안녕하세요. 이번 X-Review에서는 로봇 관점에서 attribute를 알아내고자 하는 논문에 대해 다루어보려고 합니다. CaP나 VoxPoser와 마찬가지로 LLM이 직접 코드를 생성해 계층적으로 API를 호출하는 방식을 활용하며, 이를 통해 로봇이 상호작용할 객체의 세밀한 속성을 찾아내고자 하는 연구입니다.
attirbute detection의 성능 개선 자체에 초점을 맞추었다기보다, 이를 로봇 도메인에 적용했을 때 VLM 단독으로써의 한계점을 지적하고 이를 프로그램(API) 호출 방식을 통해 개선했다 정도로 이해하시면 될 것 같습니다.


1. Introduction
로봇은 일반 사용자로부터 명령어를 이해하고 스스로 실행할 수 있어야 합니다. 자연어로된 지시는 언어적으로 모호할 수 있기 때문에 어려운 문제입니다. “선반 위의 오른쪽에서 두 번째 머그잔을 가져다줄래?”와 같은 지시가 그 예시입니다. 이러한 명령어를 물리적인 세계와 연결하고, 행동의 실행 가능성을 확인하기 위한 객체의 상태 또는 affordance를 결정하기 위해서는 객체의 attribute를 식별하는 것이 필요하다고 저자는 말합니다.
이러한 속성은 반드시 절대적인 것이 아니라, 상황에 따라, 주변 객체에 따라 상대적일 수 있습니다. 또한 로봇이 활동하는 동적인 환경에서는 occlusion 등으로 인해 속성이 더 모호해지기도 하죠. 이런 경우 속성을 잘못 탐지하면 잘못된 객체를 포함하는 plan을 생성할 수 있으며, 객체의 affordance를 오해하여 행동을 실행할 수 없는 문제들이 발생합니다.
기존의 attribute detection 모델들은 주로 supervised training이나 contrastive pre-training 방식으로, 저자는 이렇게 VLM만을 사용한 attribute detection 방식은 real-world의 로봇 조작에 쓰이기에 부족하다고 지적합니다. 따라서 LLM의 code generation 및 reasoning 능력을 활용한 보다 능동적인 방식을 제안하였습니다.
이에 따라 본 논문의 주요 contribution은 다음과 같습니다.
- attribute detection에 VLM을 단독으로 사용하는 방식의 단점을 강조하고, LLM이 생성하는 program 형태의 상호 보완적인 추론 능력을 강조합니다.
- 시각적인 추론과 로봇 제어 기능을 통합한 perception-action API를 구축하고, 그 이점을 입증합니다.
- 실제 로봇 플랫폼에서 사용 가능한 end-to-end framework를 제시합니다.
2. Related Work
Attribute Detection
기존에는 OVD를 attribute detection에 적용하려는 시도들이 있었는데, 대다수의 VLM은 OVD에 비해 attribute detection 능력이 여전히 부족합니다. 또한 embodied 환경이 아닌 상태에서 단순히 시각적으로 인식 가능한 속성들에만 집중하고 있습니다. 이와 달리 저자들은 객체의 무게와 같이 visual뿐만 아니라 physical적인 속성에도 집중하고자 했고, 이를 위해 VLM의 physical reasoning 능력을 활용합니다. 또한 저자들이 제시하는 프레임워크가 객체의 속성에 대해 추론하기 위해 능동적인 인식 행동을 유도할 수 있다고 주장합니다.
LLM as Embodied Agents
LLM을 활용하여 사람의 자연어 instruction을 실행 가능한 로봇 action으로 planning하는 연구들이 진행되어 왔습니다. 주로 few-shot prompting 방식이 사용되는데, 몇 가지 명령어와 그에 대응하는 행동 계획을 제시하면, 보지 못한 작업에 대해서도 적절한 planning을 수행할 수 있습니다. SayCan, CaP, VoxPoser, ProgPrompt 등이 그러한 예시입니다. 주로 이러한 방식들은 행동 계획을 프로그램(코드)로 표현해 LLM에게 프로그램을 생성하게 합니다. 프로그래밍 도구를 이용함으로써 조건문, 반복문 등을 처리할 수 있고 재귀적인 코드 호출을 통해 복잡한 추론을 가능하게 합니다. 그러나 여전히 perception을 OVD와 같은 시각 모델에만 의존하여, 어려운 시나리오에서는 올바른 속성 탐지를 처리하지 못할 수 있다고 저자들은 지적합니다. (위 문단에서 기술했듯이 OVD 모델 자체가 속성을 검출하는 성능이 부족하기도 하고, 언어적으로 모호하거나 상대적인 서술, 또는 로봇이 이동하며 직접 측정해야 하는 능동적인 행동을 요구하는 경우에는 OVD만으로 부족하기 때문입니다.)
