비디오 진영의 파운데이션 모델(Foundation Model)로 군림하던 InternVideo라는 모델이 있었는데요. 해당 논문에 대한 리뷰는 2023년 임근택 연구원이 읽기 쉽게 잘 정리해주신 걸 확인할 수 있었습니다: [InternVideo 리뷰 by 근택]
최근에는 InternVideo v1 대신 v2가 더 활발하게 사용되는 추세이기에, 이번 리뷰에서는 InternVideo v2에 대해 다루어보고자 합니다.

- Venue: ECCV 2024
- Authors: Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Chenting Wang, Guo Chen, Baoqi Pei, Ziang Yan, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, Limin Wang
- Affiliation: OpenGVLab, Nanjing University
- Title: InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
- Code: GitHub
1. Introduction
최근 비디오 파운데이션 모델(ViFM)은 (1) 시공간 지각 → (2) 언어 정렬 → (3) 대화 및 추론 확장(LLM 접목)이라는 세 가지 단계를 거치며 발전해 왔습니다. 이제 최근 연구들의 관심도는 “이 단계들을 어떻게 잘 결합하고 스케일업(Scale-up) 할 것인가”로 넘어왔죠.
InternVideo2는 바로 이 흐름 속에서 더 범용적인 비디오 모델을 만들려면 무엇에 집중해야 하는가? 라는 질문을 던졌고, 그 해답으로 단순히 모델 크기만 키우는 것이 아니라, 단계별 학습 목표를 분리한 ‘3-stage Progressive Training’과 데이터 품질(시간적 일관성, 캡션 퀄리티) 향상을 제시하였습니다.
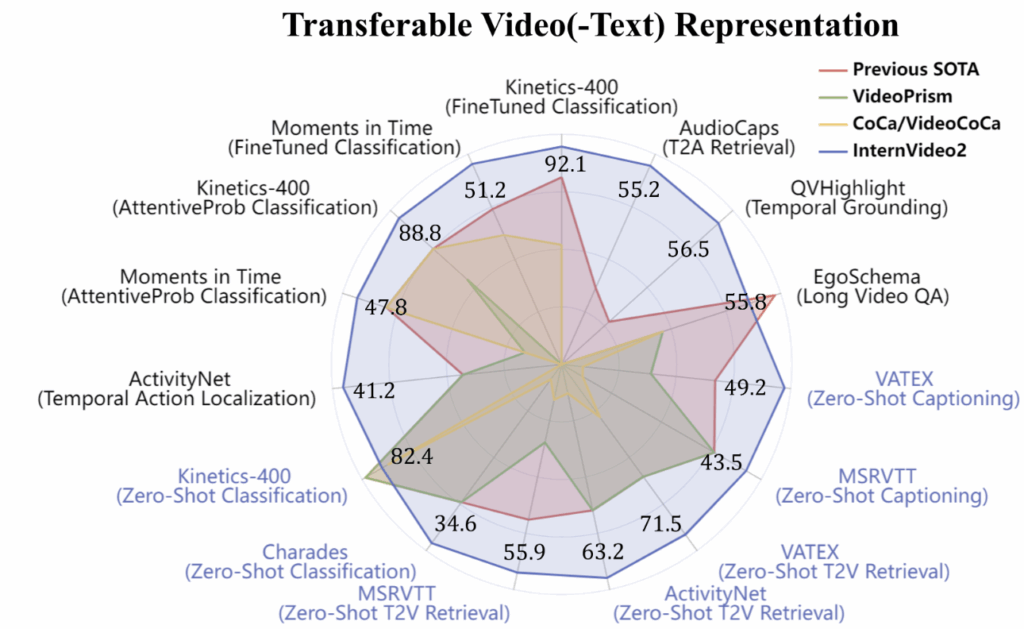
결과적으로 상단 InternVideo2의 결과인 그래프를 보면, 분류(Kinetics), 검색(MSRVTT), 캡셔닝(VATEX), Temporal Grounding 등 성격이 전혀 다른 태스크 전반에서 고르게 높은 성능을 보여주며 강력한 일반화 가능성을 보였습니다
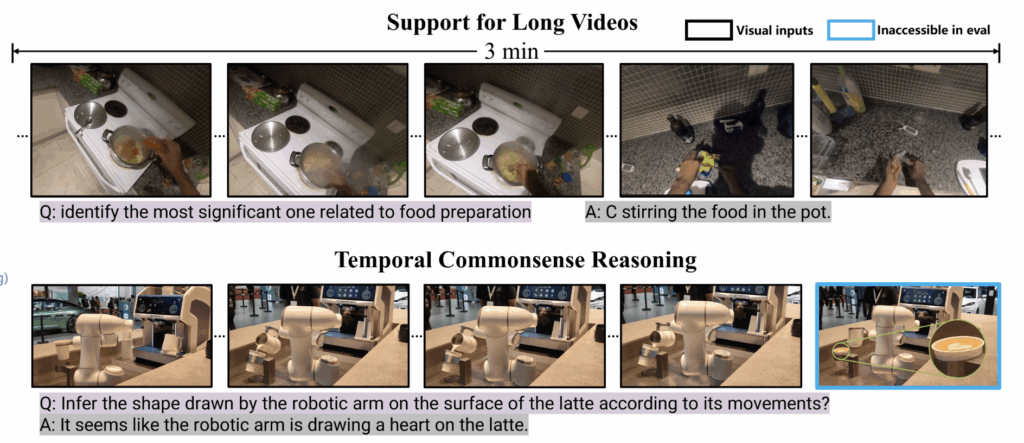
더욱 놀라운 점은 단순한 정적 장면 이해를 넘어, 어느정도의 Long Video Understanding와 Temporal Commonsense Reasoning까지 가능해졌다는 것입니다. 위에 그림을 보면 3분짜리 비디오에서 핵심 요리 순간을 짚어내거나, 로봇 팔의 움직임만 보고 완성될 라떼 아트를 추론하는 것도 가능했다고 합니다. 이는 비디오 인코더가 긴 시간의 흐름까지 파악하는 범용 표현력을 갖췄음을 의미한다고 볼 수 있죠
