안녕하세요. 오늘의 X-Review는 MLLM에서의 이미지, 비디오, 오디오 관련 token compression 서베이 논문을 소개해드리고자합니다. 저번주 Audio-Visual Question Answering task에 대한 논문을 제출한 뒤, 졸업 전까지 VLM을 다루는 연구를 해보려는 상황입니다. 아무래도 연구실 자원으로 VLM을 새롭게 학습시키기엔 무리가 있다보니, 많이들 살펴보고계시는 token compression(pruning, merging) 쪽을 건드리되 오디오라는 모달리티를 중점적으로 다뤄보려고 생각중이었습니다.
VLM 연구도 정말 하루가 멀다하고 빠르게 발전중인 상황인데요, 이에 맞게 token compression 연구도 많이 쏟아져나오고 있는 상황입니다. 마침 26년도 TMLR에 게재된 서베이 논문이 있어 최근 compression 연구는 어떤 추세인지 알아보고자 해당 글을 읽고 정리하게 되었습니다. 아무래도 본 리뷰에서는 각 방법론을 자세히 파고들어 소개해드리기보단 큼지막한 키워드 단위로 최근 방법론들을 정리하고자 하니, 흐름을 이해한다는 관점에서 편하게 읽어주시면 감사드리겠습니다.
오늘 소개해드릴 논문에는 이미지, 비디오, 오디오에 대한 compression 방법론들 정리와 이후 전반적인 compression 방법론에 대한 discussion, 그리고 token compression 이외 다양한 효율화 방법론들과의 비교가 포함되어있습니다. 대략 26페이지 분량으로 내용이 많다보니 이번 리뷰에서는 이미지와 비디오에 대한 compression 방법론 소개까지만 살펴보고, 오디오 방법론 및 여타 discussion 내용은 다음 리뷰에 작성해보겠습니다.
그럼 바로 리뷰 시작하겠습니다.
1. Introduction
앞서 말씀드린대로 최근에는 LLM의 발전에 힘입어 이미지, 비디오, 오디오를 입력받아 VQA나 ASR 등을 수행하는 MLLM이 빠르게 쏟아져나오고있습니다.
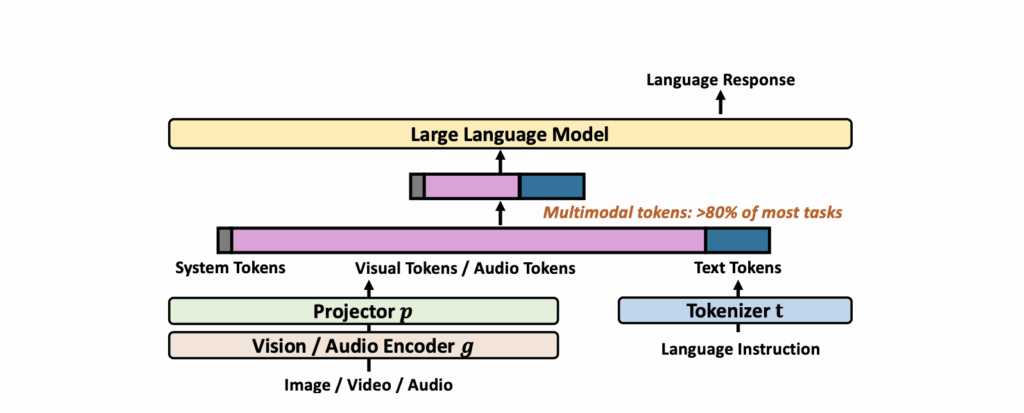
그림 1은 일반적인 MLLM architecture를 보여주고있는데, 각 모달리티 인코더로부터 얻은 token이 텍스트는 그대로, 이미지와 비디오, 오디오는 projector를 거쳐 LLM decoder에 입력되고 있는 모습입니다. 이때 각 인코더와 LLM 디코더는 모두 Transformer 구조를 가지고, 입력 토큰들은 이 안에 포함되어있는 Self-attention 연산을 거치다보니 연산량은 입력 토큰 개수에 quadratic하다는 문제가 있습니다. (참고로 대부분 모델에서 Vision encoder는 CLIP, SigLIP, DINO, Audio encoder는 Whisper, Audio-CLIP을 많이 사용합니다.)
이에 따라 최근에는 입력 토큰 개수 자체를 줄여 성능 손실은 최소화하며 효율성을 극대화하고자 하는 token compression 연구가 활발히 이루어지고 있습니다. 특히 그림 1의 분홍색으로 표시된 visual, audio token이 입력 토큰의 80% 이상을 차지하기에, 해당 모달리티의 토큰 개수를 중점적으로 줄이는 것이 연구의 핵심 목표입니다.
