
5.1 Optimal Pooling Strategy
먼저 pooling 전략의 효과를 분석합니다. 비교 대상은 다음 세 가지입니다.
- EOS pooling
- Last-layer trainable pooling
- Multi-layers trainable pooling
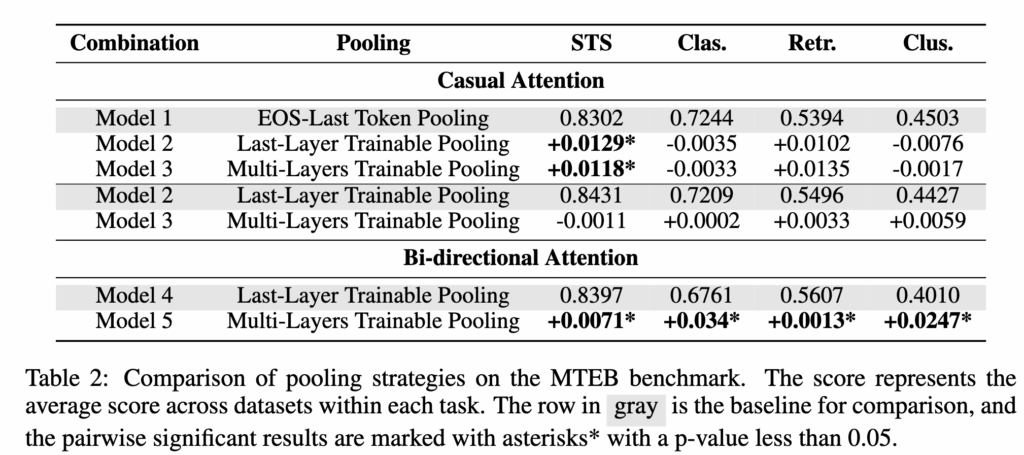
Finding (1)에 따르면, causal attention을 사용하는 경우 trainable pooling layer의 효과는 STS task에서만 유의미하게 나타났습니다. 구체적으로 STS task에서는 EOS-last token pooling을 사용하는 경우보다 trainable pooling layer를 사용하는 경우 성능이 더 높게 나타났습니다.
하지만 classification, retrieval, clustering task에서는 이러한 trainable pooling 방법들이 통계적으로 유의미한 성능 향상을 보이지 않았습니다. 즉 causal attention 환경에서는 trainable pooling layer의 효과가 특정 task에 제한적으로 나타난다고 볼 수 있습니다.
다음으로 Finding (2)를 살펴보겠습니다. 이번에는 bidirectional attention을 사용하는 경우 pooling 전략의 효과를 분석합니다. Table 2의 하단 결과를 보면 Multi-Layers Trainable Pooling이 Last-Layer Trainable Pooling보다 모든 task에서 더 좋은 성능을 보였습니다.
두 결과를 통해서 알 수 있듯이 multi-layer pooling의 효과가 항상 나타나는 것은 아니며, attention 구조와 같은 모델 설정에 따라 달라질 수 있음을 알 수 있네요.
5.2 Optimal Attention Strategy
다음으로 attention 전략의 효과를 살펴보겠습니다.
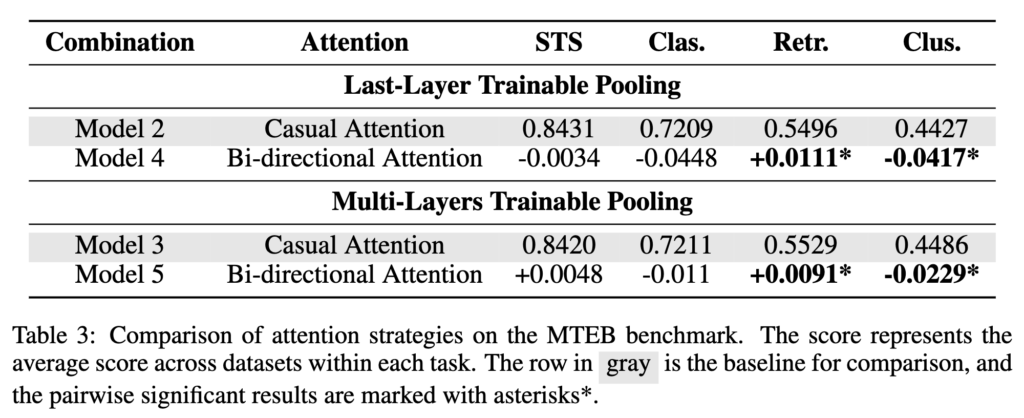
다음으로 attention 전략의 결과를 살펴보겠습니다. Finding (3)에 따르면, bidirectional attention은 retrieval task에서는 더 좋은 성능을 보이지만 clustering task에서는 오히려 성능이 떨어지는 경향을 보였습니다. Table 3의 결과를 보면, 어떤 pooling 전략을 사용하든 bidirectional attention을 적용했을 때 retrieval task의 성능이 일관되게 향상되는 것을 확인할 수 있습니다. 다만 성능 향상 폭 자체는 크지 않은 수준입니다.
반면 동일한 설정은 clustering task에서는 오히려 성능 감소로 이어졌습니다. 이러한 결과는 bidirectional attention이 양방향 문맥 정보를 모두 활용할 수 있기 때문에 관련 정보를 찾는 retrieval task에는 도움이 되지만, 동시에 추가적인 문맥 정보가 noise로 작용하여 clustering task에서는 오히려 성능을 저하시킬 수 있다고 저자는 설명하고 있습니다.
5.3 Optimal Pooling + Attention Design
이제 마지막으로 pooling과 attention 전략을 함께 고려했을 때 어떤 구조가 가장 효과적인지 살펴보겠습니다.