결국 핵심은 이 압도적인 범용성이 저자들이 설계한 3단계 학습 파이프라인과 데이터 정제 덕분이라는 점입니다. 그럼 다음 Method 섹션에서는 Fig. 2를 보며, 이 3-stage Progressive Training이 구체적으로 어떻게 구성되어 있는지 파헤쳐 보겠습니다.
2. Method
InternVideo2의 핵심은 비디오 표현 학습에서 효과가 검증되어 온 세 가지 학습 신호를 단계적으로(progressive) 묶어 스케일링했다는 점이었습니다. 저자들은 이를 3단계 학습 파이프라인으로 정리했고, 전체 구조는 아래 그림을 보시죠

우선 큰 흐름을 보면, Stage 1에서는 비디오 인코더를 처음부터 학습시키고, Stage 2와 3에서는 이전 단계에서 학습한 비디오 인코더를 그대로 이어받아 학습하는 형태죠. 이 때, Video Encoder로는 ViT-1B, ViT-6B를 사용합니다
Stage 1: Reconstructing Unmasked Video Tokens
Stage 1은 마스킹된 비디오 입력에서 unmasked 토큰의 표현을 복원하도록 학습하는 단계입니다. 이때 두 종류의 teacher를 함께 사용합니다.
– 멀티모달 의미 정보를 주는 teacher(semantic): InternVL-6B
– 모션/시간 정보를 잘 잡는 teacher(motion): VideoMAEv2-g
정리하면, 비디오 인코더가 멀티모달 태스크에 필요한 의미 표현뿐 아니라, 액션 모델링에 중요한 temporal sensitivity까지 같이 가져가도록 설계한 것이죠.
Objective Functions. 구체적으로, 입력 비디오 프레임의 80%를 마스킹한 뒤, 살아남은 Unmasked 토큰에 대해서만 학습 대상(Student)과 Expert 모델(Teachers) 간의 MSE로 최소화합니다. 적용되는 Loss 함수는 다음과 같습니다.
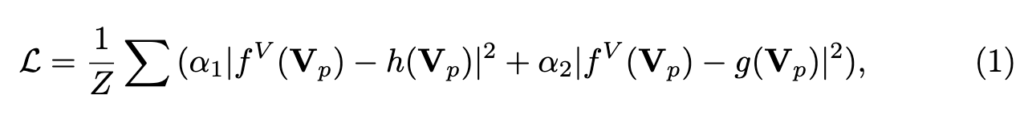
- f^V: 학습 대상인 InternVideo2의 비디오 인코더
- h: Semantic 가이드를 제공하는 멀티모달 모델 InternVL-6B
- g: Motion-aware 가이드를 제공하는 VideoMAEv2 (ViT-g)
Stage 2: Aligning Video to Audio-Speech-Text
Stage 2의 핵심은 비디오를 오디오, 스피치, 텍스트 등 다양한 모달리티와 정렬(Alignment)하여 더 풍부한 Semantic 표현을 학습하는 것입니다. 이로인해 구조적으로는 거대한 비디오 인코더와 상대적으로 가벼운 오디오 및 텍스트 인코더를 결합한 비대칭적 구조를 가지게 됩니다.