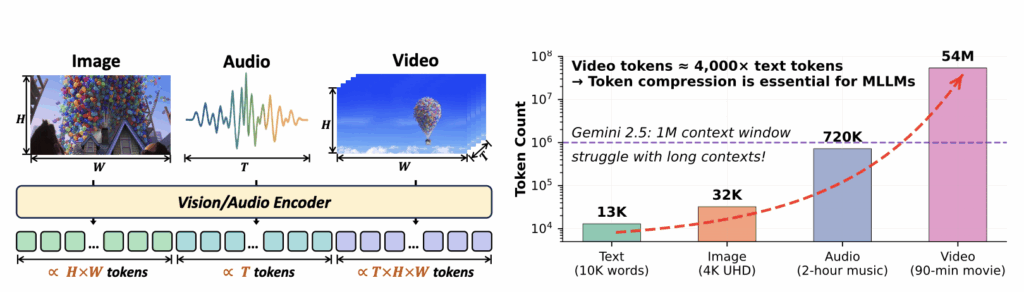
이어서 그림 2를 보시면 왼쪽은 앞서 말씀드린 바와 같이 각 모달리티의 입력 토큰을 보여주고 있습니다. 토큰의 개수 관점에서 생각해보면, 이미지 토큰 개수는 입력 이미지의 해상도에 비례합니다. 고해상도 이미지를 처리할수록 토큰이 많이 생겨나게 되는 것입니다. 그리고 오디오는 공간축이 없다보니 입력 비디오 또는 오디오 시퀀스의 길이에 비례하여 토큰 개수가 늘어나게 됩니다. 마지막으로 비디오는 시공간축을 모두 가지고있다보니 입력 비디오의 공간적 해상도와 길이에 비례하여 토큰 개수가 많아집니다.
그럼 이 토큰들의 개수는 얼마인지 실제 값을 살펴보겠습니다. 일단 그림 2 우측을 보시면 90분짜리 비디오가 54M개, 즉 5,400만개의 토큰으로 변환된다고 하는데 이게 진짜인지는 다시 한 번 살펴봐야할 것 같습니다. 저자는 (90분 * 60초 * 초당 10프레임 * 프레임당 1000개 토큰)이기에 5,400만 개의 토큰이 나온다고 하는데, 실제로 초당 10프레임씩 가져다 쓰는 VLM이 있을지는 모르겠습니다. 물론 초당 2프레임, 프레임당 500개 토큰으로 잡아 1/10으로 준다고 쳐도 단 하나의 비디오가 540만 개의 토큰을 내뱉기에 적은 양은 아닌 것 같습니다. 이 값은 제가 최신 모델들의 처리 방식을 좀 더 알아봐야 확실히 말씀드릴 수 있을 것 같습니다.
추가로 많은 연구에서 집중하고 있는 비디오는 말할 것도 없지만, 오디오도 생각보다 많은 개수의 토큰을 만들어냅니다. 다음 주 리뷰에서 다시 말씀드리겠지만 일반적인 상황에서 오디오는 보통 100Hz로 처음에 얻어지고, 여러 compression을 거쳐 25 또는 12.5Hz로 줄여 쓴다고 합니다. 그러니까 줄여야 1초당 12.5개 토큰을 얻는것이죠. 오디오는 real-world 이해에 시각 정보와 더불어 필수적인 역할을 하기 때문에 반드시 효율화가 이루어져야하는 부분이라 생각합니다. 오디오 특성상 노이즈나 공백이 존재하는데, 이에 집중해보는 것도 유의미할 것 같습니다.
아무튼 토큰 개수와 그 수에 따른 연산 소요 시간까지는 정확히 계산이 어렵겠지만, 이렇게 많은 개수의 토큰들이 Real-world application 관점에서 연산 bottleneck을 유도하는 것은 분명한 사실이기에 compression 연구가 활발히 연구되고 있을 것입니다. 뿐만 아니라 상대적으로 토큰 개수가 적은 LLM 분야에서도 token compression 연구는 많이 진행되고 있기에, VLM에서의 토큰 효율화 연구 필요성은 자명하다고 보여집니다.
이에 따라 본 논문에서는 token compression 관련 최근 연구들을 여러 갈래로 나누어 정리합니다. 가장 먼저 모달리티와 관련해 Image-centric, Video-centric, Audio-centric으로 나누고, 각 갈래에서 또 단순 Transformation-based, Similarity-based 등등으로 나눠 소개하고 있습니다. 이렇게 여러 갈래로 나눌 수 있지만, 근본적으로 compression 연구는 아래와 같은 공통 절차 또는 목표를 가집니다.
- Importance identification
- Redundancy quantification
- Token merging or pruning
이 포인트들을 기반으로 지금부터 관련 연구들을 설명드리겠습니다.