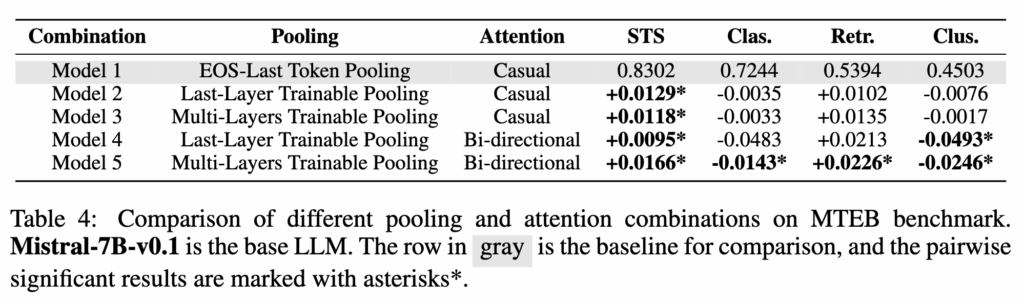
Finding (4)에서 저자는 모든 task에서 항상 가장 좋은 단일 구조는 존재하지 않는다는 점을 강조합니다. 실험 결과를 보면 task에 따라 효과적인 pooling과 attention 조합이 달라지는 것을 확인할 수 있습니다.
예를 들어 STS와 retrieval task에서는 Multi-Layers Trainable Pooling과 Bidirectional Attention을 함께 사용한 Model 5가 가장 좋은 성능을 보였습니다. 특히 retrieval task에서는 기존 LLM 기반 임베딩 모델의 기본 설정인 Model 1에 비해 약 4.2%의 성능 향상을 보였습니다. 하지만 classification이나 clustering task에서는 Model 5 구조가 오히려 덜 효과적이었습니다. 이러한 task에서는 방향성이 제한된 causal attention 구조가 더 좋은 성능을 보였습니다.
결국 이 결과는 pooling과 attention 전략의 효과가 task에 따라 달라질 수 있으며, 모든 상황에 항상 최적인 단일 구조는 존재하지 않는다는 점을 보여줍니다.
그럼에도 불구하고 LLM 기반 임베딩이 주로 semantic search나 RAG 시스템과 같은 retrieval 중심 응용에서 활용되기 때문에 저자는 STS와 retrieval task에서의 성능을 고려했을 때 Multi-Layers Trainable Pooling + Bidirectional Attention 구조가 더 유용할 가능성이 높다고 주장하며 논문을 마무리하고 있습니다.
감사합니다.
리뷰 잘 읽었습니다. 마지막 레이어만 쓰지 않고 여러 레이어를 함께 활용한다는 아이디어가 제법 흥미롭네요.
다만 실제로는 초기/중간/후기 레이어가 각각 어떤 종류의 의미 정보를 보완적으로 제공하는지가 더 궁금해지는데요.
예를 들어 retrieval에서 좋아지는 이유가 더 풍부한 의미 정보 때문인지, 아니면 단순히 여러 표현을 평균적으로 섞어 안정화되는 효과인지도 함께 궁금합니다
그리고 실험 결과를 보면 STS, retrieval, clustering, classification마다 좋은 pooling 전략이 다르게 나타난 것 같은데요.
그렇다면 결국 pooling 전략은 단순한 구현 선택이 아니라, 각 task가 요구하는 표현 수준(global 의미, 클래스 경계 등등?) 과 연결되어 있다고 볼 수 있을까요? 논문에서 이런 식으로 task 특성과 pooling의 관계를 해석하는 부분이 있었는지도 궁금합니다.
안녕하세요 좋은 질문 감사합니다.
기존 LLM 연구에서는 서로 다른 레이어가 서로 다른 수준의 의미 정보를 담고 있다는 것이 널리 알려져 있습니다. 일반적으로 초기 레이어는 단어 수준의 정보나 문법적 구조를 주로 담고 있고, 중간 레이어는 구나 문장 구성과 같은 compositional 정보를, 마지막 레이어에 가까워질수록 더 추상적인 semantic 정보나 특정 태스크에 맞는 표현을 담는 경향이 있습니다.
따라서 마지막 레이어만 사용하면 semantic 정보에만 의존을 하게 되는데, 여러 레이어를 활용할 경우 다양한 표을 동시에 반영할 수 있기에 문장의 의미적 유사성 정보를 찾는 retireval에서는 더 안정적인 표현을 형성하는데 도움을 줄 수 있다고 예상할 수 있습니다.
그리고 논문에서는 pooling 전략의 차이가 각 태스크가 요구하는 표현 특성과 어떻게 연결되는지에 대한 분석 결과가 나와 있지 않지만, 실험 결과를 해석해보면 STS나 retrieval과 같이 문장의 전반적인 의미 유사성을 판단하는 태스크에서는 다양한 의미 정보를 통합하는 표현이 유리할 수 있는 반면, classification이나 clustering에서는 클래스 경계나 표현의 분리도가 더 중요해 다른 전략이 더 잘 작동할 가능성이 있습니다.
따라서 ooling 방식이 태스크별로 요구되는 표현 특성과 관련될 수 있다고 볼 수 있을 것 같네요
안녕하세요 의철님 좋은리뷰 감사합니다.
모든 layer의 의미를 쓰는 방식에서 최종 결과가 모든 task 에 유의미하게 증가하는 방식이었다면 더 좋았을텐데 그렇지는 않네요.
간단한 질문이 있는데, layer weight matrix 는 bias 같은 역할을 기대하는 거라고 이해하면 될까요?
감사합니다.