Objective Functions. 여기서 Loss는 우리가 흔히 알고있는 것들을 결합하여 사용합니다
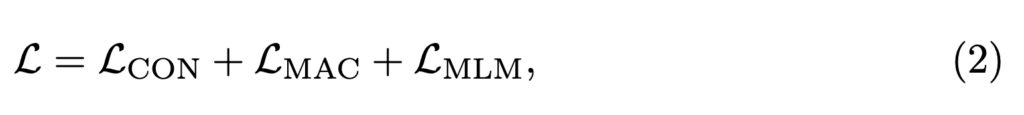
- \mathcal{L}_{\text{CON}} (Crossmodal Contrastive Learning)
- \mathcal{L}_{\text{MAC}} (Matching part)
- \mathcal{L}_{\text{MLM}} (Masked Language Modeling)
수식처럼 “비디오-텍스트(및 오디오) 간 정렬”을 강화하는 방향이고, 일반적으로 사용되는 contrastive + matching + MLM (마스킹 복원) 같은 loss를 조합한 것이죠. 여기서는 Stage 1에서 얻은 “지각(perceptive)” 표현을 의미 기준으로 정렬시키는 단계라고 이해하시면 됩니다. 또한 효율과 추론 환경 일관성을 위해 마스킹 기반 정렬 단계와 unmasked 기반 post-pretraining 단계를 나눠 진행하였습니다
Stage 3: Predicting Next Token with Video-Centric Inputs
Stage 3는 비디오 인코더를 Q-Former 기반 브릿지로 LLM에 연결하고, instruction finetuning 데이터로 next-token prediction을 학습하는 단계입니다. 여기서 중요한 점은 브릿지/LLM만 맞추는 것이 아니라, 비디오 인코더도 next-token prediction 신호로 함께 업데이트된다는 점입니다. 결과적으로 비디오 QA나 비디오 설명처럼 open-ended 태스크에서의 생성/이해 능력을 강화하려는 설계로 볼 수 있습니다.
3. Multimodal Video Data
InternVideo2에서 흥미로운 점은 3-stage 학습 과정뿐 아니라, 이를 받쳐주는 데이터 설계와 정제를 꽤 강조했다는 점입니다. 저자들은 Table 1에서 학습 데이터를 stage별로 정리했고, 그중 K-Mash와 InternVid2는 새로 구축한 데이터셋이라고 설명합니다.
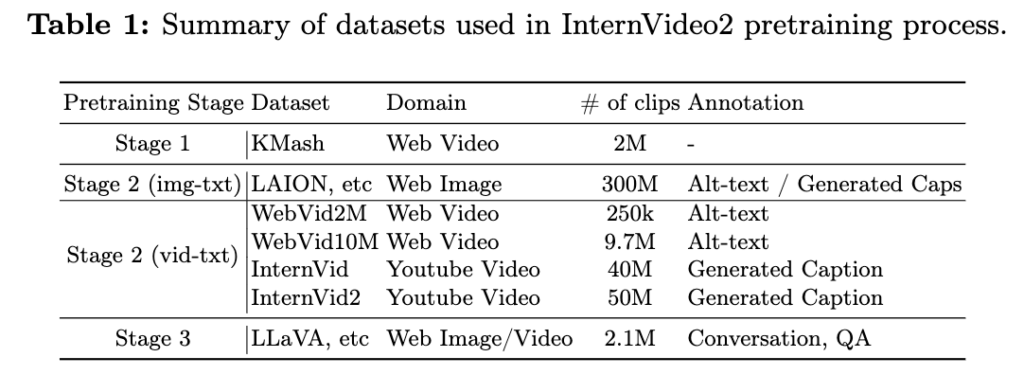
먼저 Stage 1은 라벨 없이 비디오만 있는 K-Mash(약 2M clips)로 비디오 인코더의 기본 표현을 학습합니다. Stage 2는 이미지-텍스트와 비디오-텍스트 페어 데이터로 멀티모달 정렬을 수행하는데, 이미지-텍스트는 LAION 등 대규모 데이터(약 300M)를 사용하고, 비디오-텍스트는 WebVid 계열과 함께 InternVid/InternVid2처럼 YouTube 기반 생성 캡션 데이터를 중심으로 규모를 크게 확장합니다. 마지막 Stage 3는 LLaVA 계열의 instruction 데이터(약 2.1M)를 사용해 대화/QA 형태의 학습으로 모델을 마무리합니다.
여기서 포인트는 Stage 2의 비디오-텍스트 구성이 “그냥 양을 늘린 것”이라기보다, 캡션-비디오 정렬 품질을 끌어올리는 쪽에 무게를 뒀다는 점입니다. 저자들은 InternVid2를 video-audio-speech 정보까지 포함한 멀티모달 비디오 데이터셋으로 소개하면서, 특히 긴 비디오를 clip으로 자르는 과정에서 temporal consistency가 중요하다고 강조합니다. 즉, 아무 구간이나 자르면 앞뒤 문맥이 섞인 불완전한 clip이 생기기 쉬운데, 이를 줄이기 위해 temporal boundary detection 모델(AutoShot)로 “픽셀 변화”가 아니라 의미 변화(semantic variation)를 기준으로 경계를 잡았다고 합니다.