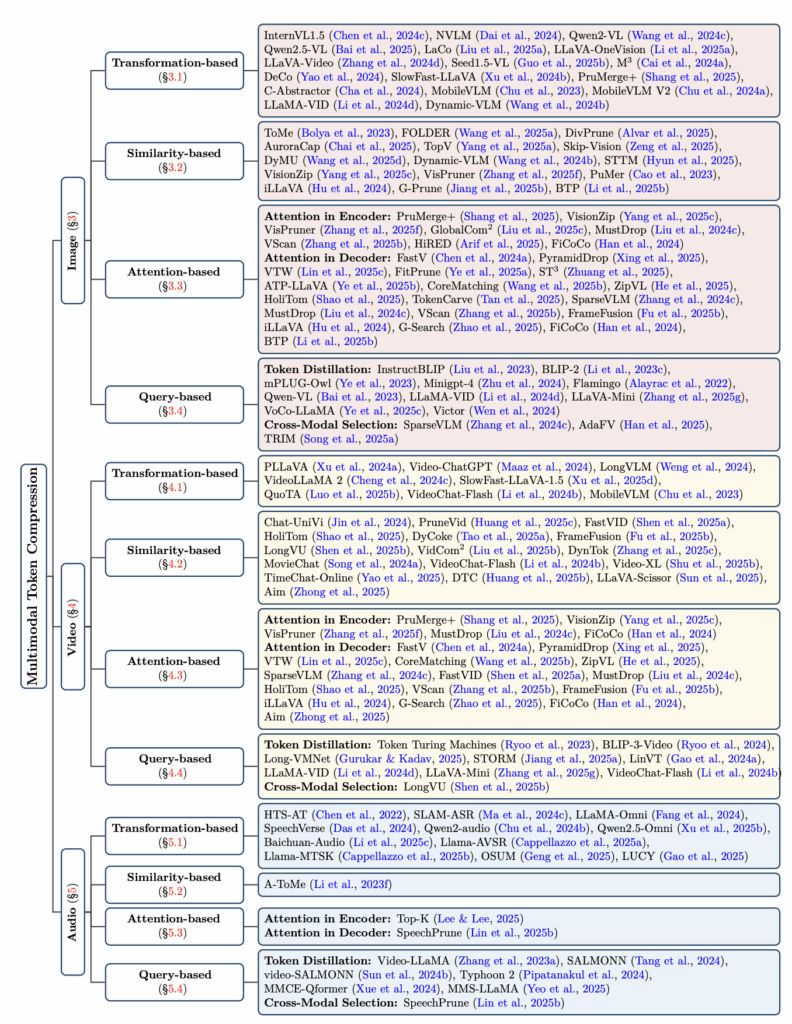
본 논문에서는 이렇게 많은 연구들을 구조적으로 정리해두었는데, 각 연구가 자세히 알고싶으신 분들은 논문의 그림 3을 참고하시면 좋을 것 같습니다. 리뷰에서 소개해드릴 방법론이 많다보니 각 방법론의 reference를 따로 달진 않겠습니다.
설명드릴 방법론에는 일반적인 VLM 모델도 있고, compression만을 위한 방법론도 섞여있습니다. 이들 중 VLM 모델들은 아예 학습부터 하더라도, 구조적 contribution을 위해 compression 관련 기술을 넣기에 포함되어있다고 볼 수 있습니다.
2. Image-centric Token Compression
먼저 3가지 모달리티 중 첫번째로 이미지에 대한 VLM의 token compression 방법론들을 소개합니다.
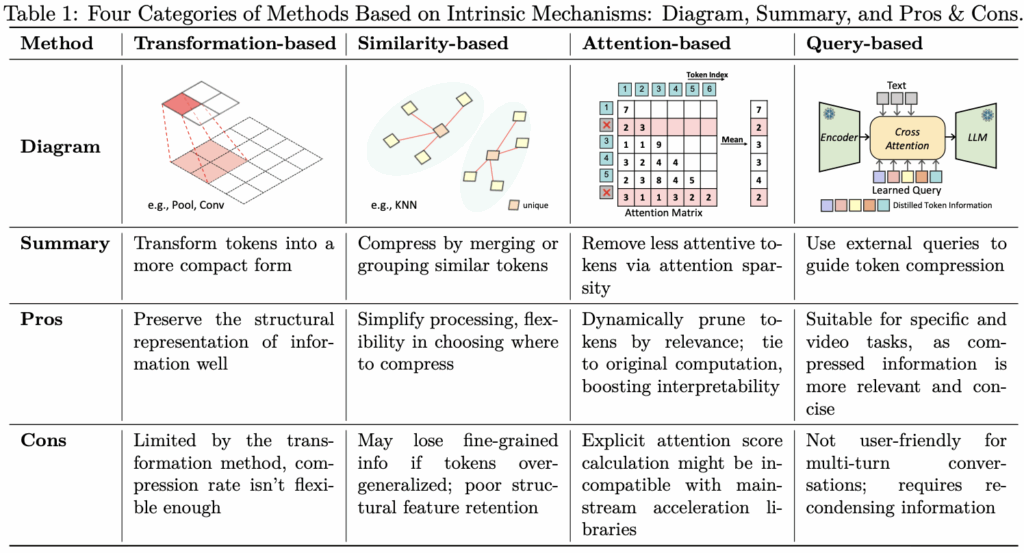
표 1은 이미지 입력에 대한 4가지 compression 방법론의 특성과 장단점을 소개하고 있습니다. 크게 Transformation-, Similarity-, Attention-, Query-based로 나누고 있고, 각 세부 갈래에 대해 살펴보겠습니다.