3. Method
A. Problem Statement
scene에 있는 객체 집합 O와 센서 집합 S를 가진 로봇을 고려합니다. 로봇은 자연어 지침 inst = f(a, g, o, img) 를 실행해야 합니다. a는 high-level action, g는 객체의 속성, o는 객체, img는 입력되는 scene 이미지입니다.
목표는 해당 속성을 가진 객체가 존재하는지 여부를 결정하고( g(o) 로 표현되며, 0 또는 1입니다.), 해당 객체의 bounding box X를 얻는 것입니다. 만약 g(o)가 참이 되는 o가 존재한다면 visual navigation policy 𝜋(a(X))가 주어집니다. 로봇은 센서 S를 활용하여 객체 o를 탐색하고 조작하여 task를 완료합니다.
이때 속성은 반드시 시각적인 속성일 필요가 없으며, 객체의 크기나 무게와 같은 형용사 표현뿐만 아니라 ‘왼쪽에서 두 번째 객체’와 같이 공간적인 관계를 나타내는 전치사구도 포함됩니다.
B. Prompt-based Attribute Detection
이 문단에서는 속성 감지를 위한 Python API를 구축하는 방식에 대해 설명하고 있으며, ViperGPT의 접근 방식을 채택했다고 합니다. 이 API는 input 이미지 img에 의해 인스턴스화되는 “ImagePatch” 클래스로 구성됩니다. “find”는 OVD 모델(GLIP)을 사용하여 객체 o를 찾고 bounding box X를 반환합니다. “visual query”는 pretrai된 VLM(BLIP-2)를 호출하여 이미지와 visual query에 대한 텍스트 답변을 제공하고, “language query”는 “visual query”에서의 반환값을 textual query로 하여 LLM을 호출합니다.
C. Programmatic Reasoning
프로그램 형태의 추론은 데이터의 구조나 내장 method들을 통해 프로그래밍 언어의 표현력을 상속받습니다. LLM이 생성하는 프로그램은 loop를 호출할 수 있고, 또 조건문을 사용하여 입력 이미지에 객체가 존재하는지의 여부와 객체가 속성을 가지고 있는지의 여부를 결정합니다.
또한 python의 list 자료구조는 append 함수를 사용하여 image patch 인스턴스를 동적으로 저장할 수 있습니다. sort 및 lambda 등의 내장 함수를 통해 탐지된 bounding box의 꼭짓점 좌표와 중심점, 면적 등을 간단히 구할 수 있으며, 간단한 기하학적 개념을 활용해 객체의 크기 또는 상대적인 위치를 추론할 수 있습니다. 복잡한 language query를 이러한 계산으로 매핑하기 위해서는 LLM의 commonsense reasoning 요소가 필수적입니다.
D. Vision-Informed Language Reasoning
저자들은 VLM의 시각적인 인식 능력과 LLM의 상식 및 추론 능력을 결합함으로써 상호 보완적인 추론을 가능하게 하고자 했습니다. 특히 객체의 무게과 같이 시각적으로 인지할 수 없는 속성을 다룰 때 효과적일 수 있습니다. 이 경우에 VLM의 visual query를 통해 zero-shot으로 객체를 detection하고, 이 detection된 객체 정보를 language query의 입력으로 전달하여, LLM이 자신의 지식을 바탕으로 객체의 무게를 추론할 수 있습니다. 또한 상대적인 속성을 찾으려는 경우, 대상 객체만 가지고 추론하면 해당 속성의 유무를 파악할 수 없기 때문에, 대상 객체 주변의 인접한 객체들을 바탕으로 text query를 제시하면 모호성이 줄어들 수 있습니다.