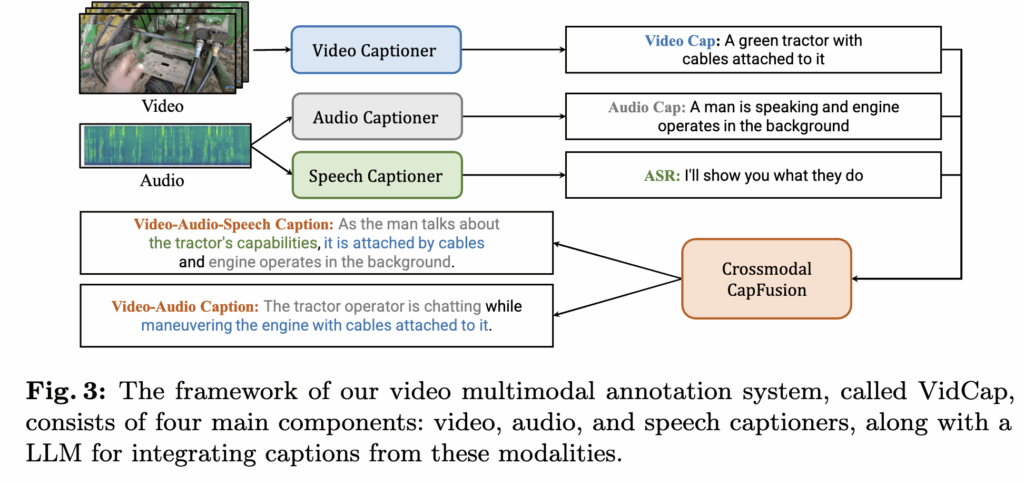
또 하나는 캡션 품질을 높이기 위한 VidCap(video-audio-speech caption fusion) 설계입니다. 구조 자체는 단순합니다. video/audio/speech captioner가 각각 캡션을 만들고, 마지막에 LLM이 이를 refinement 및 fusion해 cross-modal(VAS) caption을 생성합니다. 저자들은 세 모달리티를 따로 설명한 뒤 합치는 방식이, 비디오를 더 포괄적으로 묘사하는 데 도움이 된다고 주장합니다.
정리하면 InternVideo2의 데이터 설계는 (1) stage별로 필요한 데이터 타입을 명확히 분리하고, (2) 비디오-텍스트 정렬의 품질을 높이기 위해 clip 분할의 일관성(temporal consistency)과 캡션 라벨 품질(VidCap fusion)을 함께 사용한 것으로 볼 수 있습니다.
4. Experiments
4.1 Setup
저자들은 InternVideo2를 학습 단계에 따라 InternVideo2s1 / InternVideo2s2 / InternVideo2s3로 구분해 평가했고, stage2 모델에서 비디오·텍스트 인코더와 contrastive loss만 남긴 CLIP-style 버전(InternVideo2clip)도 별도로 평가했습니다. 평가는 zero-shot, finetuning, linear probing 등 다양한 세팅을 포함해 “전이 가능성”을 확인하는 방식이었습니다.
4.2 Video Classification
일반화를 위한 범용 모델이다보니 실험이 많습니다. 다양한 downstream 결과를 차근차근 보겠습니다.