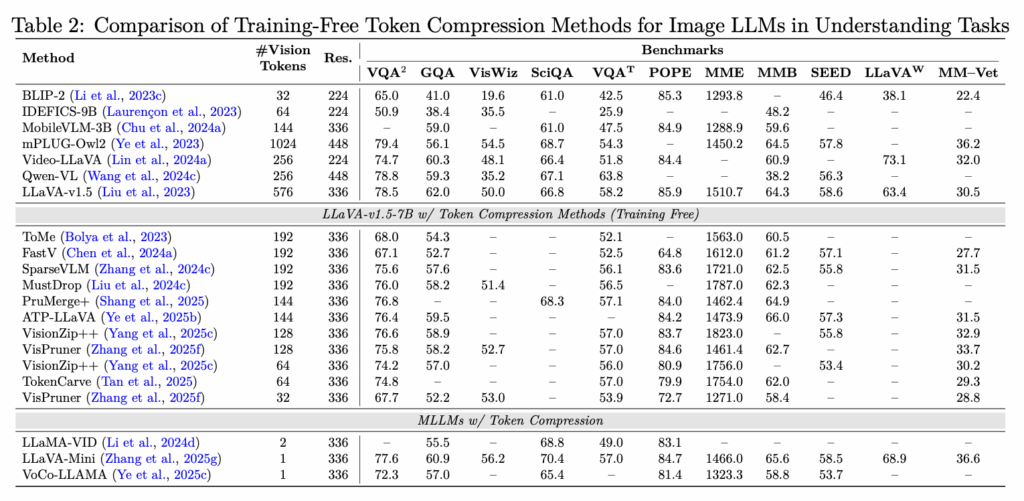
위 표 2는 이미지 기반 compression 방법론들의 대표 벤치마크 성능 비교 표입니다.
2.1 Transformation-based Image-centric Compression
여기서 말하는 transformation이란 parameter-free하게 적용되는 pooling이나 bilinear interpolation 등을 의미합니다. 이미지이다보니 2D 관련 연산들이겠죠.
2.1.1 Pixel Unshuffle
Pixel unshuffle은 pixel shuffle의 역연산이라고 볼 수 있는데, 이 연산은 아래와 같습니다.
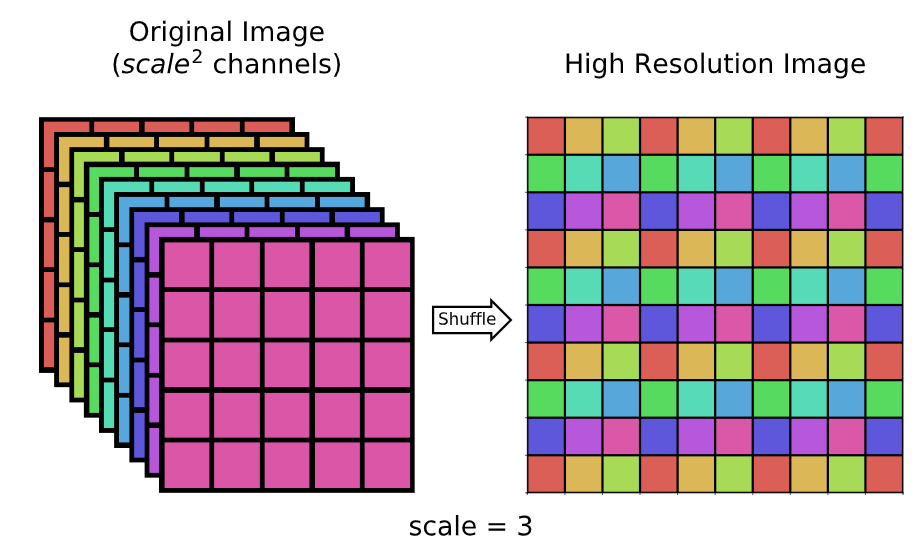
좌에서 우로가는 연산이 pixel shuffle, 우에서 좌로 가면 pixel unshuffle이라고 하는데, pixel unshuffle은 해상도를 낮추고 채널 수를 늘리는 연산이라고 보시면 됩니다. 결국은 아래 수식 (4)처럼 한 이미지를 표현하는 토큰 개수를 줄이되 한 토큰이 갖는 dimension을 키우는 것입니다.
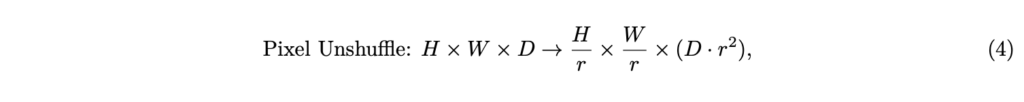
InternVL과 Qwen2, NVLM과 같은 모델이 이 방식을 채택하였으며 학습 파리미터 없이 빠르게 토큰 개수를 줄일 수 있다는 것이 장점입니다. 다만 고정된 ratio (수식에서는 r)을 정해줘야하기에 정해진 몇 개의 개수로만 줄일 수 있다는 점이 flexibility를 떨어뜨리고, 차원 수가 바뀌기 때문에 추가 MLP를 붙여줘야한다는 단점이 존재합니다.