E. Embodied Attribute Detection
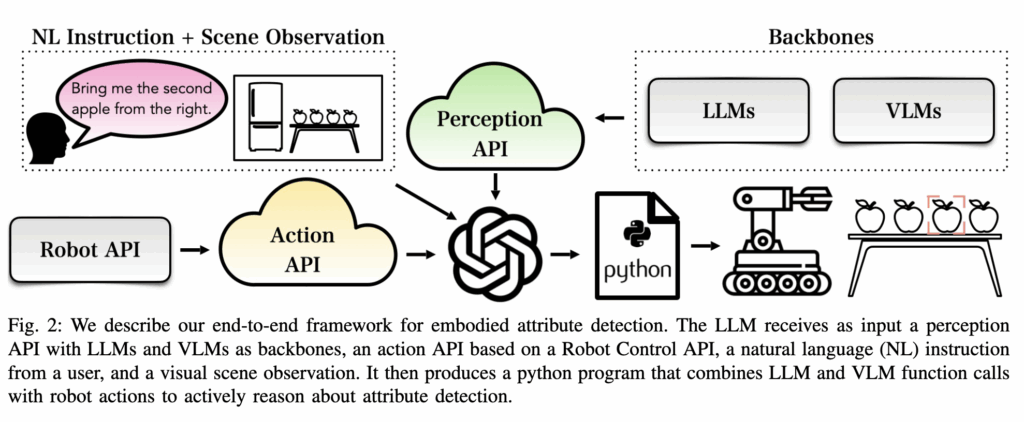
Embodied 환경에서의 attribute detection은 앞서 말씀드렸듯이 능동적인 인식이 필요합니다. 이를 위해 Fig. 2에서 보이는 바와 같이 Action API와 Perception API를 함께 활용합니다. Perception API는 B절에서 소개해드렸고, Action API는 “go_to_object”, “go_to_coords”, “pick_up”, “put_on” 등의 이동 및 조작 명령입니다. 또한 추가적인 센서가 있다면 이를 활용할 수 있는 API도 정의되어 있는데, 예를 들어 카메라부터 객체까지의 거리를 측정하는 함수가 있습니다. (RGB-D 카메라나 depth를 추정하는 모델이 없는 경우 사용할 수 있습니다.) 이미지 프레임의 중심을 객체의 patch에 정렬하는 “focus_on_patch”, 센서를 통해 카메라에서 해당 객체까지의 거리를 계산하는 “measuer_distance” 함수가 있습니다. 추가로 “measure_weight” 함수는 로봇이 pick 중인 객체의 무게를 측정할 수 있습니다. 또한 각 함수의 호출 조건들을 docstring에 명시해 LLM이 올바른 호출 순서를 생성할 수 있도록 하였습니다.
4. Evaluation
A. Spatial Reasoning
attribute detection API의 공간 추론 능력을 OVD 모델과 비교하는 실험입니다. 저자들은 Odd-One-Out 데이터셋을 기반으로 200개의 어려운 spatial query로 구성된 데이터셋을 수동으로 제작하였습니다. 저자들은 명백히 다른 객체를 구별하는 것이 아니라, 상대적인 속성에 기반하여 객체를 구별하는 추론을 유도하고자 했습니다. 이를 위해 200개의 spatial query를 100개의 location query와 100개의 size query로 구성하였습니다. 먼저 location query는 “뒤에서 두 번째 행의 왼쪽에서 두 번째 우산” 또는 “맨 밑의 중간 창문”과 같이 객체의 수와 상대적인 위치 순서를 파악하는 추론을 요구합니다. 그리고 size query는 “가장 큰 물건“, “넓은 선”과 같이 크기와 관련된 단순 형용사 또는 최상급 형태의 묘사를 사용합니다. 저자는 attribute detection API가 픽셀 단위의 연산과 python 함수들을 사용함으로써 OVD보다 우수할 것이라 예상했습니다.
B. Non-visually Perceivable Attributes
계속 언급했듯이 저자들은 시각적으로 인지할 수 없는 속성도 추론하고자 하였는데, 그 중에서도 무게에 초점을 맞추어 실험을 진행했습니다. 이 실험도 적합한 데이터셋이 없어 GPT-4를 이용해 다양한 무게를 가진 object 집합과 그 중 가장 무거운 객체의 정답 label을 생성하였습니다. 이때 객체 간 무게 분포는 명확하게 설계하였다고 하며, 그 예시로는 “깃털, 개 자동차”가 있습니다. 일반적으로 기대하듯이 VLM의 기본적인 상식 추론 능력을 가정할 때, 이러한 객체들 중 가장 무거운 객체를 찾는 것은 어렵지 않을 것입니다. 저자들은 OVD: find(”a heavy object”), VQA: visual query(”Out of these items, which on is the heaviest?”)와, 저자들이 제시하는 (VQA+GPT): visual_query(”What are the items in this image?”) → language_query(”Out of these items, which one is more likely to be the heaviest one?”)의 성능을 비교합니다.