Action Recognition
Action Recognition은 여러 세팅으로 평가를 진행하였습니다
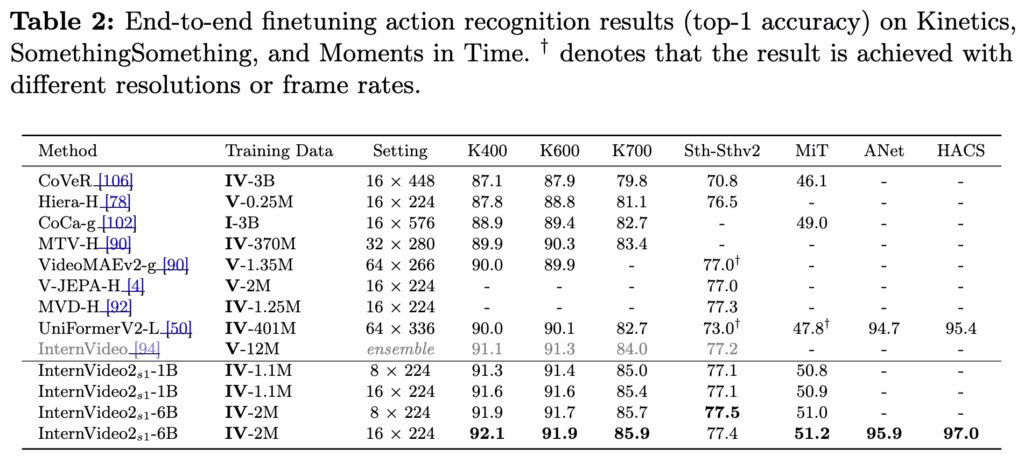
그 중 Table 2인 End-to-end finetuning 세팅에서 Kinetics/SSv2/MiT/ANet/HACS 등 액션 인식 전반 성능을 비교했고, 저자들은 InternVideo2-6B가 16프레임만으로도 기존 SOTA 대비 높은 성능을 보였다고 강조하네요
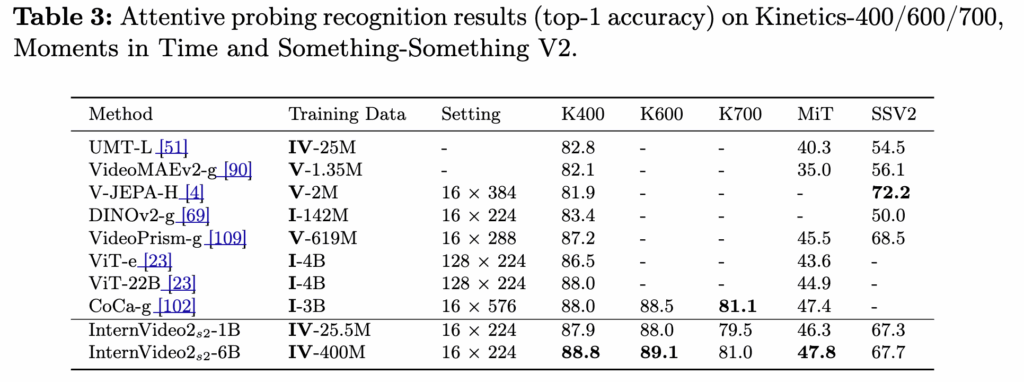
Linear probing은 백본을 고정한 채 class token(또는 평균 풀링 feature) 위에 선형 분류기만 붙여 표현력을 평가합니다. 반면 attentive probing은 백본은 그대로 두고, attention으로 중요한 토큰을 가중합해 읽어오는 작은 헤드를 추가합니다. 토큰에 정보가 분산된 표현에서는 CLS/평균만으로 성능이 과소평가될 수 있어, attentive probing은 이를 보완해 백본의 잠재 성능을 더 공정하게 측정하려는 목적이죠.
Table 3인 attentive probing 결과를 보면 저자들은 scene 중심 데이터셋뿐 아니라 temporal dynamics가 중요한 SSv2에서도 강하거나 비슷한 성능을 보여 공간·시간 정보를 모두 잘 다룬다고 해석합니다,.
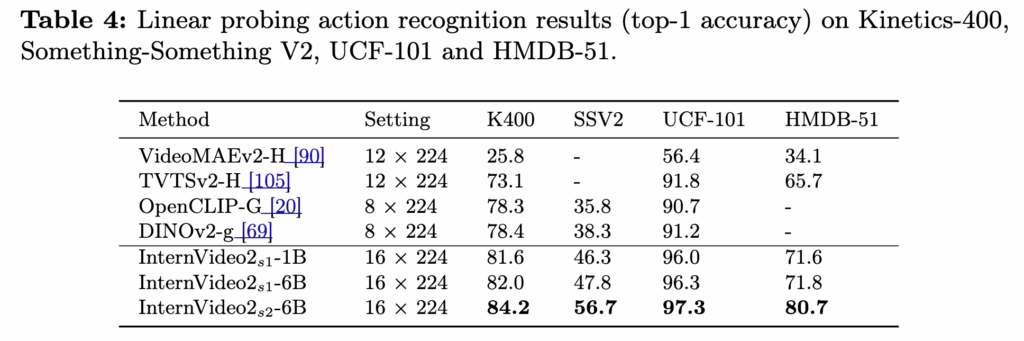
Table 4는 Linear probing 결과로, 모델 스케일업에 따라 성능이 오르고, 특히 stage 2 멀티모달 프리트레인이 추가적인 상승을 만들었다 합니다