2.1.2 Spatial Pooling / Interpolation
Pixel unshuffle이 차원을 건드리고 MLP를 통해 다시 LLM과 일치하는 차원으로 만들어주는 방식이었다면, 아래 수식 (5)처럼 단순한 2D pooling 또는 interpolation을 통해 해상도만 건드리는 방법도 많이 활용됩니다.
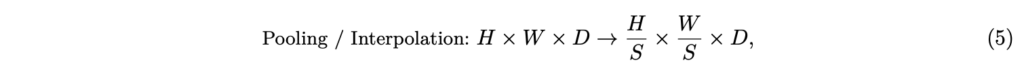
수식 (5)에서 S는 downsampling factor이고 LLaVA-OneVision은 bilinear interpolation, LLaVA-Video는 2D 평균 풀링을 적용합니다. 특히 DeCo라는 방법론은 token compression에 있어 Q-former와 같은 복잡한 연산 없이 단순 풀링만으로도 더 높은 효율성과 성능을 달성한다고 주장합니다.
2.1.3 Spatial Convolution
앞선 방법론들이 parameter-free였다면 여기선 아래 수식 (6)과 같이 2D convolution을 통해 해상도와 채널을 동시에 조절합니다.
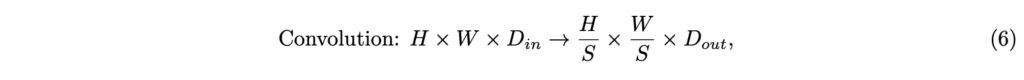
카카오에서 제안한 Honeybee 모델의 projector인 C-Abstractor가 이 2D conv를 활용하고 있습니다. 예전에 인턴할 당시 이 C-Abstractor가 자세 모델의 projector로 사용되었던 기억이 있습니다. 또한 MobileVLM도 depth-wise convolution 연산을 통해 토큰 개수를 획기적으로 줄였습니다.
2.2 Similarity-based Image-centric Compression
이 방식은 이미지 패치 토큰간 유사도를 계산해 중복적인 토큰을 제거하거나 merge하는 방식으로 동작합니다. 대부분 방법론이 이를 위해 패치 토큰간 군집을 만들고, 군집의 중심에 해당하는 토큰을 주로 활용합니다. Vision transformer의 토큰 효율화를 위한 ToMe 방법론을 다들 한번쯤은 들어보셨을 것 같은데, 대략 ViT의 이미지 패치 토큰간 유사도를 모두 구하고 이분 매칭을 통해 유사한 애들끼리는 합쳐버리는 방법론입니다.
MLLM에선 FOLDER, DivPrune, AuroraCap이라는 모델이 vision encoder단에서 유사한 방식을 활용합니다. 아무래도 Vision encoder가 ViT 구조를 갖추고 있으니 거의 그대로 활용할 수 있었을 것입니다. 최근에는 TopV라는 방법론이 이 유사도 기반 방식을 LLM decoder layer로 끌고와 수행했습니다. 이미지와 텍스트의 공통 공간인 LLM decoder 단에서 수행함으로써 효과를 보고자했던 것이고, 공통 공간인만큼 패치 토큰간의 유사도 뿐만아니라 텍스트와 패치 토큰간 유사도 또한 같이 활용하여 유사 토큰을 merge 하였습니다.
이 방식은 원하는 개수로 토큰을 줄일 수 있다는 점에서 flexible하지만 원본의 공간축 정보를 잃게 됩니다. 토큰을 병합할 때 공간축을 고려하지 않고 단순 유사도를 바탕으로 진행하기 때문에 병합 후 표현이 구조적으로 무너질 수 있다는 것입니다. 이러한 공간적 문제를 해결하고자 나중엔 DPC-KNN이라는 기법을 적용하기도 하는데, 이에 대해서는 다음 장에서 살펴보겠습니다. 추가로 토큰들끼리 거의 유사한 표현을 가지고있다면 병합 후 뒷단에서는 표현력을 제대로 학습할 수 없게 된다는 단점도 있습니다.
2.3 Attention-based Image-centric Compression
이 방식은 VLM 모델 내 attention 연산에서 얻을 수 있는 score를 기반으로하여, 이 점수가 낮은 토큰은 무의미하다고 판단하고 pruning하거나 merging해버립니다. 이때 VLM의 vision encoder와 LLM decoder 모두 attention 연산 기반으로 동작하기에 어떤 시점에서의 attention 값을 쓰는지에 따라 나눠볼 수 있습니다.
2.3.1 Attention in Encoder
ViT와 같은 구조의 vision encoder는 이미지만을 입력받고 처리합니다. 이 단계에서 패치 토큰끼리의 attention weight가 계산되는데, 이 값을 각 패치 토큰의 중요도라 가정하고 덜 중요한 토큰을 지우는 것입니다. 대부분은 이미지를 대표하는 [CLS] 토큰과 나머지 패치의 attention score를 기준으로 Top-K개 패치만을 살리게 됩니다. 즉 같이 입력되는 텍스트 형태의 질문이나 system prompt와 관계 없이 이미지만 보고 중요한 토큰을 남기는 방식입니다.