C. Evaluation in Embodied Settings
Perception-action API를 평가하기 위해, 시뮬레이션 AI2-THOR의 가정 환경에서 평가하였습니다. 로봇에는 근접 센서와 gripper의 손목에 장착되어 객체의 무게를 측정할 수 있는 힘/토크 센서가 있다고 가정합니다. Perception-action API가 로봇 카메라로부터 객체까지의 상대적인 거리를 추정하고, 가장 가벼운 객체를 식별하도록 하여 정확도를 측정합니다. 이때 baseline은 OVD, VQA, GPT-4o, 그리고 단독 attribute detection API(VQA/OVD+GPT-4)입니다. 저자들은 perception-action API에서 LLM이 생성하는 프로그램이 센서 기반의 시각 추론과 로봇 action을 활용해 환경과 능동적으로 상호작용할 수 있다고 예상하였습니다.
D. Hypotheses
저자들의 가설을 다음과 같이 형식화할 수 있습니다.
H1. OVD+GPT는 location, size query에서 OVD 및 VQA 단독 baseline보다 우수할 것임
H2. VLM은 무게를 추정할 수 있는 기본적인 추론 능력을 가지고 있음
H3. 형용사의 최상급 형태는 일반 형태보다 더 나은 grounding 성능을 제공할 것임
H4. perception-action API는 능동적으로 환경과 상호작용하여 attribute detection query를 해결할 것임
E. Results & Discussion
H1.
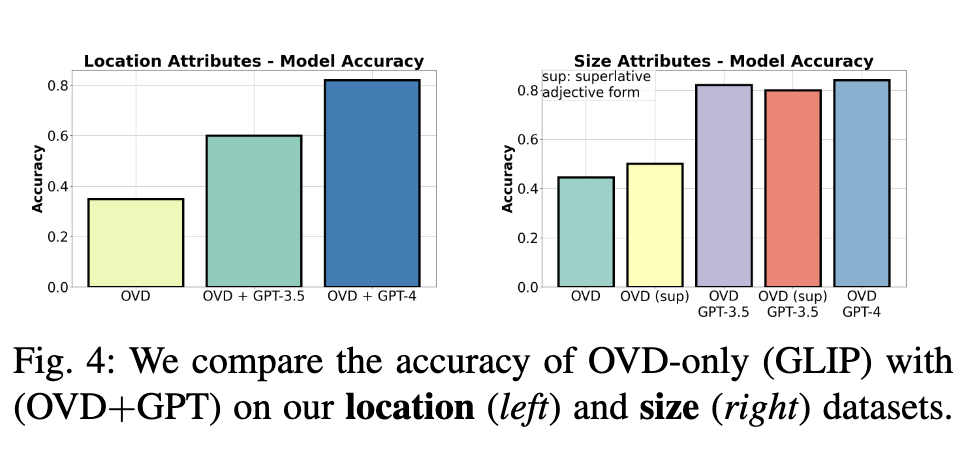

OVD+GPT는 location, size query에서 OVD 및 VQA 단독 baseline보다 우수할 것임
가설에 부합하게 저자들이 제안한 방식이 가장 우수한 성능을 보였다고 하며 Fig. 4는 정량적인 정확도 지표를, Fig. 6는 두 모델의 추론 예시를 정성적으로 보여주고 있습니다.