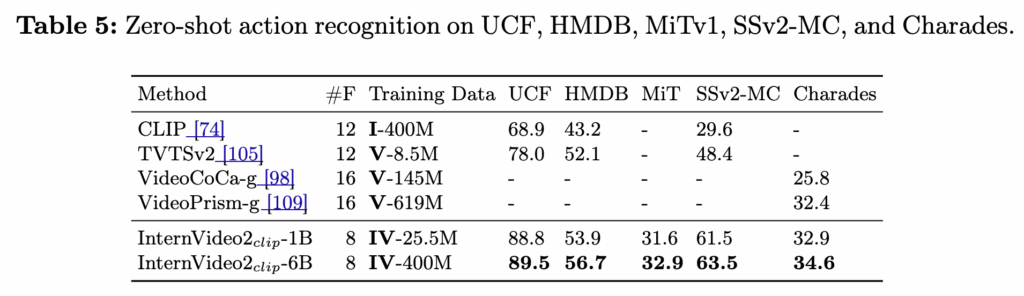
Table 5는 UCF/HMDB/MiT/SSv2-MC/Charades에 대한 zero-shot action recognition 결과로, InternVideo2clip(contrastive만 남긴 CLIP-style)이 다양한 데이터셋에서 높은 zero-shot 성능
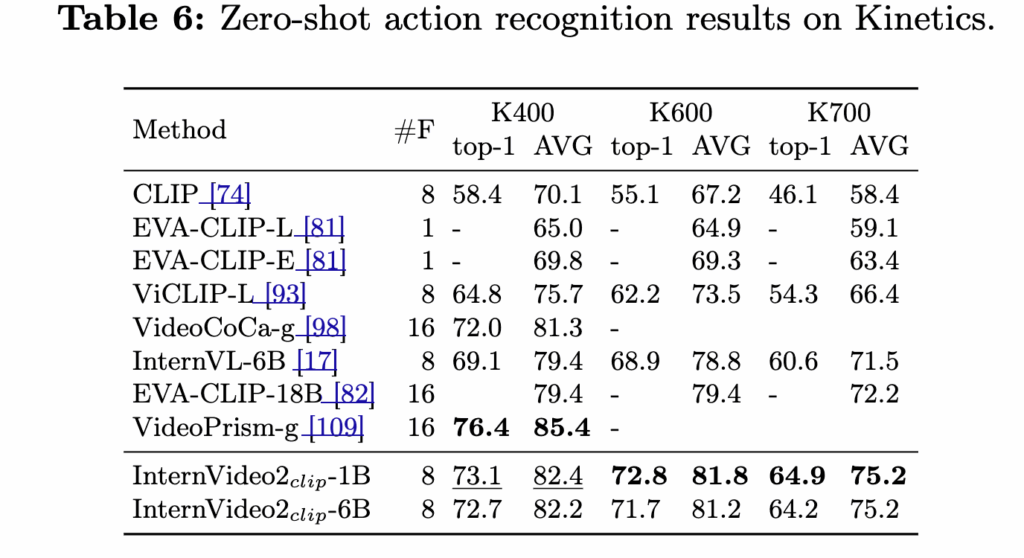
Kinetics(K400/600/700)에 대한 zero-shot 도 Table 6에서 확인할 수 있는데요, InternVideo2가 전반적으로 기존 방법들을 앞서지만 K400에서는 VideoPrism이 더 높은 예외가 있긴 했습ㄴ디ㅏ
4.3 Video Retrieval
비디오-텍스트 리트리벌은 Table 9(Zero-shot)과 Table 10(Finetuning) 실험을 수행하였습니다. 평가 시 비디오에서8 frames를 uniform sampling하고, T2V/V2T의 R@1을 리포팅하였습니다
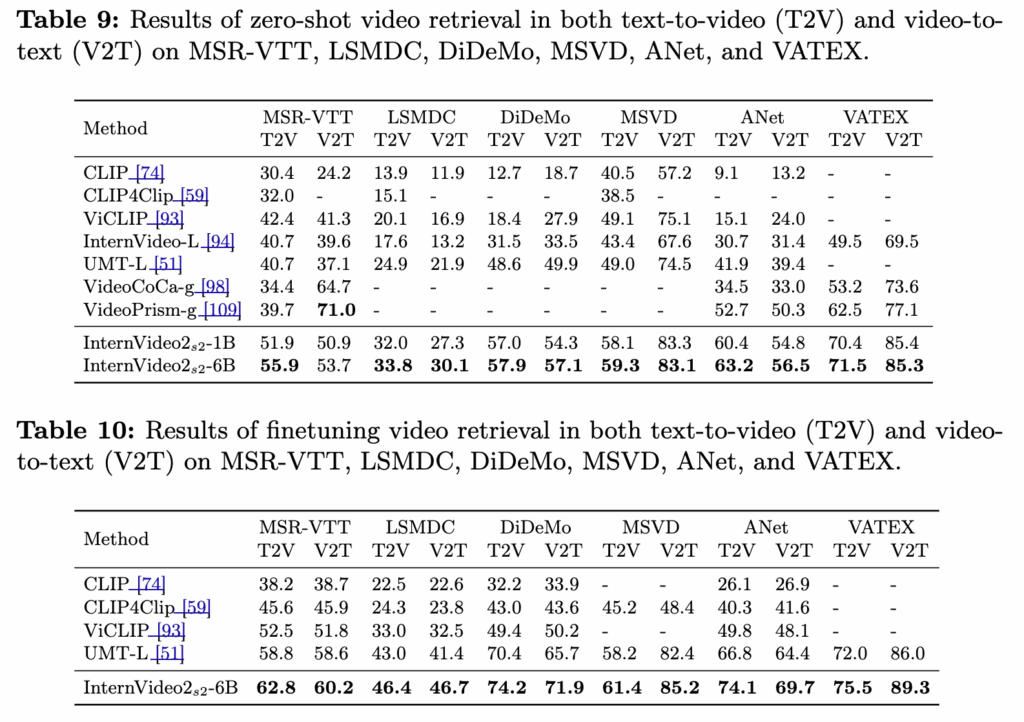
Table 9–10 모두 InternVideo2가 대부분의 데이터셋에서 zero-shot과 finetuning 모두 SOTA 대비 높은 결과를 보였습니다. (단, MSR-VTT의 V2T에서 VideoPrism이 더 좋았음). 이 결과를 통해 InternVideo2는 video-language semantic alignment와 transferrability 의 높은 성능을 가진다는것을 알 수 있었습니다.