먼저 Prumerge는 [CLS] 토큰과의 attention 기준 Top-K개 패치를 cluster center로 선택합니다. 이후 나머지는 KNN으로 병합하는 방식을 통해 패치 토큰의 개수를 줄입니다. VisionZip은 가장 높은 score의 패치를 원본 그대로 살리고 나머지는 유사한 토큰끼리 병합합니다. VisPruner도 가장 높은 score의 토큰을 살리지만, 나머지는 여러 round에 걸쳐 제거한다는 차이가 있습니다.
2.3.2 Attention in Decoder
Vision encoder에서 이미지 내부 정보만으로 토큰의 중요도를 판단하는 앞선 방식들과 달리, 이 방식은 텍스트와 공통 임베딩 공간에 해당하는 LLM decoder에서 얻은 attention score를 기준으로 토큰의 중요도를 선정합니다. 즉 입력 질문을 함께 고려할 수 있게 된 것입니다. Decoder의 self-attention에 관여하는 입력 텍스트, system prompt, 나머지 비전 패치 토큰들이 하나의 토큰을 얼마나 많이 참조하는지를 기준으로 삼는 것입니다.
FastV라는 방법론은 LLaVA 1.5의 2번째 layer 이후 visual token이 system prompt로부터 0.21%만 attention을 받는다는 사실을 활용합니다. 2번 layer 이후 attention을 많이 받지 못하는 토큰의 50%를 나머지로 aggregate해버리고 높은 성능을 달성하게 됩니다. 다음으로 PyramidDrop은 얕은 층에서 많은 token의 loss를 방지하기 위해 점진적으로 token compression 수행하고, VTW는 특정 레이어 이후의 토큰을 모두 버리는 공격적인 방식을 채택합니다.
이어서 FitPrune은 decoder 층 별로 토큰을 몇 개씩 버리고, encoder 내에서의 self-attention weight와 text와의 cross-attention 가중치를 고려하여, pruning 전후 토큰 분포의 gap을 최소화하는 최적의 pruning recipe 찾는 것을 목적으로 합니다. ATP-LLaVA는 현재 입력에 맞는 pruning ratio를 학습 기반으로 찾아 adaptive한 pruning을 수행하는 방법론입니다. 이외에도 adaptive pruning/merging 방법론들이 최근 다양하게 등장하고 있는 것으로 보입니다.
다만 이렇게 LLM decoder에서의 attention weight를 쓰는 방법론에는 단점이 있습니다. 최근 VLM은 연산 가속화를 위해 FlashAttention 라이브러리의 attention 방식을 사용하는데, 이 FlashAttention은 전체 시퀀스에 대한 attention weight를 저장하지 않습니다. 매우 긴 입력 시퀀스를 일부 블록으로 자르고 attention을 계산한 뒤 바로 버리는 방식이기에 메모리를 획기적으로 줄일 수 있었고, 줄어든 정보량에 대한 read/write로 속도 또한 굉장히 빠르게 가져갈 수 있었습니다. 그렇다보니 compression의 기준이 되는 attention 값을 중간에서 얻을 수가 없게 되는 것입니다.
이 부분은 제가 이전에 인턴 수행할 때도 겪었던 문제인데, hook을 통해 중간 과정에서 떨어지는 attention을 layer마다 가져오는 번거로운 작업을 추가해줬던 것으로 기억합니다. 아무튼 이러한 방식은 효과적이긴 하지만 현재 default처럼 적용되어있는 FlashAttention과 호환되지 않는다는 점에서 발전이 필요하다고 볼 수 있습니다. 논문에서도 이 점을 critical challenge라 부르고 있네요.
2.4 Query-based Image-centric Compression
이제 방법론 갈래중에선 마지막인 query-based 방식입니다. 여기서 이야기하는 query는 이미지와 함께 들어오는 질문이라고 보시면 될 것 같습니다. 이미지 패치 중에서도 대다수는 실제 질문과 무관한데, 이 점을 활용해 유관한 패치만을 남기는 것이 이 방식의 목적입니다. 이 query-based 방식은 다시 두 개의 세부 갈래(token distillation, cross-modal selection)로 나뉩니다.
2.4.1 Token Distillation
이 방식의 목표는 패치 토큰의 개수도 줄이고, 동시에 질문과의 정합도 맞추는 것입니다. 꽤 오래전부터 존재했던 Q-Former 시리즈는 learnable queries를 활용한 cross-attention을 통해 핵심적인 visual 정보만 고정된 개수로 추리도록 동작합니다. 유사하게 MLLM 쪽에서는 mPLUG-Owl, MiniGPT-4, Flamingo, Qwen-VL이 이 Q-Former 방식을 활용해 핵심 visual 정보를 뽑아냅니다. 특히 LLaMA-VID는 굉장히 공격적으로 compress하는데, 한 프레임을 단 2개의 토큰으로 표현합니다. 한 이미지에 대해 Q-Former 방식을 활용한 Context 토큰 하나와 패치 토큰을 평균 풀링하여 만든 Content 토큰 하나를 stack해서 쓰는 것이죠.