Fig. 6의 예시 a에서 작은 사과라는 query가 들어왔을 때 OVD 모델은 모든 사과를 검출한 반면 OVD+GPT 방식은 가장 작은 빨간 사과만 검출했는데요, 이 부분에 대해서 딱히 저자의 언급은 없었고 그저 두 모델 모두 올바르게 사과를 검출했다고만 설명하고 있습니다.
b는 실패 사례인데, 두 모델 모두 여러 개의 클립을 하나의 bounding box로 묶어버렸습니다.
c, d는 OVD+GPT가 OVD보다 우수한 사례입니다. 이러한 예시에서, scene 내의 모든 object instance는 find 함수를 통해 localize 되고, bounding box의 좌표와 중심점은 상대 거리와 면적을 계산하는 데 사용됩니다. c에서 보이듯 OVD+GPT 방식은 짧다라는 의미를 잘 이해하여 shortest pepper를 알맞게 찾았음을 확인할 수 있습니다. 그러나 사용하는 GPT의 버전에 따라 성능에 차이가 있었다고 합니다. GPT-4는 이미지 내 object의 방향에 따라 long 또는 short이라는 치수가 가로 세로 중 무엇에 해당하는지 해석할 수 있습니다. 반면 GPT-3.5는 하드코딩된 치수에 특정 형용사를 연결하는 경향이 있습니다. 그럼에도 불구하고 일반적인 OVD보다는 attribute detection 능력이 우수하게 나타났습니다.
마지막으로 d에서는 타르트의 배열이 행과 열 패턴을 가지고 있음을 이해하는 것을 확인할 수 있습니다.
H2.
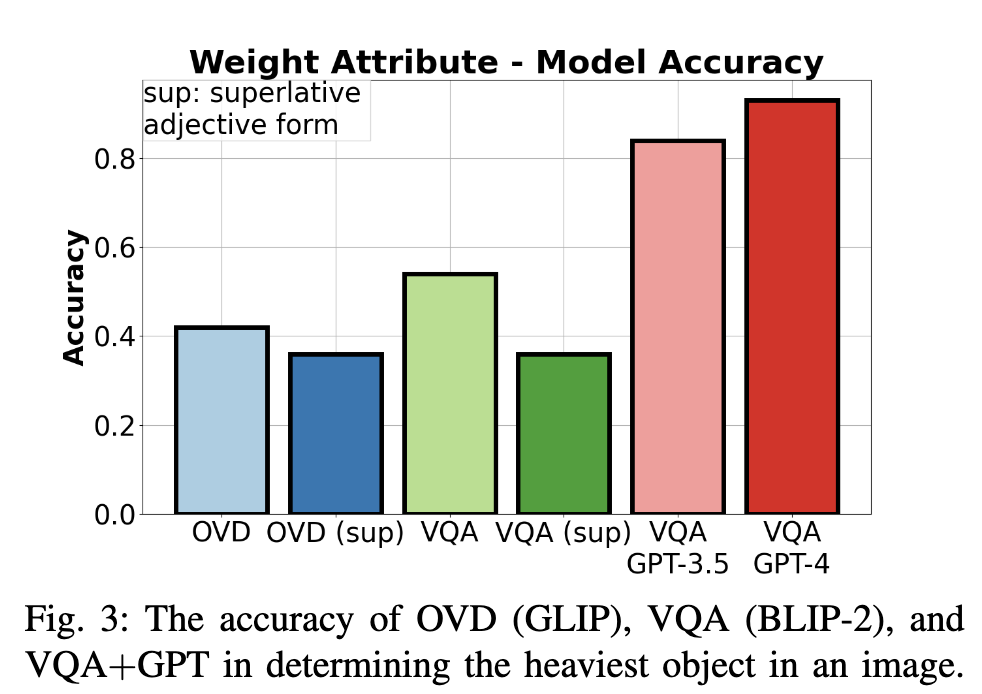
VLM은 무게를 추정할 수 있는 기본적인 추론 능력을 가지고 있음
이 가설은 부분적으로만 확인되었습니다. Fig. 3에 따르면 OVD나 VQA 단독보다 VQA와 LLM을 결합한 방식이 훨씬 높은 accuracy를 보이고 있습니다. 이는 VQA와 같은 VLM이 무게 비교를 할 수 있는 추론 능력을 갖추고 있다는 가정과 충돌합니다. VQA 단독은 OVD보다는 성능이 높지만, 결국 높은 성능을 위해서는 LLM의 결합이 피요했습니다.
H3.
형용사의 최상급 형태는 일반 형태보다 더 나은 grounding 성능을 제공할 것임
이 가설은 기각되었습니다. Fig. 3에서 OVD(sup)과 VQA(sup)은 최상급 형용사 형태를 사용했음을 나타내는데, 모두 일반 형태를 사용했을 때보다 정확도가 낮음을 확인할 수 있습니다.
H4.