4.4 Temporal Grounding

Temporal grounding은 Table 11(QVHighlight / Charades-STA)에 리포팅되어있고, CLIP(또는 CLIP+SlowFast) 기반 특징 대비 InternVideo2 특징이 점진적으로 개선되는 흐름을 보였습니다.
모든 성능에서 뛰어나기도 했고, 이 결과를 통해 단순 retrieval을 넘어서 시간 구간을 맞추는 문제에서도 견고한 성능을 보였다는 것이 의미있지 않았나 싶네요
4.5 Audio-related Tasks
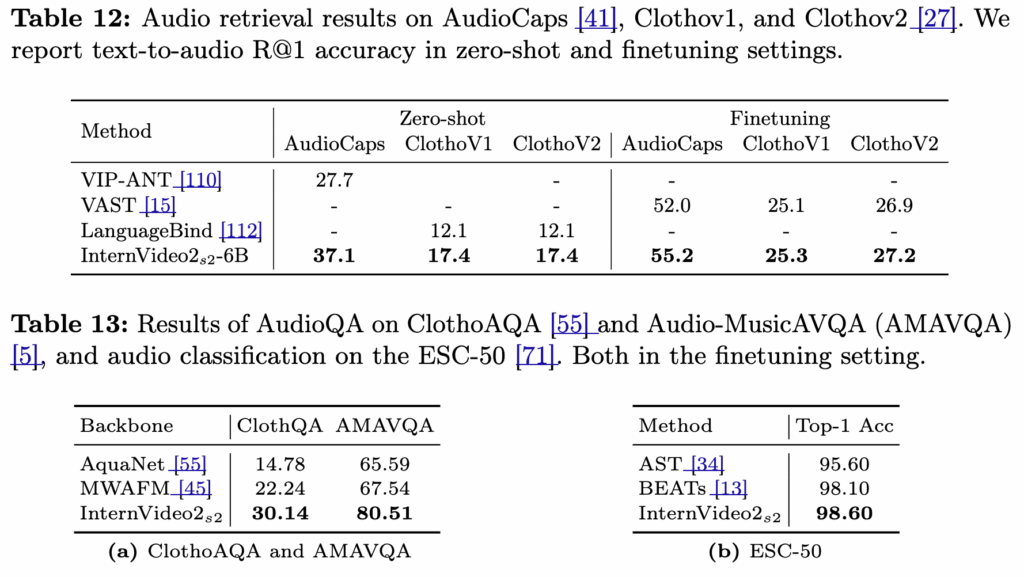
오디오 태스크는 Table 12(오디오-텍스트 리트리벌), Table 13a(AudioQA), Table 13b(오디오 분류 ESC-50)로 평가를 수행하였습니다. 그 결과 모든 downstream에서 SOTA임을 확인하였다고 하는데요.
이 부분에서 저자들은 오디오/텍스트 인코더 규모가 다소 제한적임에도 좋은 결과가 나왔다는 점을 언급하더군요. 이를 통해 crossmodal contrastive learning의 이득이 모달리티 간에 상호적(mutual)이었음을 알 수 있었다고 합니다.