2.4.2 Cross-Modal Selection
이 방식은 한 모달의 정보를 바탕으로 정합되어있는 다른 모달리티의 토큰 개수를 줄입니다. SparseVLM은 visual 정보를 바탕으로 text 토큰의 개수를 줄여 중요한 instruct나 단어만 파악하는 것이 목적입니다. 방법론의 이름은 알고있었지만 패치 토큰이 아니라 입력 텍스트 토큰의 개수를 줄인다는 점이 놀라웠습니다. 요즘엔 In-context learning, CoT 등등 방법이 성행하며 입력 텍스트의 길이도 꽤 길어지고 있는데, 이때 현재 질문에 맞는 예시만 뽑아서 많이 참조한다 정도의 컨셉으로 볼 수 있을 것 같습니다.
AdaFV는 visual token 줄이기 위해 text-to-image 유사도와 visual saliency를 모두 활용합니다. 추가로 TRIM이라는 방법론은 텍스트와 패치 토큰 간 유사도를 바탕으로 사분위수(Interquartile Range) 기준 outlier 토큰을 선정하고, 이를 중요하게 여겨 나머지를 merging 해버립니다.
지금까지 소개해드린 query-based 방법론들은 입력 질문 또는 전체 텍스트를 기준으로 패치 토큰의 중요도를 산출하였습니다. VisionZip을 비롯한 Attention in Encoder 방법론들이 지적하는 query-based 방법론의 단점은 바로 multi-turn QA에 취약하다는 점입니다. 연산 효율성을 위해 패치 토큰을 줄이는데, 이 기준이 입력 질문이다보니 다음 질문이 이어 들어온 경우 연산을 다시 한 번 해야한다는 점이 모순적이라는 것이죠.
여기까지 하여 Image-centric compression 방법론들의 갈래에 대해 알아보았고, 다음은 Video-centric compression 방법론들을 정리해보겠습니다.
3. Video-centric Token Compression
단일 이미지에 비해 고해상도 비디오는 시간축이 더해지기 때문에 훨씬 더 많은 수의 토큰을 만들어내게 됩니다. 원본 비디오는 최소 24 FPS 이상의 frame rate를 가지는데, 아무래도 이 프레임들간 시간적 중복성도 크고 모두 입력했을 때 수반되는 연산량이 너무 크기에 보통의 VLM은 1 FPS로 샘플링하게 됩니다. 이렇게 초당 1개 프레임을 쓰더라도 비디오 길이가 길어지면 선형적으로 패치 토큰 개수도 많아지기에, 비디오를 처리할 땐 시간축을 고려한 공간축의 compression이 핵심입니다.
비디오 관련 compression 연구도 이미지와 유사하게 Transformation-, Similarity-, Attention-, Query-based로 나눠볼 수 있습니다. 여기선 spatial 축 보다는 중복성이 큰 temporal 정보를 어떻게 줄여나가는지에 집중해보면 좋을 것 같습니다.
3.1 Transformation-based Video-centric Compression
3.1.1 2D/3D Pooling
초기 비디오 모델인 LLaVA-Video에선 단일 프레임에 대한 2D spatial pooling만 적용합니다. 즉 시간축을 고려하지 않기 때문에 비디오 길이가 길면 효율성 효과가 제한되는 것입니다. 이후에는 시간축으로도 downsampling하는 PLLaVA, Video-ChatGPT, SlowFast-LLaVA, LongVLM 등이 등장하였습니다. 특히 PLLaVA라는 방법론이, 비디오는 공간축보다 시간축 쪽 pooling이 효과적임을 증명했습니다. LLaMA-VID는 단일 이미지 입력엔 공간축을 유지하지만, 10분 이상의 긴 비디오는 프레임 당 1개 토큰으로 줄여버립니다. 앞서 LLaMA-VID는 단일 이미지 입력은 2개 토큰으로 줄인다했는데, 추론 시 이미지 해상도나 비디오 길이에 따라 유동적으로 선택할 수 있는 것으로 보입니다.
다음으로 SlowFast-LLaVA는 Slow와 Fast 두 개의 stream 활용합니다. Slow는 직관적으로 생각했을 때 천천히 살펴본다는 의미로, 공간축 많이 유지하고 시간축에서는 많이 생략합니다. 다음으로 Fast stream은 빠르게 훑어보는 역할로 시간축을 많이 유지하되 공간축을 축소합니다. 하나의 비디오에 대해 각 stream을 태워 얻은 결과물을 concat하여 LLM에 넘겨줍니다.
3.1.2 2D/3D Convolution
Convolution 연산의 파라미터 기반으로 토큰 개수를 줄이는 방식입니다. VideoLLaMA2는 2D와 3D Convolution을 여러개 비교해가며 어떤 방식이 가장 적합할지 실험하였습니다. 결과적으로는 3D Conv가 가장 좋은 성능을 보이며 비디오에선 확실히 시공간축을 동시에 고려하는 것이 중요함을 시사하였습니다.