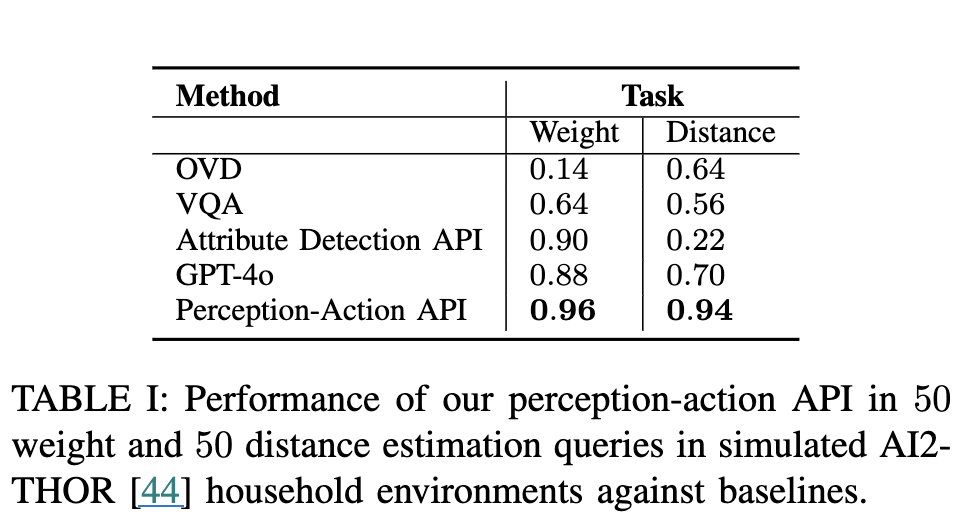
perception-action API는 능동적으로 환경과 상호작용하여 attribute detection query를 해결할 것임
저자의 perception-action API 방식이 weight와 distance 모두에서 모든 baseline보다 높은 정확도를 달성하였습니다. distance 추정에서 로봇은 “find”를 사용해 object patch를 식별하고, “focus_on_patch”를 사용해 감지된 object patch의 중심과 카메라 이미지 프레임의 중심을 맞추고, “measure_distance”를 호출해 거리 센서를 활용하여 거리를 측정합니다. weight를 예측할 때는 “find”를 사용해 patch를 찾은 후, “go_to_object”를 사용해 객체에 접근하고 force/torque 센서를 사용하여 “measuer_weight”를 호출해 무게를 측정합니다. 이후 이전에 저장된 최소값과 비교해 현재 값이 더 낮으면 업데이트하는 방식으로 최소 거리 또는 무게를 도출합니다.
5. Limitations & Future Work
Sensor Integration
향후 저자들은 이 API이 구조의 compositionality를 활용하여 더 많은 센서(IMU, 온도 센서 등)를 통합해 감지 능력을 확장하고, 능동적인 지각을 통해 추가적인 attribute detection을 연구할 계획이라고 합니다.
Error Propagation across Model Calls
VQA+GPT와 같은 구조가 OVD나 VQA 모델을 개별적으로 호출하는 것보다 더 나은 성능을 보임을 입증했지만, 이 구조의 앞 부분에서 잘못된 결과를 반환하면, 이 실패를 감지하지 못하고 연이어 잘못된 결과를 도출하게 됩니다. 따라서 향후 저자들은 이러한 실패를 탐지할 수 있도록 환경으로부터 추가적인 feedback을 받는 메커니즘을 개발할 계획이라고 합니다.
예은님 좋은 리뷰 감사합니다.
해당 논문에서 attribute이 어떤역할을 하는 지 잘 이해가 되지 않습니다. 혹시 설명해주실 수 있을까요? 해당 연구의 목적은 embodied 환경에서, 특정 속성을 알아내기 위한 로봇 작업이 가능하도록 하는 것 일까요?
Fig. 6에서 small appl;el에 대해 green 박스에 해당하는 OVD 모델은 서양 배도 사과라 잘못 인식한 것 같은데, 제대로 예측을 한 게 맞나요?
‘형용사의 최상급 형태는 일반 형태보다 더 나은 grounding 성능을 제공할 것’이라는 저자들의 가설이 물론 실제 실험 결과 일치하지 않다고는 하지만, 어떻게 도출된 가설인지가 궁금합니다. 이에 대한 저자들의 부가 설명이 있었다면 설명 부탁드립니다.