4.6 Video-centric Dialogue
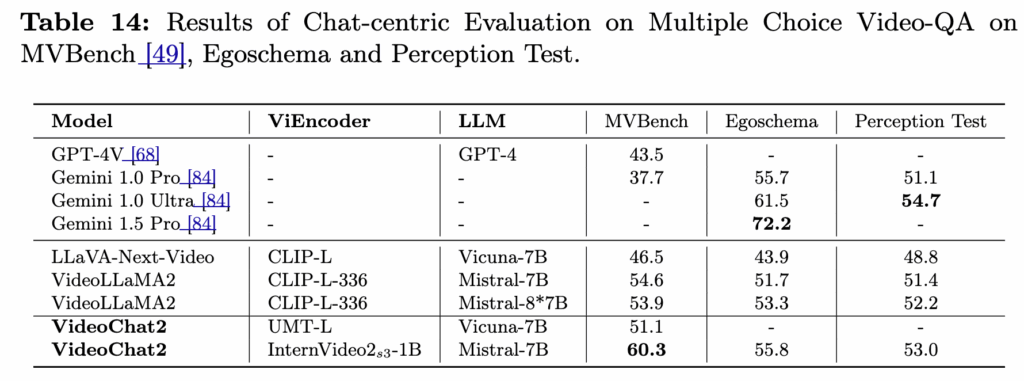
마지막으로 대화/QA 계열 평가는 Table 14(MVBench, EgoSchema, Perception Test)에서 확인할 수 있었습니다. 특히 VideoChat2에 InternVideo2 인코더를 결합했을 때 다른 시스템 대비 유의미한 성능 향상이 있었는데요. 이를 통해 stage3의 next-token 학습이 “비디오를 보고 답하는 형태”로 확장하는 데 의미가 있었다고 언급합니다.
5. Conclusion
InternVideo2는 비디오 파운데이션 모델을 “어떻게 스케일업하면 더 범용적으로 쓸 수 있는가”를 보여준 연구라고 할 수있을 것 같습니다. 특히 시공간 지각–멀티모달 정렬–대화/추론 확장을 3-stage progressive training으로 단계화했고, 그 결과가 분류나 리트리벌을 넘어 비디오-중심 대화까지 이어질 수 있음을 설득력 있게 보여줬다고 생각이 됩니다. 또한 video-text에 그치지 않고 audio/speech까지 확장해 멀티모달 축을 넓힌 점이 인상적이었고, 비디오 인코더를 MLLM 파이프라인의 범용 모듈로 활용할 가능성을 분명히 하지 않았나 싶네요.
다만…. InternVideo2-6B 기준으로 Stage 1은 A100 256장 18일, Stage 2는 A100 256장 14일, Stage 3는 A100 64장 3일 학습했다고 합니다. 결국 이 논문은 “새 아키텍처”라기보다 3단계 학습법 + 데이터 품질(temporal consistency, 캡션 정제) + 엄청난 컴퓨팅 파워로 비디오 파운데이션 모델의 범용성을 끌어올린 것이지 않나… 싶습니
안녕하세요 주영님, 좋은 리뷰 감사합니다.
stage 구조를 나누어 단계적으로 분석해주신 점이 특히 흥미로웠습니다.
한 가지 궁금한 점이 있습니다. stage 과정에서 Stage 1에서 학습된 motion/temporal sensitivity가 Stage 3까지 충분히 보존되는지, 혹은 alignment 및 language supervision 과정에서 일부 정보가 희석되거나 재구성되는 문제는 없는지에 대한 분석이 있는지 궁금합니다.
좋은 리뷰 감사합니다.📽️
답변 감사합니다.
먼저 논문에서 Stage1의 motion/temporal sensitivity가 Stage3까지 직접적으로 얼마나 보존되는지를 정량 분석한 실험은 보이지 않았lignment-language supervision에 맞게 표현이 재구성될 가능성이 높은 것 같습니다. 저자들도 이를 인지했는지, zero-shot action에서 큰 모델이 약간 불리한 케이스를 보여주면서, stage2 데이터가 커지면서 stage1 특성이 일부 잊힐 수 있다는 코멘트를 남기기도 했네요!
안녕하세요 주영님, 좋은 리뷰 감사합니다
stage 2에서 matching loss가 무엇인지 궁금합니다. 같은 정보를 나타내는 멀티모달 임베딩간의 의미가 가까워지도록 하는것인가요?
저자들이 말한 범용성이라는 강점이 저자들이 설계한 3단계 학습 파이프라인과 데이터 정제 덕분이라고 소개해주셨는데, 학습 파이프라인의 핵심은 점차적으로 멀티모달을 잘 정렬하는것이고 데이터 정제는 stage2에서 모달리티 정렬을 위한 정제된 데이터 학습이 중요했다고 이해해도 괜찮은지 여쭤봅니다
감사합니다
1. Stage2 matching loss는 보통 “비디오-텍스트(또는 이미지-텍스트) 쌍이 진짜 짝이 맞는지”를 맞히는 매칭 분류(ITM)입니다. contrastive가 “가깝게/멀게” 정렬이라면, matching은 헷갈리는 네거티브까지 포함해 짝을 더 상세하게 구분할 수 있습니다
2. 네, 정리하신 이해가 맞습니다. 3-stage는 지각→정렬→LLM supervision으로 단계적으로 능력을 쌓는 구조이고, 그중 범용성에 크게 기여하는 구간이 주로 Stage2 정렬이라서 정제된 페어 데이터(특히 VAS 캡션 등) 품질이 중요했다고 보면 될 것 같습니다