3.2 Similarity-based Video-centric Compression
기본적으로 비디오에서 인접하는 프레임 간에는 배경도 비슷하고 행동의 변화가 적습니다. 즉 유사도가 크기에 공간축 compression보다 좀 더 우선시되거나 동시에 적용됩니다. 이렇게 불필요한 프레임을 판별하고 처리하기 위해 대부분 프레임을 먼저 군집화합니다.
Chat-UniVi는 DPC-KNN을 통해 프레임을 먼저 추려 장면을 분할합니다. 앞서 DPC-KNN에 대해 한번 언급했었는데, DPC는 단순히 다른 샘플과의 거리만 고려하는 것이 아니라 전체 데이터 분포를 고려하는 군집화 방법론입니다. 먼저 내 주변에 몇 개의 샘플이 있는지, 즉 밀도를 계산합니다. 다음으로는 자신 주변에 밀도가 높은 샘플이 얼마나 많은지를 고려해 데이터 분포에서 좀 더 유의미한 군집을 만들어 내는 것입니다. 이렇게 주변 샘플을 탐색하는 과정에서 KNN을 활용하는 것이 DPC-KNN입니다. 이렇게 얻은 군집의 중심을 비디오 관점에선 중요한 이벤트 프레임이라 보는 것입니다. 이후 Chat-UniVi는 중심이 아닌 프레임들을 병합하고, spatial 축에도 동일한 과정을 별도로 적용해서 토큰 개수를 줄였습니다.
FastVID는 프레임은 단순히 인접 프레임 간 유사도로 추리고, 공간 축에 대해서는 DPC-KNN으로 토큰을 압축합니다. PruneVid는 Chat-UniVi와 동일한 방식을 적용하지만, 시공간축 별도로 압축하던 Chat-UniVi와 다르게 추려진 시간축의 프레임에 대해서만 DPC-KNN을 적용한다는 차이가 있습니다. DyCoke는 프레임들을 4개 그룹으로 묶고 각 그룹 내에서 pruning 바로 적용합니다.
3.3 Attention-based Video-centric Compression
Vision encoder 안에서 attention 기반으로 효율화하는 방법론들은 대부분 비디오를 이미지의 연속 입력으로 간주하기 때문에 앞서 정리한 이미지에서의 처리와 유사합니다.
LLM decoder에서의 attention을 활용하는 방법론도 이미지에서의 방식과 유사합니다. 다만 길이가 매우 긴 비디오에 대해서는, 마치 짧은 비디오의 연속으로 간주하는 것과 같이 특정 크기의 window 내부에서만 attention 연산을 하고 토큰 개수를 줄이는 방식을 활용한다고합니다.
3.4 Query-based Video-centric Compression
3.4.1 Token Distillation
비디오 입력에 대해서는 Q-Former나 TTM(Token Turing Machine)을 적용합니다. 결국은 learnable query 활용하는 것인데, 특히 TTM은 외부 메모리 토큰을 두어 긴 비디오를 입력받았을 때 현재 구간(timestep)의 정보를 외부 메모리(토큰)에 순차적으로 누적시키는 방식입니다. 사실상 무한한 길이의 비디오를 처리할 순 있지만, 시간이 쌓일수록 표현력이 약화되겠죠.
BLIP-3-Video는 temporal encoder를 따로 두어 수백개의 프레임 토큰을 16-32개로 압축시킵니다. LinVT는 plug-and-play 형태의 Linear Video Tokenizer를 활용하는데 프레임 토큰을 선형결합을 통해 aggregate하는 방법론입니다. Spatio-temporal scoring, multi-scale pooling, text-conditioned aggregation 과정을 거쳐 질문에 부합하는 정보만을 남긴다고 합니다. 이외에도 학습 기반 토큰 sampler를 통해 각 비디오에 대한 메모리 뱅크를 만드는 LongVMNet, Mamba 기반의 temporal encoder를 두는 STORM이 존재합니다.
3.4.2 Cross-Modal Selection
마지막으로는 질문 feature 기반의 visual 정보 압축입니다. 다양한 시공간적 정보를 가진 비디오에서 실제 정답을 맞추기 위해 요구되는 영역은 극소수일 수 있는데, 모델이 항상 비디오의 모든 정보를 다 받을 필요는 없습니다. 이에 따라 질문의 의미를 파악하고 유관한 visual 정보만 넘겨주는 방식이 존재합니다.
LongVU는 질문과 비디오의 cross-modal interaction을 통해 점수가 높은 프레임의 정보는 많이 보존하고, 점수가 낮은 프레임의 정보는 많이 압축하여 뒷단에 전달함으로써 효율성을 올리는 방법론입니다.
우선 글이 길어질 것 같아 이번 주차 리뷰에서는 여기까지 알아보겠습니다. 방법론 이름이 많이 나와서 그렇지 피상적으로만 알아봤기에 어려운 내용은 없으셨을 것 같습니다.
다음주에는 오디오 모달리티에서의 token compression 방법론과 다양한 discussion, 생각해볼 지점들을 소개해드리도록 하겠습니다.